


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (5): 1488-1495.DOI: 10.11772/j.issn.1001-9081.2024050627
• Artificial intelligence • Previous Articles
Haiyan TIAN, Saihao HUANG, Dong ZHANG( ), Shoushan LI
), Shoushan LI
Received:2024-05-17
Revised:2024-10-14
Accepted:2024-10-24
Online:2024-11-01
Published:2025-05-10
Contact:
Dong ZHANG
About author:TIAN Haiyan, born in 2000, M. S. candidate. Her research interests include multi-modal analysis.Supported by:
田海燕, 黄赛豪, 张栋(), 李寿山
通讯作者:
张栋
作者简介:田海燕(2000—),女,江苏淮安人,硕士研究生,主要研究方向:多模态分析基金资助:CLC Number:
Haiyan TIAN, Saihao HUANG, Dong ZHANG, Shoushan LI. Visually guided word segmentation and part of speech tagging[J]. Journal of Computer Applications, 2025, 45(5): 1488-1495.
田海燕, 黄赛豪, 张栋, 李寿山. 视觉指导的分词和词性标注[J]. 《计算机应用》唯一官方网站, 2025, 45(5): 1488-1495.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024050627
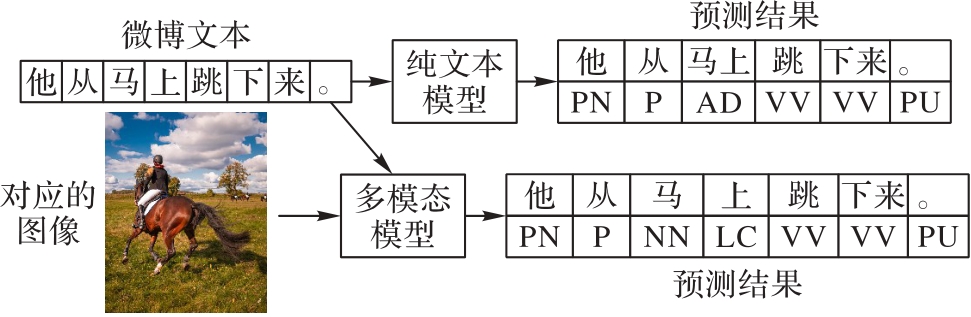
Fig. 1 Comparison among WS and POS tagging examples with or without visual guidance
| 数据集 | 模态 | 词语数/106 | 字符数/106 | 来源 |
|---|---|---|---|---|
| VG-Weibo | T+V | 0.05 | 0.12 | 新浪微博 |
| MSRA[ | T | 2.48 | 4.23 | SIGHAN 2005 |
| PKU[ | T | 1.21 | 2.00 | SIGHAN 2005 |
| CTB5[ | T | 0.51 | 0.83 | 新闻、杂志 |
| CTB6[ | T | 0.78 | 1.29 | 新闻、杂志、广播 |
| NCC[ | T | 0.63 | 1.00 | SIGHAN 2008 |
| UD[ | T | 0.12 | 0.20 | CoNLL 2017 |
Tab. 1 Comparison of WS and POS tagging datasets
| 数据集 | 模态 | 词语数/106 | 字符数/106 | 来源 |
|---|---|---|---|---|
| VG-Weibo | T+V | 0.05 | 0.12 | 新浪微博 |
| MSRA[ | T | 2.48 | 4.23 | SIGHAN 2005 |
| PKU[ | T | 1.21 | 2.00 | SIGHAN 2005 |
| CTB5[ | T | 0.51 | 0.83 | 新闻、杂志 |
| CTB6[ | T | 0.78 | 1.29 | 新闻、杂志、广播 |
| NCC[ | T | 0.63 | 1.00 | SIGHAN 2008 |
| UD[ | T | 0.12 | 0.20 | CoNLL 2017 |
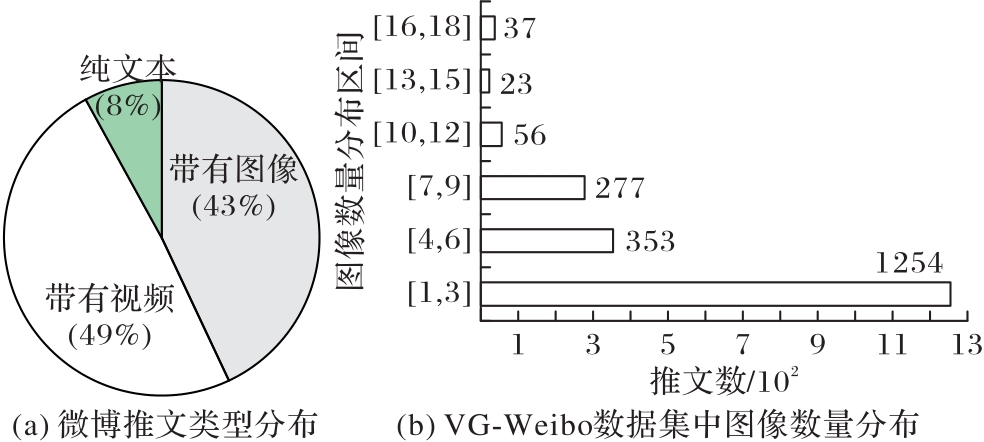
Fig. 2 Type distribution of Weibo posts in Sina Weibo and distribution of image numbers in VG-Weibo dataset

Fig. 3 Example of data annotation
| 指标 | 图像数 | 文本长度/字符数 | 句子长度/字符数 | 局部图像特征数 (置信度为0.7) |
|---|---|---|---|---|
| 最小值 | 1 | 1 | 1 | 0 |
| 最大值 | 18 | 442 | 285 | 15 |
| 平均值 | 3.78 | 59.05 | 43.88 | 1.05 |
Tab. 2 Statistics of VG-Weibo dataset
| 指标 | 图像数 | 文本长度/字符数 | 句子长度/字符数 | 局部图像特征数 (置信度为0.7) |
|---|---|---|---|---|
| 最小值 | 1 | 1 | 1 | 0 |
| 最大值 | 18 | 442 | 285 | 15 |
| 平均值 | 3.78 | 59.05 | 43.88 | 1.05 |
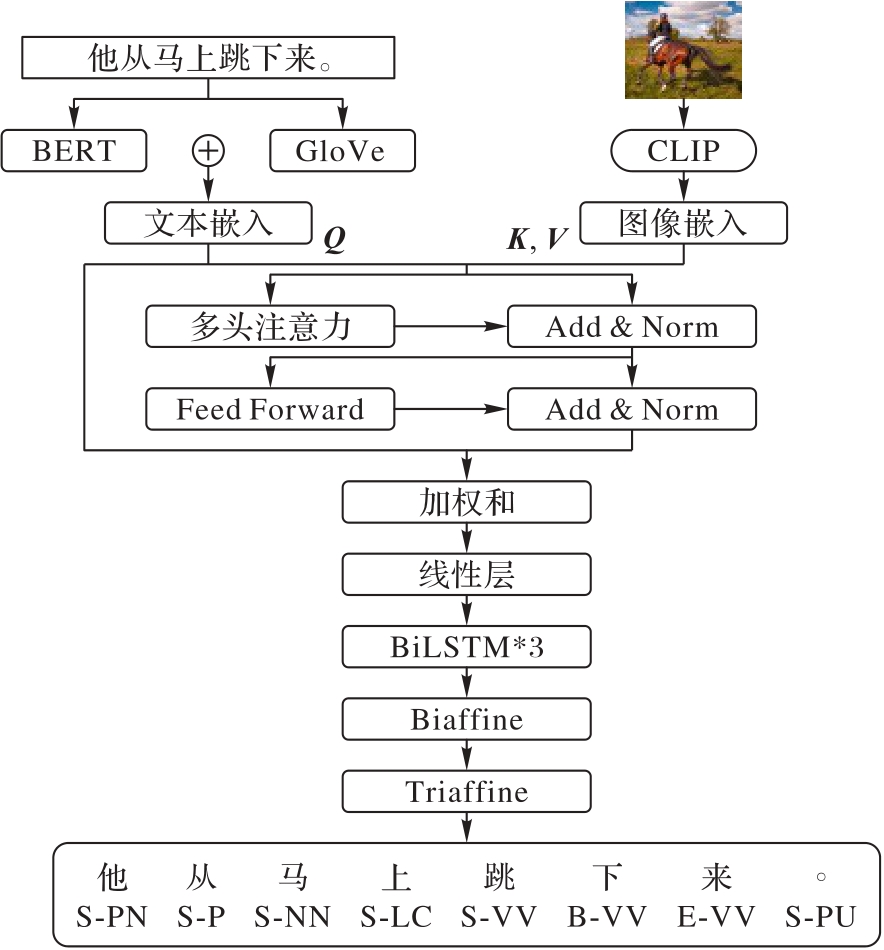
Fig. 4 Model structure of VGTD method

Fig. 5 Model structure of VGCD method
| 数据集 | 样本数 | 句子数 |
|---|---|---|
| 训练集 | 1 400 | 1 884 |
| 验证集 | 200 | 264 |
| 测试集 | 400 | 543 |
Tab. 3 Division of VG-Weibo dataset
| 数据集 | 样本数 | 句子数 |
|---|---|---|
| 训练集 | 1 400 | 1 884 |
| 验证集 | 200 | 264 |
| 测试集 | 400 | 543 |
| 方法 | WSDev | WSTest | POSDev | POSTest | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| TMIN[ | 93.84 | 93.63 | 93.73 | 93.89 | 94.14 | 94.02 | 88.45 | 88.29 | 88.37 | 89.20 | 89.24 | 89.22 |
| TD[ | 93.39 | 93.48 | 93.44 | 93.71 | 93.86 | 93.79 | 88.50 | 88.19 | 88.34 | 89.28 | 88.99 | 89.13 |
| TD+Vision | 93.59 | 93.69 | 93.64 | 93.68 | 93.89 | 93.78 | 88.78 | 88.46 | 88.62 | 89.43 | 89.07 | 89.25 |
| VGTD | 93.87 | 93.73 | 93.80 | 94.01 | 93.93 | 93.97 | 88.80 | 88.43 | 88.62 | 89.44 | 89.26 | 89.35 |
| CD[ | 94.02 | 93.22 | 93.62 | 93.34 | 94.04 | 94.19 | 88.85 | 87.78 | 88.31 | 89.31 | 88.38 | 88.84 |
| CD+Vision | 94.06 | 92.97 | 93.51 | 94.43 | 93.64 | 94.03 | 87.78 | 86.98 | 87.38 | 88.42 | 87.68 | 88.05 |
| VGCD | 94.19 | 93.49 | 93.84 | 94.66 | 94.21 | 94.44† | 89.17 | 88.22 | 88.69 | 89.75 | 89.03 | 89.39† |
Tab. 4 Performance comparison of WS and POS tagging on VG-Weibo dataset
| 方法 | WSDev | WSTest | POSDev | POSTest | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| TMIN[ | 93.84 | 93.63 | 93.73 | 93.89 | 94.14 | 94.02 | 88.45 | 88.29 | 88.37 | 89.20 | 89.24 | 89.22 |
| TD[ | 93.39 | 93.48 | 93.44 | 93.71 | 93.86 | 93.79 | 88.50 | 88.19 | 88.34 | 89.28 | 88.99 | 89.13 |
| TD+Vision | 93.59 | 93.69 | 93.64 | 93.68 | 93.89 | 93.78 | 88.78 | 88.46 | 88.62 | 89.43 | 89.07 | 89.25 |
| VGTD | 93.87 | 93.73 | 93.80 | 94.01 | 93.93 | 93.97 | 88.80 | 88.43 | 88.62 | 89.44 | 89.26 | 89.35 |
| CD[ | 94.02 | 93.22 | 93.62 | 93.34 | 94.04 | 94.19 | 88.85 | 87.78 | 88.31 | 89.31 | 88.38 | 88.84 |
| CD+Vision | 94.06 | 92.97 | 93.51 | 94.43 | 93.64 | 94.03 | 87.78 | 86.98 | 87.38 | 88.42 | 87.68 | 88.05 |
| VGCD | 94.19 | 93.49 | 93.84 | 94.66 | 94.21 | 94.44† | 89.17 | 88.22 | 88.69 | 89.75 | 89.03 | 89.39† |
| 模型 | WSTest | POSTest | ||
|---|---|---|---|---|
| F1 | ROOV | F1 | ROOV | |
| TMIN[ | 94.02 | 81.07 | 89.22 | 70.74 |
| TD[ | 93.79 | 81.52 | 89.13 | 71.29 |
| TD+Vision | 93.78 | 81.34 | 89.25 | 71.45 |
| VGTD | 93.97 | 80.48 | 89.35 | 72.03 |
| CD[ | 94.19 | 82.53 | 88.84 | 73.13 |
| CD+Vision | 94.03 | 82.30 | 88.05 | 73.66 |
| VGCD | 94.44 | 82.79 | 89.39 | 74.51 |
Tab. 5 Performance comparison of WS and POS tagging on VG-Weibo test set
| 模型 | WSTest | POSTest | ||
|---|---|---|---|---|
| F1 | ROOV | F1 | ROOV | |
| TMIN[ | 94.02 | 81.07 | 89.22 | 70.74 |
| TD[ | 93.79 | 81.52 | 89.13 | 71.29 |
| TD+Vision | 93.78 | 81.34 | 89.25 | 71.45 |
| VGTD | 93.97 | 80.48 | 89.35 | 72.03 |
| CD[ | 94.19 | 82.53 | 88.84 | 73.13 |
| CD+Vision | 94.03 | 82.30 | 88.05 | 73.66 |
| VGCD | 94.44 | 82.79 | 89.39 | 74.51 |
| 方法 | 以太坊eth行情分析 | 背影照好可爱 | 正放大图片赏颜呢 |
|---|---|---|---|
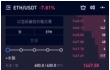 |  |  | |
| TMIN | 背影照/好/可爱 | ||
| NN/AD/VA | |||
| CD | 以太坊/eth/行情/分析 | 背影照/好/可爱 | 正/放/大/图片/赏/颜/呢 |
| NR//NN/NN | NN/AD/VA | AD/VV/JJ/NN/VV/NN/SP | |
| CD+Vision | 以太坊/eth/行情/分析 | 正/放/大/图片/赏/颜/呢 | |
| NR/NN/NN | AD/VV/JJ/NN/VV/NN/SP | ||
| VGCD | |||
Tab. 6 Cases of results predicted by different methods
| 方法 | 以太坊eth行情分析 | 背影照好可爱 | 正放大图片赏颜呢 |
|---|---|---|---|
| | | |
| TMIN | 背影照/好/可爱 | ||
| NN/AD/VA | |||
| CD | 以太坊/eth/行情/分析 | 背影照/好/可爱 | 正/放/大/图片/赏/颜/呢 |
| NR//NN/NN | NN/AD/VA | AD/VV/JJ/NN/VV/NN/SP | |
| CD+Vision | 以太坊/eth/行情/分析 | 正/放/大/图片/赏/颜/呢 | |
| NR/NN/NN | AD/VV/JJ/NN/VV/NN/SP | ||
| VGCD | |||
| 1 | XU N. Chinese word segmentation as character tagging[J]. International Journal of Computational Linguistics and Chinese Language Processing, 2003, 8(1): 29-48. |
| 2 | DUAN S, ZHAO H. Attention is all you need for Chinese word segmentation[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2020: 3862-3872. |
| 3 | ZHENG X, CHEN H, XU T. Deep learning for Chinese word segmentation and POS tagging[C]// Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2013: 647-657. |
| 4 | QIAN T, ZHANG Y, ZHANG M, et al. A transition-based model for joint segmentation, POS-tagging and normalization[C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2015: 1837-1846. |
| 5 | CHEN X, QIU X, HUANG X. A feature-enriched neural model for joint Chinese word segmentation and part-of-speech tagging[C]// Proceedings of the 26th International Joint Conference on Artificial Intelligence. San Francisco: Morgan Kaufmann Publishers Inc., 2017: 3960-3966. |
| 6 | ZHANG M, YU N, FU G. A simple and effective neural model for joint word segmentation and POS tagging[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018, 26(9): 1528-1538. |
| 7 | ZHAO L, ZHANG A, LIU Y, et al. Encoding multi-granularity structural information for joint Chinese word segmentation and POS tagging[J]. Pattern Recognition Letters, 2020, 138: 163-169. |
| 8 | NIAN F, LI J, DIAO H, et al. Weibo core user mining and propagation scale predicting[J]. Chaos, Solitons and Fractals, 2022, 156: No.111869. |
| 9 | XIAO S, CHEN G, ZHANG C, et al. Complementary or substitutive? a novel deep learning method to leverage text-image interactions for multimodal review helpfulness prediction[J]. Expert Systems with Applications, 2022, 208: No.118138. |
| 10 | ZHANG K, ZHANG B, TENG Z. Leveraging graph to improve lexicon enhanced Chinese sequence labelling[C]// Proceedings of the IEEE 13th International Symposium on Parallel Architectures, Algorithms, and Programming. Piscataway: IEEE, 2022: 1-6. |
| 11 | HAN W, CHEN H, GELBUKH A, et al. Bi-bimodal modality fusion for correlation-controlled multimodal sentiment analysis[C]// Proceedings of the 2021 International Conference on Multimodal Interaction. New York: ACM, 2021: 6-15. |
| 12 | 朱艳辉,刘璟,徐叶强,等. 基于条件随机场的中文领域分词研究[J]. 计算机工程与应用, 2016, 52(15): 97-100. |
| ZHU Y H, LIU J, XU Y Q, et al. Chinese word segmentation research based on conditional random field[J]. Computer Engineering and Applications, 2016, 52(5): 97-100. | |
| 13 | SHAO Y, HARDMEIER C, TIEDEMANN J, et al. Character-based joint segmentation and POS tagging for Chinese using bidirectional RNN-CRF[C]// Proceedings of the 8th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2017: 173-183. |
| 14 | 李雅昆,潘晴, WANG E X.基于改进的多层BLSTM的中文分词和标点预测[J].计算机应用,2018,38(5):1278-1282, 1314. |
| LI Y K, PAN Q, WANG E X. Joint Chinese word segmentation and punctuation prediction based on improved multilayer BLSTM network[J]. Journal of Computer Applications, 2018, 38(5): 1278-1282, 1314. | |
| 15 | TIAN Y, SONG Y, XIA F. Joint Chinese word segmentation and part-of-speech tagging via multi-channel attention of character n-grams[C]// Proceedings of the 28th International Conference on Computational Linguistics. [S.l.]: International Committee on Computational Linguistics, 2020: 2073-2084. |
| 16 | KE Z, SHI L, SUN S, et al. Pre-training with meta learning for Chinese word segmentation[C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2021: 5514-5523. |
| 17 | HE R, CAI S, MING Z, et al. Weighted self distillation for Chinese word segmentation[C]// Findings of the Association for Computational Linguistics: ACL 2022. Stroudsburg: ACL, 2022: 1757-1770. |
| 18 | LI D, ZHAO R, TAN F. CWSeg: an efficient and general approach to Chinese word segmentation[C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 5: Industry Track). Stroudsburg: ACL, 2023: 1-10. |
| 19 | CHANG B, YUAN Y, LI B, et al. A joint model of automatic word segmentation and part-of-speech tagging for ancient classical texts based on radicals[C]// Proceedings of 2003 Ancient Language Processing Workshop. Shoumen: INCOMA Ltd., 2023: 122-132. |
| 20 | HUANG K, YU H, LIU J, et al. Lexicon-based graph convolutional network for Chinese word segmentation[C]// Findings of the Association for Computational Linguistics: EMNLP 2021. Stroudsburg: ACL, 2021: 2908-2917. |
| 21 | 夏飞,陈帅琦,华珉,等. 基于改进BERT的电力领域中文分词方法[J]. 计算机应用, 2023, 43(12): 3711-3718. |
| XIA F, CHEN S Q, HUA M, et al. Chinese word segmentation method in electric power domain based on improved BERT[J]. Journal of Computer Applications, 2023, 43(12): 3711-3718. | |
| 22 | FENG S, LI P. Ancient Chinese word segmentation and part-of-speech tagging using distant supervision[C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| 23 | ZHANG D, HU Z, LI S, et al. More than text: multi-modal Chinese word segmentation[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). Stroudsburg: ACL, 2021: 550-557. |
| 24 | EMERSON T. The second international Chinese word segmentation bakeoff[C]// Proceedings of the 4th SIGHAN Workshop on Chinese Language Processing. [S.l.]: Asian Federation of Natural Language Processing, 2005: 123-133. |
| 25 | XUE N, XIA F, CHIOU F D, et al. The Penn Chinese TreeBank: phrase structure annotation of a large corpus[J]. Natural Language Engineering, 2005, 11(2): 207-238. |
| 26 | JIN G, CHEN X. The fourth international Chinese language processing bakeoff: Chinese word segmentation, named entity recognition, and Chinese POS tagging[C]// Proceedings of the 6th SIGHAN Workshop on Chinese Language Processing. [S.l.]: Asian Federation of Natural Language Processing, 2008: 69-81. |
| 27 | ZEMAN D, POPEL M, STRAKA M, et al. CoNLL 2017 shared task: multilingual parsing from raw text to universal dependencies[C]// Proceedings of the CoNLL 2017 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies. Stroudsburg: ACL, 2017: 1-19. |
| 28 | 俞士汶,段慧明,朱学锋,等.北京大学现代汉语语料库基本加工规范[J].中文信息学报,2002,16(5):49-64. |
| YU S W, DUAN H M, ZHU X F, et al. The basic processing of contemporary Chinese corpus at Peking University: SPECIFICATION[J]. Journal of Chinese Information Processing, 2002, 16(5): 49-64. | |
| 29 | XIA F. The segmentation guidelines for the Penn Chinese Treebank (3.0)[EB/OL]. [2024-12-23].. |
| 30 | 来斯惟,徐立恒,陈玉博,等. 基于表示学习的中文分词算法探索[J]. 中文信息学报, 2013, 27(5): 8-14. |
| LAI S W, XU L H, CHEN Y B, et al. Chinese word segment based on character representation learning[J]. Journal of Chinese Information Processing, 2013, 27(5): 8-14. | |
| 31 | LOU C, YANG S, TU K. Nested named entity recognition as latent lexicalized constituency parsing[C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 6183-6198. |
| 32 | EISNER J, SATTA G. Efficient parsing for bilexical context-free grammars and head automaton grammars[C]// Proceedings of the 37th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 1999: 457-464. |
| 33 | ZHANG Y, LI Z, ZHANG M. Efficient second-order TreeCRF for neural dependency parsing[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2020: 3295-3305. |
| 34 | FU Y, TAN C, CHEN M, et al. Nested named entity recognition with partially-observed TreeCRFs[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 12839-12847. |
| 35 | SUN Z, LI X, SUN X, et al. ChineseBERT: Chinese pretraining enhanced by glyph and pinyin information[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 2065-2075. |
| 36 | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 8748-8763. |
| 37 | POWERS D M W. Evaluation: from precision, recall and F-measure to ROC, informedness, markedness and correlation[J]. Journal of Machine Learning Technologies, 2011, 2(1): 37-63. |
| [1] | Wenbin HU, Tianxiang CAI, Tianle HAN, Zhaoman ZHONG, Changxia MA. Multimodal sarcasm detection model integrating contrastive learning with sentiment analysis [J]. Journal of Computer Applications, 2025, 45(5): 1432-1438. |
| [2] | Huanliang SUN, Siyi WANG, Junling LIU, Jingke XU. Help-seeking information extraction model for flood event in social media data [J]. Journal of Computer Applications, 2024, 44(8): 2437-2445. |
| [3] | Caiqian BAO, Jianmin XU, Guofang ZHANG. Extended belief network recommendation model based on user dynamic interaction behavior [J]. Journal of Computer Applications, 2023, 43(4): 1115-1121. |
| [4] | Xiaofei SUN, Jingyuan ZHU, Bin CHEN, Hengzhi YOU. Virtual screening of drug synthesis reaction based on multimodal data fusion [J]. Journal of Computer Applications, 2023, 43(2): 622-629. |
| [5] | Rui XIAO, Mingyi LIU, Zhiying TU, Zhongjie WANG. Personal event detection method based on text mining in social media [J]. Journal of Computer Applications, 2022, 42(11): 3513-3519. |
| [6] | MENG Xiangrui, YANG Wenzhong, WANG Ting. Survey of sentiment analysis based on image and text fusion [J]. Journal of Computer Applications, 2021, 41(2): 307-317. |
| [7] | GUO Kexin, ZHANG Yuxiang. Visual-textual sentiment analysis method based on multi-level spatial attention [J]. Journal of Computer Applications, 2021, 41(10): 2835-2841. |
| [8] | LI Shanshan, YANG Wenzhong, WANG Ting, WANG Lihua. Survey of sub-topic detection technology based on internet social media [J]. Journal of Computer Applications, 2020, 40(6): 1565-1573. |
| [9] | CAI Guoyong, HE Xinhao, CHU Yangyang. Visual sentiment analysis by combining global and local regions of image [J]. Journal of Computer Applications, 2019, 39(8): 2181-2185. |
| [10] | LU Zhigang, SUN Yadan. Multidimensional collaborative intelligence recommendation based on social media context [J]. Journal of Computer Applications, 2016, 36(3): 740-745. |
| [11] | CAI Guoyong, XIA Binbin. Multimedia sentiment analysis based on convolutional neural network [J]. Journal of Computer Applications, 2016, 36(2): 428-431. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||