《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (8): 2387-2392.DOI: 10.11772/j.issn.1001-9081.2023081209
薛凯鹏1,2, 徐涛1,2( ), 廖春节1,2
), 廖春节1,2
Kaipeng XUE1,2, Tao XU1,2(), Chunjie LIAO1,2
摘要:
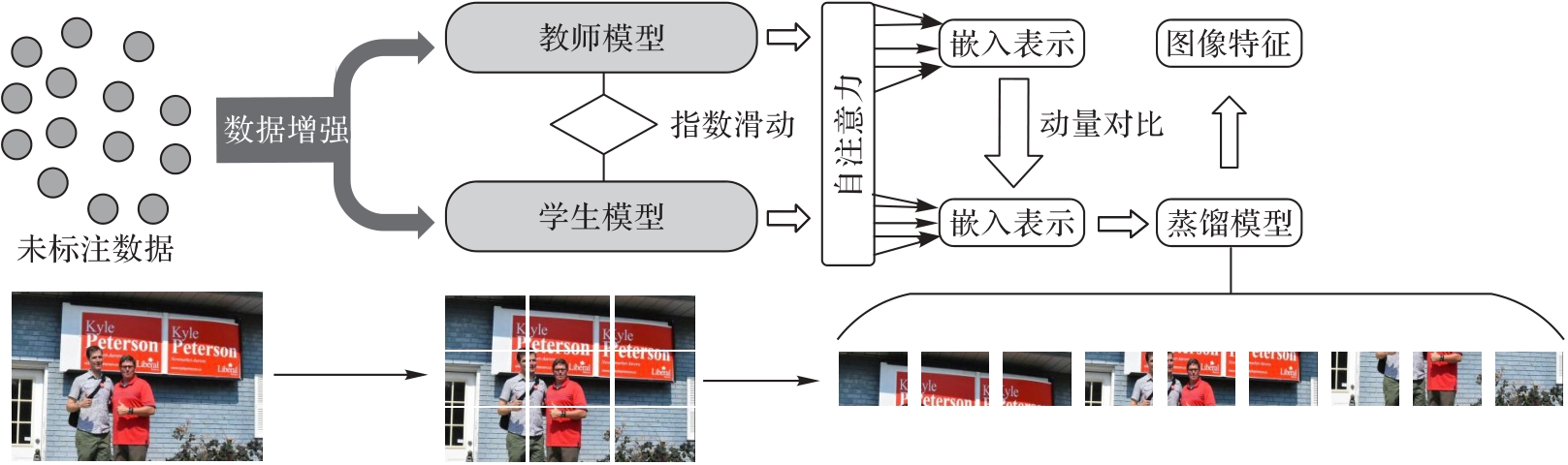
针对多模态情感分析任务中模态内信息不完整、模态间交互能力差和难以训练的问题,将视觉语言预训练(VLP)模型应用于多模态情感分析领域,提出一种融合自监督和多层交叉注意力的多模态情感分析网络(MSSM)。通过自监督学习强化视觉编码器模块,并加入多层交叉注意力以更好地建模文本和视觉特征,使模态内部信息更丰富完整,同时使模态间的信息交互更充分。此外,通过具有感知意识的快速、内存效率高的精确注意力FlashAttention解决Transformer中注意力计算高复杂度的问题。实验结果表明,与目前主流的基于对比文本-图像对的模型(CLIP)相比,MSSM在处理后的MVSA-S数据集上的准确率提高3.6个百分点,在MVSA-M数据集上的准确率提高2.2个百分点,验证所提网络能在降低运算成本的同时有效提高多模态信息融合的完整性。
中图分类号: