


《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (4): 1116-1124.DOI: 10.11772/j.issn.1001-9081.2021071257
所属专题: CCF第36届中国计算机应用大会 (CCF NCCA 2021)
• CCF第36届中国计算机应用大会 (CCF NCCA 2021) • 上一篇 下一篇
张海丰1, 曾诚1,2,3( ), 潘列1, 郝儒松1, 温超东1, 何鹏1,2,3
), 潘列1, 郝儒松1, 温超东1, 何鹏1,2,3
收稿日期:2021-07-16
修回日期:2021-11-11
接受日期:2021-11-17
发布日期:2022-04-15
出版日期:2022-04-10
通讯作者:
曾诚
作者简介:张海丰(1990—),男,湖北黄冈人,硕士研究生,主要研究方向:自然语言处理、文本分类基金资助:
Haifeng ZHANG1, Cheng ZENG1,2,3(), Lie PAN1, Rusong HAO1, Chaodong WEN1, Peng HE1,2,3
Received:2021-07-16
Revised:2021-11-11
Accepted:2021-11-17
Online:2022-04-15
Published:2022-04-10
Contact:
Cheng ZENG
About author:ZHANG Haifeng, born in 1990, M. S. candidate. His research interests include natural language processing, text classification.Supported by:摘要:
针对新闻主题文本用词缺乏规范、语义模糊、特征稀疏等问题,提出了结合BERT和特征投影网络(FPnet)的新闻主题文本分类方法。该方法包含两种实现方式:方式1将新闻主题文本在BERT模型的输出进行多层全连接层特征提取,并将最终提取到的文本特征结合特征投影方法进行提纯,从而强化分类效果;方式2在BERT模型内部的隐藏层中融合特征投影网络进行特征投影,从而通过隐藏层特征投影强化提纯分类特征。在今日头条、搜狐新闻、THUCNews-L、THUCNews-S数据集上进行实验,实验结果表明上述两种方式相较于基线BERT方法在准确率、宏平均F1值上均具有更好的表现,准确率最高分别为86.96%、86.17%、94.40%和93.73%,验证了所提方法的可行性和有效性。
中图分类号:
张海丰, 曾诚, 潘列, 郝儒松, 温超东, 何鹏. 结合BERT和特征投影网络的新闻主题文本分类方法[J]. 计算机应用, 2022, 42(4): 1116-1124.
Haifeng ZHANG, Cheng ZENG, Lie PAN, Rusong HAO, Chaodong WEN, Peng HE. News topic text classification method based on BERT and feature projection network[J]. Journal of Computer Applications, 2022, 42(4): 1116-1124.
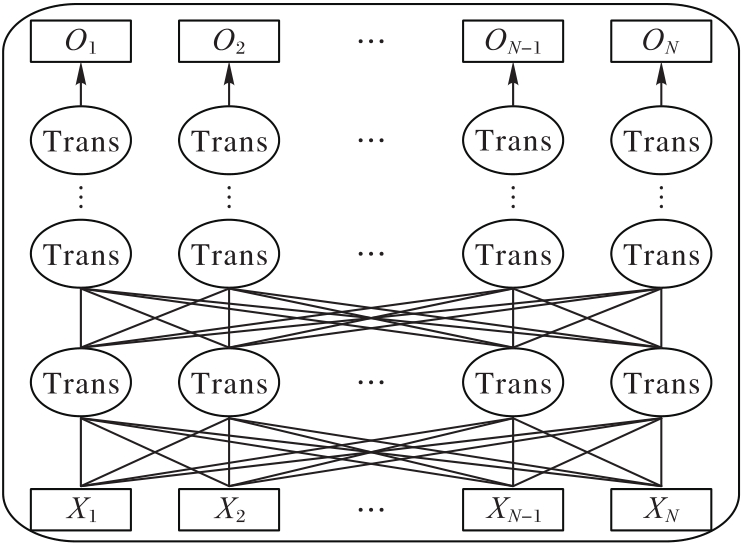
图1 BERT模型结构
Fig. 1 BERT model structure
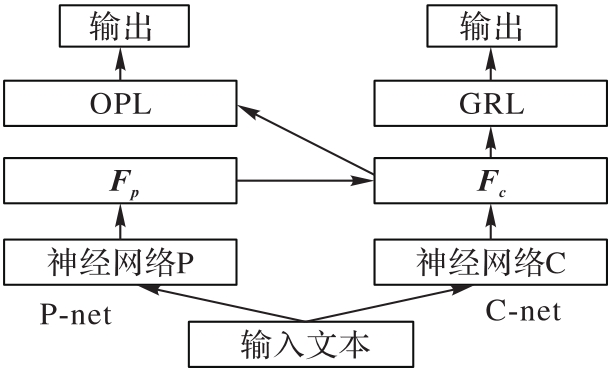
图2 特征投影网络的结构
Fig. 2 Structure of FPnet
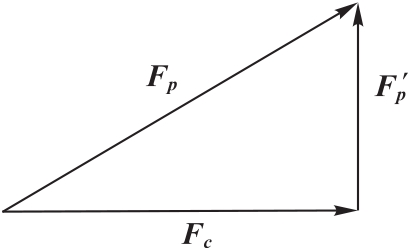
图3 特征投影
Fig. 3 Feature projection
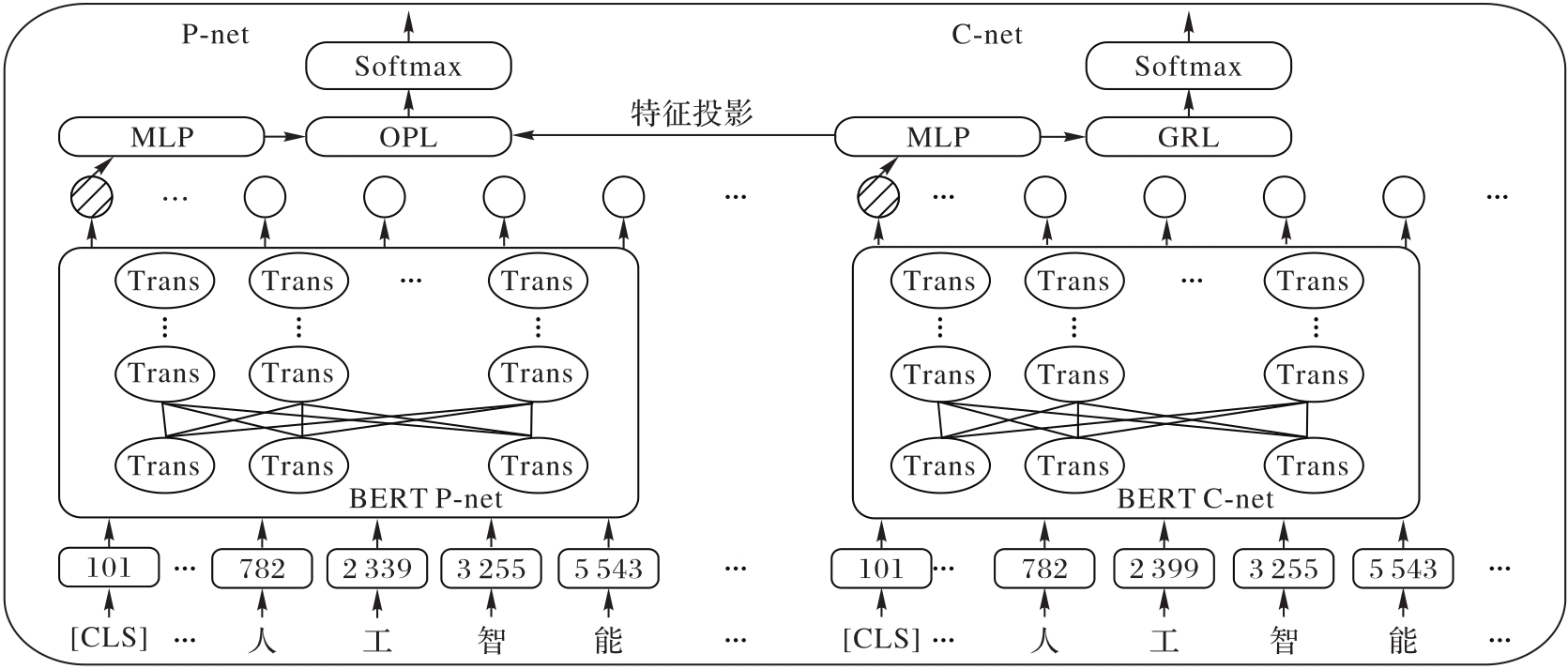
图4 BERT-FPnet模型框架
Fig. 4 BERT-FPnet model framework
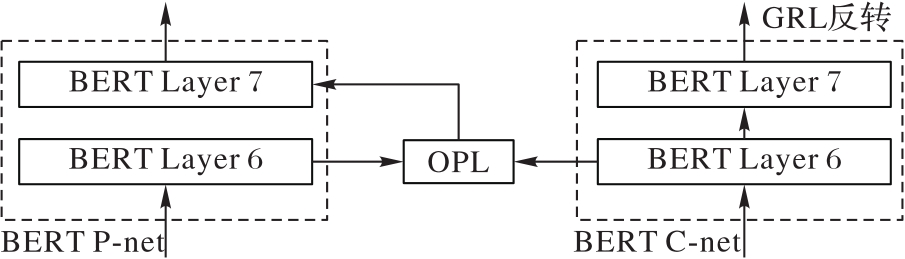
图5 BERT-FPnet-2隐藏层特征投影
Fig. 5 BERT-FPnet-2 hidden layer feature projection
| 名称 | 值 |
|---|---|
| CPU | Intel Xeon Gold 5218 |
| GPU | NVIDIA GeForce RTX5000-16G |
| 开发语言 | Python-3. 6 |
| 深度学习框架 | Pytorch-1.2.0 |
| 开发工具 | Pycharm-2020.1.3 |
表1 实验环境
Tab. 1 Experimental environment
| 名称 | 值 |
|---|---|
| CPU | Intel Xeon Gold 5218 |
| GPU | NVIDIA GeForce RTX5000-16G |
| 开发语言 | Python-3. 6 |
| 深度学习框架 | Pytorch-1.2.0 |
| 开发工具 | Pycharm-2020.1.3 |
| 数据集 | 类别 | 平均 长度 | 样本数 | |||
|---|---|---|---|---|---|---|
| 总数 | 训练集 | 验证集 | 测试集 | |||
| 今日头条 | 15 | 22 | 382 688 | 267 878 | 57 409 | 57 401 |
| 搜狐新闻 | 12 | 17 | 34 218 | 22 699 | 5 755 | 5 764 |
| THUCNews-L | 10 | 19 | 200 000 | 180 000 | 10 000 | 10 000 |
| THUCNews-S | 6 | 18 | 60 000 | 48 000 | 6 000 | 6 000 |
表2 数据集详情
Tab. 2 Dataset details
| 数据集 | 类别 | 平均 长度 | 样本数 | |||
|---|---|---|---|---|---|---|
| 总数 | 训练集 | 验证集 | 测试集 | |||
| 今日头条 | 15 | 22 | 382 688 | 267 878 | 57 409 | 57 401 |
| 搜狐新闻 | 12 | 17 | 34 218 | 22 699 | 5 755 | 5 764 |
| THUCNews-L | 10 | 19 | 200 000 | 180 000 | 10 000 | 10 000 |
| THUCNews-S | 6 | 18 | 60 000 | 48 000 | 6 000 | 6 000 |
| 名称 | 值 | 名称 | 值 |
|---|---|---|---|
| hidden_size | 768 | vocab_size | 21 128 |
| num_attention_heads | 12 | hidden_act | Gelu |
| num_hidden_layers | 12 |
表3 BERT模型主要参数
Tab. 3 Major parameters of BERT model
| 名称 | 值 | 名称 | 值 |
|---|---|---|---|
| hidden_size | 768 | vocab_size | 21 128 |
| num_attention_heads | 12 | hidden_act | Gelu |
| num_hidden_layers | 12 |
| 名称 | 值 | 名称 | 值 |
|---|---|---|---|
| optimizer | BertAdam | batchsize | 128 |
| warmup | 0.1 | λ | |
| learningrate | 5E-5 | Dropout | 0.5 |
| pad_size | 32 |
表4 BERT-FPnet模型超参数
Tab. 4 Hyperparameters of BERT-FPnet model
| 名称 | 值 | 名称 | 值 |
|---|---|---|---|
| optimizer | BertAdam | batchsize | 128 |
| warmup | 0.1 | λ | |
| learningrate | 5E-5 | Dropout | 0.5 |
| pad_size | 32 |
| 特征投影层 | 搜狐新闻 | ||
|---|---|---|---|
| Acc | M_F1 | ||
| 单层投影 | 3 | 0.824 3 | 0.823 2 |
| 6 | 0.845 9 | 0.846 6 | |
| 9 | 0.843 1 | 0.844 2 | |
| 12 | 0.861 7 | 0.862 7 | |
| 双层投影 | 3-MLP | 0.838 6 | 0.838 4 |
| 6-MLP | 0.852 5 | 0.853 1 | |
| 9-MLP | 0.840 0 | 0.842 9 | |
| 12-MLP | 0.858 9 | 0.860 4 | |
| 所有层投影 | ALL | 0.813 7 | 0.812 7 |
| 方 | BERT-FPnet-1 | 0.852 5 | 0.852 7 |
表5 搜狐新闻数据集上BERT-FPnet-2隐藏层特征投影实验结果
Tab. 5 Experimental results of BERT-FPnet-2 hidden layer feature projection on Sohu News dataset
| 特征投影层 | 搜狐新闻 | ||
|---|---|---|---|
| Acc | M_F1 | ||
| 单层投影 | 3 | 0.824 3 | 0.823 2 |
| 6 | 0.845 9 | 0.846 6 | |
| 9 | 0.843 1 | 0.844 2 | |
| 12 | 0.861 7 | 0.862 7 | |
| 双层投影 | 3-MLP | 0.838 6 | 0.838 4 |
| 6-MLP | 0.852 5 | 0.853 1 | |
| 9-MLP | 0.840 0 | 0.842 9 | |
| 12-MLP | 0.858 9 | 0.860 4 | |
| 所有层投影 | ALL | 0.813 7 | 0.812 7 |
| 方 | BERT-FPnet-1 | 0.852 5 | 0.852 7 |
| 特征投影层 | THUCNews-S | |
|---|---|---|
| Acc | M_F1 | |
| 12 | 0.936 2 | 0.936 0 |
| BERT-FPnet-1 | 0.937 3 | 0.937 2 |
表6 THUCNews-S数据集上BERT-FPnet的特征投影结果对比
Tab. 6 Comparison of BERT-FPnet feature projection results on THUCNews-S dataset
| 特征投影层 | THUCNews-S | |
|---|---|---|
| Acc | M_F1 | |
| 12 | 0.936 2 | 0.936 0 |
| BERT-FPnet-1 | 0.937 3 | 0.937 2 |
| 词嵌入 | 模型 | 今日头条 | 搜狐新闻 | THUCNews-L | THUCNews-S | ||||
|---|---|---|---|---|---|---|---|---|---|
| Acc | M_F1 | Acc | M_F1 | Acc | M_F1 | Acc | M_F1 | ||
Word2Vec | TextCNN | 0.832 1 | 0.767 8 | 0.832 0 | 0.833 3 | 0.910 5 | 0.910 7 | 0.900 8 | 0.900 5 |
| FastText | 0.839 3 | 0.773 3 | 0.823 6 | 0.823 6 | 0.920 8 | 0.920 9 | 0.898 2 | 0.898 3 | |
| Transformer | 0.793 9 | 0.733 7 | 0.781 6 | 0.781 4 | 0.897 3 | 0.897 1 | 0.884 5 | 0.884 3 | |
| DPCNN | 0.816 8 | 0.754 4 | 0.770 5 | 0.769 8 | 0.907 6 | 0.907 6 | 0.898 3 | 0.898 3 | |
| ALBERT | ALBERT-FC | 0.846 0 | 0.782 9 | 0.837 5 | 0.838 4 | 0.926 0 | 0.926 3 | 0.910 5 | 0.910 2 |
BERT | BERT-FC | 0.855 9 | 0.791 2 | 0.842 2 | 0.841 6 | 0.932 5 | 0.932 4 | 0.922 7 | 0.922 8 |
| BERT-CNN | 0.862 0 | 0.796 5 | 0.847 3 | 0.848 6 | 0.942 1 | 0.942 1 | 0.935 3 | 0.935 0 | |
| BERT-BIGRU | 0.862 4 | 0.798 1 | 0.845 9 | 0.847 2 | 0.935 2 | 0.935 2 | 0.926 2 | 0.926 2 | |
| BERT-FPnet-1 | 0.869 6 | 0.803 1 | 0.852 5 | 0.852 7 | 0.944 0 | 0.943 8 | 0.937 3 | 0.937 2 | |
| BERT-FPnet-2 | 0.868 0 | 0.801 1 | 0.861 7 | 0.862 7 | 0.941 0 | 0.942 3 | 0.936 2 | 0.936 0 | |
表7 各模型在不同数据集上的实验结果
Tab. 7 Experimental results of different models on different datasets
| 词嵌入 | 模型 | 今日头条 | 搜狐新闻 | THUCNews-L | THUCNews-S | ||||
|---|---|---|---|---|---|---|---|---|---|
| Acc | M_F1 | Acc | M_F1 | Acc | M_F1 | Acc | M_F1 | ||
Word2Vec | TextCNN | 0.832 1 | 0.767 8 | 0.832 0 | 0.833 3 | 0.910 5 | 0.910 7 | 0.900 8 | 0.900 5 |
| FastText | 0.839 3 | 0.773 3 | 0.823 6 | 0.823 6 | 0.920 8 | 0.920 9 | 0.898 2 | 0.898 3 | |
| Transformer | 0.793 9 | 0.733 7 | 0.781 6 | 0.781 4 | 0.897 3 | 0.897 1 | 0.884 5 | 0.884 3 | |
| DPCNN | 0.816 8 | 0.754 4 | 0.770 5 | 0.769 8 | 0.907 6 | 0.907 6 | 0.898 3 | 0.898 3 | |
| ALBERT | ALBERT-FC | 0.846 0 | 0.782 9 | 0.837 5 | 0.838 4 | 0.926 0 | 0.926 3 | 0.910 5 | 0.910 2 |
BERT | BERT-FC | 0.855 9 | 0.791 2 | 0.842 2 | 0.841 6 | 0.932 5 | 0.932 4 | 0.922 7 | 0.922 8 |
| BERT-CNN | 0.862 0 | 0.796 5 | 0.847 3 | 0.848 6 | 0.942 1 | 0.942 1 | 0.935 3 | 0.935 0 | |
| BERT-BIGRU | 0.862 4 | 0.798 1 | 0.845 9 | 0.847 2 | 0.935 2 | 0.935 2 | 0.926 2 | 0.926 2 | |
| BERT-FPnet-1 | 0.869 6 | 0.803 1 | 0.852 5 | 0.852 7 | 0.944 0 | 0.943 8 | 0.937 3 | 0.937 2 | |
| BERT-FPnet-2 | 0.868 0 | 0.801 1 | 0.861 7 | 0.862 7 | 0.941 0 | 0.942 3 | 0.936 2 | 0.936 0 | |
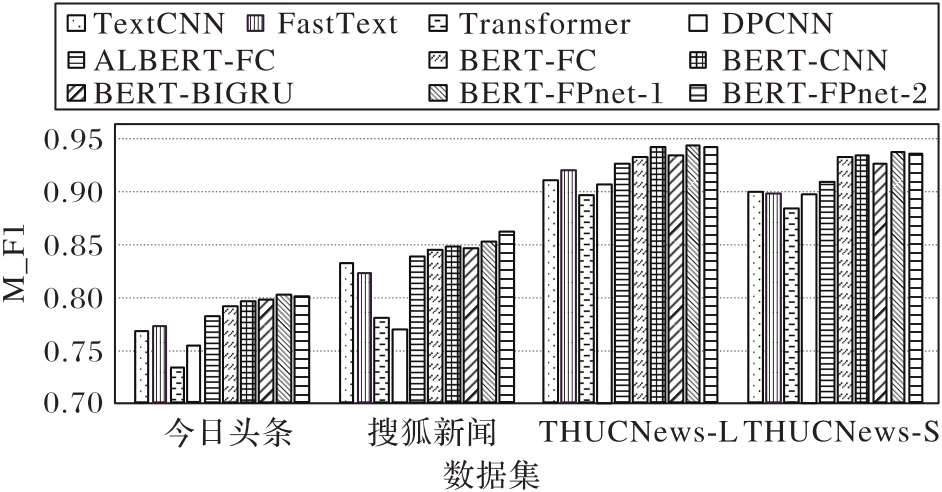
图6 各模型在不同数据集上的宏平均F1值
Fig. 6 M_F1 value of different models on different datasets
| 模型 | pad_size | THUCNews-S | |
|---|---|---|---|
| Acc | F1值 | ||
| BERT-FPnet-1 | 18 | 0.928 7 | 0.927 8 |
| 24 | 0.932 0 | 0.931 9 | |
| 32 | 0.937 3 | 0.937 2 | |
| 40 | 0.930 5 | 0.930 5 | |
| BERT-FPnet-2 | 18 | 0.931 6 | 0.930 7 |
| 24 | 0.935 7 | 0.934 6 | |
| 32 | 0.936 2 | 0.936 0 | |
| 40 | 0.936 2 | 0.936 1 | |
表8 各pad_size下本文模型在THUCNews-S数据集上的性能对比
Tab. 8 Perfomance comparison of proposed models under different pad_size on THUCNews-S dataset
| 模型 | pad_size | THUCNews-S | |
|---|---|---|---|
| Acc | F1值 | ||
| BERT-FPnet-1 | 18 | 0.928 7 | 0.927 8 |
| 24 | 0.932 0 | 0.931 9 | |
| 32 | 0.937 3 | 0.937 2 | |
| 40 | 0.930 5 | 0.930 5 | |
| BERT-FPnet-2 | 18 | 0.931 6 | 0.930 7 |
| 24 | 0.935 7 | 0.934 6 | |
| 32 | 0.936 2 | 0.936 0 | |
| 40 | 0.936 2 | 0.936 1 | |
| 模型 | λ | Acc | F1值 |
|---|---|---|---|
BERT- FPnet-1 | 1 | 0.934 3 | 0.934 6 |
| [0.25,0.5,0.75,1] | 0.937 3 | 0.937 4 | |
| [0.05, 0.1, 0.2, 0.4, 0.8, 1.0] | 0.937 3 | 0.937 2 | |
BERT- FPnet-2 | 1 | 0.936 2 | 0.936 0 |
| [0.25,0.5,0.75,1] | 0.933 3 | 0.933 5 | |
| [0.05, 0.1, 0.2, 0.4, 0.8, 1.0] | 0.936 2 | 0.936 0 |
表9 各λ下本文模型在THUCNews-S数据集上的性能对比
Tab. 9 Performance comparison of proposed models under different λ on THUCNews-S dataset
| 模型 | λ | Acc | F1值 |
|---|---|---|---|
BERT- FPnet-1 | 1 | 0.934 3 | 0.934 6 |
| [0.25,0.5,0.75,1] | 0.937 3 | 0.937 4 | |
| [0.05, 0.1, 0.2, 0.4, 0.8, 1.0] | 0.937 3 | 0.937 2 | |
BERT- FPnet-2 | 1 | 0.936 2 | 0.936 0 |
| [0.25,0.5,0.75,1] | 0.933 3 | 0.933 5 | |
| [0.05, 0.1, 0.2, 0.4, 0.8, 1.0] | 0.936 2 | 0.936 0 |
| 模型 | 双网络策略 | Acc | F1值 |
|---|---|---|---|
| BERT-FPnet-1 | 同步 | 0.937 3 | 0.937 2 |
| 异步 | 0.932 3 | 0.932 3 | |
| BERT-FPnet-2 | 同步 | 0.936 2 | 0.936 0 |
| 异步 | 0.935 3 | 0.935 4 |
表10 各优化策略下本文模型在THUCNews-S数据集上的性能对比
Tab. 10 Performance comparison of proposed models under different optimization strategies on THUCNews-S dataset
| 模型 | 双网络策略 | Acc | F1值 |
|---|---|---|---|
| BERT-FPnet-1 | 同步 | 0.937 3 | 0.937 2 |
| 异步 | 0.932 3 | 0.932 3 | |
| BERT-FPnet-2 | 同步 | 0.936 2 | 0.936 0 |
| 异步 | 0.935 3 | 0.935 4 |
| 1 | 许甜华,吴明礼. 一种基于TF-IDF的朴素贝叶斯算法改进[J]. 计算机技术与发展, 2020, 30(2):75-79. 10.3969/j.issn.1673-629X.2020.02.016 |
| XU T H, WU M L. An improved naive Bayes algorithm based on TF-IDF[J]. Computer Technology and Development, 2020, 30(2): 75-79. 10.3969/j.issn.1673-629X.2020.02.016 | |
| 2 | MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality[C]// Proceedings of the 26th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2013: 3111-3119. |
| 3 | MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space[EB/OL]. (2013-09-07) [2020-08-06].. 10.3126/jiee.v3i1.34327 |
| 4 | PENNINGTON J, SOCHER R, MANNING C D. GloVe: global vectors for word representation[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2014: 1532-1543. 10.3115/v1/d14-1162 |
| 5 | 李舟军,范宇,吴贤杰. 面向自然语言处理的预训练技术研究综述[J]. 计算机科学, 2020, 47(3):162-173. 10.11896/jsjkx.191000167 |
| LI Z J, FAN Y, WU X J. Survey of natural language processing pre-training techniques[J]. Computer Science, 2020, 47(3):162-173. 10.11896/jsjkx.191000167 | |
| 6 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2019: 4171-4186. 10.18653/v1/n19-1423 |
| 7 | KIM Y. Convolutional neural networks for sentence classification[C]// Proceedings of the 2014 Conference of Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2014: 1746-1751. 10.3115/v1/d14-1181 |
| 8 | ZHANG X, ZHAO J B, LeCUN Y. Character-level convolutional networks for text classification[C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2015: 649-657. 10.1109/icip.2015.7351229 |
| 9 | MIKOLOV T, KOMBRINK S, BURGET L, et al. Extensions of recurrent neural network language model[C]// Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2011: 5528-5531. 10.1109/icassp.2011.5947611 |
| 10 | SOCHER R, LIN C C Y, NG A Y, et al. Parsing natural scenes and natural language with recursive neural networks[C]// Proceedings of the 28th International Conference on Machine Learning. Madison, WI: Omnipress, 2011: 129-136. |
| 11 | 何力,郑灶贤,项凤涛,等. 基于深度学习的文本分类技术研究进展[J]. 计算机工程, 2021, 47(2):1-11. |
| HE L, ZHENG Z X, XIANG F T, et al. Research progress of text classification technology based on deep learning[J]. Computer Engineering, 2021, 47(2):1-11. | |
| 12 | LAI S W, XU L H, LIU K, et al. Recurrent convolutional neural networks for text classification[C]// Proceedings of the 29th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2015: 2267-2273. 10.1609/aaai.v33i01.33017370 |
| 13 | XIAO Y J, CHO K. Efficient character-level document classification by combining convolution and recurrent layers[EB/OL]. (2016-02-01) [2021-05-25].. |
| 14 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference of Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010. 10.1016/s0262-4079(17)32358-8 |
| 15 | ZHOU P, SHI W, TIAN J, et al. Attention-based bidirectional long short-term memory networks for relation classification[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2016:207-212. 10.18653/v1/p16-2034 |
| 16 | 杨春霞,李锐,秦家鹏. 一种粒度融合的新闻文本主题分类模型[J]. 小型微型计算机系统, 2020, 41(11):2256-2259. 10.3969/j.issn.1000-1220.2020.11.003 |
| YANG C X, LI R, QIN J P. Granular fusion news text topic classification model[J]. Journal of Chinese Computer Systems, 2020, 41(11):2256-2259. 10.3969/j.issn.1000-1220.2020.11.003 | |
| 17 | 付静,龚永罡,廉小亲,等. 基于BERT-LDA的新闻短文本分类方法[J]. 信息技术与信息化, 2021(2):127-129. 10.3969/j.issn.1672-9528.2021.02.044 |
| FU J, GONG Y G, LIAN X Q, et al. News short text classification method based on BERT-LDA[J]. Information Technology and Informatization, 2021(2):127-129. 10.3969/j.issn.1672-9528.2021.02.044 | |
| 18 | LAN Z Z, CHEN M D, GOODMAN S, et al. ALBERT: a lite BERT for self-supervised learning of language representations[EB/OL]. (2020-02-09) [2021-05-25].. |
| 19 | 温超东,曾诚,任俊伟,等. 结合ALBERT和双向门控循环单元的专利文本分类[J]. 计算机应用, 2021, 41(2):407-412. |
| WEN C D, ZENG C, REN J W, et al. Patent text classification combining ALBERT and bidirectional gated recurrent unit[J]. Journal of Computer Applications, 2021, 41(2):407-412. | |
| 20 | CHEN J A, YANG Z C, YANG D Y. MixText: linguistically-informed interpolation of hidden space for semi-supervised text classification[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2020:2147-2157. 10.18653/v1/2020.acl-main.194 |
| 21 | MENG Y, ZHANG Y Y, HUANG J X, et al. Text classification using label names only: a language model self-training approach[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for.Computational Linguistics, 2020:9006-9017. 10.18653/v1/2020.emnlp-main.724 |
| 22 | QIN Q, HU W P, LIU B. Feature projection for improved text classification[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2020: 8161-8171. 10.18653/v1/2020.acl-main.726 |
| 23 | GANIN Y, LEMPITSKY V. Unsupervised domain adaptation by backpropagation[C]// Proceedings of the 32nd International Conference on Machine Learning. New York: JMLR.org, 2015: 1180-1189. |
| 24 | GANIN Y, USTINOVA E, AJAKAN H, et al. Domain-adversarial training of neural networks[J]. Journal of Machine Learning Research, 2016, 17: 1-35. 10.1007/978-3-319-58347-1_10 |
| 25 | ZHANG K, ZHANG H F, LIU Q, et al. Interactive attention transfer network for cross-domain sentiment classification[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2019: 5773-5780. 10.1609/aaai.v33i01.33015773 |
| 26 | JAWAHAR G, SAGOT B, SEDDAH D. What does BERT learn about the structure of language?[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Stroudsburg, PA: Association for Computational Linguistics, 2019:3651-3657. 10.18653/v1/p19-1356 |
| 27 | JOULIN A, GRAVE E, BOJANOWSKI P, et al. Bag of tricks for efficient text classification[C]// Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics (Volume 2, Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2017: 427-431. 10.18653/v1/e17-2068 |
| 28 | JOHNSON R, ZHANG T. Deep pyramid convolutional neural networks for text categorization[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2017: 562-570. 10.18653/v1/p17-1052 |
| 29 | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 30 | 史振杰,董兆伟,庞超逸,等. 基于BERT-CNN的电商评论情感分析[J]. 智能计算机与应用, 2020, 10(2):7-11. 10.3969/j.issn.2095-2163.2020.02.002 |
| SHI Z J, DONG Z W, PANG C Y, et al. Sentiment analysis of e-commerce reviews based on BERT-CNN[J]. Intelligent Computer and Applications, 2020, 10(2):7-11. 10.3969/j.issn.2095-2163.2020.02.002 | |
| 31 | YU Q, WANG Z Y, JIANG K W. Research on text classification based on BERT-BiGRU model[J]. Journal of Physics: Conference Series, 2021, 1746: No.012019. 10.1088/1742-6596/1746/1/012019 |
| [1] | 吴相岚, 肖洋, 刘梦莹, 刘明铭. 基于语义增强模式链接的Text-to-SQL模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2689-2695. |
| [2] | 沈君凤, 周星辰, 汤灿. 基于改进的提示学习方法的双通道情感分析模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1796-1806. |
| [3] | 余新言, 曾诚, 王乾, 何鹏, 丁晓玉. 基于知识增强和提示学习的小样本新闻主题分类方法[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1767-1774. |
| [4] | 姚迅, 秦忠正, 杨捷. 生成式标签对抗的文本分类模型[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1781-1785. |
| [5] | 魏超, 陈艳平, 王凯, 秦永彬, 黄瑞章. 基于掩码提示与门控记忆网络校准的关系抽取方法[J]. 《计算机应用》唯一官方网站, 2024, 44(6): 1713-1719. |
| [6] | 余杭, 周艳玲, 翟梦鑫, 刘涵. 基于预训练模型与标签融合的文本分类[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 709-714. |
| [7] | 赖华, 孙童, 王文君, 余正涛, 高盛祥, 董凌. 多模态特征的越南语语音识别文本标点恢复[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 418-423. |
| [8] | 张家伟, 高冠东, 肖珂, 宋胜尊. 基于改进分层注意网络和TextCNN联合建模的暴力犯罪分级算法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 403-410. |
| [9] | 王楷天, 叶青, 程春雷. 基于异构图表示的中医电子病历分类方法[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 411-417. |
| [10] | 于碧辉, 蔡兴业, 魏靖烜. 基于提示学习的小样本文本分类方法[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2735-2740. |
| [11] | 崔雨萌, 王靖亚, 刘晓文, 闫尚义, 陶知众. 融合注意力和裁剪机制的通用文本分类模型[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2396-2405. |
| [12] | 拓雨欣, 薛涛. 融合指针网络与关系嵌入的三元组联合抽取模型[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2116-2124. |
| [13] | 黄梦林, 段磊, 张袁昊, 王培妍, 李仁昊. 基于Prompt学习的无监督关系抽取模型[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2010-2016. |
| [14] | 杨森淇, 段旭良, 肖展, 郎松松, 李志勇. 基于ERNIE+DPCNN+BiGRU的农业新闻文本分类[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1461-1466. |
| [15] | 张旭, 生龙, 张海芳, 田丰, 王巍. 基于标签混淆的院前急救文本分类模型[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 1050-1055. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||