


《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (8): 2611-2618.DOI: 10.11772/j.issn.1001-9081.2022091343
• 多媒体计算与计算机仿真 • 上一篇
收稿日期:2022-09-15
修回日期:2022-12-20
接受日期:2023-01-05
发布日期:2023-03-02
出版日期:2023-08-10
通讯作者:
梁美佳
作者简介:刘昕武(1989—),男,湖南株洲人,助理工程师,硕士,主要研究方向:大数据分析基金资助:
Meijia LIANG1( ), Xinwu LIU2, Xiaopeng HU1,3
), Xinwu LIU2, Xiaopeng HU1,3
Received:2022-09-15
Revised:2022-12-20
Accepted:2023-01-05
Online:2023-03-02
Published:2023-08-10
Contact:
Meijia LIANG
About author:LIU Xinwu, born in 1989, M. S., assistant engineer. His research interests include big data analysis.Supported by:摘要:
列车辅助驾驶离不开对列车运行环境的实时检测,而列车运行环境图像存在丰富的小目标。与大中型目标相比,目标占原图比例小于1%的小目标由于分辨率低而存在误检率高、检测精度较差的问题,因此提出一种基于改进YOLOv3的列车运行环境目标检测算法YOLOv3-TOEI (YOLOv3-Train Operating Environment Image)。首先,利用k-means聚类算法优化anchor,从而提高网络的收敛速度;然后,在DarkNet-53中嵌入空洞卷积以增大感受野,并引入稠密卷积网络(DenseNet)获取更丰富的图像底层细节信息;最后,将原始YOLOv3的单向特征融合结构改进为双向自适应特征融合结构,从而实现深浅层特征的有效结合,并提高网络对多尺度目标(特别是小目标)的检测效果。实验结果表明,与原YOLOv3算法相比,YOLOv3-TOEI算法的平均精度均值(mAP)@0.5达到84.5%,提升了12.2%,每秒传输帧数(FPS)为83,拥有更好的列车运行环境图像小目标检测能力。
中图分类号:
梁美佳, 刘昕武, 胡晓鹏. 基于改进YOLOv3的列车运行环境图像小目标检测算法[J]. 计算机应用, 2023, 43(8): 2611-2618.
Meijia LIANG, Xinwu LIU, Xiaopeng HU. Small target detection algorithm for train operating environment image based on improved YOLOv3[J]. Journal of Computer Applications, 2023, 43(8): 2611-2618.

图1 列车运行环境图像
Fig. 1 Train operating environment image

图2 YOLOv3的结构
Fig. 2 Structure of YOLOv3

图3 数据集样例
Fig. 3 Sample of dataset
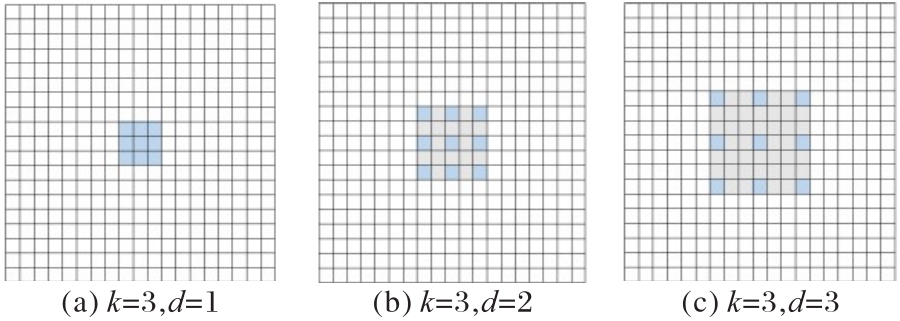
图4 不同扩张率下的空洞卷积
Fig. 4 Dilated convolutions with different dilation rates
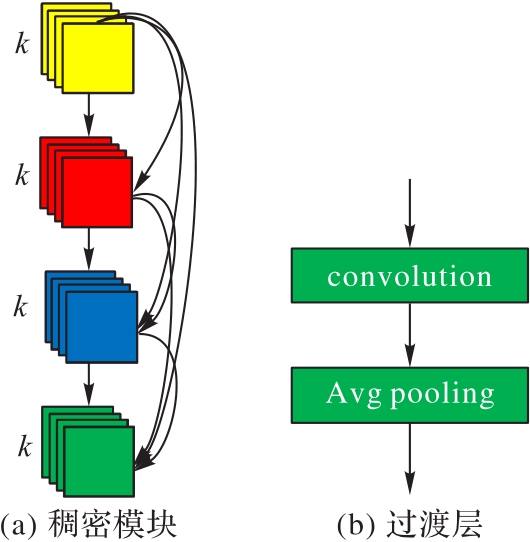
图5 DenseNet的结构
Fig. 5 Structure of DenseNet

图6 YOLOv3-dia-dense主干网络结构
Fig. 6 Structure of YOLOv3-dia-dense backbone network
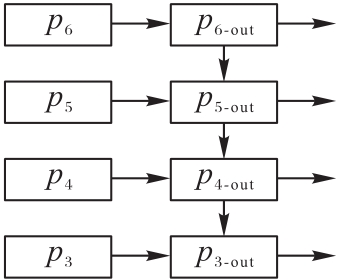
图7 FPN结构
Fig. 7 Structure of FPN
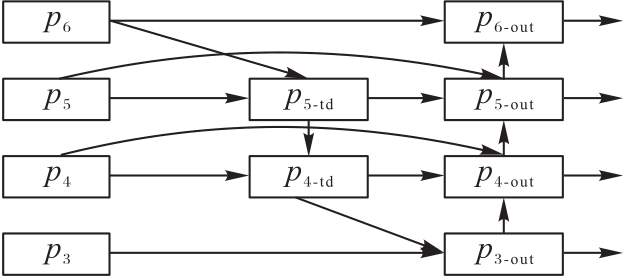
图8 BIFPN结构
Fig. 8 Structure of BIFPN
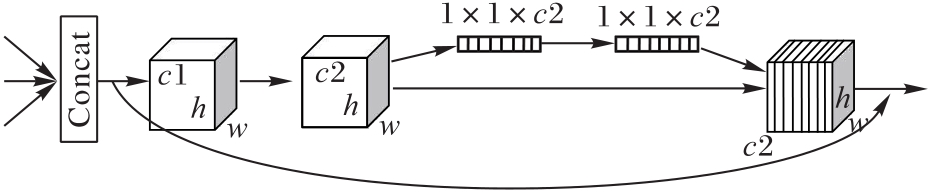
图9 ACFF的结构
Fig. 9 Structure of ACFF
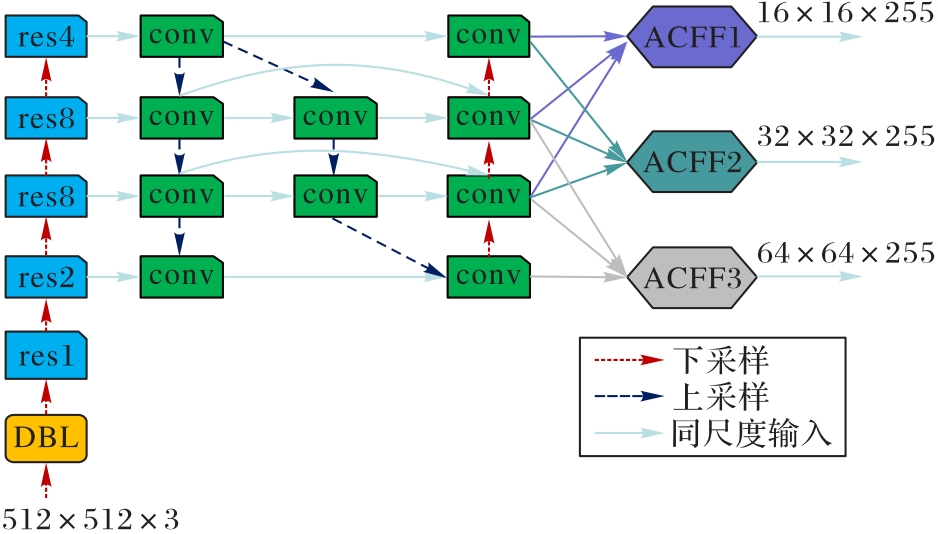
图10 YOLOv3-bi-acff网络结构
Fig. 10 Structure of YOLOv3-bi-acff network
| 输入特征层 | 操作 | 上/下采样倍数 | 输出特征图 |
|---|---|---|---|
| 256×64×64 | 下采样 | 4 | 256×16×16 |
| 512×32×32 | 下采样 | 2 | 512×16×16 |
| 1 024×16×16 | — | — | 1 024×16×16 |
表1 不同输入特征层的具体上/下采样操作
Tab. 1 Specific up-sampling or down-sampling operations for different input feature layers
| 输入特征层 | 操作 | 上/下采样倍数 | 输出特征图 |
|---|---|---|---|
| 256×64×64 | 下采样 | 4 | 256×16×16 |
| 512×32×32 | 下采样 | 2 | 512×16×16 |
| 1 024×16×16 | — | — | 1 024×16×16 |
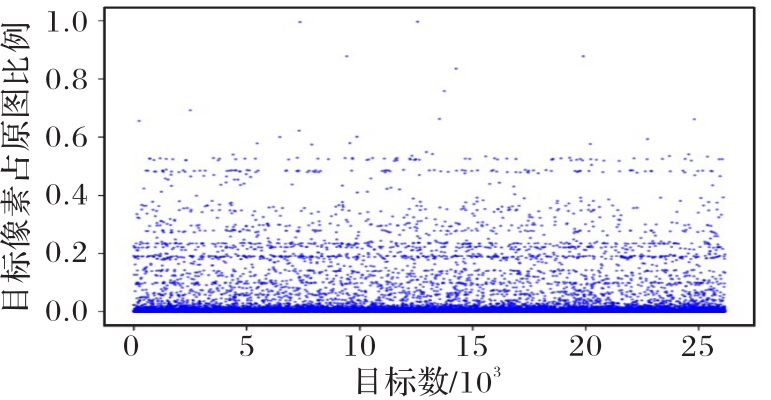
图11 训练集中目标占原图像大小的比例分布
Fig. 11 Proportion distribution of target to original image size in training set

图12 训练集中不同类别目标占原图像大小的比例分布
Fig. 12 Proportion distribution of different targets to original image size in training set
| 类别 | 训练集样本数 | 测试集样本数 |
|---|---|---|
| 共计 | 26 164 | 6 491 |
| person | 5 861 | 1 413 |
| locomotive | 8 141 | 2 141 |
| car | 284 | 89 |
| signal_light | 5 758 | 1 481 |
| truck | 195 | 39 |
| sign | 1 138 | 275 |
| obstacle | 4 787 | 1 053 |
表2 训练集和测试集信息
Tab. 2 Information of training set and test set
| 类别 | 训练集样本数 | 测试集样本数 |
|---|---|---|
| 共计 | 26 164 | 6 491 |
| person | 5 861 | 1 413 |
| locomotive | 8 141 | 2 141 |
| car | 284 | 89 |
| signal_light | 5 758 | 1 481 |
| truck | 195 | 39 |
| sign | 1 138 | 275 |
| obstacle | 4 787 | 1 053 |
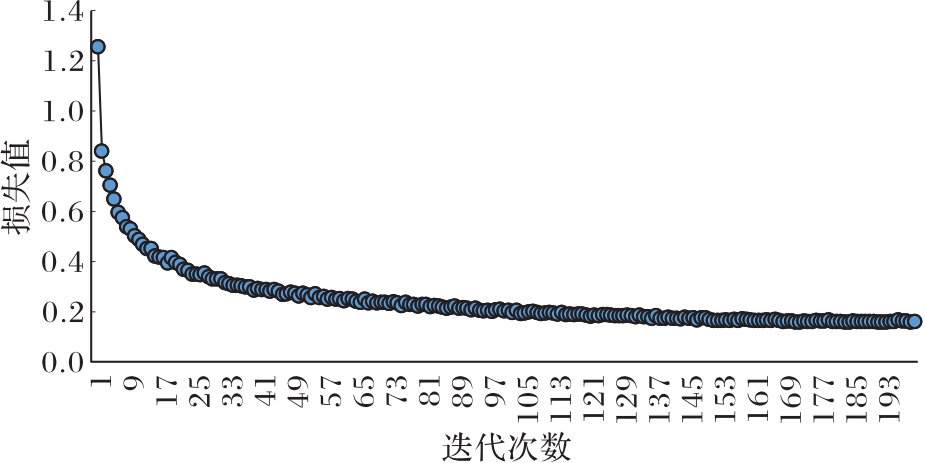
图13 YOLOv3-TOEI算法的损失曲线
Fig.13 Loss curve of YOLOv3-TOEI algorithm
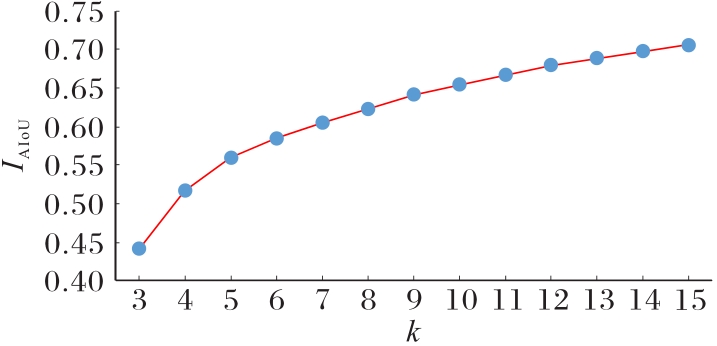
图14 不同k值的IAIoU曲线
Fig. 14 IAIoU curve with different k value

图15 聚类中心分布
Fig. 15 Cluster center distribution
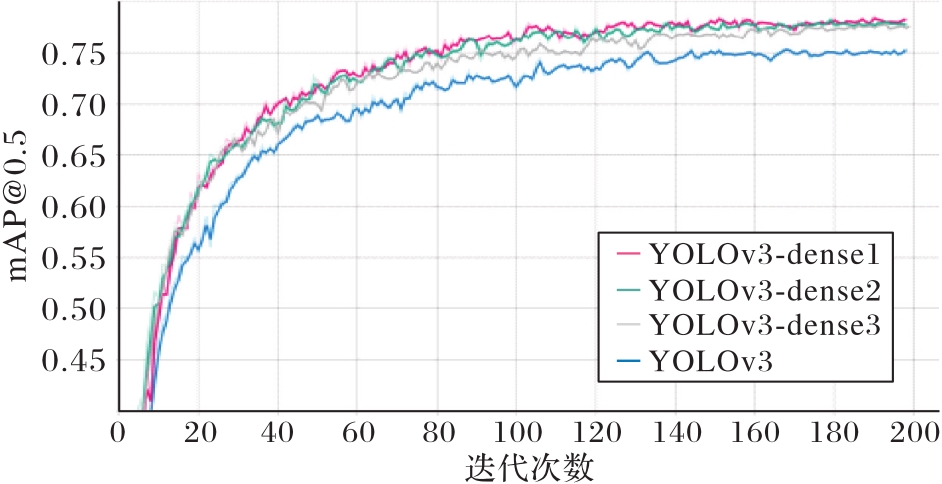
图16 不同稠密模块单元数下改进YOLOv3主干网络算法对比
Fig. 16 Comparison of improved YOLOv3 backbone network algorithms under different numbers of dense block units
| 空洞卷积 | 稠密模块 | 特征融合 | k-means | mAP@0.5 | F1 | FPS |
|---|---|---|---|---|---|---|
| — | — | — | — | 0.753 | 0.777 | 145 |
| — | — | — | √ | 0.802 | 0.823 | 145 |
| √ | — | — | — | 0.763 | 0.786 | 136 |
| √ | √ | — | — | 0.780 | 0.796 | 131 |
| — | — | √ | — | 0.779 | 0.798 | 85 |
| √ | √ | √ | — | 0.792 | 0.808 | 83 |
| √ | √ | √ | √ | 0.845 | 0.861 | 83 |
表3 模块消融实验结果对比
Tab. 3 Comparison of experimental results of module ablation
| 空洞卷积 | 稠密模块 | 特征融合 | k-means | mAP@0.5 | F1 | FPS |
|---|---|---|---|---|---|---|
| — | — | — | — | 0.753 | 0.777 | 145 |
| — | — | — | √ | 0.802 | 0.823 | 145 |
| √ | — | — | — | 0.763 | 0.786 | 136 |
| √ | √ | — | — | 0.780 | 0.796 | 131 |
| — | — | √ | — | 0.779 | 0.798 | 85 |
| √ | √ | √ | — | 0.792 | 0.808 | 83 |
| √ | √ | √ | √ | 0.845 | 0.861 | 83 |
| 类别 | YOLOv3 | YOLOv3-TOEI | 类别 | YOLOv3 | YOLOv3-TOEI |
|---|---|---|---|---|---|
| person | 0.838 | 0.880 | truck | 0.928 | 0.951 |
| locomotive | 0.957 | 0.963 | sign | 0.570 | 0.779 |
| car | 0.880 | 0.913 | obstacle | 0.528 | 0.680 |
| signal_light | 0.571 | 0.745 |
表4 YOLOv3和YOLOv3-TOEI的各类精度比较
Tab. 4 Comparison of each category AP between YOLOv3 and YOLOv3-TOEI
| 类别 | YOLOv3 | YOLOv3-TOEI | 类别 | YOLOv3 | YOLOv3-TOEI |
|---|---|---|---|---|---|
| person | 0.838 | 0.880 | truck | 0.928 | 0.951 |
| locomotive | 0.957 | 0.963 | sign | 0.570 | 0.779 |
| car | 0.880 | 0.913 | obstacle | 0.528 | 0.680 |
| signal_light | 0.571 | 0.745 |

图17 YOLOv3与YOLOv3-TOEI的目标检测结果对比
Fig. 17 Comparison of target detection results between YOLOv3 and YOLOv3-TOEI
| 算法 | mAP@0.5 | F1 | FPS |
|---|---|---|---|
| YOLOv3 | 0.753 | 0.777 | 145 |
| YOLOv3-spp | 0.748 | 0.772 | 145 |
| YOLOv3-tiny | 0.602 | 0.632 | 431 |
| YOLOv4 | 0.775 | 0.710 | 64 |
| Faster RCNN | 0.856 | 0.876 | 21 |
| SSD | 0.719 | 0.752 | 109 |
| YOLOv3-TOEI | 0.845 | 0.861 | 83 |
表5 YOLOv3-TOEI与其他算法的综合比较
Tab. 5 Comprehensive comparison of YOLOv3-TOEI and other algorithms
| 算法 | mAP@0.5 | F1 | FPS |
|---|---|---|---|
| YOLOv3 | 0.753 | 0.777 | 145 |
| YOLOv3-spp | 0.748 | 0.772 | 145 |
| YOLOv3-tiny | 0.602 | 0.632 | 431 |
| YOLOv4 | 0.775 | 0.710 | 64 |
| Faster RCNN | 0.856 | 0.876 | 21 |
| SSD | 0.719 | 0.752 | 109 |
| YOLOv3-TOEI | 0.845 | 0.861 | 83 |
| 1 | 李柯泉,陈燕,刘佳晨,等. 基于深度学习的目标检测算法综述[J]. 计算机程, 2022, 48(7):1-12. 10.19678/j.issn.1000-3428.0062725 |
| LI K Q, CHEN Y, LIU J C, et al. Survey of deep learning-based object detection algorithms[J]. Computer Engineering, 2022, 48(7):1-12. 10.19678/j.issn.1000-3428.0062725 | |
| 2 | GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2014:580-587. 10.1109/cvpr.2014.81 |
| 3 | GIRSHICK R. Fast R-CNN[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015:1440-1448. 10.1109/iccv.2015.169 |
| 4 | REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2015, 1:91-99. |
| 5 | REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. (2018-04-08) [2022-08-06].. 10.1109/cvpr.2017.690 |
| 6 | BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. (2020-04-23) [2022-08-06].. |
| 7 | LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multiBox detector[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9905. Cham: Springer, 2016:21-37. |
| 8 | 熊群芳,林军,刘悦,等. 深度学习研究现状及其在轨道交通领域的应用[J]. 控制与信息技术, 2018(2):1-6. |
| XIONG Q F, LIN J, LIU Y, et al. Deep learning and its application in the field of rail transit[J]. Control and Information Technology, 2018(2):1-6. | |
| 9 | WANG H M, PEI H Y, ZHANG J B. Detection of locomotive signal lights and pedestrians on railway tracks using improved YOLOv4[J]. IEEE Access, 2022, 10:15495-15505. 10.1109/access.2022.3148182 |
| 10 | 王焕民,张建柏,裴华艳,等. 基于MobileNet-SSD的铁路信号灯检测识别[J]. 兰州交通大学学报, 2020, 39(4):66-70. 10.3969/j.issn.1001-4373.2020.04.010 |
| WANG H M, ZHANG J B, PEI H Y, et al. Research on railway signal lamp detection based on MobileNet-SSD[J]. Journal of Lanzhou Jiaotong University, 2020, 39(4):66-70. 10.3969/j.issn.1001-4373.2020.04.010 | |
| 11 | LU Y D, LI J Y, WANG X T. Abnormal detection of track fastener based on improved YOLOV3 algorithm[C]// Proceedings of the 5th International Conference on Mechanical, Control and Computer Engineering. Piscataway: IEEE, 2020: 1826-1831. 10.1109/icmcce51767.2020.00401 |
| 12 | YE T, WANG B C, SONG P, et al. Automatic railway traffic object detection system using feature fusion refine neural network under shunting mode[J]. Sensors, 2018, 18(6): No.1916. 10.3390/s18061916 |
| 13 | KARAGIANNIS G, OLSEN S, PEDERSEN K. Deep learning for detection of railway signs and signals[C]// Proceedings of the 2019 Science and Information Conference, AISC 943. Cham: Springer, 2020: 1-15. 10.1007/978-3-030-17795-9_1 |
| 14 | YE T, ZHANG X, ZHANG Y, et al. Railway traffic object detection using differential feature fusion convolution neural network[J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 22(3): 1375-1387. 10.1109/tits.2020.2969993 |
| 15 | 冯号,黄朝兵,文元桥. 基于改进YOLOv3的遥感图像小目标检测[J]. 计算机应用, 2022, 42(12):3723-3732. |
| FENG H, HUANG C B, WEN Y Q. Remote sensing image small target detection based on improved YOLOv3[J]. Journal of Computer Applications, 2022, 42(12):3723-3732. | |
| 16 | HUANG G, LIU Z, L van der MAATEN, et al. Densely connected convolutional networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 2261-2269. 10.1109/cvpr.2017.243 |
| 17 | LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 936-944. 10.1109/cvpr.2017.106 |
| 18 | TAN M X, PANG R M, LE Q V. EfficientDet: scalable and efficient object detection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10778-10787. 10.1109/cvpr42600.2020.01079 |
| 19 | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018:7132-7141. 10.1109/cvpr.2018.00745 |
| 20 | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 21 | YU F, KOLTUN V. Multi-scale context aggregation by dilated convolutions[EB/OL]. (2016-04-30) [2022-07-21].. 10.1109/cvpr.2017.75 |
| 22 | 曹帅帅. 基于改进YOLOv3的口罩佩戴检测模型研究[D]. 青岛:青岛大学, 2021:45-52. 10.1109/cisai54367.2021.00044 |
| CAO S S. Research on mask wearing detection model based on improved YOLOv3[D]. Qingdao: Qingdao University, 2021:45-52. 10.1109/cisai54367.2021.00044 | |
| 23 | LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 8759-8768. 10.1109/cvpr.2018.00913 |
| 24 | GHIASI G, LIN T Y, LE Q V. NAS-FPN: learning scalable feature pyramid architecture for object detection[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 7029-7038. 10.1109/cvpr.2019.00720 |
| [1] | 徐则林, 杨敏, 陈勐. 融合空间和文本信息的兴趣点类别表征模型[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2456-2461. |
| [2] | 李豆豆, 李汪根, 夏义春, 束阳, 高坤. 基于特征交互与自适应融合的骨骼动作识别[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2581-2587. |
| [3] | 刘欢, 吴亮红, 张侣, 陈亮, 周博文, 张红强. 基于特征双融合CenterNet的白细胞检测方法[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2602-2610. |
| [4] | 郑帅, 张晓龙, 邓鹤, 任宏伟. 基于多尺度特征融合和网格注意力机制的三维肝脏影像分割方法[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2303-2310. |
| [5] | 吕宗喆, 徐慧, 杨骁, 王勇, 王唯鉴. 面向小目标的YOLOv5安全帽检测算法[J]. 《计算机应用》唯一官方网站, 2023, 43(6): 1943-1949. |
| [6] | 刘辉, 张琳玉, 王复港, 何如瑾. 基于注意力机制和上下文信息的目标检测算法[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1557-1564. |
| [7] | 张凯, 覃正楚, 刘月, 秦心怡. 多学习行为协同的知识追踪模型[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1422-1429. |
| [8] | 蒋瑞林, 覃仁超. 基于深度可分离卷积的多神经网络恶意代码检测模型[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1527-1533. |
| [9] | 陈路, 陈道喜, 陆一鸣, 陆卫忠. 基于注意力机制编码器‒解码器的手写数学公式识别模型[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 1297-1302. |
| [10] | 李佳东, 张丹普, 范亚琼, 杨剑锋. 基于改进YOLOv5的轻量级船舶目标检测算法[J]. 《计算机应用》唯一官方网站, 2023, 43(3): 923-929. |
| [11] | 何雪东, 宣士斌, 王款, 陈梦楠. 融合累积分布函数和通道注意力机制的DeepLabV3+图像分割算法[J]. 《计算机应用》唯一官方网站, 2023, 43(3): 936-942. |
| [12] | 吕学强, 张煜楠, 韩晶, 崔运鹏, 李欢. 融合边特征与注意力的表格结构识别模型[J]. 《计算机应用》唯一官方网站, 2023, 43(3): 752-758. |
| [13] | 王萍, 陈楠, 鲁磊. 基于场景先验及注意力引导的跌倒检测算法[J]. 《计算机应用》唯一官方网站, 2023, 43(2): 529-535. |
| [14] | 陈刚, 廖永为, 杨振国, 刘文印. 基于多特征融合的多尺度生成对抗网络图像修复算法[J]. 《计算机应用》唯一官方网站, 2023, 43(2): 536-544. |
| [15] | 李文举, 张干, 崔柳, 储王慧. 基于坐标注意力的轻量级交通标志识别模型[J]. 《计算机应用》唯一官方网站, 2023, 43(2): 608-614. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||