


Journal of Computer Applications ›› 2022, Vol. 42 ›› Issue (3): 736-742.DOI: 10.11772/j.issn.1001-9081.2021040845
Special Issue: 人工智能; 2021年中国计算机学会人工智能会议(CCFAI 2021)
• 2021 CCF Conference on Artificial Intelligence (CCFAI 2021) • Previous Articles Next Articles
Yongkang HUANG, Meiyu LIANG( ), Xiaoxiao WANG, Zheng CHEN, Xiaowen CAO
), Xiaoxiao WANG, Zheng CHEN, Xiaowen CAO
Received:2021-05-24
Revised:2021-07-08
Accepted:2021-07-09
Online:2021-11-09
Published:2022-03-10
Contact:
Meiyu LIANG
About author:HUANG Yongkang, born in 1998, M. S. candidate. His research interests include computer vision, deep learning.Supported by:
黄勇康, 梁美玉(), 王笑笑, 陈徵, 曹晓雯
通讯作者:
梁美玉
作者简介:黄勇康(1998—),男,江西樟树人,硕士研究生,CCF会员,主要研究方向:计算机视觉、深度学习基金资助:CLC Number:
Yongkang HUANG, Meiyu LIANG, Xiaoxiao WANG, Zheng CHEN, Xiaowen CAO. Multi-person classroom action recognition in classroom teaching videos based on deep spatiotemporal residual convolution neural network[J]. Journal of Computer Applications, 2022, 42(3): 736-742.
黄勇康, 梁美玉, 王笑笑, 陈徵, 曹晓雯. 基于深度时空残差卷积神经网络的课堂教学视频中多人课堂行为识别[J]. 《计算机应用》唯一官方网站, 2022, 42(3): 736-742.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2021040845

Fig. 1 Model of student classroom action recognition based on deep spatio temporal residual convolution neural network

Fig.2 Structure of classroom student object detection network

Fig. 3 Flowchart of classroom student object tracking algorithm

Fig. 4 Structure of student classroom action real-time recognition algorithm based on deep spatio temporal residual convolution neural network
| layer name | output size | 提出的模型 | |
|---|---|---|---|
| conv1 | 8×28×28 | 7×7×7, 64, stride 1×2×2 | |
| 3×3×3 max pool, stride 2 | |||
| conv2.x | 8×28×28 | 1×1×1, 64 3×3×3, 64 1×1×1, 256 | ×3 |
| conv3.x | 4×14×14 | 1×1×1, 128 3×3×3, 128 1×1×1, 512 | ×4 |
| conv4.x | 2×7×7 | 1×1×1, 256 3×3×3, 256 1×1×1, 1 024 | ×6 |
| conv5.x | 1×4×4 | 1×1×1, 512 3×3×3, 512 1×1×1, 2 048 | ×3 |
| 4 | average pool, fc | ||
Tab. 1 Structure of the proposed model
| layer name | output size | 提出的模型 | |
|---|---|---|---|
| conv1 | 8×28×28 | 7×7×7, 64, stride 1×2×2 | |
| 3×3×3 max pool, stride 2 | |||
| conv2.x | 8×28×28 | 1×1×1, 64 3×3×3, 64 1×1×1, 256 | ×3 |
| conv3.x | 4×14×14 | 1×1×1, 128 3×3×3, 128 1×1×1, 512 | ×4 |
| conv4.x | 2×7×7 | 1×1×1, 256 3×3×3, 256 1×1×1, 1 024 | ×6 |
| conv5.x | 1×4×4 | 1×1×1, 512 3×3×3, 512 1×1×1, 2 048 | ×3 |
| 4 | average pool, fc | ||

Fig. 5 Sample of various action samples
| 模型 | 图片大小/(px×px) | 识别人数 | 使用时间/ms |
|---|---|---|---|
| EfficientDet[ | 512×512 | 16 | 71 |
| 640×640 | 23 | 151 | |
| 768×768 | 20 | 234 | |
| 896×896 | 23 | 477 | |
| 1 024×1 024 | 23 | 795 | |
| YOLOv4[ | 416×416 | 14 | 290 |
| 608×608 | 20 | 510 | |
| YOLOv5s | 608×608 | 22 | 24 |
| YOLOv5m | 19 | 50 | |
| YOLOv5l | 24 | 79 | |
| YOLOv5x | 26 | 179 |
Tab. 2 Comparison of experimental results of classroom student object detection
| 模型 | 图片大小/(px×px) | 识别人数 | 使用时间/ms |
|---|---|---|---|
| EfficientDet[ | 512×512 | 16 | 71 |
| 640×640 | 23 | 151 | |
| 768×768 | 20 | 234 | |
| 896×896 | 23 | 477 | |
| 1 024×1 024 | 23 | 795 | |
| YOLOv4[ | 416×416 | 14 | 290 |
| 608×608 | 20 | 510 | |
| YOLOv5s | 608×608 | 22 | 24 |
| YOLOv5m | 19 | 50 | |
| YOLOv5l | 24 | 79 | |
| YOLOv5x | 26 | 179 |
| 目标阈值 | YOLOv5s | YOLOv5m | YOLOv5l | YOLOv5x |
|---|---|---|---|---|
| 0.3 | 22 | 19 | 24 | 26 |
| 0.2 | 27 | 25 | 32 | 28 |
| 0.1 | 32 | 40 | 40 | 36 |
Tab. 3 Experimental results comparison of classroom student object detection under different thresholds
| 目标阈值 | YOLOv5s | YOLOv5m | YOLOv5l | YOLOv5x |
|---|---|---|---|---|
| 0.3 | 22 | 19 | 24 | 26 |
| 0.2 | 27 | 25 | 32 | 28 |
| 0.1 | 32 | 40 | 40 | 36 |
| 教学课堂视频帧 | YOLOv5s | YOLOv5m | YOLOv5l | YOLOv5x |
|---|---|---|---|---|
| 1 | 10 | 12 | 11 | 10 |
| 2 | 18 | 16 | 23 | 23 |
| 3 | 18 | 24 | 19 | 22 |
| 4 | 30 | 22 | 29 | 31 |
| 5 | 18 | 14 | 18 | 18 |
Tab. 4 Experimental results comparison of classroom student object detection in different classroom scenes
| 教学课堂视频帧 | YOLOv5s | YOLOv5m | YOLOv5l | YOLOv5x |
|---|---|---|---|---|
| 1 | 10 | 12 | 11 | 10 |
| 2 | 18 | 16 | 23 | 23 |
| 3 | 18 | 24 | 19 | 22 |
| 4 | 30 | 22 | 29 | 31 |
| 5 | 18 | 14 | 18 | 18 |
| 算法 | 多行人视频 | 课堂教学视频 | ||
|---|---|---|---|---|
| 计算速度/fps | 识别人数 | 计算速度/fps | 识别人数 | |
| YOLOv5s+DeepSORT | 33 | 24 | 33 | 19 |
| FairMOT | 11 | 60 | 13 | 1 |
| JDE | 14 | 55 | 17 | 4 |
Tab. 5 Experimental results comparison of different object tracking algorithms in different scenes
| 算法 | 多行人视频 | 课堂教学视频 | ||
|---|---|---|---|---|
| 计算速度/fps | 识别人数 | 计算速度/fps | 识别人数 | |
| YOLOv5s+DeepSORT | 33 | 24 | 33 | 19 |
| FairMOT | 11 | 60 | 13 | 1 |
| JDE | 14 | 55 | 17 | 4 |
| 模型 | 预训练 数据集 | 平均 准确率/% | 训练 时间/min | 模型大小/MB | 平均推理时间/s |
|---|---|---|---|---|---|
| I3D | ImageNet | 79.3 | 40.8 | 95 | 0.273 |
| PAN | ImageNet | 83.7 | 38.0 | 326 | 0.125 |
| ResNet3D101 | Kinetics400 | 89.4 | 21.5 | 652 | 0.189 |
| ResNeXt3D101 | Kinetics400 | 89.4 | 21.5 | 364 | 0.149 |
| R(2+1)D | Sports-1M | 89.4 | 41.5 | 485 | 0.363 |
| R(2+1)D-BERT | Sports-1M | 91.4 | 40.0 | 764 | 0.366 |
| 本文模型 | Kinetics400 | 88.5 | 14.5 | 353 | 0.136 |
Tab. 6 Results comparison of different action recognition algorithm on student classroom action dataset
| 模型 | 预训练 数据集 | 平均 准确率/% | 训练 时间/min | 模型大小/MB | 平均推理时间/s |
|---|---|---|---|---|---|
| I3D | ImageNet | 79.3 | 40.8 | 95 | 0.273 |
| PAN | ImageNet | 83.7 | 38.0 | 326 | 0.125 |
| ResNet3D101 | Kinetics400 | 89.4 | 21.5 | 652 | 0.189 |
| ResNeXt3D101 | Kinetics400 | 89.4 | 21.5 | 364 | 0.149 |
| R(2+1)D | Sports-1M | 89.4 | 41.5 | 485 | 0.363 |
| R(2+1)D-BERT | Sports-1M | 91.4 | 40.0 | 764 | 0.366 |
| 本文模型 | Kinetics400 | 88.5 | 14.5 | 353 | 0.136 |

Fig. 6 Action recognition effects in classroom teaching scenes by the proposed model
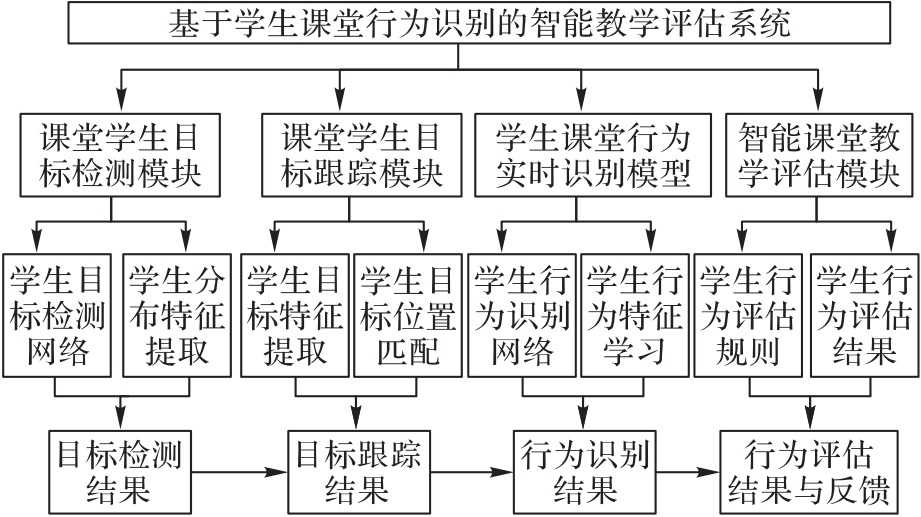
Fig. 7 Structure of intelligent teaching evaluation system based on students’ classroom action recognition
| 1 | 朱煜,赵江坤,王逸宁,等. 基于深度学习的人体行为识别算法综述[J]. 自动化学报, 2016, 42(6): 848-857. 10.16383/j.aas.2016.c150710 |
| ZHU Y, ZHAO J K, WANG Y N,et al. A review of human action recognition based on deep learning [J]. Acta Automatica Sinica,2016,42(6): 848-857. 10.16383/j.aas.2016.c150710 | |
| 2 | BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. [2020-04-23]. . 10.1109/cvpr46437.2021.01283 |
| 3 | 吴帅,徐勇,赵东宁. 基于深度卷积网络的目标检测综述[J]. 模式识别与人工智能, 2018, 31(4): 335-346. 10.16451/j.cnki.issn1003-6059.201804005 |
| WU S, XU Y, ZHAO D N. Survey of object detection based on deep convolutional network [J]. Pattern Recognition and Artificial Intelligence, 2018, 31(4):335-346. 10.16451/j.cnki.issn1003-6059.201804005 | |
| 4 | ZOU Z X, SHI Z W, GUO Y H, et al. Object detection in 20 years: a survey[EB/OL]. [2019-05-13]. . 10.1186/s12937-019-0491-x |
| 5 | REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 779-788. 10.1109/cvpr.2016.91 |
| 6 | YOLOv 5 [CP/OL]. [2020-05-30]. . 10.3390/electronics10141711 |
| 7 | LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]// Proceedings of the 2016 European Conference on Computer Vision. Cham: Springer, 2016: 21-37. 10.1007/978-3-319-46448-0_2 |
| 8 | TAN M, PANG R, LE Q V. EfficientDet: scalable and efficient object detection[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10781-10790. 10.1109/cvpr42600.2020.01079 |
| 9 | TAN M, LE Q. EfficientNet: rethinking model scaling for convolutional neural networks[C]// Proceedings of the 2019 International Conference on Machine Learning. California: PMLR, 2019: 6105-6114. 10.48550/arXiv.1905.11946 |
| 10 | BEWLEY A, GE Z, OTT L. Simple online and realtime tracking[C]// Proceedings of the 2016 IEEE International Conference on Image Processing. Piscataway: IEEE, 2016: 3464-3468. 10.1109/icip.2016.7533003 |
| 11 | WOJKE N, BEWLEY A, PAULUS D. Simple online and realtime tracking with a deep association metric[C]// Proceedings of the 2017 IEEE International Conference on Image Processing. Piscataway: IEEE, 2017: 3645--3649. 10.1109/ICIP.2017.8296962 |
| 12 | WOJKE N, BEWLEY A. Deep cosine metric learning for person re-identification[C]// Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2018: 748-756. 10.1109/wacv.2018.00087 |
| 13 | WANG Z, ZHENG L, LIU Y, et al. Towards real-time multi-object tracking[EB/OL]. [2019-09-27]. . 10.1007/978-3-030-58621-8_7 |
| 14 | ZHANG Y F, WANG C Y, WANG, X G, et al. FairMOT: On the fairness of detection and re-identification in multiple object tracking[EB/OL]. [2020-04-04]. . 10.1109/access.2020.2997072 |
| 15 | TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3D convolutional networks[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 4489-4497. 10.1109/ICCV.2015.510 |
| 16 | CARREIRA J, ZISSERMAN A. Quo vadis, action recognition? a new model and the kinetics dataset [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6299-6308. 10.1109/cvpr.2017.502 |
| 17 | SIMONYAN K, ZISSERMAN A. Two-stream convolutional networks for action recognition in videos[EB/OL]. [2014-06-09]. . 10.1109/iccvw.2017.368 |
| 18 | TRAN D, WANG H, TORRESANI L, et al. A closer look at spatiotemporal convolutions for action recognition[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6450-6459. 10.1109/cvpr.2018.00675 |
| 19 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[EB/OL]. [2018-10-11]. . 10.18653/v1/n19-1423 |
| 20 | KALFAOGLU M, KALKAN S, ALATAN A A. Late temporal modeling in 3D CNN architectures with BERT for action recognition[EB/OL]. [2020-08-03]. . 10.1007/978-3-030-68238-5_48 |
| 21 | KAREN S, ANDREW Z. Two-stream convolutional networks for action recognition in videos[EB/OL]. [2014-06-09]. . |
| 22 | CHRISTOPH F, HAOQI F, JITENDRA M, et al. SlowFast networks for video recognition[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 6202-6211. 10.1109/iccv.2019.00630 |
| 23 | CHRISTOPH F. X3D: Progressive network expansion for efficient video recognition[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 203-213. 10.1109/cvpr42600.2020.00028 |
| 24 | CAO Z, HIDALGO G, SIMON T, et al. OpenPose: realtime multi-person 2D pose estimation using part affinity fields[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 43(1): 172-186. |
| 25 | SIMON T, JOO H, MATTHEWS I, et al. Hand keypoint detection in single images using multiview bootstrapping[C]// Proceedings of the 2017 IEEE conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1145-1153. 10.1109/cvpr.2017.494 |
| 26 | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 27 | XIE S, GIRSHICK R, DOLLÁR P, et al. Aggregated residual transformations for deep neural networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1492-1500. 10.1109/cvpr.2017.634 |
| 28 | ZHANG C, ZOU Y, CHEN G, et al. PAN: towards fast action recognition via learning persistence of appearance[EB/OL]. [2020-08-08]. . 10.1145/3343031.3350876 |
| [1] | Yexin PAN, Zhe YANG. Optimization model for small object detection based on multi-level feature bidirectional fusion [J]. Journal of Computer Applications, 2024, 44(9): 2871-2877. |
| [2] | Yeheng LI, Guangsheng LUO, Qianmin SU. Logo detection algorithm based on improved YOLOv5 [J]. Journal of Computer Applications, 2024, 44(8): 2580-2587. |
| [3] | Yingjun ZHANG, Niuniu LI, Binhong XIE, Rui ZHANG, Wangdong LU. Semi-supervised object detection framework guided by curriculum learning [J]. Journal of Computer Applications, 2024, 44(8): 2326-2333. |
| [4] | Song XU, Wenbo ZHANG, Yifan WANG. Lightweight video salient object detection network based on spatiotemporal information [J]. Journal of Computer Applications, 2024, 44(7): 2192-2199. |
| [5] | Xun SUN, Ruifeng FENG, Yanru CHEN. Monocular 3D object detection method integrating depth and instance segmentation [J]. Journal of Computer Applications, 2024, 44(7): 2208-2215. |
| [6] | Yue LIU, Fang LIU, Aoyun WU, Qiuyue CHAI, Tianxiao WANG. 3D object detection network based on self-attention mechanism and graph convolution [J]. Journal of Computer Applications, 2024, 44(6): 1972-1977. |
| [7] | Yaping DENG, Yingjiang LI. Review of YOLO algorithm and its applications to object detection in autonomous driving scenes [J]. Journal of Computer Applications, 2024, 44(6): 1949-1958. |
| [8] | Huantong GENG, Zhenyu LIU, Jun JIANG, Zichen FAN, Jiaxing LI. Embedded road crack detection algorithm based on improved YOLOv8 [J]. Journal of Computer Applications, 2024, 44(5): 1613-1618. |
| [9] | Ziwen SUN, Lizhi QIAN, Chuandong YANG, Yibo GAO, Qingyang LU, Guanglin YUAN. Survey of visual object tracking methods based on Transformer [J]. Journal of Computer Applications, 2024, 44(5): 1644-1654. |
| [10] | Xiaogang SONG, Dongdong ZHANG, Pengfei ZHANG, Li LIANG, Xinhong HEI. Real-time object detection algorithm for complex construction environments [J]. Journal of Computer Applications, 2024, 44(5): 1605-1612. |
| [11] | Hongtian LI, Xinhao SHI, Weiguo PAN, Cheng XU, Bingxin XU, Jiazheng YUAN. Few-shot object detection via fusing multi-scale and attention mechanism [J]. Journal of Computer Applications, 2024, 44(5): 1437-1444. |
| [12] | Wei WANG, Chunhui ZHAO, Xinyao TANG, Liugang XI. 3D vehicle detection with adaptive horizon line constraints [J]. Journal of Computer Applications, 2024, 44(3): 909-915. |
| [13] | Xinye LI, Yening HOU, Yinghui KONG, Zhiqi YAN. Few-shot object detection combining feature fusion and enhanced attention [J]. Journal of Computer Applications, 2024, 44(3): 745-751. |
| [14] | Yuqiu LI, Liping HOU, Jian XUE, Ke LYU, Yong WANG. Remote sensing image recommendation method based on content interpretation [J]. Journal of Computer Applications, 2024, 44(3): 722-731. |
| [15] | Keyi FU, Gaocai WANG, Man WU. Few-shot object detection method based on improved region proposal network and feature aggregation [J]. Journal of Computer Applications, 2024, 44(12): 3790-3797. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||