


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (5): 1520-1527.DOI: 10.11772/j.issn.1001-9081.2024050616
• Artificial intelligence • Previous Articles
Junyan ZHANG1, Yiming ZHAO1, Bing LIN2, Yunping WU1( )
)
Received:2024-05-17
Revised:2024-08-11
Accepted:2024-09-13
Online:2024-09-18
Published:2025-05-10
Contact:
Yunping WU
About author:ZHANG Junyan, born in 2001, M. S. candidate. Her research interests include natural language processing, image captioning.Supported by:
张军燕1, 赵一鸣1, 林兵2, 吴允平1()
通讯作者:
吴允平
作者简介:张军燕(2001—),女,安徽六安人,硕士研究生,主要研究方向:自然语言处理、图像文字描述基金资助:CLC Number:
Junyan ZHANG, Yiming ZHAO, Bing LIN, Yunping WU. Chinese image captioning method based on multi-level visual and dynamic text-image interaction[J]. Journal of Computer Applications, 2025, 45(5): 1520-1527.
张军燕, 赵一鸣, 林兵, 吴允平. 基于多级视觉与图文动态交互的图像中文描述方法[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1520-1527.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024050616

Fig. 1 Schematic diagram of image captioning
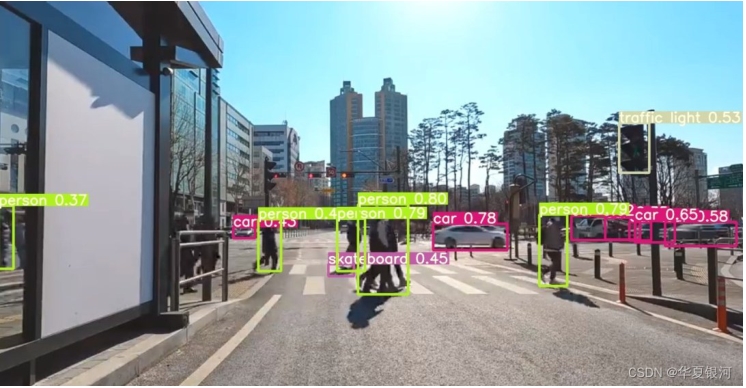
Fig. 2 Example image of YOLO object detection results in autonomous driving scenarios
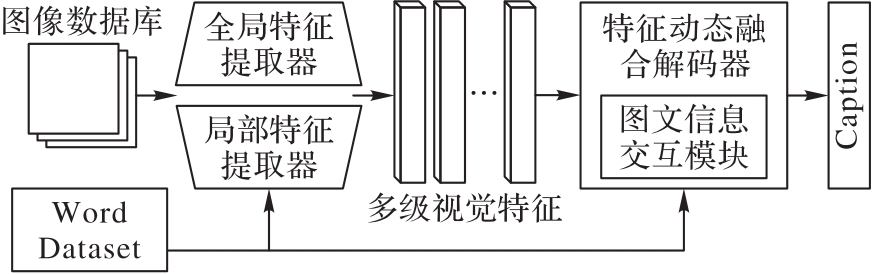
Fig. 3 Overall structure of proposed method
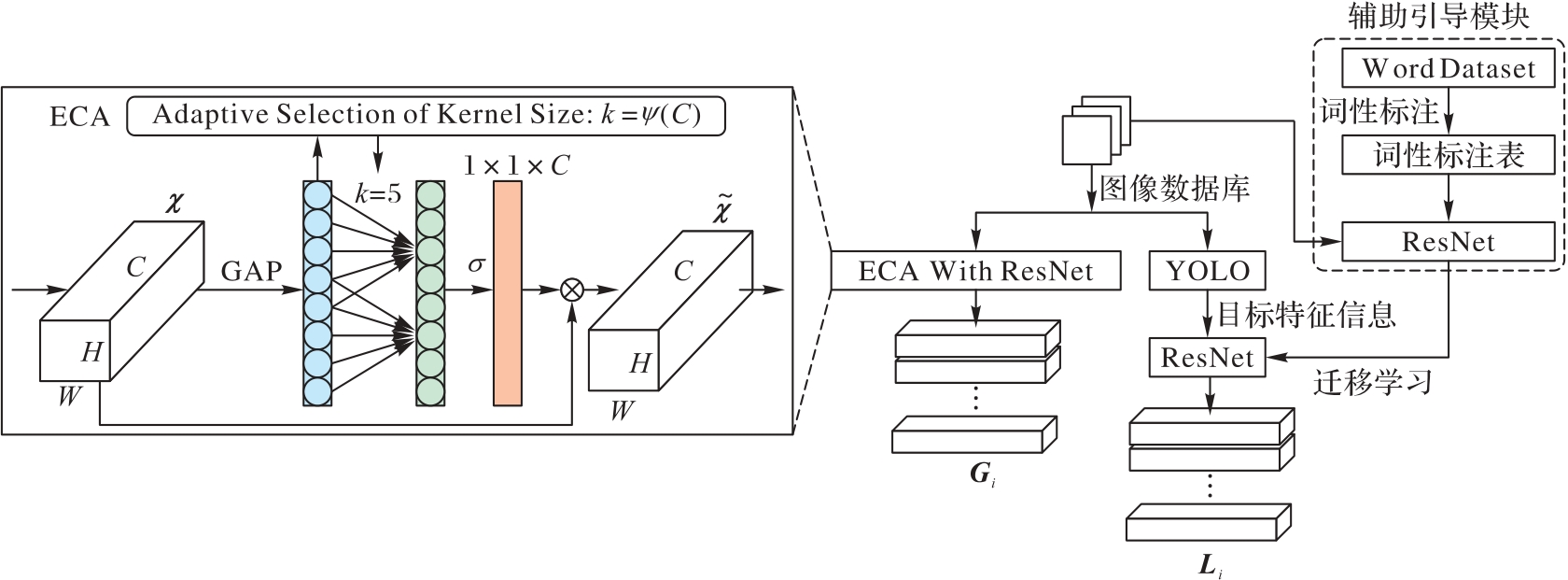
Fig. 4 Framework of encoder
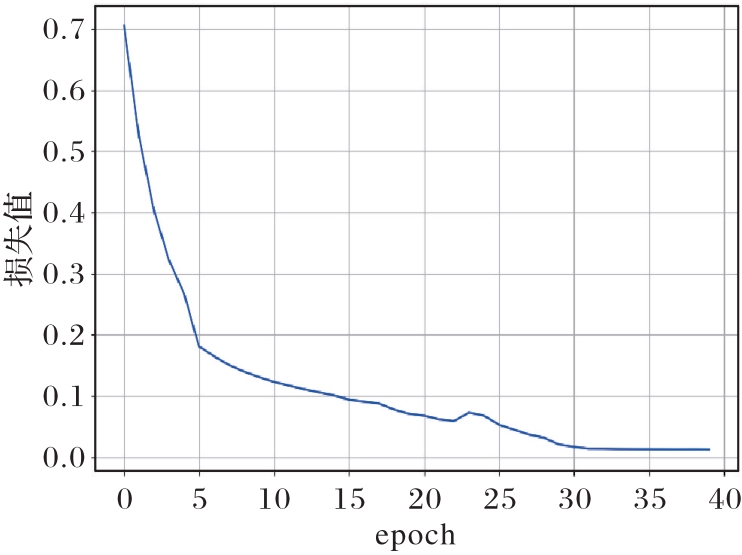
Fig. 5 M1 loss change trend
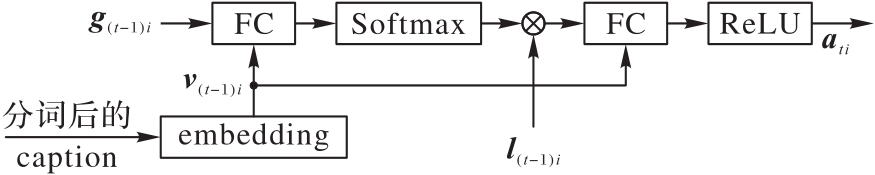
Fig. 6 Image-text information interaction module
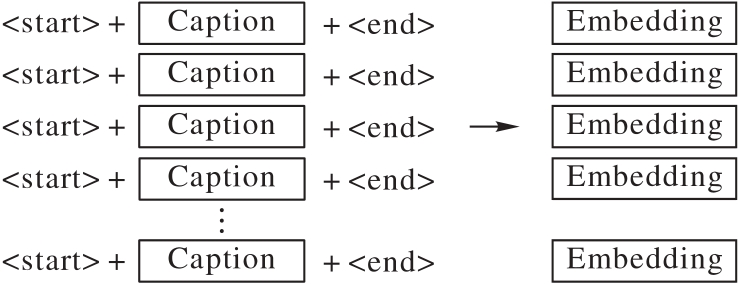
Fig. 7 Embedding of text
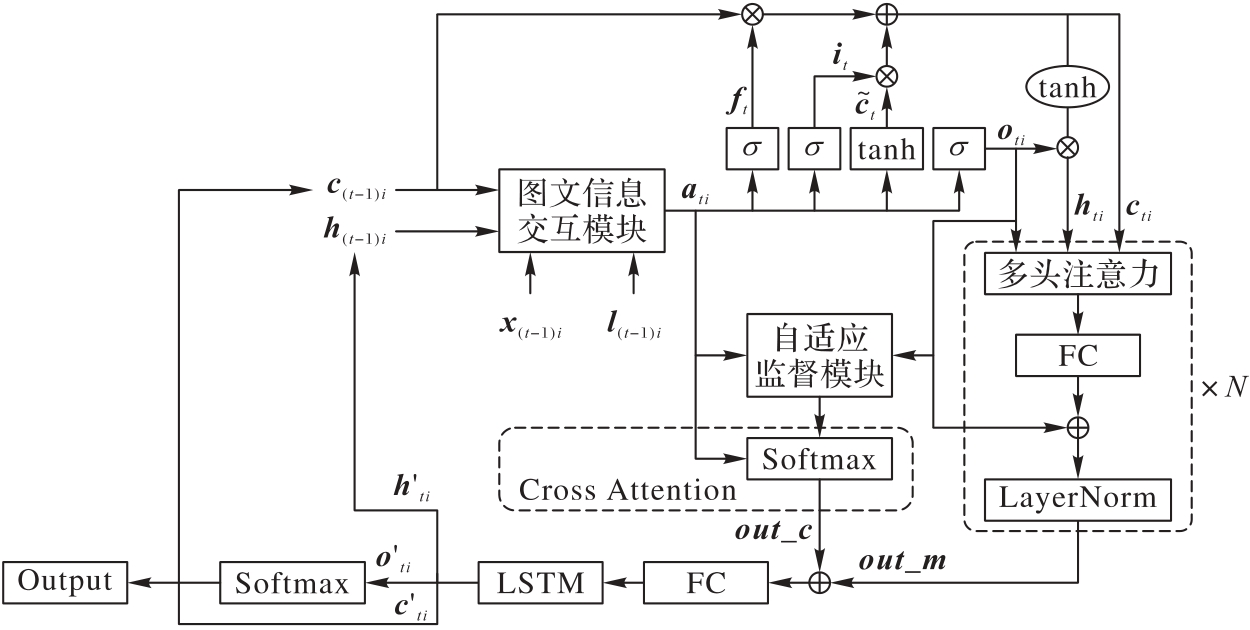
Fig. 8 Dynamic fusion decoder for features

Fig. 9 Sample image of dataset
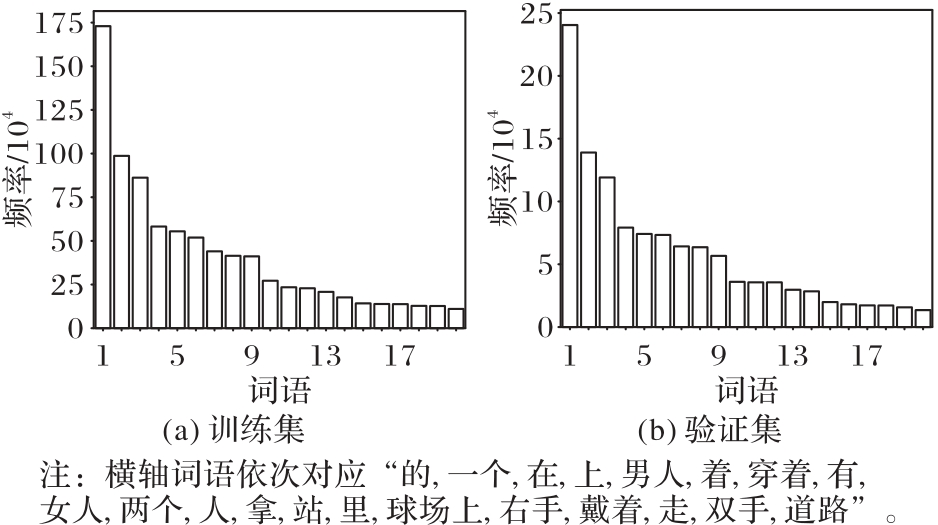
Fig. 10 Word frequency distribution of word segmentation in training and validation datasets
Fig. 11 Part-of-speech frequency distribution in training and validation datasets
| 方法 | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | Rouge_L | Meteor | CIDEr |
|---|---|---|---|---|---|---|---|
| Baseline-NIC | 0.765 | 0.648 | 0.547 | 0.461 | 0.633 | 0.370 | 1.425 |
| NICVATP2L | 0.671 | 0.468 | 0.344 | 0.235 | 0.521 | 0.303 | 0.669 |
| GLF-IFATT | 0.798 | 0.687 | 0.591 | 0.507 | 0.665 | 0.397 | 1.624 |
| 文献[ | 0.737 | 0.616 | 0.515 | 0.432 | 0.619 | 0.365 | 1.318 |
| 文献[ | 0.793 | 0.683 | 0.586 | 0.503 | 0.658 | 0.393 | 1.580 |
| 文献[ | 0.785 | — | — | 0.478 | 0.712 | 0.415 | 1.913 |
| DeCap | 0.618 | 0.448 | 0.326 | 0.240 | 0.494 | 0.309 | 0.701 |
| Knight | 0.443 | 0.298 | 0.203 | 0.140 | 0.402 | 0.247 | 0.202 |
| 本文方法 | 0.808 | 0.695 | 0.595 | 0.511 | 0.722 | 0.389 | 1.641 |
Tab.1 Evaluation index scores of different methods
| 方法 | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | Rouge_L | Meteor | CIDEr |
|---|---|---|---|---|---|---|---|
| Baseline-NIC | 0.765 | 0.648 | 0.547 | 0.461 | 0.633 | 0.370 | 1.425 |
| NICVATP2L | 0.671 | 0.468 | 0.344 | 0.235 | 0.521 | 0.303 | 0.669 |
| GLF-IFATT | 0.798 | 0.687 | 0.591 | 0.507 | 0.665 | 0.397 | 1.624 |
| 文献[ | 0.737 | 0.616 | 0.515 | 0.432 | 0.619 | 0.365 | 1.318 |
| 文献[ | 0.793 | 0.683 | 0.586 | 0.503 | 0.658 | 0.393 | 1.580 |
| 文献[ | 0.785 | — | — | 0.478 | 0.712 | 0.415 | 1.913 |
| DeCap | 0.618 | 0.448 | 0.326 | 0.240 | 0.494 | 0.309 | 0.701 |
| Knight | 0.443 | 0.298 | 0.203 | 0.140 | 0.402 | 0.247 | 0.202 |
| 本文方法 | 0.808 | 0.695 | 0.595 | 0.511 | 0.722 | 0.389 | 1.641 |
| 方法 | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | Rouge_L | Meteor | CIDEr |
|---|---|---|---|---|---|---|---|
| dff_cross | 0.802 | 0.690 | 0.582 | 0.480 | 0.704 | 0.363 | 1.445 |
| no_cross | 0.767 | 0.610 | 0.482 | 0.359 | 0.614 | 0.311 | 1.114 |
| no_multi | 0.804 | 0.691 | 0.579 | 0.481 | 0.708 | 0.366 | 1.437 |
| only_lstm | 0.789 | 0.650 | 0.528 | 0.426 | 0.671 | 0.341 | 1.262 |
| 本文方法 | 0.808 | 0.695 | 0.595 | 0.511 | 0.722 | 0.389 | 1.641 |
Tab.2 Evaluation index scores of proposed method in ablation experiments
| 方法 | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | Rouge_L | Meteor | CIDEr |
|---|---|---|---|---|---|---|---|
| dff_cross | 0.802 | 0.690 | 0.582 | 0.480 | 0.704 | 0.363 | 1.445 |
| no_cross | 0.767 | 0.610 | 0.482 | 0.359 | 0.614 | 0.311 | 1.114 |
| no_multi | 0.804 | 0.691 | 0.579 | 0.481 | 0.708 | 0.366 | 1.437 |
| only_lstm | 0.789 | 0.650 | 0.528 | 0.426 | 0.671 | 0.341 | 1.262 |
| 本文方法 | 0.808 | 0.695 | 0.595 | 0.511 | 0.722 | 0.389 | 1.641 |

Fig. 12 Result generated by proposed method
| 1 | PRUDVIRAJ J, VISHNU C, MOHAN C K. M-FFN: multi-scale feature fusion network for image captioning[J]. Applied Intelligence, 2022, 52: 14711-14723. |
| 2 | WU W, SUN D. Attention based double layer LSTM for Chinese image captioning[C]// Proceedings of the 2021 International Joint Conference on Neural Networks. Piscataway: IEEE, 2021: 1-7. |
| 3 | 徐通锵.“字”和汉语语义句法的生成机制[J]. 语言文字应用, 1999(1):24-34. |
| XU T Q. Chinese zi and the generative mechanism of semantic syntax in Chinese[J]. Applied Linguistics, 1999(1):24-34. | |
| 4 | XU M. Research on computerized automatic word segmentation of Chinese stylistic words[C]// Proceedings of the 2nd International Conference on Big Data, Information and Computer Network. Piscataway: IEEE, 2023: 230-235. |
| 5 | 白雪冰,车进,吴金蔓. 多尺度特征融合的图像描述算法[J/OL]. 计算机工程与应用 [2025-02-08].. |
| BAI X B, CHE J, WU J M. Image captioning algorithm for multi-scale features fusion[J/OL]. Computer Engineering and Applications [2025-02-08].. | |
| 6 | 陈耀传,奚雪峰,崔志明,等.图像描述技术方法研究[J]. 计算机技术与发展,2023,33(4):9-17. |
| CHEN Y C, XI X F, CUI Z M, et al. Research of image caption methods[J]. Computer Technology and Development, 2023, 33(4):9-17. | |
| 7 | 李永杰,钱艺,文益民.基于外部先验和自先验注意力的图像描述生成方法[J].计算机科学,2024,51(7):214-220. |
| LI Y J, QIAN Y, WEN Y M. Image captioning based on external prior and self-prior attention[J]. Computer Science, 2024, 51(7): 214-220. | |
| 8 | VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: a neural image caption generator[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3156-3164. |
| 9 | LALA M P, KUMAR D. Improving the quality of image captioning using CNN and LSTM method[C]// Proceedings of the 2022 International Conference on Intelligent Innovations in Engineering and Technology. Piscataway: IEEE, 2022: 64-70. |
| 10 | GUO L, LIU J, ZHU X, et al. Normalized and geometry-aware self-attention network for image captioning[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10324-10333. |
| 11 | SUN T, WANG S, ZHONG S. Multi-granularity feature attention fusion network for image-text sentiment analysis[C]// Proceedings of the 2022 Computer Graphics International Conference, LNCS 13443. Cham: Springer, 2022: 3-14. |
| 12 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| 13 | YAN J, XIE Y, LUAN X, et al. Caption TLSTMs: combining transformer with LSTMs for image captioning[J]. International Journal of Multimedia Information Retrieval, 2022, 11: 111-121. |
| 14 | HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. |
| 15 | REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. |
| 16 | REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 779-788. |
| 17 | REDMON J, FARHADI A.YOLOv3: an incremental improvement[EB/OL]. [2024-06-03].. |
| 18 | WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 7464-7475. |
| 19 | FARHADI A, HEJRATI M, SADEGHI M A, et al. Every picture tells a story: generating sentences from images[C]// Proceedings of the 2010 European Conference on Computer Vision, LNCS 6314. Berlin: Springer, 2010: 15-29. |
| 20 | KULKARNI G, PREMRAJ V, ORDONEZ V, et al. BabyTalk: understanding and generating simple image descriptions[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(12): 2891-2903. |
| 21 | WU J, ZHENG H, ZHAO B, et al. Large-scale dataset for going deeper in image understanding[C]// Proceedings of the 2019 IEEE International Conference on Multimedia and Expo. Piscataway: IEEE, 2019: 1480-1485. |
| 22 | 肖雨寒,江爱文,王明文,等. 基于视觉-语义中间综合属性特征的图像中文描述生成算法[J]. 中文信息学报, 2021, 35(4):129-138. |
| XIAO Y H, JIANG A W, WANG M W, et al. Chinese image captioning based on middle-level visual-semantic composite attributes[J]. Journal of Chinese Information Processing, 2021, 35(4):129-138. | |
| 23 | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| 24 | KONG D, ZHAO H, ZENG X. Research on image content description in Chinese based on fusion of image global and local features[J]. PLoS ONE, 2022, 17(8): No.e0271322. |
| 25 | WANG Y, WANG Y, ZHU J, et al. Image caption generation method based on target detection[C]// Proceedings of the 8th International Conference on Intelligent Informatics and Biomedical Sciences. Piscataway: IEEE, 2023: 151-155. |
| 26 | LU J, XIONG C, PARIKH D, et al. Knowing when to look: adaptive attention via a visual sentinel for image captioning[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 3242-3250. |
| 27 | ZHANG W, NIE W, LI X, et al. Image caption generation with adaptive Transformer[C]// Proceedings of the 34rd Youth Academic Annual Conference of Chinese Association of Automation. Piscataway: IEEE, 2019: 521-526. |
| 28 | LIU M, HU H, LI L, et al. Chinese image caption generation via visual attention and topic modeling[J]. IEEE Transactions on Cybernetics, 2022, 52(2): 1247-1257. |
| 29 | 赵宏,孔东一.图像特征注意力与自适应注意力融合的图像内容中文描述[J].计算机应用,2021,41(9):2496-2503. |
| ZHAO H, KONG D Y. Chinese description of image content based on fusion of image feature attention and adaptive attention[J]. Journal of Computer Applications, 2021, 41(9): 2496-2503. | |
| 30 | LU H, YANG R, DENG Z, et al. Chinese image captioning via fuzzy attention-based DenseNet-BiLSTM[J]. ACM Transactions on Multimedia Computing, Communications, and Applications, 2021, 17(1s): No.14. |
| 31 | 刘茂福,施琦,聂礼强. 基于视觉关联与上下文双注意力的图像描述生成方法[J]. 软件学报, 2022, 33(9):3210-3222. |
| LIU M F, SHI Q, NIE L Q. Image captioning based on visual relevance and context dual attention[J]. Journal of Software, 2022, 33(9):3210-3222. | |
| 32 | PAPINENI K, ROUKOS S, WARD T, et al. BLEU: a method for automatic evaluation of machine translation[C]// Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2002: 311-318. |
| 33 | DENKOWSKI M, LAVIE A. Meteor Universal: language specific translation evaluation for any target language[C]// Proceedings of the 9th Workshop on Statistical Machine Translation. Stroudsburg: ACL, 2014: 376-380. |
| 34 | LIN C Y. ROUGE: a package for automatic evaluation of summaries[C]// Proceedings of the ACL-04 Workshop: Text Summarization Branches Out. Stroudsburg: ACL, 2004: 74-81. |
| 35 | VEDANTAM R, ZITNICK C L, PARIKH D. CIDEr: consensus based image description evaluation[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 4566-4575. |
| 36 | KINGMA D P, BA J L. Adam: a method for stochastic optimization[EB/OL]. [2024-08-03].. |
| 37 | LI W, ZHU L, WEN L, et al. DeCap: decoding CLIP latents for zero-shot captioning via text-only training[EB/OL]. [2024-05-11].. |
| 38 | WANG J, YAN M, ZHANG Y. From association to generation: text-only captioning by unsupervised cross-modal mapping[C]// Proceedings of the 32nd International Joint Conference on Artificial Intelligence. San Francisco: Morgan Kaufmann Publishers Inc., 2023: 4326-4334. |
| [1] | Qianhong SHI, Yan YANG, Yongquan JIANG, Xiaocao OUYANG, Wubo FAN, Qiang CHEN, Tao JIANG, Yuan LI. Multi-granularity abrupt change fitting network for air quality prediction [J]. Journal of Computer Applications, 2024, 44(8): 2643-2650. |
| [2] | Fan MENG, Qunli YANG, Jing HUO, Xinkuan WANG. EraseMTS: iterative active multivariable time series anomaly detection algorithm based on margin anomaly candidate set [J]. Journal of Computer Applications, 2024, 44(5): 1458-1463. |
| [3] | Yuhao TANG, Dezhong PENG, Zhong YUAN. Fuzzy multi-granularity anomaly detection for incomplete mixed data [J]. Journal of Computer Applications, 2024, 44(10): 3097-3104. |
| [4] | Xiaoyan ZHANG, Jiayi WANG. Comparison of three-way concepts under attribute clustering [J]. Journal of Computer Applications, 2023, 43(5): 1336-1341. |
| [5] | YAO Huayong, YE Dongyi, CHEN Zhaojiong. Multi-round conversational reinforcement learning recommendation algorithm via multi-granularity feedback [J]. Journal of Computer Applications, 2023, 43(1): 15-21. |
| [6] | Jun HU, Zhengkang XU, Li LIU, Fujin ZHONG. Network embedding method based on multi-granularity community information [J]. Journal of Computer Applications, 2022, 42(3): 663-670. |
| [7] | MENG Fan, CHEN Guang, WANG Yong, GAO Yang, GAO Dequn, JIA Wenlong. Multi-granularity temporal structure representation based outlier detection method for prediction of oil reservoir [J]. Journal of Computer Applications, 2021, 41(8): 2453-2459. |
| [8] | WANG Peng, LI Yanwen, YANG Di, YANG Huamin. Macroscopic fundamental diagram traffic signal control model based on hierarchical control [J]. Journal of Computer Applications, 2021, 41(2): 571-576. |
| [9] | KANG Zhaoling, XU Qinbao, WANG Changda. Multi-granularity topology-based stepwise refinement provenance method for wireless sensor networks [J]. Journal of Computer Applications, 2018, 38(1): 222-227. |
| [10] | HE Wei, QI Qi, ZHANG Guoyun, WU Jianhui. Moving object detection method based on multi-information dynamic fusion [J]. Journal of Computer Applications, 2016, 36(8): 2306-2310. |
| [11] | LI Ning YIN Hong XU Ji-heng WANG Jian-min CHEN Hong-yue. Adaptive UDP flow detection based on multi-granularity [J]. Journal of Computer Applications, 2012, 32(07): 1816-1819. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||