


《计算机应用》唯一官方网站 ›› 2025, Vol. 45 ›› Issue (11): 3674-3681.DOI: 10.11772/j.issn.1001-9081.2024111569
• 先进计算 • 上一篇
周贤文( ), 龙潇, 余欣磊, 张依恋
), 龙潇, 余欣磊, 张依恋
收稿日期:2024-11-07
修回日期:2025-05-12
接受日期:2025-05-16
发布日期:2025-05-19
出版日期:2025-11-10
通讯作者:
周贤文
作者简介:龙潇(1997—),男,宁夏中卫人,硕士研究生,主要研究方向:强化学习、智能车辆制动基金资助:
Xianwen ZHOU(), Xiao LONG, Xinlei YU, Yilian ZHANG
Received:2024-11-07
Revised:2025-05-12
Accepted:2025-05-16
Online:2025-05-19
Published:2025-11-10
Contact:
Xianwen ZHOU
About author:LONG Xiao, born in 1997, M. S. candidate. His research interests include reinforcement learning, intelligent vehicle braking.Supported by:摘要:
针对智能车辆在混合交通流下的行驶安全问题,提出一种基于改进Q学习的智能车辆多场景安全制动算法。首先,根据路面情况与车辆参数建立三车模型,并分别模拟制动、跟车与变道场景。其次,对训练数据进行线性规划,以确保智能车辆存在安全制动的可能;同时,设置奖励函数,引导智能体在保证安全制动的基础上控制中车与前车、后车之间的距离尽可能相等。最后,结合区间分块方法,使算法能处理连续状态空间问题。与传统Q学习算法在制动、跟车、变道行驶场景下进行仿真对比实验的结果表明,所提算法的安全率由76.02%提高到100.00%,总训练时间降低为传统算法的69%。可见,所提算法安全性更好、训练效率更高,而且在制动、跟车与变道场景中均能在保证安全的前提下控制中车与前车、后车之间的距离尽可能相等。
中图分类号:
周贤文, 龙潇, 余欣磊, 张依恋. 基于改进Q学习的智能车辆多场景安全制动算法[J]. 计算机应用, 2025, 45(11): 3674-3681.
Xianwen ZHOU, Xiao LONG, Xinlei YU, Yilian ZHANG. Improved Q-learning-based algorithm for safe braking of intelligent vehicles in multiple scenarios[J]. Journal of Computer Applications, 2025, 45(11): 3674-3681.
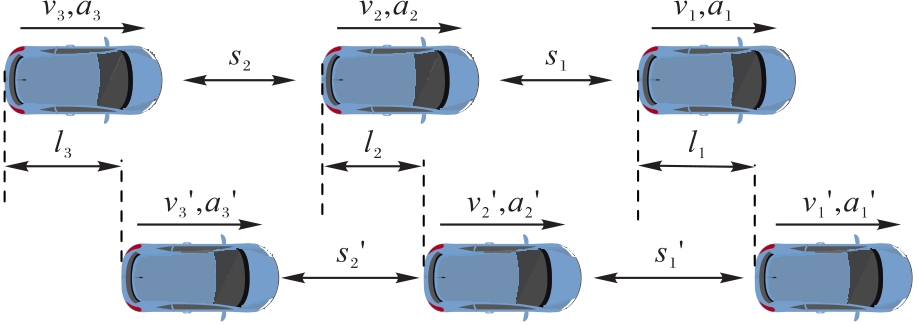
图1 三车模型示意图
Fig. 1 Schematic diagram of three-vehicle model
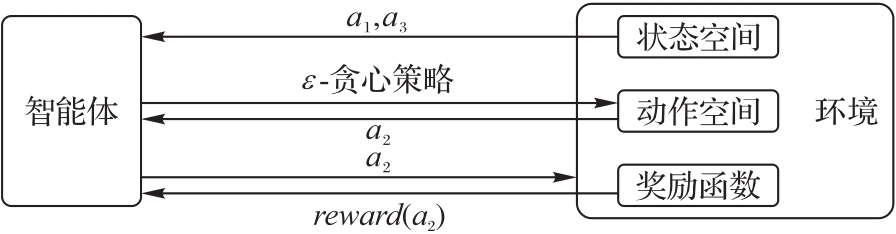
图2 智能体训练示意图
Fig. 2 Schematic diagram of agent training
| 算法 | 安全率/% | 单次训练时间/s | 总训练时间/s |
|---|---|---|---|
| 传统Q学习 | 76.02 | 21.04 | 1 052 |
| 改进Q学习 | 100.00 | 23.13 | 726 |
表1 传统Q学习与改进Q学习的性能对比
Tab. 1 Performance comparison between traditional Q-learning and improved Q-learning
| 算法 | 安全率/% | 单次训练时间/s | 总训练时间/s |
|---|---|---|---|
| 传统Q学习 | 76.02 | 21.04 | 1 052 |
| 改进Q学习 | 100.00 | 23.13 | 726 |
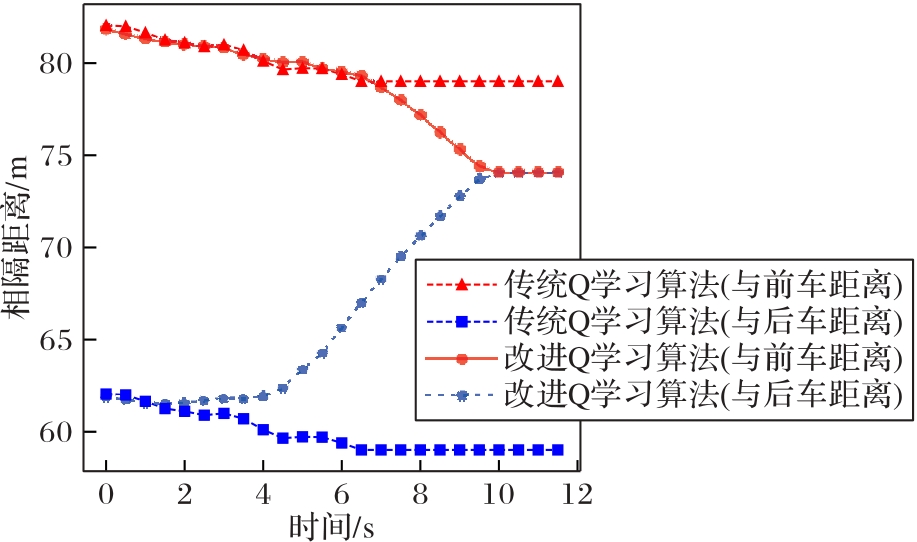
图3 制动场景下中车与前/后车相隔距离
Fig. 3 Distances between middle vehicle and preceding/following vehicles in braking scenario
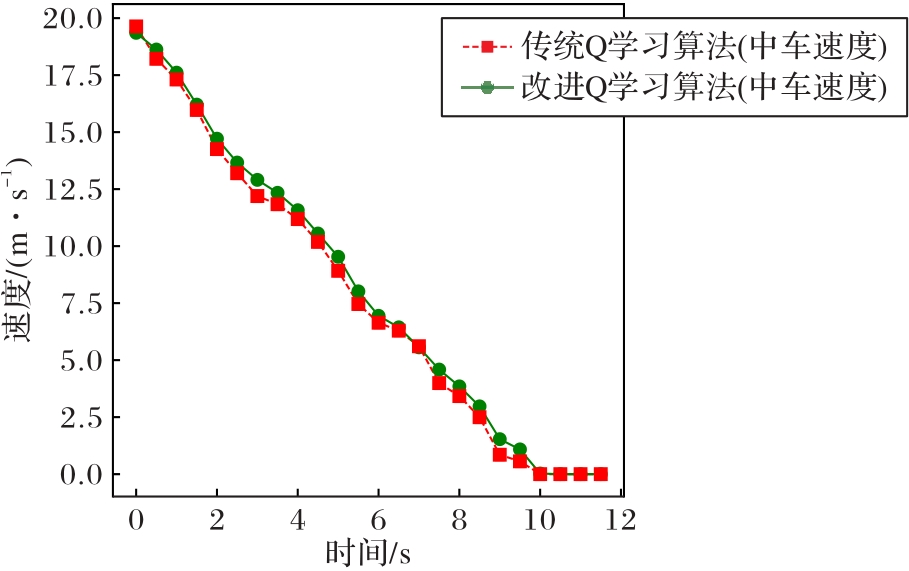
图4 制动场景下传统Q学习与改进Q学习的中车速度对比
Fig. 4 Comparison of middle vehicle speed using traditional Q-learning and improved Q-learning in braking scenario
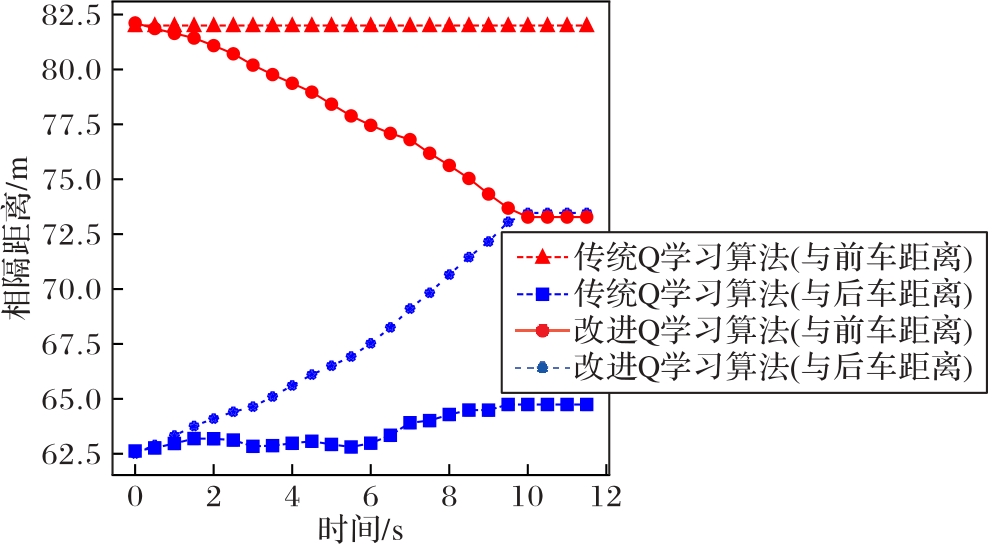
图5 跟车场景下中车与前\后车相隔距离
Fig. 5 Distances between middle vehicle and preceding/following vehicles in car-following scenario
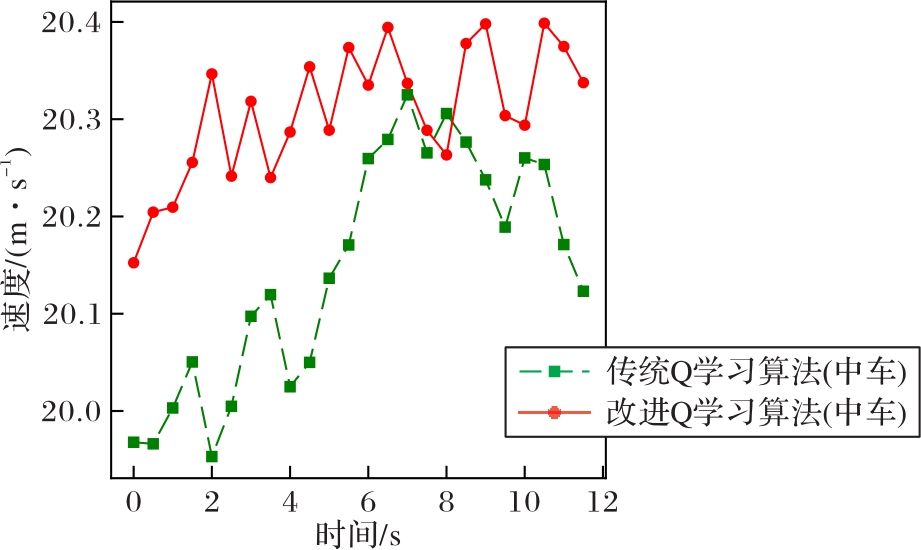
图6 跟车场景下传统Q学习与改进Q学习的中车速度对比
Fig. 6 Comparison of middle vehicle speed using traditional Q-learning and improved Q-learning in car-following scenario
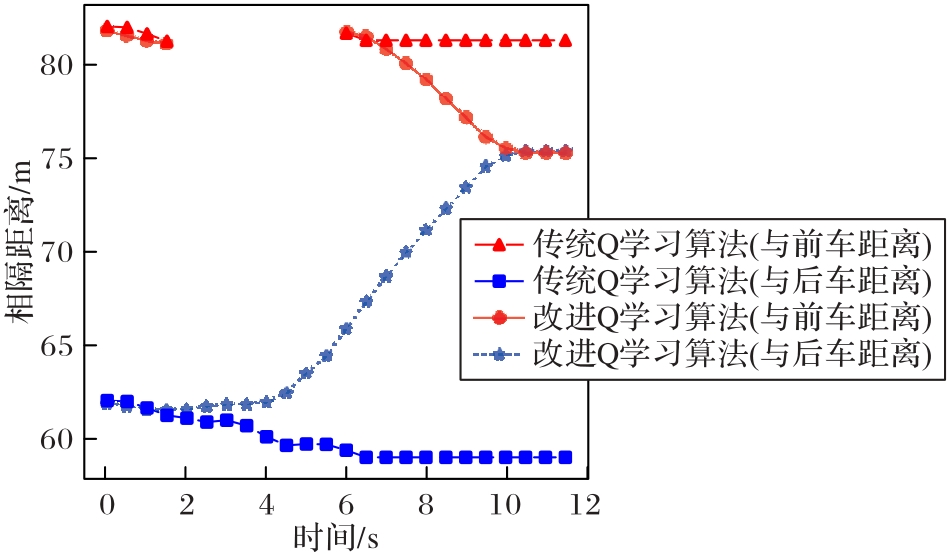
图7 变道场景下中车与前/后车相隔距离图
Fig. 7 Distances between middle vehicle and preceding/following vehicles in lane-changing scenario
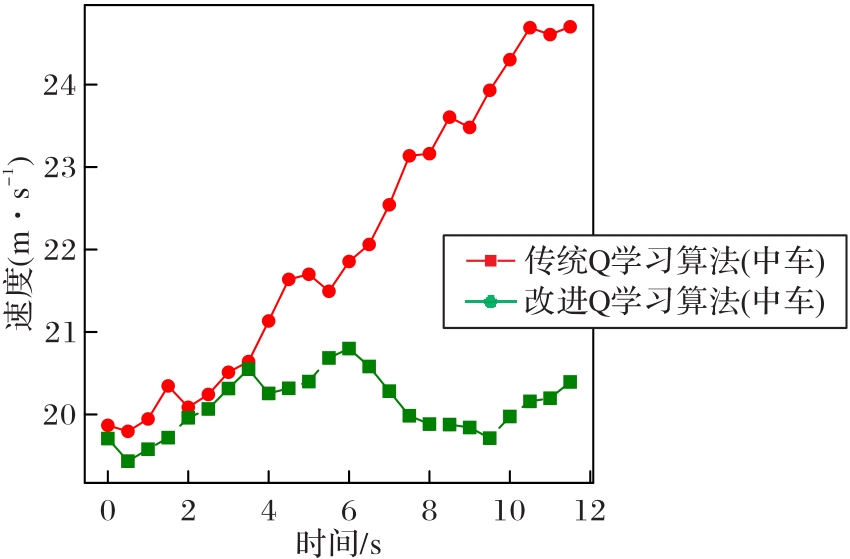
图8 变道场景下传统Q学习与改进Q学习的中车速度对比
Fig. 8 Comparison of middle vehicle speed using traditional Q-learning and improved Q-learning in lane-changing scenario
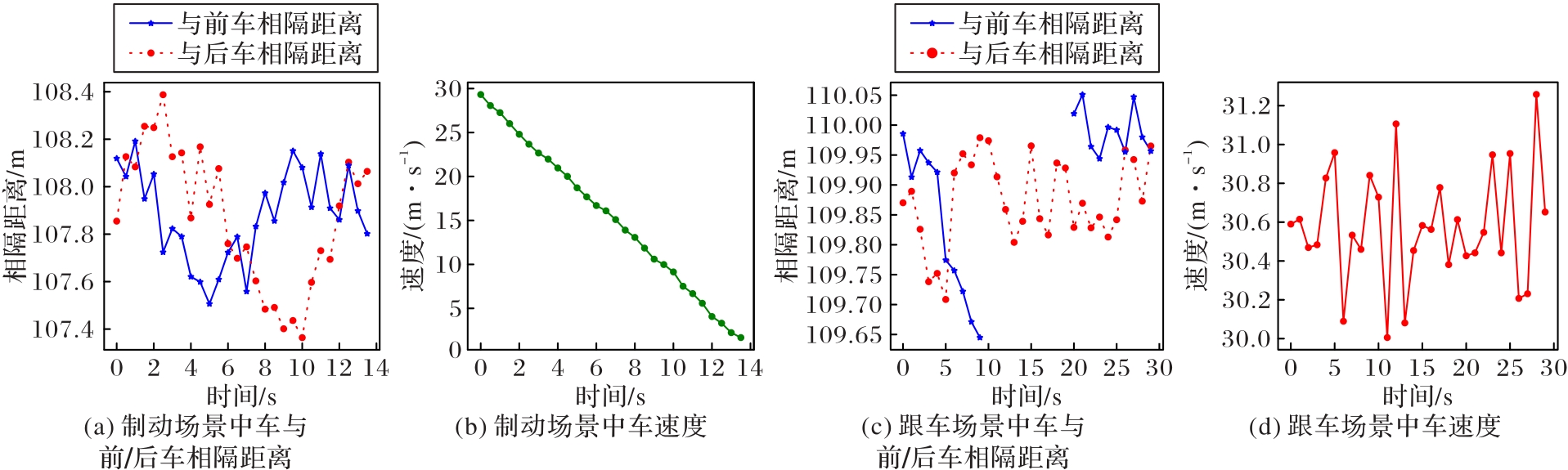
图9 高速公路仿真
Fig. 9 Simulation of highway
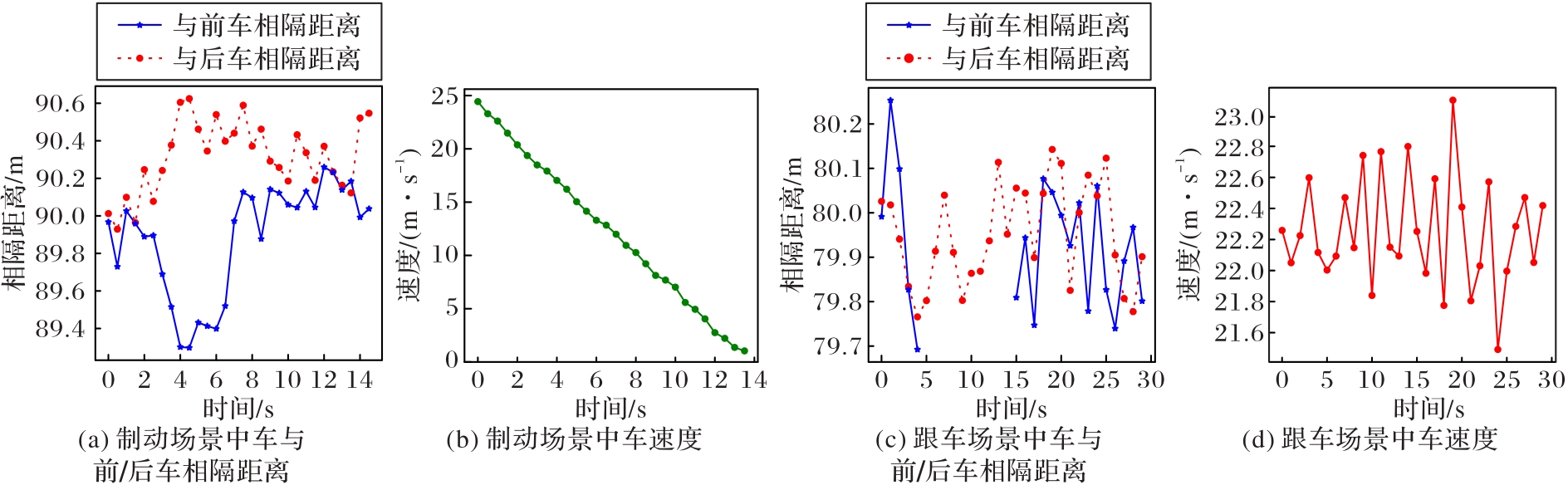
图10 城市快速路仿真
Fig. 10 Simulation of urban expressway
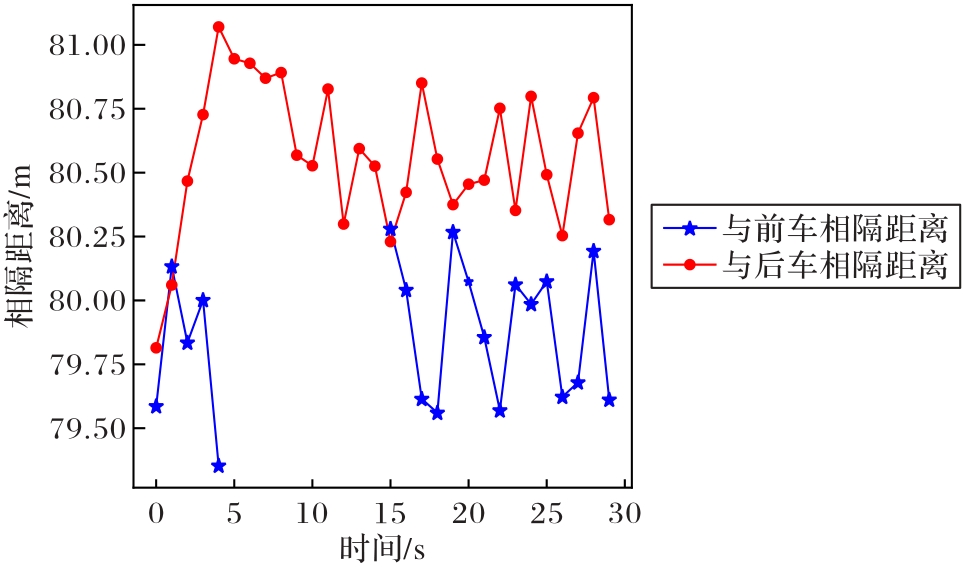
图11 城市快速路跟车场景下中车与前/后车相隔的距离
Fig. 11 Time curve between middle vehicle and preceding/following vehicles in urban expressway car-following scenario
| [1] | 李克强,戴一凡,李升波,等. 智能网联汽车(ICV)技术的发展现状及趋势[J]. 汽车安全与节能学报, 2017, 8(1): 1-14. |
| LI K Q, DAI Y F, LI S B, et al. State-of-the-art and technical trends of intelligent and connected vehicles[J]. Journal of Automotive Safety and Energy, 2017, 8(1): 1-14. | |
| [2] | 陈虹,郭露露,宫洵,等.智能时代的汽车控制[J].自动化学报,2020,46(7):1313-1332. |
| CHEN H, GUO L L, GONG X, et al. Automotive control in intelligent era[J]. Acta Automatica Sinica, 2020, 46(7): 1313-1332. | |
| [3] | 熊璐,杨兴,卓桂荣,等.无人驾驶车辆的运动控制发展现状综述[J].机械工程学报,2020,56(10):127-143. |
| XIONG L, YANG X, ZHUO G R, et al. Review on motion control of autonomous vehicles[J]. Journal of Mechanical Engineering, 2020, 56(10): 127-143. | |
| [4] | 韩磊,张轮,郭为安.混合交通流环境下基于MSIF-DRL的网联自动驾驶车辆换道决策模型[J].北京交通大学学报,2023,47(5):148-161. |
| HAN L, ZHANG L, GUO W A. Lane-changing decision-making model for connected and automated vehicles based on MSIF-DRL in a mixed traffic environment[J]. Journal of Beijing Jiaotong University, 2023, 47(5): 148-161. | |
| [5] | 金立生,谢宪毅,司法,等.考虑驾驶人特性的智能驾驶路径跟踪算法[J].汽车工程,2021,43(4):553-561. |
| JIN L S, XIE X Y, SI F, et al. Intelligent driving path tracking algorithm considering driver characteristics[J]. Automotive Engineering, 2021, 43(4): 553-561. | |
| [6] | XIE J, GONG J, WU S, et al. A personalized curve driving model for intelligent vehicle[C]// Proceedings of the 2017 IEEE International Conference on Unmanned Systems. Piscataway: IEEE, 2017: 301-306. |
| [7] | 李金瑜,宋非,斯白露.生物导航机制启发的智能驾驶路径规划技术综述[J].人工智能,2023(5):70-77. |
| LI J Y, SONG F, SI B L. A review of intelligent driving path planning technology inspired by biological navigation mechanism[J]. AI-View, 2023(5): 70-77. | |
| [8] | 康腾. 基于遗传算法的智能驾驶车辆纵向PID控制研究[J]. 汽车文摘, 2022(10): 52-56. |
| KANG T. Research on longitudinal PID control of intelligent driving vehicle based on genetic algorithm[J]. Automotive Digest, 2022(10): 52-56. | |
| [9] | 赵春宇,赖俊.元强化学习综述[J].计算机应用研究,2023,40(1): 1-10. |
| ZHAO C Y, LAI J. Survey on meta reinforcement learning[J]. Application Research of Computers, 2023, 40(1): 1-10. | |
| [10] | 国子婧,冯旸赫,姚晨蝶,等.基于人类先验知识的强化学习综述[J].计算机应用,2021,41(S2):1-4. |
| GUO Z J, FENG Y H, YAO C D, et al. Survey of reinforcement learning based on human prior knowledge[J]. Journal of Computer Applications, 2021, 41(S2): 1-4. | |
| [11] | 韩磊,张轮,郭为安.混合交通流环境下基于改进强化学习的可变限速控制策略[J].交通运输系统工程与信息,2023,23(3): 110-122. |
| HAN L, ZHANG L, GUO W A. Variable speed limit control based on improved dueling double deep Q network under mixed traffic environment[J]. Journal of Transportation Systems Engineering and Information Technology, 2023, 23(3): 110-122. | |
| [12] | CHALMERS E, CONTRERAS E B, ROBERTSON B, et al. Learning to predict consequences as a method of knowledge transfer in reinforcement learning[J]. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(6): 2259-2270. |
| [13] | 朱美强,李明,程玉虎,等.基于拉普拉斯特征映射的启发式Q学习[J].控制与决策,2014,29(3):425-430. |
| ZHU M Q, LI M, CHENG Y H, et al. Heuristically accelerated Q-learning algorithm based on Laplacian Eigenmap[J]. Control and Decision, 2014, 29(3): 425-430. | |
| [14] | 韩红桂,徐子昂,王晶晶.基于Q学习的多任务多目标粒子群优化算法[J].控制与决策,2023,38(11):3039-3047. |
| HAN H G, XU Z A, WANG J J. A Q-learning-based multi-task multi-objective particle swarm optimization algorithm[J]. Control and Decision, 2023, 38(11): 3039-3047. | |
| [15] | TAN B, PENG Y, LIN J. A local path planning method based on Q-learning[C]// Proceedings of the 2021 International Conference on Signal Processing and Machine Learning. Piscataway: IEEE, 2021: 80-84. |
| [16] | JANG H C, LEE C Y. Study on Q-learning and deep Q-learning in urban roadside parking space search[C]// Proceedings of the 2022 International Conference on Computational Science and Computational Intelligence. Piscataway: IEEE, 2022: 1248-1253. |
| [17] | 赵冬斌,邵坤,朱圆恒,等.深度强化学习综述:兼论计算机围棋的发展[J].控制理论与应用,2016,33(6):701-717. |
| ZHAO D B, SHAO K, ZHU Y H, et al. Review of deep reinforcement learning and discussions on the development of computer Go[J]. Control Theory and Applications, 2016, 33(6): 701-717. | |
| [18] | LYU L, SHEN Y, ZHANG S. The advance of reinforcement learning and deep reinforcement learning[C]// Proceedings of the 2022 IEEE International Conference on Electrical Engineering, Big Data and Algorithms. Piscataway: IEEE, 2022: 644-648. |
| [19] | 王壮,周少武,陈祉达,等. 面向冲突解脱的强化学习模型奖励函数研究[J]. 中国民航飞行学院学报, 2023, 34(6): 10-15. |
| WANG Z, ZHOU S W, CHEN Z D, et al. Research of reward function design in reinforcement learning method for conflict resolution[J]. Journal of Civil Aviation Flight University of China, 2023, 34(6): 10-15. | |
| [20] | 余欣磊,周贤文,张依恋,等.基于区间分块Q学习的智能车辆安全舒适刹车算法[J].计算机应用研究,2024,41(1):183-187. |
| YU X L, ZHOU X W, ZHANG Y L, et al. Interval-block-based Q-learning algorithm for safe and comfortable braking of intelligent vehicles[J]. Application Research of Computers, 2024, 41(1): 183-187. |
| [1] | 郭新明, 刘蕊, 谢飞, 林德钰. 无线视频传感器网络β-QoM目标栅栏覆盖构建算法[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2877-2884. |
| [2] | 林东东, 李曼曼, 陈少真. 基于神经区分器的KATAN48算法条件差分分析方法[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2462-2470. |
| [3] | 石一鹏, 刘杰, 祖锦源, 张涛, 张国群. 基于混合整数线性规划模型的SPONGENT S盒紧凑约束分析[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1504-1510. |
| [4] | 徐周波, 陈浦青, 刘华东, 杨欣. 基于自注意力网络的深度图匹配模型[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 1005-1012. |
| [5] | 于振华, 刘争气, 刘颖, 郭城. 基于自适应混合粒子群优化的软件缺陷预测特征选择方法[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 1206-1213. |
| [6] | 姚华勇, 叶东毅, 陈昭炯. 考虑多粒度反馈的多轮对话强化学习推荐算法[J]. 《计算机应用》唯一官方网站, 2023, 43(1): 15-21. |
| [7] | 姜松岩, 廖晓鹃, 陈光柱. 基于可满足性模理论的多处理机通信延迟优化任务调度方法[J]. 《计算机应用》唯一官方网站, 2023, 43(1): 185-191. |
| [8] | 赵海妮, 焦健. 基于强化学习的渗透路径推荐模型[J]. 《计算机应用》唯一官方网站, 2022, 42(6): 1689-1694. |
| [9] | 郑延斌, 樊文鑫, 韩梦云, 陶雪丽. 基于博弈论及Q学习的多Agent协作追捕算法[J]. 计算机应用, 2020, 40(6): 1613-1620. |
| [10] | 刘宗甫, 袁征, 赵晨曦, 朱亮. 对PICO算法基于可分性的积分攻击[J]. 计算机应用, 2020, 40(10): 2967-2972. |
| [11] | 杨晓华, 郭健全. 模糊环境下多周期多决策生鲜闭环物流网络[J]. 计算机应用, 2019, 39(7): 2168-2174. |
| [12] | 郑红星, 王泉慧, 任亚群. 考虑潮汐影响的班轮多船型船舶调度[J]. 计算机应用, 2019, 39(2): 611-617. |
| [13] | 范晓波, 李兴明. 基于线性松弛方法的网络故障链路诊断[J]. 计算机应用, 2018, 38(7): 2005-2008. |
| [14] | 丁静文, 陈树越, 陆贵荣. 基于Q学习算法的X光主动视觉安检方法[J]. 计算机应用, 2018, 38(12): 3414-3418. |
| [15] | 袁亚男, 王鹏, 刘峰. 多尺度量子谐振子算法性能分析[J]. 计算机应用, 2015, 35(6): 1600-1604. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||