


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (11): 3345-3353.DOI: 10.11772/j.issn.1001-9081.2023111693
• Artificial intelligence • Previous Articles Next Articles
Jie WU( ), Xuezhong QIAN, Wei SONG
), Xuezhong QIAN, Wei SONG
Received:2023-12-08
Revised:2024-03-06
Accepted:2024-03-14
Online:2024-03-22
Published:2024-11-10
Contact:
Jie WU
About author:QIAN Xuezhong, born in 1967, M. S., associate professor. His research interests include data mining, machine learning, artificial intelligence.Supported by:
巫婕(), 钱雪忠, 宋威
通讯作者:
巫婕
作者简介:钱雪忠(1967—),男,江苏无锡人,副教授,硕士,CCF会员,主要研究方向:数据挖掘、机器学习、人工智能基金资助:CLC Number:
Jie WU, Xuezhong QIAN, Wei SONG. Personalized federated learning based on similarity clustering and regularization[J]. Journal of Computer Applications, 2024, 44(11): 3345-3353.
巫婕, 钱雪忠, 宋威. 基于相似度聚类和正则化的个性化联邦学习[J]. 《计算机应用》唯一官方网站, 2024, 44(11): 3345-3353.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023111693
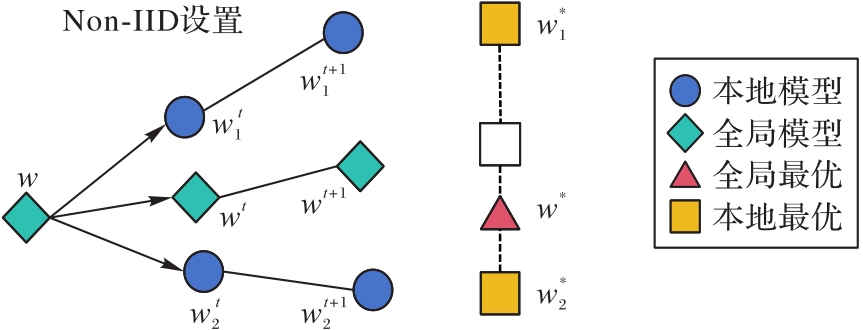
Fig. 1 Influence of Non-IID data on model update
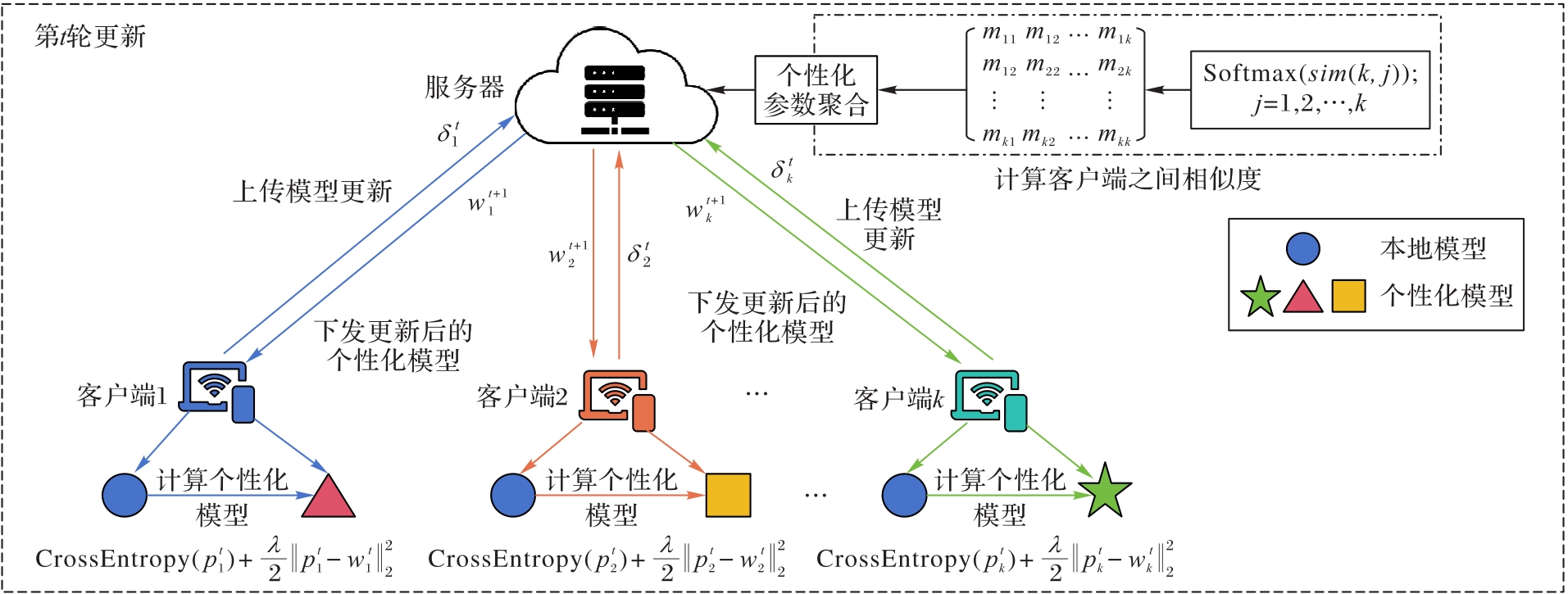
Fig. 2 Overall framework of pFedSCR
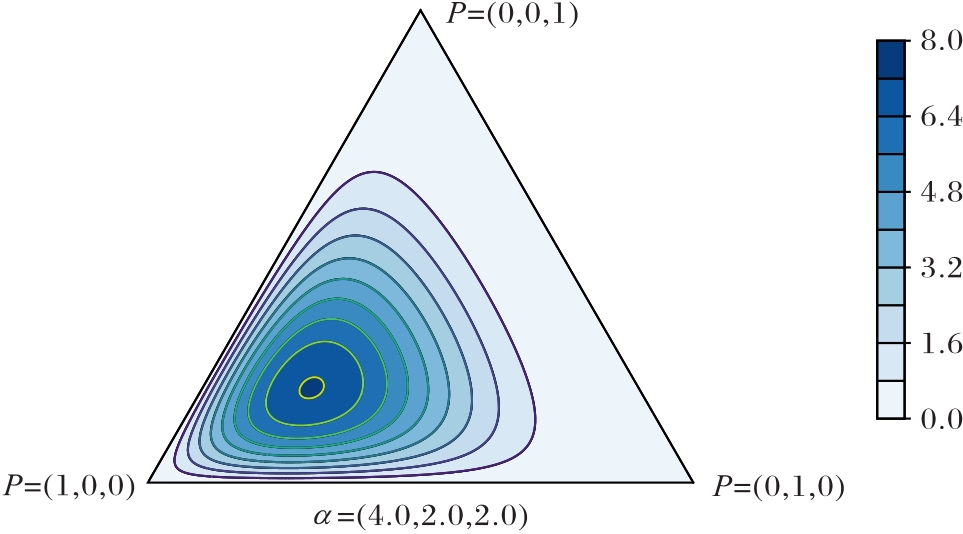
Fig. 3 Dirichlet distribution
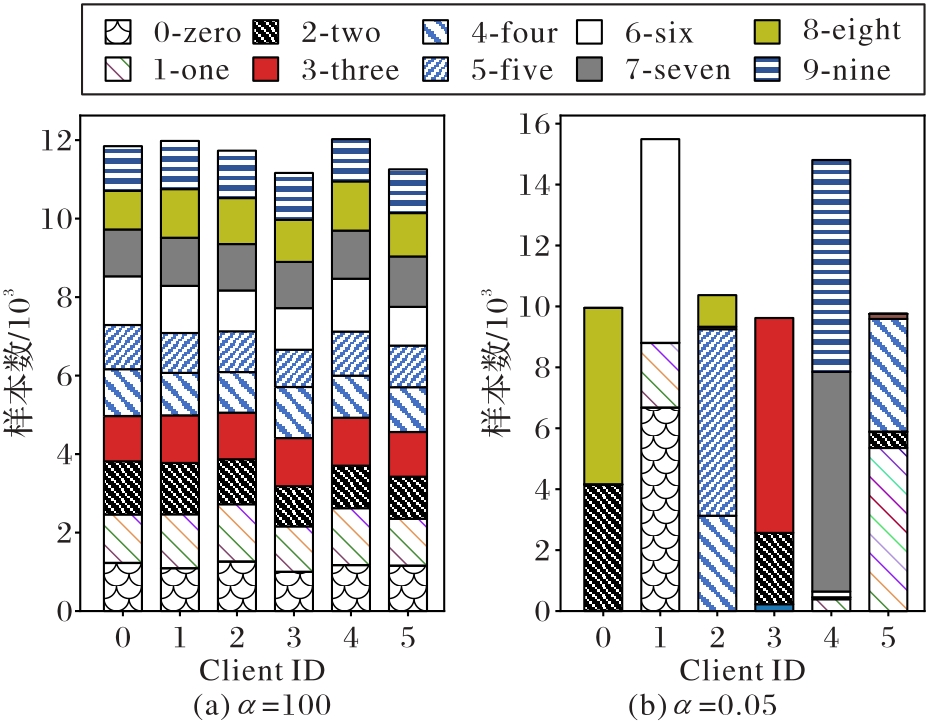
Fig. 4 Non-IID data division of different clients
| 参数 | 描述 | 默认值 |
|---|---|---|
| 学习率 | 0.01 | |
| K | 客户端总数 | 20 |
| B | Batch size | 10 |
| 学习衰减率 | 0.99 | |
| E | 本地更新Epoch | 5 |
| T | 训练总轮数 | 100 |
| α | Dirichlet参数 | 0.03 |
| 损失项平衡参数 | 1 | |
| β | 客户端贡献值 | 0.2 |
Tab. 1 Experimental default parameters
| 参数 | 描述 | 默认值 |
|---|---|---|
| 学习率 | 0.01 | |
| K | 客户端总数 | 20 |
| B | Batch size | 10 |
| 学习衰减率 | 0.99 | |
| E | 本地更新Epoch | 5 |
| T | 训练总轮数 | 100 |
| α | Dirichlet参数 | 0.03 |
| 损失项平衡参数 | 1 | |
| β | 客户端贡献值 | 0.2 |
| 数据集 | α | 准确度/% | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| FedAvg | FedProx | FedAvg+DBE | MOON | FedPCL | FedBN | FedPAC | FedGH | pFedSCR | ||
| MNIST | 0.01 | 86.87 | 87.71 | 98.07 | 87.50 | 87.89 | 87.61 | 98.77 | 98.76 | 98.35 |
| 0.03 | 94.08 | 96.30 | 96.97 | 96.29 | 96.63 | 96.26 | 99.56 | 99.04 | 97.95 | |
| 0.05 | 95.90 | 96.12 | 98.47 | 95.94 | 94.15 | 96.20 | 98.57 | 98.99 | 99.03 | |
| CIFAR-10 | 0.1 | 58.37 | 61.29 | 69.02 | 60.81 | 62.90 | 59.08 | 70.23 | 82.51 | 77.58 |
| 0.03 | 56.61 | 58.81 | 70.25 | 60.11 | 75.59 | 64.86 | 68.56 | 74.13 | 79.31 | |
| 0.05 | 55.00 | 55.39 | 75.35 | 59.81 | 61.01 | 60.78 | 78.53 | 77.02 | 78.92 | |
| Fashion-MNIST | 0.1 | 86.03 | 86.23 | 86.99 | 86.18 | 86.03 | 86.05 | 91.83 | 95.32 | 92.32 |
| 0.03 | 79.53 | 78.99 | 88.40 | 79.92 | 85.57 | 79.40 | 92.34 | 97.80 | 89.88 | |
Tab. 2 Accuracy comparison of proposed algorithm and baseline algorithms on different class distributions
| 数据集 | α | 准确度/% | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| FedAvg | FedProx | FedAvg+DBE | MOON | FedPCL | FedBN | FedPAC | FedGH | pFedSCR | ||
| MNIST | 0.01 | 86.87 | 87.71 | 98.07 | 87.50 | 87.89 | 87.61 | 98.77 | 98.76 | 98.35 |
| 0.03 | 94.08 | 96.30 | 96.97 | 96.29 | 96.63 | 96.26 | 99.56 | 99.04 | 97.95 | |
| 0.05 | 95.90 | 96.12 | 98.47 | 95.94 | 94.15 | 96.20 | 98.57 | 98.99 | 99.03 | |
| CIFAR-10 | 0.1 | 58.37 | 61.29 | 69.02 | 60.81 | 62.90 | 59.08 | 70.23 | 82.51 | 77.58 |
| 0.03 | 56.61 | 58.81 | 70.25 | 60.11 | 75.59 | 64.86 | 68.56 | 74.13 | 79.31 | |
| 0.05 | 55.00 | 55.39 | 75.35 | 59.81 | 61.01 | 60.78 | 78.53 | 77.02 | 78.92 | |
| Fashion-MNIST | 0.1 | 86.03 | 86.23 | 86.99 | 86.18 | 86.03 | 86.05 | 91.83 | 95.32 | 92.32 |
| 0.03 | 79.53 | 78.99 | 88.40 | 79.92 | 85.57 | 79.40 | 92.34 | 97.80 | 89.88 | |
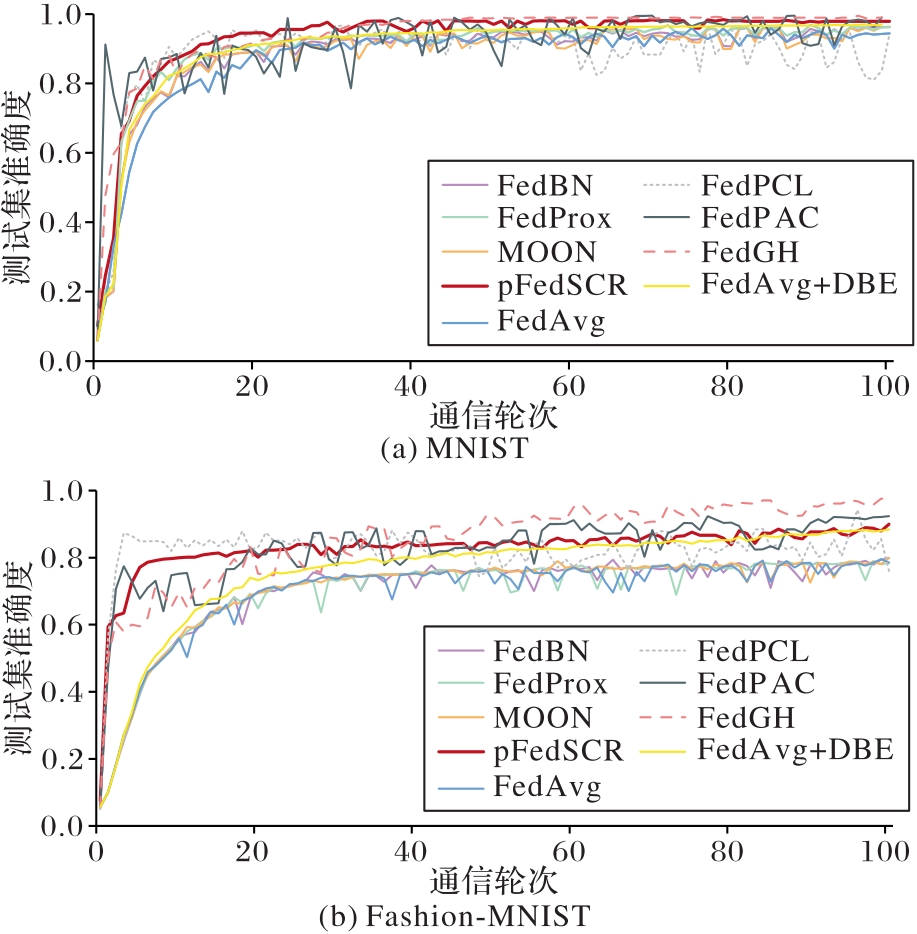
Fig. 5 Test accuracy under default parameter setting
| FL算法 | 达目标准确度所需的通信轮次 | ||
|---|---|---|---|
| MNIST | CIFAR-10 | Fashion-MNIST | |
| FedAvg | 100 | 100 | 100 |
| FedProx | 40 | 100 | — |
| FedBN | 50 | 89 | — |
| MOON | 45 | 91 | 100 |
| FedPCL | 29 | 50 | 65 |
| FedGH | 20 | 48 | 41 |
| FedAvg+DBE | 32 | 50 | 52 |
| FedPAC | 30 | 59 | 43 |
| pFedSCR | 30 | 48 | 50 |
Tab. 3 Communication rounds required to reach target accuracy under default parameters
| FL算法 | 达目标准确度所需的通信轮次 | ||
|---|---|---|---|
| MNIST | CIFAR-10 | Fashion-MNIST | |
| FedAvg | 100 | 100 | 100 |
| FedProx | 40 | 100 | — |
| FedBN | 50 | 89 | — |
| MOON | 45 | 91 | 100 |
| FedPCL | 29 | 50 | 65 |
| FedGH | 20 | 48 | 41 |
| FedAvg+DBE | 32 | 50 | 52 |
| FedPAC | 30 | 59 | 43 |
| pFedSCR | 30 | 48 | 50 |
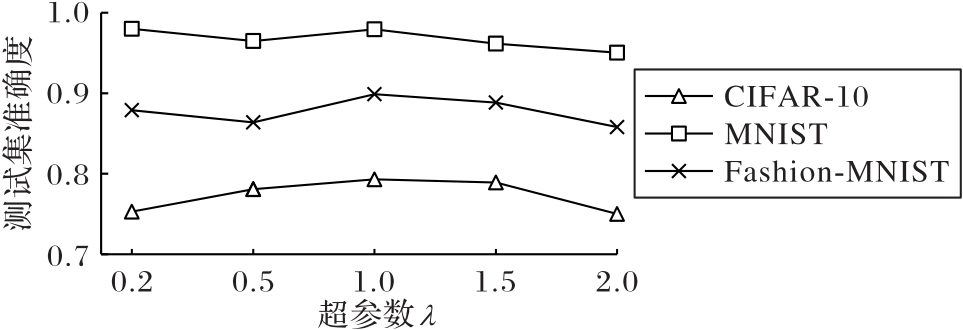
Fig. 6 Influence of hyperparameters λ on model performance

Fig. 7 Influence of local Epoch number on model performance
| 1 | 杨强,刘洋,陈天健,等.联邦学习[J].中国计算机学会通讯, 2018,14(11):49-55. |
| YANG Q, LIU Y, CHEN T J, et al. Federated learning[J]. Communications of the CCF, 2018, 14(11): 49-55. | |
| 2 | McMAHAN B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data[C]// Proceedings of the 20th International Conference on Artificial Intelligence and Statistics. New York: JMLR.org, 2017: 1273-1282. |
| 3 | ZHAO Y, LI M, LAI L, et al. Federated learning with non-IID data[EB/OL]. [2023-11-12]. . |
| 4 | LI T, SAHU A K, TALWALKAR A, et al. Federated learning: challenges, methods, and future directions[J]. IEEE Signal Processing Magazine, 2020, 37(3): 50-60. |
| 5 | TAN A Z, YU H, CUI L, et al. Towards personalized federated learning[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(12): 9587-9603. |
| 6 | LI T, SAHU A K, ZAHEER M, et al. Federated optimization in heterogeneous networks[C/OL]// Proceedings of the 3rd Machine Learning and Systems Conference. [S.l.]: MLSys, 2020 [2023-11-12]. . |
| 7 | YANG Z, ZHANG Y, ZHENG Y, et al. FedFed: feature distillation against data heterogeneity in federated learning[C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2023: 60397-60428. |
| 8 | LI Q, HE B, SONG D. Model-contrastive federated learning[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 10708-10717. |
| 9 | MA X, ZHANG J, GUO S, et al. Layer-wised model aggregation for personalized federated learning[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 10082-10091. |
| 10 | ZHANG H, LI C, DAI W, et al. FedCR: personalized federated learning based on across-client common representation with conditional mutual information regularization[C]// Proceedings of the 40th International Conference on Machine Learning. New York: JMLR.org, 2023: 41314-41330. |
| 11 | LIN S, HAN Y, LI X, et al. Personalized federated learning towards communication efficiency, robustness and fairness[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2022: 30471-30485. |
| 12 | DAI R, SHEN L, HE F, et al. DisPFL: towards communication-efficient personalized federated learning via decentralized sparse training[C]// Proceedings of the International Conference on Machine Learning. New York: JMLR.org, 2022: 4587-4604. |
| 13 | HUANG Y, CHU L, ZHOU Z, et al. Personalized cross-silo federated learning on non-IID data[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto, CA : AAAI Press, 2021: 7865-7873. |
| 14 | TAN Y, LONG G, LIU L, et al. FedProto: federated prototype learning across heterogeneous clients[C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto, CA : AAAI Press, 2022: 8432-8440. |
| 15 | DUAN M, LIU D, CHEN X, et al. Self-balancing federated learning with global imbalanced data in mobile systems[J]. IEEE Transactions on Parallel and Distributed Systems, 2021, 32(1): 59-71. |
| 16 | JIANG Y, KONEČNÝ J, RUSH K, et al. Improving federated learning personalization via model agnostic meta learning[EB/OL]. [2023-11-12]. . |
| 17 | FALLAH A, MOKHTARI A, OZDAGLAR A. Personalized federated learning with theoretical guarantees: a model-agnostic meta-learning approach[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2020: 3557-3568. |
| 18 | WANG K I K, ZHOU X, LIANG W, et al. Federated transfer learning based cross-domain prediction for smart manufacturing[J]. IEEE Transactions on Industrial Informatics, 2022, 18(6): 4088-4096. |
| 19 | YANG H, HE H, ZHANG W, et al. FedSteg: a federated transfer learning framework for secure image steganalysis[J]. IEEE Transactions on Network Science and Engineering, 2021, 8(2): 1084-1094. |
| 20 | HWANG H, YANG S, KIM D, et al. Towards the practical utility of federated learning in the medical domain[C]// Proceedings of the 2023 Conference on Health, Inference, and Learning. New York: JMLR.org, 2023: 163-181. |
| 21 | BUI D, MALIK K, GOETZ J, et al. Federated user representation learning[EB/OL]. [2023-11-05]. . |
| 22 | LIANG P P, LIU T, ZIYIN L, et al. Think locally, act globally: federated learning with local and global representations[EB/OL]. [2023-11-05]. . |
| 23 | GAO L, FU H, LI L, et al. FedDC: federated learning with non‑IID data via local drift decoupling and correction[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 10102-10111. |
| 24 | ARIVAZHAGAN M G, AGGARWAL V, SINGH A K, et al. Federated learning with personalization layers[EB/OL]. [2023-11-02]. . |
| 25 | ZHU Z, HONG J, ZHOU J. Data-free knowledge distillation for heterogeneous federated learning[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 12878-12889. |
| 26 | JIN H, BAI D, YAO D, et al. Personalized edge intelligence via federated self-knowledge distillation[J]. IEEE Transactions on Parallel and Distributed Systems, 2023, 34(2): 567-580. |
| 27 | CHEN H, VIKALO H. The best of both worlds: accurate global and personalized models through federated learning with data-free hyper-knowledge distillation[EB/OL]. [2024-01-21]. . |
| 28 | SHU J, YANG T, LIAO X, et al. Clustered federated multitask learning on non-IID data with enhanced privacy[J]. IEEE Internet of Things Journal, 2023, 10(4): 3453-3467. |
| 29 | PRESOTTO R, CIVITARESE G, BETTINI C. FedCLAR: federated clustering for personalized sensor-based human activity recognition[C]// Proceedings of the 2022 IEEE International Conference on Pervasive Computing and Communications. Piscataway: IEEE, 2022: 227-236. |
| 30 | GHOSH A, CHUNG J, YIN D, et al. An efficient framework for clustered federated learning[J]. IEEE Transactions on Information Theory, 2022, 68(12): 8076-8091. |
| 31 | SHENAJ D, FANÌ E, TOLDO M, et al. Learning across domains and devices: style-driven source-free domain adaptation in clustered federated learning[C]// Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2023: 444-454. |
| 32 | ZHANG J, HUA Y, WANG H, et al. FedCP: separating feature information for personalized federated learning via conditional policy[C]// Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. New York: ACM, 2023: 3249-3261. |
| 33 | XIA P, ZHANG L, LI F. Learning similarity with cosine similarity ensemble[J]. Information Sciences, 2015, 307: 39-52. |
| 34 | LI X, JIANG M, ZHANG X, et al. FedBN: federated learning on non-IID features via local batch normalization[EB/OL]. [2023-11-24]. . |
| 35 | TAN Y, LONG G, MA J, et al. Federated learning from pre-trained models: a contrastive learning approach[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2022: 19332-19344. |
| 36 | XU J, TONG X, HUANG S L. Personalized federated learning with feature alignment and classifier collaboration[EB/OL]. [2024-01-25]. . |
| 37 | YI L, WANG G, LIU X, et al. FedGH: heterogeneous federated learning with generalized global header[C]// Proceedings of the 31st ACM International Conference on Multimedia. New York: ACM, 2023: 8686-8696. |
| 38 | ZHANG J, HUA Y, CAO J, et al. Eliminating domain bias for federated learning in representation space[C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2023: 14204-14227. |
| [1] | Shufen ZHANG, Hongyang ZHANG, Zhiqiang REN, Xuebin CHEN. Survey of fairness in federated learning [J]. Journal of Computer Applications, 2025, 45(1): 1-14. |
| [2] | Shun YANG, Xiaoyong BIAN, Xi CHEN. Non-iterative graph capsule network for remote sensing scene classification [J]. Journal of Computer Applications, 2025, 45(1): 247-252. |
| [3] | Zheyuan SHEN, Keke YANG, Jing LI. Personalized federated learning method based on dual stream neural network [J]. Journal of Computer Applications, 2024, 44(8): 2319-2325. |
| [4] | Hongtian LI, Xinhao SHI, Weiguo PAN, Cheng XU, Bingxin XU, Jiazheng YUAN. Few-shot object detection via fusing multi-scale and attention mechanism [J]. Journal of Computer Applications, 2024, 44(5): 1437-1444. |
| [5] | Xuebin CHEN, Changsheng QU. Overview of backdoor attacks and defense in federated learning [J]. Journal of Computer Applications, 2024, 44(11): 3459-3469. |
| [6] | Shuaihua ZHANG, Shufen ZHANG, Mingchuan ZHOU, Chao XU, Xuebin CHEN. Malicious traffic detection model based on semi-supervised federated learning [J]. Journal of Computer Applications, 2024, 44(11): 3487-3494. |
| [7] | Chunyong YIN, Yongcheng ZHOU. Automatically adjusted clustered federated learning for double-ended clustering [J]. Journal of Computer Applications, 2024, 44(10): 3011-3020. |
| [8] | Hui ZHOU, Yuling CHEN, Xuewei WANG, Yangwen ZHANG, Jianjiang HE. Deep shadow defense scheme of federated learning based on generative adversarial network [J]. Journal of Computer Applications, 2024, 44(1): 223-232. |
| [9] | Mengjie LAN, Jianping CAI, Lan SUN. Self-regularization optimization methods for Non-IID data in federated learning [J]. Journal of Computer Applications, 2023, 43(7): 2073-2081. |
| [10] | Wanzhen CHEN, En ZHANG, Leiyong QIN, Shuangxi HONG. Privacy-preserving federated learning algorithm based on blockchain in edge computing [J]. Journal of Computer Applications, 2023, 43(7): 2209-2216. |
| [11] | Chunyong YIN, Rui QU. Federated learning algorithm based on personalized differential privacy [J]. Journal of Computer Applications, 2023, 43(4): 1160-1168. |
| [12] | Qian CHEN, Zheng CHAI, Zilong WANG, Jiawei CHEN. Poisoning attack detection scheme based on generative adversarial network for federated learning [J]. Journal of Computer Applications, 2023, 43(12): 3790-3798. |
| [13] | Wenbo LI, Bo LIU, Lingling TAO, Fen LUO, Hang ZHANG. Deep spectral clustering algorithm with L1 regularization [J]. Journal of Computer Applications, 2023, 43(12): 3662-3667. |
| [14] | ZHENG Sai, LI Tianrui, HUANG Wei. Federated learning algorithm for communication cost optimization [J]. Journal of Computer Applications, 2023, 43(1): 1-7. |
| [15] | Zhenyu ZHANG, Guoping TAN, Siyuan ZHOU. Efficient wireless federated learning algorithm based on 1‑bit compressive sensing [J]. Journal of Computer Applications, 2022, 42(6): 1675-1682. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||