


《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (3): 867-873.DOI: 10.11772/j.issn.1001-9081.2021030375
所属专题: 人工智能
杜曾贞1, 唐东昕2, 解丹1( )
)
收稿日期:2021-03-15
修回日期:2021-05-20
接受日期:2021-05-31
发布日期:2022-04-09
出版日期:2022-03-10
通讯作者:
解丹
作者简介:杜曾贞(1998—),女,湖北荆州人,硕士研究生,主要研究方向:自然语言处理、人工智能基金资助:
Zengzhen DU1, Dongxin TANG2, Dan XIE1()
Received:2021-03-15
Revised:2021-05-20
Accepted:2021-05-31
Online:2022-04-09
Published:2022-03-10
Contact:
Dan XIE
About author:DU Zengzhen, born in 1998, M. S. candidate. Her research interests include natural language processing, artificial intelligence.Supported by:摘要:
在智能问诊中,为了让医生快速提出合理的反问以提高医患对话效率,提出了基于深度神经网络的反问生成方法。首先获取大量医患对话文本并进行标注;然后使用文本循环神经网络(TextRNN)、文本卷积神经网络(TextCNN)二种分类模型分别对医生的陈述进行分类;再利用双向文本循环神经网络(TextRNN-B)、双向变形编码器(BERT)分类模型进行问题触发;设计六种不同的问答选取方式来模拟医疗咨询领域情景,采用开源神经机器翻译(OpenNMT)模型进行反问生成;最后对已生成的反问进行综合评估。实验结果表明,使用TextRNN进行分类优于TextCNN,利用BERT模型进行问题触发优于TextRNN-B,采用OpenNMT模型在Window-top方式下实现反问生成时,使用双语评估替补(BLEU)和困惑度(PPL)指标进行评价的结果最好。所提方法验证了深度神经网络技术在反问生成中的有效性,可以有效解决智能问诊中医生反问生成的问题。
中图分类号:
杜曾贞, 唐东昕, 解丹. 智能问诊中基于深度神经网络的反问生成方法[J]. 计算机应用, 2022, 42(3): 867-873.
Zengzhen DU, Dongxin TANG, Dan XIE. Method of generating rhetorical questions based on deep neural network in intelligent consultation[J]. Journal of Computer Applications, 2022, 42(3): 867-873.
| 角色 | 对话 |
|---|---|
| 患者 | 弱视属于视力明显下降吗? |
| 医生 | 弱视是指视力要比健康眼差。 |
| 患者 | 我的孩子检查出弱视。 |
| 医生 | 孩子是两个眼睛视力不好还是一只呢? |
| 患者 | 一只眼睛。 |
| 医生 | 方便提供孩子的裸眼和矫正视力吗? |
表1 医患问诊对话实例
Tab.1 Question-answer example between a doctor and a patient
| 角色 | 对话 |
|---|---|
| 患者 | 弱视属于视力明显下降吗? |
| 医生 | 弱视是指视力要比健康眼差。 |
| 患者 | 我的孩子检查出弱视。 |
| 医生 | 孩子是两个眼睛视力不好还是一只呢? |
| 患者 | 一只眼睛。 |
| 医生 | 方便提供孩子的裸眼和矫正视力吗? |
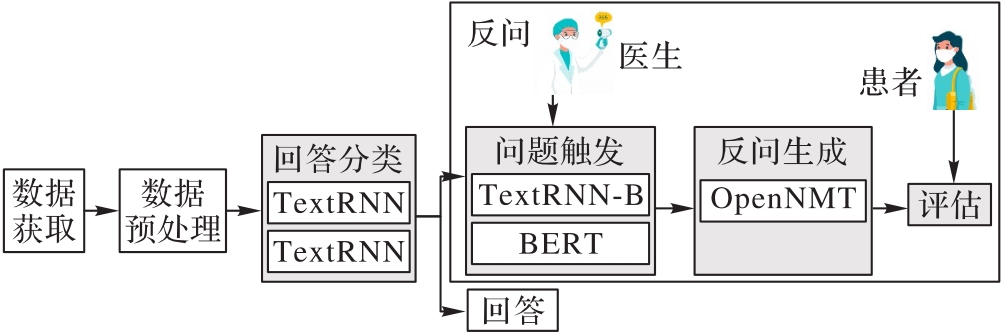
图1 反问生成流程
Fig. 1 Flowchart of rhetorical question generation

图2 TextRNN-B基本流程
Fig. 2 Basic flowchart of TextRNN-B
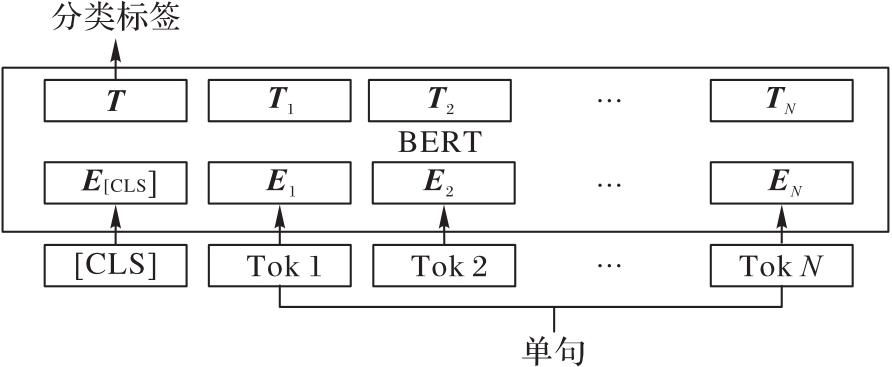
图3 使用BERT处理的单句分类模型
Fig. 3 Single sentence classification model with BERT

图4 神经机器翻译原理
Fig. 4 Principle of neural machine translation

图5 问答论坛中的医患对话实例
Fig. 5 QA example between a doctor and a patient on QA forum
| 数据集数量 | TextCNN | TextRNN | 数据集数量 | TextCNN | TextRNN |
|---|---|---|---|---|---|
| 1 000 | 84.60 | 92.50 | 10 000 | 89.50 | 96.25 |
| 2 000 | 86.50 | 94.00 | 20 000 | 89.00 | 96.00 |
| 5 000 | 88.00 | 95.50 | 30 000 | 88.65 | 95.75 |
表2 不同数据集选取的准确率测试结果 ( %)
Tab. 2 Accuracy test results of different selected datasets
| 数据集数量 | TextCNN | TextRNN | 数据集数量 | TextCNN | TextRNN |
|---|---|---|---|---|---|
| 1 000 | 84.60 | 92.50 | 10 000 | 89.50 | 96.25 |
| 2 000 | 86.50 | 94.00 | 20 000 | 89.00 | 96.00 |
| 5 000 | 88.00 | 95.50 | 30 000 | 88.65 | 95.75 |
| 选取方式 | BLSTM-QuD | BERT-QuD | |||
|---|---|---|---|---|---|
| F1-macro | F1-micro | Accuracy | F1 | Accuracy | |
| Window-top | 0.715 1 | 0.715 7 | 0.663 1 | 0.696 3 | 0.678 7 |
| Window-last-q | 0.742 3 | 0.745 6 | 0.692 8 | 0.753 8 | 0.749 6 |
| Window-1 | 0.704 1 | 0.704 1 | 0.667 1 | 0.705 4 | 0.709 0 |
| Window-3 | 0.702 8 | 0.703 1 | 0.659 6 | 0.718 7 | 0.712 2 |
| Window-5 | 0.696 3 | 0.696 4 | 0.644 8 | 0.725 3 | 0.726 0 |
| Window-10 | 0.677 6 | 0.677 7 | 0.610 7 | 0.671 4 | 0.669 2 |
表3 基于六种选取方式的问题触发检测结果对比
Tab. 3 Comparison of question trigger detection results based on six selection methods
| 选取方式 | BLSTM-QuD | BERT-QuD | |||
|---|---|---|---|---|---|
| F1-macro | F1-micro | Accuracy | F1 | Accuracy | |
| Window-top | 0.715 1 | 0.715 7 | 0.663 1 | 0.696 3 | 0.678 7 |
| Window-last-q | 0.742 3 | 0.745 6 | 0.692 8 | 0.753 8 | 0.749 6 |
| Window-1 | 0.704 1 | 0.704 1 | 0.667 1 | 0.705 4 | 0.709 0 |
| Window-3 | 0.702 8 | 0.703 1 | 0.659 6 | 0.718 7 | 0.712 2 |
| Window-5 | 0.696 3 | 0.696 4 | 0.644 8 | 0.725 3 | 0.726 0 |
| Window-10 | 0.677 6 | 0.677 7 | 0.610 7 | 0.671 4 | 0.669 2 |
| 选取方式 | 机器评估 | 人工评价/% | |||||||
|---|---|---|---|---|---|---|---|---|---|
| BLEU-1 | BLEU-2 | BLEU-4 | PPL | “0” | “1” | “2” | “3” | Average | |
| Window-top | 0.360 0 | 0.254 5 | 0.111 7 | 1.569 7 | 0.40 | 19.20 | 55.60 | 24.80 | 51.20 |
| Window-last-q | 0.310 4 | 0.209 0 | 0.053 6 | 1.864 3 | 0.80 | 22.60 | 49.80 | 26.80 | 50.65 |
| Window-1 | 0.062 0 | 0.007 9 | 0.001 8 | 1.824 8 | 3.60 | 48.60 | 35.80 | 12.00 | 39.05 |
| Window-3 | 0.287 5 | 0.204 8 | 0.057 0 | 1.885 4 | 0.60 | 31.00 | 45.40 | 23.00 | 47.70 |
| Window-5 | 0.326 2 | 0.226 0 | 0.056 5 | 1.973 7 | 1.40 | 34.00 | 43.20 | 21.40 | 46.15 |
| Window-10 | 0.305 3 | 0.212 2 | 0.060 9 | 1.968 6 | 4.20 | 37.40 | 41.40 | 17.00 | 42.80 |
表4 基于六种选取方式的反问生成结果对比
Tab. 4 Comparison of rhetorical question generation results based on six selection methods
| 选取方式 | 机器评估 | 人工评价/% | |||||||
|---|---|---|---|---|---|---|---|---|---|
| BLEU-1 | BLEU-2 | BLEU-4 | PPL | “0” | “1” | “2” | “3” | Average | |
| Window-top | 0.360 0 | 0.254 5 | 0.111 7 | 1.569 7 | 0.40 | 19.20 | 55.60 | 24.80 | 51.20 |
| Window-last-q | 0.310 4 | 0.209 0 | 0.053 6 | 1.864 3 | 0.80 | 22.60 | 49.80 | 26.80 | 50.65 |
| Window-1 | 0.062 0 | 0.007 9 | 0.001 8 | 1.824 8 | 3.60 | 48.60 | 35.80 | 12.00 | 39.05 |
| Window-3 | 0.287 5 | 0.204 8 | 0.057 0 | 1.885 4 | 0.60 | 31.00 | 45.40 | 23.00 | 47.70 |
| Window-5 | 0.326 2 | 0.226 0 | 0.056 5 | 1.973 7 | 1.40 | 34.00 | 43.20 | 21.40 | 46.15 |
| Window-10 | 0.305 3 | 0.212 2 | 0.060 9 | 1.968 6 | 4.20 | 37.40 | 41.40 | 17.00 | 42.80 |
| 类别 | 实例1 | 实例2 |
|---|---|---|
| 上文 | 患者:慢性鼻炎怎么治疗啊? 医生:您好。平时是什么症状呢? 患者:鼻子不通气。 | 患者:弱视属于视力明显下降吗? 医生:弱视是指视力要比健康眼差。 患者:我的孩子检查出是弱视。 医生:孩子是两个眼睛视力不好还是一只呢? 患者:一只眼睛。 |
| 原文 | 医生:持续多久了? | 医生:方便提供孩子的裸眼和矫正视力吗? |
| Window-top | 医生:您好,这种情况多久了? | 医生:已经持续一阵子了吗? |
| Window-last-q | 医生,您好,做过什么检查? | 医生:视力是多少呢? |
表5 反问生成的两个实例
Tab. 5 Two examples of rhetorical question generation between a doctor and a patient
| 类别 | 实例1 | 实例2 |
|---|---|---|
| 上文 | 患者:慢性鼻炎怎么治疗啊? 医生:您好。平时是什么症状呢? 患者:鼻子不通气。 | 患者:弱视属于视力明显下降吗? 医生:弱视是指视力要比健康眼差。 患者:我的孩子检查出是弱视。 医生:孩子是两个眼睛视力不好还是一只呢? 患者:一只眼睛。 |
| 原文 | 医生:持续多久了? | 医生:方便提供孩子的裸眼和矫正视力吗? |
| Window-top | 医生:您好,这种情况多久了? | 医生:已经持续一阵子了吗? |
| Window-last-q | 医生,您好,做过什么检查? | 医生:视力是多少呢? |
| 得分 | 对话长度<5 | 对话长度≥5 |
|---|---|---|
| 1 | 75.2 | 30.6 |
| 0 | 24.8 | 69.4 |
表6 短上文与长上文的得分占比 (%)
Tab.6 Score proportion of short context and long context
| 得分 | 对话长度<5 | 对话长度≥5 |
|---|---|---|
| 1 | 75.2 | 30.6 |
| 0 | 24.8 | 69.4 |
| 1 | EASTIN C, EASTIN T. Clinical characteristics of coronavirus disease 2019 in China[J]. Journal of Emergency Medicine, 2020, 58(4): 711-712. 10.1016/j.jemermed.2020.04.004 |
| 2 | 王智悦,于清,王楠,等. 基于知识图谱的智能问答研究综述[J]. 计算机工程与应用, 2020, 56(23): 1-11. 10.1109/aeeca52519.2021.9574313 |
| WANG Z Y, YU Q, WANG N, et al. Survey of intelligent question answering research based on knowledge graph[J]. Computer Engineering and Applications, 2020, 56(23): 1-11. 10.1109/aeeca52519.2021.9574313 | |
| 3 | 贺佳,杜建强,聂斌,等. 智能问答系统在医学领域的应用研究[J]. 医学信息, 2018, 31(14): 16-19. 10.3969/j.issn.1006-1959.2018.14.007 |
| HE J, DU J Q, NIE B, et al. Research on the application of intelligent question-answering system in medical field[J]. Medical Information, 2018, 31(14): 16-19. 10.3969/j.issn.1006-1959.2018.14.007 | |
| 4 | LEE M, CIMINO J, HAI R Z, et al. Beyond information retrieval-medical question answering[J]. American Medical Informatics Association Annual Symposium Proceedings, 2006, 1(1): 469-473. |
| 5 | CAO Y G, LIU F, SIMPSON P, et al. AskHERMES: an online question answering system for complex clinical questions[J]. Journal of Biomedical Informatics, 2011, 44(2): 277-288. 10.1016/j.jbi.2011.01.004 |
| 6 | ABACHA A BEN, ZWEIGENBAUM P. MEANS: a medical question-answering system combining NLP techniques and semantic Web technologies[J]. Information Processing and Management, 2015, 51(5): 570-594. 10.1016/j.ipm.2015.04.006 |
| 7 | ASIAEE A H, MINNING T, DOSHI P, et al. A framework for ontology-based question answering with application to parasite immunology[J]. Journal of Biomedical Semantics, 2015(6): Article No. 31. 10.1186/s13326-015-0029-x |
| 8 | YIN Y, ZHANG Y, LIU X, et al. HealthQA: a Chinese QA summary system for smart health[C]// Proceedings of the 2014 International Conference on Smart Health. Cham: Springer, 2014:51-62. 10.1007/978-3-319-08416-9_6 |
| 9 | 田迎,单娅辉,王时绘. 基于知识图谱的抑郁症自动问答系统研究[J]. 湖北大学学报(自然科学版), 2020, 42(5): 587-591. |
| TIAN Y, SHAN Y H, WANG S H. The research of depression automatic question answering system based on knowledge graph[J]. Journal of Hubei University (Natural Science), 2020, 42(5): 587-591. | |
| 10 | 乔宇,崔亮亮,李帅,等. 智能问答机器人系统研发及应用研究:以济南市新型冠状病毒肺炎疫情处置应对为例[J]. 山东大学学报(医学版), 2020, 58(4): 17-22. |
| QIAO Y, CUI L L, LI S, et al. Research and development of intelligent question answering robot system: a case study of its application in response to COVID-19 epidemic in Jinan City[J]. Journal of Shandong University (Health Sciences), 2020, 58(4): 17-22. | |
| 11 | 汤人杰,杨巧节. 基于医疗知识图谱的智能辅助问诊模型研究[J]. 中国数字医学, 2020, 15(10): 5-8. 10.3969/j.issn.1673-7571.2020.10.002 |
| TANG R J, YANG Q J. Research on the intelligent assisted inquiry model based on medical knowledge map[J]. China Digital Medicine, 2020, 15(10): 5-8. 10.3969/j.issn.1673-7571.2020.10.002 | |
| 12 | 王浩. 神经机器翻译模型的实现验证及其剪枝压缩[D]. 南京:南京大学, 2019:2.(WANG H. Implementation, verification and compression by pruning of neural machine translation model[D]. Nanjing: Nanjing University, 2019:2.) |
| 13 | WU Y, SCHUSTER M, CHEN Z, et al. Google’s neural machine translation system: bridging the gap between human and machine translation[EB/OL].[2020-06-22]. . |
| 14 | OTT M, EDUNOV S, BAEVSKI A, et al. Fairseq: a fast, extensible toolkit for sequence modeling[EB/OL].[2020-06-22]. . 10.18653/v1/n19-4009 |
| 15 | KLEIN G, KIM Y, DENG Y T, et al. OpenNMT: open-source toolkit for neural machine translation[C]// Proceedings of the 2017 Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2017:67-72. 10.18653/v1/p17-4012 |
| 16 | 周海林,沈志贤. 谷歌神经机器翻译质量现状分析[J]. 科技资讯, 2018, 16(1): 220. 10.16661/j.cnki.1672-3791.2018.01.220 |
| ZHOU H L, SHEN Z X. Analysis of the quality of Google’s neural machine translation[J]. Science and Technology Information, 2018, 16(1): 220. 10.16661/j.cnki.1672-3791.2018.01.220 | |
| 17 | 牛向华,苏依拉,高芬,等. 单语数据训练在蒙汉神经机器翻译中的应用[J]. 计算机应用与软件, 2020, 37(6):178-183. 10.3969/j.issn.1000-386x.2020.06.032 |
| NIU X H, SU Y L, GAO F, et al. Application of monolingual data training on Mongolian-Chinese neural machine translation[J]. Computer Applications and Software, 2020, 37(6):178-183. 10.3969/j.issn.1000-386x.2020.06.032 | |
| 18 | KIM Y. Convolutional neural networks for sentence classification[C]// Proceedings of the 2014 Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2014:1746-1751. 10.3115/v1/d14-1181 |
| 19 | 李雅昆,潘晴, WANG E X.基于改进的多层BLSTM的中文分词和标点预测[J]. 计算机应用, 2018, 38(5): 1278-1282, 1314. 10.11772/j.issn.1001-9081.201711112631 |
| LI Y K, PAN Q, WANG F. Joint Chinese word segmentation and punctuation prediction based on improved multilayer BLSTM network[J]. Journal of Computer Applications, 2018, 38(5): 1278-1282, 1314. 10.11772/j.issn.1001-9081.201711112631 | |
| 20 | 华冰涛,袁志祥,肖维民,等. 基于BLSTM-CNN-CRF模型的槽填充与意图识别[J]. 计算机工程与应用, 2019, 55(9): 139-143. 10.3778/j.issn.1002-8331.1801-0183 |
| HUA B T, YUAN Z X, XIAO W M, et al. Joint slot filling and intent detection with BLSTM-CNN-CRF[J]. Computer Engineering and Applications, 2019, 55(9): 139-143. 10.3778/j.issn.1002-8331.1801-0183 | |
| 21 | 严佩敏,唐婉琪. 基于改进BERT的中文文本分类[J]. 工业控制计算机, 2020, 33(7): 108-110. 10.3969/j.issn.1001-182X.2020.07.041 |
| YAN P M, TANG W Q. Chinese text classification based on improved BERT[J]. Industrial Control Computer, 2020, 33(7): 108-110. 10.3969/j.issn.1001-182X.2020.07.041 | |
| 22 | 张东东,彭敦陆. ENT-BERT:结合BERT和实体信息的实体关系分类模型[J]. 小型微型计算机系统, 2020, 41(12): 2557-2562. 10.3969/j.issn.1000-1220.2020.12.016 |
| ZHANG D D, PENG D L. ENT-BERT: entity relation classification model combining BERT and entity information[J]. Journal of Chinese Computer Systems, 2020, 41(12): 2257-2562. 10.3969/j.issn.1000-1220.2020.12.016 | |
| 23 | 张小川,戴旭尧,刘璐,等. 融合多头自注意力机制的中文短文本分类模型[J]. 计算机应用, 2020, 40(12): 3485-3489. 10.11772/j.issn.1001-9081.2020060914 |
| ZHANG X C, DAI X Y, LIU L, et al. Chinese short text classification model with multi-head self-attention mechanism[J]. Journal of Computer Applications, 2020, 40(12): 3485-3489. 10.11772/j.issn.1001-9081.2020060914 | |
| 24 | 王月,王孟轩,张胜,等. 基于BERT的警情文本命名实体识别[J]. 计算机应用, 2020, 40(2): 535-540. 10.11772/j.issn.1001-9081.2019101717 |
| WANG Y, WANG M X, ZHANG S, et al. Alarm text named entity recognition based on BERT[J]. Journal of Computer Applications, 2020, 40(2): 535-540. 10.11772/j.issn.1001-9081.2019101717 | |
| 25 | LUO W, WU D. Research and implementation of Seq2Seq model chat robot based on attention mechanism[J]. Journal of Physics: Conference Series, 2020, 1693(1): 1-8. 10.1088/1742-6596/1693/1/012200 |
| 26 | QIU L, LI J, BI W, et al. Are training samples correlated? learning to generate dialogue responses with multiple references[C]// Proceedings of the 2019 Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2019:3826-3835. 10.18653/v1/p19-1372 |
| 27 | SERBAN I V, SORDONI A, LOWE R, et al. A hierarchical latent variable encoder-decoder model for generating dialogues[C]// Proceedings of the 2017 AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2017:3295-3301. |
| 28 | LI J W, MONROE W, SHI T L, et al. Adversarial learning for neural dialogue generation[C]// Proceedings of the 2017 Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2017:2157-2169. |
| 29 | 乔博文,李军辉. 融合语义角色的神经机器翻译[J]. 计算机科学, 2020, 47(2): 163-168. 10.11896/jsjkx.190100048 |
| QIAO B W, LI J H. Neural machine translation combining source semantic roles[J]. Computer Science, 2020, 47(2): 163-168. 10.11896/jsjkx.190100048 | |
| 30 | CHUANG S P, SUNG T W, LIU A H, et al. Worse WER, but better BLEU? leveraging word embedding as intermediate in multitask end-to-end speech translation[C]// Proceedings of the 2020 Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2020:5998-6003. 10.18653/v1/2020.acl-main.533 |
| 31 | 陈俊航,徐小平,杨恒泓. 基于Seq2seq模型的推荐应用研究[J]. 计算机科学, 2019, 46(S1): 493-496. |
| CHEN J H, XU X P, YANG H H. Research on recommendation application based on Seq2seq model[J]. Computer Science, 2019, 46(S1): 493-496. | |
| 32 | HE T W, WANG H, HU B F. Evaluate the Chinese version of machine translation based on perplexity analysis[C]// Proceedings of the 2017 International Conference on Computational Science and Engineering. Piscataway: IEEE, 2017:278-281. 10.1109/cse-euc.2017.57 |
| [1] | 武小平, 张强, 赵芳, 焦琳. 基于BERT的心血管医疗指南实体关系抽取方法[J]. 计算机应用, 2021, 41(1): 145-149. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||