


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (1): 75-81.DOI: 10.11772/j.issn.1001-9081.2023121843
李斌1, 林民1( ), 斯日古楞null2,3, 高颖杰1, 王玉荣4, 张树钧1,3
), 斯日古楞null2,3, 高颖杰1, 王玉荣4, 张树钧1,3
收稿日期:2024-01-04
修回日期:2024-02-28
接受日期:2024-03-04
发布日期:2024-03-11
出版日期:2025-01-10
通讯作者:
林民
作者简介:李斌(1998—),男,内蒙古乌兰察布人,硕士研究生,CCF会员,主要研究方向:实体关系抽取、自然语言处理;基金资助:
Bin LI1, Min LIN1(), Siriguleng2,3, Yingjie GAO1, Yurong WANG4, Shujun ZHANG1,3
Received:2024-01-04
Revised:2024-02-28
Accepted:2024-03-04
Online:2024-03-11
Published:2025-01-10
Contact:
Min LIN
About author:LI Bin, born in 1998, M. S. candidate. His research interests include entity-relation extraction, natural language processing.Supported by:摘要:
基于“预训练+微调”范式的实体关系联合抽取方法依赖大规模标注数据,在数据标注难度大、成本高的中文古籍小样本场景下微调效率低,抽取性能不佳;中文古籍中普遍存在实体嵌套和关系重叠的问题,限制了实体关系联合抽取的效果;管道式抽取方法存在错误传播问题,影响抽取效果。针对以上问题,提出一种基于提示学习和全局指针网络的中文古籍实体关系联合抽取方法。首先,利用区间抽取式阅读理解的提示学习方法对预训练语言模型(PLM)注入领域知识以统一预训练和微调的优化目标,并对输入句子进行编码表示;其次,使用全局指针网络分别对主、客实体边界和不同关系下的主、客实体边界进行预测和联合解码,对齐成实体关系三元组,并构建了PTBG (Prompt Tuned BERT with Global pointer)模型,解决实体嵌套和关系重叠问题,同时避免了管道式解码的错误传播问题;最后,在上述工作基础上分析了不同提示模板对抽取性能的影响。在《史记》数据集上进行实验的结果表明,相较于注入领域知识前后的OneRel模型,PTBG模型所取得的F1值分别提升了1.64和1.97个百分点。可见,PTBG模型能更好地对中文古籍实体关系进行联合抽取,为低资源的小样本深度学习场景提供了新的研究思路与方法。
中图分类号:
李斌, 林民, 斯日古楞null, 高颖杰, 王玉荣, 张树钧. 基于提示学习和全局指针网络的中文古籍实体关系联合抽取方法[J]. 计算机应用, 2025, 45(1): 75-81.
Bin LI, Min LIN, Siriguleng, Yingjie GAO, Yurong WANG, Shujun ZHANG. Joint entity-relation extraction method for ancient Chinese books based on prompt learning and global pointer network[J]. Journal of Computer Applications, 2025, 45(1): 75-81.
| 原文 | “左右”的含义 |
|---|---|
| 左右欲刃相如。 | (名词,身边的人) |
| 王之左右,无一能佐。 | (名词,身边) |
| 使君七尺丈夫,安能为家奴左右。 | (动词,控制) |
| 高祖为亭长,常左右之。 | (动词,帮助) |
| 你左右将到村里去卖,一般还你钱,便卖些与我们,打甚么不紧? | (副词,反正) |
表1 中文古籍中的一词多义现象
Tab. 1 Polysemy in ancient Chinese books
| 原文 | “左右”的含义 |
|---|---|
| 左右欲刃相如。 | (名词,身边的人) |
| 王之左右,无一能佐。 | (名词,身边) |
| 使君七尺丈夫,安能为家奴左右。 | (动词,控制) |
| 高祖为亭长,常左右之。 | (动词,帮助) |
| 你左右将到村里去卖,一般还你钱,便卖些与我们,打甚么不紧? | (副词,反正) |

图1 中文古籍中的实体嵌套和关系重叠
Fig. 1 Entity nesting and relation overlapping in ancient Chinese books
| 来源 | token数/109 | 来源 | token数/109 |
|---|---|---|---|
| 古文诗词 | 0.8 | 中文专利 | 9.5 |
| 百科 | 5.0 | 法律判决 | 90.0 |
| 各类小说 | 120.0 | 博客 | 64.0 |
| 社区问答 | 200.0 | 学术论文 | 9.5 |
| 新闻 | 100.0 | 合计 | 598.8 |
表2 中文语料规模分布
Tab. 2 Chinese corpus size distribution
| 来源 | token数/109 | 来源 | token数/109 |
|---|---|---|---|
| 古文诗词 | 0.8 | 中文专利 | 9.5 |
| 百科 | 5.0 | 法律判决 | 90.0 |
| 各类小说 | 120.0 | 博客 | 64.0 |
| 社区问答 | 200.0 | 学术论文 | 9.5 |
| 新闻 | 100.0 | 合计 | 598.8 |
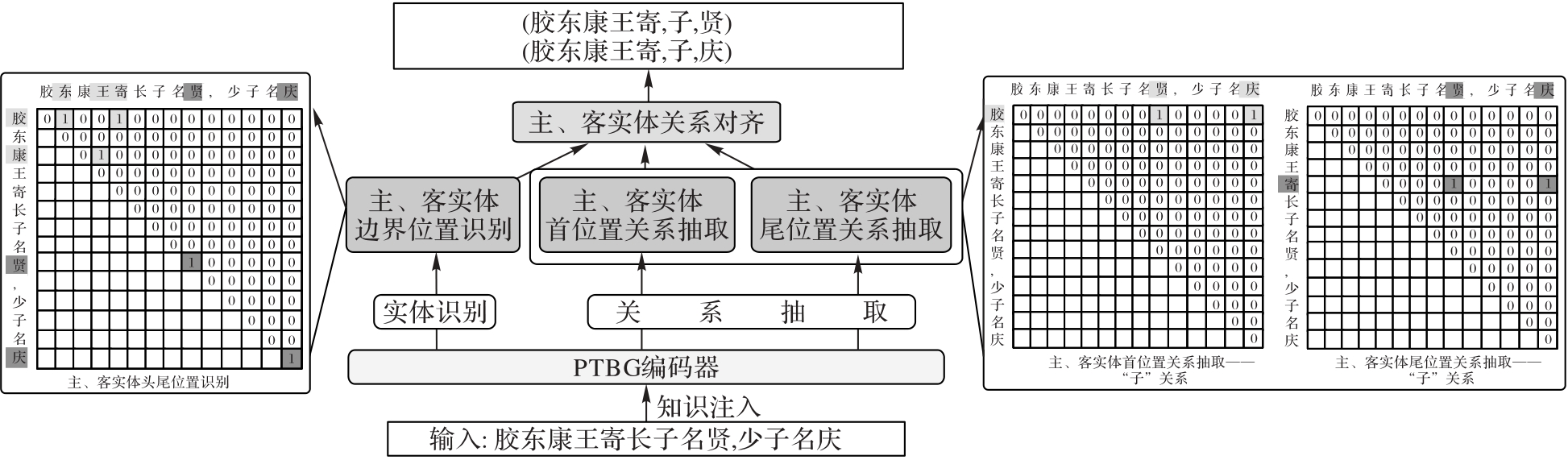
图2 PTBG模型结构
Fig. 2 PTBG model structure

图3 PLM-KnowledgeInject算法流程
Fig. 3 Flowchart of PLM-KnowledgeInject algorithm
| 分类 | 总字符数 | 实例句子数 | 三元组数 | ||||
|---|---|---|---|---|---|---|---|
| 总数 | 三元组数为1 | 三元组数大于1 | 总数 | 实体嵌套三元组 | 关系重叠三元组 | ||
| 训练集 | 100 630 | 777 | 289 | 488 | 1 828 | 490 | 245 |
| 验证集 | 12 817 | 102 | 37 | 65 | 229 | 136 | 115 |
| 测试集 | 13 162 | 95 | 33 | 62 | 233 | 63 | 28 |
表3 实验数据
Tab. 3 Experimental data
| 分类 | 总字符数 | 实例句子数 | 三元组数 | ||||
|---|---|---|---|---|---|---|---|
| 总数 | 三元组数为1 | 三元组数大于1 | 总数 | 实体嵌套三元组 | 关系重叠三元组 | ||
| 训练集 | 100 630 | 777 | 289 | 488 | 1 828 | 490 | 245 |
| 验证集 | 12 817 | 102 | 37 | 65 | 229 | 136 | 115 |
| 测试集 | 13 162 | 95 | 33 | 62 | 233 | 63 | 28 |
| 主实体类型 | 关系类型 | 客实体类型 |
|---|---|---|
| 人物 | 名 | 人物 |
| 国家 | 作战 | 国家 |
| 人物 | 杀 | 人物 |
| 人物 | 去往 | 国家 |
| 人物 | 去往 | 地点 |
| 人物 | 朋友 | 人物 |
| 国家 | 讨伐 | 国家 |
| 国家 | 杀 | 国家 |
| 人物 | 作战 | 人物 |
| 人物 | 任职 | 职位 |
表4 部分关系三元组模式
Tab. 4 Partial relation triple schema patterns
| 主实体类型 | 关系类型 | 客实体类型 |
|---|---|---|
| 人物 | 名 | 人物 |
| 国家 | 作战 | 国家 |
| 人物 | 杀 | 人物 |
| 人物 | 去往 | 国家 |
| 人物 | 去往 | 地点 |
| 人物 | 朋友 | 人物 |
| 国家 | 讨伐 | 国家 |
| 国家 | 杀 | 国家 |
| 人物 | 作战 | 人物 |
| 人物 | 任职 | 职位 |
| 实验环境 | 配置 |
|---|---|
| 操作系统 | Ubuntu 20.04.6 |
| CPU | Intel Xeon Silver 4314 CPU @ 2.40 GHz |
| GPU | GeForce RTX 3090Ti×4 |
| 内存 | 128 GB |
| 编程语言 | Python 3.8.17 |
| 深度学习框架 | PyTorch 1.12.1 + Transformers 4.34.0 |
表5 实验环境
Tab. 5 Experimental environment
| 实验环境 | 配置 |
|---|---|
| 操作系统 | Ubuntu 20.04.6 |
| CPU | Intel Xeon Silver 4314 CPU @ 2.40 GHz |
| GPU | GeForce RTX 3090Ti×4 |
| 内存 | 128 GB |
| 编程语言 | Python 3.8.17 |
| 深度学习框架 | PyTorch 1.12.1 + Transformers 4.34.0 |
| 阶段 | 参数 | 设置 |
|---|---|---|
| 知识注入 | Epoch | 20 |
| Learning Rate | 2×10-5 | |
| 实体关系联合抽取 | Batch Size | 8 |
| Max Sequence Length | 512 | |
| Learning Rate | 2×10-5 | |
| Optimizer | BertAdam | |
| Epoch | 100 |
表6 实验参数设置
Tab. 6 Experimental parameter setting
| 阶段 | 参数 | 设置 |
|---|---|---|
| 知识注入 | Epoch | 20 |
| Learning Rate | 2×10-5 | |
| 实体关系联合抽取 | Batch Size | 8 |
| Max Sequence Length | 512 | |
| Learning Rate | 2×10-5 | |
| Optimizer | BertAdam | |
| Epoch | 100 |
| 模型 | Cpm_RoBERTa | 注入领域事实知识后的Cpm_RoBERTa | ||||
|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | |
| CasRel | 33.44 | 30.30 | 31.79 | 33.75 | 32.21 | 32.96 |
| TPLinker | 34.75 | 33.20 | 33.96 | 34.70 | 34. 21 | 34.45 |
| OneRel | 36.26 | 34.16 | 35.18 | 38.52 | 37.15 | 37.82 |
| PTBG | 37.32 | 36.34 | 36.82 | 40.42 | 39.18 | 39.79 |
表7 不同模型的实验结果对比 ( %)
Tab. 7 Experimental result comparison of different models
| 模型 | Cpm_RoBERTa | 注入领域事实知识后的Cpm_RoBERTa | ||||
|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | |
| CasRel | 33.44 | 30.30 | 31.79 | 33.75 | 32.21 | 32.96 |
| TPLinker | 34.75 | 33.20 | 33.96 | 34.70 | 34. 21 | 34.45 |
| OneRel | 36.26 | 34.16 | 35.18 | 38.52 | 37.15 | 37.82 |
| PTBG | 37.32 | 36.34 | 36.82 | 40.42 | 39.18 | 39.79 |
| 模板序号 | 描述 | 形式 | 样例 |
|---|---|---|---|
| ① | 古文式的询问 | [主实体]之[关系]孰为? | 孝景皇帝之子孰为? |
| ② | 直接性的现代汉语模板 | [主实体]的[关系]? | 孝景皇帝的子? |
| ③ | 现代汉语模板 | [主实体]的[关系]是谁? | 孝景皇帝的子女是谁? |
| ④ | 明确实体类型的现代汉语模板 | [主实体]是[主实体类型],[主实体]的[关系]是谁? | 孝景皇帝是人名实体,孝景皇帝的子女是谁? |
表8 不同的提示模板
Tab. 8 Different prompt templates
| 模板序号 | 描述 | 形式 | 样例 |
|---|---|---|---|
| ① | 古文式的询问 | [主实体]之[关系]孰为? | 孝景皇帝之子孰为? |
| ② | 直接性的现代汉语模板 | [主实体]的[关系]? | 孝景皇帝的子? |
| ③ | 现代汉语模板 | [主实体]的[关系]是谁? | 孝景皇帝的子女是谁? |
| ④ | 明确实体类型的现代汉语模板 | [主实体]是[主实体类型],[主实体]的[关系]是谁? | 孝景皇帝是人名实体,孝景皇帝的子女是谁? |
| 属性 | GujiBERT_jian_fan | Cpm_RoBERTa |
|---|---|---|
| 参数量 | 1 126 97 856 | 325 522 432 |
| 隐藏层数 | 12 | 24 |
| 隐藏层维度 | 768 | 1 024 |
| 中间层大小 | 3 072 | 4 096 |
| 注意力头数 | 12 | 16 |
| 词汇表大小 | 34 709 | 21 128 |
表9 PLM属性详细信息
Tab. 9 PLM attribute details
| 属性 | GujiBERT_jian_fan | Cpm_RoBERTa |
|---|---|---|
| 参数量 | 1 126 97 856 | 325 522 432 |
| 隐藏层数 | 12 | 24 |
| 隐藏层维度 | 768 | 1 024 |
| 中间层大小 | 3 072 | 4 096 |
| 注意力头数 | 12 | 16 |
| 词汇表大小 | 34 709 | 21 128 |
| 模板 | GujiBERT_jian_fan | Cpm_RoBERTa | ||||
|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1 | 精确率 | 召回率 | F1 | |
| 未注入 | 26.85 | 29.74 | 28.22 | 37.32 | 36.34 | 36.82 |
| 模板① | 27.52 | 25.86 | 26.67 | 43.45 | 31.47 | 36.50 |
| 模板② | 30.73 | 28.88 | 29.78 | 38.12 | 36.64 | 37.36 |
| 模板③ | 32.72 | 30.60 | 31.63 | 39.22 | 38.44 | 38.82 |
| 模板④ | 33.18 | 31.47 | 32.30 | 40.42 | 39.18 | 39.79 |
表10 消融实验结果 ( %)
Tab. 10 Results of ablation experiments
| 模板 | GujiBERT_jian_fan | Cpm_RoBERTa | ||||
|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1 | 精确率 | 召回率 | F1 | |
| 未注入 | 26.85 | 29.74 | 28.22 | 37.32 | 36.34 | 36.82 |
| 模板① | 27.52 | 25.86 | 26.67 | 43.45 | 31.47 | 36.50 |
| 模板② | 30.73 | 28.88 | 29.78 | 38.12 | 36.64 | 37.36 |
| 模板③ | 32.72 | 30.60 | 31.63 | 39.22 | 38.44 | 38.82 |
| 模板④ | 33.18 | 31.47 | 32.30 | 40.42 | 39.18 | 39.79 |
| 1 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1(Long and Short Papers). Stroudsburg, PA: ACL, 2019: 4171-4186. |
| 2 | LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach [EB/OL]. [2023-12-08]. . |
| 3 | CHIU I P C, NICHOLS E. Named entity recognition with bidirectional LSTM-CNNs [J]. Transactions of the Association for Computational Linguistics, 2016, 4: 357-370. |
| 4 | ZHANG Y, YANG J. Chinese NER using lattice LSTM [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Volume 1 (Long Papers). Stroudsburg, PA: ACL, 2018: 1554-1564. |
| 5 | 左敏,薛明慧,张青川,等.面向互联网食品文本实体关系联合抽取研究[J].重庆邮电大学学报(自然科学版),2022,34(5):812-817. |
| ZUO M, XUE M H, ZHANG Q C, et al. Research on joint extraction of internet-oriented food text entity relationship[J]. Journal of Chongqing University of Posts & Telecommunications (Natural Science Edition),2022,34(5):812-817. | |
| 6 | SU J, MURTADHA A, PAN S, et al. Global Pointer: novel efficient span-based approach for named entity recognition [EB/OL]. [2023-10-07]. . |
| 7 | 孙玉轩.古汉语知识图谱的构建方法研究[D].大连:大连理工大学, 2020: 21-30. |
| SUN Y X. Research on the construction method of knowledge map in ancient Chinese [D]. Dalian: Dalian University of Technology, 2020: 21-30. | |
| 8 | 刘兴丽,范俊杰,马海群.面向小样本命名实体识别的数据增强算法改进策略研究[J].数据分析与知识发现, 2022, 6(10): 128-141. |
| LIU X L, FAN J J, MA H Q. Improvement of data augment algorithm for named entity recognition with small samples [J]. Data Analysis and Knowledge Discovery, 2022, 6(10): 128-141. | |
| 9 | WEI J, ZOU K. EDA: easy data augmentation techniques for boosting performance on text classification tasks [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2019: 6382-6388. |
| 10 | 程树文.基于深度学习的典籍人物关系触发词识别研究[D].南京:南京农业大学, 2020: 25-38. |
| CHENG S W. Research on recognition of trigger words in Chinese classics based on deep learning [D]. Nanjing: Nanjing Agricultural University, 2020: 25-38. | |
| 11 | 王永生,王昊,虞为,等.融合结构和内容的方志文本人物关系抽取方法[J].数据分析与知识发现, 2022, 6(Z1): 318-328. |
| WANG Y S, WANG H, YU W, et al. Extracting relationship among characters from local chronicles with text structures and contents [J]. Data Analysis and Knowledge Discovery, 2022, 6(Z1): 318-328. | |
| 12 | 彭博.基于ALBERT的网络文物信息资源实体关系抽取方法研究[J].情报杂志, 2022, 41(8): 156-162. |
| PENG B. Research on entity relationship extraction of cultural relic information resources with ALBERT [J]. Journal of Intelligence, 2022, 41(8): 156-162. | |
| 13 | WANG D, LIU C, ZHAO Z, et al. GujiBERT and GujiGPT: construction of intelligent information processing foundation language models for ancient texts [EB/OL]. [2024-01-08]. . |
| 14 | 温枫杰.基于深度学习的中华典籍人物关系研究[D].太原:中北大学, 2021: 17-21. |
| WEN F J. Deep learning based character relationship study of Chinese canonical texts [D]. Taiyuan: North University of China, 2021: 17-21. | |
| 15 | 唐雪梅,苏祺,王军.融合实体信息的古汉语关系分类研究[J].数据分析与知识发现, 2024, 8(1): 114-124. |
| TANG X M, SU Q, WANG J. Classifying ancient Chinese text relations with entity information [J]. Data Analysis and Knowledge Discovery, 2024, 8(1): 114-124. | |
| 16 | BROWN T, MANN B, RYDER N, et al. Language models are few-shot learners [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2020: 1877-1901. |
| 17 | LEVY O, SEO M, CHOI E, et al. Zero-shot relation extraction via reading comprehension [C]// Proceedings of the 21st Conference on Computational Natural Language Learning. Stroudsburg, PA: ACL, 2017: 333-342. |
| 18 | PETRONI F, ROCKTÄSCHEL T, RIEDEL S, et al. Language models as knowledge bases? [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2019: 2463-2473. |
| 19 | SHIN T, RAZEGHI Y, LOGAN R L, IV, et al. AutoPrompt: eliciting knowledge from language models with automatically generated prompts [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2020: 4222-4235. |
| 20 | CHEN X, ZHANG N, XIE X, et al. KnowPrompt: knowledge-aware prompt-tuning with synergistic optimization for relation extraction [C]// Proceedings of the ACM Web Conference 2022. New York: ACM, 2022: 2778-2788. |
| 21 | WEI Z, SU J, WANG Y, et al. A novel cascade binary tagging framework for relational triple extraction [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2020: 1476-1488. |
| 22 | WANG Y, YU B, ZHANG Y, et al. TPLinker: single-stage joint extraction of entities and relations through token pair linking [C]// Proceedings of the 28th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2020: 1572-1582. |
| 23 | SHANG Y M, HUANG H, MAO X L. OneRel: joint entity and relation extraction with one module in one step [C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2022: 11285-11293. |
| [1] | 吴相岚, 肖洋, 刘梦莹, 刘明铭. 基于语义增强模式链接的Text-to-SQL模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2689-2695. |
| [2] | 游新冬, 问英姿, 佘鑫鹏, 吕学强. 面向煤矿机电设备领域的三元组抽取方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2026-2033. |
| [3] | 沈君凤, 周星辰, 汤灿. 基于改进的提示学习方法的双通道情感分析模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1796-1806. |
| [4] | 魏超, 陈艳平, 王凯, 秦永彬, 黄瑞章. 基于掩码提示与门控记忆网络校准的关系抽取方法[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1713-1719. |
| [5] | 余新言, 曾诚, 王乾, 何鹏, 丁晓玉. 基于知识增强和提示学习的小样本新闻主题分类方法[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1767-1774. |
| [6] | 高颖杰, 林民, 斯日古楞null, 李斌, 张树钧. 基于片段抽取原型网络的古籍文本断句标点提示学习方法[J]. 《计算机应用》唯一官方网站, 2024, 44(12): 3815-3822. |
| [7] | 王炫力, 靳小龙, 侯中妮, 廖华明, 张瑾. 基于森林的实体关系联合抽取模型[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2700-2706. |
| [8] | 于碧辉, 蔡兴业, 魏靖烜. 基于提示学习的小样本文本分类方法[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2735-2740. |
| [9] | 黄梦林, 段磊, 张袁昊, 王培妍, 李仁昊. 基于Prompt学习的无监督关系抽取模型[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2010-2016. |
| [10] | 高永兵, 高军甜, 马蓉, 杨立东. 用户粒度级的个性化社交文本生成模型[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 1021-1028. |
| [11] | 许亮, 张春, 张宁, 田雪涛. 融合多Prompt模板的零样本关系抽取模型[J]. 《计算机应用》唯一官方网站, 2023, 43(12): 3668-3675. |
| [12] | 江静, 陈渝, 孙界平, 琚生根. 融合后验概率校准训练的文本分类算法[J]. 《计算机应用》唯一官方网站, 2022, 42(6): 1789-1795. |
| [13] | 张海丰, 曾诚, 潘列, 郝儒松, 温超东, 何鹏. 结合BERT和特征投影网络的新闻主题文本分类方法[J]. 《计算机应用》唯一官方网站, 2022, 42(4): 1116-1124. |
| [14] | 王小鹏, 孙媛媛, 林鸿飞. 基于刑事Electra的编-解码关系抽取模型[J]. 《计算机应用》唯一官方网站, 2022, 42(1): 87-93. |
| [15] | 李志超, 吐尔地·托合提, 艾斯卡尔·艾木都拉. 基于动态注意力和多角度匹配的答案选择模型[J]. 《计算机应用》唯一官方网站, 2021, 41(11): 3156-3163. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||