


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (3): 702-708.DOI: 10.11772/j.issn.1001-9081.2023030361
Special Issue: 人工智能
• Artificial intelligence • Previous Articles Next Articles
Yongfeng DONG1,2,3, Jiaming BAI1, Liqin WANG1,2,3( ), Xu WANG1,2,3
), Xu WANG1,2,3
Received:2023-04-04
Revised:2023-05-08
Accepted:2023-05-18
Online:2023-05-30
Published:2024-03-10
Contact:
Liqin WANG
About author:DONG Yongfeng, born in 1977, Ph. D., professor. His research interests include artificial intelligence, knowledge graph.Supported by:
董永峰1,2,3, 白佳明1, 王利琴1,2,3(), 王旭1,2,3
通讯作者:
王利琴
作者简介:董永峰(1977—),男,河北定州人,教授,博士,CCF高级会员,主要研究方向:人工智能、知识图谱基金资助:CLC Number:
Yongfeng DONG, Jiaming BAI, Liqin WANG, Xu WANG. Chinese named entity recognition combining prior knowledge and glyph features[J]. Journal of Computer Applications, 2024, 44(3): 702-708.
董永峰, 白佳明, 王利琴, 王旭. 融合先验知识和字形特征的中文命名实体识别[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 702-708.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023030361
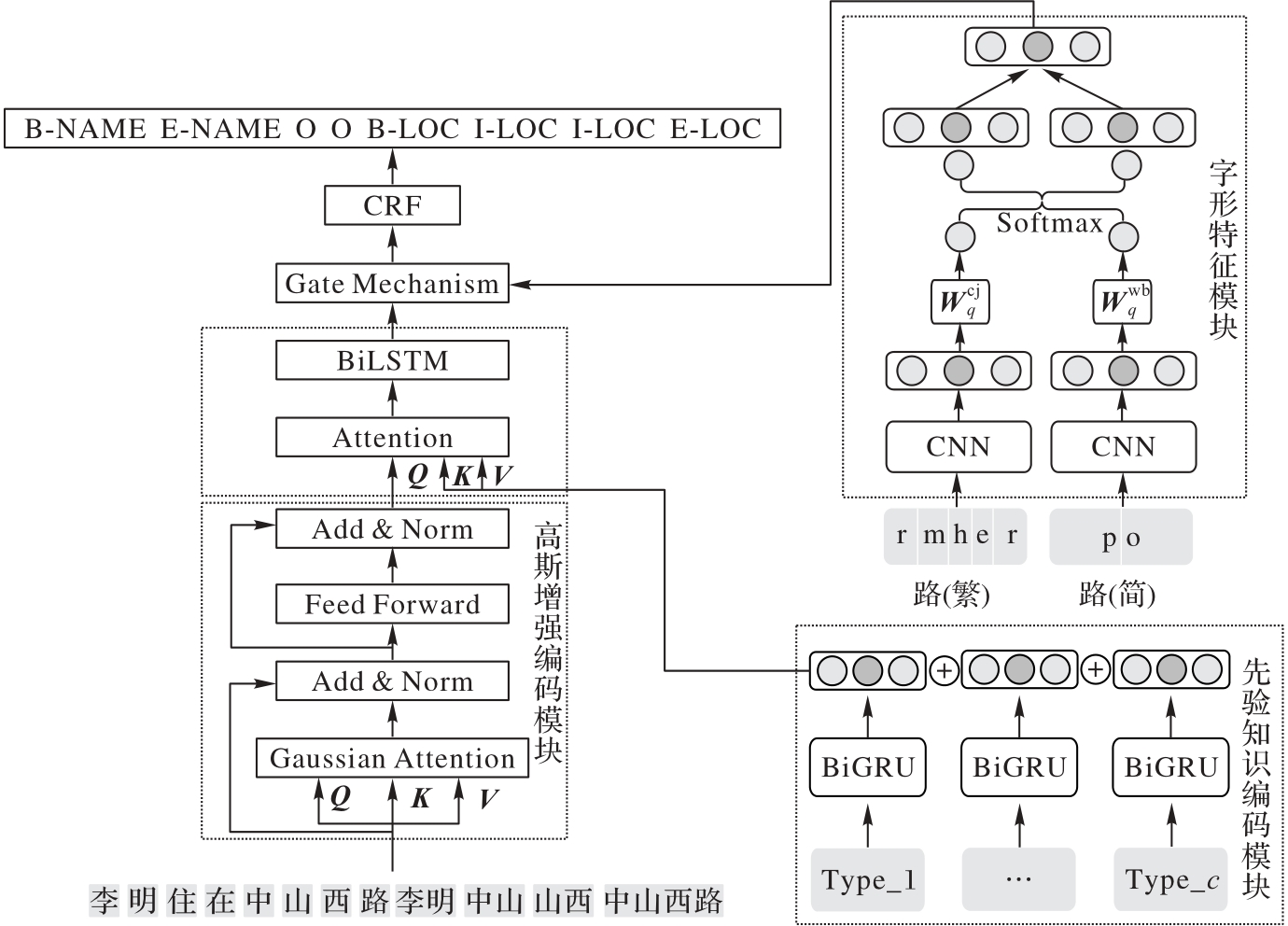
Fig. 1 Structure of PKGF model
| 实体类型 | 中文释义 |
|---|---|
| 人名 | 指为区分个体,给每个个体给定的特定名称符号的人名命名实体 |
| 地名 | 指人们赋予某一特定空间位置上自然或人文地理实体的专有名称的地点名称命名实体 |
| 组织机构 | 指一个团体、单位或组织的结构、职能、人员和业务联系等方面的有机整体的组织机构命名实体 |
Tab. 1 Information of some entity types
| 实体类型 | 中文释义 |
|---|---|
| 人名 | 指为区分个体,给每个个体给定的特定名称符号的人名命名实体 |
| 地名 | 指人们赋予某一特定空间位置上自然或人文地理实体的专有名称的地点名称命名实体 |
| 组织机构 | 指一个团体、单位或组织的结构、职能、人员和业务联系等方面的有机整体的组织机构命名实体 |
| 繁体字 | 仓颉码 | 简体字 | 现代五笔码 |
|---|---|---|---|
| 南 | jbtj | 南 | gc |
| 京 | xyrf | 京 | wkuj |
| 市 | ylb | 市 | wm |
| 長 | smv | 长 | rl |
| 江 | em | 江 | vd |
| 大 | k | 大 | as |
| 橋 | dhkb | 桥 | mr |
Tab. 2 Examples of font codes for traditional and simplified characters
| 繁体字 | 仓颉码 | 简体字 | 现代五笔码 |
|---|---|---|---|
| 南 | jbtj | 南 | gc |
| 京 | xyrf | 京 | wkuj |
| 市 | ylb | 市 | wm |
| 長 | smv | 长 | rl |
| 江 | em | 江 | vd |
| 大 | k | 大 | as |
| 橋 | dhkb | 桥 | mr |
| 数据集 | 句子数/103 | 命名实体数/103 |
|---|---|---|
| 2.0 | 2.7 | |
| Boson | 11.0 | 22.4 |
| PeopleDaily | 27.8 | 45.5 |
Tab. 3 Information statistics of different datasets
| 数据集 | 句子数/103 | 命名实体数/103 |
|---|---|---|
| 2.0 | 2.7 | |
| Boson | 11.0 | 22.4 |
| PeopleDaily | 27.8 | 45.5 |
| 超参数 | 中文描述 | 值 |
|---|---|---|
| output_dropout | 输入CRF之前的最终向量的dropout | {0.3,0.4} |
| zx_dropout | 字形特征表示的dropout | 0.2 |
| prior_dropout | 先验知识表示的dropout | {0.2,0.5} |
| warm_up | 学习率预热 | {0.1,0.3} |
| zx_lr | 字形特征学习率 | {0.001 4,0.001 5,0.001 8} |
| prior_lr | 先验知识信息学习率 | {0.001 4,0.001 5} |
| head_num | Transformer中多头注意力的头的数量 | 8 |
Tab. 4 Hyper-paramerters setting
| 超参数 | 中文描述 | 值 |
|---|---|---|
| output_dropout | 输入CRF之前的最终向量的dropout | {0.3,0.4} |
| zx_dropout | 字形特征表示的dropout | 0.2 |
| prior_dropout | 先验知识表示的dropout | {0.2,0.5} |
| warm_up | 学习率预热 | {0.1,0.3} |
| zx_lr | 字形特征学习率 | {0.001 4,0.001 5,0.001 8} |
| prior_lr | 先验知识信息学习率 | {0.001 4,0.001 5} |
| head_num | Transformer中多头注意力的头的数量 | 8 |
| 模型 | NE | NM | Overall |
|---|---|---|---|
| LatticeLSTM | 53.04 | 62.25 | 58.79 |
| LB-GNN | 55.34 | 64.98 | 60.21 |
| SoftLexicon | 59.08 | 62.22 | 61.42 |
| LR-CNN | 57.14 | 66.67 | 59.92 |
| FLAT | — | — | 60.32 |
| MECT | 61.91 | 62.51 | 63.30 |
| PKGF | 58.09 | 69.65 | 65.77 |
Tab. 5 F1 results of different models on Weibo dataset
| 模型 | NE | NM | Overall |
|---|---|---|---|
| LatticeLSTM | 53.04 | 62.25 | 58.79 |
| LB-GNN | 55.34 | 64.98 | 60.21 |
| SoftLexicon | 59.08 | 62.22 | 61.42 |
| LR-CNN | 57.14 | 66.67 | 59.92 |
| FLAT | — | — | 60.32 |
| MECT | 61.91 | 62.51 | 63.30 |
| PKGF | 58.09 | 69.65 | 65.77 |
| 数据集 | 模型 | P | R | F1 |
|---|---|---|---|---|
| Boson | LatticeLSTM | 80.56 | 79.16 | 79.85 |
| LB-GNN | 79.67 | 77.92 | 78.79 | |
| SoftLexicon | 81.48 | 80.44 | 80.96 | |
| LR-CNN | 79.31 | 80.58 | 79.94 | |
| FLAT | 80.79 | 78.46 | 79.61 | |
| MECT | 81.55 | 81.30 | 81.42 | |
| PKGF | 83.71 | 81.56 | 82.62 | |
| PeopleDaily | LatticeLSTM | 92.35 | 91.50 | 91.92 |
| LB-GNN | 92.48 | 91.99 | 92.08 | |
| SoftLexicon | 93.00 | 92.42 | 92.71 | |
| LR-CNN | 93.51 | 92.70 | 93.10 | |
| FLAT | 92.96 | 93.01 | 92.90 | |
| MECT | 93.57 | 91.88 | 92.72 | |
| PKGF | 94.35 | 93.06 | 93.70 |
Tab. 6 Comparison results on Boson and PeopleDaily datasets
| 数据集 | 模型 | P | R | F1 |
|---|---|---|---|---|
| Boson | LatticeLSTM | 80.56 | 79.16 | 79.85 |
| LB-GNN | 79.67 | 77.92 | 78.79 | |
| SoftLexicon | 81.48 | 80.44 | 80.96 | |
| LR-CNN | 79.31 | 80.58 | 79.94 | |
| FLAT | 80.79 | 78.46 | 79.61 | |
| MECT | 81.55 | 81.30 | 81.42 | |
| PKGF | 83.71 | 81.56 | 82.62 | |
| PeopleDaily | LatticeLSTM | 92.35 | 91.50 | 91.92 |
| LB-GNN | 92.48 | 91.99 | 92.08 | |
| SoftLexicon | 93.00 | 92.42 | 92.71 | |
| LR-CNN | 93.51 | 92.70 | 93.10 | |
| FLAT | 92.96 | 93.01 | 92.90 | |
| MECT | 93.57 | 91.88 | 92.72 | |
| PKGF | 94.35 | 93.06 | 93.70 |
| 模型 | P | R | F1 |
|---|---|---|---|
| PKGF | 69.12 | 62.72 | 65.77 |
| -w/o 高斯注意力 | 68.99 | 61.18 | 64.85 |
| -w/o 简体字形特征 | 68.79 | 61.18 | 64.76 |
| -w/o 繁体字形特征 | 66.40 | 62.98 | 64.64 |
| -w/o 实体类型信息 | 68.60 | 60.67 | 64.39 |
| -w/o 繁体和简体字形特征 | 65.84 | 61.44 | 63.56 |
Tab. 7 Ablation experiment results
| 模型 | P | R | F1 |
|---|---|---|---|
| PKGF | 69.12 | 62.72 | 65.77 |
| -w/o 高斯注意力 | 68.99 | 61.18 | 64.85 |
| -w/o 简体字形特征 | 68.79 | 61.18 | 64.76 |
| -w/o 繁体字形特征 | 66.40 | 62.98 | 64.64 |
| -w/o 实体类型信息 | 68.60 | 60.67 | 64.39 |
| -w/o 繁体和简体字形特征 | 65.84 | 61.44 | 63.56 |
| 实体类型 | 中文释义 |
|---|---|
| 方案A | 特指为区分个体,给每个个体给定的特定名称符号的人名命名实体 |
| 方案B | 特指的人名命名实体 |
| 方案C | 特指的具有人类姓名特征的词语 |
Tab. 8 Different entity type information
| 实体类型 | 中文释义 |
|---|---|
| 方案A | 特指为区分个体,给每个个体给定的特定名称符号的人名命名实体 |
| 方案B | 特指的人名命名实体 |
| 方案C | 特指的具有人类姓名特征的词语 |
| 模型 | P | R | F1 |
|---|---|---|---|
| PKGF-w/o 实体类型信息 | 68.60 | 60.67 | 64.39 |
| 方案A(PKGF) | 69.12 | 62.72 | 65.77 |
| 方案B | 66.58 | 62.98 | 64.73 |
| 方案C | 67.40 | 62.72 | 94.98 |
Tab. 9 Results using different entity type information
| 模型 | P | R | F1 |
|---|---|---|---|
| PKGF-w/o 实体类型信息 | 68.60 | 60.67 | 64.39 |
| 方案A(PKGF) | 69.12 | 62.72 | 65.77 |
| 方案B | 66.58 | 62.98 | 64.73 |
| 方案C | 67.40 | 62.72 | 94.98 |
| 模型组合 | P | R | F1 | |
|---|---|---|---|---|
| 先验知识编码结构 | 序列编码结构 | |||
| BiGRU | BiLSTM | 69.12 | 62.72 | 65.77 |
| BiLSTM | BiLSTM | 68.71 | 62.85 | 65.65 |
| BiGRU | BiGRU | 69.33 | 61.64 | 65.26 |
| BiLSTM | BiGRU | 69.31 | 61.44 | 65.14 |
Tab. 10 Experiment results using BiLSTM or BiGRU
| 模型组合 | P | R | F1 | |
|---|---|---|---|---|
| 先验知识编码结构 | 序列编码结构 | |||
| BiGRU | BiLSTM | 69.12 | 62.72 | 65.77 |
| BiLSTM | BiLSTM | 68.71 | 62.85 | 65.65 |
| BiGRU | BiGRU | 69.33 | 61.64 | 65.26 |
| BiLSTM | BiGRU | 69.31 | 61.44 | 65.14 |
| 1 | 赵山,罗睿,蔡志平. 中文命名实体识别综述[J]. 计算机科学与探索, 2022, 16(2): 296-304. 10.3778/j.issn.1673-9418.2107031 |
| ZHAO S, LUO R, CAI Z P. Survey of Chinese named entity recognition [J]. Journal of Frontiers of Computer Science & Technology, 2022, 16(2): 296-304. 10.3778/j.issn.1673-9418.2107031 | |
| 2 | 乔勇鹏,于亚新,刘树越,等. 图卷积增强多路解码的实体关系联合抽取模型[J]. 计算机研究与发展, 2023, 60(1): 153-166. 10.7544/issn1000-1239.202110767 |
| QIAO Y P, YU Y X, LIU S Y, et al. Graph convolution-enhanced multi-channel decoding joint entity and relation extraction model[J]. Journal of Computer Research and Development, 2023, 60(1): 153-166. 10.7544/issn1000-1239.202110767 | |
| 3 | 冀相冰,朱艳辉,詹飞,等. 基于门控多层次注意机制的事件主体抽取[J]. 计算机应用与软件, 2021, 38(9): 173-179,187. 10.3969/j.issn.1000-386x.2021.09.027 |
| JI X B, ZHU Y H, ZHAN F,et al. Event subject extraction based on gated multi-level attention mechanism [J]. Computer Applications and Software, 2021, 38(9): 173-179,187. 10.3969/j.issn.1000-386x.2021.09.027 | |
| 4 | 秦贺然,刘浏,李斌,等. 融入实体特征的典籍自动分类研究[J]. 数据分析与知识发现, 2019, 3(9): 68-76. |
| QIN H R, LIU L, LI B, et al. Automatic classification of ancient classics with entity features [J]. Data Analysis and Knowledge Discovery, 2019, 3(9): 68-76. | |
| 5 | 肖新凤,李石君,余伟,等. 基于改进seq2seq模型的英汉翻译研究[J]. 计算机工程与科学, 2019, 41(7): 1257-1265. 10.3969/j.issn.1007-130X.2019.07.016 |
| XIAO X F, LI S J, YU W, et al. English-Chinese translation based on an improved seq2seq model [J]. Computer Engineering and Science, 2019, 41(7): 1257-1265. 10.3969/j.issn.1007-130X.2019.07.016 | |
| 6 | LIU P, GUO Y, WANG F, et al. Chinese named entity recognition: the state of the art [J]. Neurocomputing, 2022, 473: 37-53. 10.1016/j.neucom.2021.10.101 |
| 7 | MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality [C]// Proceedings of the 26th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2013: 3111-3119. |
| 8 | PENNINGTON J, SOCHER R, MANNIN C. GloVe: global vectors for word representation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2014: 1532-1543. 10.3115/v1/d14-1162 |
| 9 | BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 1877-1901. 10.18653/v1/2021.emnlp-main.734 |
| 10 | DEVLIN J, CHANG M-W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2019: 4171-4186. 10.18653/v1/n18-2 |
| 11 | FU G, K-K LUKE. Chinese named entity recognition using lexicalized HMMs [J]. ACM SIGKDD Explorations Newsletter, 2005,7(1):19-25. 10.1145/1089815.1089819 |
| 12 | MALOUF R. A comparison of algorithms for maximum entropy parameter estimation [C]// Proceedings of the 6th Conference on Natural Language Learning. Stroudsburg: ACL, 2002: 1-7. 10.3115/1118853.1118871 |
| 13 | CHEN W, ZHANG Y, ISAHARA H. Chinese named entity recognition with conditional random fields [C]// Proceedings of the 5th SIGHAN Workshop on Chinese Language Processing. Stroudsburg: ACL,2006: 118-121. |
| 14 | CAI X, DONG S, HU J. A deep learning model incorporating part of speech and self-matching attention for named entity recognition of Chinese electronic medical records [J]. BMC Medical Informatics and Decision Making, 2019, 19(): 65. 10.1186/s12911-019-0762-7 |
| 15 | 罗凌, 杨志豪, 宋雅文, 等. 基于笔画ELMo和多任务学习的中文电子病历命名实体识别研究[J]. 计算机学报, 2020, 43(10): 1943-1957. 10.11897/SP.J.1016.2020.01943 |
| LUO L, YANG Z H, SONG Y W, et al. Chinese clinical named entity recognition based on stroke ELMo and multi-task learning [J]. Chinese Journal of Computers, 2020, 43(10): 1943-1957. 10.11897/SP.J.1016.2020.01943 | |
| 16 | XUAN Z, BAO R, JIANG S. FGN: fusion glyph network for Chinese named entity recognition [C]// Proceedings of the 5th China Conference on Knowledge Graph and Semantic Computing. Cham: Springer, 2020: 28-40. 10.1007/978-981-16-1964-9_3 |
| 17 | DONG C, ZHANG J, ZONG C, et al. Character-based LSTM-CRF with radical-level features for Chinese named entity recognition [C]// Proceedings of the 2016 International Conference on Computer Processing of Oriental Languages and 2016 National CCF Conference on Natural Language Processing and Chinese Computing. Cham: Springer, 2016: 239-250. 10.1007/978-3-319-50496-4_20 |
| 18 | ZHANG Y, YANG J. Chinese NER using lattice LSTM [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2018: 1554-1564. 10.18653/v1/p18-1144 |
| 19 | LIU W, XU T, XU Q, et al. An encoding strategy based word-character LSTM for Chinese NER [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1(Long and Short Papers). Stroudsburg: ACL, 2019: 2379-2389. 10.18653/v1/n18-2 |
| 20 | XUE M, YU B, LIU T, et al. Porous lattice transformer encoder for Chinese NER [C]// Proceedings of the 28th International Conference on Computational Linguistics. Stroudsburg: ACL, 2020: 3831-3841. 10.18653/v1/2020.coling-main.340 |
| 21 | GUI T, ZOU Y, ZHANG Q, et al. A lexicon-based graph neural network for Chinese NER [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 1040-1050. 10.18653/v1/d19-1096 |
| 22 | LI X, YAN H, QIU X, et al. FLAT: Chinese NER using flat-lattice Transformer [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 6836-6842. 10.18653/v1/2020.acl-main.611 |
| 23 | WU S, SONG X, FENG Z. MECT: multi-metadata embedding based Cross-Transformer for Chinese named entity recognition[C]// Proceedings of the 2021 Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 1529-1539. 10.18653/v1/2021.acl-long.121 |
| 24 | LI X, FENG J, MENG Y, et al. A unified MRC framework for named entity recognition [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 5849-5859. 10.18653/v1/2020.acl-main.519 |
| 25 | 刘奕洋,余正涛,高盛祥,等. 基于机器阅读理解的中文命名实体识别方法[J]. 模式识别与人工智能, 2020, 33(7): 653-659. 10.16451/j.cnki.issn1003-6059.202007007 |
| LIU Y Y, YU Z T, GAO S X, et al. Chinese named entity recognition method based on machine reading comprehension [J]. Pattern Recognition and Artificial Intelligence, 2020, 33(7): 653-659. 10.16451/j.cnki.issn1003-6059.202007007 | |
| 26 | CUI L, WU Y, LIU J, et al. Template-based named entity recognition using BART [C]// Proceedings of the 10th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2021: 1835-1845. 10.18653/v1/2021.findings-acl.161 |
| 27 | LEE D-H, KADAKIA A, TAN K, et al. Good examples make a faster learner: simple demonstration-based learning for low-resource NER [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 2687-2700. 10.18653/v1/2022.acl-long.192 |
| 28 | GUI T, MA R, ZHANG Q, et al. CNN-based Chinese NER with lexicon rethinking [C]// Proceedings of the 28th International Joint Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2019: 4982-4988. 10.24963/ijcai.2019/692 |
| 29 | MA R, PENG M, ZHANG Q, et al. Simplify the usage of lexicon in Chinese NER [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 5951-5960. 10.18653/v1/2020.acl-main.528 |
| [1] | Jing QIN, Zhiguang QIN, Fali LI, Yueheng PENG. Diagnosis of major depressive disorder based on probabilistic sparse self-attention neural network [J]. Journal of Computer Applications, 2024, 44(9): 2970-2974. |
| [2] | Liting LI, Bei HUA, Ruozhou HE, Kuang XU. Multivariate time series prediction model based on decoupled attention mechanism [J]. Journal of Computer Applications, 2024, 44(9): 2732-2738. |
| [3] | Yun LI, Fuyou WANG, Peiguang JING, Su WANG, Ao XIAO. Uncertainty-based frame associated short video event detection method [J]. Journal of Computer Applications, 2024, 44(9): 2903-2910. |
| [4] | Zhiqiang ZHAO, Peihong MA, Xinhong HEI. Crowd counting method based on dual attention mechanism [J]. Journal of Computer Applications, 2024, 44(9): 2886-2892. |
| [5] | Hong CHEN, Bing QI, Haibo JIN, Cong WU, Li’ang ZHANG. Class-imbalanced traffic abnormal detection based on 1D-CNN and BiGRU [J]. Journal of Computer Applications, 2024, 44(8): 2493-2499. |
| [6] | Huanliang SUN, Siyi WANG, Junling LIU, Jingke XU. Help-seeking information extraction model for flood event in social media data [J]. Journal of Computer Applications, 2024, 44(8): 2437-2445. |
| [7] | Kaipeng XUE, Tao XU, Chunjie LIAO. Multimodal sentiment analysis network with self-supervision and multi-layer cross attention [J]. Journal of Computer Applications, 2024, 44(8): 2387-2392. |
| [8] | Yuqing WANG, Guangli ZHU, Wenjie DUAN, Shuyu LI, Ruotong ZHOU. Sentiment classification model of psychological counseling text based on attention over attention mechanism [J]. Journal of Computer Applications, 2024, 44(8): 2393-2399. |
| [9] | Pengqi GAO, Heming HUANG, Yonghong FAN. Fusion of coordinate and multi-head attention mechanisms for interactive speech emotion recognition [J]. Journal of Computer Applications, 2024, 44(8): 2400-2406. |
| [10] | Zhonghua LI, Yunqi BAI, Xuejin WANG, Leilei HUANG, Chujun LIN, Shiyu LIAO. Low illumination face detection based on image enhancement [J]. Journal of Computer Applications, 2024, 44(8): 2588-2594. |
| [11] | Shangbin MO, Wenjun WANG, Ling DONG, Shengxiang GAO, Zhengtao YU. Single-channel speech enhancement based on multi-channel information aggregation and collaborative decoding [J]. Journal of Computer Applications, 2024, 44(8): 2611-2617. |
| [12] | Yangyi GAO, Tao LEI, Xiaogang DU, Suiyong LI, Yingbo WANG, Chongdan MIN. Crowd counting and locating method based on pixel distance map and four-dimensional dynamic convolutional network [J]. Journal of Computer Applications, 2024, 44(7): 2233-2242. |
| [13] | Li LIU, Haijin HOU, Anhong WANG, Tao ZHANG. Generative data hiding algorithm based on multi-scale attention [J]. Journal of Computer Applications, 2024, 44(7): 2102-2109. |
| [14] | Song XU, Wenbo ZHANG, Yifan WANG. Lightweight video salient object detection network based on spatiotemporal information [J]. Journal of Computer Applications, 2024, 44(7): 2192-2199. |
| [15] | Dahai LI, Zhonghua WANG, Zhendong WANG. Dual-branch low-light image enhancement network combining spatial and frequency domain information [J]. Journal of Computer Applications, 2024, 44(7): 2175-2182. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||