


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (2): 424-431.DOI: 10.11772/j.issn.1001-9081.2023020155
Special Issue: 人工智能
• Artificial intelligence • Previous Articles Next Articles
Cunyi LIAO1, Yi ZHENG1, Weijin LIU1, Huan YU2, Shouyin LIU1( )
)
Received:2023-02-21
Revised:2023-04-22
Accepted:2023-05-06
Online:2023-08-14
Published:2024-02-10
Contact:
Shouyin LIU
About author:LIAO Cunyi, born in 1998, M. S. candidate. His research interests include autonomous driving.Supported by:
廖存燚1, 郑毅1, 刘玮瑾1, 于欢2, 刘守印1()
通讯作者:
刘守印
作者简介:廖存燚(1998—),男,四川成都人,硕士研究生,主要研究方向:自动驾驶基金资助:CLC Number:
Cunyi LIAO, Yi ZHENG, Weijin LIU, Huan YU, Shouyin LIU. Decoupling-fusing algorithm for multiple tasks with autonomous driving environment perception[J]. Journal of Computer Applications, 2024, 44(2): 424-431.
廖存燚, 郑毅, 刘玮瑾, 于欢, 刘守印. 自动驾驶环境感知多任务去耦-融合算法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 424-431.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023020155
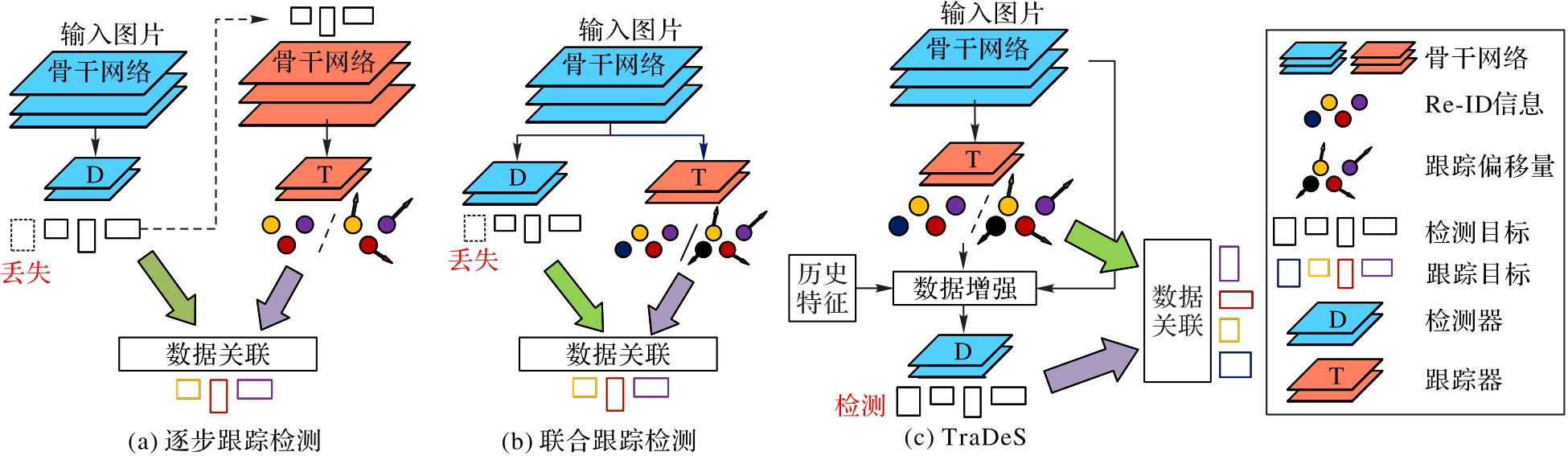
Fig. 1 Target tracking framework
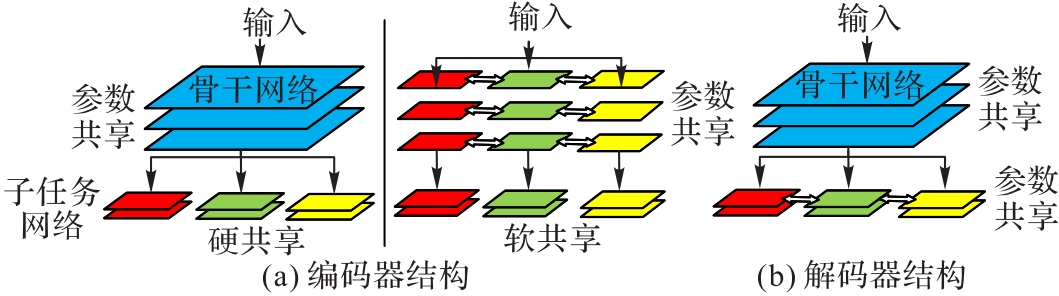
Fig. 2 Multi-task learning framework

Fig. 3 Overall flow of multi-task decoupling-fusing algorithm
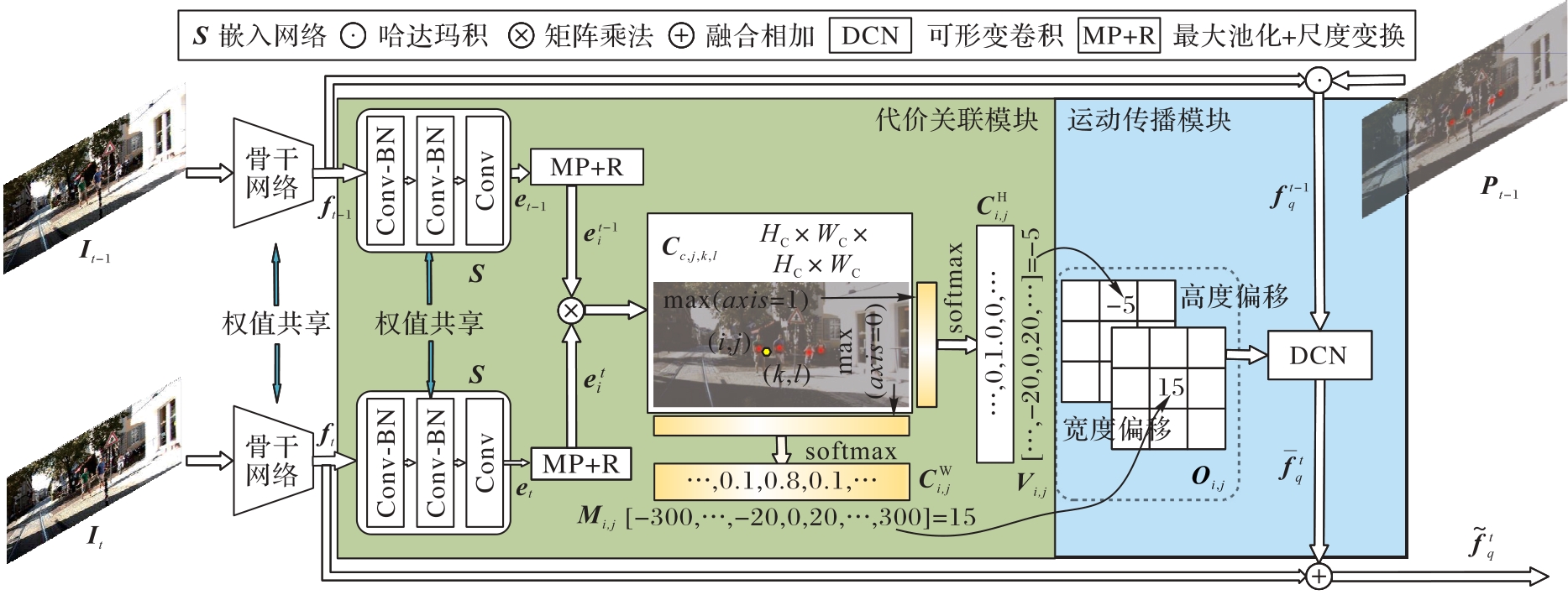
Fig. 4 Spatio-temporal feature extraction module

Fig. 5 Feature decoupling-fusing module
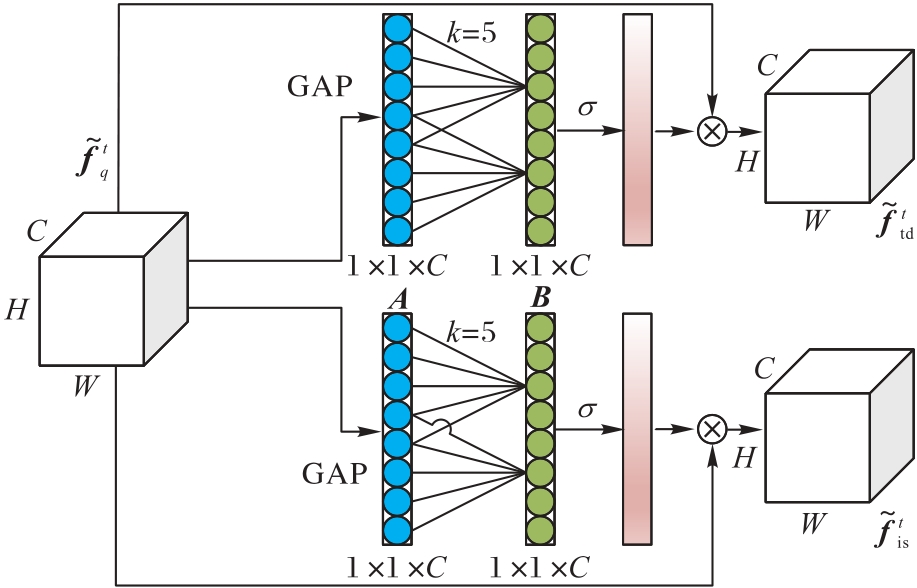
Fig. 6 Flow of feature decoupling module
| 任务类型 | 模型 | MOTA | F1得分 | FPS | ||
|---|---|---|---|---|---|---|
| 单任务 | TraDeS | 0.839 9 | 0.925 6 | — | — | 13.90 |
| CenterTrack | 0.838 5 | 0.923 3 | — | — | 14.20 | |
| DEFT | 0.843 4 | 0.922 3 | — | — | 11.40 | |
| SOLOv2 | — | — | 0.864 | 0.661 | 17.90 | |
| 多任务 | OPITrack | 0.832 9 | 0.923 3 | 0.894 | 0.683 | 10.90 |
| SearchTrack | 0.808 1 | 0.913 4 | 0.833 | 0.679 | 12.80 | |
| 本文模型 | 0.8470 | 0.9292 | 0.938 | 0.700 | 8.78 |
Tab. 1 Comparative experimental results between proposed method and existing methods on KITTI dataset
| 任务类型 | 模型 | MOTA | F1得分 | FPS | ||
|---|---|---|---|---|---|---|
| 单任务 | TraDeS | 0.839 9 | 0.925 6 | — | — | 13.90 |
| CenterTrack | 0.838 5 | 0.923 3 | — | — | 14.20 | |
| DEFT | 0.843 4 | 0.922 3 | — | — | 11.40 | |
| SOLOv2 | — | — | 0.864 | 0.661 | 17.90 | |
| 多任务 | OPITrack | 0.832 9 | 0.923 3 | 0.894 | 0.683 | 10.90 |
| SearchTrack | 0.808 1 | 0.913 4 | 0.833 | 0.679 | 12.80 | |
| 本文模型 | 0.8470 | 0.9292 | 0.938 | 0.700 | 8.78 |
| 模型 | MOTA | F1得分 | FPS | ||
|---|---|---|---|---|---|
| Baseline | 0.786 5 | 0.900 7 | — | — | 18.10 |
| Baseline+Seg | 0.775 8 | 0.894 2 | 0.749 | 0.340 | 11.70 |
| Baseline+Seg+Self | 0.748 6 | 0.883 0 | 0.734 | 0.334 | 9.90 |
| Baseline+Seg+DA | 0.787 7 | 0.900 1 | 0.757 | 0.358 | 11.49 |
| Baseline+Seg+ECA | 0.802 6 | 0.907 4 | 0.766 | 0.357 | 11.62 |
Tab. 2 Comparative experimental results before and after adding feature decoupling module with ResNet18 as backbone network
| 模型 | MOTA | F1得分 | FPS | ||
|---|---|---|---|---|---|
| Baseline | 0.786 5 | 0.900 7 | — | — | 18.10 |
| Baseline+Seg | 0.775 8 | 0.894 2 | 0.749 | 0.340 | 11.70 |
| Baseline+Seg+Self | 0.748 6 | 0.883 0 | 0.734 | 0.334 | 9.90 |
| Baseline+Seg+DA | 0.787 7 | 0.900 1 | 0.757 | 0.358 | 11.49 |
| Baseline+Seg+ECA | 0.802 6 | 0.907 4 | 0.766 | 0.357 | 11.62 |
| 模型 | MOTA | F1得分 | FPS | ||
|---|---|---|---|---|---|
| Baseline | 0.839 9 | 0.925 6 | — | — | 13.90 |
| Baseline+Seg | 0.829 1 | 0.920 4 | 0.904 | 0.617 | 9.00 |
| Baseline+Seg+ECA | 0.845 7 | 0.929 2 | 0.935 | 0.689 | 8.88 |
| Baseline+Seg+ECA+FFM | 0.847 0 | 0.929 2 | 0.938 | 0.700 | 8.78 |
Tab. 3 Comparative experimental results before and after adding feature fusion module with DLA34 as backbone network
| 模型 | MOTA | F1得分 | FPS | ||
|---|---|---|---|---|---|
| Baseline | 0.839 9 | 0.925 6 | — | — | 13.90 |
| Baseline+Seg | 0.829 1 | 0.920 4 | 0.904 | 0.617 | 9.00 |
| Baseline+Seg+ECA | 0.845 7 | 0.929 2 | 0.935 | 0.689 | 8.88 |
| Baseline+Seg+ECA+FFM | 0.847 0 | 0.929 2 | 0.938 | 0.700 | 8.78 |
| 训练方法 | 骨干网络 | MOTA | F1得分 | FPS | ||
|---|---|---|---|---|---|---|
| 等权相加 | DLA34 | 0.838 5 | 0.925 7 | 0.908 | 0.577 | 8.89 |
| 不确定权重 | DLA34 | 0.834 1 | 0.923 5 | 0.913 | 0.607 | 8.84 |
| 投射冲突梯度 | DLA34 | 0.846 8 | 0.929 6 | 0.918 | 0.608 | 8.92 |
| 动态加权平均 | DLA34 | 0.845 7 | 0.929 2 | 0.935 | 0.689 | 8.88 |
Tab. 4 Comparison experimental results of multi-task training methods
| 训练方法 | 骨干网络 | MOTA | F1得分 | FPS | ||
|---|---|---|---|---|---|---|
| 等权相加 | DLA34 | 0.838 5 | 0.925 7 | 0.908 | 0.577 | 8.89 |
| 不确定权重 | DLA34 | 0.834 1 | 0.923 5 | 0.913 | 0.607 | 8.84 |
| 投射冲突梯度 | DLA34 | 0.846 8 | 0.929 6 | 0.918 | 0.608 | 8.92 |
| 动态加权平均 | DLA34 | 0.845 7 | 0.929 2 | 0.935 | 0.689 | 8.88 |

Fig. 7 Comparative visual effects of proposed model with baseline model on KITTI dataset
| 1 | 刘少山, 唐洁, 吴双,等. 第一本无人驾驶技术书[M]. 北京: 电子工业出版社, 2017: 120-169. 10.1007/978-3-031-01802-2_9 |
| LIU S S, TANG J, WU S, et al. The First Book on Autonomous Driving Technology [M]. Beijing: Publishing House of Electronics Industry, 2017: 120-169. 10.1007/978-3-031-01802-2_9 | |
| 2 | REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. 10.1109/tpami.2016.2577031 |
| 3 | BOCHKOVSKIY A, WANG C-Y, LIAO H-Y M. YOLOv4: optimal speed and accuracy of object detection [EB/OL]. (2020-04-23)[2021-10-16]. . |
| 4 | RONNEBERGER O, FISCHER P, BROX T. U-Net: Convolutional networks for biomedical image segmentation[C]// Proceedings of the 2015 International Conference on Medical Image Computing and Computer-assisted Intervention. Cham: Springer, 2015: 234-241. 10.1007/978-3-319-24574-4_28 |
| 5 | ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6230-6239. 10.1109/cvpr.2017.660 |
| 6 | PAN X, SHI J, LUO P, et al. Spatial as deep: spatial CNN for traffic scene understanding[C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI, 2018: 7276-7283. 10.1609/aaai.v32i1.12301 |
| 7 | HOU Y, MA Z, LIU C, et al. Learning lightweight lane detection CNNs by self attention distillation[C]// Proceedings of the 2019 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2019: 1013-1021. 10.1109/iccv.2019.00110 |
| 8 | WU D, LIAO M-W, ZHANG W-T,et al.YOLOP:You only look once for panoptic driving perception[J]. Machine Intelligence Research, 2022, 19: 550-562. 10.1007/s11633-022-1339-y |
| 9 | TEICHMANN M, WEBER M, ZÖLLNER M, et al. MultiNet: real-time joint semantic reasoning for autonomous driving[C]// Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV). Piscataway: IEEE, 2018: 1013-1020. 10.1109/ivs.2018.8500504 |
| 10 | QIAN Y, DOLAN J M, YANG M. DLT-Net: joint detection of drivable areas,lane lines, and traffic objects[J]. IEEE Transactions on Intelligent Transportation Systems, 2019,21(11): 4670-4679. 10.1109/tits.2019.2943777 |
| 11 | LIU S, JOHNS E, DAVISON A J. End-to-end multi-task learning with attention[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 1871-1880. 10.1109/cvpr.2019.00197 |
| 12 | ZHOU X, KOLTUN V, KRÄHENBÜHL P. Tracking objects as points[C]// Proceedings of the 2020 European Conference on Computer Vision. Cham: Springer,2020: 474-490. 10.1007/978-3-030-58548-8_28 |
| 13 | WU J, CAO J, SONG L, et al. Track to detect and segment: an online multi-object tracker[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 12347-12356. 10.1109/cvpr46437.2021.01217 |
| 14 | WANG X, ZHANG R, KONG T, et al. SOLOv2: Dynamic and fast instance segmentation[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 17721-17732. |
| 15 | GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2014: 580-587. 10.1109/cvpr.2014.81 |
| 16 | GIRSHICK R. Fast R-CNN[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE,2015: 1440-1448. 10.1109/iccv.2015.169 |
| 17 | REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 779-788. 10.1109/cvpr.2016.91 |
| 18 | ZHOU X, WANG D, KRÄHENBÜHL P. Objects as points[EB/OL].[2020-08-03]. . |
| 19 | HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2980-2988. 10.1109/iccv.2017.322 |
| 20 | WANG X, KONG T, SHEN C, et al. SOLO: segmenting objects by locations[C]// Proceedings of the 2020 European Conference on Computer Vision. Cham: Springer, 2020: 649-665. 10.1007/978-3-030-58523-5_38 |
| 21 | BALAJI V, RAYMOND J W, PRITAM C. DeepSort: deep convolutional networks for sorting haploid maize seeds[J]. BMC Bioinformatics, 2018, 19: 289. 10.1186/s12859-018-2267-2 |
| 22 | WANG Z, ZHENG L, LIU Y, et al. Towards real-time multi-object tracking[C]// Proceedings of the 2020 European Conference on Computer Vision. Cham: Springer, 2020: 107-122. 10.1007/978-3-030-58621-8_7 |
| 23 | MISRA I, SHRIVASTAVA A, GUPTA A, et al. Cross-stitch networks for multi-task learning[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 3994-4003. 10.1109/cvpr.2016.433 |
| 24 | RUDER S, BINGEL J, AUGENSTEIN I, et al. Sluice networks: learning what to share between loosely related tasks[EB/OL]. (2017-05-23) [2023-02-01]. . 10.1609/aaai.v33i01.33014822 |
| 25 | 文含, 赵莹, 杨涌,等. 基于多任务学习的肝细胞癌分割与病理分化程度预测方法[J]. 生物医学工程学杂志, 2023, 40(1): 60-69. 10.7507/1001-5515.202208045 |
| WEN H, ZHAO Y, YANG Y, et al. Segmentation and pathological differentiation of hepatocellular carcinoma based on multi-task learning [J]. Journal of Biomedical Engineering, 2023, 40(1): 60-69. 10.7507/1001-5515.202208045 | |
| 26 | XU D, OUYANG W, WANG X, et al. PAD-Net: multi-tasks guided prediction-and-distillation network for simultaneous depth estimation and scene parsing[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 675-684. 10.1109/cvpr.2018.00077 |
| 27 | VANDENHENDE S, GEORGOULIS S, VAN GOOL L. MTI-Net: multi-scale task interaction networks for multi-task learning[C]// Proceedings of the 2020 European Conference on Computer Vision. Cham: Springer, 2020: 527-543. 10.1007/978-3-030-58548-8_31 |
| 28 | YOSINSKI J, CLUNE J, BENGIO Y, et al. How transferable are features in deep neural networks? [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2014: 3320-3328. |
| 29 | FU J, LIU J, TIAN H, et al. Dual attention network for scene segmentation[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE, 2019: 3141-3149. 10.1109/cvpr.2019.00326 |
| 30 | WANG Q, WU B, ZHU P, et al. ECA-Net: efficient channel attention for deep convolutional neural networks[C]// Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 11531-11539. 10.1109/cvpr42600.2020.01155 |
| 31 | CHAABANE M, ZHANG P, BEVERIDGE J R, et al. DEFT: detection embeddings for tracking[EB/OL]. [2023-02-01]. . |
| 32 | GAO Y, XU H, ZHENG Y, et al. An object point set inductive tracker for multi-object tracking and segmentation[J]. IEEE Transactions on Image Processing, 2022, 31: 6083-6096. 10.1109/tip.2022.3203607 |
| 33 | Z-M TSAI, Y-J TSAI, WANG C-Y, et al. SearchTrack: multiple object tracking with object-customized search and motion-aware features[EB/OL]. [2023-02-01]. . |
| 34 | KENDALL A, GAL Y, CIPOLLA R. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7482-7491. 10.1109/cvpr.2018.00781 |
| 35 | YU T, KUMAR S, GUPTA A, et al. Gradient surgery for multi-task learning [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 5824-5836. 10.48550/arXiv.2001.06782 |
| [1] | Wentao JIANG, Wanxuan LI, Shengchong ZHANG. Correlation filtering based target tracking with nonlinear temporal consistency [J]. Journal of Computer Applications, 2024, 44(8): 2558-2570. |
| [2] | Xun SUN, Ruifeng FENG, Yanru CHEN. Monocular 3D object detection method integrating depth and instance segmentation [J]. Journal of Computer Applications, 2024, 44(7): 2208-2215. |
| [3] | Zhangjian JI, Na DU. Tiny target detection based on improved VariFocalNet [J]. Journal of Computer Applications, 2024, 44(7): 2200-2207. |
| [4] | Tianhua CHEN, Jiaxuan ZHU, Jie YIN. Bird recognition algorithm based on attention mechanism [J]. Journal of Computer Applications, 2024, 44(4): 1114-1120. |
| [5] | Wei LI, Ling CHEN, Xiuyuan XU, Min ZHU, Jixiang GUO, Kai ZHOU, Hao NIU, Yuchen ZHANG, Shanye YI, Yi ZHANG, Fengming LUO. Interstitial lung disease segmentation algorithm based on multi-task learning [J]. Journal of Computer Applications, 2024, 44(4): 1285-1293. |
| [6] | Zhanjun JIANG, Baijing WU, Long MA, Jing LIAN. Faster-RCNN water-floating garbage recognition based on multi-scale feature and polarized self-attention [J]. Journal of Computer Applications, 2024, 44(3): 938-944. |
| [7] | Aiguo SHANG, Xinjuan ZHU. Joint approach of intent detection and slot filling based on multi-task learning [J]. Journal of Computer Applications, 2024, 44(3): 690-695. |
| [8] | Yuliang ZHENG, Yunhua CHEN, Weijie BAI, Pinghua CHEN. Vehicle target detection by fusing event data and image frames [J]. Journal of Computer Applications, 2024, 44(3): 931-937. |
| [9] | Yudan SONG, Jing WANG, Xuehui WANG, Zhaoyang MA, Youfang LIN. Sleep physiological time series classification method based on adaptive multi-task learning [J]. Journal of Computer Applications, 2024, 44(2): 654-662. |
| [10] | Chenhui CUI, Suzhen LIN, Dawei LI, Xiaofei LU, Jie WU. Infrared dim small target tracking method based on Siamese network and Transformer [J]. Journal of Computer Applications, 2024, 44(2): 563-571. |
| [11] | Yudong PANG, Zhixing LI, Weijie LIU, Tianhao LI, Ningning WANG. Small target detection model in overlooking scenes on tower cranes based on improved real-time detection Transformer [J]. Journal of Computer Applications, 2024, 44(12): 3922-3929. |
| [12] | Dahai LI, Bingtao LI, Zhendong WANG. Underwater target detection algorithm based on improved YOLOv8 [J]. Journal of Computer Applications, 2024, 44(11): 3610-3616. |
| [13] | Lin WANG, Jingliang LIU, Wuwei WANG. Small target detection method in UAV images based on fusion of dilated convolution and Transformer [J]. Journal of Computer Applications, 2024, 44(11): 3595-3602. |
| [14] | Rui HUANG, Chaoqun ZHANG, Xuyi CHENG, Yan XING, Bao ZHANG. Incomplete instance guided aeroengine blade instance segmentation [J]. Journal of Computer Applications, 2024, 44(1): 167-174. |
| [15] | Xiao GUO, Yanping CHEN, Ruixue TANG, Ruizhang HUANG, Yongbin QIN. Multi-task learning model for charge prediction with action words [J]. Journal of Computer Applications, 2024, 44(1): 159-166. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||