


《计算机应用》唯一官方网站 ›› 2026, Vol. 46 ›› Issue (4): 1034-1041.DOI: 10.11772/j.issn.1001-9081.2025040452
韩雨晨1,2,3, 徐峰磊1, 吕凡4, 姚睿5, 胡伏原1,2,3( )
)
收稿日期:2025-04-23
修回日期:2025-07-29
接受日期:2025-07-31
发布日期:2025-08-11
出版日期:2026-04-10
通讯作者:
胡伏原
作者简介:韩雨晨(2000—),女,江苏南京人,硕士研究生,CCF会员,主要研究方向:机器学习、连续学习基金资助:
Yuchen HAN1,2,3, Fenglei XU1, Fan LYU4, Rui YAO5, Fuyuan HU1,2,3()
Received:2025-04-23
Revised:2025-07-29
Accepted:2025-07-31
Online:2025-08-11
Published:2026-04-10
Contact:
Fuyuan HU
About author:HAN Yuchen, born in 2000, M. S. candidate. Her research interests include machine learning, continual learning.Supported by:摘要:
无边界在线连续学习是一种任务无关的自主高效机器学习方法,通过连续适应新数据和抑制遗忘实现模型的动态更新。现有在线连续学习方法通常追求模型准确率而牺牲计算效率,这使得在高速数据流场景中,模型因训练速度滞后,难以及时响应数据流的变化。针对以上问题,提出一种面向效率?性能协同优化的在线稀疏连续学习框架,通过构建双向稀疏自适应调控机制突破传统方法的瓶颈。首先,设计参数重要性度量的动态稀疏拓扑优化框架,融合参数敏感性分析,实现非结构化参数剪枝;其次,建立记忆?效率双目标优化模型,基于在线类别分布估计动态调节计算预算分配,实现计算资源的最优配置;最后,构建梯度解耦优化策略,采用梯度掩码方法实现新旧知识的双向优化,在加速模型更新的同时保持知识拓扑的完整性。基准测试结果表明,所提框架展现出显著优势,当内存缓冲区大小为100时,相较于基线ER(Experience Replay),在CIFAR-10数据集上,平均在线准确率(AOA)和测试准确率(TA)分别提升了4.86%和6.25%;在CIFAR-100数据集上,AOA和TA分别提升了13.77%和3.08%;在Mini-ImageNet数据集上,AOA和TA的提升幅度达17.83%和25.00%。可视化分析表明,所提框架在保持实时响应能力的同时,成功捕获了数据流中的潜在概念漂移模式。可见,所提框架突破了传统方法在计算效率与模型性能间的权衡困境,为开放环境下的在线连续学习系统建立了新范式。
中图分类号:
韩雨晨, 徐峰磊, 吕凡, 姚睿, 胡伏原. 高速数据流下无边界在线稀疏连续学习方法[J]. 计算机应用, 2026, 46(4): 1034-1041.
Yuchen HAN, Fenglei XU, Fan LYU, Rui YAO, Fuyuan HU. Task-free online sparse continual learning method for high-speed data streams[J]. Journal of Computer Applications, 2026, 46(4): 1034-1041.
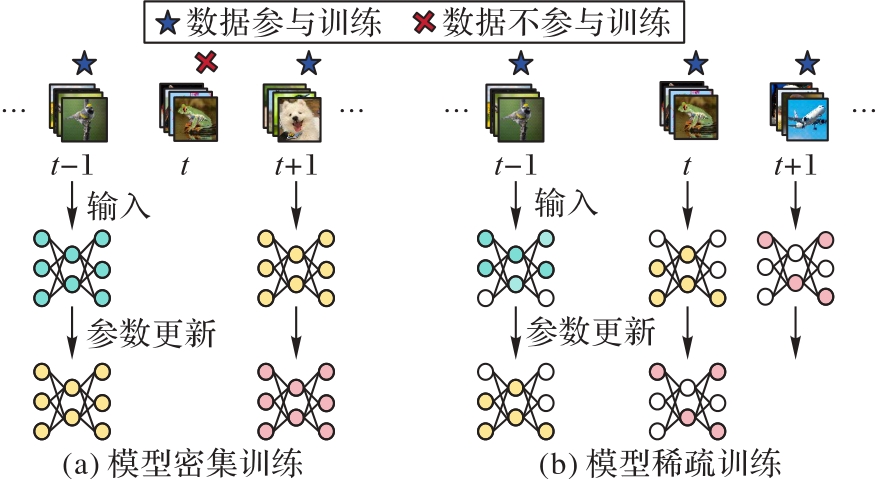
图1 在线连续学习模型的密集和稀疏训练
Fig. 1 Dense and sparse training of online continual learning models
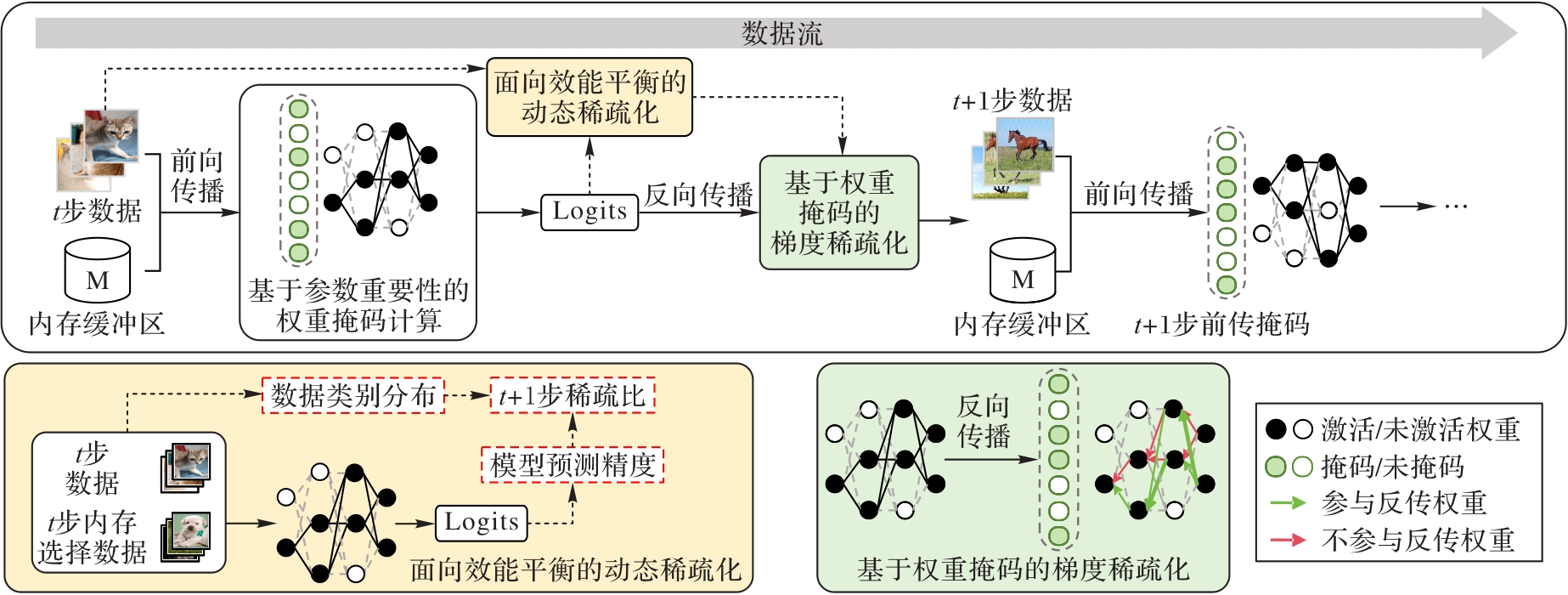
图2 无边界在线稀疏连续学习框架
Fig. 2 Task-free online sparse continual learning framework
内存缓冲区 大小 | 方法 | CIFAR-10 | CIFAR-100 | Mini-ImageNet | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| AOA/% | TA/% | 运算浮点数/GFLOPs | AOA/% | TA/% | 运算浮点数/GFLOPs | AOA/% | TA/% | 运算浮点数/GFLOPs | ||
| 100 | ACE | 53.05 | 67.01 | 657.93 | 12.15 | 17.92 | 666.64 | 16.07 | 0.99 | 5 205.41 |
| GSS | 33.67 | 43.69 | 3 947.58 | 5.45 | 7.86 | 3 999.81 | 8.43 | 1.16 | 31 232.48 | |
| LwF | 49.08 | 59.07 | 877.24 | 10.99 | 17.98 | 888.85 | 14.85 | 0.75 | 5 783.41 | |
| MIR | 43.55 | 55.24 | 1 644.83 | 9.31 | 14.57 | 1 666.60 | 12.62 | 0.75 | 13 013.54 | |
| RWalk | 42.22 | 54.72 | 1 315.86 | 7.46 | 12.23 | 1 333.28 | 11.35 | 1.25 | 10 410.83 | |
| ER | 51.60 | 63.97 | 657.93 | 11.55 | 17.86 | 666.64 | 14.13 | 0.92 | 5 205.41 | |
| X-DER | 52.39 | 64.39 | 822.42 | 11.95 | 17.38 | 833.30 | 14.85 | 0.93 | 6 506.77 | |
| EARL | 52.82 | 64.93 | 1 291.83 | 12.01 | 17.72 | 1 308.93 | 15.41 | 1.04 | 10 220.71 | |
| DPCL | 52.73 | 64.29 | 756.76 | 11.98 | 17.93 | 766.77 | 15.38 | 0.93 | 5 987.27 | |
| 本文方法 | 54.11 | 67.97 | 162.51 | 13.14 | 18.41 | 181.33 | 16.65 | 1.15 | 1 395.05 | |
| 300 | ACE | 56.77 | 68.69 | 657.93 | 13.87 | 20.89 | 666.64 | 16.76 | 1.23 | 5 205.41 |
| GSS | 35.58 | 44.03 | 3 947.58 | 6.07 | 9.63 | 3 999.81 | 8.57 | 1.32 | 31 232.48 | |
| LwF | 50.74 | 61.95 | 877.24 | 13.83 | 22.82 | 888.85 | 17.64 | 1.01 | 5 783.41 | |
| MIR | 46.63 | 59.62 | 1 644.83 | 9.64 | 15.33 | 1 666.60 | 12.91 | 0.87 | 13 013.54 | |
| RWalk | 45.61 | 57.88 | 1 315.86 | 9.75 | 14.86 | 1 333.28 | 13.21 | 1.13 | 10 410.83 | |
| ER | 54.15 | 65.82 | 657.93 | 12.82 | 20.09 | 666.64 | 15.70 | 1.13 | 5 205.41 | |
| X-DER | 54.35 | 66.16 | 822.42 | 13.28 | 20.75 | 833.30 | 15.59 | 1.14 | 6 506.77 | |
| EARL | 55.03 | 66.71 | 1 291.83 | 14.62 | 21.83 | 1 308.93 | 16.28 | 1.16 | 10 220.71 | |
| DPCL | 55.29 | 65.93 | 756.76 | 14.28 | 21.39 | 766.77 | 16.03 | 1.14 | 5 987.27 | |
| 本文方法 | 57.17 | 68.81 | 162.51 | 15.02 | 23.32 | 181.33 | 17.66 | 1.31 | 1 395.05 | |
| 500 | ACE | 57.32 | 69.62 | 657.93 | 14.39 | 21.21 | 666.64 | 17.82 | 0.90 | 5 205.41 |
| GSS | 35.86 | 44.13 | 3 947.58 | 6.41 | 9.66 | 3 999.81 | 8.28 | 1.70 | 31 232.48 | |
| LwF | 51.22 | 62.53 | 877.24 | 14.47 | 23.26 | 888.85 | 18.29 | 1.10 | 5 783.41 | |
| MIR | 45.96 | 57.56 | 1 644.83 | 10.38 | 15.08 | 1 666.60 | 13.52 | 1.23 | 13 013.54 | |
| RWalk | 45.59 | 56.68 | 1 315.86 | 10.33 | 15.61 | 1 333.28 | 13.89 | 1.06 | 10 410.83 | |
| ER | 55.53 | 65.09 | 657.93 | 13.13 | 20.95 | 666.64 | 16.62 | 0.94 | 5 205.41 | |
| X-DER | 55.94 | 66.30 | 822.42 | 13.94 | 21.04 | 833.30 | 16.40 | 0.94 | 6 506.77 | |
| EARL | 56.28 | 67.83 | 1 291.83 | 14.02 | 21.38 | 1 308.93 | 17.03 | 1.01 | 10 220.71 | |
| DPCL | 55.38 | 66.94 | 756.76 | 13.84 | 20.93 | 766.77 | 16.93 | 0.96 | 5 987.27 | |
| 本文方法 | 57.79 | 70.33 | 162.51 | 15.58 | 22.75 | 181.33 | 18.41 | 1.76 | 1 395.05 | |
表1 不同方法的实验结果比较
Tab. 1 Comparison of experimental results of different methods
内存缓冲区 大小 | 方法 | CIFAR-10 | CIFAR-100 | Mini-ImageNet | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| AOA/% | TA/% | 运算浮点数/GFLOPs | AOA/% | TA/% | 运算浮点数/GFLOPs | AOA/% | TA/% | 运算浮点数/GFLOPs | ||
| 100 | ACE | 53.05 | 67.01 | 657.93 | 12.15 | 17.92 | 666.64 | 16.07 | 0.99 | 5 205.41 |
| GSS | 33.67 | 43.69 | 3 947.58 | 5.45 | 7.86 | 3 999.81 | 8.43 | 1.16 | 31 232.48 | |
| LwF | 49.08 | 59.07 | 877.24 | 10.99 | 17.98 | 888.85 | 14.85 | 0.75 | 5 783.41 | |
| MIR | 43.55 | 55.24 | 1 644.83 | 9.31 | 14.57 | 1 666.60 | 12.62 | 0.75 | 13 013.54 | |
| RWalk | 42.22 | 54.72 | 1 315.86 | 7.46 | 12.23 | 1 333.28 | 11.35 | 1.25 | 10 410.83 | |
| ER | 51.60 | 63.97 | 657.93 | 11.55 | 17.86 | 666.64 | 14.13 | 0.92 | 5 205.41 | |
| X-DER | 52.39 | 64.39 | 822.42 | 11.95 | 17.38 | 833.30 | 14.85 | 0.93 | 6 506.77 | |
| EARL | 52.82 | 64.93 | 1 291.83 | 12.01 | 17.72 | 1 308.93 | 15.41 | 1.04 | 10 220.71 | |
| DPCL | 52.73 | 64.29 | 756.76 | 11.98 | 17.93 | 766.77 | 15.38 | 0.93 | 5 987.27 | |
| 本文方法 | 54.11 | 67.97 | 162.51 | 13.14 | 18.41 | 181.33 | 16.65 | 1.15 | 1 395.05 | |
| 300 | ACE | 56.77 | 68.69 | 657.93 | 13.87 | 20.89 | 666.64 | 16.76 | 1.23 | 5 205.41 |
| GSS | 35.58 | 44.03 | 3 947.58 | 6.07 | 9.63 | 3 999.81 | 8.57 | 1.32 | 31 232.48 | |
| LwF | 50.74 | 61.95 | 877.24 | 13.83 | 22.82 | 888.85 | 17.64 | 1.01 | 5 783.41 | |
| MIR | 46.63 | 59.62 | 1 644.83 | 9.64 | 15.33 | 1 666.60 | 12.91 | 0.87 | 13 013.54 | |
| RWalk | 45.61 | 57.88 | 1 315.86 | 9.75 | 14.86 | 1 333.28 | 13.21 | 1.13 | 10 410.83 | |
| ER | 54.15 | 65.82 | 657.93 | 12.82 | 20.09 | 666.64 | 15.70 | 1.13 | 5 205.41 | |
| X-DER | 54.35 | 66.16 | 822.42 | 13.28 | 20.75 | 833.30 | 15.59 | 1.14 | 6 506.77 | |
| EARL | 55.03 | 66.71 | 1 291.83 | 14.62 | 21.83 | 1 308.93 | 16.28 | 1.16 | 10 220.71 | |
| DPCL | 55.29 | 65.93 | 756.76 | 14.28 | 21.39 | 766.77 | 16.03 | 1.14 | 5 987.27 | |
| 本文方法 | 57.17 | 68.81 | 162.51 | 15.02 | 23.32 | 181.33 | 17.66 | 1.31 | 1 395.05 | |
| 500 | ACE | 57.32 | 69.62 | 657.93 | 14.39 | 21.21 | 666.64 | 17.82 | 0.90 | 5 205.41 |
| GSS | 35.86 | 44.13 | 3 947.58 | 6.41 | 9.66 | 3 999.81 | 8.28 | 1.70 | 31 232.48 | |
| LwF | 51.22 | 62.53 | 877.24 | 14.47 | 23.26 | 888.85 | 18.29 | 1.10 | 5 783.41 | |
| MIR | 45.96 | 57.56 | 1 644.83 | 10.38 | 15.08 | 1 666.60 | 13.52 | 1.23 | 13 013.54 | |
| RWalk | 45.59 | 56.68 | 1 315.86 | 10.33 | 15.61 | 1 333.28 | 13.89 | 1.06 | 10 410.83 | |
| ER | 55.53 | 65.09 | 657.93 | 13.13 | 20.95 | 666.64 | 16.62 | 0.94 | 5 205.41 | |
| X-DER | 55.94 | 66.30 | 822.42 | 13.94 | 21.04 | 833.30 | 16.40 | 0.94 | 6 506.77 | |
| EARL | 56.28 | 67.83 | 1 291.83 | 14.02 | 21.38 | 1 308.93 | 17.03 | 1.01 | 10 220.71 | |
| DPCL | 55.38 | 66.94 | 756.76 | 13.84 | 20.93 | 766.77 | 16.93 | 0.96 | 5 987.27 | |
| 本文方法 | 57.79 | 70.33 | 162.51 | 15.58 | 22.75 | 181.33 | 18.41 | 1.76 | 1 395.05 | |
| 稀疏度 | AOA/% | TA/% | 运算浮点数/GFLOPs |
|---|---|---|---|
| Adaptive | 13.14 | 18.41 | 181.33 |
| 0.1 | 11.82 | 18.93 | 599.97 |
| 0.2 | 10.69 | 15.26 | 533.31 |
| 0.3 | 10.41 | 15.60 | 466.65 |
| 0.4 | 10.21 | 14.89 | 399.98 |
| 0.5 | 10.08 | 15.33 | 333.32 |
| 0.6 | 9.74 | 15.03 | 266.66 |
| 0.7 | 9.62 | 14.73 | 199.99 |
| 0.8 | 9.25 | 14.44 | 133.33 |
| 0.9 | 8.47 | 13.42 | 66.66 |
表2 不同稀疏度的结果比较
Tab. 2 Comparison of results with different sparsity ratios
| 稀疏度 | AOA/% | TA/% | 运算浮点数/GFLOPs |
|---|---|---|---|
| Adaptive | 13.14 | 18.41 | 181.33 |
| 0.1 | 11.82 | 18.93 | 599.97 |
| 0.2 | 10.69 | 15.26 | 533.31 |
| 0.3 | 10.41 | 15.60 | 466.65 |
| 0.4 | 10.21 | 14.89 | 399.98 |
| 0.5 | 10.08 | 15.33 | 333.32 |
| 0.6 | 9.74 | 15.03 | 266.66 |
| 0.7 | 9.62 | 14.73 | 199.99 |
| 0.8 | 9.25 | 14.44 | 133.33 |
| 0.9 | 8.47 | 13.42 | 66.66 |
| 方法 | CIFAR-10 | CIFAR-100 | Mini-ImageNet |
|---|---|---|---|
| 基线方法 | 1 094 750 | 1 109 240 | 11 227 812 |
| 本文方法 | 270 403 | 301 713 | 3 009 054 |
表3 不同数据集上基线和本文方法的参数量对比
Tab. 3 Comparison of number of parameters of baseline and proposed method on different datasets
| 方法 | CIFAR-10 | CIFAR-100 | Mini-ImageNet |
|---|---|---|---|
| 基线方法 | 1 094 750 | 1 109 240 | 11 227 812 |
| 本文方法 | 270 403 | 301 713 | 3 009 054 |
内存缓冲区 大小 | 方法 | 时间/s | ||
|---|---|---|---|---|
| CIFAR-10 | CIFAR-100 | Mini-ImageNet | ||
| 100 | 基线方法 | 1 856.19 | 1 775.22 | 1 534.93 |
| 本文方法 | 462.19 | 488.19 | 406.76 | |
| 300 | 基线方法 | 1 865.41 | 1 795.23 | 1 563.98 |
| 本文方法 | 451.43 | 493.69 | 414.45 | |
| 500 | 基线方法 | 1 844.45 | 1 772.25 | 1 575.57 |
| 本文方法 | 453.76 | 487.45 | 422.25 | |
表4 不同数据集和内存缓冲区大小下基线和本文方法的运行时间对比
Tab. 4 Comparison of running time of baseline and proposed method on different datasets under different memory buffer sizes
内存缓冲区 大小 | 方法 | 时间/s | ||
|---|---|---|---|---|
| CIFAR-10 | CIFAR-100 | Mini-ImageNet | ||
| 100 | 基线方法 | 1 856.19 | 1 775.22 | 1 534.93 |
| 本文方法 | 462.19 | 488.19 | 406.76 | |
| 300 | 基线方法 | 1 865.41 | 1 795.23 | 1 563.98 |
| 本文方法 | 451.43 | 493.69 | 414.45 | |
| 500 | 基线方法 | 1 844.45 | 1 772.25 | 1 575.57 |
| 本文方法 | 453.76 | 487.45 | 422.25 | |
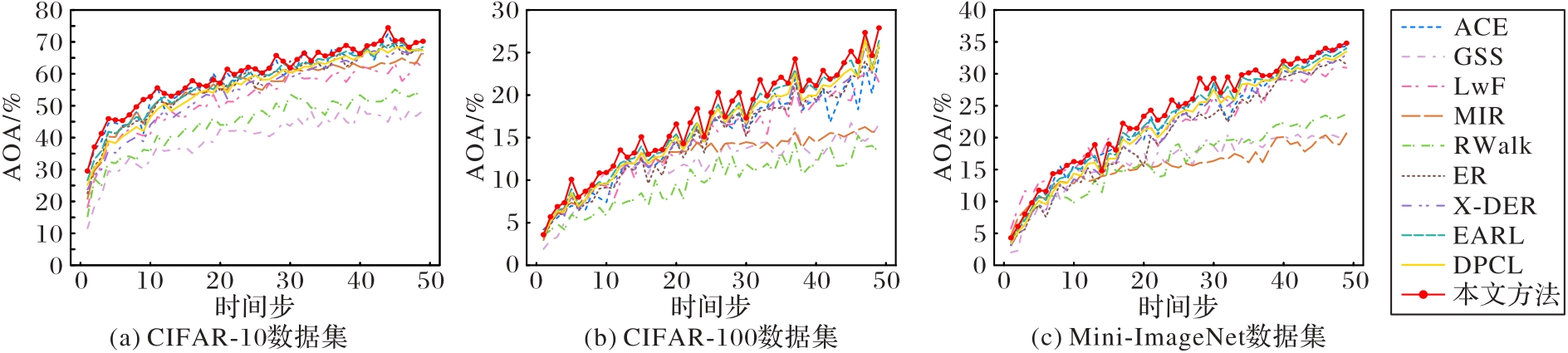
图3 不同方法在3种数据集上的平均在线准确率比较
Fig. 3 Comparison of average online accuracy of different methods on three datasets
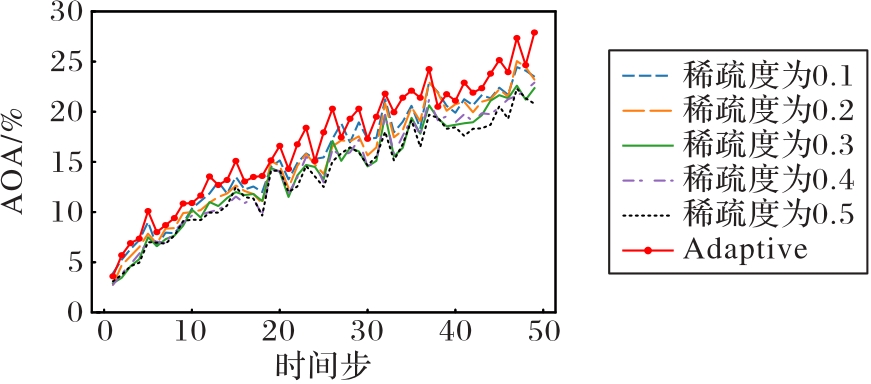
图4 不同稀疏度下的AOA对比
Fig. 4 AOA comparison under different sparsity ratios
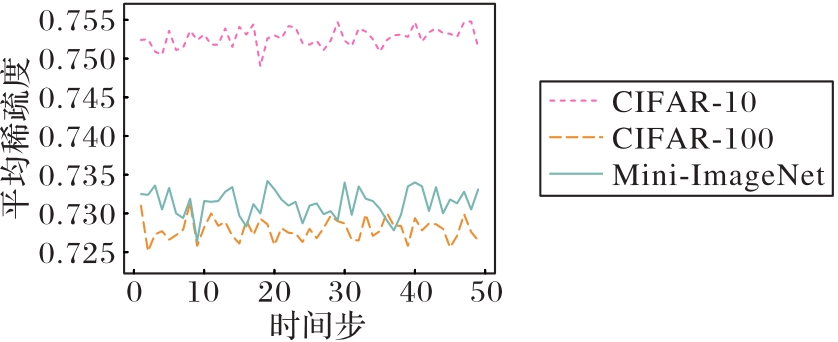
图5 不同数据集上的动态稀疏度变化
Fig. 5 Dynamic sparsity variation on different datasets
| 组号 | MWI | AS | CGI | AOA/% | TA/% | 运算浮点数/GFLOPs |
|---|---|---|---|---|---|---|
| 1 | × | × | × | 11.55 | 17.86 | 666.64 |
| 2 | × | × | √ | 12.82 | 20.28 | 577.75 |
| 3 | √ | × | × | 10.74 | 16.78 | 622.20 |
| 4 | × | √ | √ | 13.46 | 18.77 | 343.10 |
| 5 | √ | × | √ | 12.20 | 18.05 | 533.31 |
| 6 | √ | √ | × | 12.29 | 18.92 | 504.87 |
| 7 | √ | √ | √ | 13.14 | 18.41 | 181.33 |
表5 消融实验结果
Tab. 5 Ablation study results
| 组号 | MWI | AS | CGI | AOA/% | TA/% | 运算浮点数/GFLOPs |
|---|---|---|---|---|---|---|
| 1 | × | × | × | 11.55 | 17.86 | 666.64 |
| 2 | × | × | √ | 12.82 | 20.28 | 577.75 |
| 3 | √ | × | × | 10.74 | 16.78 | 622.20 |
| 4 | × | √ | √ | 13.46 | 18.77 | 343.10 |
| 5 | √ | × | √ | 12.20 | 18.05 | 533.31 |
| 6 | √ | √ | × | 12.29 | 18.92 | 504.87 |
| 7 | √ | √ | √ | 13.14 | 18.41 | 181.33 |
| [1] | KIRKPATRICK J, PASCANU R, RABINOWITZ N, et al. Overcoming catastrophic forgetting in neural networks[J]. National Academy of Sciences of the United States of America, 2017, 114(13): 3521-3526. |
| [2] | ALFARRA M, CAI Z, BIBI A, et al. SimCS: simulation for domain incremental online continual segmentation[C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 10795-10803. |
| [3] | YE F, BORS A G. Task-free continual learning via online discrepancy distance learning[C]// Proceedings of the 36th Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 23675-23688. |
| [4] | 李文斌,熊亚锟,范祉辰,等. 持续学习的研究进展与趋势[J]. 计算机研究与发展, 2024, 61(6): 1476-1496. |
| LI W B, XIONG Y K, FAN Z C, et al. Advances and trends of continual learning[J]. Journal of Computer Research and Development, 2024, 61(6): 1476-1496. | |
| [5] | 王卓,瞿绍军. 深度学习实时语义分割研究进展和挑战[J]. 中国图象图形学报, 2024, 29(5): 1188-1220. |
| WANG Z, QU S J. Research progress and challenges in real-time semantic segmentation for deep learning[J]. Journal of Image and Graphics, 2024, 29(5): 1188-1220. | |
| [6] | CAI Z, SENER O, KOLTUN V. Online continual learning with natural distribution shifts: an empirical study with visual data[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 8261-8270. |
| [7] | LI Z, HOIEM D. Learning without forgetting[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(12): 2935-2947. |
| [8] | MOCANU D C, MOCANU E, STONE P, et al. Scalable training of artificial neural networks with adaptive sparse connectivity inspired by network science[J]. Nature Communications, 2018, 9: No.2383. |
| [9] | ALJUNDI R, KELCHTERMANS K, TUYTELAARS T. Task-free continual learning[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 11246-11255. |
| [10] | ALJUNDI R, CACCIA L, BELILOVSKY E, et al. Online continual learning with maximal interfered retrieval[C]// Proceedings of the 33rd Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 11872-11883. |
| [11] | ALJUNDI R, LIN M, GOUJAUD B, et al. Gradient based sample selection for online continual learning[C]// Proceedings of the 33rd Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 11817-11826. |
| [12] | LANGE M D, TUYTELAARS T. Continual prototype evolution: learning online from nonstationary data streams[C]// Proceedings of the 2021 International Conference on Computer Vision. Piscataway: IEEE, 2021: 8250-8259. |
| [13] | JIN X, SADHU A, DU J, et al. Gradient-based editing of memory examples for online task-free continual learning[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 29193-29205. |
| [14] | CHAUDHRY A, DOKANIA P K, AJANTHAN T, et al. Riemannian walk for incremental learning: understanding forgetting and intransigence[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11215. Cham: Springer, 2018: 556-572. |
| [15] | WANG Z, JIAN T, CHOWDHURY K, et al. Learn-prune-share for lifelong learning[C]// Proceedings of the 2020 IEEE International Conference on Data Mining. Piscataway: IEEE, 2020: 641-650. |
| [16] | DETTMERS T, ZETTLEMOYER L. Sparse networks from scratch: faster training without losing performance[EB/OL]. [2019-08-23].. |
| [17] | YAN S, XIE J, HE X. DER: dynamically expandable representation for class incremental learning[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 3013-3022. |
| [18] | ADEL T. Similarity-based adaptation for task-aware and task-free continual learning[J]. Journal of Artificial Intelligence Research, 2024, 80: 377-417. |
| [19] | YE F, BORS A G. Task-free dynamic sparse vision transformer for continual learning[C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 16442-16450. |
| [20] | YE F, BORS A G. Continual variational autoencoder learning via online cooperative memorization[C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13683. Cham: Springer, 2022: 531-549. |
| [21] | KRIZHEVSKY A. Learning multiple layers of features from tiny images[R/OL]. [2025-04-08].. |
| [22] | VINYALS O, BLUNDELL C, LILLICRAP T, et al. Matching networks for one shot learning[C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2016: 3637-3645. |
| [23] | 周大蔚,汪福运,叶翰嘉,等. 基于深度学习的类别增量学习算法综述[J]. 计算机学报, 2023, 46(8): 1577-1605. |
| ZHOU D W, WANG F Y, YE H J, et al. Deep learning for class-incremental learning: a survey[J]. Chinese Journal of Computers, 2023, 46(8): 1577-1605. | |
| [24] | ZHU X, YI J, ZHANG L. Continual learning with unknown task boundary[J]. IEEE Transactions on Neural Networks and Learning Systems, 2025, 36(5): 8140-8152. |
| [25] | CHEN X, LI H, LI M, et al. Learning a sparse Transformer network for effective image deraining[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 5896-5905. |
| [26] | WANG Z, ZHAN Z, GONG Y, et al. SparCL: sparse continual learning on the edge[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 20366-20380. |
| [27] | GHUNAIM Y, BIBI A, ALHAMOUD K, et al. Real-time evaluation in online continual learning: a new hope[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 11888-11897. |
| [28] | CHAUDHRY A, ROHRBACH M, ELHOSEINY M, et al. Continual learning with tiny episodic memories[EB/OL]. [2019-02-27].. |
| [29] | CACCIA L, ALJUNDI R, ASADI N, et al. New insights on reducing abrupt representation change in online continual learning[EB/OL]. [2019-02-27].. |
| [30] | BOSCHINI M, BONICELLI L, BUZZEGA P, et al. Class-incremental continual learning into the eXtended DER-verse[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(5): 5497-5512. |
| [31] | SEO M, KOH H, JEUNG W, et al. Learning equi-angular representations for online continual learning[C]// Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2024: 23933-23942. |
| [32] | LEE B H, OH M H, CHUN S Y. Doubly perturbed task free continual learning[C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 13346-13354. |
| [1] | 郭书君, 任卫军, 陈倩倩, 游广飞. 基于聚类多变量时间序列模型的交通状态实时预测[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2253-2261. |
| [2] | 董永峰, 王雅琮, 董瑶, 邓亚晗. 在线学习资源推荐综述[J]. 《计算机应用》唯一官方网站, 2023, 43(6): 1655-1663. |
| [3] | 刘清华, 廖士中. 基于随机素描方法的在线核回归[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 676-682. |
| [4] | 樊海玮, 张锐驰, 安毅生, 秦佳杰. 融合知识图谱邻居双端的在线学习资源推荐算法[J]. 《计算机应用》唯一官方网站, 2022, 42(10): 3054-3059. |
| [5] | 郭一村, 陈华辉. 在线哈希算法研究综述[J]. 《计算机应用》唯一官方网站, 2021, 41(4): 1106-1112. |
| [6] | 崔艺馨, 陈晓东. Spark框架优化的大规模谱聚类并行算法[J]. 计算机应用, 2020, 40(1): 168-172. |
| [7] | 吴婉婷, 朱燕, 黄定江. 在线投资组合选择的半指数梯度策略及实证分析[J]. 计算机应用, 2019, 39(8): 2462-2467. |
| [8] | 郁顺昌, 黄定江. 基于自回归移动平均反转的在线投资组合选择[J]. 计算机应用, 2018, 38(5): 1505-1511. |
| [9] | 高庆吉, 霍璐, 牛国臣. 基于改进霍夫森林框架的多目标跟踪算法[J]. 计算机应用, 2016, 36(8): 2311-2315. |
| [10] | 刘建华, 毛可飞, 胡俊伟. 基于双线性对的无证书聚合签密方案[J]. 计算机应用, 2016, 36(6): 1558-1562. |
| [11] | 许浩锋, 凌青. 分布式在线交替方向乘子法[J]. 计算机应用, 2015, 35(6): 1595-1599. |
| [12] | 李唯实 毛晓光 谢建文. 学习者知识模型的在线学习算法[J]. 计算机应用, 2012, 32(02): 436-439. |
| [13] | 吴宗亮 窦衡. 一种新的最小二乘支持向量机稀疏化算法[J]. 计算机应用, 2009, 29(06): 1559-1581. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||