


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (7): 2175-2182.DOI: 10.11772/j.issn.1001-9081.2023070933
李大海, 王忠华( ), 王振东
), 王振东
收稿日期:2023-07-13
修回日期:2023-09-16
接受日期:2023-09-20
发布日期:2023-10-26
出版日期:2024-07-10
通讯作者:
王忠华
作者简介:李大海(1975—),男,山东乳山人,副教授,博士,CCF会员,主要研究方向:智能优化算法、深度学习;基金资助:
Dahai LI, Zhonghua WANG(), Zhendong WANG
Received:2023-07-13
Revised:2023-09-16
Accepted:2023-09-20
Online:2023-10-26
Published:2024-07-10
Contact:
Zhonghua WANG
About author:LI Dahai, born in 1975, Ph. D., associate professor. His research interests include intelligent optimization algorithms, deep learning.Supported by:摘要:
针对低光照图像增强中纹理细节模糊和颜色失真的问题,从空间域和频域信息结合的角度出发,提出一个端到端的轻量级双分支网络(SAFNet)。SAFNet使用基于Transformer的空间域处理模块和频域处理模块在空间域分支和频域分支分别对图像的空间域信息和傅里叶变换后的频域信息进行处理,并通过注意力机制引导两个分支的特征进行自适应融合,得到最终增强的图像。此外,针对频域信息提出一个频域损失函数作为联合损失函数的一部分,通过联合损失函数在空间域和频域都对SAFNet进行约束。在公开数据集LOL和LSRW上进行实验,在LOL上,SAFNet在客观指标结构相似性(SSIM)和学习感知图像块相似度(LPIPS)两项指标上分别达到0.823和0.114;在LSRW上,峰值信噪比(PSNR)和SSIM分别达到17.234 dB和0.550,均优于LLFormer (Low-Light Transformer)、IAT (Illumination Adaptive Transformer)、 KinD (Kindling the Darkness)++等主流方法,且网络参数量仅为0.07×106;在DarkFace数据集上,使用SAFNet作为预处理步骤对待检测图像进行增强,可以使人脸检测平均精确率从52.6%提升至72.5%。实验结果表明,SAFNet能有效提高低光照图像的质量,并能显著改善下游任务低光照人脸检测的性能。
中图分类号:
李大海, 王忠华, 王振东. 结合空间域和频域信息的双分支低光照图像增强网络[J]. 计算机应用, 2024, 44(7): 2175-2182.
Dahai LI, Zhonghua WANG, Zhendong WANG. Dual-branch low-light image enhancement network combining spatial and frequency domain information[J]. Journal of Computer Applications, 2024, 44(7): 2175-2182.
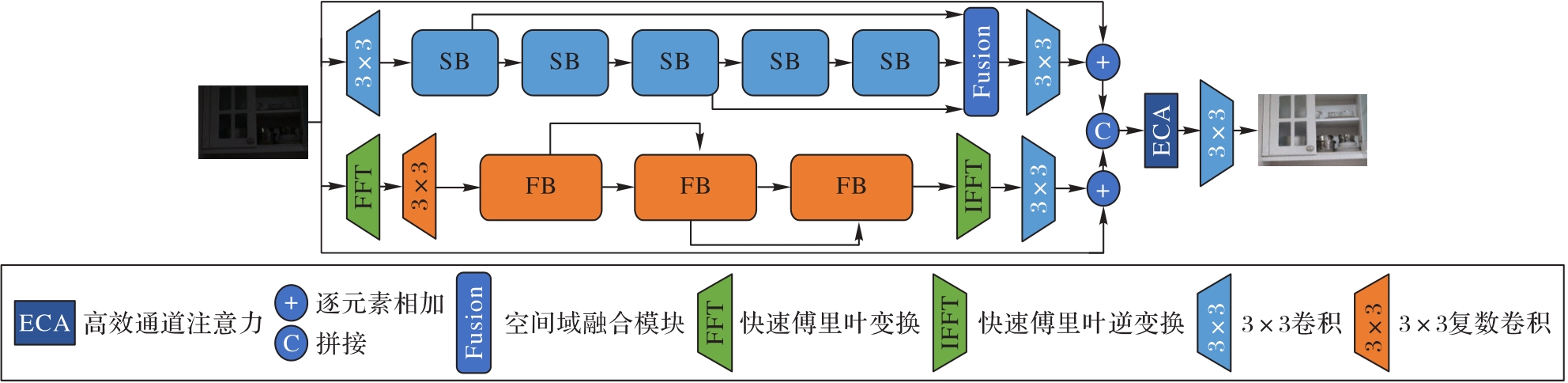
图1 SAFNet的总体框架
Fig. 1 Overall framework of SAFNet
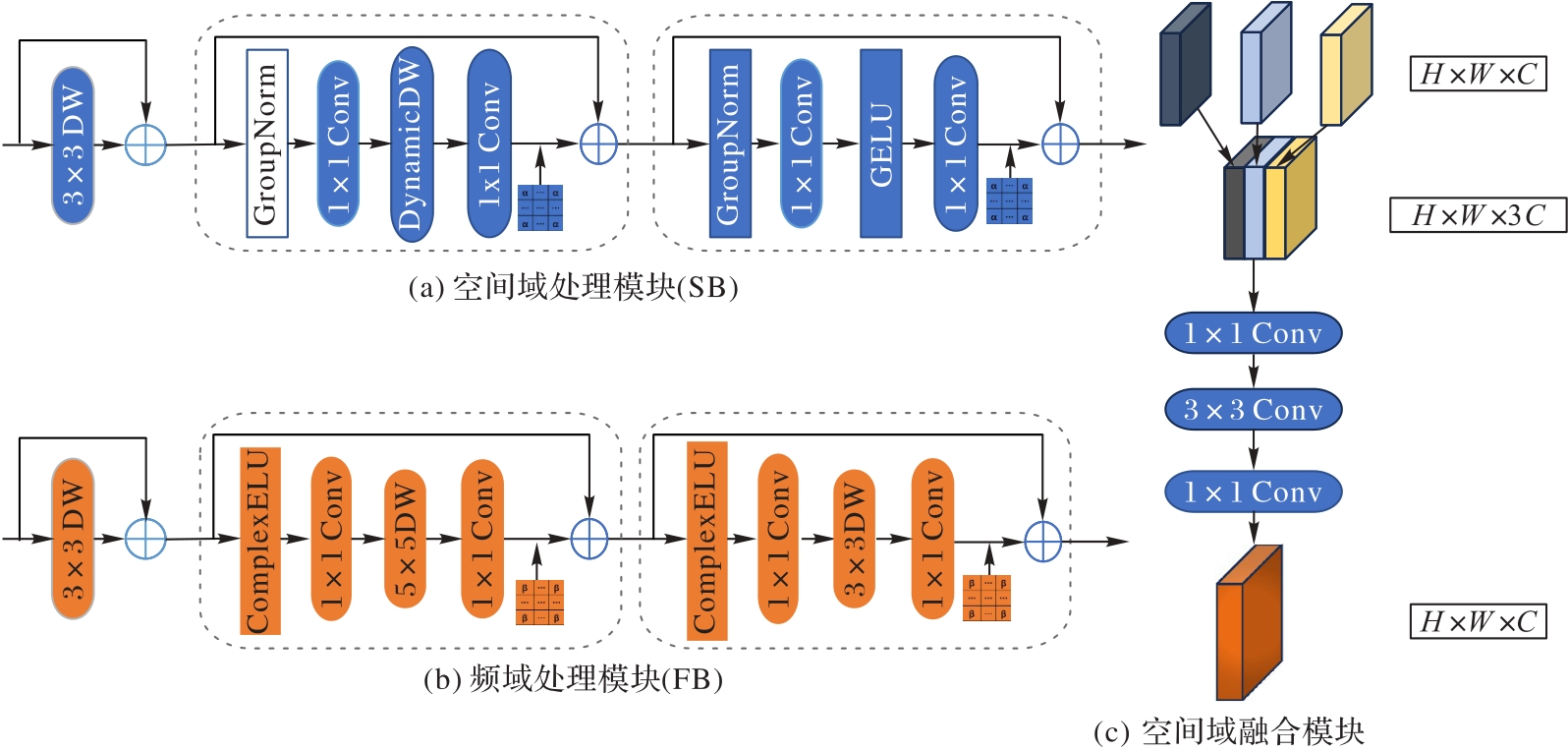
图2 空间域处理模块、频域处理模块和空间域融合模块的详细结构
Fig. 2 Detailed structures of spatial block, frequency block and fusion block
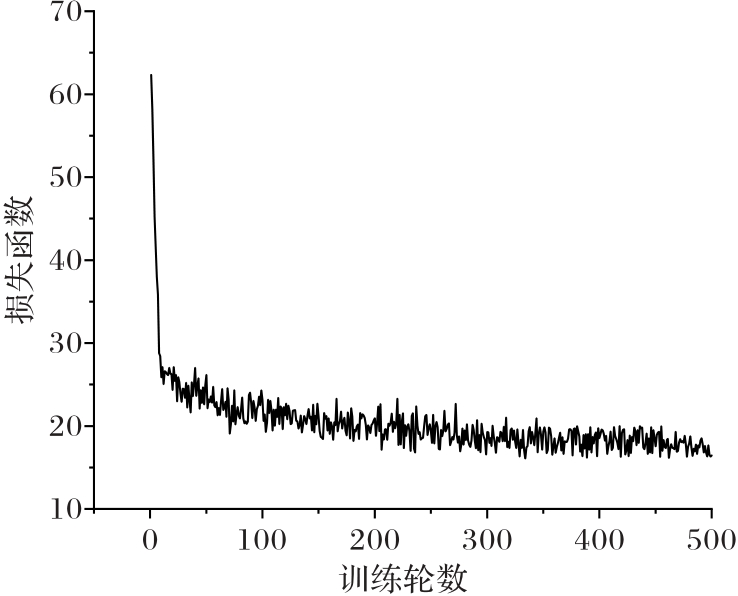
图3 损失函数收敛曲线
Fig. 3 Convergence curve of loss function
| 网络模型 | PSNR/dB | SSIM | LPIPS | 参数量/106 |
|---|---|---|---|---|
| Retinex-Net[ | 16.77 | 0.462 | 0.474 | 0.44 |
| Zero-DCE[ | 14.86 | 0.589 | 0.335 | 0.08 |
| DRBN[ | 15.13 | 0.472 | 0.316 | 0.58 |
| EnlightenGAN[ | 17.48 | 0.677 | 0.322 | 8.64 |
| KinD++[ | 20.86 | 0.760 | 0.164 | 8.27 |
| IAT[ | 23.38 | 0.809 | 0.261 | 0.09 |
| LLFormer[ | 23.64 | 0.816 | 0.169 | 24.52 |
| SAFNet | 22.11 | 0.823 | 0.114 | 0.07 |
表1 LOL数据集上不同网络模型的客观评价结果
Tab. 1 Objective evaluation results of different network models on LOL dataset
| 网络模型 | PSNR/dB | SSIM | LPIPS | 参数量/106 |
|---|---|---|---|---|
| Retinex-Net[ | 16.77 | 0.462 | 0.474 | 0.44 |
| Zero-DCE[ | 14.86 | 0.589 | 0.335 | 0.08 |
| DRBN[ | 15.13 | 0.472 | 0.316 | 0.58 |
| EnlightenGAN[ | 17.48 | 0.677 | 0.322 | 8.64 |
| KinD++[ | 20.86 | 0.760 | 0.164 | 8.27 |
| IAT[ | 23.38 | 0.809 | 0.261 | 0.09 |
| LLFormer[ | 23.64 | 0.816 | 0.169 | 24.52 |
| SAFNet | 22.11 | 0.823 | 0.114 | 0.07 |
| 网络模型 | PSNR/dB | SSIM |
|---|---|---|
| Retinex-Net[ | 15.90 | 0.373 |
| Zero-DCE[ | 15.83 | 0.466 |
| DRBN[ | 16.15 | 0.542 |
| EnlightenGAN[ | 16.31 | 0.469 |
| KinD++[ | 16.47 | 0.492 |
| IAT[ | 16.51 | 0.516 |
| LLFormer[ | 17.16 | 0.522 |
| SAFNet | 17.23 | 0.550 |
表2 LSRW数据集上不同网络模型的客观评价结果
Tab. 2 Objective evaluation results of different network models on LSRW dataset
| 网络模型 | PSNR/dB | SSIM |
|---|---|---|
| Retinex-Net[ | 15.90 | 0.373 |
| Zero-DCE[ | 15.83 | 0.466 |
| DRBN[ | 16.15 | 0.542 |
| EnlightenGAN[ | 16.31 | 0.469 |
| KinD++[ | 16.47 | 0.492 |
| IAT[ | 16.51 | 0.516 |
| LLFormer[ | 17.16 | 0.522 |
| SAFNet | 17.23 | 0.550 |

图4 在LOL数据集上不同网络模型的可视化对比
Fig. 4 Visual comparison of different network models on LOL dataset

图5 LSRW数据集上不同网络模型的可视化对比
Fig. 5 Visual comparison of different network models on LSRW dataset

图6 人脸检测结果
Fig. 6 Results of face detection
| 模型 | PSNR/dB | SSIM |
|---|---|---|
| w/o FB | 21.62 | 0.814 |
| w/o Fusion | 21.81 | 0.819 |
| w/o ECA | 21.76 | 0.816 |
| SAFNet | 22.11 | 0.823 |
表3 LOL数据集上不同模型结构的客观评价结果
Tab. 3 Objective evaluation results of different model structures on LOL dataset
| 模型 | PSNR/dB | SSIM |
|---|---|---|
| w/o FB | 21.62 | 0.814 |
| w/o Fusion | 21.81 | 0.819 |
| w/o ECA | 21.76 | 0.816 |
| SAFNet | 22.11 | 0.823 |

图7 LOL数据集上不同模型结构的可视化对比
Fig. 7 Visual comparison of different model structures on LOL dataset
| 损失函数 | PSNR/dB | SSIM |
|---|---|---|
| 20.16 | 0.809 | |
| 21.74 | 0.817 | |
| 21.97 | 0.819 | |
| 22.11 | 0.823 |
表4 LOL数据集上不同损失函数的客观评价结果
Tab. 4 Objective evaluation results of different loss functions on LOL dataset
| 损失函数 | PSNR/dB | SSIM |
|---|---|---|
| 20.16 | 0.809 | |
| 21.74 | 0.817 | |
| 21.97 | 0.819 | |
| 22.11 | 0.823 |

图8 LOL数据集上不同损失函数的可视化对比
Fig. 8 Visual comparison of different loss functions on LOL dataset
| 1 | LIU J, XU D, YANG W, et al. Benchmarking low-light image enhancement and beyond [J]. International Journal of Computer Vision, 2021, 129: 1153-1184. |
| 2 | ABDULLAH-AL-WADUD M, KABIR M H, DEWAN M A A, et al. A dynamic histogram equalization for image contrast enhancement [J]. IEEE Transactions on Consumer Electronics, 2007, 53(2): 593-600. |
| 3 | LAND E H. The Retinex theory of color vision [J]. Scientific American, 1977, 237(6): 108-129. |
| 4 | JOBSON D J, RAHMAN Z, WOODELL G A. A multiscale Retinex for bridging the gap between color images and the human observation of scenes [J]. IEEE Transactions on Image Processing, 1997, 6(7): 965-976. |
| 5 | LORE K G, AKINTAYO A, SARKAR S. LLNet: a deep autoencoder approach to natural low-light image enhancement [J]. Pattern Recognition, 2017, 61: 650-662. |
| 6 | WEI C, WANG W, YANG W, et al. Deep Retinex decomposition for low-light enhancement [EB/OL]. [2023-06-15]. . |
| 7 | WANG T, ZHANG K, SHEN T, et al. Ultra-high-definition low-light image enhancement: a benchmark and transformer-based method [J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2023, 37(3): 2654-2662. |
| 8 | CUI Z, LI K, GU L, et al. You only need 90K parameters to adapt light: a light weight transformer for image enhancement and exposure correction [C]// Proceedings of the 33rd Britich Machine Vision Conference. London: BMVA Press, 2022: No. 238. |
| 9 | XU Z-Q J, ZHANG Y, LUO T, et al. Frequency principle: Fourier analysis sheds light on deep neural networks [EB/OL]. [2023-05-13]. . |
| 10 | XU Z-Q J, ZHANG Y, XIAO Y. Training behavior of deep neural network in frequency domain [C]// Proceedings of the 26th International Conference on Neural Information Processing. Cham: Springer, 2019: 264-274. |
| 11 | WANG H, WU X, HUANG Z, et al. High-frequency component helps explain the generalization of convolutional neural networks [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 8681-8691. |
| 12 | ZHANG Y, ZHANG J, GUO X. Kindling the darkness: a practical low-light image enhancer [C]// Proceedings of the 27th ACM International Conference on Multimedia. New York: ACM, 2019: 1632-1640. |
| 13 | ZHANG Y, GUO X, MA J, et al. Beyond brightening low-light images [J]. International Journal of Computer Vision, 2021, 129: 1013-1037. |
| 14 | HAI J, XUAN Z, YANG R, et al. R2RNet: low-light image enhancement via real-low to real-normal network [J]. Journal of Visual Communication and Image Representation, 2023, 90: 103712. |
| 15 | 祖佳贞,周永霞,陈乐.结合注意力的双分支残差低光照图像增强[J].计算机应用, 2023, 43(4): 1240-1247. |
| ZU J Z, ZHOU Y X, CHEN L. Dual-branch residual low-light image enhancement combined with attention [J]. Journal of Computer Applications, 2023, 43(4): 1240-1247. | |
| 16 | 谌贵辉,林瑾瑜,李跃华,等.注意力机制下的多阶段低照度图像增强网络[J].计算机应用, 2023, 43(2): 552-559. |
| CHEN G H, LIN J Y, LI Y H, et al. Multi-stage low-illuminance image enhancement network based on attention mechanism [J]. Journal of Computer Applications, 2023, 43(2): 552-559. | |
| 17 | JIANG Y, GONG X, LIU D, et al. EnlightenGAN: deep light enhancement without paired supervision [J]. IEEE Transactions on Image Processing, 2021, 30: 2340-2349. |
| 18 | YANG W, WANG S, FANG Y, et al. From fidelity to perceptual quality: a semi-supervised approach for low-light image enhancement [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 3060-3069. |
| 19 | GUO C, LI C, GUO J, et al. Zero-reference deep curve estimation for low-light image enhancement [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 1777-1786. |
| 20 | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale [EB/OL]. [2023-04-10]. . |
| 21 | CAI M, ZHANG H, HUANG H, et al. Frequency domain image translation: more photo-realistic, better identity-preserving [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 13930-13940. |
| 22 | JIANG L, DAI B, WU W, et al. Focal frequency loss for image reconstruction and synthesis [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 13899-13909. |
| 23 | ZHONG Y, LI B, TANG L, et al. Detecting camouflaged object in frequency domain [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 4494-4503. |
| 24 | XU K, YANG X, YIN B, et al. Learning to restore low-light images via decomposition-and-enhancement [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 2281-2287. |
| 25 | WANG Q, WU B, ZHU P, et al. ECA-Net: efficient channel attention for deep convolutional neural networks [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 11531-11539. |
| 26 | HAN Q, FAN Z, DAI Q, et al. On the connection between local attention and dynamic depth-wise convolution [EB/OL]. [2023-07-10]. . |
| 27 | WU Y, HE K. Group normalization [C]// Proceedings of the 15th European Conference on Computer Vision. Cham: Springer, 2018: 3-19. |
| 28 | TOUVRON H, CORD M, SABLAYROLLES A, et al. Going deeper with image transformers [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 32-42. |
| 29 | TRABELSI C, BILANIUK O, ZHANG Y, et al. Deep complex networks [EB/OL]. [2023-04-10]. . |
| 30 | ZHAO H, GALLO O, FROSIO I, et al. Loss functions for image restoration with neural networks [J]. IEEE Transactions on Computational Imaging, 2016, 3(1): 47-57. |
| 31 | ZHANG R, ISOLA P, EFROS A A, et al. The unreasonable effectiveness of deep features as a perceptual metric [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 586-595. |
| 32 | YANG W, YUAN Y, REN W, et al. Advancing image understanding in poor visibility environments: a collective benchmark study [J]. IEEE Transactions on Image Processing, 2020, 29: 5737-5752. |
| 33 | LI J, WANG Y, WANG C, et al. DSFD: dual shot face detector [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 5055-5064. |
| [1] | 赵志强, 马培红, 黑新宏. 基于双重注意力机制的人群计数方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2886-2892. |
| [2] | 李金金, 桑国明, 张益嘉. APK-CNN和Transformer增强的多域虚假新闻检测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2674-2682. |
| [3] | 秦璟, 秦志光, 李发礼, 彭悦恒. 基于概率稀疏自注意力神经网络的重性抑郁疾患诊断[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2970-2974. |
| [4] | 方介泼, 陶重犇. 应对零日攻击的混合车联网入侵检测系统[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2763-2769. |
| [5] | 李力铤, 华蓓, 贺若舟, 徐况. 基于解耦注意力机制的多变量时序预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2732-2738. |
| [6] | 任烈弘, 黄铝文, 田旭, 段飞. 基于DFT的频率敏感双分支Transformer多变量长时间序列预测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2739-2746. |
| [7] | 贾洁茹, 杨建超, 张硕蕊, 闫涛, 陈斌. 基于自蒸馏视觉Transformer的无监督行人重识别[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2893-2902. |
| [8] | 黄云川, 江永全, 黄骏涛, 杨燕. 基于元图同构网络的分子毒性预测[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2964-2969. |
| [9] | 杨鑫, 陈雪妮, 吴春江, 周世杰. 结合变种残差模型和Transformer的城市公路短时交通流预测[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2947-2951. |
| [10] | 薛凯鹏, 徐涛, 廖春节. 融合自监督和多层交叉注意力的多模态情感分析网络[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2387-2392. |
| [11] | 汪雨晴, 朱广丽, 段文杰, 李书羽, 周若彤. 基于交互注意力机制的心理咨询文本情感分类模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2393-2399. |
| [12] | 高鹏淇, 黄鹤鸣, 樊永红. 融合坐标与多头注意力机制的交互语音情感识别[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2400-2406. |
| [13] | 丁宇伟, 石洪波, 李杰, 梁敏. 基于局部和全局特征解耦的图像去噪网络[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2571-2579. |
| [14] | 李钟华, 白云起, 王雪津, 黄雷雷, 林初俊, 廖诗宇. 基于图像增强的低照度人脸检测[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2588-2594. |
| [15] | 邓凯丽, 魏伟波, 潘振宽. 改进掩码自编码器的工业缺陷检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2595-2603. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||