


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (5): 1588-1596.DOI: 10.11772/j.issn.1001-9081.2023050636
Special Issue: 多媒体计算与计算机仿真
• Multimedia computing and computer simulation • Previous Articles Next Articles
Zihan LIU( ), Dengwen ZHOU, Yukai LIU
), Dengwen ZHOU, Yukai LIU
Received:2023-05-23
Revised:2023-08-31
Accepted:2023-09-13
Online:2023-09-19
Published:2024-05-10
Contact:
Zihan LIU
About author:ZHOU Dengwen, born in 1965, M. S., professor. His research interests include image denoising, image super-resolution.
刘子涵(), 周登文, 刘玉铠
通讯作者:
刘子涵
作者简介:周登文(1965—),男,湖北黄梅人,教授,硕士,主要研究方向:图像去噪、图像超分辨率CLC Number:
Zihan LIU, Dengwen ZHOU, Yukai LIU. Image super-resolution network based on global dependency Transformer[J]. Journal of Computer Applications, 2024, 44(5): 1588-1596.
刘子涵, 周登文, 刘玉铠. 基于全局依赖Transformer的图像超分辨率网络[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1588-1596.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023050636
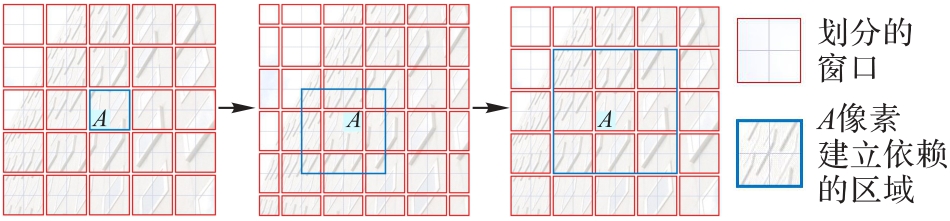
Fig. 1 Schematic diagram of shift window strategy

Fig. 2 Schematic diagram of axial window

Fig. 3 PSNR and parameter quantity comparison among different methods for ×4 SR on dataset Urban100

Fig. 4 Structure of GDTSR

Fig. 5 Structure of RSAWB and its windows division of each network layer

Fig. 6 Structure of AWTRL
| 训练集 | 模型 | 参数量/103 | Set5 | Set14 | B100 | Urban100 | Manga109 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | |||
| DIV2K | IMDN[ | 694 | 38.00 | 0.960 5 | 33.63 | 0.917 7 | 32.19 | 0.899 6 | 32.17 | 0.928 3 | 38.88 | 0.977 4 |
| DIV2K | LAPAR[ | 548 | 38.01 | 0.960 5 | 33.62 | 0.918 3 | 32.19 | 0.899 9 | 32.10 | 0.928 3 | 38.67 | 0.977 2 |
| DIV2K | LatticeNet[ | 756 | 38.15 | 0.961 0 | 33.78 | 0.919 3 | 32.25 | 0.900 5 | 32.43 | 0.930 2 | — | — |
| DIV2K | ESRT[ | 677 | 38.03 | 0.960 0 | 33.75 | 0.918 4 | 32.25 | 0.900 5 | 32.58 | 0.931 8 | 39.12 | 0.977 4 |
| DIV2K | SwinIR-light[ | 878 | 38.14 | 0.961 1 | 33.86 | 0.920 6 | 32.31 | 0.901 2 | 32.76 | 0.934 0 | 39.12 | 0.978 3 |
| DIV2K | ELAN-light[ | 582 | 38.17 | 0.961 1 | 33.94 | 0.920 7 | 32.30 | 0.901 2 | 32.76 | 0.934 0 | 39.11 | 0.978 2 |
| DIV2K | GDTSR-T | 600 | 38.17 | 0.961 2 | 33.99 | 0.920 3 | 32.31 | 0.901 3 | 32.78 | 0.934 2 | 39.27 | 0.978 4 |
| DIV2K | EDSR-baseline[ | 1 370 | 37.99 | 0.960 4 | 33.57 | 0.917 5 | 32.16 | 0.899 4 | 31.98 | 0.927 2 | 38.54 | 0.976 9 |
| DIV2K | CARN[ | 1 592 | 37.76 | 0.959 0 | 33.52 | 0.916 6 | 32.09 | 0.897 8 | 31.92 | 0.925 6 | 38.36 | 0.976 5 |
| DIV2K | SMSR[ | 985 | 38.00 | 0.960 1 | 33.64 | 0.917 9 | 32.17 | 0.899 0 | 32.19 | 0.928 4 | 38.76 | 0.977 1 |
| DIV2K | HGSRCNN[ | 2 178 | 37.80 | 0.959 1 | 33.56 | 0.917 5 | 32.12 | 0.898 4 | 32.21 | 0.929 2 | — | — |
| DIV2K | SwinIR-NG[ | 1 181 | 38.17 | 0.961 2 | 33.94 | 0.920 5 | 32.31 | 0.901 3 | 32.78 | 0.934 0 | 39.20 | 0.978 1 |
| DIV2K | Swin2SR-s[ | 1 000 | 38.17 | 0.961 3 | 33.95 | 0.921 6 | 32.35 | 0.902 4 | 32.85 | 0.934 9 | 39.32 | 0.978 4 |
| DIV2K | GDTSR | 1 003 | 32.35 | 0.901 8 | 0.978 7 | |||||||
| DF2K | EDT-T[ | 917 | 38.23 | 33.99 | 0.920 9 | 32.98 | 0.936 2 | 0.978 9 | ||||
| DF2K | GDTSR-DF | 1 003 | 38.31 | 0.961 6 | 34.28 | 0.923 9 | 32.39 | 0.902 3 | 33.34 | 0.938 4 | 39.66 | |
Tab. 1 Average PSNRs and SSIMs of ×2 SR for various SISR models
| 训练集 | 模型 | 参数量/103 | Set5 | Set14 | B100 | Urban100 | Manga109 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | |||
| DIV2K | IMDN[ | 694 | 38.00 | 0.960 5 | 33.63 | 0.917 7 | 32.19 | 0.899 6 | 32.17 | 0.928 3 | 38.88 | 0.977 4 |
| DIV2K | LAPAR[ | 548 | 38.01 | 0.960 5 | 33.62 | 0.918 3 | 32.19 | 0.899 9 | 32.10 | 0.928 3 | 38.67 | 0.977 2 |
| DIV2K | LatticeNet[ | 756 | 38.15 | 0.961 0 | 33.78 | 0.919 3 | 32.25 | 0.900 5 | 32.43 | 0.930 2 | — | — |
| DIV2K | ESRT[ | 677 | 38.03 | 0.960 0 | 33.75 | 0.918 4 | 32.25 | 0.900 5 | 32.58 | 0.931 8 | 39.12 | 0.977 4 |
| DIV2K | SwinIR-light[ | 878 | 38.14 | 0.961 1 | 33.86 | 0.920 6 | 32.31 | 0.901 2 | 32.76 | 0.934 0 | 39.12 | 0.978 3 |
| DIV2K | ELAN-light[ | 582 | 38.17 | 0.961 1 | 33.94 | 0.920 7 | 32.30 | 0.901 2 | 32.76 | 0.934 0 | 39.11 | 0.978 2 |
| DIV2K | GDTSR-T | 600 | 38.17 | 0.961 2 | 33.99 | 0.920 3 | 32.31 | 0.901 3 | 32.78 | 0.934 2 | 39.27 | 0.978 4 |
| DIV2K | EDSR-baseline[ | 1 370 | 37.99 | 0.960 4 | 33.57 | 0.917 5 | 32.16 | 0.899 4 | 31.98 | 0.927 2 | 38.54 | 0.976 9 |
| DIV2K | CARN[ | 1 592 | 37.76 | 0.959 0 | 33.52 | 0.916 6 | 32.09 | 0.897 8 | 31.92 | 0.925 6 | 38.36 | 0.976 5 |
| DIV2K | SMSR[ | 985 | 38.00 | 0.960 1 | 33.64 | 0.917 9 | 32.17 | 0.899 0 | 32.19 | 0.928 4 | 38.76 | 0.977 1 |
| DIV2K | HGSRCNN[ | 2 178 | 37.80 | 0.959 1 | 33.56 | 0.917 5 | 32.12 | 0.898 4 | 32.21 | 0.929 2 | — | — |
| DIV2K | SwinIR-NG[ | 1 181 | 38.17 | 0.961 2 | 33.94 | 0.920 5 | 32.31 | 0.901 3 | 32.78 | 0.934 0 | 39.20 | 0.978 1 |
| DIV2K | Swin2SR-s[ | 1 000 | 38.17 | 0.961 3 | 33.95 | 0.921 6 | 32.35 | 0.902 4 | 32.85 | 0.934 9 | 39.32 | 0.978 4 |
| DIV2K | GDTSR | 1 003 | 32.35 | 0.901 8 | 0.978 7 | |||||||
| DF2K | EDT-T[ | 917 | 38.23 | 33.99 | 0.920 9 | 32.98 | 0.936 2 | 0.978 9 | ||||
| DF2K | GDTSR-DF | 1 003 | 38.31 | 0.961 6 | 34.28 | 0.923 9 | 32.39 | 0.902 3 | 33.34 | 0.938 4 | 39.66 | |
| 训练集 | 模型 | 参数量/103 | Set5 | Set14 | B100 | Urban100 | Manga109 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | |||
| DIV2K | IMDN[ | 703 | 34.36 | 0.927 0 | 30.32 | 0.841 7 | 29.09 | 0.804 6 | 28.17 | 0.851 9 | 33.61 | 0.944 5 |
| DIV2K | LAPAR[ | 544 | 34.36 | 0.926 7 | 30.34 | 0.842 1 | 29.11 | 0.805 4 | 28.15 | 0.852 3 | 33.51 | 0.944 1 |
| DIV2K | LatticeNet[ | 765 | 34.53 | 0.928 1 | 30.39 | 0.842 4 | 29.15 | 0.805 9 | 28.33 | 0.853 8 | — | — |
| DIV2K | ESRT[ | 770 | 34.42 | 0.926 8 | 30.43 | 0.843 3 | 29.15 | 0.806 3 | 28.46 | 0.857 4 | 33.95 | 0.945 5 |
| DIV2K | SwinIR-light[ | 886 | 34.62 | 0.928 9 | 30.54 | 0.846 3 | 29.20 | 0.808 2 | 28.66 | 0.862 4 | 33.98 | 0.947 8 |
| DIV2K | ELAN-light[ | 590 | 34.61 | 0.928 8 | 30.55 | 0.846 3 | 29.21 | 0.808 1 | 28.69 | 0.862 4 | 34.00 | 0.947 8 |
| DIV2K | GDTSR-T | 611 | 34.62 | 0.928 9 | 30.58 | 0.846 3 | 29.23 | 0.808 6 | 28.71 | 0.862 9 | 34.35 | 0.948 8 |
| DIV2K | EDSR-baseline[ | 1 555 | 34.37 | 0.927 0 | 30.28 | 0.841 7 | 29.09 | 0.805 2 | 28.15 | 0.852 7 | 33.45 | 0.943 9 |
| DIV2K | CARN[ | 1 592 | 34.29 | 0.925 5 | 30.29 | 0.840 7 | 29.06 | 0.803 4 | 28.06 | 0.849 3 | 33.43 | 0.942 7 |
| DIV2K | SMSR[46] | 993 | 34.40 | 0.927 0 | 30.33 | 0.841 2 | 29.10 | 0.805 0 | 28.25 | 0.853 6 | 33.68 | 0.944 5 |
| DIV2K | HGSRCNN[ | 2 363 | 34.35 | 0.926 0 | 33.32 | 0.841 3 | 29.09 | 0.804 2 | 28.29 | 0.854 6 | — | — |
| DIV2K | SwinIR-NG[ | 1 190 | 34.64 | 0.929 3 | 30.58 | 0.847 1 | 29.24 | 0.809 0 | 28.75 | 0.863 9 | 34.22 | 0.948 8 |
| DIV2K | GDTSR | 1 014 | 0.847 7 | 0.810 2 | ||||||||
| DF2K | EDT-T[ | 919 | 34.73 | 0.929 9 | 30.66 | 28.89 | 0.867 4 | 34.44 | 0.949 8 | |||
| DF2K | GDTSR | 1 014 | 34.83 | 0.930 4 | 30.72 | 0.848 7 | 29.33 | 0.810 9 | 29.22 | 0.871 7 | 34.80 | 0.951 3 |
Tab. 2 Average PSNRs and SSIMs of ×3 SR for various SISR models
| 训练集 | 模型 | 参数量/103 | Set5 | Set14 | B100 | Urban100 | Manga109 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | |||
| DIV2K | IMDN[ | 703 | 34.36 | 0.927 0 | 30.32 | 0.841 7 | 29.09 | 0.804 6 | 28.17 | 0.851 9 | 33.61 | 0.944 5 |
| DIV2K | LAPAR[ | 544 | 34.36 | 0.926 7 | 30.34 | 0.842 1 | 29.11 | 0.805 4 | 28.15 | 0.852 3 | 33.51 | 0.944 1 |
| DIV2K | LatticeNet[ | 765 | 34.53 | 0.928 1 | 30.39 | 0.842 4 | 29.15 | 0.805 9 | 28.33 | 0.853 8 | — | — |
| DIV2K | ESRT[ | 770 | 34.42 | 0.926 8 | 30.43 | 0.843 3 | 29.15 | 0.806 3 | 28.46 | 0.857 4 | 33.95 | 0.945 5 |
| DIV2K | SwinIR-light[ | 886 | 34.62 | 0.928 9 | 30.54 | 0.846 3 | 29.20 | 0.808 2 | 28.66 | 0.862 4 | 33.98 | 0.947 8 |
| DIV2K | ELAN-light[ | 590 | 34.61 | 0.928 8 | 30.55 | 0.846 3 | 29.21 | 0.808 1 | 28.69 | 0.862 4 | 34.00 | 0.947 8 |
| DIV2K | GDTSR-T | 611 | 34.62 | 0.928 9 | 30.58 | 0.846 3 | 29.23 | 0.808 6 | 28.71 | 0.862 9 | 34.35 | 0.948 8 |
| DIV2K | EDSR-baseline[ | 1 555 | 34.37 | 0.927 0 | 30.28 | 0.841 7 | 29.09 | 0.805 2 | 28.15 | 0.852 7 | 33.45 | 0.943 9 |
| DIV2K | CARN[ | 1 592 | 34.29 | 0.925 5 | 30.29 | 0.840 7 | 29.06 | 0.803 4 | 28.06 | 0.849 3 | 33.43 | 0.942 7 |
| DIV2K | SMSR[46] | 993 | 34.40 | 0.927 0 | 30.33 | 0.841 2 | 29.10 | 0.805 0 | 28.25 | 0.853 6 | 33.68 | 0.944 5 |
| DIV2K | HGSRCNN[ | 2 363 | 34.35 | 0.926 0 | 33.32 | 0.841 3 | 29.09 | 0.804 2 | 28.29 | 0.854 6 | — | — |
| DIV2K | SwinIR-NG[ | 1 190 | 34.64 | 0.929 3 | 30.58 | 0.847 1 | 29.24 | 0.809 0 | 28.75 | 0.863 9 | 34.22 | 0.948 8 |
| DIV2K | GDTSR | 1 014 | 0.847 7 | 0.810 2 | ||||||||
| DF2K | EDT-T[ | 919 | 34.73 | 0.929 9 | 30.66 | 28.89 | 0.867 4 | 34.44 | 0.949 8 | |||
| DF2K | GDTSR | 1 014 | 34.83 | 0.930 4 | 30.72 | 0.848 7 | 29.33 | 0.810 9 | 29.22 | 0.871 7 | 34.80 | 0.951 3 |
| 训练集 | 模型 | 参数量/103 | Set5 | Set14 | B100 | Urban10 | Manga109 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | |||
| DIV2K | IMDN[ | 715 | 32.21 | 0.894 8 | 28.58 | 0.781 1 | 27.56 | 0.735 3 | 26.04/ | 0.783 8 | 30.45 | 0.907 5 |
| DIV2K | LAPAR[ | 659 | 32.15 | 0.894 4 | 28.61 | 0.781 8 | 27.61 | 0.736 6 | 26.14 | 0.787 1 | 30.42 | 0.907 4 |
| DIV2K | LatticeNet[ | 777 | 32.30 | 0.896 2 | 28.68 | 0.783 0 | 27.62 | 0.736 7 | 26.25 | 0.787 3 | — | — |
| DIV2K | ESRT[ | 751 | 32.19 | 0.894 7 | 28.69 | 0.783 3 | 27.69 | 0.737 9 | 36.39 | 0.796 2 | 30.75 | 0.910 0 |
| DIV2K | SwinIR-light[ | 897 | 32.44 | 0.897 6 | 28.77 | 0.785 8 | 27.69 | 0.740 6 | 26.47 | 0.798 0 | 30.92 | 0.915 1 |
| DIV2K | ELAN-light[ | 601 | 32.43 | 0.897 5 | 28.78 | 0.785 8 | 27.69 | 0.740 6 | 26.54 | 0.798 2 | 30.92 | 0.915 0 |
| DIV2K | GDTSR-T | 627 | 32.40 | 0.897 8 | 28.84 | 0.786 9 | 27.72 | 0.741 4 | 26.64 | 0.801 2 | 31.21 | 0.916 3 |
| DIV2K | EDSR-baseline[ | 1 518 | 32.09 | 0.893 8 | 28.58 | 0.781 3 | 27.57 | 0.735 7 | 26.04 | 0.784 9 | 30.35 | 0.906 7 |
| DIV2K | CARN[ | 1 592 | 32.13 | 0.893 7 | 28.60 | 0.780 6 | 27.58 | 0.734 9 | 26.07 | 0.783 7 | 30.42 | 0.907 0 |
| DIV2K | SMSR[46] | 1 006 | 32.12 | 0.893 2 | 28.55 | 0.780 8 | 27.55 | 0.735 1 | 26.11 | 0.786 8 | 30.54 | 0.908 5 |
| DIV2K | HGSRCNN[ | 2 321 | 32.13 | 0.894 0 | 28.62 | 0.782 0 | 27.60 | 0.736 3 | 26.27 | 0.790 8 | — | — |
| DIV2K | SwinIR-NG[ | 1 201 | 32.44 | 0.898 0 | 28.83 | 0.787 0 | 27.73 | 0.741 8 | 26.61 | 0.801 0 | 31.09 | 0.916 1 |
| DIV2K | GDTSR | 1 030 | ||||||||||
| DF2K | EDT-T[ | 922 | 32.53 | 0.899 1 | 28.88 | 0.788 2 | 27.76 | 0.743 3 | 26.71 | 0.805 1 | 31.35 | 0.918 0 |
| DF2K | GDTSR | 1 030 | 32.71 | 0.900 7 | 28.97 | 0.789 8 | 27.82 | 0.744 4 | 27.04 | 0.812 0 | 31.64 | 0.920 2 |
Tab. 3 Average PSNRs and SSIMs of ×4 SR for various SISR models
| 训练集 | 模型 | 参数量/103 | Set5 | Set14 | B100 | Urban10 | Manga109 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | |||
| DIV2K | IMDN[ | 715 | 32.21 | 0.894 8 | 28.58 | 0.781 1 | 27.56 | 0.735 3 | 26.04/ | 0.783 8 | 30.45 | 0.907 5 |
| DIV2K | LAPAR[ | 659 | 32.15 | 0.894 4 | 28.61 | 0.781 8 | 27.61 | 0.736 6 | 26.14 | 0.787 1 | 30.42 | 0.907 4 |
| DIV2K | LatticeNet[ | 777 | 32.30 | 0.896 2 | 28.68 | 0.783 0 | 27.62 | 0.736 7 | 26.25 | 0.787 3 | — | — |
| DIV2K | ESRT[ | 751 | 32.19 | 0.894 7 | 28.69 | 0.783 3 | 27.69 | 0.737 9 | 36.39 | 0.796 2 | 30.75 | 0.910 0 |
| DIV2K | SwinIR-light[ | 897 | 32.44 | 0.897 6 | 28.77 | 0.785 8 | 27.69 | 0.740 6 | 26.47 | 0.798 0 | 30.92 | 0.915 1 |
| DIV2K | ELAN-light[ | 601 | 32.43 | 0.897 5 | 28.78 | 0.785 8 | 27.69 | 0.740 6 | 26.54 | 0.798 2 | 30.92 | 0.915 0 |
| DIV2K | GDTSR-T | 627 | 32.40 | 0.897 8 | 28.84 | 0.786 9 | 27.72 | 0.741 4 | 26.64 | 0.801 2 | 31.21 | 0.916 3 |
| DIV2K | EDSR-baseline[ | 1 518 | 32.09 | 0.893 8 | 28.58 | 0.781 3 | 27.57 | 0.735 7 | 26.04 | 0.784 9 | 30.35 | 0.906 7 |
| DIV2K | CARN[ | 1 592 | 32.13 | 0.893 7 | 28.60 | 0.780 6 | 27.58 | 0.734 9 | 26.07 | 0.783 7 | 30.42 | 0.907 0 |
| DIV2K | SMSR[46] | 1 006 | 32.12 | 0.893 2 | 28.55 | 0.780 8 | 27.55 | 0.735 1 | 26.11 | 0.786 8 | 30.54 | 0.908 5 |
| DIV2K | HGSRCNN[ | 2 321 | 32.13 | 0.894 0 | 28.62 | 0.782 0 | 27.60 | 0.736 3 | 26.27 | 0.790 8 | — | — |
| DIV2K | SwinIR-NG[ | 1 201 | 32.44 | 0.898 0 | 28.83 | 0.787 0 | 27.73 | 0.741 8 | 26.61 | 0.801 0 | 31.09 | 0.916 1 |
| DIV2K | GDTSR | 1 030 | ||||||||||
| DF2K | EDT-T[ | 922 | 32.53 | 0.899 1 | 28.88 | 0.788 2 | 27.76 | 0.743 3 | 26.71 | 0.805 1 | 31.35 | 0.918 0 |
| DF2K | GDTSR | 1 030 | 32.71 | 0.900 7 | 28.97 | 0.789 8 | 27.82 | 0.744 4 | 27.04 | 0.812 0 | 31.64 | 0.920 2 |

Fig. 7 Structure of SWTL

Fig. 8 Structure of TACUpSample

Fig. 9 Visual effect comparison of ×2 SR and ×4 SR
| 模型 | 推理时间/s | GFLOPs | PSNR/dB |
|---|---|---|---|
| SwinIR-light[ | 118.25 | 49.6 | 26.47 |
| EDT-T[ | 128.48 | 54.9 | 26.71 |
| GDTSR | 110.75 | 71.9 | 26.89 |
Tab. 4 Comparison of ×4 SR performance among three models on Urban100 dataset
| 模型 | 推理时间/s | GFLOPs | PSNR/dB |
|---|---|---|---|
| SwinIR-light[ | 118.25 | 49.6 | 26.47 |
| EDT-T[ | 128.48 | 54.9 | 26.71 |
| GDTSR | 110.75 | 71.9 | 26.89 |
| AWTRL的窗口类型 | PSNR/dB |
|---|---|
| 方形窗口 | 29.72 |
| 轴向窗口 | 29.89 |
Tab. 5 PSNR results of ×4 SR with different window types in AWTRL on validation set DIV_val10
| AWTRL的窗口类型 | PSNR/dB |
|---|---|
| 方形窗口 | 29.72 |
| 轴向窗口 | 29.89 |
| 模型 | 参数量/103 | PSNR/dB |
|---|---|---|
| GDTSR_w/o_RB | 773 | 29.79 |
| GDTSR | 1 030 | 29.89 |
Tab. 6 Parameter quantity and PSNR results of ×4 SR with or without RB in AWTRL on validation set DIV_val10
| 模型 | 参数量/103 | PSNR/dB |
|---|---|---|
| GDTSR_w/o_RB | 773 | 29.79 |
| GDTSR | 1 030 | 29.89 |
| 窗口宽度 | 占用显存/MB | 推理时间/s | PSNR/dB |
|---|---|---|---|
| 1 | 3 898 | 50.46 | 29.89 |
| 2 | 5 427 | 56.73 | 29.89 |
| 4 | 7 982 | 62.94 | 29.90 |
| 8 | 9 864 | 81.87 | 29.91 |
Tab. 7 Performance comparison of ×4 SR with different widths of axial window in ATWSR on validation set DIV_val10
| 窗口宽度 | 占用显存/MB | 推理时间/s | PSNR/dB |
|---|---|---|---|
| 1 | 3 898 | 50.46 | 29.89 |
| 2 | 5 427 | 56.73 | 29.89 |
| 4 | 7 982 | 62.94 | 29.90 |
| 8 | 9 864 | 81.87 | 29.91 |
| 模型 | PSNR/dB | 参数量/103 |
|---|---|---|
| GDTSR_0 | 29.85 | 1 024 |
| GDTSR_1 | 29.66 | 1 027 |
| GDTSR | 29.89 | 1 030 |
Tab. 8 Ablation experimental results of super-resolution reconstruction module for ×4 SR on validation set DIV_val10
| 模型 | PSNR/dB | 参数量/103 |
|---|---|---|
| GDTSR_0 | 29.85 | 1 024 |
| GDTSR_1 | 29.66 | 1 027 |
| GDTSR | 29.89 | 1 030 |
| 模型 | 是否采用TACUpSample | PSNR/dB |
|---|---|---|
| EDSR-baseline | 否 | 29.61 |
| 是 | 29.67(↑0.06) | |
| SwinIR-light | 否 | 29.80 |
| 是 | 29.83(↑0.03) |
Tab. 9 PSNR results comparison between different models with or without TACUpSampl for ×4 SR on validation set DIV_val10
| 模型 | 是否采用TACUpSample | PSNR/dB |
|---|---|---|
| EDSR-baseline | 否 | 29.61 |
| 是 | 29.67(↑0.06) | |
| SwinIR-light | 否 | 29.80 |
| 是 | 29.83(↑0.03) |
| 模型 | PSNR/dB |
|---|---|
| GDTSR | 29.89 |
| GDTSR-DF | 30.18 |
Tab. 10 PSNR results of ×4 SR for GDTSR and GDTSR-DF on validation dataset DIV_val10
| 模型 | PSNR/dB |
|---|---|
| GDTSR | 29.89 |
| GDTSR-DF | 30.18 |
| 1 | DONG C, LOY C C, HE K, et al. Learning a deep convolutional network for image super-resolution[C]// Proceedings of the 13th European Conference on Computer Vision. Cham: Springer, 2014: 184-199. 10.1007/978-3-319-10593-2_13 |
| 2 | DONG C, LOY C C, TANG X. Accelerating the super-resolution convolutional neural network[C]// Proceedings of the 14th European Conference on Computer Vision. Cham: Springer, 2016: 391-407. 10.1007/978-3-319-46475-6_25 |
| 3 | KIM J, LEE J K, LEE K M. Accurate image super-resolution using very deep convolutional networks[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1646-1654. 10.1109/cvpr.2016.182 |
| 4 | LIM B, SON S, KIM H, et al. Enhanced deep residual networks for single image super-resolution[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2017:136-144. 10.1109/cvprw.2017.151 |
| 5 | ZHANG Y, LI K, LI K, et al. Image super-resolution using very deep residual channel attention networks[C]// Proceedings of the 15th European Conference on Computer Vision. Cham: Springer, 2018: 294-310. 10.1007/978-3-030-01234-2_18 |
| 6 | TONG T, LI G, LIU X, et al. Image super-resolution using dense skip connections[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 4799-4807. 10.1109/iccv.2017.514 |
| 7 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017:6000-6010. |
| 8 | LIANG J, CAO J, SUN G, et al. SwinIR: image restoration using Swin Transformer[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 1833-1844. 10.1109/iccvw54120.2021.00210 |
| 9 | LIU Z, LIN Y, CAO Y, et al. Swin Transformer: hierarchical vision Transformer using shifted windows[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 9992-10002. 10.1109/iccv48922.2021.00986 |
| 10 | HO J, KALCHBRENNER N, WEISSENBORN D, et al. Axial attention in multidimensional Transformers[EB/OL]. [2023-04-16]. . |
| 11 | SHI W, CABALLERO J, HUSZÁR F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1874-1883. 10.1109/cvpr.2016.207 |
| 12 | HUANG J-B, SINGH A, AHUJA N. Single image super-resolution from transformed self-exemplars[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 5197-5206. 10.1109/cvpr.2015.7299156 |
| 13 | TIMOFTE R, DE SMET V, VAN GOOL L. A+: adjusted anchored neighborhood regression for fast super-resolution[C]// Proceedings of the 12th Asian Conference on Computer Vision. Cham: Springer, 2015: 111-126. 10.1007/978-3-319-16817-3_8 |
| 14 | ZHANG L, WU X. An edge-guided image interpolation algorithm via directional filtering and data fusion[J]. IEEE Transactions on Image Processing, 2006, 15(8): 2226-2238. 10.1109/tip.2006.877407 |
| 15 | MEI Y, FAN Y, ZHOU Y. Image super-resolution with non-local sparse attention[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 3517-3526. 10.1109/cvpr46437.2021.00352 |
| 16 | KIM J, LEE J K, LEE K M. Deeply-recursive convolutional network for image super-resolution[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1637-1645. 10.1109/cvpr.2016.181 |
| 17 | LEDIG C, THEIS L, HUSZÁR F, et al. Photo-realistic single image super-resolution using a generative adversarial network[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 4681-4690. 10.1109/cvpr.2017.19 |
| 18 | WANG X, YU K, WU S, et al. ESRGAN: enhanced super-resolution generative adversarial networks[C]// Proceedings of the 2018 ECCV Workshops. Berlin: Springer, 2018: 63-79. 10.1007/978-3-030-11021-5_5 |
| 19 | GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2014: 2672-2680. |
| 20 | LI W, LU X, QIAN S, et al. On efficient Transformer-based image pre-training for low-level vision[EB/OL]. [2023-05-01]. . 10.24963/ijcai.2023/121 |
| 21 | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[EB/OL]. [2023-06-01]. . |
| 22 | YANG J, LI C, ZHANG P, et al. Focal self-attention for local-global interactions in vision transformers[EB/OL]. [2023-05-23]. . 10.48550/arXiv.2107.00641 |
| 23 | DONG X, BAO J, CHEN D, et al. CSWin Transformer: a general vision Transformer backbone with cross-shaped windows[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 12124-12134. 10.1109/cvpr52688.2022.01181 |
| 24 | CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers[C]// Proceedings of the 16th European Conference on Computer Vision. Cham: Springer, 2020: 213-229. 10.1007/978-3-030-58452-8_13 |
| 25 | CHEN H, WANG Y, GUO T, et al. Pre-trained image processing Transformer[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 12294-12305. 10.1109/cvpr46437.2021.01212 |
| 26 | YOO J, KIM T, LEE S, et al. Rich CNN-transformer feature aggregation networks for super-resolution[C]// Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2023: 4956-4965. 10.1109/wacv56688.2023.00493 |
| 27 | LU Z, LI J, LIU H, et al. Transformer for single image super-resolution[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 457-466. 10.1109/cvprw56347.2022.00061 |
| 28 | CHOI H, LEE J, YANG J. N-Gram in Swin Transformers for efficient lightweight image super-resolution[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 2071-2081. 10.1109/cvpr52729.2023.00206 |
| 29 | ZHANG B, CHEN J, WEN Q. Single image super-resolution using lightweight networks based on Swin Transforme[EB/OL]. [2023-06-07]. . |
| 30 | TIMOFTE R, AGUSTSSON E, VAN GOOL L, et al. NTIRE 2017 challenge on single image super-resolution: methods and results[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2017: 114-125. 10.1109/cvprw.2017.150 |
| 31 | KINGMA D P, BA J. ADAM: a method for stochastic optimization[EB/OL]. [2023-05-21]. . |
| 32 | BEVILACQUA M, ROUMY A, GUILLEMOT R C, et al. Low-complexity single-image super-resolution based on nonnegative neighbor embedding[C/OL]// Proceedings of the 2012 British Machine Vision Conference. [S.l.]: BMVC, 2012 [2023-05-01]. . |
| 33 | ZEYDE R, ELAD M, PROTTER M. On single image scale-up using sparse-representations[C]// Proceedings of the 7th International Conference on Curves and Surfaces. Berlin: Springer, 2012: 711-730. 10.1007/978-3-642-27413-8_47 |
| 34 | MARTIN D, FOWLKES C, TAL D, et al. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics[C]// Proceedings of the 8th IEEE International Conference on Computer Vision. Piscataway: IEEE, 2001, 2: 416-423. 10.1109/iccv.2001.937491 |
| 35 | MATSUI Y, ITO K, ARAMAKI Y, et al. Sketch-based manga retrieval using Manga109 dataset[J]. Multimedia Tools and Applications, 2017, 76: 21811-21838. 10.1007/s11042-016-4020-z |
| 36 | WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13(4): 600-612. 10.1109/tip.2003.819861 |
| 37 | HUI Z, WANG X, GAO X. Fast and accurate single image super-resolution via information distillation network[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 723-731. 10.1109/cvpr.2018.00082 |
| 38 | HUI Z, GAO X, YANG Y, et al. Lightweight image super-resolution with information multi-distillation network[C]// Proceedings of the 27th ACM International Conference on Multimedia. New York: ACM, 2019: 2024-2032. 10.1145/3343031.3351084 |
| 39 | LI W, ZHOU K, QI L, et al. LAPAR: linearly-assembled pixel-adaptive regression network for single image super-resolution and beyond[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 20343-20355. |
| 40 | LUO X, XIE Y, ZHANG Y, et al. LatticeNet: towards lightweight image super-resolution with lattice block[C]// Proceedings of the 16th European Conference on Computer Vision. Cham: Springer, 2020: 272-289. 10.1007/978-3-030-58542-6_17 |
| 41 | ZHANG X, ZENG H, GUO S, et al. Efficient long-range attention network for image super-resolution[C]// Proceedings of the 17th European Conference on Computer Vision. Cham: Springer, 2022: 649-667. 10.1007/978-3-031-19790-1_39 |
| 42 | AHN N, KANG B, K-A SOHN. Fast, accurate, and lightweight super-resolution with cascading residual network[C]// Proceedings of the 15th European Conference on Computer Vision. Cham: Springer, 2018: 256-272. 10.1007/978-3-030-01249-6_16 |
| 43 | WANG L, DONG X, WANG Y, et al. Exploring sparsity in image super-resolution for efficient inference[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 4917-4926. 10.1109/cvpr46437.2021.00488 |
| 44 | TIAN C, ZHANG Y, ZUO W, et al. A heterogeneous group CNN for image super-resolution[J/OL]. IEEE Transactions on Neural Networks and Learning Systems, 2022 (Early Access) [2023-07-09]. . 10.1016/j.neunet.2022.06.009 |
| 45 | CONDE M V, U-J CHOI, BURCHI M, et al. Swin2SR: SwinV2 Transformer for compressed image super-resolution and restoration[C]// Proceedings of the ECCV 2022 Workshops. Cham: Springer, 2023: 669-687. 10.1007/978-3-031-25063-7_42 |
| [1] | Yunchuan HUANG, Yongquan JIANG, Juntao HUANG, Yan YANG. Molecular toxicity prediction based on meta graph isomorphism network [J]. Journal of Computer Applications, 2024, 44(9): 2964-2969. |
| [2] | Xin YANG, Xueni CHEN, Chunjiang WU, Shijie ZHOU. Short-term traffic flow prediction of urban highway based on variant residual model and Transformer [J]. Journal of Computer Applications, 2024, 44(9): 2947-2951. |
| [3] | Jing QIN, Zhiguang QIN, Fali LI, Yueheng PENG. Diagnosis of major depressive disorder based on probabilistic sparse self-attention neural network [J]. Journal of Computer Applications, 2024, 44(9): 2970-2974. |
| [4] | Xiyuan WANG, Zhancheng ZHANG, Shaokang XU, Baocheng ZHANG, Xiaoqing LUO, Fuyuan HU. Unsupervised cross-domain transfer network for 3D/2D registration in surgical navigation [J]. Journal of Computer Applications, 2024, 44(9): 2911-2918. |
| [5] | Jiepo FANG, Chongben TAO. Hybrid internet of vehicles intrusion detection system for zero-day attacks [J]. Journal of Computer Applications, 2024, 44(9): 2763-2769. |
| [6] | Liting LI, Bei HUA, Ruozhou HE, Kuang XU. Multivariate time series prediction model based on decoupled attention mechanism [J]. Journal of Computer Applications, 2024, 44(9): 2732-2738. |
| [7] | Shunyong LI, Shiyi LI, Rui XU, Xingwang ZHAO. Incomplete multi-view clustering algorithm based on self-attention fusion [J]. Journal of Computer Applications, 2024, 44(9): 2696-2703. |
| [8] | Liehong REN, Lyuwen HUANG, Xu TIAN, Fei DUAN. Multivariate long-term series forecasting method with DFT-based frequency-sensitive dual-branch Transformer [J]. Journal of Computer Applications, 2024, 44(9): 2739-2746. |
| [9] | Jieru JIA, Jianchao YANG, Shuorui ZHANG, Tao YAN, Bin CHEN. Unsupervised person re-identification based on self-distilled vision Transformer [J]. Journal of Computer Applications, 2024, 44(9): 2893-2902. |
| [10] | Jinjin LI, Guoming SANG, Yijia ZHANG. Multi-domain fake news detection model enhanced by APK-CNN and Transformer [J]. Journal of Computer Applications, 2024, 44(9): 2674-2682. |
| [11] | Yuwei DING, Hongbo SHI, Jie LI, Min LIANG. Image denoising network based on local and global feature decoupling [J]. Journal of Computer Applications, 2024, 44(8): 2571-2579. |
| [12] | Kaili DENG, Weibo WEI, Zhenkuan PAN. Industrial defect detection method with improved masked autoencoder [J]. Journal of Computer Applications, 2024, 44(8): 2595-2603. |
| [13] | Fan YANG, Yao ZOU, Mingzhi ZHU, Zhenwei MA, Dawei CHENG, Changjun JIANG. Credit card fraud detection model based on graph attention Transformation neural network [J]. Journal of Computer Applications, 2024, 44(8): 2634-2642. |
| [14] | Dahai LI, Zhonghua WANG, Zhendong WANG. Dual-branch low-light image enhancement network combining spatial and frequency domain information [J]. Journal of Computer Applications, 2024, 44(7): 2175-2182. |
| [15] | Xiting LYU, Jinghua ZHAO, Haiying RONG, Jiale ZHAO. Information diffusion prediction model based on Transformer and relational graph convolutional network [J]. Journal of Computer Applications, 2024, 44(6): 1760-1766. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||