


《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (7): 2256-2264.DOI: 10.11772/j.issn.1001-9081.2021050810
陈海龙( ), 杨畅, 杜梅, 张颖宇
), 杨畅, 杜梅, 张颖宇
收稿日期:2021-05-18
修回日期:2021-09-29
接受日期:2021-10-12
发布日期:2022-07-15
出版日期:2022-07-10
通讯作者:
陈海龙
作者简介:杨畅(1997—),女,黑龙江绥化人,硕士研究生,主要研究方向:机器学习基金资助:
Hailong CHEN(), Chang YANG, Mei DU, Yingyu ZHANG
Received:2021-05-18
Revised:2021-09-29
Accepted:2021-10-12
Online:2022-07-15
Published:2022-07-10
Contact:
Hailong CHEN
About author:YANG Chang, born in 1997, M. S. candidate. Her research interests include machine learning.Supported by:摘要:
针对信用风险评估中数据集不平衡影响模型预测效果的问题,提出一种基于边界自适应合成少数类过采样方法(BA-SMOTE)和利用Focal Loss函数改进LightGBM损失函数的算法(FLLightGBM)相结合的信用风险预测模型。首先,在边界合成少数类过采样(Borderline-SMOTE)的基础上,引入自适应思想和新的插值方式,使每个处于边界的少数类样本生成不同数量的新样本,并且新样本的位置更靠近原少数类样本,以此来平衡数据集;其次,利用Focal Loss函数来改进LightGBM算法的损失函数,并以改进的算法训练新的数据集以得到最终结合BA-SMOTE方法和FLLightGBM算法建立的BA-SMOTE-FLLightGBM模型;最后,在Lending Club数据集上进行信用风险预测。实验结果表明,与其他不平衡分类算法RUSBoost、CUSBoost、KSMOTE-AdaBoost和AK-SMOTE-Catboost相比,所建立的模型在G-mean和AUC两个指标上都有明显的提升,提升了9.0%~31.3%和5.0%~14.1%。以上结果验证了所提出的模型在信用风险评估中具有更好的违约预测效果。
中图分类号:
陈海龙, 杨畅, 杜梅, 张颖宇. 基于边界自适应SMOTE和Focal Loss函数改进LightGBM的信用风险预测模型[J]. 计算机应用, 2022, 42(7): 2256-2264.
Hailong CHEN, Chang YANG, Mei DU, Yingyu ZHANG. Credit risk prediction model based on borderline adaptive SMOTE and Focal Loss improved LightGBM[J]. Journal of Computer Applications, 2022, 42(7): 2256-2264.
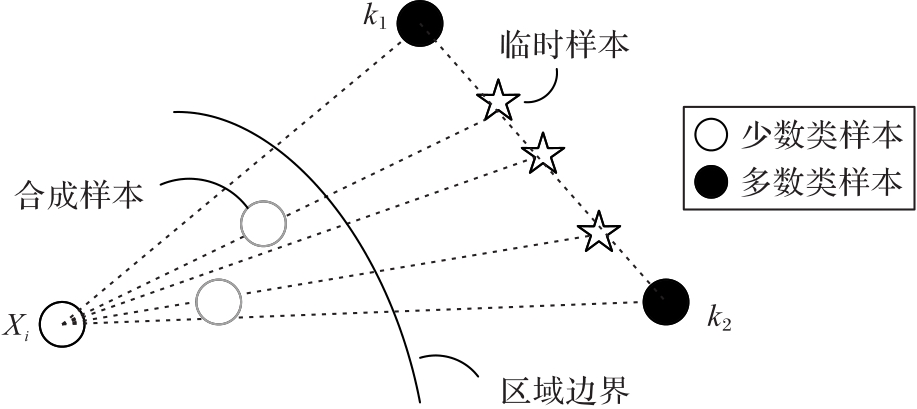
图1 第一种插值方式
Fig.1 First interpolation method

图2 第二种插值方式
Fig.2 Second interpolation method

图3 建模流程
Fig.3 Modeling flow

图 4 贷款状态分布
Fig.4 Distribution of loan status
| 序号 | 特征 | 重要性 | 序号 | 特征 | 重要性 | 序号 | 特征 | 重要性 |
|---|---|---|---|---|---|---|---|---|
| 1 | loan_amnt | 0.131 9 | 7 | verification_status | 0.072 0 | 13 | pub_rec | 0.022 6 |
| 2 | term | 0.100 8 | 8 | dti | 0.064 3 | 14 | revol_bal | 0.019 4 |
| 3 | int_rate | 0.091 5 | 9 | deling_2yrs | 0.061 2 | 15 | total_acc | 0.019 3 |
| 4 | grade | 0.081 4 | 10 | inq_last_6mths | 0.058 1 | 16 | total_bc_limit | 0.013 4 |
| 5 | home_ownership | 0.080 3 | 11 | acc_open_past_24mths | 0.051 1 | 17 | bc_util | 0.012 6 |
| 6 | annual_inc | 0.077 9 | 12 | open_acc | 0.023 8 | 18 | out_prncp_inv | 0.009 1 |
表1 特征及其重要性
Tab.1 Features and their importances
| 序号 | 特征 | 重要性 | 序号 | 特征 | 重要性 | 序号 | 特征 | 重要性 |
|---|---|---|---|---|---|---|---|---|
| 1 | loan_amnt | 0.131 9 | 7 | verification_status | 0.072 0 | 13 | pub_rec | 0.022 6 |
| 2 | term | 0.100 8 | 8 | dti | 0.064 3 | 14 | revol_bal | 0.019 4 |
| 3 | int_rate | 0.091 5 | 9 | deling_2yrs | 0.061 2 | 15 | total_acc | 0.019 3 |
| 4 | grade | 0.081 4 | 10 | inq_last_6mths | 0.058 1 | 16 | total_bc_limit | 0.013 4 |
| 5 | home_ownership | 0.080 3 | 11 | acc_open_past_24mths | 0.051 1 | 17 | bc_util | 0.012 6 |
| 6 | annual_inc | 0.077 9 | 12 | open_acc | 0.023 8 | 18 | out_prncp_inv | 0.009 1 |
| 实际类别 | 预测类别 | |
|---|---|---|
| 正类 | 负类 | |
| 正类 | TP | FN |
| 负类 | FP | TN |
表 2 混淆矩阵
Tab.2 Confusion matrix
| 实际类别 | 预测类别 | |
|---|---|---|
| 正类 | 负类 | |
| 正类 | TP | FN |
| 负类 | FP | TN |
| 算法 | 参数取值 (b,ε) | F1-score | G-mean | AUC | KS |
|---|---|---|---|---|---|
| LightGBM | (0.5,0.3) | 0.971 5 | 0.681 2 | 0.825 1 | 0.515 0 |
| (0.5,0.5) | 0.972 9 | 0.688 3 | 0.826 0 | 0.506 7 | |
| (1,0.3) | 0.976 5 | 0.693 1 | 0.830 9 | 0.519 4 | |
| (1,0.5) | 0.9773 | 0.7226 | 0.8360 | 0.5409 | |
| XGBoost | (0.5,0.3) | 0.971 8 | 0.664 5 | 0.812 4 | 0.537 6 |
| (0.5,0.5) | 0.970 7 | 0.658 4 | 0.817 4 | 0.518 5 | |
| (1,0.3) | 0.974 6 | 0.674 4 | 0.826 1 | 0.538 8 | |
| (1,0.5) | 0.9765 | 0.6916 | 0.8268 | 0.5401 | |
| GBDT | (0.5,0.3) | 0.960 2 | 0.630 7 | 0.789 2 | 0.448 3 |
| (0.5,0.5) | 0.9710 | 0.668 3 | 0.790 1 | 0.459 7 | |
| (1,0.3) | 0.970 2 | 0.649 9 | 0.784 0 | 0.453 7 | |
| (1,0.5) | 0.970 5 | 0.6704 | 0.7903 | 0.4618 | |
| RF | (0.5,0.3) | 0.970 1 | 0.657 2 | 0.788 5 | 0.466 9 |
| (0.5,0.5) | 0.961 2 | 0.650 1 | 0.786 1 | 0.472 7 | |
| (1,0.3) | 0.966 5 | 0.648 7 | 0.780 2 | 0.458 8 | |
| (1,0.5) | 0.9709 | 0.6786 | 0.8077 | 0.4883 | |
| LR | (0.5,0.3) | 0.829 8 | 0.631 0 | 0.742 0 | 0.375 5 |
| (0.5,0.5) | 0.831 5 | 0.644 1 | 0.762 7 | 0.4156 | |
| (1,0.3) | 0.824 3 | 0.652 8 | 0.762 4 | 0.409 6 | |
| (1,0.5) | 0.8334 | 0.6546 | 0.7645 | 0.413 3 |
表3 不同b,ε下的分类效果对比
Tab.3 Comparison of classification effect under different b, ε
| 算法 | 参数取值 (b,ε) | F1-score | G-mean | AUC | KS |
|---|---|---|---|---|---|
| LightGBM | (0.5,0.3) | 0.971 5 | 0.681 2 | 0.825 1 | 0.515 0 |
| (0.5,0.5) | 0.972 9 | 0.688 3 | 0.826 0 | 0.506 7 | |
| (1,0.3) | 0.976 5 | 0.693 1 | 0.830 9 | 0.519 4 | |
| (1,0.5) | 0.9773 | 0.7226 | 0.8360 | 0.5409 | |
| XGBoost | (0.5,0.3) | 0.971 8 | 0.664 5 | 0.812 4 | 0.537 6 |
| (0.5,0.5) | 0.970 7 | 0.658 4 | 0.817 4 | 0.518 5 | |
| (1,0.3) | 0.974 6 | 0.674 4 | 0.826 1 | 0.538 8 | |
| (1,0.5) | 0.9765 | 0.6916 | 0.8268 | 0.5401 | |
| GBDT | (0.5,0.3) | 0.960 2 | 0.630 7 | 0.789 2 | 0.448 3 |
| (0.5,0.5) | 0.9710 | 0.668 3 | 0.790 1 | 0.459 7 | |
| (1,0.3) | 0.970 2 | 0.649 9 | 0.784 0 | 0.453 7 | |
| (1,0.5) | 0.970 5 | 0.6704 | 0.7903 | 0.4618 | |
| RF | (0.5,0.3) | 0.970 1 | 0.657 2 | 0.788 5 | 0.466 9 |
| (0.5,0.5) | 0.961 2 | 0.650 1 | 0.786 1 | 0.472 7 | |
| (1,0.3) | 0.966 5 | 0.648 7 | 0.780 2 | 0.458 8 | |
| (1,0.5) | 0.9709 | 0.6786 | 0.8077 | 0.4883 | |
| LR | (0.5,0.3) | 0.829 8 | 0.631 0 | 0.742 0 | 0.375 5 |
| (0.5,0.5) | 0.831 5 | 0.644 1 | 0.762 7 | 0.4156 | |
| (1,0.3) | 0.824 3 | 0.652 8 | 0.762 4 | 0.409 6 | |
| (1,0.5) | 0.8334 | 0.6546 | 0.7645 | 0.413 3 |

图5 不同(α,γ)下FLLightGBM的G-mean值和AUC值
Fig.5 G-mean and AUC values of FLLightGBM under different (α,γ)
| 算法 | F1-score | G-mean | AUC | KS |
|---|---|---|---|---|
| LightGBM | 0.952 4 | 0.601 7 | 0.778 5 | 0.437 2 |
| BA-SMOTE-LightGBM | 0.977 3 | 0.722 6 | 0.836 0 | 0.540 9 |
| BA-SMOTE-FLLightGBM | 0.978 2 | 0.783 2 | 0.851 9 | 0.565 7 |
表4 不同改进方法的阶段性实验对比结果
Tab.4 Phase experimental comparison results of different improvement methods
| 算法 | F1-score | G-mean | AUC | KS |
|---|---|---|---|---|
| LightGBM | 0.952 4 | 0.601 7 | 0.778 5 | 0.437 2 |
| BA-SMOTE-LightGBM | 0.977 3 | 0.722 6 | 0.836 0 | 0.540 9 |
| BA-SMOTE-FLLightGBM | 0.978 2 | 0.783 2 | 0.851 9 | 0.565 7 |
| 算法 | F1-score | G-mean | AUC | KS |
|---|---|---|---|---|
| SMOTE-FLLightGBM | 0.969 1 | 0.641 5 | 0.794 1 | 0.462 1 |
| Borderline-SMOTE-FLLightGBM | 0.976 4 | 0.698 9 | 0.826 3 | 0.484 5 |
| ADASYN-FLLightGBM | 0.977 5 | 0.696 3 | 0.812 4 | 0.475 8 |
| BA-SMOTE-FLLightGBM | 0.978 2 | 0.783 2 | 0.851 9 | 0.565 7 |
| SMOTE-XGBoost | 0.953 9 | 0.607 4 | 0.785 3 | 0.452 4 |
| Borderline-SMOTE-XGBoost | 0.958 1 | 0.629 8 | 0.795 4 | 0.466 5 |
| ADASYN-XGBoost | 0.962 9 | 0.632 6 | 0.786 7 | 0.457 5 |
| BA-SMOTE-XGBoost | 0.976 5 | 0.691 6 | 0.826 8 | 0.540 1 |
| SMOTE-GBDT | 0.956 6 | 0.605 9 | 0.782 2 | 0.458 3 |
| Borderline-SMOTE-GBDT | 0.960 1 | 0.618 2 | 0.784 5 | 0.454 7 |
| ADASYN-GBDT | 0.968 2 | 0.602 4 | 0.775 1 | 0.446 3 |
| BA-SMOTE-GBDT | 0.970 5 | 0.670 4 | 0.790 3 | 0.461 8 |
| SMOTE-RF | 0.968 2 | 0.596 6 | 0.778 6 | 0.463 3 |
| Borderline-SMOTE-RF | 0.967 9 | 0.622 7 | 0.793 2 | 0.470 8 |
| ADASYN-RF | 0.969 7 | 0.616 1 | 0.787 4 | 0.459 2 |
| BA-SMOTE-RF | 0.970 9 | 0.678 6 | 0.807 7 | 0.488 3 |
| SMOTE-LR | 0.821 6 | 0.559 6 | 0.739 5 | 0.370 4 |
| Borderline-SMOTE-LR | 0.856 5 | 0.603 5 | 0.747 3 | 0.375 6 |
| ADASYN-LR | 0.802 7 | 0.624 9 | 0.749 9 | 0.377 8 |
| BA-SMOTE-LR | 0.833 4 | 0.654 6 | 0.764 5 | 0.413 3 |
表5 不同过采样方法的实验结果比较
Tab.5 Experimental results comparison of different oversampling methods
| 算法 | F1-score | G-mean | AUC | KS |
|---|---|---|---|---|
| SMOTE-FLLightGBM | 0.969 1 | 0.641 5 | 0.794 1 | 0.462 1 |
| Borderline-SMOTE-FLLightGBM | 0.976 4 | 0.698 9 | 0.826 3 | 0.484 5 |
| ADASYN-FLLightGBM | 0.977 5 | 0.696 3 | 0.812 4 | 0.475 8 |
| BA-SMOTE-FLLightGBM | 0.978 2 | 0.783 2 | 0.851 9 | 0.565 7 |
| SMOTE-XGBoost | 0.953 9 | 0.607 4 | 0.785 3 | 0.452 4 |
| Borderline-SMOTE-XGBoost | 0.958 1 | 0.629 8 | 0.795 4 | 0.466 5 |
| ADASYN-XGBoost | 0.962 9 | 0.632 6 | 0.786 7 | 0.457 5 |
| BA-SMOTE-XGBoost | 0.976 5 | 0.691 6 | 0.826 8 | 0.540 1 |
| SMOTE-GBDT | 0.956 6 | 0.605 9 | 0.782 2 | 0.458 3 |
| Borderline-SMOTE-GBDT | 0.960 1 | 0.618 2 | 0.784 5 | 0.454 7 |
| ADASYN-GBDT | 0.968 2 | 0.602 4 | 0.775 1 | 0.446 3 |
| BA-SMOTE-GBDT | 0.970 5 | 0.670 4 | 0.790 3 | 0.461 8 |
| SMOTE-RF | 0.968 2 | 0.596 6 | 0.778 6 | 0.463 3 |
| Borderline-SMOTE-RF | 0.967 9 | 0.622 7 | 0.793 2 | 0.470 8 |
| ADASYN-RF | 0.969 7 | 0.616 1 | 0.787 4 | 0.459 2 |
| BA-SMOTE-RF | 0.970 9 | 0.678 6 | 0.807 7 | 0.488 3 |
| SMOTE-LR | 0.821 6 | 0.559 6 | 0.739 5 | 0.370 4 |
| Borderline-SMOTE-LR | 0.856 5 | 0.603 5 | 0.747 3 | 0.375 6 |
| ADASYN-LR | 0.802 7 | 0.624 9 | 0.749 9 | 0.377 8 |
| BA-SMOTE-LR | 0.833 4 | 0.654 6 | 0.764 5 | 0.413 3 |

图6 不同过采样方法的ROC曲线
Fig.6 ROC curves of different oversampling methods
| 算法 | F1-score | G-mean | AUC | KS |
|---|---|---|---|---|
| RUSBoost | 0.853 7 | 0.596 5 | 0.746 5 | 0.378 7 |
| CUSBoost | 0.935 2 | 0.634 1 | 0.781 5 | 0.445 2 |
| KSMOTE-AdaBoost | 0.954 9 | 0.705 6 | 0.792 3 | 0.453 6 |
| AK-SMOTE-Catboost | 0.961 7 | 0.718 5 | 0.811 5 | 0.473 1 |
| BA-SMOTE-FLLightGBM | 0.978 2 | 0.783 2 | 0.851 9 | 0.565 7 |
表6 所提模型与其他不平衡分类算法的结果比较
Tab.6 Results comparison among the proposed model and other imbalanced classification algorithms
| 算法 | F1-score | G-mean | AUC | KS |
|---|---|---|---|---|
| RUSBoost | 0.853 7 | 0.596 5 | 0.746 5 | 0.378 7 |
| CUSBoost | 0.935 2 | 0.634 1 | 0.781 5 | 0.445 2 |
| KSMOTE-AdaBoost | 0.954 9 | 0.705 6 | 0.792 3 | 0.453 6 |
| AK-SMOTE-Catboost | 0.961 7 | 0.718 5 | 0.811 5 | 0.473 1 |
| BA-SMOTE-FLLightGBM | 0.978 2 | 0.783 2 | 0.851 9 | 0.565 7 |
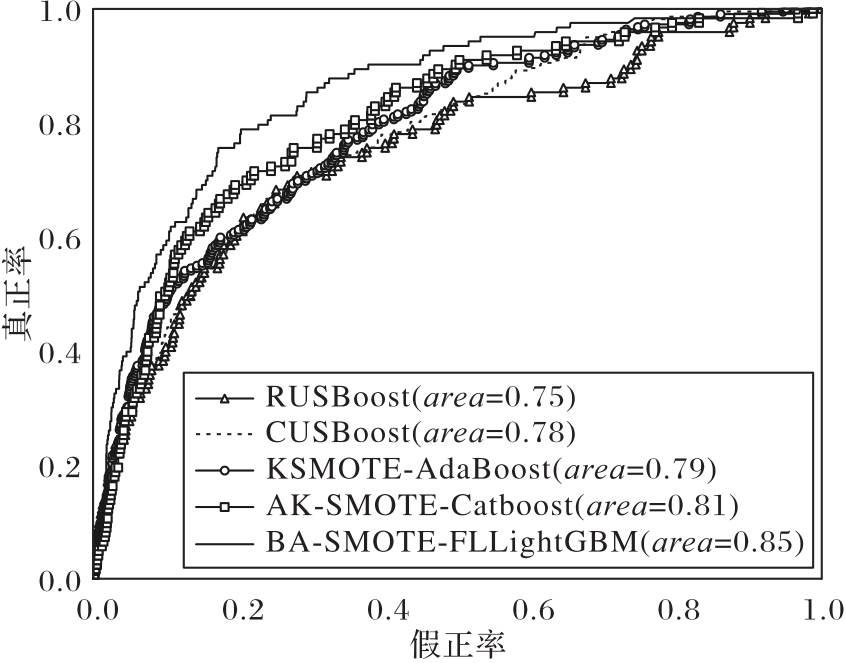
图7 不同不平衡分类算法的ROC曲线
Fig.7 ROC curves of different imbalanced classification algorithms
| 算法 | F1-score | G-mean | AUC | KS |
|---|---|---|---|---|
| RUSBoost | 0.766 8 | 0.579 4 | 0.742 8 | 0.376 4 |
| CUSBoost | 0.781 2 | 0.597 1 | 0.747 3 | 0.395 0 |
| KSMOTE-AdaBoost | 0.825 4 | 0.620 1 | 0.759 5 | 0.398 4 |
| AK-SMOTE-Catboost | 0.834 4 | 0.632 6 | 0.761 3 | 0.412 5 |
| BA-SMOTE-FLLightGBM | 0.856 0 | 0.657 8 | 0.788 4 | 0.447 3 |
表7 German数据集上的算法比较结果
Tab.7 Comparison results of algorithms on German dataset
| 算法 | F1-score | G-mean | AUC | KS |
|---|---|---|---|---|
| RUSBoost | 0.766 8 | 0.579 4 | 0.742 8 | 0.376 4 |
| CUSBoost | 0.781 2 | 0.597 1 | 0.747 3 | 0.395 0 |
| KSMOTE-AdaBoost | 0.825 4 | 0.620 1 | 0.759 5 | 0.398 4 |
| AK-SMOTE-Catboost | 0.834 4 | 0.632 6 | 0.761 3 | 0.412 5 |
| BA-SMOTE-FLLightGBM | 0.856 0 | 0.657 8 | 0.788 4 | 0.447 3 |
| 1 | 马晓君,沙靖岚,牛雪琪. 基于LightGBM算法的P2P项目信用评级模型的设计及应用[J]. 数量经济技术经济研究, 2018, 35(5):144-160. 10.1016/j.elerap.2018.08.002 |
| MA X J, SHA J L, NIU X Q. An empirical study on the credit rating of P2P projects based on LightGBM algorithm[J]. The Journal of Quantitative and Technical Economics, 2018, 35(5): 144-160. 10.1016/j.elerap.2018.08.002 | |
| 2 | 谢陈昕. P2P网贷平台借款人信用风险评估模型适应性研究[J]. 武汉金融, 2019(3):23-29. 10.3969/j.issn.1009-3540.2019.03.005 |
| XIE C X. Research on adaptability of credit risk assessment model for borrowers of P2P online lending platform[J]. Wuhan Finance, 2019(3): 23-29. 10.3969/j.issn.1009-3540.2019.03.005 | |
| 3 | COSTA E SILVA E, LOPES I C, CORREIA A, et al. A logistic regression model for consumer default risk[J]. Journal of Applied Statistics, 2020, 47(13/14/15): 2879-2894. 10.1080/02664763.2020.1759030 |
| 4 | BEKHET H A, ELETTER S F K. Credit risk assessment model for Jordanian commercial banks: neural scoring approach[J]. Review of Development Finance, 2014, 4(1): 20-28. 10.1016/j.rdf.2014.03.002 |
| 5 | WANG T, LI J C. An improved support vector machine and its application in P2P lending personal credit scoring[J]. IOP Conference Series: Materials Science and Engineering, 2019, 490(6): No.062041. 10.1088/1757-899x/490/6/062041 |
| 6 | 邵良杉,周玉. 一种改进过采样算法在类别不平衡信用评分中的应用[J]. 计算机应用研究, 2019, 36(6):1683-1687. |
| SHAO L S, ZHOU Y. Application of improved oversampling algorithm in class-imbalance credit scoring[J]. Application Research of Computers, 2019, 36(6): 1683-1687. | |
| 7 | GARCÍA V, SÁNCHEZ J S, MOLLINEDA R A. On the effectiveness of preprocessing methods when dealing with different levels of class imbalance[J]. Knowledge-Based Systems, 2012, 25(1): 13-21. 10.1016/j.knosys.2011.06.013 |
| 8 | 陈启伟,王伟,马迪,等. 基于Ext-GBDT集成的类别不平衡信用评分模型[J]. 计算机应用研究, 2018, 35(2):421-427. 10.3969/j.issn.1001-3695.2018.02.022 |
| CHEN Q W, WANG W, MA D, et al. Class-imbalance credit scoring using Ext-GBDT ensemble[J]. Application Research of Computers, 2018, 35(2): 421-427. 10.3969/j.issn.1001-3695.2018.02.022 | |
| 9 | CHAWLA N V, BOWYER K W, HALL L O, et al. SMOTE: Synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2002, 16: 321-357. 10.1613/jair.953 |
| 10 | NIU A W, CAI B Q, CAI S S, et al. Big data analytics for complex credit risk assessment of network lending based on SMOTE algorithm[J] Complexity, 2020, 2020: No.8563030. 10.1155/2020/8563030 |
| 11 | KHEMAKHEM S, SAID F BEN, BOUJELBENE Y. Credit risk assessment for unbalanced datasets based on data mining, artificial neural network and support vector machines[J]. Journal of Modelling in Management, 2018, 13(4): 932-951. 10.1108/jm2-01-2017-0002 |
| 12 | 王超学,张涛,马春森. 面向不平衡数据集的改进型SMOTE算法[J]. 计算机科学与探索, 2014, 8(6):727-734. |
| WANG C X, ZHANG T, MA C S. Improved SMOTE algorithm for imbalanced datasets[J]. Journal of Frontiers of Computer Science and Technology, 2014, 8(6): 727-734. | |
| 13 | HAN H, WANG W Y, MAO B H. Border-line-SMOTE: a new over-sampling method in imbalanced data sets learning[C]// Proceedings of the 2005 International Conference on Intelligent Computing, LNCS 3644. Berlin: Springer, 2005: 878-887. |
| 14 | NAKAMURA M, KAJIWARA Y, OTSUKA A, et al. LVQ-SMOTE — learning vector quantization based synthetic minority over-sampling technique for biomedical data[J]. BioData Mining, 2013, 6: No.16. 10.1186/1756-0381-6-16 |
| 15 | 田臣,周丽娟. 基于带多数类权重的少数类过采样技术和随机森林的信用评估方法[J]. 计算机应用, 2019, 39(6):1707-1712. 10.11772/j.issn.1001-9081.2018102180 |
| TIAN C, ZHOU L J. Credit assessment method based on majority weight minority oversampling technique and random forest[J]. Journal of Computer Applications, 2019, 39(6): 1707-1712. 10.11772/j.issn.1001-9081.2018102180 | |
| 16 | BARUA S, ISLAM M M, YAO X, et al. MWMOTE — majority weighted minority oversampling technique for imbalanced data set learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(2):405-425. 10.1109/tkde.2012.232 |
| 17 | HE H B, BAI Y, GARCIA E A, et al. ADASYN: adaptive synthetic sampling approach for imbalanced learning[C]// Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence). Piscataway: IEEE, 2008: 1322-1328. 10.1109/ijcnn.2008.4633969 |
| 18 | 赵楠,张小芳,张利军. 不平衡数据分类研究综述[J]. 计算机科学, 2018, 45(6A):22-27, 57. 10.11896/j.issn.1002-137X.2018.Z6.004 |
| ZHAO N, ZHANG X F, ZHANG L J. Overview of imbalanced data classification[J]. Computer Science, 2018, 45(6A):22-27, 57. 10.11896/j.issn.1002-137X.2018.Z6.004 | |
| 19 | 吴雨茜,王俊丽,杨丽,等. 代价敏感深度学习方法研究综述[J]. 计算机科学, 2019, 46(5):1-12. 10.11896/j.issn.1002-137X.2019.05.001 |
| WU Y X, WANG J L, YANG L, et al. Survey on cost-sensitive deep learning methods[J]. Computer Science, 2019, 46(5):1-12. 10.11896/j.issn.1002-137X.2019.05.001 | |
| 20 | 陈白强,盛静文,江开忠. 基于损失函数的代价敏感集成算法[J]. 计算机应用, 2020, 40(S2):60-65. |
| CHEN B Q, SHENG J W, JIANG K Z. Cost-sensitive ensemble algorithm based on loss function[J]. Journal of Computer Applications, 2020, 40(S2):60-65. | |
| 21 | 王俊红,闫家荣. 基于欠采样和代价敏感的不平衡数据分类算法[J]. 计算机应用, 2021, 41(1):48-52. |
| WANG J H, YAN J R. Classification algorithm based on undersampling and cost-sensitiveness for unbalanced data[J]. Journal of Computer Applications, 2021, 41(1):48-52. | |
| 22 | WANG C, DENG C Y, WANG S Z. Imbalance-XGBoost: leveraging weighted and focal losses for binary label-imbalanced classification with XGBoost[J]. Pattern Recognition Letters, 2020, 136: 190-197. 10.1016/j.patrec.2020.05.035 |
| 23 | SEIFFERT C, KHOSHGOFTAAR T M, VAN HULSE J, et al. RUSBoost: a hybrid approach to alleviating class imbalance[J]. IEEE Transactions on Systems, Man, and Cybernetics — Part A: Systems and Humans, 2010, 40(1):185-197. 10.1109/tsmca.2009.2029559 |
| 24 | RAYHAN F, AHMED S, MAHBUB A, et al. CUSBoost: cluster-based under-sampling with boosting for imbalanced classification[C]// Proceedings of the 2nd International Conference on Computational Systems and Information Technology for Sustainable Solutions. Piscataway: IEEE, 2017: 1-5. 10.1109/csitss.2017.8447534 |
| 25 | 王忠震,黄勃,方志军,等. 改进SMOTE的不平衡数据集成分类算法[J]. 计算机应用, 2019, 39(9):2591-2596. 10.11772/j.issn.1001-9081.2019030531 |
| WANG Z Z, HUANG B, FANG Z J, et al. Improved SMOTE unbalanced data integration classification algorithm[J]. Journal of Computer Applications, 2019, 39(9):2591-2596. 10.11772/j.issn.1001-9081.2019030531 | |
| 26 | 张德鑫,雒腾,曾志勇. 基于改进的SMOTE采样Catboost分类算法[J]. 信息通信, 2020(1):57-60. 10.3969/j.issn.1673-1131.2020.01.026 |
| ZHANG D X, LUO T, ZENG Z Y. Catboost classification algorithm based on improved SMOTE sampling[J]. Information & Communications, 2020(1):57-60. 10.3969/j.issn.1673-1131.2020.01.026 | |
| 27 | KE G L, MENG Q, FINLEY T, et al. LightGBM: a highly efficient gradient boosting decision tree[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 3149-3157. |
| 28 | LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(2): 318-327. 10.1109/tpami.2018.2858826 |
| 29 | 宋玲玲,王时绘,杨超,等. 改进的XGBoost在不平衡数据处理中的应用研究[J]. 计算机科学, 2020, 47(6):98-103. 10.11896/jsjkx.191200138 |
| SONG L L, WANG S H, YANG C, et al. Application research of improved XGBoost in unbalanced data processing[J]. Computer Science, 2020, 47(6):98-103. 10.11896/jsjkx.191200138 | |
| 30 | 姚登举,杨静,詹晓娟. 基于随机森林的特征选择算法[J]. 吉林大学学报(工学版), 2014, 44(1):137-141. 10.1504/ijdmb.2015.070852 |
| YAO D J, YANG J, ZHAN X J. Feature selection algorithm based on random forest[J]. Journal of Jilin University (Engineering and Technology Edition), 2014, 44(1): 137-141. 10.1504/ijdmb.2015.070852 |
| [1] | 冷强奎, 孙薛梓, 孟祥福. 基于样本势和噪声进化的不平衡数据过采样方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2466-2475. |
| [2] | 雷明珠, 王浩, 贾蓉, 白琳, 潘晓英. 基于特征间关系合成少数类样本的过采样算法[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1428-1436. |
| [3] | 郭祥, 姜文刚, 王宇航. 基于改进Inception-ResNet的加密流量分类方法[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2471-2476. |
| [4] | 穆栋梁, 韩萌, 李昂, 刘淑娟, 高智慧. 概念漂移复杂数据流分类方法综述[J]. 《计算机应用》唯一官方网站, 2023, 43(6): 1664-1675. |
| [5] | 刘学文, 王继奎, 杨正国, 李强, 易纪海, 李冰, 聂飞平. 密度峰值优化的球簇划分欠采样不平衡数据分类算法[J]. 《计算机应用》唯一官方网站, 2022, 42(5): 1455-1463. |
| [6] | 李懿恒, 杜晨曦, 杨燕燕, 李翔宇. 基于伪标签一致度的不平衡数据特征选择算法[J]. 《计算机应用》唯一官方网站, 2022, 42(2): 475-484. |
| [7] | 陆宇, 赵凌云, 白斌雯, 姜震. 基于改进的半监督聚类的不平衡分类算法[J]. 《计算机应用》唯一官方网站, 2022, 42(12): 3750-3755. |
| [8] | 肖振远, 王逸涵, 罗建桥, 熊鹰, 李柏林. 基于部分加权损失函数的RefineDet[J]. 计算机应用, 2021, 41(7): 1928-1932. |
| [9] | 王垚, 孙国梓. 基于聚类和实例硬度的入侵检测过采样方法[J]. 计算机应用, 2021, 41(6): 1709-1714. |
| [10] | 余东昌, 赵文芳, 聂凯, 张舸. 基于LightGBM算法的能见度预测模型[J]. 《计算机应用》唯一官方网站, 2021, 41(4): 1035-1041. |
| [11] | 秦静, 左长青, 汪祖民, 季长清, 王宝凤. 基于堆叠分类器的心电异常监测模型设计[J]. 计算机应用, 2021, 41(3): 887-890. |
| [12] | 王俊红, 闫家荣. 基于欠采样和代价敏感的不平衡数据分类算法[J]. 计算机应用, 2021, 41(1): 48-52. |
| [13] | 陈晓楠, 胡建敏, 陈茜, 张威. 基于LightGBM算法的网络战仿真与效能评估[J]. 计算机应用, 2020, 40(7): 2003-2008. |
| [14] | 崔鑫, 徐华, 宿晨. 面向不均衡数据集的过抽样算法[J]. 计算机应用, 2020, 40(6): 1662-1667. |
| [15] | 陈玉娜, 史晓东. 通过标点恢复提高机器同传效果[J]. 计算机应用, 2020, 40(4): 972-977. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||