


Journal of Computer Applications ›› 2021, Vol. 41 ›› Issue (11): 3234-3241.DOI: 10.11772/j.issn.1001-9081.2021010026
Special Issue: 人工智能
• Artificial intelligence • Previous Articles Next Articles
Huaiyu ZHU1, Bo LI2( )
)
Received:2021-01-07
Revised:2021-02-03
Accepted:2021-03-23
Online:2021-04-15
Published:2021-11-10
Contact:
Bo LI
About author:ZHU Huaiyu, born in 1995, M. S. candidate. His research
interests include machine vision,artificial intelligence
朱槐雨1, 李博2()
通讯作者:
李博
作者简介:朱槐雨(1995—),男,四川自贡人,硕士研究生,主要研究方向:机器视觉、人工智能CLC Number:
Huaiyu ZHU, Bo LI. Single shot multibox detector recognition method for aerial targets of unmanned aerial vehicle[J]. Journal of Computer Applications, 2021, 41(11): 3234-3241.
朱槐雨, 李博. 单阶段多框检测器无人机航拍目标识别方法[J]. 《计算机应用》唯一官方网站, 2021, 41(11): 3234-3241.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2021010026
| 目标检测模型 | mAP/% | 帧率/(frame·s-1) |
|---|---|---|
| R-CNN | 66 | 0.02 |
| Fast R-CNN | 70 | 0.4 |
| Faster R-CNN | 73 | 7 |
| YOLO | 66 | 21 |
| SSD300 | 77 | 46 |
| SSD512 | 80 | 19 |
Tab. 1 Comparison of mAP and frame rate of different target detection models on PASCAL VOC2007 dataset
| 目标检测模型 | mAP/% | 帧率/(frame·s-1) |
|---|---|---|
| R-CNN | 66 | 0.02 |
| Fast R-CNN | 70 | 0.4 |
| Faster R-CNN | 73 | 7 |
| YOLO | 66 | 21 |
| SSD300 | 77 | 46 |
| SSD512 | 80 | 19 |

Fig. 1 SSD model structure
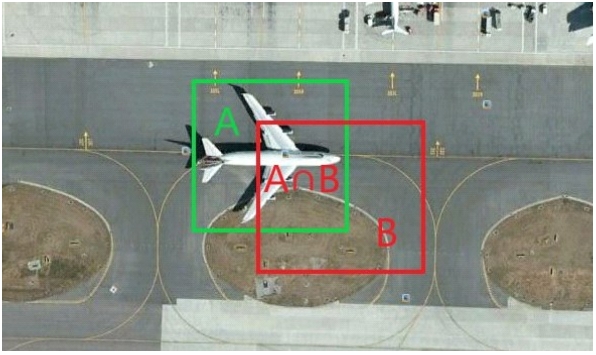
Fig. 2 IoU calculation
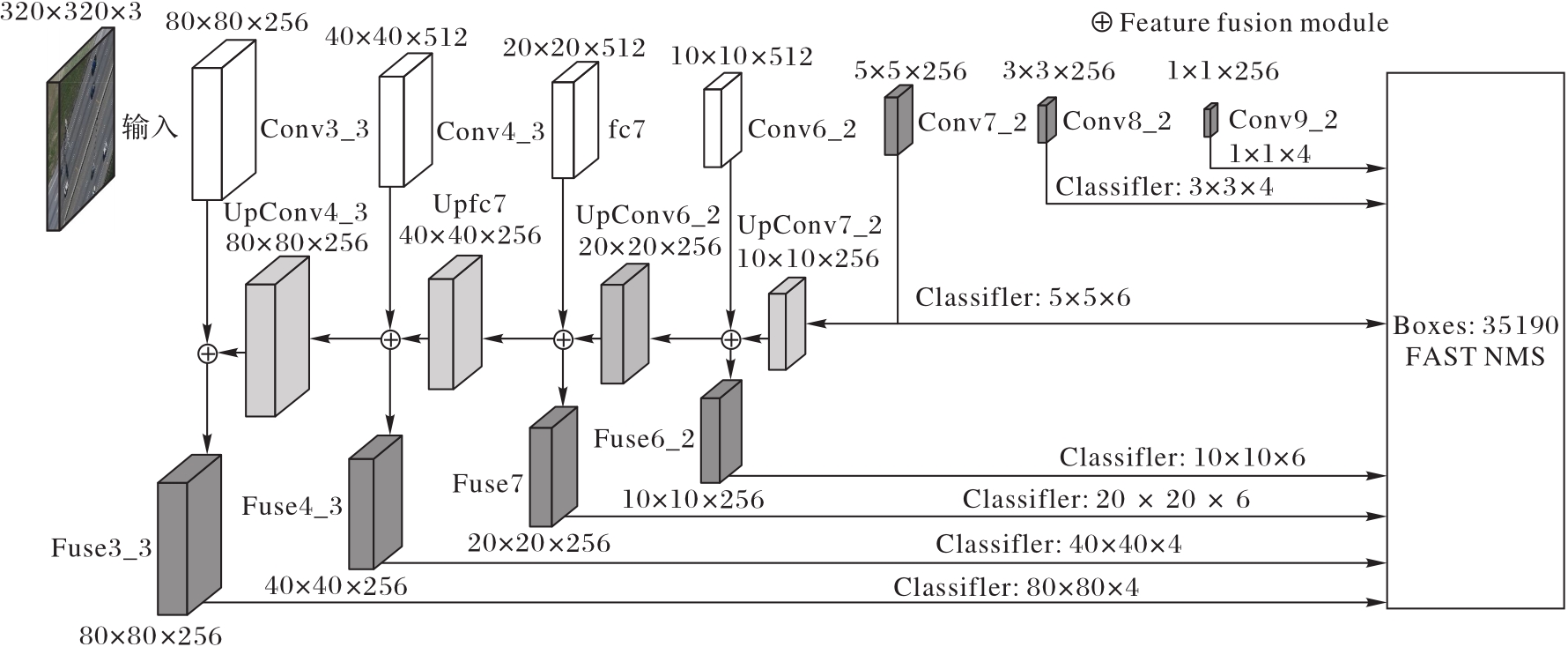
Fig. 3 CU-SSD model structure
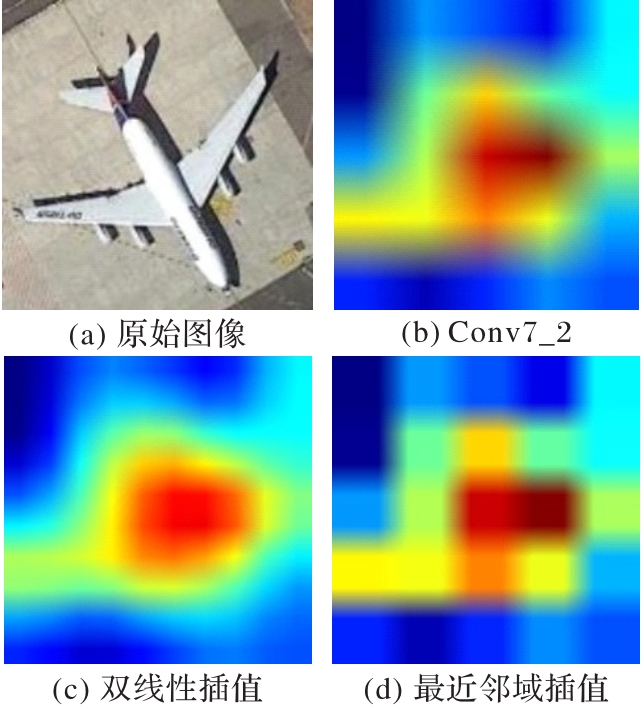
Fig. 4 Upsampling results on feature layer
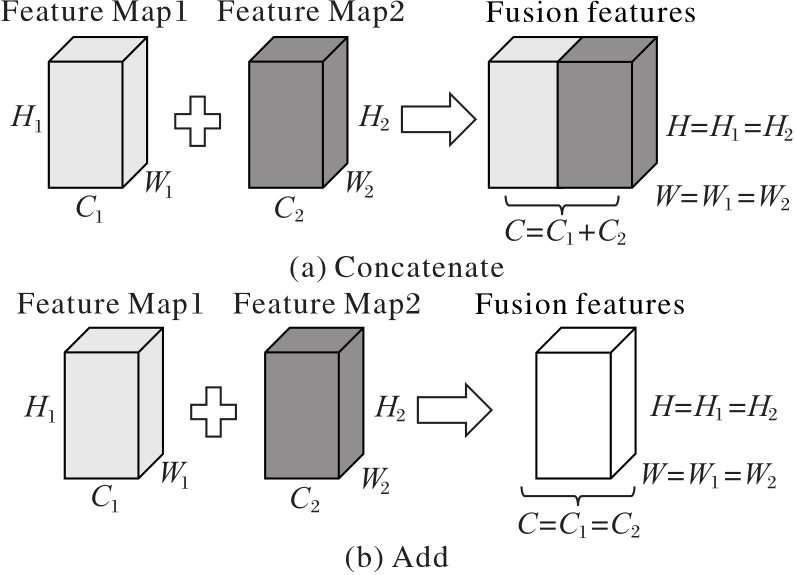
Fig. 5 Feature fusion methods
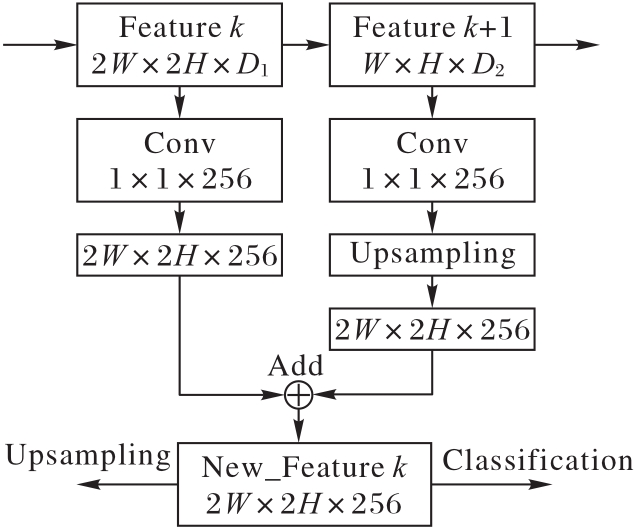
Fig. 6 Feature fusion module

Fig. 7 Heat map of Conv3_3 layer
| 特征层 | Conv3_3 | Conv4_3 | fc7 | Conv6_2 | Conv7_2 | Conv8_2 | Conv9_2 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Min_size | Max_size | Min_size | Max_size | Min_size | Max_size | Min_size | Max_size | Min_size | Max_size | Min_size | Max_size | Min_size | Max_size | |
| SSD | — | — | 30 | 60 | 60 | 111 | 111 | 162 | 152 | 213 | 213 | 264 | 264 | 315 |
| CU-SSD | 16 | 32 | 32 | 64 | 64 | 118 | 118 | 173 | 162 | 227 | 227 | 282 | 282 | 336 |
Tab. 2 Size of anchor box
| 特征层 | Conv3_3 | Conv4_3 | fc7 | Conv6_2 | Conv7_2 | Conv8_2 | Conv9_2 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Min_size | Max_size | Min_size | Max_size | Min_size | Max_size | Min_size | Max_size | Min_size | Max_size | Min_size | Max_size | Min_size | Max_size | |
| SSD | — | — | 30 | 60 | 60 | 111 | 111 | 162 | 152 | 213 | 213 | 264 | 264 | 315 |
| CU-SSD | 16 | 32 | 32 | 64 | 64 | 118 | 118 | 173 | 162 | 227 | 227 | 282 | 282 | 336 |

Fig. 8 Comparison of anchor boxes of different feature layers
| 样本 | 图像数 | 样本数 |
|---|---|---|
| 总数 | 1 510 | 14 596 |
| 飞机 | 1 000 | 7 482 |
| 汽车 | 510 | 7 114 |
Tab. 3 Dataset composition
| 样本 | 图像数 | 样本数 |
|---|---|---|
| 总数 | 1 510 | 14 596 |
| 飞机 | 1 000 | 7 482 |
| 汽车 | 510 | 7 114 |
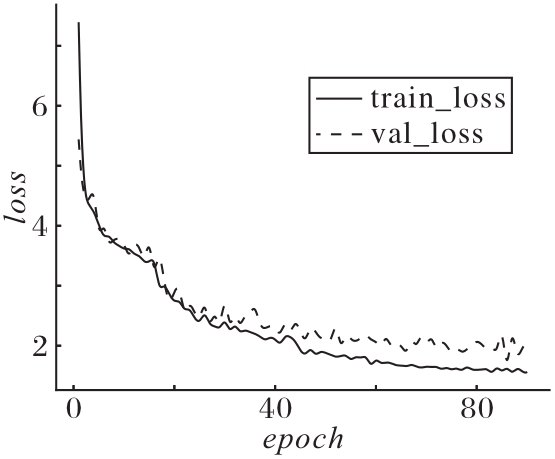
Fig. 9 Loss curves during training process
| 模型 | AP/% | mAP/% | 帧率/(frame·s-1) | Size/MB | |
|---|---|---|---|---|---|
| car | plane | ||||
| SSD | 69.33 | 91.84 | 80.58 | 13.6 | 91 |
| FSSD | 62.04 | 90.24 | 76.14 | 13.0 | 105 |
| RFBNet | 73.80 | 93.88 | 83.84 | 9.9 | 142 |
| YOLOv3 | 86.07 | 94.06 | 90.07 | 12.0 | 235 |
| CU-SSD | 93.44 | 96.12 | 94.78 | 9.0 | 79 |
Tab. 4 Performance results of different models
| 模型 | AP/% | mAP/% | 帧率/(frame·s-1) | Size/MB | |
|---|---|---|---|---|---|
| car | plane | ||||
| SSD | 69.33 | 91.84 | 80.58 | 13.6 | 91 |
| FSSD | 62.04 | 90.24 | 76.14 | 13.0 | 105 |
| RFBNet | 73.80 | 93.88 | 83.84 | 9.9 | 142 |
| YOLOv3 | 86.07 | 94.06 | 90.07 | 12.0 | 235 |
| CU-SSD | 93.44 | 96.12 | 94.78 | 9.0 | 79 |
| 融合层数 | AP/% | mAP/% | |
|---|---|---|---|
| car | plane | ||
| 0 | 89.49 | 94.34 | 91.92 |
| 2 | 90.04 | 94.84 | 92.44 |
| 3 | 90.85 | 95.06 | 92.96 |
| 4 | 92.44 | 96.24 | 94.34 |
| 5 | 93.44 | 96.12 | 94.78 |
| 6 | 93.12 | 95.90 | 94.51 |
Tab. 5 Experimental results of different feature fusion layers
| 融合层数 | AP/% | mAP/% | |
|---|---|---|---|
| car | plane | ||
| 0 | 89.49 | 94.34 | 91.92 |
| 2 | 90.04 | 94.84 | 92.44 |
| 3 | 90.85 | 95.06 | 92.96 |
| 4 | 92.44 | 96.24 | 94.34 |
| 5 | 93.44 | 96.12 | 94.78 |
| 6 | 93.12 | 95.90 | 94.51 |
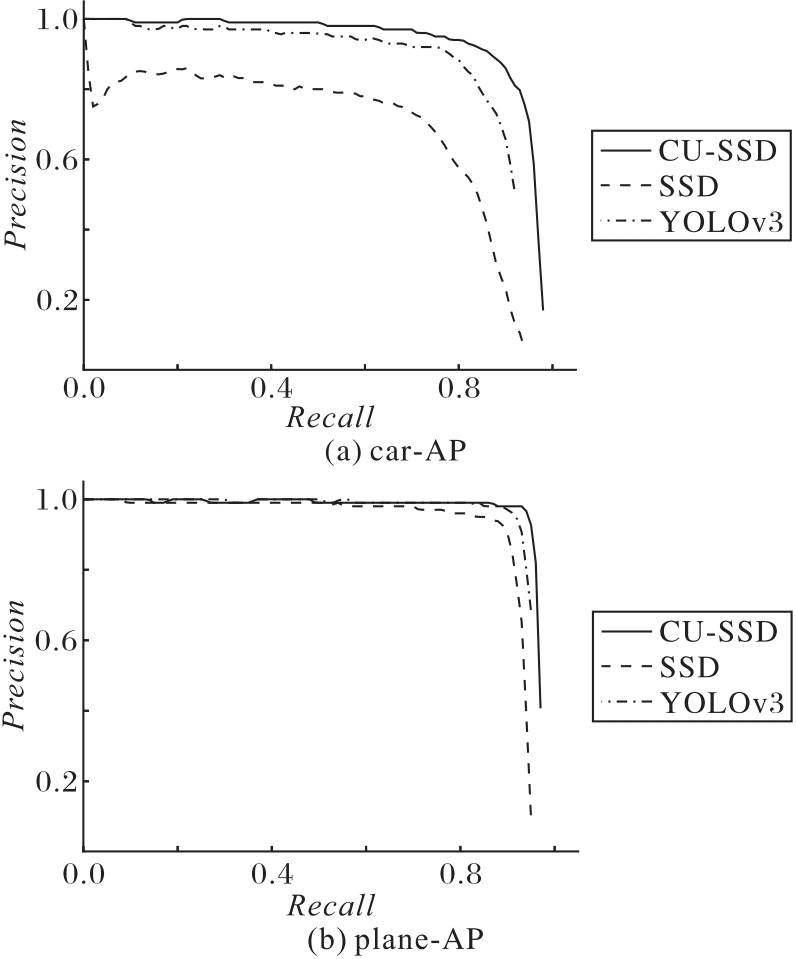
Fig. 10 P-R curves of car and plane categories
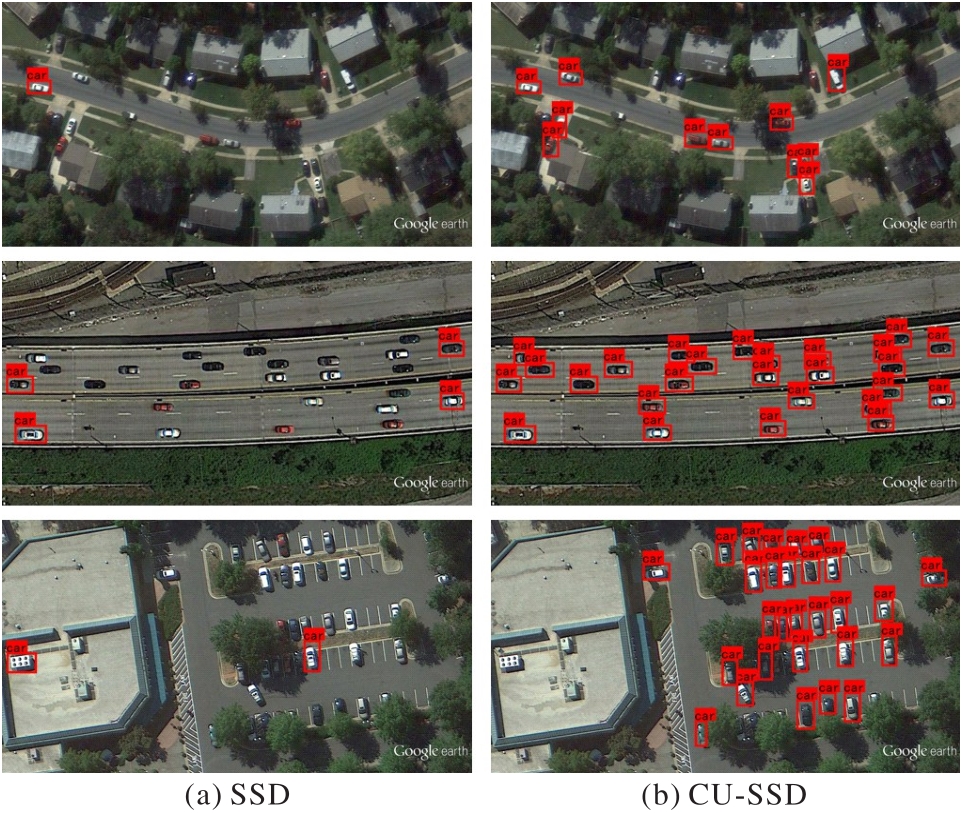
Fig. 11 Detection effects of SSD and CU-SSD on car category

Fig. 12 Detection effects of SSD and CU-SSD on plane category
| 组别 | 改进模块 | AP/% | mAP/% | 帧率/(frame·s-1) | |||
|---|---|---|---|---|---|---|---|
| Conv3_3 | Fusion | anchors | car | plane | |||
| 1 | × | × | × | 69.33 | 91.84 | 80.58 | 13.6 |
| 2 | × | √ | × | 63.78 | 90.51 | 77.15 | 12.2 |
| 3 | × | × | √ | 85.18 | 94.15 | 89.66 | 9.6 |
| 4 | × | √ | √ | 89.19 | 94.28 | 91.74 | 9.6 |
| 5 | √ | × | √ | 89.49 | 94.34 | 91.92 | 9.2 |
| 6 | √ | √ | √ | 93.44 | 96.12 | 94.78 | 9.0 |
Tab. 6 Performance comparison of different improved modules
| 组别 | 改进模块 | AP/% | mAP/% | 帧率/(frame·s-1) | |||
|---|---|---|---|---|---|---|---|
| Conv3_3 | Fusion | anchors | car | plane | |||
| 1 | × | × | × | 69.33 | 91.84 | 80.58 | 13.6 |
| 2 | × | √ | × | 63.78 | 90.51 | 77.15 | 12.2 |
| 3 | × | × | √ | 85.18 | 94.15 | 89.66 | 9.6 |
| 4 | × | √ | √ | 89.19 | 94.28 | 91.74 | 9.6 |
| 5 | √ | × | √ | 89.49 | 94.34 | 91.92 | 9.2 |
| 6 | √ | √ | √ | 93.44 | 96.12 | 94.78 | 9.0 |
| 1 | HU S, LEE G H. Image-based geo-localization using satellite imagery [J]. International Journal of Computer Vision, 2020, 128(5): 1205-1219. 10.1007/s11263-019-01186-0 |
| 2 | YANG S, CHENG H, LI T, et al. UAV reconnaissance images targeting method [C]// Proceeding of the 2016 8th International Conference on Digital Image Processing. Bellingham: SPIE, 2016: Article No.100333X. 10.1117/12.2244925 |
| 3 | WANG B, GU Y. An improved FBPN-based detection network for vehicles in aerial images [J]. Sensors, 2020, 20(17): Article No.4709. 10.3390/s20174709 |
| 4 | XIA Y, YE G X, YAN S S, et al. Application research of fast UAV aerial photography object detection and recognition based on improved YOLOv3 [J]. Journal of Physics: Conference Series, 2020, 1550: Article No.032075. 10.1088/1742-6596/1550/3/032075 |
| 5 | QIN Z W, YU F X, LIU C C, et al. How convolutional neural networks see the world — a survey of convolutional neural network visualization methods [J]. Mathematical Foundations of Computing, 2018, 1(2): 149-180. 10.3934/mfc.2018008 |
| 6 | GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2014: 580-587. 10.1109/cvpr.2014.81 |
| 7 | GIRSHICK R. Fast R-CNN [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 1440-1448. 10.1109/iccv.2015.169 |
| 8 | REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6):1137-1149. 10.1109/tpami.2016.2577031 |
| 9 | REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 779-788. 10.1109/cvpr.2016.91 |
| 10 | LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS9905. Cham: Springer, 2016: 21-37. |
| 11 | LI X L, LI X W, GUAN S J, et al. Trident SSD: a trident single-shot multibox object detector with deconvolution [J]. Journal of Physics: Conference Series, 2020, 1631: Article No.012182. 10.1088/1742-6596/1631/1/012182 |
| 12 | CAO J W, SONG C X, SONG S X, et al. Front vehicle detection algorithm for smart car based on improved SSD model [J]. Sensors, 2020, 20(16): Article No.4646. 10.3390/s20164646 |
| 13 | LI Y D, DONG H, LI H G, et al. Multi-block SSD based on small object detection for UAV railway scene surveillance [J]. Chinese Journal of Aeronautics, 2020, 33(6): 1747-1755. 10.1016/j.cja.2020.02.024 |
| 14 | HOU Z Q, LIU X Y, CHEN L L. Object detection algorithm for improving non-Maximum suppression using GIoU [J]. IOP Conference Series: Materials Science and Engineering, 2020, 790: Article No.012062. 10.1088/1757-899x/790/1/012062 |
| 15 | ZHU H T, GU C Y. Target detection algorithm introducing attention mechanism: attention_SSD [J]. International Core Journal of Engineering, 2020, 6(7): 267-275. |
| 16 | LIANG Y J, LI H H, GUO B, et al. Fusion of heterogeneous attention mechanisms in multi-view convolutional neural network for text classification [J]. Information Sciences, 2021, 548: 295-312. 10.1016/j.ins.2020.10.021 |
| 17 | 姚桐,于雪媛,王越,等.改进SSD无人机航拍小目标识别[J]. 舰船电子工程,2020,40(9):162-166. 10.3969/j.issn.1672-9730.2020.09.039 |
| YAO T, YU X H, WANG Y, et al. Improvement of small target recognition algorithm of aerial photography images based on SSD [J]. Ship Electronic Engineering, 2020, 40(9): 162-166. 10.3969/j.issn.1672-9730.2020.09.039 | |
| 18 | FU C Y, LIU W, RANGA A, et al. DSSD: deconvolutional single shot detector [EB/OL]. (2017-01-23)[2020-12-04]. . |
| 19 | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL]. (2015-04-10)[2020-12-06]. . 10.5244/c.28.6 |
| 20 | HE K M, ZHANG X Y, REN S Q, et al. Deep residual leaning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 21 | REDMON J, FARHADI A. YOLOv3: an incremental improvement [EB/OL]. (2018-04-08)[2020-12-10].. 10.1109/cvpr.2018.00430 |
| 22 | 赵爽,黄怀玉,胡一鸣,等.基于深度学习的无人机航拍车辆检测[J].计算机应用,2019,39(S2):91-96. |
| ZHAO S, HUANG H Y, HU Y M, et al. Vehicle detection in satellite imagery based on deep learning [J]. Journal of Computer Applications, 2019, 39(S2): 91-96. | |
| 23 | LI M, ZHANG Z J, LEI L P, et al. Agricultural greenhouses detection in high-resolution satellite images based on convolutional neural networks: comparison of faster R-CNN, YOLO v3 and SSD[J]. Sensors, 2020, 20(17): Article No.4938. 10.3390/s20174938 |
| 24 | 刘英杰,杨风暴,胡鹏.基于Cascade R-CNN的并行特征金字塔网络无人机航拍图像目标检测算法[J].激光与光电子学进展,2020,57(20):302-309. 10.3788/lop57.201505 |
| LIU Y J, YANG F B, HU P. Parallel FPN algorithm based on Cascade R-CNN for object detection from UAV aerial lmages [J]. Laser & Optoelectronics Progress, 2020, 57(20): 302-309. 10.3788/lop57.201505 | |
| 25 | ZHOU B L, KHOSLA A, LAPEDRIZA A, et al. Learning deep features for discriminative localization [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 2921-2929. 10.1109/cvpr.2016.319 |
| [1] | Yexin PAN, Zhe YANG. Optimization model for small object detection based on multi-level feature bidirectional fusion [J]. Journal of Computer Applications, 2024, 44(9): 2871-2877. |
| [2] | Zhangjian JI, Na DU. Tiny target detection based on improved VariFocalNet [J]. Journal of Computer Applications, 2024, 44(7): 2200-2207. |
| [3] | Ruihua LIU, Zihe HAO, Yangyang ZOU. Gait recognition algorithm based on multi-layer refined feature fusion [J]. Journal of Computer Applications, 2024, 44(7): 2250-2257. |
| [4] | Yue LIU, Fang LIU, Aoyun WU, Qiuyue CHAI, Tianxiao WANG. 3D object detection network based on self-attention mechanism and graph convolution [J]. Journal of Computer Applications, 2024, 44(6): 1972-1977. |
| [5] | Mengyuan HUANG, Kan CHANG, Mingyang LING, Xinjie WEI, Tuanfa QIN. Progressive enhancement algorithm for low-light images based on layer guidance [J]. Journal of Computer Applications, 2024, 44(6): 1911-1919. |
| [6] | Guijin HAN, Xinyuan ZHANG, Wentao ZHANG, Ya HUANG. Self-supervised image registration algorithm based on multi-feature fusion [J]. Journal of Computer Applications, 2024, 44(5): 1597-1604. |
| [7] | Hongtian LI, Xinhao SHI, Weiguo PAN, Cheng XU, Bingxin XU, Jiazheng YUAN. Few-shot object detection via fusing multi-scale and attention mechanism [J]. Journal of Computer Applications, 2024, 44(5): 1437-1444. |
| [8] | Xin LI, Qiao MENG, Junyi HUANGFU, Lingchen MENG. YOLOv5 multi-attribute classification based on separable label collaborative learning [J]. Journal of Computer Applications, 2024, 44(5): 1619-1628. |
| [9] | Tianhua CHEN, Jiaxuan ZHU, Jie YIN. Bird recognition algorithm based on attention mechanism [J]. Journal of Computer Applications, 2024, 44(4): 1114-1120. |
| [10] | Zongze JIA, Pengfei GAO, Yinglong MA, Xiaofeng LIU, Haixin XIA. Multi-feature fusion attention-based hierarchical classification method for dialogue act [J]. Journal of Computer Applications, 2024, 44(3): 715-721. |
| [11] | Ning WU, Yangyang LUO, Huajie XU. Semantic segmentation method for remote sensing images based on multi-scale feature fusion [J]. Journal of Computer Applications, 2024, 44(3): 737-744. |
| [12] | Yuliang ZHENG, Yunhua CHEN, Weijie BAI, Pinghua CHEN. Vehicle target detection by fusing event data and image frames [J]. Journal of Computer Applications, 2024, 44(3): 931-937. |
| [13] | Xinye LI, Yening HOU, Yinghui KONG, Zhiqi YAN. Few-shot object detection combining feature fusion and enhanced attention [J]. Journal of Computer Applications, 2024, 44(3): 745-751. |
| [14] | Zhanjun JIANG, Baijing WU, Long MA, Jing LIAN. Faster-RCNN water-floating garbage recognition based on multi-scale feature and polarized self-attention [J]. Journal of Computer Applications, 2024, 44(3): 938-944. |
| [15] | Cunyi LIAO, Yi ZHENG, Weijin LIU, Huan YU, Shouyin LIU. Decoupling-fusing algorithm for multiple tasks with autonomous driving environment perception [J]. Journal of Computer Applications, 2024, 44(2): 424-431. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||