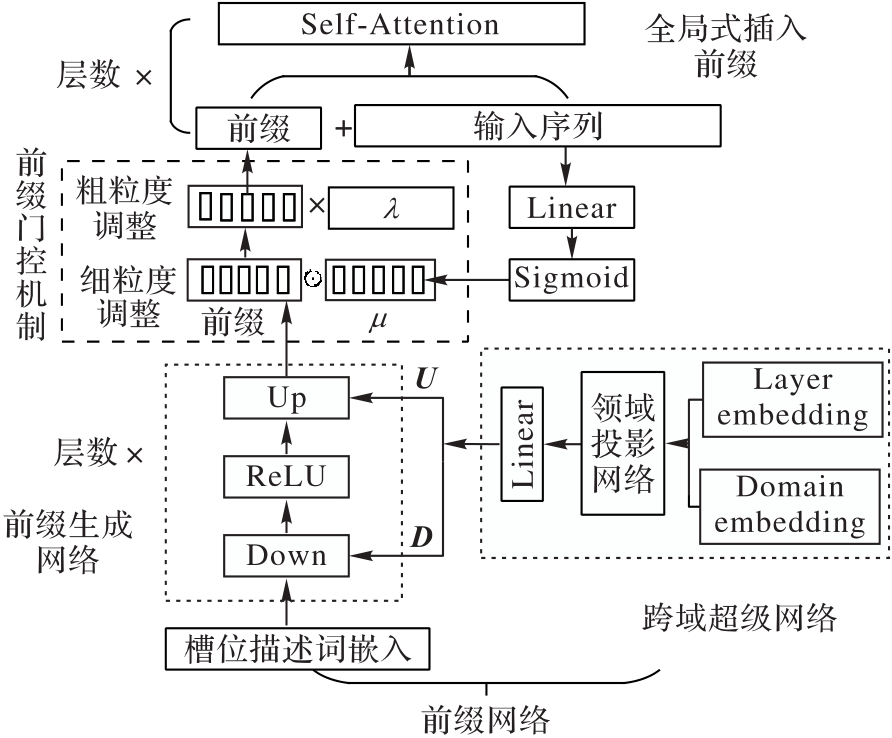
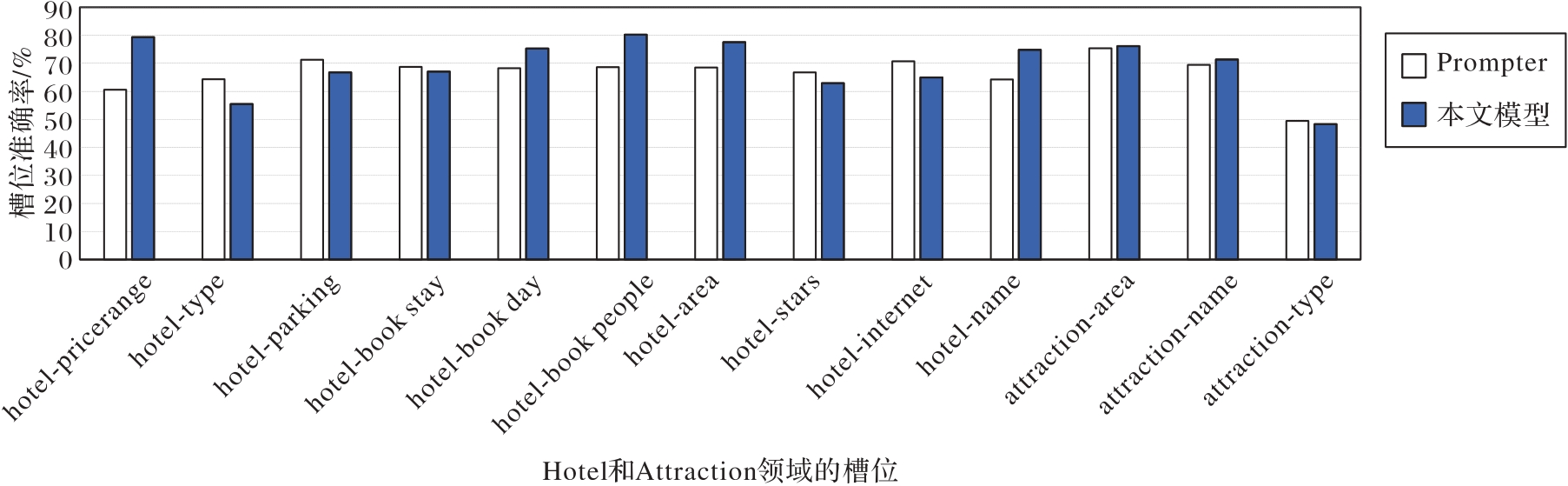
| [1] |
赵阳洋,王振宇,王佩,等.任务型对话系统研究综述[J].计算机学报,2020, 43(10): 1862-1896.
|
|
ZHAO Y Y, WANG Z Y, WANG P, et al. A survey on task-oriented dialogue systems [J]. Chinese Journal of Computers, 2020, 43(10): 1862-1896.
|
| [2] |
JACQMIN L, BARAHONA L M R, FAVRE B. “Do you follow me?”: a survey of recent approaches in dialogue state tracking [C]// Proceedings of the 23rd Annual Meeting of the Special Interest Group on Discourse and Dialogue. Stroudsburg: ACL, 2022: 336-350.
|
| [3] |
WU C S, MADOTTO A, HOSSEINI-ASL E, et al. Transferable multi-domain state generator for task-oriented dialogue systems [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019: 808-819.
|
| [4] |
KUMAR A, KU P, GOYAL A, et al. MA-DST: multi-attention-based scalable dialog state tracking [C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 8107-8114.
|
| [5] |
RASTOGI A, ZANG X, SUNKARA S, et al. Towards scalable multi-domain conversational agents: the schema-guided dialogue dataset [C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 8689-8696.
|
| [6] |
DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long and Short Papers). Stroudsburg, PA: ACL, 2019: 4171-4186.
|
| [7] |
FENG Y, WANG Y, LI H. A sequence-to-sequence approach to dialogue state tracking [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 1714-1725.
|
| [8] |
LEE H, LEE J, KIM T Y. SUMBT: slot-utterance matching for universal and scalable belief tracking [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019: 5478-5483.
|
| [9] |
SHIN J, YU H, MOON H, et al. Dialogue Summaries as Dialogue States (DS2), template-guided summarization for few-shot dialogue state tracking [C]// Findings of the Association for Computational Linguistics: ACL 2022. Stroudsburg: ACL, 2022: 3824-3846.
|
| [10] |
RAFFEL C, SHAZEER N, ROBERTS A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer [J]. Journal of Machine Learning Research, 2020, 21: 1-67.
|
| [11] |
LIN Z, LIU B, MADOTTO A, et al. Zero-shot dialogue state tracking via cross-task transfer [C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2021: 7890-7900.
|
| [12] |
LIN Z, LIU B, MOON S, et al. Leveraging slot descriptions for zero-shot cross-domain dialogue state tracking [C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2021: 5640-5648.
|
| [13] |
HECK M, LUBIS N, RUPPIK B, et al. ChatGPT for zero-shot dialogue state tracking: a solution or an opportunity? [C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg: ACL, 2023: 936-950.
|
| [14] |
MAHABADI R K, RUDER S, DEHGHANI M, et al. Parameter-efficient multi-task fine-tuning for transformers via shared hypernetworks [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 565-576.
|
| [15] |
WANG Q, DING L, CAO Y, et al. Divide, conquer, and combine: mixture of semantic-independent experts for zero-shot dialogue state tracking [C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2023: 2048-2061.
|
| [16] |
LI X L, LIANG P. Prefix-tuning: optimizing continuous prompts for generation [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 4582-4597.
|
| [17] |
AKSU I T, KAN M Y, CHEN N. Prompter: zero-shot adaptive prefixes for dialogue state tracking domain adaptation [C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2023: 4588-4603.
|
| [18] |
ERIC M, GOEL R, PAUL S, et al. MultiWOZ 2.1: a consolidated multi-domain dialogue dataset with state corrections and state tracking baselines [C]// Proceedings of the 12th Language Resources and Evaluation Conference. Paris: European Language Resources Association, 2020: 422-428.
|
| [19] |
HA D, DAI A M, LE Q V. HyperNetworks [EB/OL]. [2024-06-20]. .
|
| [20] |
TENNEY I, DAS D, PAVLICK E. BERT rediscovers the classical NLP pipeline [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2019: 4593-4601.
|
| [21] |
SU Y, SHU L, MANSIMOV E, et al. Multi-task pre-training for plug-and-play task-oriented dialogue system [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 4661-4676.
|
| [22] |
HOFFMAN M D, BLEI D M, BACH F. Online learning for latent Dirichlet allocation [C]// Proceedings of the 24th International Conference on Neural Information Processing Systems — Volume 1. Red Hook: Curran Associates Inc., 2010: 856-864.
|


 )
)