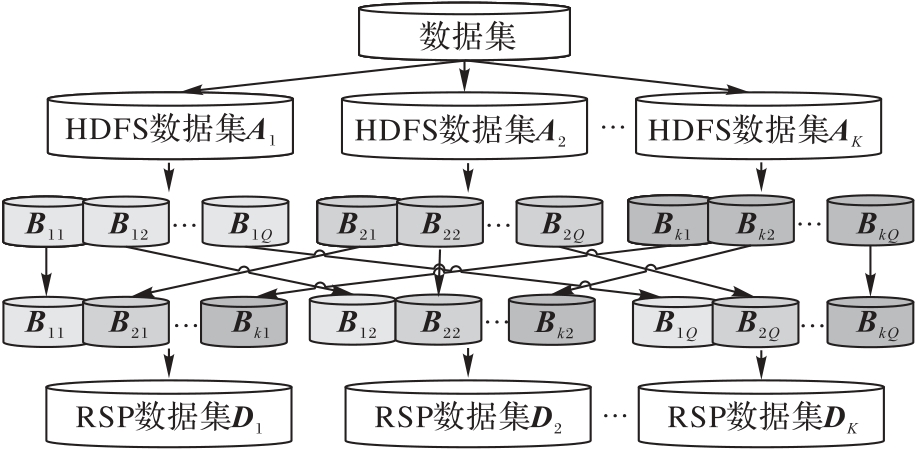
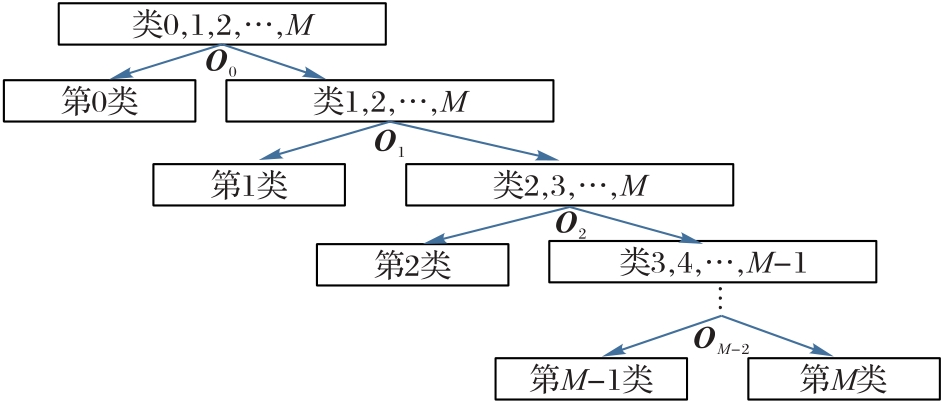
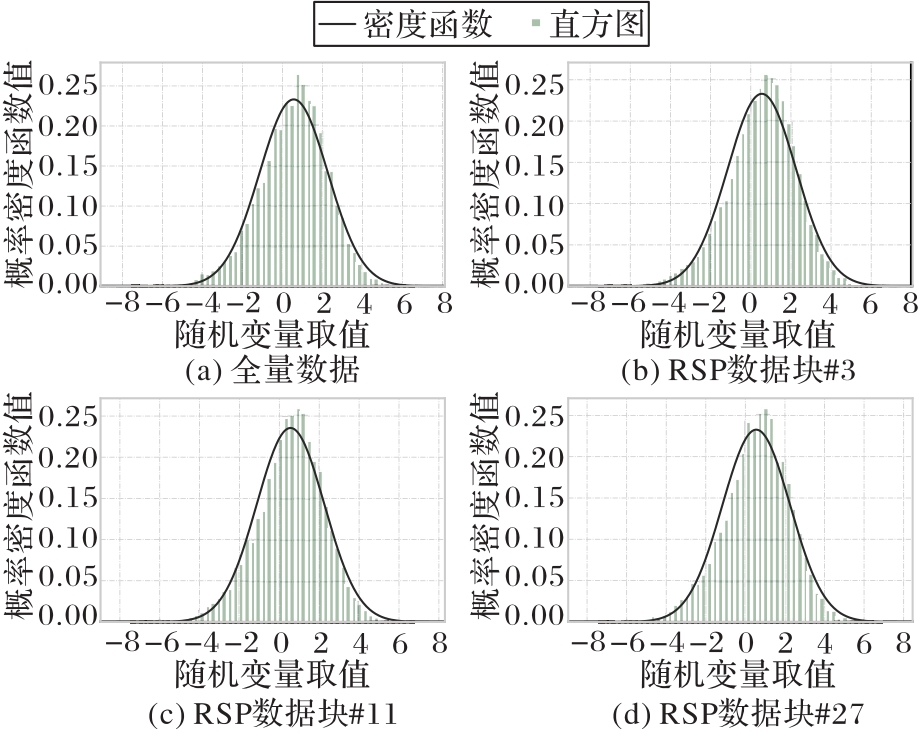
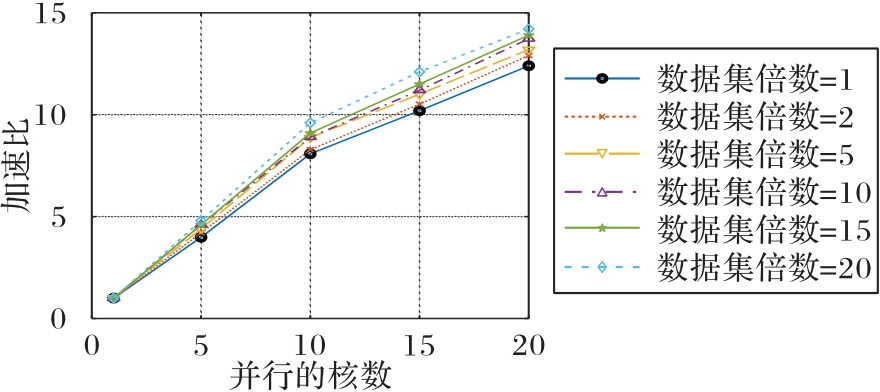
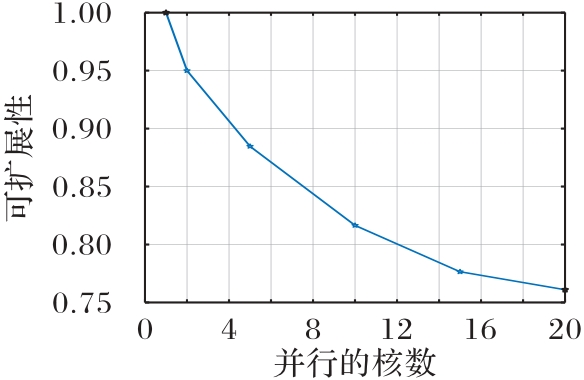
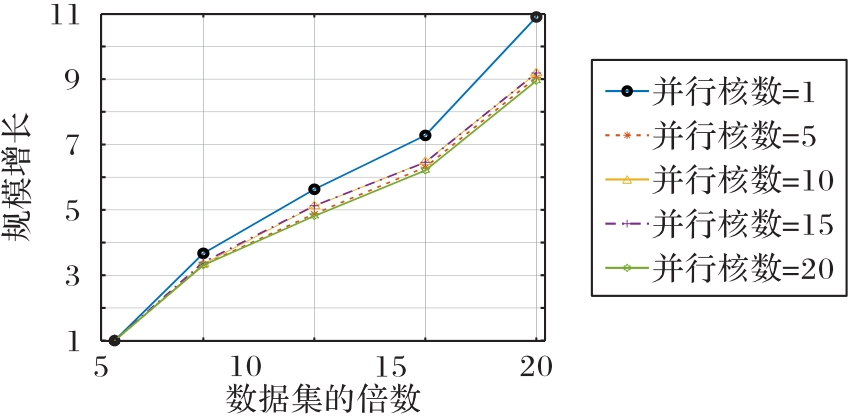
| 1 |
梅宏, 杜小勇, 金海, 等. 大数据技术前瞻[J]. 大数据, 2023, 9(1):1-20.
|
|
MEI H, DU X Y, JIN H, et al. Big data technologies forward-looking [J]. Big Data Research, 2023, 9(1):1-20.
|
| 2 |
KARUN A K, CHITHARANJAN K. A review on hadoop: HDFS infrastructure extensions[C]// Proceedings of the 2013 IEEE Conference on Information & Communication Technologies. Piscataway: IEEE, 2013: 132-137.
|
| 3 |
DEAN J, GHEMAWAT S. MapReduce: a flexible data processing tool [J]. Communications of the ACM, 2010, 53(1): 72-77.
|
| 4 |
ZAHARIA M, XIN R S, WENDELL P, et al. Apache Spark: a unified engine for big data processing [J]. Communications of the ACM, 2016, 59(11): 56-65.
|
| 5 |
SLEEMAN IV W C, KRAWCZYK B. Multi-class imbalanced big data classification on Spark [J]. Knowledge-Based Systems, 2021, 212: 106598.
|
| 6 |
黄哲学, 何玉林, 魏丞昊,等. 大数据随机样本划分模型及相关分析计算技术[J]. 数据采集与处理, 2019, 34(3): 373-385.
|
|
HUANG Z X, HE Y L, WEI C H, et al. Random sample partition data model and related technologies for big data analysis[J]. Journal of Data Acqusisition & Processing, 2019, 34(3): 373-385.
|
| 7 |
SALLOUM S, HUANG J Z, HE Y. Random sample partition: a distributed data model for big data analysis [J]. IEEE Transactions on Industrial Informatics, 2019, 15(11): 5846-5854.
|
| 8 |
HE Y L, LI X, FOURNIER-VIGER P, et al. Observation points classifier ensemble for high-dimensional imbalanced classification[J]. CAAI Transactions on Intelligence Technology, 2023, 8(2): 500-517.
|
| 9 |
TRIGUERO I, PERALTA D, BACARDIT J, et al. MRPR: a MapReduce solution for prototype reduction in big data classification[J]. Neurocomputing, 2015, 150: 331-345.
|
| 10 |
MAILLO J, TRIGUERO I, HERRERA F. A MapReduce-based k-nearest neighbor approach for big data classification[C]// Proceedings of the 2015 IEEE Trustcom/BigDataSE/ISPA. Piscataway: IEEE, 2015: 167-172.
|
| 11 |
KUMAR M, RATH S K. Classification of microarray using MapReduce based proximal support vector machine classifier [J]. Knowledge-Based Systems, 2015, 89: 584-602.
|
| 12 |
SUYKENS J A K, VANDEWALLE J. Least squares support vector machine classifiers[J]. Neural Processing Letters, 1999, 9(3): 293-300.
|
| 13 |
BECHINI A, MARCELLONI F, SEGATORI A. A MapReduce solution for associative classification of big data[J]. Information Sciences, 2016, 332: 33-55.
|
| 14 |
LI H, WANG Y, ZHANG D, et al. PFP: parallel FP-Growth for query recommendation[C]// Proceedings of the 2008 ACM Conference on Recommender Systems. New York: ACM, 2008: 107-114.
|
| 15 |
于苹苹,倪建成,姚彬修,等.基于Spark框架的高效KNN中文文本分类算法[J]. 计算机应用, 2016, 36(12): 3292-3297.
|
|
YU P P, NI J C, YAO B X, et al. Highly efficient Chinese text classification algorithm of KNN based on Spark framework[J]. Journal of Computer Applications, 2016, 36(12): 3292-3297.
|
| 16 |
夏宁霞, 苏一丹, 覃希. 一种高效的K-medoids聚类算法[J]. 计算机应用研究, 2010, 27(12): 4517-4519.
|
|
XIA N X, SU Y D, QIN X. Efficient K-medoids clustering algorithm[J]. Application Research of Computers, 2010, 27(12): 4517-4519.
|
| 17 |
RAMÍREZ-GALLEGO S, KRAWCZYK B, GARCÍA S, et al. Nearest neighbor classification for high-speed big data streams using Spark[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2017, 47(10): 2727-2739.
|
| 18 |
刘牧雷,徐菲菲.基于Spark的大数据三枝决策分类方法[J]. 上海电力学院学报, 2018, 34(5): 483-490.
|
|
LIU M L, XU F F. Processing big data with three way decision based on Spark [J]. Journal of Shanghai University of Electric Power, 2018, 34(5): 483-490.
|
| 19 |
YAO Y. The superiority of three-way decisions in probabilistic rough set models [J]. Information Sciences, 2011, 181(6): 1080-1096.
|
| 20 |
LIU P, ZHAO H, TENG J, et al. Parallel naive Bayes algorithm for large-scale Chinese text classification based on Spark[J]. Journal of Central South University, 2019, 26(1): 1-12.
|
| 21 |
ALI A H, ABDULLAH M Z. A parallel grid optimization of SVM hyperparameter for big data classification using Spark Radoop [J]. Karbala International Journal of Modern Science, 2020, 6(1): 3.
|
| 22 |
KENNEDY J, EBERHART R. Particle swarm optimization [C]// Proceedings of the 1995 International Conference on Neural Networks. Piscataway: IEEE, 1995, 4: 1942-1948.
|
| 23 |
HE Q, SHANG T, ZHUANG F, et al. Parallel extreme learning machine for regression based on MapReduce[J]. Neurocomputing, 2013, 102: 52-58.
|


 ), 崔来中1,2, 黄哲学1,2, PHILIPPE Fournier‑Viger2
), 崔来中1,2, 黄哲学1,2, PHILIPPE Fournier‑Viger2