


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (8): 2537-2545.DOI: 10.11772/j.issn.1001-9081.2024071058
• 人工智能 • 上一篇
颜承志, 陈颖( ), 钟凯, 高寒
), 钟凯, 高寒
收稿日期:2024-07-29
修回日期:2024-09-29
接受日期:2024-10-08
发布日期:2024-11-19
出版日期:2025-08-10
通讯作者:
陈颖
作者简介:颜承志(2000—),男,湖南株洲人,硕士研究生,CCF会员,主要研究方向:计算机视觉、目标检测基金资助:
Chengzhi YAN, Ying CHEN(), Kai ZHONG, Han GAO
Received:2024-07-29
Revised:2024-09-29
Accepted:2024-10-08
Online:2024-11-19
Published:2025-08-10
Contact:
Ying CHEN
About author:YAN Chengzhi, born in 2000, M. S. candidate. His research interests include computer vision, object detection.Supported by:摘要:
在3D目标检测中小目标诸如行人和骑行者的检测精确度较低,这是自动驾驶感知系统中存在的挑战性问题。为了准确估计周围环境的状态从而提高行车安全,对Voxel R-CNN(Voxel Region-based Convolutional Neural Network)算法进行改进,提出一种基于多尺度网络与轴向注意力的3D目标检测算法。首先,在主干网络中构建多尺度网络和像素级融合模块(PFM)获取更丰富和精准的特征表示,从而增强算法在复杂场景下的鲁棒性和泛化能力;其次,设计适用于具有3D空间维度特征的轴向注意力,并将它应用于感兴趣区域(RoI)的多尺度池化特征,以在有效捕捉局部和全局特征的同时保留3D空间结构中的重要信息,从而提升算法的目标检测和分类的精度和效率;最后,将一种旋转解耦的交并比(RDIoU)方法纳入回归和分类分支,从而使网络学习更精确的边界框,并解决分类和回归之间的对齐问题。在KITTI公开数据集上的实验结果表明,所提算法对行人和骑行者的平均精度均值(mAP)分别达到了62.25%和79.36%,与基准算法Voxel R-CNN相比分别提高了4.02和3.15个百分点,显示出了改进算法在难感知目标检测上的有效性。
中图分类号:
颜承志, 陈颖, 钟凯, 高寒. 基于多尺度网络与轴向注意力的3D目标检测算法[J]. 计算机应用, 2025, 45(8): 2537-2545.
Chengzhi YAN, Ying CHEN, Kai ZHONG, Han GAO. 3D object detection algorithm based on multi-scale network and axial attention[J]. Journal of Computer Applications, 2025, 45(8): 2537-2545.
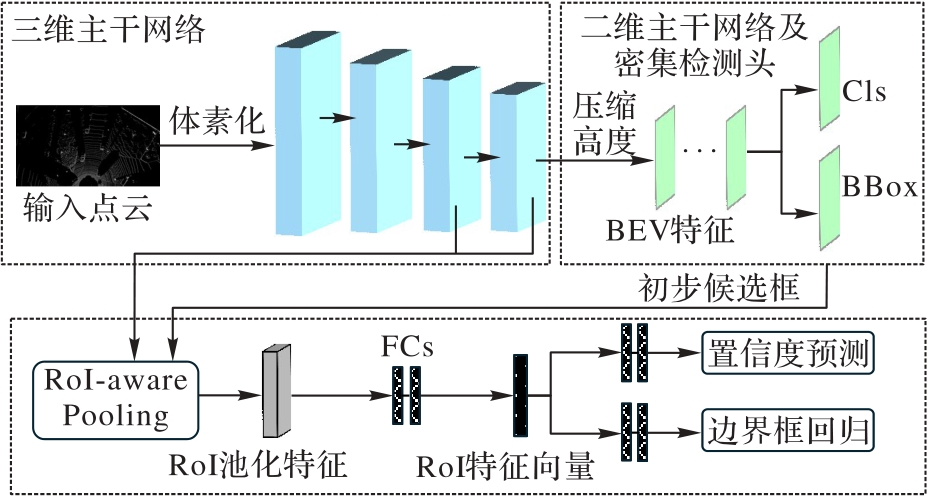
图1 Voxel R-CNN总体结构
Fig. 1 Overall structure of Voxel R-CNN
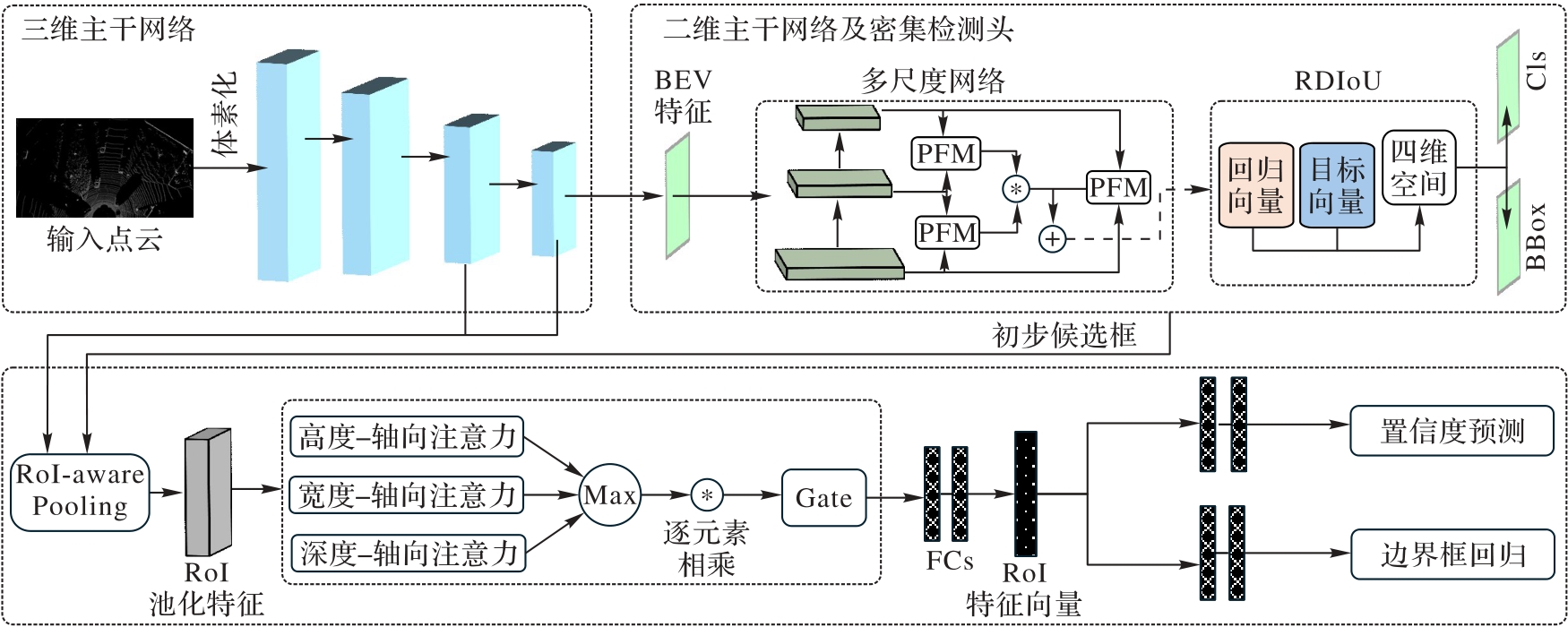
图2 本文算法的总体结构
Fig. 2 Overall structure of proposed algorithm
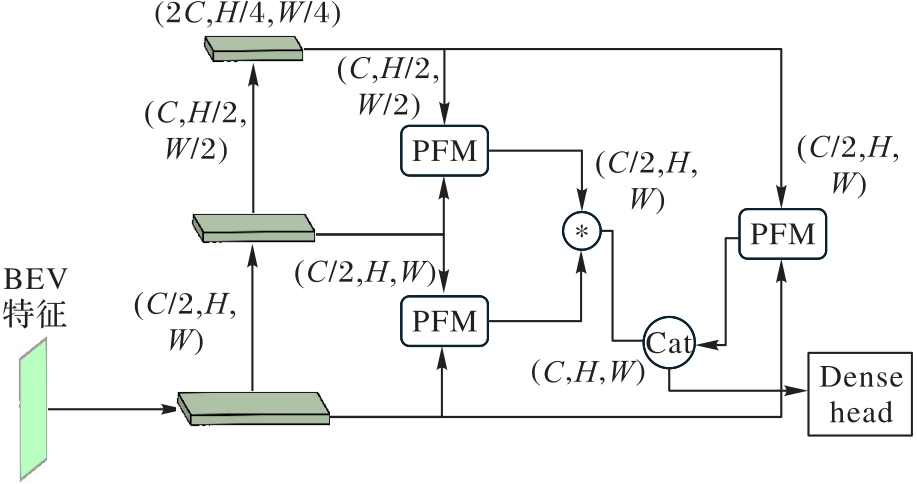
图3 多尺度网络结构
Fig. 3 Multi-scale network structure
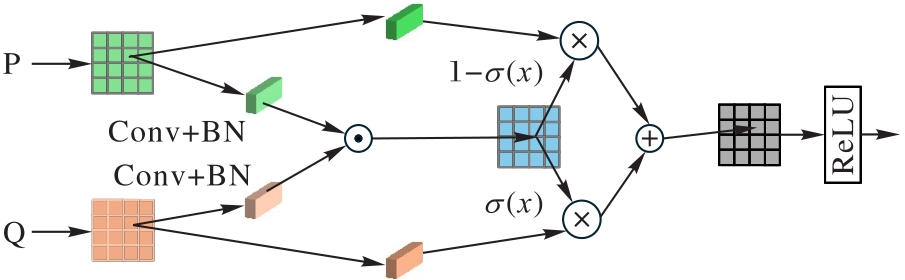
图4 特征融合模块PFM
Fig.4 Feature fusion module PFM
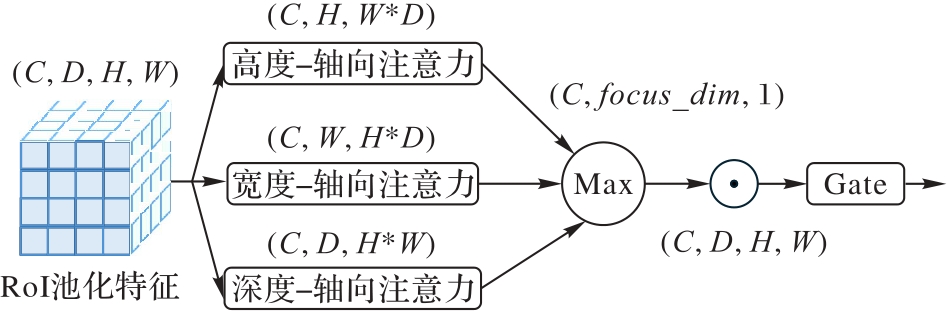
图5 轴向注意力模块
Fig. 5 Axial attention module
| 阶段 | 算法 | 推理 时间/ms | IoU=0.7时Car AP3D/% | IoU=0.5时Pedestrian AP3D/% | IoU=0.5时Cyclist AP3D/% | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | |||
单阶段 算法 | SECOND[ | 26.6 | 89.91 | 81.34 | 78.33 | 55.81 | 51.28 | 46.47 | 86.52 | 68.17 | 63.65 |
| PointPillars[ | 27.6 | 87.64 | 78.35 | 75.45 | 52.69 | 47.82 | 43.83 | 83.95 | 64.30 | 60.01 | |
| IA-SSD[ | 25.2 | 91.19 | 83.25 | 80.36 | 58.20 | 53.63 | 48.82 | 93.61 | 73.81 | 69.62 | |
| VoxelNeXt[ | 26.8 | 87.77 | 79.62 | 77.36 | 59.30 | 54.96 | 50.53 | 86.64 | 67.57 | 64.22 | |
| CoIn[ | 27.8 | 87.96 | 78.47 | 76.72 | 53.88 | 50.66 | 46.92 | 85.19 | 67.43 | 63.38 | |
两阶段 算法 | PointRCNN[ | 42.8 | 89.71 | 80.53 | 78.03 | 61.81 | 54.39 | 47.98 | 89.76 | 70.39 | 65.88 |
| PV-RCNN[ | 48.6 | 91.86 | 84.58 | 82.49 | 66.55 | 58.53 | 53.56 | 92.07 | 73.37 | 68.71 | |
| CT3D[ | 39.7 | 92.27 | 84.65 | 82.51 | 63.10 | 57.19 | 52.52 | 88.80 | 69.87 | 66.02 | |
| Part-A2[ | 34.9 | 91.76 | 82.57 | 81.95 | 66.63 | 58.39 | 53.96 | 86.16 | 70.72 | 67.37 | |
| Voxel R-CNN[ | 30.5 | 92.05 | 84.14 | 82.34 | 64.25 | 57.58 | 52.87 | 89.40 | 71.28 | 67.97 | |
| 3D Cascade RCNN[ | 35.5 | 92.64 | 84.71 | 82.62 | 66.97 | 58.43 | 54.21 | 92.43 | 73.47 | 69.51 | |
| DSVT-Voxel[ | 57.4 | 92.28 | 83.64 | 82.96 | 63.51 | 57.37 | 52.88 | 89.31 | 69.96 | 66.89 | |
| 本文算法 | 34.2 | 92.87 | 85.06 | 82.93 | 68.39 | 61.67 | 56.70 | 93.17 | 74.11 | 70.82 | |
表1 不同算法在KITTI验证集上的AP3D及推理时间对比
Tab. 1 Comparison of AP3D and inference time of different algorithms on KITTI validation set
| 阶段 | 算法 | 推理 时间/ms | IoU=0.7时Car AP3D/% | IoU=0.5时Pedestrian AP3D/% | IoU=0.5时Cyclist AP3D/% | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | |||
单阶段 算法 | SECOND[ | 26.6 | 89.91 | 81.34 | 78.33 | 55.81 | 51.28 | 46.47 | 86.52 | 68.17 | 63.65 |
| PointPillars[ | 27.6 | 87.64 | 78.35 | 75.45 | 52.69 | 47.82 | 43.83 | 83.95 | 64.30 | 60.01 | |
| IA-SSD[ | 25.2 | 91.19 | 83.25 | 80.36 | 58.20 | 53.63 | 48.82 | 93.61 | 73.81 | 69.62 | |
| VoxelNeXt[ | 26.8 | 87.77 | 79.62 | 77.36 | 59.30 | 54.96 | 50.53 | 86.64 | 67.57 | 64.22 | |
| CoIn[ | 27.8 | 87.96 | 78.47 | 76.72 | 53.88 | 50.66 | 46.92 | 85.19 | 67.43 | 63.38 | |
两阶段 算法 | PointRCNN[ | 42.8 | 89.71 | 80.53 | 78.03 | 61.81 | 54.39 | 47.98 | 89.76 | 70.39 | 65.88 |
| PV-RCNN[ | 48.6 | 91.86 | 84.58 | 82.49 | 66.55 | 58.53 | 53.56 | 92.07 | 73.37 | 68.71 | |
| CT3D[ | 39.7 | 92.27 | 84.65 | 82.51 | 63.10 | 57.19 | 52.52 | 88.80 | 69.87 | 66.02 | |
| Part-A2[ | 34.9 | 91.76 | 82.57 | 81.95 | 66.63 | 58.39 | 53.96 | 86.16 | 70.72 | 67.37 | |
| Voxel R-CNN[ | 30.5 | 92.05 | 84.14 | 82.34 | 64.25 | 57.58 | 52.87 | 89.40 | 71.28 | 67.97 | |
| 3D Cascade RCNN[ | 35.5 | 92.64 | 84.71 | 82.62 | 66.97 | 58.43 | 54.21 | 92.43 | 73.47 | 69.51 | |
| DSVT-Voxel[ | 57.4 | 92.28 | 83.64 | 82.96 | 63.51 | 57.37 | 52.88 | 89.31 | 69.96 | 66.89 | |
| 本文算法 | 34.2 | 92.87 | 85.06 | 82.93 | 68.39 | 61.67 | 56.70 | 93.17 | 74.11 | 70.82 | |
| 算法 | mAP3D | ||
|---|---|---|---|
| Car | Pedestrian | Cyclist | |
| 基准算法 | 86.17 | 58.23 | 76.21 |
| 基准+① | 86.69 | 61.93 | 78.32 |
| 基准+② | 86.58 | 59.68 | 77.90 |
| 基准+③ | 86.25 | 58.95 | 78.40 |
| 本文算法 | 86.95 | 62.25 | 79.36 |
表2 3D检测消融实验的结果 (%)
Tab. 2 Results of 3D detection ablation study
| 算法 | mAP3D | ||
|---|---|---|---|
| Car | Pedestrian | Cyclist | |
| 基准算法 | 86.17 | 58.23 | 76.21 |
| 基准+① | 86.69 | 61.93 | 78.32 |
| 基准+② | 86.58 | 59.68 | 77.90 |
| 基准+③ | 86.25 | 58.95 | 78.40 |
| 本文算法 | 86.95 | 62.25 | 79.36 |
| 算法 | mAPBEV | ||
|---|---|---|---|
| Car | Pedestrian | Cyclist | |
| 基准算法 | 91.65 | 62.63 | 79.97 |
| 基准+① | 92.39 | 64.63 | 81.34 |
| 基准+② | 92.32 | 62.74 | 80.12 |
| 基准+③ | 91.69 | 62.91 | 80.50 |
| 本文算法 | 92.57 | 64.90 | 81.58 |
表3 BEV检测消融实验结果 (%)
Tab. 3 Results of BEV detection ablation study
| 算法 | mAPBEV | ||
|---|---|---|---|
| Car | Pedestrian | Cyclist | |
| 基准算法 | 91.65 | 62.63 | 79.97 |
| 基准+① | 92.39 | 64.63 | 81.34 |
| 基准+② | 92.32 | 62.74 | 80.12 |
| 基准+③ | 91.69 | 62.91 | 80.50 |
| 本文算法 | 92.57 | 64.90 | 81.58 |

图6 复杂场景中的可视化结果
Fig. 6 Visualization results in complex scenarios
| [1] | MAO J, SHI S, WANG X, et al. 3D object detection for autonomous driving: a comprehensive survey[J]. International Journal of Computer Vision, 2023, 131(8): 1909-1963. |
| [2] | MOZAFFARI S, AL-JARRAH O Y, DIANATI M, et al. Deep learning-based vehicle behavior prediction for autonomous driving applications: a review[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(1): 33-47. |
| [3] | 秦静,王伟滨,邹启杰,等. 基于激光雷达点云的3D目标检测方法综述[J]. 计算机科学, 2023, 50(6A): No.220400214. |
| QIN J, WANG W B, ZOU Q J, et al. Review of 3D target detection methods based on LiDAR point clouds[J]. Computer Science, 2023, 50(6A): No.220400214. | |
| [4] | LI H, SIMA C, DAI J, et al. Delving into the devils of bird’s-eye-view perception: a review, evaluation and recipe[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(4): 2151-2170. |
| [5] | SHI S, WANG X, LI H. PointRCNN: 3D object proposal generation and detection from point cloud[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 770-779. |
| [6] | QI C R, YI L, SU H, et al. PointNet++: deep hierarchical feature learning on point sets in a metric space[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 5105-5114. |
| [7] | YANG Z, SUN Y, LIU S, et al. STD: sparse-to-dense 3D object detector for point cloud[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 1951-1960. |
| [8] | CHEN Y, LIU S, SHEN X, et al. Fast point R-CNN[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 9774-9783. |
| [9] | QI C R, SU H, MO K, et al. PointNet: deep learning on point sets for 3D classification and segmentation[C]// Proceedings of the 2017 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 77-85. |
| [10] | SHI S, GUO C, JIANG L, et al. PV-RCNN: point-voxel feature set abstraction for 3D object detection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10526-10535. |
| [11] | DENG J J, SHI S S, LI P W, et al. Voxel R-CNN: towards high performance voxel-based 3D object detection[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 1201-1209. |
| [12] | ZHOU Y, TUZEL O. VoxelNet: end-to-end learning for point cloud based 3D object detection[C]// Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 4490-4499. |
| [13] | SHENG H, CAI S, LIU Y, et al. Improving 3D object detection with channel-wise Transformer[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 2723-2732. |
| [14] | CAI Q, PAN Y, YAO T, et al. 3D Cascade RCNN: high quality object detection in point clouds[J]. IEEE Transactions on Image Processing, 2022, 31: 5706-5719. |
| [15] | WANG H, CHEN S, SHI S, et al. DSVT: dynamic sparse voxel Transformer with rotated sets[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 13520-13529. |
| [16] | 冯军. 基于注意力机制与多尺度残差网络结构的目标检测算法研究[D]. 郑州:河南大学, 2020. |
| FENG J. A research and application of Faster RCNN target detection algorithm based on attention mechanism[D]. Zhengzhou: Henan University, 2020. | |
| [17] | LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 936-944. |
| [18] | SHENG H, CAI S, ZHAO N, et al. Rethinking IoU-based optimization for single-stage 3D object detection [C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13669. Cham: Springer, 2022: 544-561. |
| [19] | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| [20] | SHI W, CABALLERO J, HUSZÁR F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1874-1883. |
| [21] | HO J, KALCHBRENNER N, WEISSENBORN D, et al. Axial attention in multidimensional Transformers[EB/OL]. [2024-09-25].. |
| [22] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [23] | RAMACHANDRAN P, ZOPH B, LE Q V. Searching for activation functions[EB/OL]. [2024-09-25].. |
| [24] | ZHENG Z, WANG P, LIU W, et al. Distance-IoU loss: faster and better learning for bounding box regression[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 12993-13000. |
| [25] | YAN Y, MAO Y, LI B. SECOND: sparsely embedded convolutional detection[J]. Sensors, 2018, 18(10): No.3337. |
| [26] | LANG A H, VORA S, CAESAR H, et al. PointPillars: fast encoders for object detection from point clouds[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 12689-12697. |
| [27] | ZHANG Y, HU Q, XU G, et al. Not all points are equal: learning highly efficient point-based detectors for 3D LiDAR point clouds[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 18931-18940. |
| [28] | CHEN Y, LIU J, ZHANG X, et al. VoxelNeXt: fully sparse VoxelNet for 3D object detection and tracking[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 21674-21683. |
| [29] | XIA Q, DENG J, WEN C, et al. CoIn: contrastive instance feature mining for outdoor 3D object detection with very limited annotations[C]// Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2023: 6231-6240. |
| [30] | SHI S, WANG Z, SHI J, et al. From points to parts: 3D object detection from point cloud with part-aware and part-aggregation network[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(8): 2647-2664. |
| [1] | 习怡萌, 邓箴, 刘倩, 刘立波. 跨模态信息融合的视频-文本检索[J]. 《计算机应用》唯一官方网站, 2025, 45(8): 2448-2456. |
| [2] | 陈亮, 王璇, 雷坤. 复杂场景下跨层多尺度特征融合的安全帽佩戴检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2333-2341. |
| [3] | 王向, 崔倩倩, 张晓明, 王建超, 王震洲, 宋佳霖. 改进ConvNeXt的无线胶囊内镜图像分类模型[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 2016-2024. |
| [4] | 周得辉, 赵军, 程进峰. 基于RT-DETR的轴承表面微小缺陷检测算法[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1987-1997. |
| [5] | 吴宗航, 张东, 李冠宇. 基于联合自监督学习的多模态融合推荐算法[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1858-1868. |
| [6] | 孙林嘉, 秦磊, 康美金, 王莹琳. 基于音节类型识别的自动语音分割算法[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 2034-2042. |
| [7] | 黄颖, 高胜美, 陈广, 刘苏. 结合信噪比引导的双分支结构和直方图均衡的低照度图像增强网络[J]. 《计算机应用》唯一官方网站, 2025, 45(6): 1971-1979. |
| [8] | 胡婕, 吴翠, 孙军, 张龑. 基于回指与逻辑推理的文档级关系抽取模型[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1496-1503. |
| [9] | 杨雅莉, 黎英, 章育涛, 宋佩华. 面向人脸识别的多模态研究方法综述[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1645-1657. |
| [10] | 周阳, 李辉. 基于语义和细节特征双促进的遥感影像建筑物提取网络[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1310-1316. |
| [11] | 郭诗月, 党建武, 王阳萍, 雍玖. 结合注意力机制和多尺度特征融合的三维手部姿态估计[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1293-1299. |
| [12] | 王一丁, 王泽浩, 李耀利, 蔡少青, 袁媛. 多尺度2D-Adaboost的中药材粉末显微图像识别算法[J]. 《计算机应用》唯一官方网站, 2025, 45(4): 1325-1332. |
| [13] | 王泉, 曹心雨, 陈祺东. 面向车路协同的路侧交通目标检测模型及部署[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 1016-1024. |
| [14] | 周浩, 王超, 崔国恒, 罗廷金. 基于多语义关联与融合的视觉问答模型[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 739-745. |
| [15] | 马汉达, 吴亚东. 多域时空层次图神经网络的空气质量预测[J]. 《计算机应用》唯一官方网站, 2025, 45(2): 444-452. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||