


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (3): 946-952.DOI: 10.11772/j.issn.1001-9081.2024030290
张传浩1( ), 屠晓涵1, 谷学汇1, 轩波2
), 屠晓涵1, 谷学汇1, 轩波2
收稿日期:2024-03-20
修回日期:2024-06-03
接受日期:2024-06-04
发布日期:2024-07-19
出版日期:2025-03-10
通讯作者:
张传浩
作者简介:屠晓涵(1991—),女,河南南阳人,讲师,博士,CCF会员,主要研究方向:计算机视觉、机器学习基金资助:
Chuanhao ZHANG1(), Xiaohan TU1, Xuehui GU1, Bo XUAN2
Received:2024-03-20
Revised:2024-06-03
Accepted:2024-06-04
Online:2024-07-19
Published:2025-03-10
Contact:
Chuanhao ZHANG
About author:TU Xiaohan, born in 1991, Ph. D., lecturer. Her research interests include computer vision, machine learning.Supported by:摘要:
多模态三维目标检测是计算机视觉的一项重要任务,如何更好地融合不同模态之间的信息一直是该任务的研究重点。现有方法在融合不同模态信息时缺少对信息的筛选,且过多无关与干扰信息会造成模型性能的下降。针对上述问题,提出一种基于多模态信息相互引导补充的雷达-相机三维目标检测模型,以在融合特征时从另一种模态中自适应地挑选信息进行融合。自适应信息融合包括数据层面的相互引导补充和特征层面的相互引导补充。在数据层面的融合中,使用由点云产生的深度图和图像产生的分割掩码作为输入,以分别构建出实例级的深度图与实例级的三维虚拟点用于图像与点云的补充。在特征层面的融合中,使用点云产生的体素特征和图像产生的特征图作为输入,并从另一种模态中为待融合特征选取关键区域并通过注意力机制进行特征融合。实验结果表明,所提模型在nuScenes测试集上取得了良好的效果。相较于BEVFusion和TransFusion等传统非引导的融合模型,所提模型将平均精度均值(mAP)和nuScenes检测分数(NDS)这2个主流评测指标分别提升了0.9~28.9个百分点和0.6~26.1个百分点。以上验证了所提模型可有效提高多模态三维目标检测的准确性。
中图分类号:
张传浩, 屠晓涵, 谷学汇, 轩波. 基于多模态信息相互引导补充的雷达-相机三维目标检测[J]. 计算机应用, 2025, 45(3): 946-952.
Chuanhao ZHANG, Xiaohan TU, Xuehui GU, Bo XUAN. LiDAR-camera 3D object detection based on multi-modal information mutual guidance and supplementation[J]. Journal of Computer Applications, 2025, 45(3): 946-952.
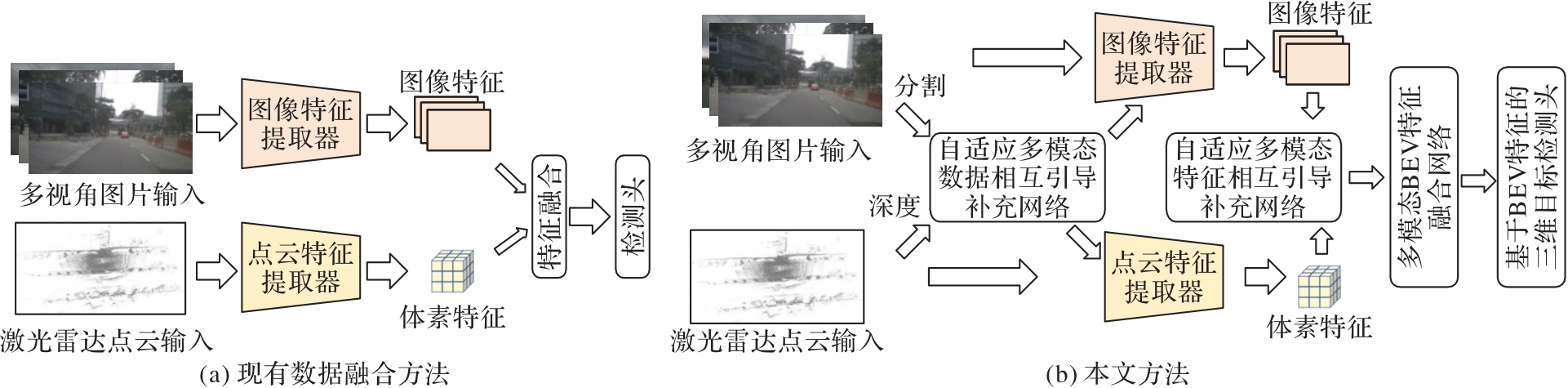
图1 本文方法与现有方法的对比
Fig. 1 Comparison between proposed method and existing method
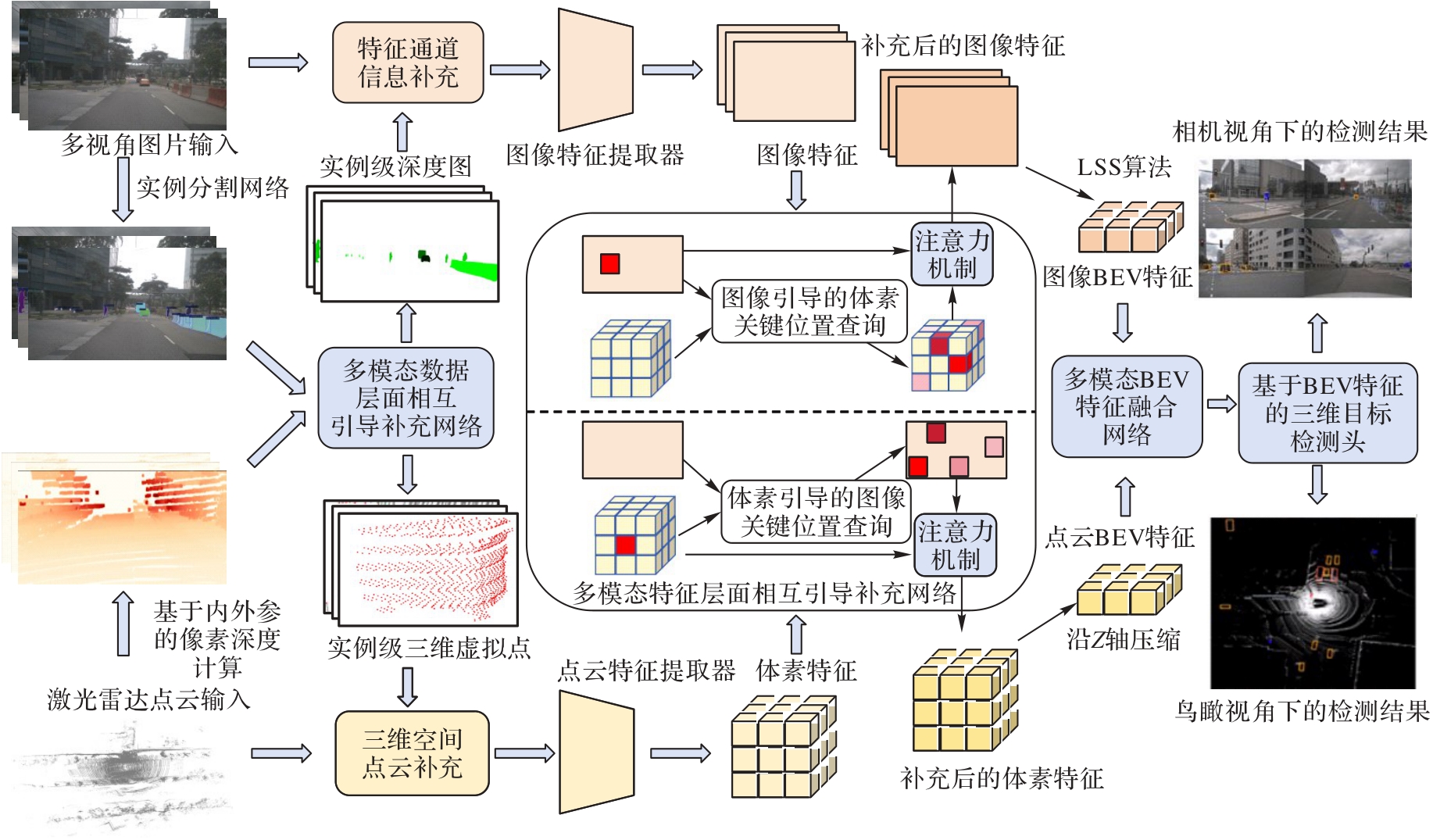
图2 基于多模态相互引导的信息补充网络的整体架构
Fig. 2 Overall architecture of information supplementation network based on multi-modal mutual guidance
| 模态 | 模型 | 测试集 | 验证集 | ||
|---|---|---|---|---|---|
| mAP | NDS | mAP | NDS | ||
| 相机 | BEVDet | 42.2 | 48.2 | — | — |
| M2BEV | 42.9 | 47.4 | 41.7 | 47.0 | |
| BEVFormer | 44.5 | 53.5 | 41.6 | 51.7 | |
| BEVDet4D | 45.1 | 56.9 | — | — | |
| 雷达 | PointPillars | — | — | 52.3 | 61.3 |
| SECOND | 52.8 | 63.3 | 52.6 | 63.0 | |
| CenterPoint | 60.3 | 67.3 | 59.6 | 66.8 | |
| 雷达+相机 | PointPainting | — | — | 65.8 | 69.6 |
| MVP | 66.4 | 70.5 | 66.1 | 70.0 | |
| FusionPainting | 68.1 | 71.6 | 66.5 | 70.7 | |
| AutoAlign | — | — | 66.6 | 71.1 | |
| FUTR3D | — | — | 64.5 | 68.3 | |
| TransFusion | 68.9 | 71.6 | 67.5 | 71.3 | |
| BEVFusion | 70.2 | 72.9 | 68.5 | 71.4 | |
| 本文模型 | 71.1 | 73.5 | 70.0 | 72.3 | |
表1 不同模型在nuScenes数据集上的评估结果 (%)
Tab. 1 Evaluation results of different models on nuScenes dataset
| 模态 | 模型 | 测试集 | 验证集 | ||
|---|---|---|---|---|---|
| mAP | NDS | mAP | NDS | ||
| 相机 | BEVDet | 42.2 | 48.2 | — | — |
| M2BEV | 42.9 | 47.4 | 41.7 | 47.0 | |
| BEVFormer | 44.5 | 53.5 | 41.6 | 51.7 | |
| BEVDet4D | 45.1 | 56.9 | — | — | |
| 雷达 | PointPillars | — | — | 52.3 | 61.3 |
| SECOND | 52.8 | 63.3 | 52.6 | 63.0 | |
| CenterPoint | 60.3 | 67.3 | 59.6 | 66.8 | |
| 雷达+相机 | PointPainting | — | — | 65.8 | 69.6 |
| MVP | 66.4 | 70.5 | 66.1 | 70.0 | |
| FusionPainting | 68.1 | 71.6 | 66.5 | 70.7 | |
| AutoAlign | — | — | 66.6 | 71.1 | |
| FUTR3D | — | — | 64.5 | 68.3 | |
| TransFusion | 68.9 | 71.6 | 67.5 | 71.3 | |
| BEVFusion | 70.2 | 72.9 | 68.5 | 71.4 | |
| 本文模型 | 71.1 | 73.5 | 70.0 | 72.3 | |
| 模型 | 模态 | 晴天 | 雨天 | 白天 | 夜晚 | ||||
|---|---|---|---|---|---|---|---|---|---|
| mAP | mIoU | mAP | mIoU | mAP | mIoU | mAP | mIoU | ||
| CenterPoint | 雷达 | 62.9 | 50.7 | 59.2 | 42.3 | 62.8 | 48.9 | 35.4 | 37.0 |
| BEVDet/LSS | 相机 | 32.9 | 59.0 | 33.7 | 50.5 | 33.7 | 57.4 | 13.5 | 30.8 |
| BEVFusion | 雷达+相机 | 68.2 | 65.6 | 69.9 | 55.9 | 68.5 | 63.1 | 42.8 | 43.6 |
| 本文模型 | 雷达+相机 | 69.0 | 66.5 | 71.6 | 57.2 | 69.2 | 63.8 | 43.9 | 45.3 |
表2 不同模型在不同天气条件下的评估结果 (%)
Tab. 2 Evaluation results of different models under different weather conditions
| 模型 | 模态 | 晴天 | 雨天 | 白天 | 夜晚 | ||||
|---|---|---|---|---|---|---|---|---|---|
| mAP | mIoU | mAP | mIoU | mAP | mIoU | mAP | mIoU | ||
| CenterPoint | 雷达 | 62.9 | 50.7 | 59.2 | 42.3 | 62.8 | 48.9 | 35.4 | 37.0 |
| BEVDet/LSS | 相机 | 32.9 | 59.0 | 33.7 | 50.5 | 33.7 | 57.4 | 13.5 | 30.8 |
| BEVFusion | 雷达+相机 | 68.2 | 65.6 | 69.9 | 55.9 | 68.5 | 63.1 | 42.8 | 43.6 |
| 本文模型 | 雷达+相机 | 69.0 | 66.5 | 71.6 | 57.2 | 69.2 | 63.8 | 43.9 | 45.3 |
| 模态 | mAP | NDS |
|---|---|---|
| 雷达 | 62.7 | 69.8 |
| 相机 | 36.6 | 43.4 |
| 雷达+相机 | 70.0 | 72.3 |
表3 本文模型在不同模态下的对比结果 (%)
Tab. 3 Comparison results of proposed model in different modalities
| 模态 | mAP | NDS |
|---|---|---|
| 雷达 | 62.7 | 69.8 |
| 相机 | 36.6 | 43.4 |
| 雷达+相机 | 70.0 | 72.3 |
| 模型 | mAP | NDS |
|---|---|---|
| 基线 | 68.5 | 71.4 |
| 基线+多模态引导(数据) | 68.9 | 71.7 |
| 基线+多模态引导(特征) | 69.6 | 72.1 |
| 基线+多模态引导(数据+特征) | 70.0 | 72.3 |
表4 消融实验结果 (%)
Tab. 4 Ablation experimental results
| 模型 | mAP | NDS |
|---|---|---|
| 基线 | 68.5 | 71.4 |
| 基线+多模态引导(数据) | 68.9 | 71.7 |
| 基线+多模态引导(特征) | 69.6 | 72.1 |
| 基线+多模态引导(数据+特征) | 70.0 | 72.3 |
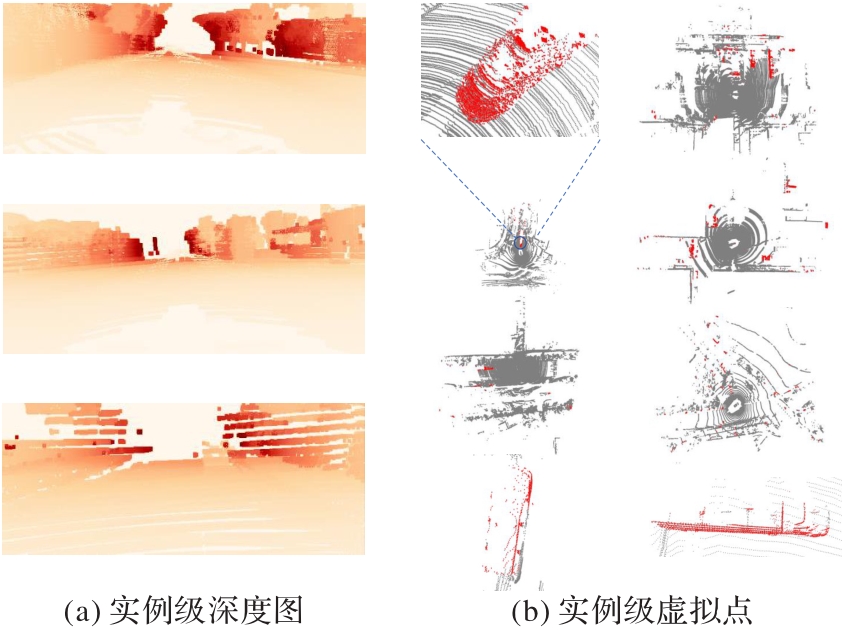
图3 数据补充的可视化分析
Fig. 3 Visual analysis of data supplementation

图4 本文模型在不同场景下的检测结果可视化
Fig. 4 Visualization of detection results of proposed model in different scenarios
| 1 | QI C R, LIU W, WU C, et al. Frustum PointNets for 3D object detection from RGB-D data [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 918-927. |
| 2 | SHIN K, KWON Y, TOMIZUKA M. RoarNet: a robust 3D object detection based on region approximation refinement [C]// Proceedings of the 2019 IEEE Intelligent Vehicles Symposium. Piscataway: IEEE, 2019: 2510-2515. |
| 3 | ZHANG Y, CHEN J, HUANG D. CAT-Det: contrastively augmented Transformer for multi-modal 3D object detection [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 898-907. |
| 4 | HUANG J, HUANG G, ZHU Z, et al. BEVDet: high-performance multi-camera 3D object detection in bird-eye-view [EB/OL]. [2024-02-14]. . |
| 5 | LIU Z, TANG H, AMINI A, et al. BEVFusion: multi-task multi-sensor fusion with unified bird’s-eye view representation [C]// Proceedings of the IEEE 2023 International Conference on Robotics and Automation. Piscataway: IEEE, 2023: 2774-2781. |
| 6 | PANG S, MORRIS D, RADHA H. CLOCs: camera-LiDAR object candidates fusion for 3D object detection [C]// Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2020: 10386-10393. |
| 7 | MAO J, WANG X, LI H. Interpolated convolutional networks for 3D point cloud understanding [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 1578-1587. |
| 8 | QI C R, SU H, MO K, et al. PointNet: deep learning on point sets for 3D classification and segmentation [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 77-85. |
| 9 | QI C R, YI L, SU H, et al. PointNet++ deep hierarchical feature learning on point sets in a metric space [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 5105-5114. |
| 10 | WANG Y, SUN Y, LIU Z, et al. Dynamic graph CNN for learning on point clouds [J]. ACM Transactions on Graphics, 2019, 38(5): No.146. |
| 11 | ZHOU Y, TUZEL O. VoxelNet: end-to-end learning for point cloud based 3D object detection [C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 4490-4499. |
| 12 | LANG A H, VORA S, CAESAR H, et al. PointPillars: fast encoders for object detection from point clouds [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 12689-12697. |
| 13 | ZHOU Y, SUN P, ZHANG Y, et al. End-to-end multi-view fusion for 3D object detection in LiDAR point clouds [C]// Proceedings of the 2020 Conference on Robot Learning. New York: JMLR.org, 2020: 923-932. |
| 14 | MEYER G P, LADDHA A, KEE E, et al. LaserNet: an efficient probabilistic 3D object detector for autonomous driving [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 12669-12678. |
| 15 | YIN T, ZHOU X, KRÄHENBÜHL P. Center-based 3D object detection and tracking [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 11779-11788. |
| 16 | YANG B, LUO W, URTASUN R. PIXOR: real-time 3D object detection from point clouds [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7652-7660. |
| 17 | BRAZIL G, LIU X. M3D-RPN: monocular 3D region proposal network for object detection [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 9286-9295. |
| 18 | MANHARDT F, KEHL W, GAIDON A. ROI-10D: monocular lifting of 2D detection to 6D pose and metric shape [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 2064-2073. |
| 19 | BRAZIL G, PONS-MOLL G, LIU X, et al. Kinematic 3D object detection in monocular video [C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12368. Cham: Springer, 2020: 135-152. |
| 20 | MOUSAVIAN A, ANGUELOV D, FLYNN J, et al. 3D bounding box estimation using deep learning and geometry [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5632-5640. |
| 21 | FU H, GONG M, WANG C, et al. Deep ordinal regression network for monocular depth estimation [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 2002-2011. |
| 22 | ZIA M Z, STARK M, SCHINDLER K. Are cars just 3D boxes? — jointly estimating the 3D shape of multiple objects [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2014: 3678-3685. |
| 23 | PHILION J, FIDLER S. Lift, splat, shoot: encoding images from arbitrary camera rigs by implicitly unprojecting to 3D [C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12359. Cham: Springer, 2020:194-210. |
| 24 | HUANG J, HUANG G. BEVDet 4D: exploit temporal cues in multi-camera 3D object detection [EB/OL]. [2023-12-02]. . |
| 25 | PANG S, MORRIS D, RADHA H. Fast-CLOCs: fast camera-LiDAR object candidates fusion for 3D object detection [C]// Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2022: 3747-3756. |
| 26 | YANG B, GUO R, LIANG M, et al. RadarNet: exploiting radar for robust perception of dynamic objects [C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12363. Cham: Springer, 2020: 496-512. |
| 27 | QIAN K, ZHU S, ZHANG X, et al. Robust multimodal vehicle detection in foggy weather using complementary lidar and radar signals [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 444-453. |
| 28 | YANG B, LIANG M, URTASUN R. HDNET: exploiting HD maps for 3D object detection [C]// Proceedings of the 2nd Conference on Robot Learning. New York: JMLR.org, 2018: 146-155. |
| 29 | FANG J, ZHOU D, SONG X, et al. MapFusion: a general framework for 3D object detection with HDMaps [C]// Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2021: 3406-3413. |
| 30 | LIU Z, LIN Y, CAO Y, et al. Swin Transformer: hierarchical vision Transformer using shifted windows [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 9992-10002. |
| 31 | XIE E, YU Z, ZHOU D, et al. M2 BEV: multi-camera joint 3D detection and segmentation with unified birds-eye view representation[EB/OL]. [2024-01-25]. . |
| 32 | LI Z, WANG W, LI H, et al. BEVFormer: learning bird’s-eye-view representation from multi-camera images via spatiotemporal Transformers [C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13669. Cham: Springer, 2022: 1-18. |
| 33 | YAN Y, MAO Y, LI B. SECOND: sparsely embedded convolutional detection [J]. Sensors, 2018, 18(10): No.3337. |
| 34 | VORA S, LANG A H, HELOU B, et al. PointPainting: sequential fusion for 3D object detection [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 4603-4611. |
| 35 | YIN T, ZHOU X, KRÄHENBÜHL P. Multimodal virtual point 3D detection [C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 16494-16507. |
| 36 | XU S, ZHOU D, FANG J, et al. FusionPainting: multimodal fusion with adaptive attention for 3D object detection [C]// Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference. Piscataway: IEEE, 2021: 3047-3054. |
| 37 | CHEN Z, LI Z, ZHANG S, et al. AutoAlign: pixel-instance feature aggregation for multi-modal 3D object detection [C]// Proceedings of the 31st International Joint Conference on Artificial Intelligence. California: IJCAI.org, 2022:827-833. |
| 38 | CHEN X, ZHANG T, WANG Y, et al. FUTR3D: a unified sensor fusion framework for 3D detection [C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 172-181. |
| 39 | BAI X, HU Z, ZHU X, et al. Transfusion: robust LiDAR-camera fusion for 3D object detection with transformers [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 1080-1089. |
| [1] | 孙晨伟, 侯俊利, 刘祥根, 吕建成. 面向工程图纸理解的大语言模型提示生成方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 801-807. |
| [2] | 陈维, 施昌勇, 马传香. 基于多模态数据融合的农作物病害识别方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 840-848. |
| [3] | 蔡启健, 谭伟. 语义图增强的多模态推荐算法[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 421-427. |
| [4] | 黄颖, 杨佳宇, 金家昊, 万邦睿. 用于RGBT跟踪的孪生混合信息融合算法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2878-2885. |
| [5] | 张睿, 张鹏云, 高美蓉. 自优化双模态多通路非深度前庭神经鞘瘤识别模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2975-2982. |
| [6] | 薛凯鹏, 徐涛, 廖春节. 融合自监督和多层交叉注意力的多模态情感分析网络[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2387-2392. |
| [7] | 刘越, 刘芳, 武奥运, 柴秋月, 王天笑. 基于自注意力机制与图卷积的3D目标检测网络[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1972-1977. |
| [8] | 陈田, 蔡从虎, 袁晓辉, 罗蓓蓓. 基于多尺度卷积和自注意力特征融合的多模态情感识别方法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 369-376. |
| [9] | 赖华, 孙童, 王文君, 余正涛, 高盛祥, 董凌. 多模态特征的越南语语音识别文本标点恢复[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 418-423. |
| [10] | 郑盛有, 陈雁翔, 赵祖兴, 刘海洋. 多模态部分伪造数据集的构建与基准检测[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 3134-3140. |
| [11] | 林于翔, 吴运兵, 阴爱英, 廖祥文. 基于语义相关性分析的多模态摘要模型[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 65-72. |
| [12] | 赵强, 王中卿, 王红玲. 融合多模态信息的产品摘要抽取模型[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 73-78. |
| [13] | 黄懿蕊, 罗俊玮, 陈景强. 基于对比学习和GIF标记的多模态对话回复检索[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 32-38. |
| [14] | 王春雷, 王肖, 刘凯. 多模态知识图谱表示学习综述[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 1-15. |
| [15] | 罗俊豪, 朱焱. 用于未对齐多模态语言序列情感分析的多交互感知网络[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 79-85. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||