


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (10): 2995-3010.DOI: 10.11772/j.issn.1001-9081.2023101415
• Artificial intelligence • Previous Articles Next Articles
Wenze CHAI1,2,3, Jing FAN1,2,3( ), Shukui SUN1,2,3, Yiming LIANG1,2,3, Jingfeng LIU1,2,3
), Shukui SUN1,2,3, Yiming LIANG1,2,3, Jingfeng LIU1,2,3
Received:2023-10-19
Revised:2024-02-05
Accepted:2024-02-06
Online:2024-10-15
Published:2024-10-10
Contact:
Jing FAN
About author:CHAI Wenze, born in 1998, M. S. candidate. His research interests include deep learning, image classification.Supported by:
柴汶泽1,2,3, 范菁1,2,3(), 孙书魁1,2,3, 梁一鸣1,2,3, 刘竟锋1,2,3
通讯作者:
范菁
作者简介:柴汶泽(1998—),男,山西朔州人,硕士研究生,CCF会员,主要研究方向:深度学习、图像分类基金资助:CLC Number:
Wenze CHAI, Jing FAN, Shukui SUN, Yiming LIANG, Jingfeng LIU. Overview of deep metric learning[J]. Journal of Computer Applications, 2024, 44(10): 2995-3010.
柴汶泽, 范菁, 孙书魁, 梁一鸣, 刘竟锋. 深度度量学习综述[J]. 《计算机应用》唯一官方网站, 2024, 44(10): 2995-3010.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023101415
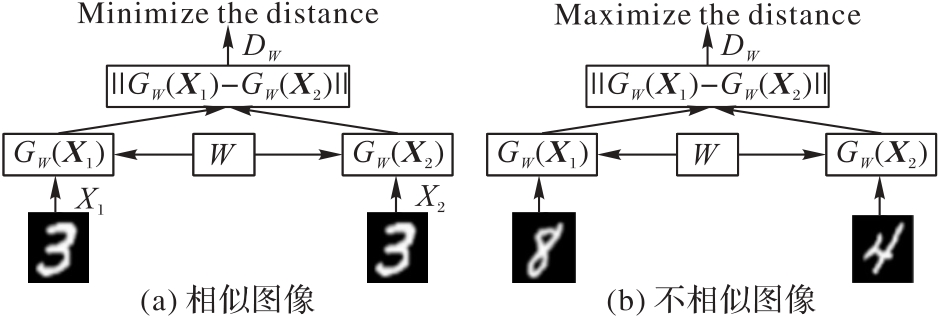
Fig. 1 Siamese network architecture
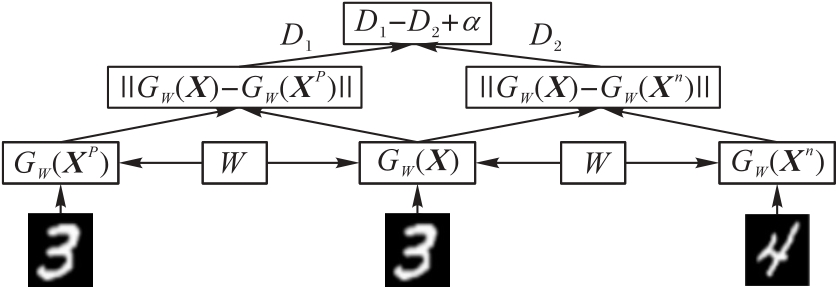
Fig. 2 Triplet network architecture
| Metric | 方法 | 优点 | 缺点 | 应用 |
|---|---|---|---|---|
| Triplet Loss | Standard Triplet Loss[ | 简单易用,计算开销小 | 容易受易分样本和难分样本的 影响,难以平衡 | 人脸识别、图像检索 |
| Semi-Hard Triplet Loss[ | 比普通三元组损失更鲁棒 | 难以摆脱难分样本的干扰 | 人脸识别、行人识别 | |
| Hard Negative Triplet Loss[ | 解决了三元组损失难以摆脱难分样本 干扰的问题 | 容易忽略其他负样本的信息, 泛化性能易受影响 | 人脸识别、行人识别 | |
Adaptive Sampling Triplet Loss[ | 动态调整正负对数,平衡易分样本和 难分样本对损失的影响 | 需要更多的计算资源, 且该方法的参数设置较复杂 | 人脸识别、图像检索 | |
| Soft-Hard Triplet Loss[ | 引入软标签,提高损失的稳定性和 分类边界的质量 | 可能需要额外的标注信息, 大规模数据集训练时可能 计算复杂度高 | 图像识别、人脸识别、 目标检测 | |
Contrastive Loss | Contrastive Loss[ | 支持学习样本之间的相似性和差异性, 明确的正负样本对比,简单易实现 | 需要平衡正负样本的数量和种类, 以避免过度拟合或欠拟合 | 图像检索、文本匹配、 特征学习 |
| N-pair Loss[ | 有效平衡易分样本和难分样本, 提高训练效果 | 相较于Triplet Loss计算开销更大, 需要构建更多的样本对 | 大规模图像分类、 语义相关任务 | |
| Non-local Triplet Loss[ | 增加了训练中样本之间的差异性, 提高了特征表示的判别能力 | 计算开销较大,需要额外的 样本挖掘和选择策略 | 图像检索、视频分析、 行人重识别 | |
Multi-modal Contrastive Loss[ | 可以学习跨模态的语义对齐信息 | 样本选择和模态间的对齐问题 较复杂,对数据预处理和模型 设计要求较高 | 图像与文本检索、 多模态推理、 跨模态检索 | |
Adaptive Weighted Contrastive Loss[ | 改善模型鲁棒性、提高样本边界 判别能力、减少样本选择的依赖 | 对参数的选择比较敏感, 计算复杂度高 | 人脸识别、目标识别、 推荐系统 | |
In-batch Contrastive Learning[ | 减少了负样本的挖掘, 加快了训练速度 | 需要合适的批次大小和样本采样 策略,对小批次可能引入噪声 | 图像分类、文本分类 | |
Generative Contrastive Loss[ | 将对比学习与生成模型结合, 同时学习数据的判别性特征和 生成性特征 | 需要合适的模型架构和训练策略, 计算复杂度较高 | 图像生成、语义分割、 图像修复 | |
| Center Loss | Contrastive Center Loss[ | 适用于样本分布明显且类别 之间有较大重叠的情况 | 不适用类别嵌入空间中存在 复杂结构的情况,可能导致 类别内部方差过大 | 图像分类、人脸识别 |
| Triplet Center Loss[ | 通过比较锚点、正样本和负样本之间的 距离,学习更具判别性的特征表示 | 容易受到困难样本选择的影响, 需要精心设计有效的采样策略 | 人脸识别、目标检测 | |
| Quadruplet Center Loss[ | 相较于三元组损失引入了额外的 易负样本,可以提高模型的判别能力 | 复杂度较高,要求样本对的构造和 选择更精细,计算代价也相应增加 | 人脸识别、 行人重识别 | |
Cross-Entropy Loss[ | — | 在分类问题中广泛使用, 易于计算和实现 | 对于度量学习任务可能不够灵活, 未考虑样本之间的具体距离信息 | — |
Region Alignment Loss | Local Triplet Loss[ | 引入局部采样和选择最近邻样本 构建三元组,处理大规模数据集 具有较低的计算开销 | 可能仅关注每个样本的局部区域, 而忽略了全局特征的信息,容易 受采样策略的影响 | 人脸识别 |
| Margin Loss | Hierarchical Margin Loss[ | 将不同难度级别的样本分为不同层次 训练,平衡易分样本和 难分样本之间的训练效果 | 需要提前确定合适的层次划分, 且需要根据实际情况调整, 对初始设置较敏感 | 图像检索 |
| Predictive Margin Loss[ | 引入额外的分类标签作为监督信息, 在优化特征向量的同时, 提高样本之间的可区分性 | 需要额外的标签信息,且大规模 数据集训练时可能计算复杂度高 | 人脸识别 | |
Deep Ensemble Metric Learning[ | 利用深度学习模型的非线性特性 提高度量学习的性能 | 模型复杂,需要大量的计算资源和 数据支持 | 图像检索、文本匹配 |
Tab. 1 Deep metric learning methods based on sample pairs
| Metric | 方法 | 优点 | 缺点 | 应用 |
|---|---|---|---|---|
| Triplet Loss | Standard Triplet Loss[ | 简单易用,计算开销小 | 容易受易分样本和难分样本的 影响,难以平衡 | 人脸识别、图像检索 |
| Semi-Hard Triplet Loss[ | 比普通三元组损失更鲁棒 | 难以摆脱难分样本的干扰 | 人脸识别、行人识别 | |
| Hard Negative Triplet Loss[ | 解决了三元组损失难以摆脱难分样本 干扰的问题 | 容易忽略其他负样本的信息, 泛化性能易受影响 | 人脸识别、行人识别 | |
Adaptive Sampling Triplet Loss[ | 动态调整正负对数,平衡易分样本和 难分样本对损失的影响 | 需要更多的计算资源, 且该方法的参数设置较复杂 | 人脸识别、图像检索 | |
| Soft-Hard Triplet Loss[ | 引入软标签,提高损失的稳定性和 分类边界的质量 | 可能需要额外的标注信息, 大规模数据集训练时可能 计算复杂度高 | 图像识别、人脸识别、 目标检测 | |
Contrastive Loss | Contrastive Loss[ | 支持学习样本之间的相似性和差异性, 明确的正负样本对比,简单易实现 | 需要平衡正负样本的数量和种类, 以避免过度拟合或欠拟合 | 图像检索、文本匹配、 特征学习 |
| N-pair Loss[ | 有效平衡易分样本和难分样本, 提高训练效果 | 相较于Triplet Loss计算开销更大, 需要构建更多的样本对 | 大规模图像分类、 语义相关任务 | |
| Non-local Triplet Loss[ | 增加了训练中样本之间的差异性, 提高了特征表示的判别能力 | 计算开销较大,需要额外的 样本挖掘和选择策略 | 图像检索、视频分析、 行人重识别 | |
Multi-modal Contrastive Loss[ | 可以学习跨模态的语义对齐信息 | 样本选择和模态间的对齐问题 较复杂,对数据预处理和模型 设计要求较高 | 图像与文本检索、 多模态推理、 跨模态检索 | |
Adaptive Weighted Contrastive Loss[ | 改善模型鲁棒性、提高样本边界 判别能力、减少样本选择的依赖 | 对参数的选择比较敏感, 计算复杂度高 | 人脸识别、目标识别、 推荐系统 | |
In-batch Contrastive Learning[ | 减少了负样本的挖掘, 加快了训练速度 | 需要合适的批次大小和样本采样 策略,对小批次可能引入噪声 | 图像分类、文本分类 | |
Generative Contrastive Loss[ | 将对比学习与生成模型结合, 同时学习数据的判别性特征和 生成性特征 | 需要合适的模型架构和训练策略, 计算复杂度较高 | 图像生成、语义分割、 图像修复 | |
| Center Loss | Contrastive Center Loss[ | 适用于样本分布明显且类别 之间有较大重叠的情况 | 不适用类别嵌入空间中存在 复杂结构的情况,可能导致 类别内部方差过大 | 图像分类、人脸识别 |
| Triplet Center Loss[ | 通过比较锚点、正样本和负样本之间的 距离,学习更具判别性的特征表示 | 容易受到困难样本选择的影响, 需要精心设计有效的采样策略 | 人脸识别、目标检测 | |
| Quadruplet Center Loss[ | 相较于三元组损失引入了额外的 易负样本,可以提高模型的判别能力 | 复杂度较高,要求样本对的构造和 选择更精细,计算代价也相应增加 | 人脸识别、 行人重识别 | |
Cross-Entropy Loss[ | — | 在分类问题中广泛使用, 易于计算和实现 | 对于度量学习任务可能不够灵活, 未考虑样本之间的具体距离信息 | — |
Region Alignment Loss | Local Triplet Loss[ | 引入局部采样和选择最近邻样本 构建三元组,处理大规模数据集 具有较低的计算开销 | 可能仅关注每个样本的局部区域, 而忽略了全局特征的信息,容易 受采样策略的影响 | 人脸识别 |
| Margin Loss | Hierarchical Margin Loss[ | 将不同难度级别的样本分为不同层次 训练,平衡易分样本和 难分样本之间的训练效果 | 需要提前确定合适的层次划分, 且需要根据实际情况调整, 对初始设置较敏感 | 图像检索 |
| Predictive Margin Loss[ | 引入额外的分类标签作为监督信息, 在优化特征向量的同时, 提高样本之间的可区分性 | 需要额外的标签信息,且大规模 数据集训练时可能计算复杂度高 | 人脸识别 | |
Deep Ensemble Metric Learning[ | 利用深度学习模型的非线性特性 提高度量学习的性能 | 模型复杂,需要大量的计算资源和 数据支持 | 图像检索、文本匹配 |
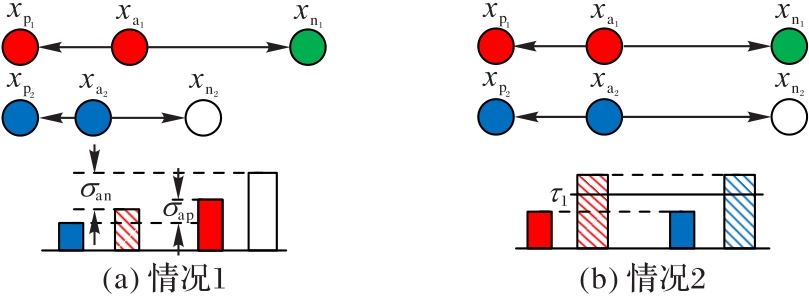
Fig. 3 Schematic diagrams of intra-pair variation

Fig. 4 Three types of similarity in negative pairs
| 类别 | 具体方法 | 优点 | 缺点 | 应用 |
|---|---|---|---|---|
基于 模型 优化 | Multi-Proxy Loss[ | 引入多个代理比较,增加了语义信息, 提高了模型的分类性能 | 增加了数据收集和标注的成本和 计算复杂度 | 图像多标签分类、 人脸识别 |
| Proxy Regularization[ | 约束特征和代理之间的距离,帮助模型 更好地学习分类决策边界 | 选择不合适的proxy样本可能导致 模型学习无效特征或产生偏差 | 图像分类、目标检测 | |
| Proxy Rebalancing[ | 模型更平衡地学习各个类别的特征和 决策边界 | 如果标签信息不准确,可能导致 性能下降或引入新的偏差 | 罕见病诊断、欺诈检测、 异常检测 | |
| Meta-learning with Proxies[ | 帮助模型更快地适应新任务或新领域 | 有一定的数据收集和标注成本 | 自然语言处理、物体识别 | |
Multi-Proxies for Metric Learning[ | 引入多个代理比较提高模型对数据集 中噪声和异常值的鲁棒性 | 在一些小规模数据集上可能过拟合 | 人脸识别、 商品推荐 | |
Domain Adaptive Person Re-identification[ | 可以解决数据分布不一致的问题 | 需要有明确的域标签或领域知识 处理域适应问题 | 跨域音频分类、 行人重识别 | |
| Proxy Networks[ | 能够较好地处理少样本学习中的数据 稀缺问题 | 在样本分布不均匀或存在噪声的 情况下,性能可能下降 | 人脸识别、物体检测 | |
Generalized Zero-Shot Learning[ | 能够解决零样本学习中类别遗漏和 数据不平衡的问题 | 对于具有复杂特征和类别间关系的 任务,合成样本可能无法完全覆盖 真实情况 | 图像识别、 自然语言处理 | |
基于 距离 | Proxy-NCA Loss[ | 可以有效地进行大规模分类任务 | 对于小规模数据集,可能导致过拟合 | 人脸识别、图像分类 |
| Proxy Alignment[ | 通过样本与类别代理之间的对齐关系, 能够有效提高分类准确性 | 对于存在类别重叠或噪声的情况, 可能无法有效学习良好的对齐关系 | 图像分类、目标检测 | |
| Proxy Triplet Loss[ | 对于类别不平衡的数据集, 具有较好的效果 | 可能存在样本难易度不均衡的问题 | 人脸验证、图像检索 | |
| Proxy Regularization[ | 通过约束代理与特征之间的关系, 可以提高特征的判别性 | 对于较小的数据集,可能导致欠拟合 | 图像分类、目标检测、 人脸识别 | |
Proxy-based Contrastive Learning[ | 不需要标注的类别信息,适用于 无监督或弱监督学习 | 对于小规模数据集,可能在负样本的 选择上存在困难 | 图像检索、聚类、 特征学习 | |
| Proxy Anchor Loss[ | 可以适应类别不平衡和 存在噪声的情况 | 计算复杂度较高,对于大规模数据集 可能效率较低 | 图像分类、目标检测、 人脸识别 | |
基于 代理 向量 | Proxy Selection[ | 计算和存储开销低,模型的效率高 | 不适用于需要完整代理信息的任务 | 大规模数据集的训练 |
| Proxy Subset Selection[ | 保留关键信息的同时减少噪声和 冗余样本 | 代理子集选择不当,可能影响模型的 性能 | 大规模数据集的训练 | |
Proxy Guided Network Pruning[ | 通过代理信息指导网络剪枝, 保留重要的特征和连接 | 可能引入一定的误差和性能损失 | 模型压缩和加速 | |
Proxy-based Anomaly Detection[ | 降低由于噪声、冗余和偏斜数据 造成的误报率 | 代理样本的选择可能影响模型的 鲁棒性和检测效果 | 网络入侵检测、 异常检测 | |
Reduced-parameter Proxy Networks[ | 有效地控制神经架构搜索的规模和 复杂度 | 参数减少,代理网络可能引入误差和 对模型性能的影响 | 神经架构搜索 | |
| Deep Neural Networks[ | 通过代理样本引导模型学习更稳定的 特征表示和决策边界 | 代理样本的选择可能会影响模型的 性能和泛化能力 | — | |
Align Classifiers with Applications[ | 通过代理样本引导不同分类器之间的 特征对齐学习 | 代理样本的选择可能会影响模型的 识别性能和鲁棒性 | 人脸识别 | |
D-VAE(DAG Variational Autoencoder)[ | 有效地建模有向无环图(Directed Acyclic Graphs, DAG)数据 | DAG数据的复杂性高和计算开销可 能导致模型的复杂度和训练难度高 | 药物预测 | |
优化 嵌入 向量 | Proxy Discrimination[ | 提高图像分类和目标检测任务的 性能和效果 | 在噪声和混淆的场景下,代理标签的 准确性可能受到影响 | 图像分类、目标检测 |
| Metric embedding[ | 增加样本间的样本对比度,提高特征 表示的判别性和鉴别性 | 多批次样本学习可能受到噪声和 错误的影响 | 人脸识别 |
Tab. 2 Deep metric learning methods based on proxies
| 类别 | 具体方法 | 优点 | 缺点 | 应用 |
|---|---|---|---|---|
基于 模型 优化 | Multi-Proxy Loss[ | 引入多个代理比较,增加了语义信息, 提高了模型的分类性能 | 增加了数据收集和标注的成本和 计算复杂度 | 图像多标签分类、 人脸识别 |
| Proxy Regularization[ | 约束特征和代理之间的距离,帮助模型 更好地学习分类决策边界 | 选择不合适的proxy样本可能导致 模型学习无效特征或产生偏差 | 图像分类、目标检测 | |
| Proxy Rebalancing[ | 模型更平衡地学习各个类别的特征和 决策边界 | 如果标签信息不准确,可能导致 性能下降或引入新的偏差 | 罕见病诊断、欺诈检测、 异常检测 | |
| Meta-learning with Proxies[ | 帮助模型更快地适应新任务或新领域 | 有一定的数据收集和标注成本 | 自然语言处理、物体识别 | |
Multi-Proxies for Metric Learning[ | 引入多个代理比较提高模型对数据集 中噪声和异常值的鲁棒性 | 在一些小规模数据集上可能过拟合 | 人脸识别、 商品推荐 | |
Domain Adaptive Person Re-identification[ | 可以解决数据分布不一致的问题 | 需要有明确的域标签或领域知识 处理域适应问题 | 跨域音频分类、 行人重识别 | |
| Proxy Networks[ | 能够较好地处理少样本学习中的数据 稀缺问题 | 在样本分布不均匀或存在噪声的 情况下,性能可能下降 | 人脸识别、物体检测 | |
Generalized Zero-Shot Learning[ | 能够解决零样本学习中类别遗漏和 数据不平衡的问题 | 对于具有复杂特征和类别间关系的 任务,合成样本可能无法完全覆盖 真实情况 | 图像识别、 自然语言处理 | |
基于 距离 | Proxy-NCA Loss[ | 可以有效地进行大规模分类任务 | 对于小规模数据集,可能导致过拟合 | 人脸识别、图像分类 |
| Proxy Alignment[ | 通过样本与类别代理之间的对齐关系, 能够有效提高分类准确性 | 对于存在类别重叠或噪声的情况, 可能无法有效学习良好的对齐关系 | 图像分类、目标检测 | |
| Proxy Triplet Loss[ | 对于类别不平衡的数据集, 具有较好的效果 | 可能存在样本难易度不均衡的问题 | 人脸验证、图像检索 | |
| Proxy Regularization[ | 通过约束代理与特征之间的关系, 可以提高特征的判别性 | 对于较小的数据集,可能导致欠拟合 | 图像分类、目标检测、 人脸识别 | |
Proxy-based Contrastive Learning[ | 不需要标注的类别信息,适用于 无监督或弱监督学习 | 对于小规模数据集,可能在负样本的 选择上存在困难 | 图像检索、聚类、 特征学习 | |
| Proxy Anchor Loss[ | 可以适应类别不平衡和 存在噪声的情况 | 计算复杂度较高,对于大规模数据集 可能效率较低 | 图像分类、目标检测、 人脸识别 | |
基于 代理 向量 | Proxy Selection[ | 计算和存储开销低,模型的效率高 | 不适用于需要完整代理信息的任务 | 大规模数据集的训练 |
| Proxy Subset Selection[ | 保留关键信息的同时减少噪声和 冗余样本 | 代理子集选择不当,可能影响模型的 性能 | 大规模数据集的训练 | |
Proxy Guided Network Pruning[ | 通过代理信息指导网络剪枝, 保留重要的特征和连接 | 可能引入一定的误差和性能损失 | 模型压缩和加速 | |
Proxy-based Anomaly Detection[ | 降低由于噪声、冗余和偏斜数据 造成的误报率 | 代理样本的选择可能影响模型的 鲁棒性和检测效果 | 网络入侵检测、 异常检测 | |
Reduced-parameter Proxy Networks[ | 有效地控制神经架构搜索的规模和 复杂度 | 参数减少,代理网络可能引入误差和 对模型性能的影响 | 神经架构搜索 | |
| Deep Neural Networks[ | 通过代理样本引导模型学习更稳定的 特征表示和决策边界 | 代理样本的选择可能会影响模型的 性能和泛化能力 | — | |
Align Classifiers with Applications[ | 通过代理样本引导不同分类器之间的 特征对齐学习 | 代理样本的选择可能会影响模型的 识别性能和鲁棒性 | 人脸识别 | |
D-VAE(DAG Variational Autoencoder)[ | 有效地建模有向无环图(Directed Acyclic Graphs, DAG)数据 | DAG数据的复杂性高和计算开销可 能导致模型的复杂度和训练难度高 | 药物预测 | |
优化 嵌入 向量 | Proxy Discrimination[ | 提高图像分类和目标检测任务的 性能和效果 | 在噪声和混淆的场景下,代理标签的 准确性可能受到影响 | 图像分类、目标检测 |
| Metric embedding[ | 增加样本间的样本对比度,提高特征 表示的判别性和鉴别性 | 多批次样本学习可能受到噪声和 错误的影响 | 人脸识别 |
| 数据集 | 详情 |
|---|---|
| CUB-200-2011 | 共200个类,包含11 788张图片:前100个类用于训练(5 864张图片),其余的类用于测试(5 924张图片) |
| Cars196 | 共196个类,共16 185张图片:前98个类用于训练(8 054张图片),其他98个类用于测试(8 131张图片) |
| SOP | 共22 634个产品,120 053张图片:前11 318个产品类别用于训练(59 551张图片),后11 316个产品类别用于测试(60 502张图片) |
| Market1501 | 共1 501个身份:750个身份用于培训,751个身份用于测试 |
| CUHK03-NP | 共1 360个标识:1 160个用于培训,100个用于测试,100个用于验证 |
| MSMT17 | 共4 101个身份和126 441个边界框,由12个室外摄像头、3个室内摄像头在12个时间段内捕获的180 h的视频组成 |
| VoxCeleb1 | 验证部分开发集包含1 211个说话人、21 819个视频和148 642个话语;测试集包含40个说话人、677个视频和4 874个话语 |
| VoxCeleb1-E | VoxCeleb1的扩展版本,包含1 251个说话人共581 480组测试对 |
Tab. 3 Details of classic datasets
| 数据集 | 详情 |
|---|---|
| CUB-200-2011 | 共200个类,包含11 788张图片:前100个类用于训练(5 864张图片),其余的类用于测试(5 924张图片) |
| Cars196 | 共196个类,共16 185张图片:前98个类用于训练(8 054张图片),其他98个类用于测试(8 131张图片) |
| SOP | 共22 634个产品,120 053张图片:前11 318个产品类别用于训练(59 551张图片),后11 316个产品类别用于测试(60 502张图片) |
| Market1501 | 共1 501个身份:750个身份用于培训,751个身份用于测试 |
| CUHK03-NP | 共1 360个标识:1 160个用于培训,100个用于测试,100个用于验证 |
| MSMT17 | 共4 101个身份和126 441个边界框,由12个室外摄像头、3个室内摄像头在12个时间段内捕获的180 h的视频组成 |
| VoxCeleb1 | 验证部分开发集包含1 211个说话人、21 819个视频和148 642个话语;测试集包含40个说话人、677个视频和4 874个话语 |
| VoxCeleb1-E | VoxCeleb1的扩展版本,包含1 251个说话人共581 480组测试对 |
| 方法 | 网络层数 | CUB-200-2011 | Cars196 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| NMI/% | R@1/% | R@2/% | R@4/% | R@8/% | NMI/% | R@1/% | R@2/% | R@4/% | R@8/% | ||
| Circleloss[ | 512 | — | 66.7 | 77.4 | 86.2 | 91.2 | — | 83.4 | 89.8 | 94.1 | 96.5 |
| ProxyAnchor[ | 512 | — | 68.4 | 79.2 | — | — | — | 86.8 | 91.6 | — | — |
| ProxyGML[ | 512 | 69.8 | 66.6 | 77.6 | — | — | 72.4 | 85.5 | 91.8 | — | — |
| DRML[ | 512 | 69.3 | 68.7 | 78.6 | — | — | 72.1 | 86.9 | 92.1 | — | — |
| PA+MemVir[ | 512 | — | 69.0 | 79.2 | — | — | — | 86.7 | 92.0 | — | — |
| HIST[ | 512 | 70.8 | 69.7 | 80.0 | 87.3 | — | 73.0 | 87.4 | 92.5 | 95.4 | — |
| PA+NIR[ | 512 | 71.0 | 70.1 | 80.1 | — | — | 73.7 | 87.9 | 92.8 | — | — |
| CCL[ | — | 71.8 | 80.8 | 87.8 | — | — | 89.6 | 93.9 | 96.4 | — | |
Tab. 4 Performance of classic methods on CUB-200-2011 and Cars196 datasets
| 方法 | 网络层数 | CUB-200-2011 | Cars196 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| NMI/% | R@1/% | R@2/% | R@4/% | R@8/% | NMI/% | R@1/% | R@2/% | R@4/% | R@8/% | ||
| Circleloss[ | 512 | — | 66.7 | 77.4 | 86.2 | 91.2 | — | 83.4 | 89.8 | 94.1 | 96.5 |
| ProxyAnchor[ | 512 | — | 68.4 | 79.2 | — | — | — | 86.8 | 91.6 | — | — |
| ProxyGML[ | 512 | 69.8 | 66.6 | 77.6 | — | — | 72.4 | 85.5 | 91.8 | — | — |
| DRML[ | 512 | 69.3 | 68.7 | 78.6 | — | — | 72.1 | 86.9 | 92.1 | — | — |
| PA+MemVir[ | 512 | — | 69.0 | 79.2 | — | — | — | 86.7 | 92.0 | — | — |
| HIST[ | 512 | 70.8 | 69.7 | 80.0 | 87.3 | — | 73.0 | 87.4 | 92.5 | 95.4 | — |
| PA+NIR[ | 512 | 71.0 | 70.1 | 80.1 | — | — | 73.7 | 87.9 | 92.8 | — | — |
| CCL[ | — | 71.8 | 80.8 | 87.8 | — | — | 89.6 | 93.9 | 96.4 | — | |
| 方法 | 网络 层数 | 指标值/% | ||||
|---|---|---|---|---|---|---|
| NMI | R@1 | R@10 | R@100 | R@1 000 | ||
| Circleloss[ | 512 | — | 83.4 | 89.8 | 94.1 | 96.5 |
| ProxyAnchor[ | 512 | — | 79.1 | 90.8 | — | — |
| ProxyGML[ | 512 | 90.2 | 78.0 | 90.6 | — | — |
| DRML[ | 512 | 88.1 | 71.5 | 85.2 | — | — |
| PA+MemVir[ | 512 | — | 79.7 | 91.0 | — | — |
| HIST[ | 512 | 92.2 | 79.6 | 91.0 | 96.2 | — |
| PA+NIR[ | 512 | 90.2 | 79.3 | 90.4 | — | — |
| CCL[ | — | 82.3 | 93.0 | 97.4 | — | |
Tab. 5 Performance of classic methods on SOP dataset
| 方法 | 网络 层数 | 指标值/% | ||||
|---|---|---|---|---|---|---|
| NMI | R@1 | R@10 | R@100 | R@1 000 | ||
| Circleloss[ | 512 | — | 83.4 | 89.8 | 94.1 | 96.5 |
| ProxyAnchor[ | 512 | — | 79.1 | 90.8 | — | — |
| ProxyGML[ | 512 | 90.2 | 78.0 | 90.6 | — | — |
| DRML[ | 512 | 88.1 | 71.5 | 85.2 | — | — |
| PA+MemVir[ | 512 | — | 79.7 | 91.0 | — | — |
| HIST[ | 512 | 92.2 | 79.6 | 91.0 | 96.2 | — |
| PA+NIR[ | 512 | 90.2 | 79.3 | 90.4 | — | — |
| CCL[ | — | 82.3 | 93.0 | 97.4 | — | |
| 方法 | Market1501 | CUHK03-NP | MSMT17 | |||
|---|---|---|---|---|---|---|
| R@1 | mAP | R@1 | mAP | R@1 | mAP | |
| M3L[ | 75.9 | 50.2 | 33.1 | 32.1 | 36.9 | 14.7 |
| OSNet-AIN[ | 94.2 | 84.4 | — | — | 23.5 | 8.2 |
| QAConv-GS[ | 91.6 | 75.5 | 19.1 | 18.1 | 45.9 | 17.2 |
| QAConv-MS[ | — | — | 26.2 | 24.3 | 48.8 | 19.3 |
Tab. 6 Performance of classic methods on Market1501,CUHK03-NP and MSMT17 datasets
| 方法 | Market1501 | CUHK03-NP | MSMT17 | |||
|---|---|---|---|---|---|---|
| R@1 | mAP | R@1 | mAP | R@1 | mAP | |
| M3L[ | 75.9 | 50.2 | 33.1 | 32.1 | 36.9 | 14.7 |
| OSNet-AIN[ | 94.2 | 84.4 | — | — | 23.5 | 8.2 |
| QAConv-GS[ | 91.6 | 75.5 | 19.1 | 18.1 | 45.9 | 17.2 |
| QAConv-MS[ | — | — | 26.2 | 24.3 | 48.8 | 19.3 |
| 数据集 | 方法 | EER/% | minDCF |
|---|---|---|---|
| VoxCeleb1 | ECAPA-TDNN[ | 0.87 | 0.107 |
| Bayesian attn-8+Channel attn[ | 0.76 | 0.077 | |
| Bayesian attn-32+Channel attn[ | 0.74 | 0.076 | |
| VoxCeleb1-E | ECAPA-TDNN[ | 1.12 | 0.132 |
| Bayesian attn-8+Channel attn[ | 1.08 | 0.079 | |
| Bayesian attn-32+Channel attn[ | 1.04 | 0.075 |
Tab. 7 Performance of classic methods on VoxCeleb1 and VoxCeleb1-E datasets
| 数据集 | 方法 | EER/% | minDCF |
|---|---|---|---|
| VoxCeleb1 | ECAPA-TDNN[ | 0.87 | 0.107 |
| Bayesian attn-8+Channel attn[ | 0.76 | 0.077 | |
| Bayesian attn-32+Channel attn[ | 0.74 | 0.076 | |
| VoxCeleb1-E | ECAPA-TDNN[ | 1.12 | 0.132 |
| Bayesian attn-8+Channel attn[ | 1.08 | 0.079 | |
| Bayesian attn-32+Channel attn[ | 1.04 | 0.075 |
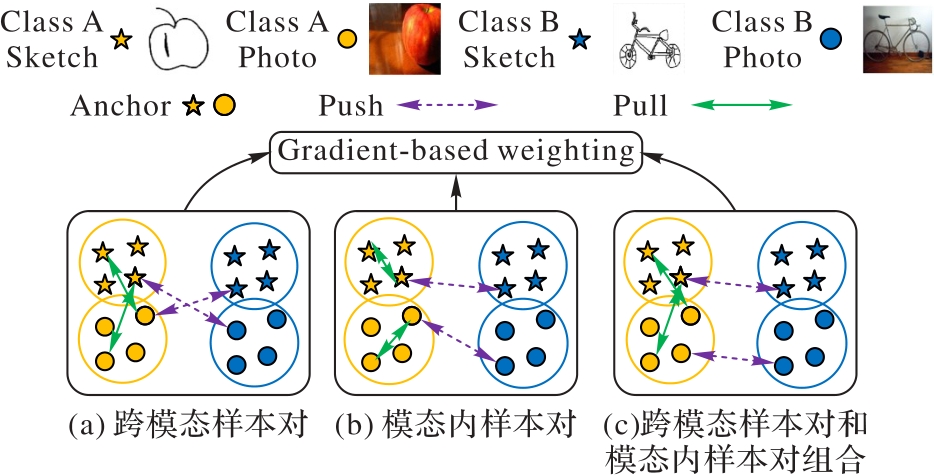
Fig. 5 Schematic diagrams of three types of triplets
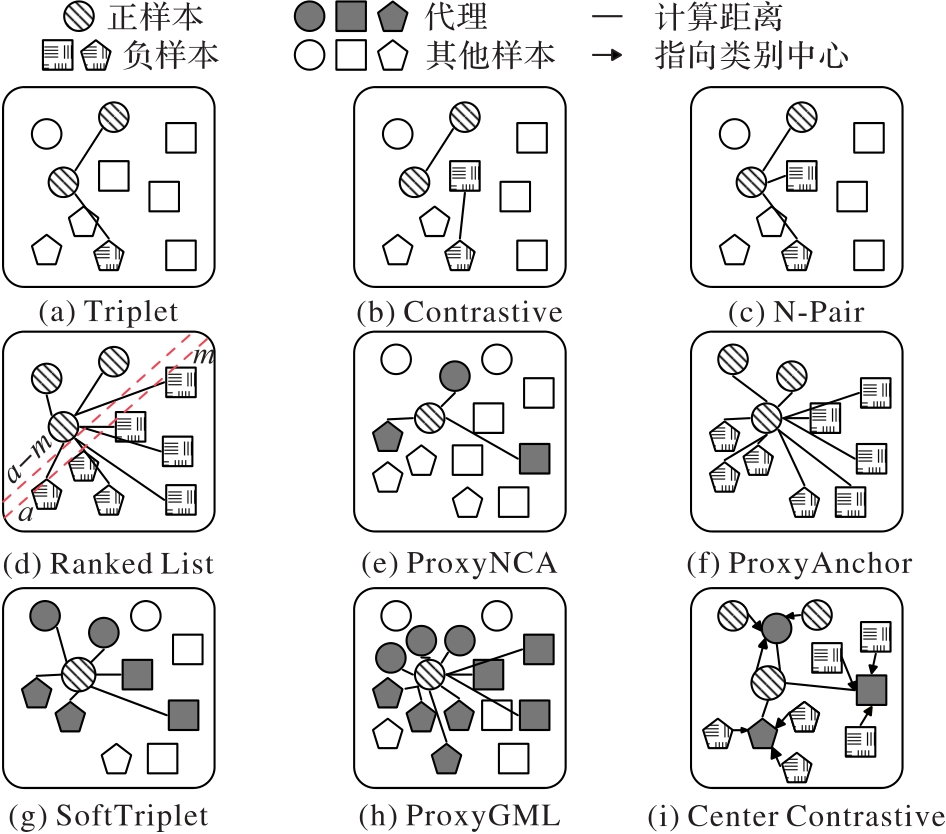
Fig. 6 Schematic diagrams of popular metric learning losses
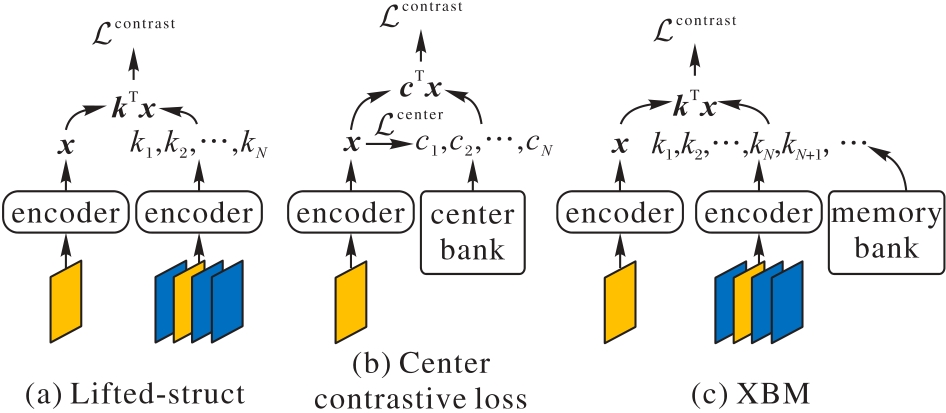
Fig. 7 Conceptual comparison of different contrastive mechanisms

Fig. 8 Working principle of AutoAugment
Fig. 9 SPA training flow
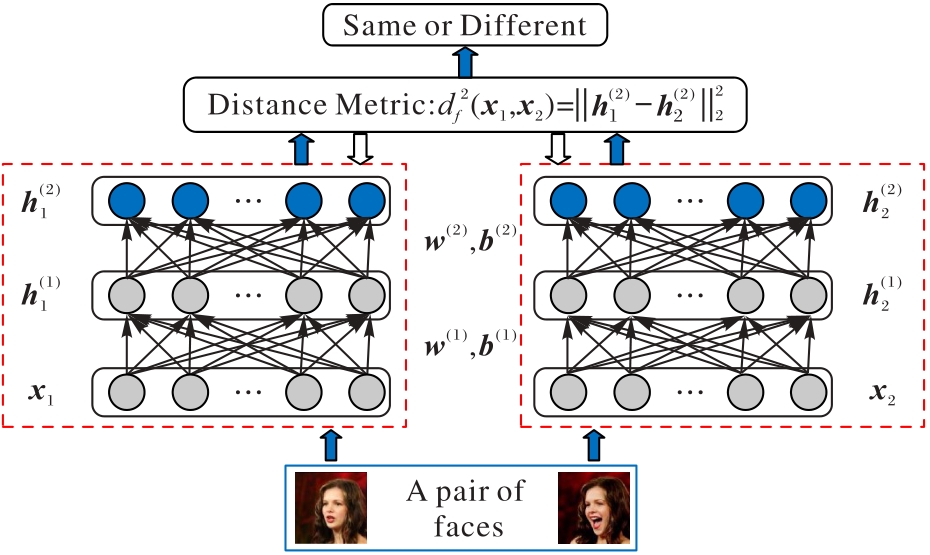
Fig. 10 Flow of DDML method for face verification
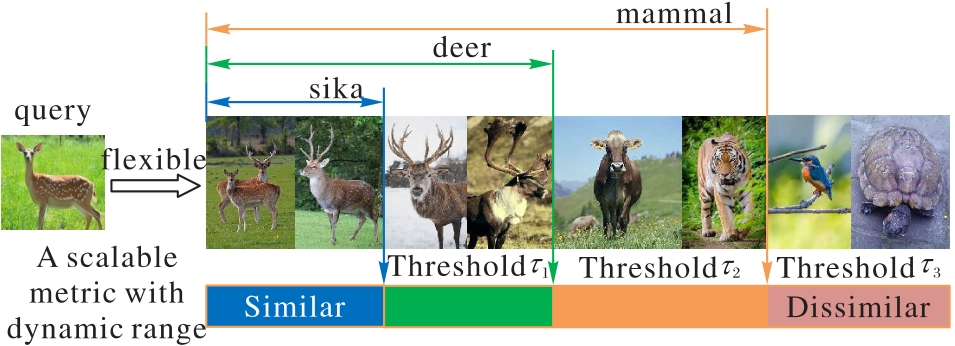
Fig. 11 Multi-scale metrics with dynamic range
| 1 | KAYA M, BİLGE H Ş. Deep metric learning: a survey[J]. Symmetry, 2019, 11(9): No.1066. |
| 2 | YU B, TAO D. Deep metric learning with tuplet margin loss[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 6489-6498. |
| 3 | LIU H, CHENG J, WANG W, et al. The general pair-based weighting loss for deep metric learning[EB/OL]. (2019-05-30) [2023-10-15]. . |
| 4 | WANG X, HAN X, HUANG W, et al. Multi-similarity loss with general pair weighting for deep metric learning[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 5017-5025. |
| 5 | BOUDIAF M, RONY J, ZIKO I M, et al. A unifying mutual information view of metric learning: cross-entropy vs. pairwise losses[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12351. Cham: Springer, 2020: 548-564. |
| 6 | YAN M, LI N. Borderline-margin loss based deep metric learning framework for imbalanced data[J]. Applied Intelligence, 2023, 53(2): 1487-1504. |
| 7 | SCHROFF F, KALENICHENKO D, PHILBIN J. FaceNet: a unified embedding for face recognition and clustering[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 815-823. |
| 8 | HERMANS A, BEYER L, LEIBE B. In defense of the triplet loss for person re-identification[EB/OL]. (2017-11-21) [2023-10-15]. . |
| 9 | XUAN H, STYLIANOU A, LIU X, et al. Hard negative examples are hard, but useful[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12359. Cham: Springer, 2020: 126-142. |
| 10 | WU C Y, MANMATHA R, SMOLA A J, et al. Sampling matters in deep embedding learning[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2859-2867. |
| 11 | YU R, DOU Z, BAI S, et al. Hard-aware point-to-set deep metric for person re-identification[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11220. Cham: Springer, 2018: 196-212. |
| 12 | HADSELL R, CHOPRA S, LeCUN Y. Dimensionality reduction by learning an invariant mapping[C]// Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition — Volume 2. Piscataway: IEEE, 2006: 1735-1742. |
| 13 | SOHN K. Improved deep metric learning with multi-class N-pair loss objective[C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2016: 1857-1865. |
| 14 | LIN Y, ZHENG L, ZHENG Z, et al. Improving person re-identification by attribute and identity learning[J]. Pattern Recognition, 2019, 95: 151-161. |
| 15 | LI J, SELVARAJU R R, GOTMARE A D, et al. Align before fuse: vision and language representation learning with momentum distillation[C]// Proceedings of the 35th Conference on Neural Information Processing Systems. New York: ACM, 2024: 9694-9705. |
| 16 | SHMELKOV K, SCHMID C, ALAHARI K. Incremental learning of object detectors without catastrophic forgetting[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 3420-3429. |
| 17 | ZHANG Y, YANG J, TAN Z, et al. RelationMatch: matching in-batch relationships for semi-supervised learning[EB/OL]. (2023-05-30) [2023-10-15]. . |
| 18 | WU C, PFROMMER J, ZHOU M, et al. Generative-contrastive learning for self-supervised latent representations of 3D shapes from multi-modal Euclidean input[EB/OL]. (2023-01-11) [2023-10-15].. |
| 19 | WEN Y, ZHANG K, LI Z, et al. A discriminative feature learning approach for deep face recognition[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9911. Cham: Springer, 2016: 499-515. |
| 20 | HE X, ZHOU Y, ZHOU Z, et al. Triplet-center loss for multi-view 3D object retrieval[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 1945-1954. |
| 21 | YU J, FENG Y. Quadruplet-center loss for face verification[C]// Proceedings of the 2019 Chinese Automation Congress. Piscataway: IEEE, 2019: 5034-5039. |
| 22 | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90. |
| 23 | XU X, HE L, LU H, et al. Deep adversarial metric learning for cross-modal retrieval[J]. World Wide Web, 2019, 22(2): 657-672. |
| 24 | QIU Z, PAN Y, YAO T, et al. Deep semantic hashing with generative adversarial networks[EB/OL]. (2018-04-23) [2023-10-15].. |
| 25 | BOUTROS F, DAMER N, KIRCHBUCHNER F, et al. ElasticFace: elastic margin loss for deep face recognition[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2022: 1577-1586. |
| 26 | WANG N, ZHOU W, TIAN Q, et al. Multi-cue correlation filters for robust visual tracking[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 4844-4853. |
| 27 | SONG H O, XIANG Y, JEGELKA S, et al. Deep metric learning via lifted structured feature embedding[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 4004-4012. |
| 28 | SUN Y, CHENG C, ZHANG Y, et al. Circle loss: a unified perspective of pair similarity optimization[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 6397-6406. |
| 29 | WANG X, HUA Y, KODIROV E, et al. Ranked list loss for deep metric learning[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 5202-5211. |
| 30 | CAKIR F, HE K, XIA X, et al. Deep metric learning to rank[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 1861-1870. |
| 31 | FU Z, MAO Z, YAN C, et al. Self-supervised synthesis ranking for deep metric learning[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(7): 4736-4750. |
| 32 | DUAN Y, ZHENG W, LIN X, et al. Deep adversarial metric learning[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 2780-2789. |
| 33 | JACOB P, PICARD D, HISTACE A. Improving deep metric learning with virtual classes and examples mining[C]// Proceedings of the 2022 IEEE International Conference on Image Processing. Piscataway: IEEE, 2022: 2696-2700. |
| 34 | HUANG W, ZHANG S, ZHANG P, et al. Identity-aware facial expression recognition via deep metric learning based on synthesized images[J]. IEEE Transactions on Multimedia, 2022, 24: 3327-3339. |
| 35 | DENG X, WU W, WANG F. Deep metric learning for text data based on triplet network[J]. IOP Conference Series: Materials Science and Engineering, 2020, 806: No.012038. |
| 36 | MATTIES M A. Vector embeddings with subvector permutation invariance using a triplet enhanced autoencoder[EB/OL]. (2020-10-18) [2023-10-15].. |
| 37 | WANG J, WANG K C, LAW M T, et al. Centroid-based deep metric learning for speaker recognition[C]// Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2019: 3652-3656. |
| 38 | MA Y, HE Y, ZHANG A, et al. CrossCBR: cross-view contrastive learning for bundle recommendation[C]// Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. New York: ACM, 2022: 1233-1241. |
| 39 | SABERI-MOVAHED F, EBRAHIMPOUR M K, SABERI-MOVAHED F, et al. Deep metric learning with soft orthogonal proxies[EB/OL]. (2023-06-22) [2023-10-15].. |
| 40 | GU G, KO B, KIM H G. Proxy Synthesis: learning with synthetic classes for deep metric learning[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 1460-1468. |
| 41 | ZHAI A, WU H Y. Classification is a strong baseline for deep metric learning[C]// Proceedings of the 2019 British Machine Vision Conference. Durham: BMVA Press, 2019: No.1206. |
| 42 | ZHAO X, QI H, LUO R, et al. A weakly supervised adaptive triplet loss for deep metric learning[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshops. Piscataway: IEEE, 2019: 3177-3180. |
| 43 | FEHERVARI I, MACEDO I. Adaptive additive classification-based loss for deep metric learning[EB/OL]. (2020-06-25) [2023-10-15].. |
| 44 | KIM M, GUERRERO R, PHAM H X, et al. Variational continual proxy-anchor for deep metric learning[C]// Proceedings of the 25th International Conference on Artificial Intelligence and Statistics. New York: JMLR.org, 2022: 4552-4573. |
| 45 | PORZI L, HOFINGER M, RUIZ I, et al. Learning multi-object tracking and segmentation from automatic annotations[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 6845-6854. |
| 46 | ZHANG W, OUYANG W, LI W, et al. Collaborative and adversarial network for unsupervised domain adaptation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 3801-3809. |
| 47 | BENGAR J Z, VAN DE WEIJER J, FUENTES L L, et al. Class-balanced active learning for image classification[C]// Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2022: 3708-3716. |
| 48 | FINN C, ABBEEL P, LEVINE S. Model-agnostic meta-learning for fast adaptation of deep networks[C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 1126-1135. |
| 49 | SAEKI S, KAWAHARA M, AMAN H. Multi proxy anchor family loss for several types of gradients[J]. Computer Vision and Image Understanding, 2023, 229: No.103654. |
| 50 | LIU X, ZHANG S. Domain adaptive person re-identification via coupling optimization[C]// Proceedings of the 28th ACM International Conference on Multimedia. New York: ACM, 2020: 547-555. |
| 51 | XIAO B, LIU C L, HSAIO W H. Proxy network for few shot learning[C]// Proceedings of the 12th Asian Conference on Machine Learning. New York: JMLR.org, 2020: 657-672. |
| 52 | VERMA V K, ARORA G, MISHRA A, et al. Generalized zero-shot learning via synthesized examples[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 4281-4289. |
| 53 | MOVSHOVITZ-ATTIAS Y, TOSHEV A, LEUNG T K, et al. No fuss distance metric learning using proxies[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 360-368. |
| 54 | LI S, GAO P, TAN X, et al. ProxyFormer: proxy alignment assisted point cloud completion with missing part sensitive transformer[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 9466-9475. |
| 55 | WU H, SHEN F, ZHU J, et al. A sample-proxy dual triplet loss function for object re-identification[J]. IET Image Processing, 2022, 16(14): 3781-3789. |
| 56 | ROTH K, VINYALS O, AKATA Z. Non-isotropy regularization for proxy-based deep metric learning[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 7410-7420. |
| 57 | CHEN T, KORNBLITH S, SWERSKY K, et al. Big self-supervised models are strong semi-supervised learners[C]// Proceedings of the 34th Conference on Neural Information Processing Systems. New York: ACM, 2020: 22243-22255. |
| 58 | KIM S, KIM D, CHO M, et al. Proxy anchor loss for deep metric learning[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 3235-3244. |
| 59 | CHO J, KANG S, HYUN D, et al. Unsupervised proxy selection for session-based recommender systems[C]// Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2021: 327-336. |
| 60 | COLEMAN C, YEH C, MUSSMANN S, et al. Selection via proxy: efficient data selection for deep learning[EB/OL]. (2020-10-27) [2023-10-15].. |
| 61 | LIU Z, LI J, SHEN Z, et al. Learning efficient convolutional networks through network slimming[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2755-2763. |
| 62 | LIZNERSKI P, RUFF L, VANDERMEULEN R A, et al. Explainable deep one-class classification[EB/OL]. (2021-03-18) [2023-10-15].. |
| 63 | NA B, MOK J, CHOE H, et al. Accelerating neural architecture search via proxy data[C]// Proceedings of the 30th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2021: 2848-2854. |
| 64 | ZHENG S, SONG Y, LEUNG T, et al. Improving the robustness of deep neural networks via stability training[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 4480-4488. |
| 65 | POMĚNKOVÁ J, MALACH T. Optimized classifier learning for face recognition performance boost in security and surveillance applications[J]. Sensors, 2023, 23(15): No.7012. |
| 66 | ZHANG M, JIANG S, CUI Z, et al. D-VAE: a variational autoencoder for directed acyclic graphs[C]// Proceedings of the 33rd Conference on Neural Information Processing Systems. New York: ACM, 2019: 1588-1600. |
| 67 | TSCHANTZ M C. What is proxy discrimination?[C]// Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency. New York: ACM, 2022: 1993-2003. |
| 68 | TADMOR O, ROSENWEIN T, SHALEV-SHWARTZ S, et al. Learning a metric embedding for face recognition using the multibatch method[C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2016: 1396-1397. |
| 69 | WANG C, JIANG Z, YIN Y, et al. Controlling class layout for deep ordinal classification via constrained proxies learning[C]// Proceedings of the 37th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023: 2483-2491. |
| 70 | FURUSAWA T. Mean field theory in deep metric learning[EB/OL]. (2023-06-27) [2023-10-15].. |
| 71 | YAO X, SHE D, ZHANG H, et al. Adaptive deep metric learning for affective image retrieval and classification[J]. IEEE Transactions on Multimedia, 2021, 23: 1640-1653. |
| 72 | HUA Y, YANG Y, DU J. Deep multi-modal metric learning with multi-scale correlation for image-text retrieval[J]. Electronics, 2020, 9(3): No.466. |
| 73 | MEI X, LIU X, SUN J, et al. On metric learning for audio-text cross-modal retrieval[C]// Proceedings of the INTERSPEECH 2022. [S.l.]: International Speech Communication Association, 2022: 4142-4146. |
| 74 | CHEN T, KORNBLITH S, NOROUZI M, et al. A simple framework for contrastive learning of visual representations[C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 1597-1607. |
| 75 | MOCANU B, TAPU R, ZAHARIA T. Multimodal emotion recognition using cross modal audio-video fusion with attention and deep metric learning[J]. Image and Vision Computing, 2023, 133: No.104676. |
| 76 | HUANG Z, SUN Y, HAN C, et al. Modality-aware triplet hard mining for zero-shot sketch-based image retrieval[EB/OL]. (2021-12-16) [2023-10-15].. |
| 77 | WANG J, SONG Y, LEUNG T, et al. Learning fine-grained image similarity with deep ranking[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2014: 1386-1393. |
| 78 | MA C, SUN H, ZHU J, et al. Normalized maximal margin loss for open-set image classification[J]. IEEE Access, 2021, 9: 54276-54285. |
| 79 | ZHU Y, YANG M, DENG C, et al. Fewer is more: a deep graph metric learning perspective using fewer proxies[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 17792-17803. |
| 80 | ZHENG W, ZHANG B, LU J, et al. Deep relational metric learning[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 12045-12054. |
| 81 | KO B, GU G, KIM H G. Learning with memory-based virtual classes for deep metric learning[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 11772-11781. |
| 82 | LIM J, YUN S, PARK S, et al. Hypergraph-induced semantic tuplet loss for deep metric learning[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 212-222. |
| 83 | CAI B, XIONG P, TIAN S. Center contrastive loss for metric learning[EB/OL]. (2023-08-01) [2023-10-15].. |
| 84 | ZHAO Y, ZHONG Z, YANG F, et al. Learning to generalize unseen domains via memory-based multi-source meta-learning for person re-identification[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 6273-6282. |
| 85 | ZHOU K, YANG Y, CAVALLARO A, et al. Learning generalisable omni-scale representations for person re-identification[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(9): 5056-5069. |
| 86 | LIAO S, SHAO L. Graph sampling based deep metric learning for generalizable person re-identification[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 7349-7358. |
| 87 | CHEN K, GONG T, ZHANG L. Multi-scale query-adaptive convolution for generalizable person re-identification[C]// Proceedings of the 2023 IEEE International Conference on Multimedia and Expo. Piscataway: IEEE, 2023: 2411-2416. |
| 88 | DESPLANQUES B, THIENPONDT J, DEMUYNCK K. ECAPA-TDNN: emphasized channel attention, propagation and aggregation in TDNN based speaker verification[C]// Proceedings of the INTERSPEECH 2020. [S.l.]: International Speech Communication Association, 2020: 3830-3834. |
| 89 | ZHU Y, MAK B. Bayesian self-attentive speaker embeddings for text-independent speaker verification[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023, 31: 1000-1012. |
| 90 | WANG F, XIANG X, CHENG J, et al. NormFace: L2 hypersphere embedding for face verification[C]// Proceedings of the 25th ACM International Conference on Multimedia. New York: ACM, 2017: 1041-1049. |
| 91 | LIU W, WEN Y, YU Z, et al. Large-margin softmax loss for convolutional neural networks[C]// Proceedings of the 33rd International Conference on Machine Learning. New York: JMLR.org, 2016: 507-516. |
| 92 | LIU W, WEN Y, YU Z, et al. SphereFace: deep hypersphere embedding for face recognition[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6738-6746. |
| 93 | QIAN Q, SHANG L, SUN B, et al. SoftTriple loss: deep metric learning without triplet sampling[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 6449-6457. |
| 94 | VAN DEN OORD A, LI Y, VINYALS O. Representation learning with contrastive predictive coding[EB/OL]. (2019-01-22) [2023-10-15].. |
| 95 | WANG X, ZHANG H, HUANG W, et al. Cross-batch memory for embedding learning[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 6387-6396. |
| 96 | WANG H, WANG Y, ZHOU Z, et al. CosFace: large margin cosine loss for deep face recognition[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 5265-5274. |
| 97 | FENG Y, YOU H, ZHANG Z, et al. Hypergraph neural networks[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2019: 3558-3565. |
| 98 | CUBUK E D, ZOPH B, MANÉ D, et al. Autoaugment: learning augmentation strategies from data[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 113-123. |
| 99 | HATAYA R, ZDENEK J, YOSHIZOE K, et al. Meta approach to data augmentation optimization[C]// Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2022: 3535-3544. |
| 100 | TAKASE T, KARAKIDA R, ASOH H. Self-paced data augmentation for training neural networks[J]. Neurocomputing, 2021, 442: 296-306. |
| 101 | TANG Z, PENG X, LI T, et al. AdaTransform: adaptive data transformation[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 2998-3006. |
| 102 | ZHE X, CHEN S, YAN H. Directional statistics-based deep metric learning for image classification and retrieval[J]. Pattern Recognition, 2019, 93: 113-123. |
| 103 | HU J, LU J, TAN Y P. Discriminative deep metric learning for face verification in the wild[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2014: 1875-1882. |
| 104 | LU J, HU J, TAN Y P. Discriminative deep metric learning for face and kinship verification[J]. IEEE Transactions on Image Processing, 2017, 26(9): 4269-4282. |
| 105 | GOLWALKAR R, MEHENDALE N. Masked-face recognition using deep metric learning and FaceMaskNet-21[J]. Applied Intelligence, 2022, 52(11): 13268-13279. |
| 106 | YUCER S, AKGUL Y S. 3D human action recognition with Siamese-LSTM based deep metric learning[J]. Journal of Image and Graphics, 2018, 6(1): 21-26. |
| 107 | GUTOSKI M, LAZZARETTI A E, LOPES H S. Deep metric learning for open-set human action recognition in videos[J]. Neural Computing and Applications, 2021, 33(4): 1207-1220. |
| 108 | SUN Y, ZHU Y, ZHANG Y, et al. Dynamic metric learning: towards a scalable metric space to accommodate multiple semantic scales[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 5389-5398. |
| 109 | WU S, GONG X. BoundaryFace: a mining framework with noise label self-correction for face recognition[C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13673. Cham: Springer, 2022: 91-106. |
| 110 | LI S, XIA X, GE S, et al. Selective-supervised contrastive learning with noisy labels[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 316-325. |
| 111 | ZHENG W, HUANG Y, ZHANG B, et al. Dynamic metric learning with cross-level concept distillation[C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13684. Cham: Springer, 2022: 197-213. |
| 112 | RO Y, CHOI J Y. Heterogeneous double-head ensemble for deep metric learning[J]. IEEE Access, 2020, 8: 118525-118533. |
| 113 | LIU C, YU H, LI B, et al. Noise-resistant deep metric learning with ranking-based instance selection[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 6807-6816. |
| 114 | BURIS L H, PEDRONETTE D C G, PAPA J P, et al. Mixup-based deep metric learning approaches for incomplete supervision[C]// Proceedings of the 2022 IEEE International Conference on Image Processing. Piscataway: IEEE, 2022: 2581-2585. |
| 115 | MEYER B J, HARWOOD B, DRUMMOND T. Deep metric learning and image classification with nearest neighbour Gaussian kernels[C]// Proceedings of the 2018 IEEE International Conference on Image Processing. Piscataway: IEEE, 2018: 151-155. |
| 116 | ZHANG H, CISSE M, DAUPHIN Y N, et al. mixup: beyond empirical risk minimization[EB/OL]. (2018-04-27) [2023-10-15].. |
| 117 | ZHANG D, LI Y, ZHANG Z. Deep metric learning with spherical embedding[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 18772-18783. |
| 118 | 李子龙,周勇,鲍蓉,等. 优化三元组损失的深度距离度量学习方法[J].计算机应用, 2021, 41(12):3480-3484. |
| LI Z L, ZHOU Y, BAO R, et al. Deep distance metric learning method based on optimized triplet loss[J]. Journal of Computer Applications, 2021, 41(12): 3480-3484. | |
| 119 | KIM Y, PARK W. Multi-level distance regularization for deep metric learning[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 1827-1835. |
| [1] | Yexin PAN, Zhe YANG. Optimization model for small object detection based on multi-level feature bidirectional fusion [J]. Journal of Computer Applications, 2024, 44(9): 2871-2877. |
| [2] | Shuai FU, Xiaoying GUO, Ruyi BAI, Tao YAN, Bin CHEN. Age estimation method combining improved CloFormer model and ordinal regression [J]. Journal of Computer Applications, 2024, 44(8): 2372-2380. |
| [3] | Rui SHI, Yong LI, Yanhan ZHU. Adversarial sample attack algorithm of modulation signal based on equalization of feature gradient [J]. Journal of Computer Applications, 2024, 44(8): 2521-2527. |
| [4] | Sailong SHI, Zhiwen FANG. Gaze estimation model based on multi-scale aggregation and shared attention [J]. Journal of Computer Applications, 2024, 44(7): 2047-2054. |
| [5] | Zihao YAO, Yuanming LI, Ziqiang MA, Yang LI, Lianggen WEI. Multi-object cache side-channel attack detection model based on machine learning [J]. Journal of Computer Applications, 2024, 44(6): 1862-1871. |
| [6] | Mei WANG, Xuesong SU, Jia LIU, Ruonan YIN, Shan HUANG. Time series classification method based on multi-scale cross-attention fusion in time-frequency domain [J]. Journal of Computer Applications, 2024, 44(6): 1842-1847. |
| [7] | Xuebin CHEN, Zhiqiang REN, Hongyang ZHANG. Review on security threats and defense measures in federated learning [J]. Journal of Computer Applications, 2024, 44(6): 1663-1672. |
| [8] | Ziwen SUN, Lizhi QIAN, Chuandong YANG, Yibo GAO, Qingyang LU, Guanglin YUAN. Survey of visual object tracking methods based on Transformer [J]. Journal of Computer Applications, 2024, 44(5): 1644-1654. |
| [9] | Bin XIAO, Mo YANG, Min WANG, Guangyuan QIN, Huan LI. Domain generalization method of phase-frequency fusion from independent perspective [J]. Journal of Computer Applications, 2024, 44(4): 1002-1009. |
| [10] | Wei SHE, Yang LI, Lihong ZHONG, Defeng KONG, Zhao TIAN. Hyperparameter optimization for neural network based on improved real coding genetic algorithm [J]. Journal of Computer Applications, 2024, 44(3): 671-676. |
| [11] | Yi ZHENG, Cunyi LIAO, Tianqian ZHANG, Ji WANG, Shouyin LIU. Image denoising-based cell-level RSRP estimation method for urban areas [J]. Journal of Computer Applications, 2024, 44(3): 855-862. |
| [12] | Mengmei YAN, Dongping YANG. Review of mean field theory for deep neural network [J]. Journal of Computer Applications, 2024, 44(2): 331-343. |
| [13] | Yudong PANG, Zhixing LI, Weijie LIU, Tianhao LI, Ningning WANG. Small target detection model in overlooking scenes on tower cranes based on improved real-time detection Transformer [J]. Journal of Computer Applications, 2024, 44(12): 3922-3929. |
| [14] | Xuebin CHEN, Changsheng QU. Overview of backdoor attacks and defense in federated learning [J]. Journal of Computer Applications, 2024, 44(11): 3459-3469. |
| [15] | Yongjiang LIU, Bin CHEN. Pixel-level unsupervised industrial anomaly detection based on multi-scale memory bank [J]. Journal of Computer Applications, 2024, 44(11): 3587-3594. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||