


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (7): 2101-2112.DOI: 10.11772/j.issn.1001-9081.2024070953
• CCF第39届中国计算机应用大会 (CCF NCCA 2024) • 上一篇 下一篇
何玉林1,2( ), 何芃1,2, 黄哲学1,2, 解为成2, PHILIPPE Fournier-Viger2
), 何芃1,2, 黄哲学1,2, 解为成2, PHILIPPE Fournier-Viger2
收稿日期:2024-07-09
修回日期:2024-09-26
接受日期:2024-09-26
发布日期:2025-07-10
出版日期:2025-07-10
通讯作者:
何玉林
作者简介:何芃(2001—),女,江西南昌人,硕士研究生,主要研究方向:大数据分布式计算、数据挖掘、机器学习基金资助:
Yulin HE1,2(), Peng HE1,2, Zhexue HUANG1,2, Weicheng XIE2, Fournier-Viger PHILIPPE2
Received:2024-07-09
Revised:2024-09-26
Accepted:2024-09-26
Online:2025-07-10
Published:2025-07-10
Contact:
Yulin HE
About author:HE Peng, born in 2001, M. S. candidate. Her research interests include distributed computing of big data, data mining, machine learning.Supported by:摘要:
正类-无标签学习(PUL)是在负例样本未知时,利用已知的少量正类样本和大量无标签样本训练出性能可被实际应用接受的分类器。现有的PUL算法存在共性的缺陷,即对无标签样本标注的不确定性较大,这将导致分类器学习到的分类边界不准确,并且限制了所训练分类器在新数据上的泛化能力。为了解决这一问题,提出一种以无标签样本标注确定性增强为导向的PUL(LCE-PUL)算法。首先,通过验证集的后验概率均值和正类样本集中心点的相似程度筛选出可靠的正类样本,并通过多轮迭代逐步精细化标注过程,以提升对无标签样本初步类别判断的准确性,从而提高无标签样本标注的确定性;其次,把这些可靠的正类样本与原始正类样本集合并,以形成新的正类样本集,之后从无标签样本集中将它剔除;然后,遍历新的无标签样本集,并利用每个样本与若干近邻点的相似程度再次筛选可靠正类样本,以更准确地推断无标签样本的潜在标签,从而减少误标注的可能性,并提升标注的确定性;最后,更新正类样本集,并把未被选中的无标签样本视为负类样本。在具有代表性的数据集上对LCE-PUL算法的可行性、合理性和有效性进行验证。随着迭代次数的增加,LCE-PUL算法的训练呈现收敛的特性,且当正类样本比例为40%、35%和30%时,LCE-PUL算法构建的分类器测试精度相较于基于特定成本函数的偏置支持向量机(Biased-SVM)算法、基于Dijkstra的PUL标签传播(LP-PUL)算法和基于标签传播的PUL(PU-LP)算法等5种代表性对比算法中最多提升了5.8、8.8和7.6个百分点。实验结果表明,LCE-PUL是一种有效处理PUL问题的机器学习算法。
中图分类号:
何玉林, 何芃, 黄哲学, 解为成, PHILIPPE Fournier-Viger. 以标注确定性增强为导向的正类-无标签学习算法[J]. 计算机应用, 2025, 45(7): 2101-2112.
Yulin HE, Peng HE, Zhexue HUANG, Weicheng XIE, Fournier-Viger PHILIPPE. Labeling certainty enhancement-oriented positive and unlabeled learning algorithm[J]. Journal of Computer Applications, 2025, 45(7): 2101-2112.
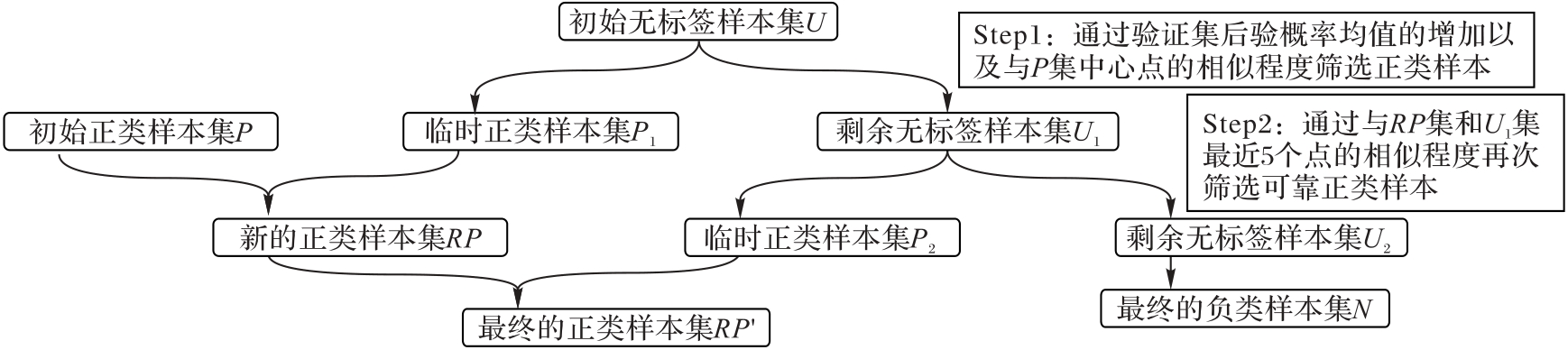
图1 LCE-PUL算法的框架
Fig. 1 Framework of LCE-PUL algorithm
| 数据集 | 属性数 | 样本数 |
|---|---|---|
| abalone | 7 | 1 268 |
| balance | 4 | 576 |
| housevotes | 16 | 336 |
| ionosphere | 32 | 126 |
| page-blocks | 10 | 658 |
| phoneme | 5 | 3 172 |
| saheart | 8 | 192 |
| satimage | 36 | 3 016 |
| seeds | 7 | 140 |
| spambase | 57 | 3 624 |
| spectfheart | 44 | 110 |
| thyroid | 6 | 736 |
| titanic | 3 | 1 422 |
| twonorm | 20 | 7 394 |
| vertebral | 6 | 398 |
| breast | 10 | 480 |
| bd | 30 | 422 |
| band | 23 | 456 |
| magic | 10 | 13 376 |
| musk | 166 | 412 |
| pima | 8 | 536 |
| vehicle | 8 | 432 |
表1 数据集信息
Tab. 1 Information of datasets
| 数据集 | 属性数 | 样本数 |
|---|---|---|
| abalone | 7 | 1 268 |
| balance | 4 | 576 |
| housevotes | 16 | 336 |
| ionosphere | 32 | 126 |
| page-blocks | 10 | 658 |
| phoneme | 5 | 3 172 |
| saheart | 8 | 192 |
| satimage | 36 | 3 016 |
| seeds | 7 | 140 |
| spambase | 57 | 3 624 |
| spectfheart | 44 | 110 |
| thyroid | 6 | 736 |
| titanic | 3 | 1 422 |
| twonorm | 20 | 7 394 |
| vertebral | 6 | 398 |
| breast | 10 | 480 |
| bd | 30 | 422 |
| band | 23 | 456 |
| magic | 10 | 13 376 |
| musk | 166 | 412 |
| pima | 8 | 536 |
| vehicle | 8 | 432 |
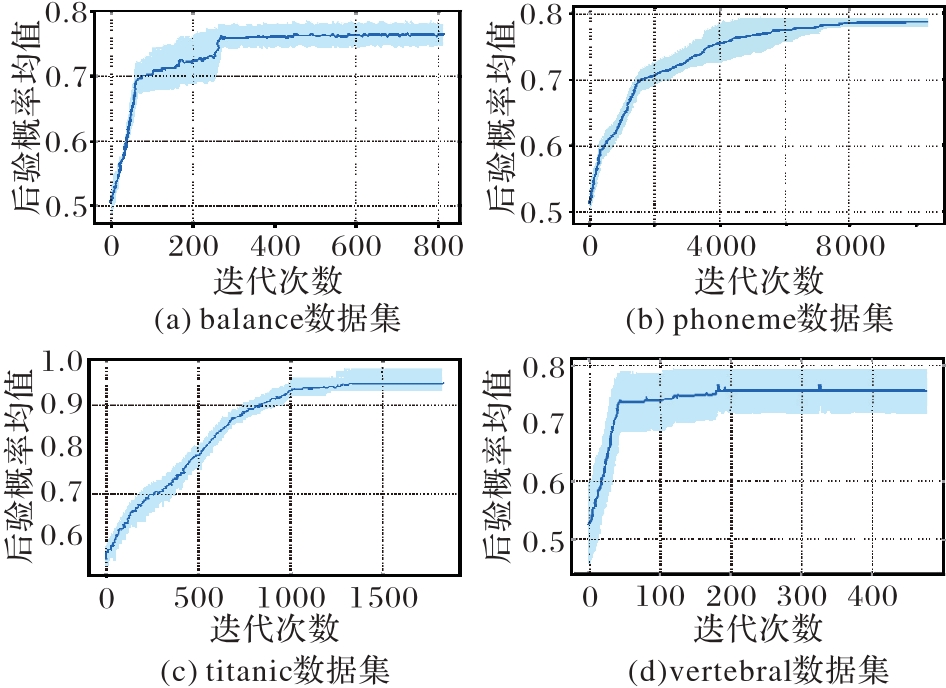
图2 验证集上后验概率的收敛
Fig. 2 Convergence of posterior probabilities on validation set

图3 LCE-PUL算法的分步分类表现
Fig. 3 Stepwise classification performance of LCE-PUL algorithm

图4 PU-LP和LP-PUL算法的分类效果对比
Fig. 4 Comparison of classification performance between PU-LP and LP-PUL algorithms
| 数据集 | S-EM | Biased-SVM | Modified-PUL | PU-LP | LP-PUL | LCE-PUL |
|---|---|---|---|---|---|---|
| 平均 | 0.433 3 | 0.777 5 | 0.771 9 | 0.748 3 | 0.755 0 | 0.806 5 |
| abalone | 0.474 0 | 0.569 6 | 0.586 9 | 0.586 6 | 0.569 6 | 0.587 9 |
| balance | 0.485 5 | 0.841 6 | 0.886 7 | 0.841 0 | 0.887 3 | 0.943 4 |
| housevotes | 0.316 8 | 0.918 8 | 0.934 7 | 0.846 5 | 0.886 1 | 0.950 5 |
| ionosphere | 0.242 1 | 0.813 2 | 0.810 5 | 0.763 2 | 0.848 7 | 0.868 4 |
| page-blocks | 0.292 9 | 0.897 0 | 0.910 1 | 0.853 5 | 0.947 0 | 0.959 6 |
| phoneme | 0.430 3 | 0.733 4 | 0.725 6 | 0.737 4 | — | 0.740 5 |
| saheart | 0.479 3 | 0.658 6 | 0.631 0 | 0.620 7 | 0.655 2 | 0.672 4 |
| satimage | 0.306 5 | 0.910 1 | 0.909 8 | 0.919 9 | — | 0.931 9 |
| seeds | 0.376 2 | 0.938 1 | 0.909 5 | 0.916 7 | 0.892 9 | 0.952 4 |
| spambase | 0.248 2 | 0.827 2 | 0.851 8 | 0.793 2 | — | 0.871 5 |
| spectfheart | 0.545 5 | 0.775 8 | 0.757 6 | 0.818 2 | 0.651 5 | 0.848 5 |
| thyroid | 0.504 1 | 0.686 9 | 0.638 9 | 0.619 9 | 0.565 6 | 0.692 3 |
| titanic | 0.406 1 | 0.718 0 | 0.711 9 | 0.721 3 | 0.721 3 | 0.730 7 |
| twonorm | 0.498 9 | 0.974 1 | 0.976 1 | — | — | 0.979 2 |
| vertebral | 0.433 3 | 0.791 7 | 0.790 0 | 0.795 8 | 0.733 3 | 0.800 0 |
| breast | 0.700 0 | 0.955 6 | 0.941 7 | 0.947 9 | 0.899 3 | 0.962 5 |
| bd | 0.409 4 | 0.924 4 | 0.897 6 | 0.850 4 | 0.909 4 | 0.929 1 |
| band | 0.430 7 | 0.592 7 | 0.583 9 | 0.591 2 | 0.565 7 | 0.624 8 |
| magic | 0.439 7 | 0.629 6 | 0.657 5 | — | — | 0.676 0 |
| musk | 0.419 4 | 0.714 5 | 0.701 6 | 0.544 4 | 0.705 6 | 0.721 0 |
| pima | 0.436 0 | 0.708 1 | 0.718 0 | 0.664 6 | 0.705 0 | 0.720 5 |
| vehicle | 0.415 4 | 0.713 8 | 0.710 8 | 0.738 5 | 0.692 3 | 0.746 2 |
表2 正类样本比例为40%时6种PUL算法的测试精度比较
Tab. 2 Comparison of test accuracy of 6 PUL algorithms with positive sample ratio of 40%
| 数据集 | S-EM | Biased-SVM | Modified-PUL | PU-LP | LP-PUL | LCE-PUL |
|---|---|---|---|---|---|---|
| 平均 | 0.433 3 | 0.777 5 | 0.771 9 | 0.748 3 | 0.755 0 | 0.806 5 |
| abalone | 0.474 0 | 0.569 6 | 0.586 9 | 0.586 6 | 0.569 6 | 0.587 9 |
| balance | 0.485 5 | 0.841 6 | 0.886 7 | 0.841 0 | 0.887 3 | 0.943 4 |
| housevotes | 0.316 8 | 0.918 8 | 0.934 7 | 0.846 5 | 0.886 1 | 0.950 5 |
| ionosphere | 0.242 1 | 0.813 2 | 0.810 5 | 0.763 2 | 0.848 7 | 0.868 4 |
| page-blocks | 0.292 9 | 0.897 0 | 0.910 1 | 0.853 5 | 0.947 0 | 0.959 6 |
| phoneme | 0.430 3 | 0.733 4 | 0.725 6 | 0.737 4 | — | 0.740 5 |
| saheart | 0.479 3 | 0.658 6 | 0.631 0 | 0.620 7 | 0.655 2 | 0.672 4 |
| satimage | 0.306 5 | 0.910 1 | 0.909 8 | 0.919 9 | — | 0.931 9 |
| seeds | 0.376 2 | 0.938 1 | 0.909 5 | 0.916 7 | 0.892 9 | 0.952 4 |
| spambase | 0.248 2 | 0.827 2 | 0.851 8 | 0.793 2 | — | 0.871 5 |
| spectfheart | 0.545 5 | 0.775 8 | 0.757 6 | 0.818 2 | 0.651 5 | 0.848 5 |
| thyroid | 0.504 1 | 0.686 9 | 0.638 9 | 0.619 9 | 0.565 6 | 0.692 3 |
| titanic | 0.406 1 | 0.718 0 | 0.711 9 | 0.721 3 | 0.721 3 | 0.730 7 |
| twonorm | 0.498 9 | 0.974 1 | 0.976 1 | — | — | 0.979 2 |
| vertebral | 0.433 3 | 0.791 7 | 0.790 0 | 0.795 8 | 0.733 3 | 0.800 0 |
| breast | 0.700 0 | 0.955 6 | 0.941 7 | 0.947 9 | 0.899 3 | 0.962 5 |
| bd | 0.409 4 | 0.924 4 | 0.897 6 | 0.850 4 | 0.909 4 | 0.929 1 |
| band | 0.430 7 | 0.592 7 | 0.583 9 | 0.591 2 | 0.565 7 | 0.624 8 |
| magic | 0.439 7 | 0.629 6 | 0.657 5 | — | — | 0.676 0 |
| musk | 0.419 4 | 0.714 5 | 0.701 6 | 0.544 4 | 0.705 6 | 0.721 0 |
| pima | 0.436 0 | 0.708 1 | 0.718 0 | 0.664 6 | 0.705 0 | 0.720 5 |
| vehicle | 0.415 4 | 0.713 8 | 0.710 8 | 0.738 5 | 0.692 3 | 0.746 2 |
| 数据集 | S-EM | Biased-SVM | Modified-PUL | PU-LP | LP-PUL | LCE-PUL |
|---|---|---|---|---|---|---|
| 平均 | 0.413 2 | 0.760 4 | 0.763 4 | 0.714 8 | 0.719 9 | 0.803 1 |
| abalone | 0.445 1 | 0.574 3 | 0.588 5 | 0.564 3 | 0.576 1 | 0.592 7 |
| balance | 0.486 7 | 0.806 9 | 0.845 1 | 0.939 3 | 0.817 9 | 0.943 4 |
| housevotes | 0.202 0 | 0.918 8 | 0.928 7 | 0.897 0 | 0.841 6 | 0.934 7 |
| ionosphere | 0.289 5 | 0.826 3 | 0.834 2 | 0.736 8 | 0.809 2 | 0.878 9 |
| page-blocks | 0.410 1 | 0.863 6 | 0.881 8 | 0.738 4 | 0.873 7 | 0.934 3 |
| phoneme | 0.407 1 | 0.729 6 | 0.726 1 | 0.705 6 | — | 0.758 8 |
| saheart | 0.472 4 | 0.637 9 | 0.651 7 | 0.612 1 | 0.586 2 | 0.689 7 |
| satimage | 0.267 6 | 0.910 3 | 0.902 1 | 0.909 5 | — | 0.931 7 |
| seeds | 0.357 1 | 0.905 8 | 0.914 3 | 0.785 3 | 0.845 2 | 0.952 4 |
| spambase | 0.224 3 | 0.828 9 | 0.856 1 | 0.788 6 | — | 0.875 9 |
| spectfheart | 0.442 4 | 0.757 6 | 0.727 3 | 0.715 2 | 0.621 2 | 0.763 6 |
| thyroid | 0.481 4 | 0.609 0 | 0.657 0 | 0.573 8 | 0.493 2 | 0.715 8 |
| titanic | 0.405 2 | 0.709 1 | 0.711 0 | 0.504 4 | 0.695 6 | 0.721 3 |
| twonorm | 0.488 3 | 0.975 1 | 0.975 4 | — | — | 0.979 0 |
| vertebral | 0.428 3 | 0.760 0 | 0.773 3 | 0.779 2 | 0.645 8 | 0.800 0 |
| breast | 0.476 4 | 0.955 6 | 0.941 7 | 0.941 0 | 0.881 9 | 0.965 3 |
| bd | 0.319 7 | 0.913 4 | 0.921 3 | 0.897 6 | 0.846 5 | 0.927 6 |
| band | 0.521 2 | 0.579 6 | 0.534 3 | 0.616 8 | 0.624 1 | 0.649 6 |
| magic | 0.435 3 | 0.625 7 | 0.629 6 | — | — | 0.676 6 |
| musk | 0.451 6 | 0.700 0 | 0.651 6 | 0.576 6 | 0.709 7 | 0.727 4 |
| pima | 0.400 0 | 0.704 3 | 0.716 8 | 0.723 6 | 0.689 4 | 0.726 7 |
| vehicle | 0.435 4 | 0.704 6 | 0.698 5 | 0.549 6 | 0.680 8 | 0.729 2 |
表3 正类样本比例为35%时6种PUL算法的测试精度比较
Tab. 3 Comparison of test accuracy of 6 PUL algorithms with positive sample ratio of 35%
| 数据集 | S-EM | Biased-SVM | Modified-PUL | PU-LP | LP-PUL | LCE-PUL |
|---|---|---|---|---|---|---|
| 平均 | 0.413 2 | 0.760 4 | 0.763 4 | 0.714 8 | 0.719 9 | 0.803 1 |
| abalone | 0.445 1 | 0.574 3 | 0.588 5 | 0.564 3 | 0.576 1 | 0.592 7 |
| balance | 0.486 7 | 0.806 9 | 0.845 1 | 0.939 3 | 0.817 9 | 0.943 4 |
| housevotes | 0.202 0 | 0.918 8 | 0.928 7 | 0.897 0 | 0.841 6 | 0.934 7 |
| ionosphere | 0.289 5 | 0.826 3 | 0.834 2 | 0.736 8 | 0.809 2 | 0.878 9 |
| page-blocks | 0.410 1 | 0.863 6 | 0.881 8 | 0.738 4 | 0.873 7 | 0.934 3 |
| phoneme | 0.407 1 | 0.729 6 | 0.726 1 | 0.705 6 | — | 0.758 8 |
| saheart | 0.472 4 | 0.637 9 | 0.651 7 | 0.612 1 | 0.586 2 | 0.689 7 |
| satimage | 0.267 6 | 0.910 3 | 0.902 1 | 0.909 5 | — | 0.931 7 |
| seeds | 0.357 1 | 0.905 8 | 0.914 3 | 0.785 3 | 0.845 2 | 0.952 4 |
| spambase | 0.224 3 | 0.828 9 | 0.856 1 | 0.788 6 | — | 0.875 9 |
| spectfheart | 0.442 4 | 0.757 6 | 0.727 3 | 0.715 2 | 0.621 2 | 0.763 6 |
| thyroid | 0.481 4 | 0.609 0 | 0.657 0 | 0.573 8 | 0.493 2 | 0.715 8 |
| titanic | 0.405 2 | 0.709 1 | 0.711 0 | 0.504 4 | 0.695 6 | 0.721 3 |
| twonorm | 0.488 3 | 0.975 1 | 0.975 4 | — | — | 0.979 0 |
| vertebral | 0.428 3 | 0.760 0 | 0.773 3 | 0.779 2 | 0.645 8 | 0.800 0 |
| breast | 0.476 4 | 0.955 6 | 0.941 7 | 0.941 0 | 0.881 9 | 0.965 3 |
| bd | 0.319 7 | 0.913 4 | 0.921 3 | 0.897 6 | 0.846 5 | 0.927 6 |
| band | 0.521 2 | 0.579 6 | 0.534 3 | 0.616 8 | 0.624 1 | 0.649 6 |
| magic | 0.435 3 | 0.625 7 | 0.629 6 | — | — | 0.676 6 |
| musk | 0.451 6 | 0.700 0 | 0.651 6 | 0.576 6 | 0.709 7 | 0.727 4 |
| pima | 0.400 0 | 0.704 3 | 0.716 8 | 0.723 6 | 0.689 4 | 0.726 7 |
| vehicle | 0.435 4 | 0.704 6 | 0.698 5 | 0.549 6 | 0.680 8 | 0.729 2 |
| 数据集 | S-EM | Biased-SVM | Modified-PUL | PU-LP | LP-PUL | LCE-PUL |
|---|---|---|---|---|---|---|
| 平均 | 0.399 1 | 0.747 4 | 0.755 7 | 0.759 9 | 0.718 7 | 0.795 4 |
| abalone | 0.447 8 | 0.582 2 | 0.549 1 | 0.579 0 | 0.536 5 | 0.582 7 |
| balance | 0.453 2 | 0.714 5 | 0.768 8 | 0.928 3 | 0.832 4 | 0.953 8 |
| housevotes | 0.184 2 | 0.897 0 | 0.899 0 | 0.897 0 | 0.734 7 | 0.910 9 |
| ionosphere | 0.286 8 | 0.813 2 | 0.815 8 | 0.705 3 | 0.802 6 | 0.876 3 |
| page-blocks | 0.173 7 | 0.892 9 | 0.890 9 | 0.920 2 | 0.896 0 | 0.929 3 |
| phoneme | 0.413 2 | 0.725 4 | 0.721 6 | 0.748 1 | — | 0.755 3 |
| saheart | 0.462 1 | 0.603 4 | 0.624 1 | 0.648 3 | 0.551 7 | 0.672 4 |
| satimage | 0.244 0 | 0.893 0 | 0.896 6 | 0.925 1 | — | 0.929 7 |
| seeds | 0.323 8 | 0.933 3 | 0.928 6 | 0.890 5 | 0.914 3 | 0.947 6 |
| spambase | 0.212 7 | 0.819 9 | 0.839 9 | 0.780 1 | — | 0.846 3 |
| spectfheart | 0.557 6 | 0.654 5 | 0.763 6 | 0.733 3 | 0.606 1 | 0.772 7 |
| thyroid | 0.508 6 | 0.606 3 | 0.633 5 | 0.642 5 | 0.615 4 | 0.643 4 |
| titanic | 0.414 1 | 0.714 3 | 0.709 6 | 0.709 6 | 0.706 3 | 0.728 3 |
| twonorm | 0.480 6 | 0.971 0 | 0.976 1 | — | — | 0.977 6 |
| vertebral | 0.431 7 | 0.758 3 | 0.790 0 | 0.783 3 | 0.658 3 | 0.806 7 |
| breast | 0.533 3 | 0.955 6 | 0.943 1 | 0.959 7 | 0.902 8 | 0.965 3 |
| bd | 0.307 1 | 0.915 0 | 0.892 9 | 0.916 5 | 0.866 1 | 0.917 3 |
| band | 0.448 2 | 0.560 6 | 0.591 2 | 0.616 1 | 0.531 4 | 0.635 0 |
| magic | 0.427 3 | 0.629 6 | 0.612 0 | — | — | 0.690 2 |
| musk | 0.446 8 | 0.674 2 | 0.659 7 | 0.611 3 | 0.661 3 | 0.738 7 |
| pima | 0.366 5 | 0.723 0 | 0.713 0 | 0.677 0 | 0.698 1 | 0.725 5 |
| vehicle | 0.440 0 | 0.707 7 | 0.673 8 | 0.700 0 | 0.704 6 | 0.715 4 |
表4 正类样本比例为30%时6种PUL算法的测试精度比较
Tab. 4 Comparison of test accuracy of 6 PUL algorithms with positive sample ratio of 30%
| 数据集 | S-EM | Biased-SVM | Modified-PUL | PU-LP | LP-PUL | LCE-PUL |
|---|---|---|---|---|---|---|
| 平均 | 0.399 1 | 0.747 4 | 0.755 7 | 0.759 9 | 0.718 7 | 0.795 4 |
| abalone | 0.447 8 | 0.582 2 | 0.549 1 | 0.579 0 | 0.536 5 | 0.582 7 |
| balance | 0.453 2 | 0.714 5 | 0.768 8 | 0.928 3 | 0.832 4 | 0.953 8 |
| housevotes | 0.184 2 | 0.897 0 | 0.899 0 | 0.897 0 | 0.734 7 | 0.910 9 |
| ionosphere | 0.286 8 | 0.813 2 | 0.815 8 | 0.705 3 | 0.802 6 | 0.876 3 |
| page-blocks | 0.173 7 | 0.892 9 | 0.890 9 | 0.920 2 | 0.896 0 | 0.929 3 |
| phoneme | 0.413 2 | 0.725 4 | 0.721 6 | 0.748 1 | — | 0.755 3 |
| saheart | 0.462 1 | 0.603 4 | 0.624 1 | 0.648 3 | 0.551 7 | 0.672 4 |
| satimage | 0.244 0 | 0.893 0 | 0.896 6 | 0.925 1 | — | 0.929 7 |
| seeds | 0.323 8 | 0.933 3 | 0.928 6 | 0.890 5 | 0.914 3 | 0.947 6 |
| spambase | 0.212 7 | 0.819 9 | 0.839 9 | 0.780 1 | — | 0.846 3 |
| spectfheart | 0.557 6 | 0.654 5 | 0.763 6 | 0.733 3 | 0.606 1 | 0.772 7 |
| thyroid | 0.508 6 | 0.606 3 | 0.633 5 | 0.642 5 | 0.615 4 | 0.643 4 |
| titanic | 0.414 1 | 0.714 3 | 0.709 6 | 0.709 6 | 0.706 3 | 0.728 3 |
| twonorm | 0.480 6 | 0.971 0 | 0.976 1 | — | — | 0.977 6 |
| vertebral | 0.431 7 | 0.758 3 | 0.790 0 | 0.783 3 | 0.658 3 | 0.806 7 |
| breast | 0.533 3 | 0.955 6 | 0.943 1 | 0.959 7 | 0.902 8 | 0.965 3 |
| bd | 0.307 1 | 0.915 0 | 0.892 9 | 0.916 5 | 0.866 1 | 0.917 3 |
| band | 0.448 2 | 0.560 6 | 0.591 2 | 0.616 1 | 0.531 4 | 0.635 0 |
| magic | 0.427 3 | 0.629 6 | 0.612 0 | — | — | 0.690 2 |
| musk | 0.446 8 | 0.674 2 | 0.659 7 | 0.611 3 | 0.661 3 | 0.738 7 |
| pima | 0.366 5 | 0.723 0 | 0.713 0 | 0.677 0 | 0.698 1 | 0.725 5 |
| vehicle | 0.440 0 | 0.707 7 | 0.673 8 | 0.700 0 | 0.704 6 | 0.715 4 |
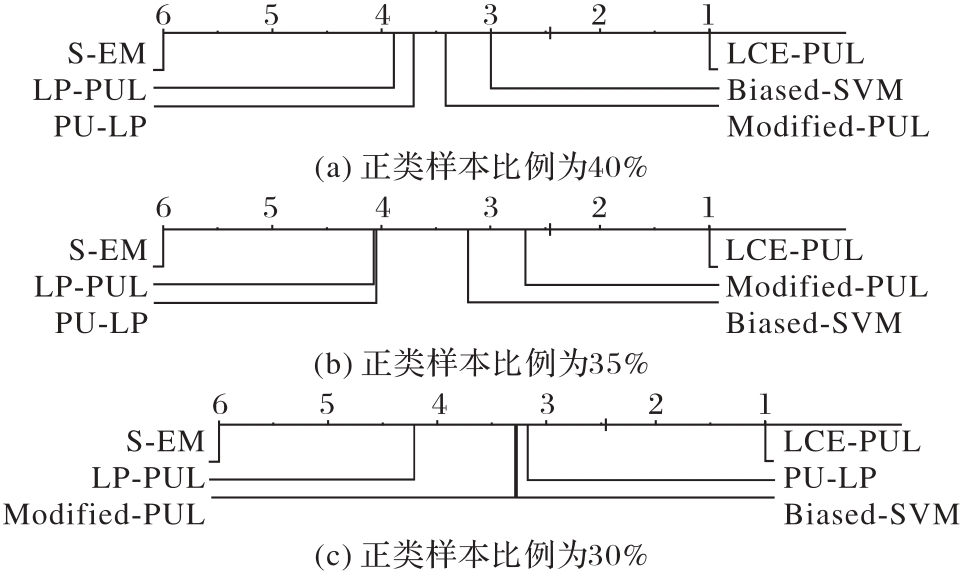
图5 不同正类样本比例时的测试精度CD图
Fig. 5 Test accuracy CD diagrams at different positive class sample ratios
| [1] | DE COMITÉ F, DENIS F, GILLERON R, et al. Positive and unlabeled examples help learning [C]// Proceedings of the 1999 International Conference on Algorithmic Learning Theory, LNCS 1720. Berlin: Springer, 1999: 219-230. |
| [2] | ELKAN C, NOTO K. Learning classifiers from only positive and unlabeled data [C]// Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2008: 213-220. |
| [3] | YANG P, LI X, CHUA H N, et al. Ensemble positive unlabeled learning for disease gene identification [J]. PLoS ONE, 2014, 9(5): No.e97079. |
| [4] | WARD G, HASTIE T, BARRY S, et al. Presence-only data and the EM algorithm [J]. Biometrics, 2009, 65(2): 554-563. |
| [5] | DENIS F, GILLERON R, TOMMASI M. Text classification from positive and unlabeled examples [EB/OL]. [2024-03-03]. . |
| [6] | LIBEN-NOWELL D, KLEINBERG J. The link prediction problem for social networks [C]// Proceedings of the 12th International Conference on Information and Knowledge Management. New York: ACM, 2003: 556-559. |
| [7] | 胡斌皓,张建朋,陈鸿昶.基于生成式对抗网络和正类无标签学习的知识图谱补全算法[J].计算机科学,2024, 51(1): 310-315. |
| HU B H, ZHANG J P, CHEN H C. Knowledge graph completion algorithm based on generative adversarial network and positive and unlabeled learning [J]. Computer Science, 2024, 51(1): 310-315. | |
| [8] | BEKKER J, DAVIS J. Learning from positive and unlabeled data: a survey [J]. Machine Learning, 2020, 109(4): 719-760. |
| [9] | LIU B, LEE W S, YU P S, et al. Partially supervised classification of text documents [C]// Proceedings of the 19th International Conference on Machine Learning. San Francisco: Morgan Kaufmann Publishers Inc., 2002: 387-394. |
| [10] | FUNG G P C, YU J X, LU H, et al. Text classification without negative examples revisit [J]. IEEE Transactions on Knowledge and Data Engineering, 2006, 18(1): 6-20. |
| [11] | LIU B, DAI Y, LI X, et al. Building text classifiers using positive and unlabeled examples [C]// Proceedings of the 3rd IEEE International Conference on Data Mining. Piscataway: IEEE, 2003: 179-186. |
| [12] | YU S, LI C. PE-PUC: a graph based PU-learning approach for text classification [C]// Proceedings of the 2007 International Conference on Machine Learning and Data Mining in Pattern Recognition, LNCS 4571. Berlin: Springer, 2007: 574-584. |
| [13] | 李炳聪.用正则的方法在正样本和无标签样本上训练二分类器[J].信息与电脑,2019(5): 67-68. |
| LI B C. Training bi-classifier on positive and unlabeled sample by regular method [J]. Information and Computer, 2019(5): 67-68. | |
| [14] | HERNÁNDEZ FUSILIER D, MONTES-Y-GÓMEZ M, ROSSO P, et al. Detecting positive and negative deceptive opinions using PU-learning [J]. Information Processing and Management, 2015, 51(4): 433-443. |
| [15] | LI X, LIU B. Learning to classify texts using positive and unlabeled data [C]// Proceedings of the 18th International Joint Conference on Artificial Intelligence. San Francisco: Morgan Kaufmann Publishers Inc., 2003: 587-592. |
| [16] | HE F, LIU T, WEBB G I, et al. Instance-dependent PU learning by Bayesian optimal relabeling [EB/OL]. [2024-03-03]. . |
| [17] | CHAUDHARI S, SHEVADE S. Learning from positive and unlabelled examples using maximum margin clustering [C]// Proceedings of the 2012 International Conference on Neural Information Processing, LNCS 7665. Berlin: Springer, 2012: 465-473. |
| [18] | ZHANG B, ZUO W. Reliable negative extracting based on knn for learning from positive and unlabeled examples [J]. Journal of Computers, 2009, 4(1): 94-101. |
| [19] | KE T, YANG B, ZHEN L, et al. Building high-performance classifiers using positive and unlabeled examples for text classification [C]// Proceedings of the 2012 International Symposium on Neural Networks, LNCS 7368. Berlin: Springer, 2012: 187-195. |
| [20] | LIU Z, SHI W, LI D, et al. Partially supervised classification: based on weighted unlabeled samples support vector machine [M]// WANG J. Data warehousing and mining: concepts, methodologies, tools, and applications. Hershey, PA: IGI Global, 2008: 1216-1230. |
| [21] | SCOTT C, BLANCHARD G. Novelty detection: unlabeled data definitely help [C]// Proceedings of the 12th International Conference on Artificial Intelligence and Statistics. New York: JMLR.org, 2009: 464-471. |
| [22] | SUYKENS J A K, VANDEWALLE J. Least squares support vector machine classifiers: a large scale algorithm [J]. Neural Processing Letters, 1999, 9(3): 293-300. |
| [23] | MORDELET F, VERT J P. A bagging SVM to learn from positive and unlabeled examples [J]. Pattern Recognition Letters, 2014, 37: 201-209. |
| [24] | KE T, JING L, LV H, et al. Global and local learning from positive and unlabeled examples [J]. Applied Intelligence, 2018, 48(8): 2373-2392. |
| [25] | KE T, LV H, SUN M, et al. A biased least squares support vector machine based on Mahalanobis distance for PU learning [J]. Physica A: Statistical Mechanics and its Applications, 2018, 509: 422-438. |
| [26] | SHAO Y H, CHEN W J, LIU L M, et al. Laplacian unit-hyperplane learning from positive and unlabeled examples [J]. Information Sciences, 2015, 314: 152-168. |
| [27] | BEKKER J, DAVIS J. Learning from positive and unlabeled data under the selected at random assumption [C]// Proceedings of the 2nd International Workshop on Learning with Imbalanced Domains: Theory and Applications. New York: JMLR.org, 2018: 8-22. |
| [28] | KATO M, TESHIMA T, HONDA J. Learning from positive and unlabeled data with a selection bias [EB/OL]. [2024-03-03]. . |
| [29] | JASKIE K, ELKAN C, SPANIAS A. A modified logistic regression for positive and unlabeled learning [C]// Proceedings of the 53rd Asilomar Conference on Signals, Systems, and Computers. Piscataway: IEEE, 2019: 2007-2011. |
| [30] | VAN ENGELEN J E, HOOS H H. A survey on semi-supervised learning [J]. Machine Learning, 2020, 109(2): 373-440. |
| [31] | KE T, TAN J, YANG B, et al. A novel graph-based approach for transductive positive and unlabeled learning [J]. Journal of Computational Information Systems, 2014, 10(4): 1439-1447. |
| [32] | MA S, ZHANG R. PU-LP: a novel approach for positive and unlabeled learning by label propagation [C]// Proceedings of the 2017 IEEE International Conference on Multimedia and Expo Workshops. Piscataway: IEEE, 2017: 537-542. |
| [33] | DE SOUZA M C, NOGUEIRA B M, ROSSI R G, et al. A network-based positive and unlabeled learning approach for fake news detection [J]. Machine Learning, 2022, 111(10): 3549-3592. |
| [34] | CARNEVALI J C, ROSSI R G, MILIOS E, et al. A graph-based approach for positive and unlabeled learning [J]. Information Sciences, 2021, 580: 655-672. |
| [35] | DUA D, GRAFF C. The UCI machine learning repository [DB/OL]. [2024-03-03]. . |
| [36] | ALCALÁ-FDEZ J, FERNÁNDEZ A, LUENGO L, et al. Keel data-mining software tool: data set repository, integration of algorithms and experimental analysis framework [EB/OL]. [2024-03-03]. . |
| [1] | 王翠, 邓淼磊, 张德贤, 李磊, 杨晓艳. 基于图像的端到端行人搜索算法综述[J]. 《计算机应用》唯一官方网站, 2024, 44(8): 2544-2550. |
| [2] | 江静, 陈渝, 孙界平, 琚生根. 融合后验概率校准训练的文本分类算法[J]. 《计算机应用》唯一官方网站, 2022, 42(6): 1789-1795. |
| [3] | 丁建立, 韩宇超, 王家亮. 基于粗精二次估计的RFID标签数目估算方法[J]. 计算机应用, 2017, 37(9): 2722-2727. |
| [4] | 黄育, 张鸿. 基于潜语义主题加强的跨媒体检索算法[J]. 计算机应用, 2017, 37(4): 1061-1064. |
| [5] | 黄文娜, 彭亚雄, 贺松. 基于MAP+CMLLR的说话人识别中发声力度问题[J]. 计算机应用, 2017, 37(3): 906-910. |
| [6] | 张俊, 关胜晓. 基于改进的最大后验概率矢量量化和最小二乘支持向量机集成算法[J]. 计算机应用, 2015, 35(7): 2101-2104. |
| [7] | 齐耀辉 潘复平 葛凤培 颜永红. 鉴别性最大后验概率声学模型自适应[J]. 计算机应用, 2014, 34(1): 265-269. |
| [8] | 张毅 黄聪 罗元. 基于改进朴素贝叶斯分类器的康复训练行为识别方法[J]. 计算机应用, 2013, 33(11): 3187-3189. |
| [9] | 刘洋 季薇. 认知无线电中一种改进的两步协作感知算法[J]. 计算机应用, 2013, 33(05): 1244-1247. |
| [10] | 刘磊 陈兴蜀 尹学渊 段意 吕昭. 基于特征加权朴素贝叶斯算法的网络用户识别[J]. 计算机应用, 2011, 31(12): 3268-3270. |
| [11] | 张洪艳 沈焕锋 张良培 李平湘 袁强强. 基于最大后验估计的影像盲超分辨率重建方法[J]. 计算机应用, 2011, 31(05): 1209-1213. |
| [12] | 王卫星 王李平 员志超. 一种基于最大类间后验概率的Canny边缘检测算法[J]. 计算机应用, 2009, 29(4): 962-965,. |
| [13] | 陈丽 陈静. 基于支持向量机和k-近邻分类器的多特征融合方法[J]. 计算机应用, 2009, 29(3): 833-835. |
| [14] | 王益艳. 基于广义变分模型的自适应图像去噪算法[J]. 计算机应用, 2009, 29(11): 3033-3036. |
| [15] | 刘杰 张艳宁 许星 王志印. 一种基于灰度分布马尔可夫模型的图像分割[J]. 计算机应用, 2008, 28(3): 686-687. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||