


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (8): 2588-2594.DOI: 10.11772/j.issn.1001-9081.2023081198
李钟华, 白云起, 王雪津( ), 黄雷雷, 林初俊, 廖诗宇
), 黄雷雷, 林初俊, 廖诗宇
收稿日期:2023-09-06
修回日期:2023-10-18
接受日期:2023-11-03
发布日期:2024-08-22
出版日期:2024-08-10
通讯作者:
王雪津
作者简介:李钟华(1976—),男,福建南平人,副教授,博士,主要研究方向:人工智能、图像处理基金资助:
Zhonghua LI, Yunqi BAI, Xuejin WANG(), Leilei HUANG, Chujun LIN, Shiyu LIAO
Received:2023-09-06
Revised:2023-10-18
Accepted:2023-11-03
Online:2024-08-22
Published:2024-08-10
Contact:
Xuejin WANG
About author:LI Zhonghua, born in 1976, Ph. D., associate professor. His research interests include artificial intelligence, image processing.Supported by:摘要:
针对人脸检测模型在低照度环境下出现的检测性能明显降低这一问题,提出一种基于图像增强的低照度人脸检测方法。首先,采用图像增强方法对低照度图像预处理,以增强人脸的有效特征信息;其次,在模型主干网络后引入注意力机制,以提升网络对人脸区域的关注,并同时降低非均匀光照与噪声带来的负面影响;此外,引入注意力边界框损失函数WIoU(Wise Intersection over Union),以提升网络对低质量人脸的检测准确率;最后,使用更有效的特征融合模块代替模型原有结构。在低照度人脸数据集DARK FACE上的实验结果表明,所提方法的平均检测精度AP@0.5相较于原始YOLOv7模型提升了2.4个百分点,精度平均值AP@0.5:0.95提升了1.4个百分点,并且不引入额外参数与计算量。另外,在其他2个低照度人脸数据集上的结果也表明所提方法的有效性与鲁棒性,证明所提方法适用于不同场景下的低照度人脸检测。
中图分类号:
李钟华, 白云起, 王雪津, 黄雷雷, 林初俊, 廖诗宇. 基于图像增强的低照度人脸检测[J]. 计算机应用, 2024, 44(8): 2588-2594.
Zhonghua LI, Yunqi BAI, Xuejin WANG, Leilei HUANG, Chujun LIN, Shiyu LIAO. Low illumination face detection based on image enhancement[J]. Journal of Computer Applications, 2024, 44(8): 2588-2594.
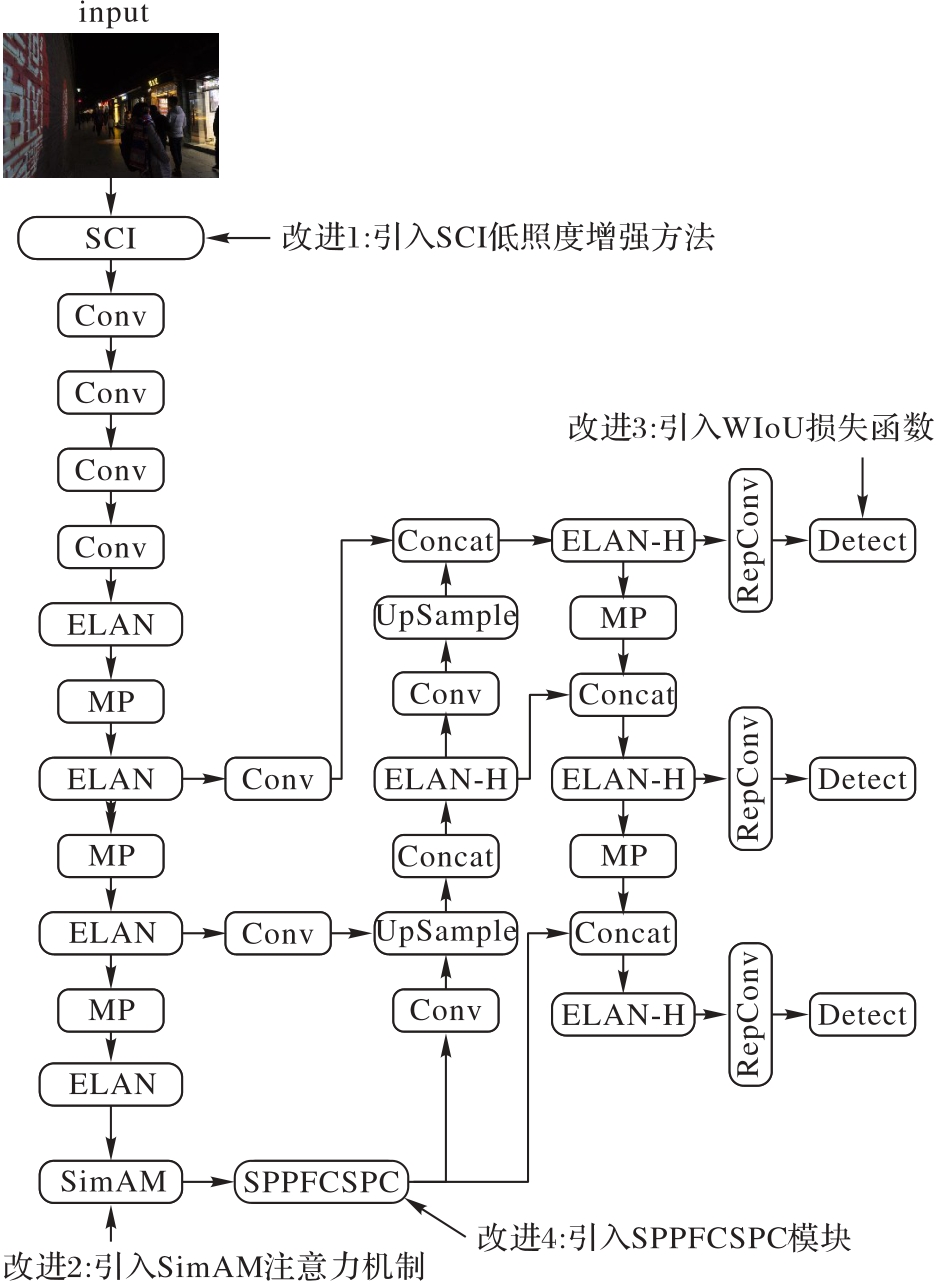
图1 改进方法的结构
Fig. 1 Structure of improved method

图2 不同增强方法的视觉对比
Fig. 2 Visual comparison of different enhancement methods
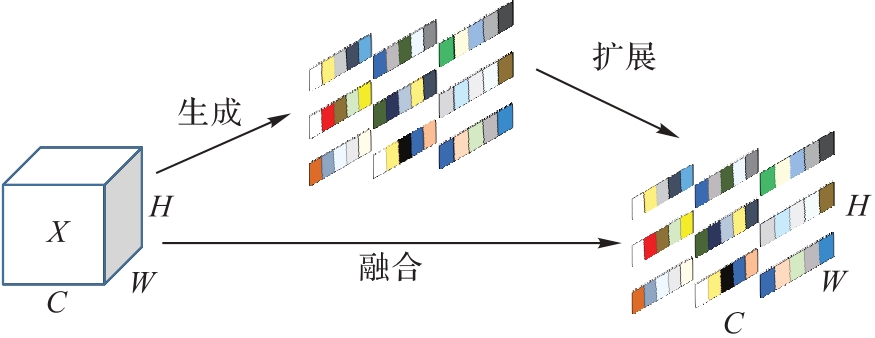
图3 SimAM注意力机制的原理
Fig. 3 Principles of SimAM attention mechanism
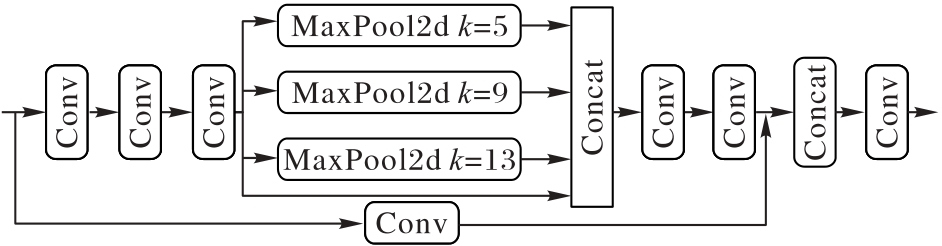
图4 SPPCSPC模块结构
Fig. 4 SPPCSPC module structure
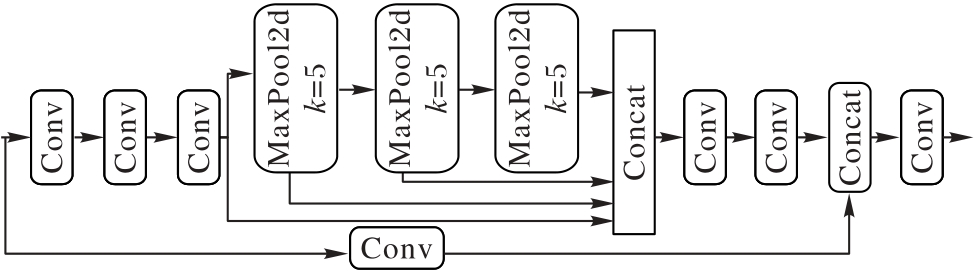
图5 SPPFCSPC模块结构
Fig. 5 SPPFCSPC module structure

图6 DARK FACE数据集示例
Fig. 6 Examples of ARK FACE dataset

图7 增强处理后的DARK FACE数据集示例
Fig. 7 Examples of enhanced DARK FACE dataset
| 组号 | SIMAM | WIOU | SCI | SPPFCSPC | 参数量/106 | GFLOPs | AP@0.5/% | AP@0.5:0.95/% |
|---|---|---|---|---|---|---|---|---|
| 1 | × | × | × | × | 37.2 | 105.1 | 70.2 | 32.3 |
| 2 | √ | × | × | × | 37.2 | 105.1 | 70.9 | 32.5 |
| 3 | √ | √ | × | × | 37.2 | 105.1 | 71.8 | 33.0 |
| 4 | √ | √ | √ | × | 37.2 | 105.1 | 72.3 | 33.5 |
| 5 | √ | √ | √ | √ | 37.2 | 105.1 | 72.6 | 33.7 |
表1 消融实验结果
Tab. 1 Results of ablation experiments
| 组号 | SIMAM | WIOU | SCI | SPPFCSPC | 参数量/106 | GFLOPs | AP@0.5/% | AP@0.5:0.95/% |
|---|---|---|---|---|---|---|---|---|
| 1 | × | × | × | × | 37.2 | 105.1 | 70.2 | 32.3 |
| 2 | √ | × | × | × | 37.2 | 105.1 | 70.9 | 32.5 |
| 3 | √ | √ | × | × | 37.2 | 105.1 | 71.8 | 33.0 |
| 4 | √ | √ | √ | × | 37.2 | 105.1 | 72.3 | 33.5 |
| 5 | √ | √ | √ | √ | 37.2 | 105.1 | 72.6 | 33.7 |
| 方法 | AP@0.5/% | AP@0.95/% |
|---|---|---|
| CIoU(原方法) | 71.9 | 33.0 |
| WIOUv1 | 71.7 | 33.5 |
| WIOUv2 | 72.4 | 33.6 |
| WIOUv3 | 72.6 | 33.7 |
表2 边界框损失函数的性能对比
Tab. 2 Performance comparison of bounding box loss functions
| 方法 | AP@0.5/% | AP@0.95/% |
|---|---|---|
| CIoU(原方法) | 71.9 | 33.0 |
| WIOUv1 | 71.7 | 33.5 |
| WIOUv2 | 72.4 | 33.6 |
| WIOUv3 | 72.6 | 33.7 |
| 增强方法 | FPS | AP@0.5/% | AP@0.5:0.95/% |
|---|---|---|---|
| 未使用增强方法 | 98 | 71.8 | 33.1 |
| LIME | 98 | 68.9 | 31.0 |
| MBLLEN | 92 | 68.7 | 31.4 |
| NIGHT-ENHANCEMENT | 93 | 52.7 | 22.2 |
| DRBN | 84 | 68.1 | 30.8 |
| EnlightenGAN | 87 | 70.1 | 32.0 |
| RUAS | 97 | 71.5 | 32.6 |
| Zero-DCE | 98 | 72.2 | 33.3 |
| SCI(本文方法) | 86 | 72.6 | 33.7 |
表3 不同增强方法的性能对比
Tab. 3 Performance comparison of different enhancement methods
| 增强方法 | FPS | AP@0.5/% | AP@0.5:0.95/% |
|---|---|---|---|
| 未使用增强方法 | 98 | 71.8 | 33.1 |
| LIME | 98 | 68.9 | 31.0 |
| MBLLEN | 92 | 68.7 | 31.4 |
| NIGHT-ENHANCEMENT | 93 | 52.7 | 22.2 |
| DRBN | 84 | 68.1 | 30.8 |
| EnlightenGAN | 87 | 70.1 | 32.0 |
| RUAS | 97 | 71.5 | 32.6 |
| Zero-DCE | 98 | 72.2 | 33.3 |
| SCI(本文方法) | 86 | 72.6 | 33.7 |
| 模型 | FPS | AP@0.5/% | AP@0.5:0.95/% |
|---|---|---|---|
| SSD300 | 40 | 11.6 | 6.3 |
| Faster R-CNN | 38 | 41.3 | 18.6 |
| ObjectBox [ | 70 | 53.6 | 21.7 |
| YOLO-Facev2l[ | 80 | 50.2 | 22.5 |
| YOLOv5l | 94 | 65.4 | 29.1 |
| YOLOv7 | 98 | 70.2 | 32.3 |
| YOLOv8l [ | 86 | 56.1 | 25.1 |
| 本文方法 | 86 | 72.6 | 33.7 |
表4 不同检测模型的性能对比
Tab. 4 Performance comparison of different detection models
| 模型 | FPS | AP@0.5/% | AP@0.5:0.95/% |
|---|---|---|---|
| SSD300 | 40 | 11.6 | 6.3 |
| Faster R-CNN | 38 | 41.3 | 18.6 |
| ObjectBox [ | 70 | 53.6 | 21.7 |
| YOLO-Facev2l[ | 80 | 50.2 | 22.5 |
| YOLOv5l | 94 | 65.4 | 29.1 |
| YOLOv7 | 98 | 70.2 | 32.3 |
| YOLOv8l [ | 86 | 56.1 | 25.1 |
| 本文方法 | 86 | 72.6 | 33.7 |
| 模型 | FPS | AP@0.5/% | AP@0.5:0.95/% |
|---|---|---|---|
| SSD300 | 35 | 12.8 | 8.7 |
| Faster R-CNN | 33 | 42.7 | 19.8 |
| ObjectBox | 60 | 56.2 | 22.7 |
| YOLO-Facev2l | 71 | 52.4 | 23.4 |
| YOLOv5l | 92 | 67.5 | 30.1 |
| YOLOv7 | 94 | 71.4 | 32.8 |
| YOLOv8 | 72 | 59.3 | 26.5 |
| 本文方法 | 86 | 72.6 | 33.7 |
表5 经过SCI预处理后的不同模型性能对比
Tab. 5 Performance comparison of different models after SCI preprocessing
| 模型 | FPS | AP@0.5/% | AP@0.5:0.95/% |
|---|---|---|---|
| SSD300 | 35 | 12.8 | 8.7 |
| Faster R-CNN | 33 | 42.7 | 19.8 |
| ObjectBox | 60 | 56.2 | 22.7 |
| YOLO-Facev2l | 71 | 52.4 | 23.4 |
| YOLOv5l | 92 | 67.5 | 30.1 |
| YOLOv7 | 94 | 71.4 | 32.8 |
| YOLOv8 | 72 | 59.3 | 26.5 |
| 本文方法 | 86 | 72.6 | 33.7 |

图8 检测结果的可视化分析
Fig. 8 Visual analysis of detection results
| 数据集 | 模型 | AP@0.5 | AP@0.5:0.95 |
|---|---|---|---|
| UFDD | SSD300 | 15.4 | 8.5 |
| Faster R-CNN | 30.7 | 9.4 | |
| ObjectBox | 20.2 | 5.1 | |
| YOLO-Facev2l | 42.7 | 11.2 | |
| YOLOv5l | 37.4 | 10.0 | |
| YOLOv7 | 42.6 | 11.2 | |
| YOLOv8l | 28.2 | 8.0 | |
| 本文方法 | 51.0 | 13.9 | |
| ExDark | SSD300 | 43.3 | 13.8 |
| Faster R-CNN | 47.9 | 14.7 | |
| ObjectBox | 28.8 | 8.1 | |
| YOLO-Facev2l | 43.3 | 13.8 | |
| YOLOv5l | 55.2 | 16.3 | |
| YOLOv7 | 54.3 | 16.2 | |
| YOLOv8l | 43.5 | 14.1 | |
| 本文方法 | 68.9 | 21.2 |
表6 UFDD和 ExDark数据集上不同模型的性能对比 (%)
Tab. 6 Performance comparison of different models on UFDD and ExDark datasets
| 数据集 | 模型 | AP@0.5 | AP@0.5:0.95 |
|---|---|---|---|
| UFDD | SSD300 | 15.4 | 8.5 |
| Faster R-CNN | 30.7 | 9.4 | |
| ObjectBox | 20.2 | 5.1 | |
| YOLO-Facev2l | 42.7 | 11.2 | |
| YOLOv5l | 37.4 | 10.0 | |
| YOLOv7 | 42.6 | 11.2 | |
| YOLOv8l | 28.2 | 8.0 | |
| 本文方法 | 51.0 | 13.9 | |
| ExDark | SSD300 | 43.3 | 13.8 |
| Faster R-CNN | 47.9 | 14.7 | |
| ObjectBox | 28.8 | 8.1 | |
| YOLO-Facev2l | 43.3 | 13.8 | |
| YOLOv5l | 55.2 | 16.3 | |
| YOLOv7 | 54.3 | 16.2 | |
| YOLOv8l | 43.5 | 14.1 | |
| 本文方法 | 68.9 | 21.2 |
| 1 | MINAEE S, LUO P, LIN Z, et al. Going deeper into face detection: a survey[EB/OL]. (2021-04-13) [2023-04-20].. |
| 2 | GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2014: 580-587. |
| 3 | GIRSHICK R. Fast R-CNN[C]// Proceedings of 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE 2015: 1440-1448. |
| 4 | REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2015: 91-99. |
| 5 | LIU W, ANHUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9905. Cham: Springer, 2016: 21-37. |
| 6 | REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. (2018-04-08) [2023-04-20].. |
| 7 | BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. (2020-04-23) [2023-04-20].. |
| 8 | GE Z, LIU S, WANG F, et al. YOLOx: exceeding YOLO series in 2021[EB/OL]. (2021-08-06) [2023-04-20].. |
| 9 | YANG S, LUO P, LOY C C, et al. WIDER FACE: a face detection benchmark[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 5525-5533. |
| 10 | JAIN V, LEARNED-MILLER E. FDDB: a benchmark for face detection in unconstrained settings[EB/OL]. [2023-04-20].. |
| 11 | WANG W, YANG W, LIU J. HLA-face: joint high-low adaptation for low light face detection[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 16190-16199. |
| 12 | YANG W, YUAN Y, REN W, et al. Advancing image understanding in poor visibility environments: a collective benchmark study[J]. IEEE Transactions on Image Processing, 2020, 29: 5737-5752. |
| 13 | 江泽涛,覃露露,秦嘉奇,等. 一种基于MDARNet的低照度图像增强方法[J]. 软件学报, 2021, 32(12): 3977-3991. |
| JIANG Z T, QIN L L, QIN J Q, et al. Low-light image enhancement method based on MDARNet[J]. Journal of Software, 2021, 32(12):3977-3991. | |
| 14 | 江泽涛,翟丰硕,钱艺,等. 结合特征增强和多尺度感受野的低照度目标检测[J]. 计算机研究与发展, 2023, 60(4): 903-915. |
| JIANG Z T, ZHAI F S, QIAN Y, et al. Low illumination object detection combined with feature enhancement and multi-scale receptive field[J]. Journal of Computer Research and Development, 2023, 60(4): 903-915. | |
| 15 | 黄淑英,胡威,杨勇,等. 基于渐进式双网络模型的低曝光图像增强方法[J]. 计算机学报, 2021, 44(2): 384-394. |
| HUANG S Y, HU W, YANG Y, et al. A low-exposure image enhancement based on progressive dual network model[J]. Chinese Journal of Computers, 2021, 44(2): 384-394. | |
| 16 | WANG W, WANG X, YANG W, et al. Unsupervised face detection in the dark[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(1): 1250-1266. |
| 17 | MA L, MA T, LIU R, et al. Toward fast, flexible, and robust low-light image enhancement[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 5627-5636. |
| 18 | YU J, HAO X, HE P. Single-stage face detection under extremely low-light conditions[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops. Piscataway: IEEE, 2021: 3516-3525. |
| 19 | LIANG J, WANG J, QUAN Y, et al. Recurrent exposure generation for low-light face detection[J]. IEEE Transactions on Multimedia, 2022, 24: 1609-1621. |
| 20 | 李可夫,钟汇才,高兴宇,等. 显著性引导的低光照人脸检测[J]. 北京航空航天大学学报, 2021, 47(3): 572-584. |
| LI K F, ZHONG H C, GAO X Y, et al. Saliency guided low-light face detection[J]. Journal of Beijing University of Aeronautics and Astronautics, 2021, 47(3): 572-584. | |
| 21 | WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 7464-7475. |
| 22 | Ultralytics. YOLOv5[EB/OL]. [2023-04-20].. |
| 23 | GUO X, LI Y, LING H. LIME: low-light image enhancement via illumination map estimation[J]. IEEE Transactions on Image Processing, 2017, 26(2): 982-993. |
| 24 | JIN Y, YANG W, TAN R T. Unsupervised night image enhancement: when layer decomposition meets light-effects suppression[C]// Proceedings of the 17th European Conference on Computer Vision. Cham: Springer, 2022: 404-421. |
| 25 | JIANG Y, GONG X, LIU D, et al. EnlightenGAN: deep light enhancement without paired supervision[J]. IEEE Transactions on Image Processing, 2021, 30: 2340-2349. |
| 26 | YANG W, WANG S, FANG Y, et al. From fidelity to perceptual quality: a semi-supervised approach for low-light image enhancement[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 3060-3069. |
| 27 | LIU R, MA L, ZHANG J, et al. Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 10556-10565. |
| 28 | LV F, LU F, WU J, et al. MBLLEN: low-light image/video enhancement using CNNs[C]// Proceedings of the 2018 British Machine Vision Conference. Durham: BMVA Press, 2018, 1-13. |
| 29 | GUO C, LI C, GUO J, et al. Zero-reference deep curve estimation for low-light image enhancement[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 1777-1786. |
| 30 | YANG L, ZHANG R Y, LI L, et al. SimAM: a simple, parameter-free attention module for convolutional neural networks[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 11863-11874. |
| 31 | ZHENG Z, WANG P, LIU W, et al. Distance-IoU loss: faster and better learning for bounding box regression [C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 12993-13000. |
| 32 | TONG Z, CHEN Y, XU Z, et al. Wise-IoU: bounding box regression loss with dynamic focusing mechanism[EB/OL]. (2023-04-08) [2023-04-20].. |
| 33 | NADA H, SINDAGI V A, ZHANG H, et al. Pushing the limits of unconstrained face detection: a challenge dataset and baseline results[C]// Proceedings of the IEEE 9th International Conference on Biometrics Theory, Applications and Systems. Piscataway: IEEE, 2018: 1-10. |
| 34 | LOH Y P, CHAN C S. Getting to know low-light images with the Exclusively Dark dataset[J]. Computer Vision and Image Understanding, 2019, 178: 30-42. |
| 35 | ZAND M, ETEMAD A, GREENSPAN M. ObjectBox: from centers to boxes for anchor-free object detection[C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13670. Cham: Springer, 2022: 390-406. |
| 36 | YU Z, HUANG H, CHEN W, et al. YOLO-Facev2: a scale and occlusion aware face detector[EB/OL]. (2022-08-04) [2023-04-20].. |
| 37 | Ultralytics. Ultralytics YOLOv8[EB/OL]. [2023-04-20].. |
| [1] | 赵志强, 马培红, 黑新宏. 基于双重注意力机制的人群计数方法[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2886-2892. |
| [2] | 秦璟, 秦志光, 李发礼, 彭悦恒. 基于概率稀疏自注意力神经网络的重性抑郁疾患诊断[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2970-2974. |
| [3] | 戎妍, 刘嘉雯, 李馨蕾. 面向学生课堂情感计算的自适应混合网络[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2919-2930. |
| [4] | 李力铤, 华蓓, 贺若舟, 徐况. 基于解耦注意力机制的多变量时序预测模型[J]. 《计算机应用》唯一官方网站, 2024, 44(9): 2732-2738. |
| [5] | 薛凯鹏, 徐涛, 廖春节. 融合自监督和多层交叉注意力的多模态情感分析网络[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2387-2392. |
| [6] | 汪雨晴, 朱广丽, 段文杰, 李书羽, 周若彤. 基于交互注意力机制的心理咨询文本情感分类模型[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2393-2399. |
| [7] | 高鹏淇, 黄鹤鸣, 樊永红. 融合坐标与多头注意力机制的交互语音情感识别[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2400-2406. |
| [8] | 邓凯丽, 魏伟波, 潘振宽. 改进掩码自编码器的工业缺陷检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2595-2603. |
| [9] | 莫尚斌, 王文君, 董凌, 高盛祥, 余正涛. 基于多路信息聚合协同解码的单通道语音增强[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2611-2617. |
| [10] | 刘丽, 侯海金, 王安红, 张涛. 基于多尺度注意力的生成式信息隐藏算法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2102-2109. |
| [11] | 徐松, 张文博, 王一帆. 基于时空信息的轻量视频显著性目标检测网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2192-2199. |
| [12] | 李大海, 王忠华, 王振东. 结合空间域和频域信息的双分支低光照图像增强网络[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2175-2182. |
| [13] | 魏文亮, 王阳萍, 岳彪, 王安政, 张哲. 基于光照权重分配和注意力的红外与可见光图像融合深度学习模型[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2183-2191. |
| [14] | 孔哲, 李寒, 甘少伟, 孔明茹, 何冰涛, 郭子钰, 金督程, 邱兆文. 基于非对称多解码器和注意力模块的三维肾脏影像结构分割模型[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2216-2224. |
| [15] | 熊武, 曹从军, 宋雪芳, 邵云龙, 王旭升. 基于多尺度混合域注意力机制的笔迹鉴别方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2225-2232. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||