


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (12): 3766-3775.DOI: 10.11772/j.issn.1001-9081.2023121783
• Artificial intelligence • Previous Articles Next Articles
Jingxin LIU1, Wenjing HUANG1, Liangsheng XU2, Chong HUANG3( ), Jiansheng WU1
), Jiansheng WU1
Received:2023-12-27
Revised:2024-02-06
Accepted:2024-02-23
Online:2024-03-11
Published:2024-12-10
Contact:
Chong HUANG
About author:LIU Jingxin, born in 1999, M. S. candidate. Her research interests include machine learning, data mining.Supported by:
刘晶鑫1, 黄雯静1, 徐亮胜2, 黄冲3(), 吴建生1
通讯作者:
黄冲
作者简介:刘晶鑫(1999—),女,四川江油人,硕士研究生,主要研究方向:机器学习、数据挖掘基金资助:CLC Number:
Jingxin LIU, Wenjing HUANG, Liangsheng XU, Chong HUANG, Jiansheng WU. Unsupervised feature selection model with dictionary learning and sample correlation preservation[J]. Journal of Computer Applications, 2024, 44(12): 3766-3775.
刘晶鑫, 黄雯静, 徐亮胜, 黄冲, 吴建生. 字典学习与样本关联保持结合的无监督特征选择模型[J]. 《计算机应用》唯一官方网站, 2024, 44(12): 3766-3775.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023121783

Fig. 1 Schematic diagram of DLSCP
| 数据集 | 特征维度 | 样本数 | 类别数 | 数据来源 |
|---|---|---|---|---|
| BinaryAlphadigits | 320 | 1 404 | 36 | https://cs.nyu.edu/~roweis/data/ |
| Isolet | 617 | 1 559 | 26 | http://www.cad.zju.edu.cn/home/dengcai/Data/MLData.html |
| Event | 1 000 | 1 579 | 8 | http://vision.stanford.edu/resources_links.html#datasets |
| ORL | 1 024 | 400 | 40 | http://www.cad.zju.edu.cn/home/dengcai/Data/FaceData.html. |
| TOX | 5 748 | 171 | 4 | http://featureselection.asu.edu/datasets.php |
| CLL-SUB | 11 340 | 111 | 3 | http://featureselection.asu.edu/datasets.php |
Tab. 1 Information of datasets
| 数据集 | 特征维度 | 样本数 | 类别数 | 数据来源 |
|---|---|---|---|---|
| BinaryAlphadigits | 320 | 1 404 | 36 | https://cs.nyu.edu/~roweis/data/ |
| Isolet | 617 | 1 559 | 26 | http://www.cad.zju.edu.cn/home/dengcai/Data/MLData.html |
| Event | 1 000 | 1 579 | 8 | http://vision.stanford.edu/resources_links.html#datasets |
| ORL | 1 024 | 400 | 40 | http://www.cad.zju.edu.cn/home/dengcai/Data/FaceData.html. |
| TOX | 5 748 | 171 | 4 | http://featureselection.asu.edu/datasets.php |
| CLL-SUB | 11 340 | 111 | 3 | http://featureselection.asu.edu/datasets.php |

Fig. 2 NMI results on different datasets

Fig. 3 Acc results on different datasets
| 模型 | 不同数据集上NMI的均值和标准差 | |||||
|---|---|---|---|---|---|---|
| BinaryAlphadigits | Isolet | Event | ORL | TOX | CLL-SUB | |
| LapScore | 67.64±1.56 | 9.58±0.44 | 68.04±1.50 | 10.70±0.64 | 18.73±0.03 | |
| NDFS | 56.28±2.77 | 68.59±4.57 | 18.77±1.49 | 71.53±1.08 | 16.43±0.82 | 18.78±0.09 |
| DFSC | 52.56±4.90 | 62.05±8.93 | 9.59±0.24 | 67.76±2.37 | 10.95±0.37 | 18.73±0.03 |
| NPLFS | 46.35±8.80 | 48.80±7.18 | 12.78±2.47 | 60.82±4.89 | 8.02±2.22 | 12.72±2.87 |
| F-SUGFS | 49.61±7.80 | 62.53±6.44 | 9.30±0.20 | 71.18±1.66 | ||
| LSEUFS | 56.20±2.56 | 70.95±4.05 | 73.17±0.49 | 18.81±3.32 | ||
| RJGSC | 55.33±2.87 | 70.07±1.58 | 20.64±1.93 | 73.37±0.78 | ||
| DLUFS | 56.04±2.78 | 19.31±1.63 | ||||
| DGL-UFS | 54.95±3.48 | 67.91±3.60 | 15.65±0.67 | 71.89±0.74 | ||
| DLSCP | 57.74±1.76 | 72.75±2.44 | 25.96±0.83 | 74.52±0.62 | 27.68±0.95 | 20.84±3.96 |
Tab. 2 Mean and standard deviation of NMI for DLSCP and comparison models
| 模型 | 不同数据集上NMI的均值和标准差 | |||||
|---|---|---|---|---|---|---|
| BinaryAlphadigits | Isolet | Event | ORL | TOX | CLL-SUB | |
| LapScore | 67.64±1.56 | 9.58±0.44 | 68.04±1.50 | 10.70±0.64 | 18.73±0.03 | |
| NDFS | 56.28±2.77 | 68.59±4.57 | 18.77±1.49 | 71.53±1.08 | 16.43±0.82 | 18.78±0.09 |
| DFSC | 52.56±4.90 | 62.05±8.93 | 9.59±0.24 | 67.76±2.37 | 10.95±0.37 | 18.73±0.03 |
| NPLFS | 46.35±8.80 | 48.80±7.18 | 12.78±2.47 | 60.82±4.89 | 8.02±2.22 | 12.72±2.87 |
| F-SUGFS | 49.61±7.80 | 62.53±6.44 | 9.30±0.20 | 71.18±1.66 | ||
| LSEUFS | 56.20±2.56 | 70.95±4.05 | 73.17±0.49 | 18.81±3.32 | ||
| RJGSC | 55.33±2.87 | 70.07±1.58 | 20.64±1.93 | 73.37±0.78 | ||
| DLUFS | 56.04±2.78 | 19.31±1.63 | ||||
| DGL-UFS | 54.95±3.48 | 67.91±3.60 | 15.65±0.67 | 71.89±0.74 | ||
| DLSCP | 57.74±1.76 | 72.75±2.44 | 25.96±0.83 | 74.52±0.62 | 27.68±0.95 | 20.84±3.96 |
| 模型 | 不同数据集上Acc的均值和标准差 | |||||
|---|---|---|---|---|---|---|
| BinaryAlphadigits | Isolet | Event | ORL | TOX | CLL-SUB | |
| LapScore | 44.14±1.66 | 20.87±0.47 | 43.44±1.77 | 39.75±0.83 | 53.03±0.17 | |
| NDFS | 39.70±2.91 | 48.71±2.51 | 29.82±1.53 | 48.68±1.63 | 44.01±1.58 | 53.14±0.04 |
| DFSC | 36.42±5.16 | 43.53±8.52 | 20.77±0.35 | 42.65±3.23 | 40.00±0.71 | 52.99±0.36 |
| NPLFS | 30.15±7.73 | 31.20±5.39 | 24.22±2.03 | 36.98±5.33 | 38.18±1.82 | 50.95±1.79 |
| F-SUGFS | 33.42±7.57 | 43.85±4.71 | 20.60±0.22 | 47.01±2.48 | 44.42±6.97 | |
| LSEUFS | 40.07±2.62 | 34.82±0.53 | 50.10±0.89 | |||
| RJGSC | 39.71±2.43 | 51.45±1.95 | 31.45±1.40 | 50.56±0.53 | ||
| DLUFS | 40.13±2.77 | 50.40±1.63 | 30.41±0.94 | |||
| DGL-UFS | 39.42±3.34 | 47.85±1.99 | 27.61±0.70 | 48.85±0.71 | ||
| DLSCP | 41.52±1.98 | 53.71±2.23 | 52.42±0.76 | 50.29±2.30 | 53.69±0.95 | |
Tab. 3 Mean and standard deviation of Acc for DLSCP and comparison models
| 模型 | 不同数据集上Acc的均值和标准差 | |||||
|---|---|---|---|---|---|---|
| BinaryAlphadigits | Isolet | Event | ORL | TOX | CLL-SUB | |
| LapScore | 44.14±1.66 | 20.87±0.47 | 43.44±1.77 | 39.75±0.83 | 53.03±0.17 | |
| NDFS | 39.70±2.91 | 48.71±2.51 | 29.82±1.53 | 48.68±1.63 | 44.01±1.58 | 53.14±0.04 |
| DFSC | 36.42±5.16 | 43.53±8.52 | 20.77±0.35 | 42.65±3.23 | 40.00±0.71 | 52.99±0.36 |
| NPLFS | 30.15±7.73 | 31.20±5.39 | 24.22±2.03 | 36.98±5.33 | 38.18±1.82 | 50.95±1.79 |
| F-SUGFS | 33.42±7.57 | 43.85±4.71 | 20.60±0.22 | 47.01±2.48 | 44.42±6.97 | |
| LSEUFS | 40.07±2.62 | 34.82±0.53 | 50.10±0.89 | |||
| RJGSC | 39.71±2.43 | 51.45±1.95 | 31.45±1.40 | 50.56±0.53 | ||
| DLUFS | 40.13±2.77 | 50.40±1.63 | 30.41±0.94 | |||
| DGL-UFS | 39.42±3.34 | 47.85±1.99 | 27.61±0.70 | 48.85±0.71 | ||
| DLSCP | 41.52±1.98 | 53.71±2.23 | 52.42±0.76 | 50.29±2.30 | 53.69±0.95 | |
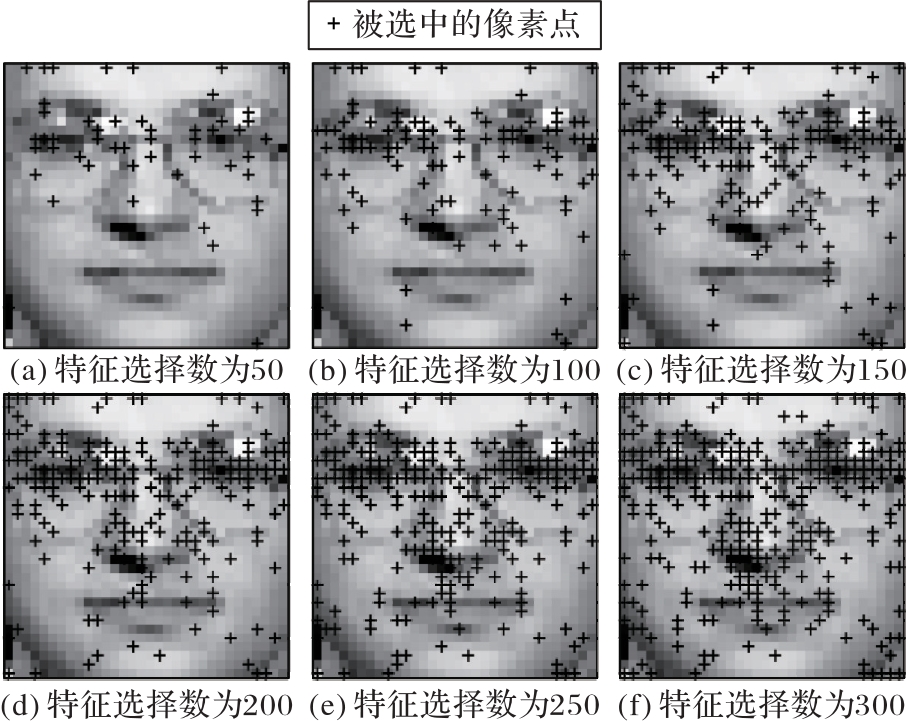
Fig. 4 Distribution of 50 to 300 pixels selected by DLSCP on ORL

Fig. 5 Distribution of 100 pixels selected by DLSCP and comparison models on ORL

Fig. 6 Comparison of NMI and Acc of DLSCP and model without sample correlation

Fig. 7 Convergence of DLSCP on 6 datasets
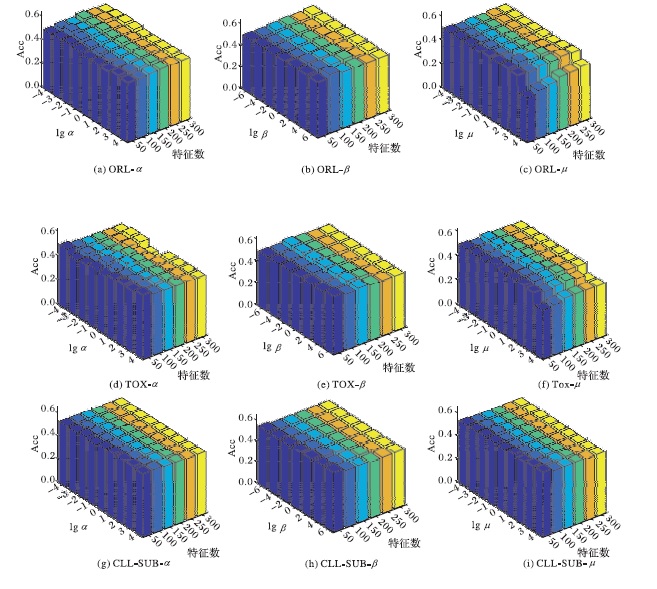
Fig. 8 Sensitivity analysis of parameters on three datasets
| 1 | CUI L, BAI L, WANG Y, et al. Fused Lasso for feature selection using structural information [J]. Pattern Recognition, 2021, 119: No.108058. |
| 2 | CUI L, BAI L, WANG Y, et al. Internet financing credit risk evaluation using multiple structural interacting elastic net feature selection [J]. Pattern Recognition, 2021, 114: No.107835. |
| 3 | ZHANG Z, BAI L, LIANG Y, et al. Joint hypergraph learning and sparse regression for feature selection[J]. Pattern Recognition, 2017, 63: 291-309. |
| 4 | 谢惠华,黎明,王艳,等. 基于特征优选和字典优化的组稀疏表示表情识别[J]. 模式识别与人工智能, 2021, 34(5): 446-454. |
| XIE H H, LI M, WANG Y, et al. Group sparse representation based on feature selection and dictionary optimization for expression recognition[J]. Pattern Recognition and Artificial Intelligence, 2021, 34(5): 446-454. | |
| 5 | 何添,沈宗鑫,黄倩倩,等. 基于自适应学习的多视图无监督特征选择方法[J]. 计算机应用, 2023, 43(9): 2657-2664. |
| HE T, SHEN Z X, HUANG Q Q, et al. Adaptive learning-based multi-view unsupervised feature selection method[J]. Journal of Computer Applications, 2023, 43(9): 2657-2664. | |
| 6 | ZHAO J, YAN S, FENG J. Towards age-invariant face recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(1): 474-487. |
| 7 | ZHANG Z, LIU L, SHEN F, et al. Binary multi-view clustering[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(7): 1774-1782. |
| 8 | MIAO J, YANG T, SUN L, et al. Graph regularized locally linear embedding for unsupervised feature selection[J]. Pattern Recognition, 2022, 122: No.108299. |
| 9 | HAN X, LIU P, WANG L, et al. Unsupervised feature selection via graph matrix learning and the low-dimensional space learning for classification[J]. Engineering Applications of Artificial Intelligence, 2020, 87: No.103283. |
| 10 | ZHU J, CHEN J, XU B, et al. Fast orthogonal locality-preserving projections for unsupervised feature selection[J]. Neurocomputing, 2023, 531: 100-113. |
| 11 | LI X, ZHANG H, ZHANG R, et al. Generalized uncorrelated regression with adaptive graph for unsupervised feature selection[J]. IEEE Transactions on Neural Networks and Learning Systems, 2019, 30(5): 1587-1595. |
| 12 | LI Z, NIE F, WU D, et al. Unsupervised feature selection with weighted and projected adaptive neighbors [J]. IEEE Transactions on Cybernetics, 2023, 53(2): 1260-1271. |
| 13 | ZHU P, HU Q, ZHANG C, et al. Coupled dictionary learning for unsupervised feature selection [C]// Proceedings of the 30th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2016: 2422-2428. |
| 14 | LU Z, CHU Q. Feature selection using class-level regularized self-representation [J]. Applied Intelligence, 2023, 53(11): 13130-13144. |
| 15 | MIAO J, YANG T, FAN C, et al. Self-paced non-convex regularized analysis-synthesis dictionary learning for unsupervised feature selection[J]. Knowledge-Based Systems, 2022, 241: No.108279. |
| 16 | FAN Y, DAI J, ZHANG Q L. Latent space embedding for unsupervised feature selection via joint dictionary learning [C]// Proceedings of the 2019 International Joint Conference on Neural Networks. Piscataway: IEEE, 2019: 1-8. |
| 17 | ZHU X F, LI X L, ZHANG S C, et al. Robust joint graph sparse coding for unsupervised spectral feature selection[J]. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(6): 1263-1275. |
| 18 | PARSA M G, ZARE H, GHATEE M. Low-rank dictionary learning for unsupervised feature selection[J]. Expert Systems with Applications, 2022, 202: No.117149. |
| 19 | DING D, XIA F, YANG X, et al. Joint dictionary and graph learning for unsupervised feature selection[J]. Applied Intelligence, 2020, 50(9): 1379-1397. |
| 20 | DU L, SHEN Y D. Unsupervised feature selection with adaptive structure learning[C]// Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2015: 209-218. |
| 21 | BELKIN M, NIYOGI P. Laplacian eigenmaps for dimensionality reduction and data representation [J]. Neural Computation, 2003, 15(6): 1373-1396. |
| 22 | HE X, NIYOGI P. Locality preserving projections[C]// Proceedings of the 16th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2003: 153-160. |
| 23 | NISHIHARA R, LESSARD L, RECHT B, et al. A general analysis of the convergence of ADMM [C]// Proceedings of the 32nd International Conference on Machine Learning. New York: JMLR.org, 2015: 343-352. |
| 24 | MAIRAL J, BACH F, PONCE J, et al. Online learning for matrix factorization and sparse coding [J]. Journal of Machine Learning Research, 2010, 11: 19-60. |
| 25 | HE X, CAI D, NIYOGI P. Laplacian score for feature selection[C]// Proceedings of the 18th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2005: 507-514. |
| 26 | LI Z, YANG Y, LIU J, et al. Unsupervised feature selection using nonnegative spectral analysis [C]// Proceedings of the 26th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2012: 1026-1032. |
| 27 | SHANG R, ZHANG Z, JIAO L, et al. Self-representation based dual-graph regularized feature selection clustering[J]. Neurocomputing, 2016, 171: 1242-1253. |
| 28 | 刘艳芳,叶东毅. 基于邻域保持学习的无监督特征选择算法[J]. 模式识别与人工智能, 2018, 31(12): 1096-1102. |
| LIU Y F, YE D Y. Unsupervised feature selection algorithm based on neighborhood preserving learning[J]. Pattern Recognition and Artificial Intelligence, 2018, 31(12): 1096-1102. | |
| 29 | 孟田田,周水生,田昕润. 基于l2,0范数稀疏性和模糊相似性的图优化无监督组特征选择方法[J]. 模式识别与人工智能, 2023, 36(1): 34-48. |
| MENG T T, ZHOU S S, TIAN X R. Unsupervised group feature selection method for graph optimization based on l2,0-norm sparsity and fuzzy similarity[J]. Pattern Recognition and Artificial Intelligence, 2023, 36(1): 34-48. | |
| 30 | ZHANG Y, LU Z, WANG S. Unsupervised feature selection via transformed auto-encoder [J]. Knowledge-Based Systems, 2021, 215: No.106748. |
| [1] | Tian HE, Zongxin SHEN, Qianqian HUANG, Yanyong HUANG. Adaptive learning-based multi-view unsupervised feature selection method [J]. Journal of Computer Applications, 2023, 43(9): 2657-2664. |
| [2] | Jianwen GAN, Yan CHEN, Peng ZHOU, Liang DU. Clustering ensemble algorithm with high-order consistency learning [J]. Journal of Computer Applications, 2023, 43(9): 2665-2672. |
| [3] | Zhifeng MA, Junyang YU, Longge WANG. Diversity represented deep subspace clustering algorithm [J]. Journal of Computer Applications, 2023, 43(2): 407-412. |
| [4] | Yu YANG, Weiwei DUAN. Spectral clustering based dynamic community discovery algorithm in social network [J]. Journal of Computer Applications, 2023, 43(10): 3129-3135. |
| [5] | Lei MA, Chuan LUO, Tianrui LI, Hongmei CHEN. Fuzzy-rough set based unsupervised dynamic feature selection algorithm [J]. Journal of Computer Applications, 2023, 43(10): 3121-3128. |
| [6] | ZHANG Cheng, WAN Yuan, QIANG Haopeng. Deep unsupervised discrete cross-modal hashing based on knowledge distillation [J]. Journal of Computer Applications, 2021, 41(9): 2523-2531. |
| [7] | LIN Junchao, WAN Yuan. Self-adaptive multi-measure unsupervised feature selection method with structured graph optimization [J]. Journal of Computer Applications, 2021, 41(5): 1282-1289. |
| [8] | LYU Yali, MIAO Junzhong, HU Weixin. Semi-supervised learning algorithm of graph based on label metric learning [J]. Journal of Computer Applications, 2020, 40(12): 3430-3436. |
| [9] | SONG Yan, YIN Jun. Multi-view spectral clustering algorithm based on shared nearest neighbor [J]. Journal of Computer Applications, 2020, 40(11): 3211-3216. |
| [10] | YANG Yanlin, YE Zhonglin, ZHAO Haixing, MENG Lei. Link prediction algorithm based on high-order proximity approximation [J]. Journal of Computer Applications, 2019, 39(8): 2366-2373. |
| [11] | XU Tao, WANG Xiaoming. Generalization error bound guided discriminative dictionary learning [J]. Journal of Computer Applications, 2019, 39(4): 940-948. |
| [12] | TAO Yongpeng, JING Yu, XU Cong. Image denoising algorithm based on grouped dictionaries and variational model [J]. Journal of Computer Applications, 2019, 39(2): 551-555. |
| [13] | XIANG Wen, ZHANG Ling, CHEN Yunhua, JI Qiumin. Single image super resolution algorithm based on structural self-similarity and deformation block feature [J]. Journal of Computer Applications, 2019, 39(1): 275-280. |
| [14] | YANG Xiaoling, LI Zhiqing, LIU Yutong. Automatic image annotation based on multi-label discriminative dictionary learning [J]. Journal of Computer Applications, 2018, 38(5): 1294-1298. |
| [15] | WANG Na, WANG Xiaofeng, GENG Guohua, SONG Qiannan. Semi-supervised classification algorithm based on C-means clustering and graph transduction [J]. Journal of Computer Applications, 2017, 37(9): 2595-2599. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||