


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (9): 2993-3002.DOI: 10.11772/j.issn.1001-9081.2024081227
• Multimedia computing and computer simulation • Previous Articles
Lili WEI1, Lirong YAN1, Xiaofen TANG1,2( )
)
Received:2024-09-02
Revised:2024-09-30
Accepted:2024-11-04
Online:2024-11-19
Published:2025-09-10
Contact:
Xiaofen TANG
About author:WEI Lili, born in 1996, M. S. candidate. Her research interests include few-shot object detection.Supported by:
魏利利1, 闫丽蓉1, 唐晓芬1,2()
通讯作者:
唐晓芬
作者简介:魏利利(1996—),女,山东济南人,硕士研究生,CCF会员,主要研究方向:小样本目标检测基金资助:CLC Number:
Lili WEI, Lirong YAN, Xiaofen TANG. Contextual semantic representation and pixel relationship correction for few-shot object detection[J]. Journal of Computer Applications, 2025, 45(9): 2993-3002.
魏利利, 闫丽蓉, 唐晓芬. 上下文语义表征和像素关系纠正的小样本目标检测[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2993-3002.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024081227

Fig. 1 Division of FSOD task
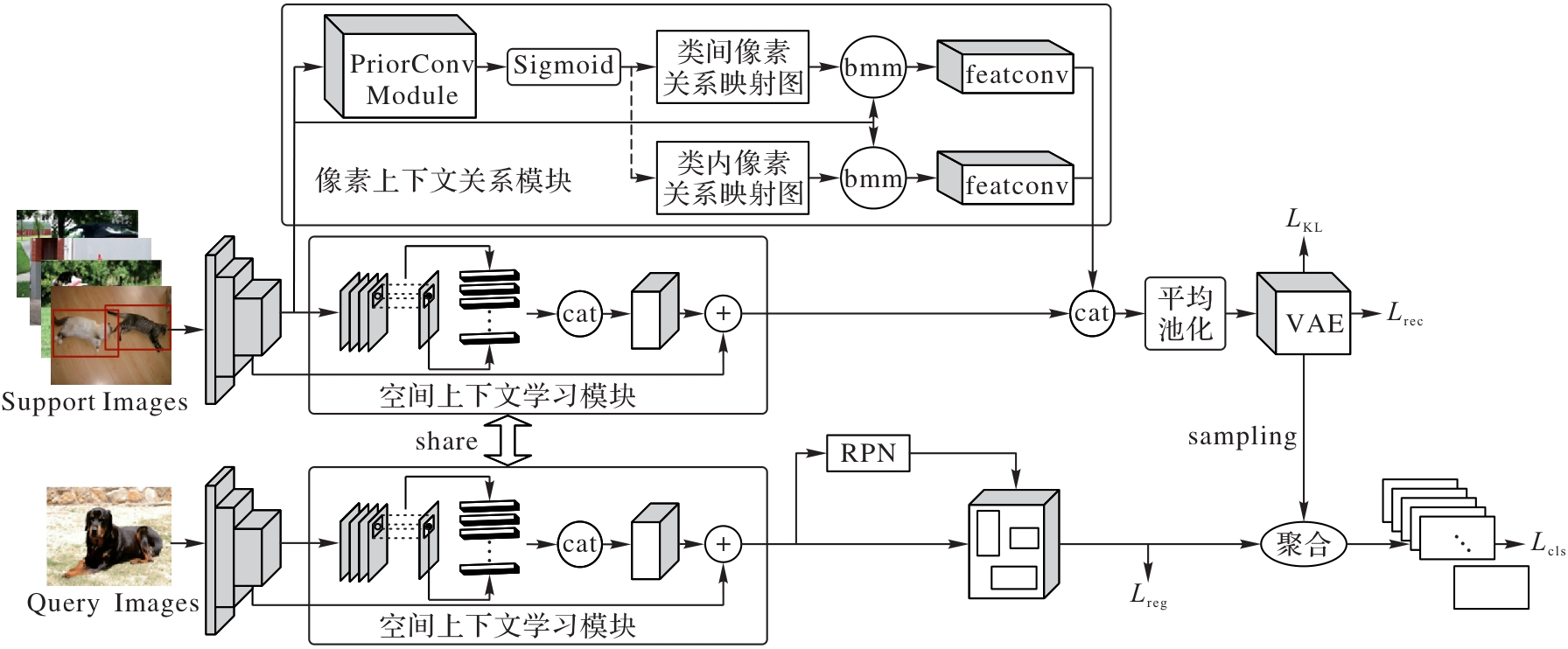
Fig. 2 Structure of SCM
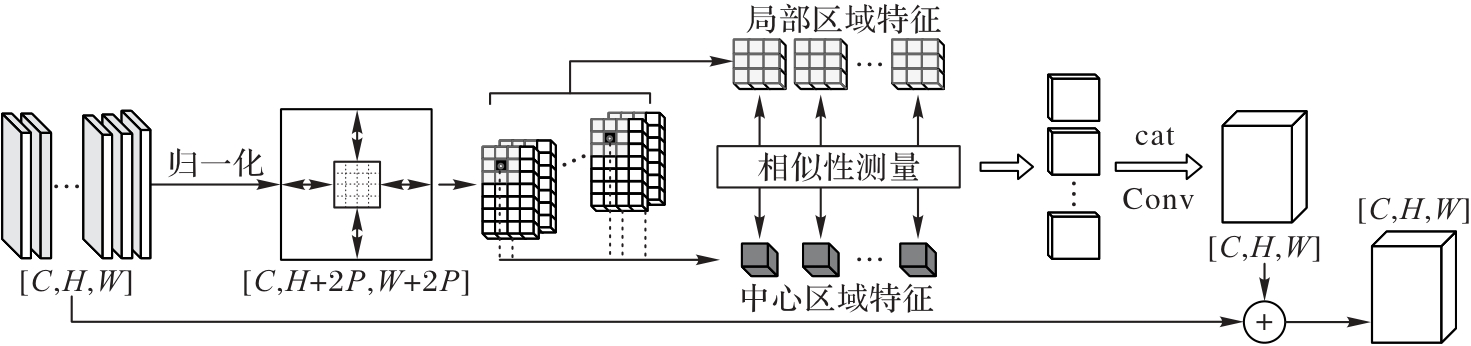
Fig. 3 Structure of spatial context learning module
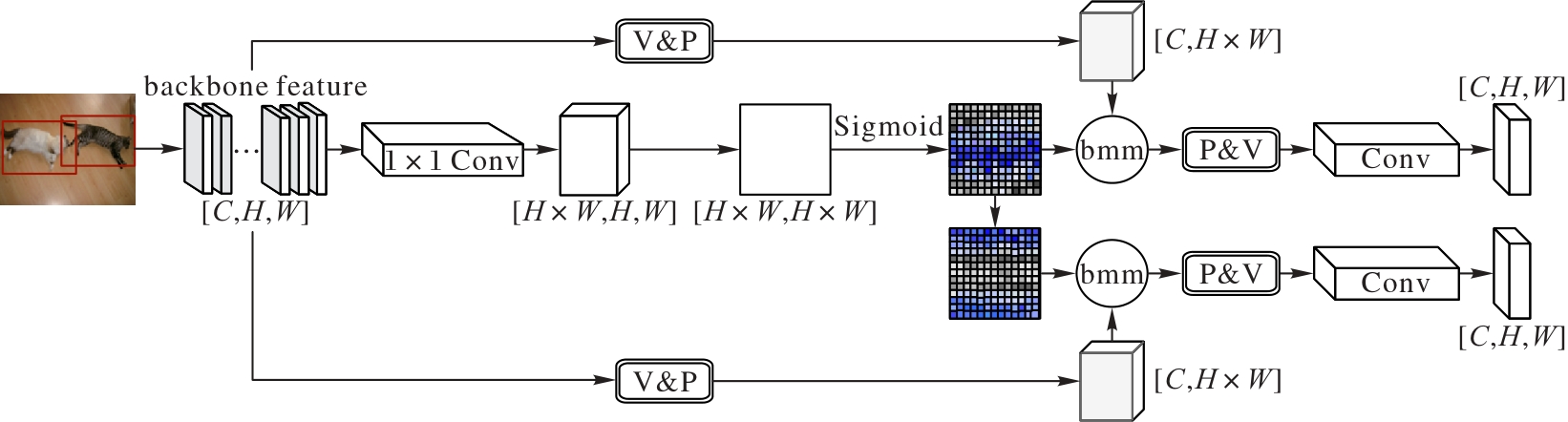
Fig. 4 Structure of pixel context relationship module
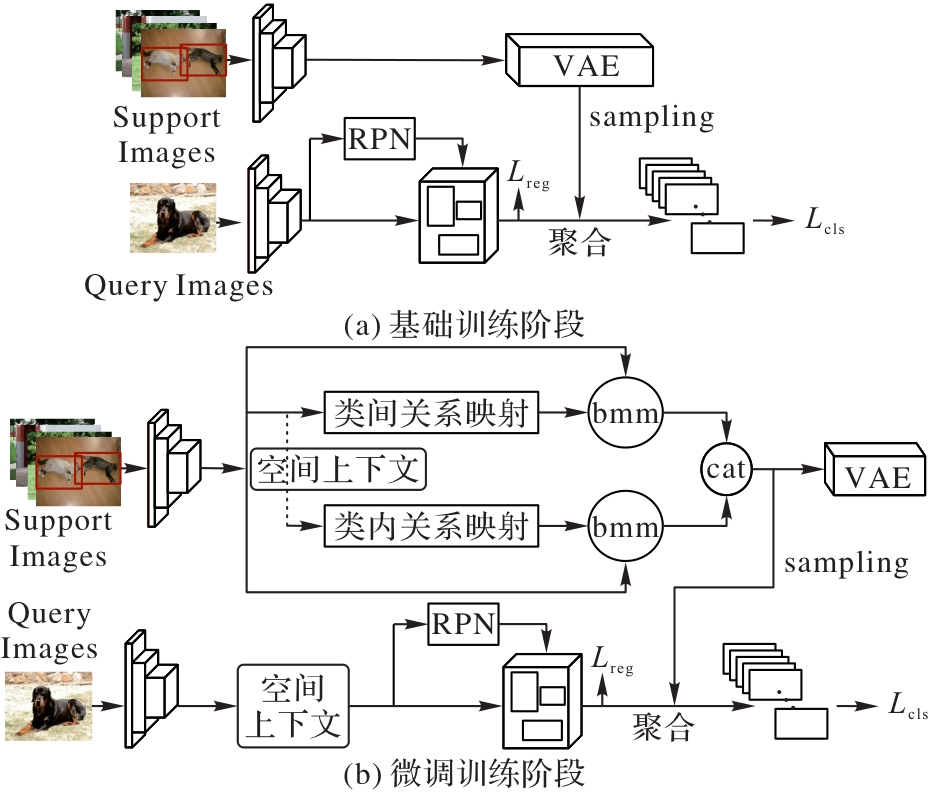
Fig. 5 Two-stage training structure of meta learning
| 方法 | split1 | split2 | split3 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1-shot | 2-shot | 3-shot | 5-shot | 10-shot | 1-shot | 2-shot | 3-shot | 5-shot | 10-shot | 1-shot | 2-shot | 3-shot | 5-shot | 10-shot | |
| FSCE[ | 44.2 | 43.8 | 51.4 | 61.9 | 63.4 | 27.3 | 29.5 | 43.5 | 44.2 | 50.2 | 37.2 | 41.9 | 47.5 | 54.6 | 58.5 |
| Halluc[ | 45.1 | 44.0 | 44.7 | 55.0 | 55.9 | 23.2 | 27.5 | 35.1 | 34.9 | 39.0 | 30.5 | 35.1 | 41.4 | 49.0 | 49.3 |
| UP-FSOD[ | 43.8 | 47.8 | 50.3 | 55.4 | 61.7 | 31.2 | 30.5 | 41.2 | 42.2 | 48.3 | 35.5 | 39.7 | 43.9 | 50.6 | 53.5 |
| FADI[ | 50.3 | 54.8 | 54.2 | 59.3 | 63.2 | 30.6 | 35.0 | 40.3 | 42.8 | 48.0 | 45.7 | 49.7 | 49.1 | 55.0 | 59.6 |
| DeFRCN[ | 53.6 | 57.5 | 61.5 | 64.1 | 60.8 | 30.1 | 38.1 | 47.0 | 53.3 | 47.9 | 48.4 | 50.9 | 52.3 | 54.9 | 57.4 |
| Meta FR-CNN[ | 43.0 | 54.5 | 60.6 | 66.1 | 65.4 | 27.7 | 35.5 | 46.1 | 47.8 | 51.4 | 40.6 | 46.4 | 53.4 | 59.9 | 58.6 |
| FCT[ | 49.9 | 57.1 | 57.9 | 63.2 | 67.1 | 27.6 | 34.5 | 43.7 | 49.2 | 51.2 | 39.5 | 54.7 | 52.3 | 57.0 | 58.7 |
| KFSOD[ | 44.6 | — | 54.4 | 60.9 | 65.8 | 37.8 | — | 43.1 | 48.1 | 50.4 | 34.8 | — | 44.1 | 52.7 | 53.9 |
| VFA*[ | 54.4 | 63.8 | 64.7 | 68.0 | 68.4 | 40.1 | 48.9 | 53.1 | 52.6 | 54.5 | 48.8 | 57.0 | 59.2 | 62.6 | 63.1 |
| SCM | 57.1 | 64.8 | 66.3 | 68.0 | 68.8 | 42.1 | 49.0 | 52.6 | 53.1 | 55.6 | 50.1 | 57.8 | 59.7 | 62.7 | 63.5 |
Tab. 1 Performance comparison of few-shot object detection on VOC dataset (AP50 for novel classes)
| 方法 | split1 | split2 | split3 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1-shot | 2-shot | 3-shot | 5-shot | 10-shot | 1-shot | 2-shot | 3-shot | 5-shot | 10-shot | 1-shot | 2-shot | 3-shot | 5-shot | 10-shot | |
| FSCE[ | 44.2 | 43.8 | 51.4 | 61.9 | 63.4 | 27.3 | 29.5 | 43.5 | 44.2 | 50.2 | 37.2 | 41.9 | 47.5 | 54.6 | 58.5 |
| Halluc[ | 45.1 | 44.0 | 44.7 | 55.0 | 55.9 | 23.2 | 27.5 | 35.1 | 34.9 | 39.0 | 30.5 | 35.1 | 41.4 | 49.0 | 49.3 |
| UP-FSOD[ | 43.8 | 47.8 | 50.3 | 55.4 | 61.7 | 31.2 | 30.5 | 41.2 | 42.2 | 48.3 | 35.5 | 39.7 | 43.9 | 50.6 | 53.5 |
| FADI[ | 50.3 | 54.8 | 54.2 | 59.3 | 63.2 | 30.6 | 35.0 | 40.3 | 42.8 | 48.0 | 45.7 | 49.7 | 49.1 | 55.0 | 59.6 |
| DeFRCN[ | 53.6 | 57.5 | 61.5 | 64.1 | 60.8 | 30.1 | 38.1 | 47.0 | 53.3 | 47.9 | 48.4 | 50.9 | 52.3 | 54.9 | 57.4 |
| Meta FR-CNN[ | 43.0 | 54.5 | 60.6 | 66.1 | 65.4 | 27.7 | 35.5 | 46.1 | 47.8 | 51.4 | 40.6 | 46.4 | 53.4 | 59.9 | 58.6 |
| FCT[ | 49.9 | 57.1 | 57.9 | 63.2 | 67.1 | 27.6 | 34.5 | 43.7 | 49.2 | 51.2 | 39.5 | 54.7 | 52.3 | 57.0 | 58.7 |
| KFSOD[ | 44.6 | — | 54.4 | 60.9 | 65.8 | 37.8 | — | 43.1 | 48.1 | 50.4 | 34.8 | — | 44.1 | 52.7 | 53.9 |
| VFA*[ | 54.4 | 63.8 | 64.7 | 68.0 | 68.4 | 40.1 | 48.9 | 53.1 | 52.6 | 54.5 | 48.8 | 57.0 | 59.2 | 62.6 | 63.1 |
| SCM | 57.1 | 64.8 | 66.3 | 68.0 | 68.8 | 42.1 | 49.0 | 52.6 | 53.1 | 55.6 | 50.1 | 57.8 | 59.7 | 62.7 | 63.5 |
| 方法 | 10-shot | 30-shot | ||||
|---|---|---|---|---|---|---|
| AP | AP | |||||
| LSTD[ | 3.2 | 8.1 | 2.1 | 6.7 | 15.8 | 5.1 |
| FSRW[ | 5.6 | 12.3 | 4.6 | 9.1 | 19.0 | 7.6 |
| MetaDet[ | 7.1 | 14.6 | 6.1 | 11.3 | 21.7 | 8.1 |
| Meta R-CNN[ | 8.7 | 19.1 | 6.6 | 12.4 | 25.3 | 10.8 |
| TFA w/cos[ | 10.0 | — | 9.3 | 13.7 | — | 13.4 |
| Attention RPN[ | 11.1 | 20.4 | 10.6 | — | — | — |
| Viewpoint[ | 12.5 | 27.3 | 9.8 | 14.7 | 30.6 | 12.2 |
| MPSR[ | 9.8 | 17.9 | 9.7 | 14.1 | 25.4 | 14.2 |
| CME[ | 15.1 | 24.6 | 16.4 | 16.9 | 28.0 | 17.8 |
| Meta FR-CNN[ | 12.7 | 25.7 | 10.8 | 16.6 | 31.8 | 15.8 |
| VFA*[ | 16.2 | — | — | 18.9 | — | — |
| SCM | 16.6 | 37.1 | 13.2 | 19.5 | 40.5 | 16.9 |
Tab. 2 Comparison of detection performance for novel classes on COCO dataset
| 方法 | 10-shot | 30-shot | ||||
|---|---|---|---|---|---|---|
| AP | AP | |||||
| LSTD[ | 3.2 | 8.1 | 2.1 | 6.7 | 15.8 | 5.1 |
| FSRW[ | 5.6 | 12.3 | 4.6 | 9.1 | 19.0 | 7.6 |
| MetaDet[ | 7.1 | 14.6 | 6.1 | 11.3 | 21.7 | 8.1 |
| Meta R-CNN[ | 8.7 | 19.1 | 6.6 | 12.4 | 25.3 | 10.8 |
| TFA w/cos[ | 10.0 | — | 9.3 | 13.7 | — | 13.4 |
| Attention RPN[ | 11.1 | 20.4 | 10.6 | — | — | — |
| Viewpoint[ | 12.5 | 27.3 | 9.8 | 14.7 | 30.6 | 12.2 |
| MPSR[ | 9.8 | 17.9 | 9.7 | 14.1 | 25.4 | 14.2 |
| CME[ | 15.1 | 24.6 | 16.4 | 16.9 | 28.0 | 17.8 |
| Meta FR-CNN[ | 12.7 | 25.7 | 10.8 | 16.6 | 31.8 | 15.8 |
| VFA*[ | 16.2 | — | — | 18.9 | — | — |
| SCM | 16.6 | 37.1 | 13.2 | 19.5 | 40.5 | 16.9 |
| 划分 | 阶段 | 1-shot | 2-shot | 3-shot | 5-shot | 10-shot |
|---|---|---|---|---|---|---|
| split1 | 基础训练 | 53.9 | 64.1 | 65.2 | 67.3 | 68.6 |
| 微调训练 | 57.1 | 64.8 | 66.3 | 68.0 | 68.8 | |
| split2 | 基础训练 | 37.7 | 46.8 | 50.2 | 49.2 | 52.6 |
| 微调训练 | 42.1 | 49.0 | 52.6 | 53.1 | 55.6 | |
| split3 | 基础训练 | 51.1 | 54.6 | 58.6 | 61.7 | 62.7 |
| 微调训练 | 50.1 | 57.8 | 59.7 | 62.7 | 63.5 |
Tab. 3 Comparison of AP50 of adding prior spatial context method at different model training stages
| 划分 | 阶段 | 1-shot | 2-shot | 3-shot | 5-shot | 10-shot |
|---|---|---|---|---|---|---|
| split1 | 基础训练 | 53.9 | 64.1 | 65.2 | 67.3 | 68.6 |
| 微调训练 | 57.1 | 64.8 | 66.3 | 68.0 | 68.8 | |
| split2 | 基础训练 | 37.7 | 46.8 | 50.2 | 49.2 | 52.6 |
| 微调训练 | 42.1 | 49.0 | 52.6 | 53.1 | 55.6 | |
| split3 | 基础训练 | 51.1 | 54.6 | 58.6 | 61.7 | 62.7 |
| 微调训练 | 50.1 | 57.8 | 59.7 | 62.7 | 63.5 |
| 组件 | SCL-Q | SCL-S | PCR | 1-shot | 2-shot | 3-shot | 5-shot | 10-shot |
|---|---|---|---|---|---|---|---|---|
| VFA | 54.4 | 63.8 | 64.7 | 68.0 | 68.4 | |||
| SCM | √ | 55.6 | 64.2 | 65.0 | 68.5 | 68.6 | ||
| √ | 55.7 | 64.3 | 64.6 | 68.2 | 68.3 | |||
| √ | 56.3 | 64.1 | 64.9 | 68.3 | 68.5 | |||
| √ | √ | 55.7 | 64.2 | 65.0 | 68.5 | 68.6 | ||
| √ | √ | 56.7 | 64.5 | 65.8 | 68.3 | 68.6 | ||
| √ | √ | √ | 57.1 | 64.8 | 66.3 | 68.0 | 68.8 |
Tab. 4 Influence of different model components (AP50)
| 组件 | SCL-Q | SCL-S | PCR | 1-shot | 2-shot | 3-shot | 5-shot | 10-shot |
|---|---|---|---|---|---|---|---|---|
| VFA | 54.4 | 63.8 | 64.7 | 68.0 | 68.4 | |||
| SCM | √ | 55.6 | 64.2 | 65.0 | 68.5 | 68.6 | ||
| √ | 55.7 | 64.3 | 64.6 | 68.2 | 68.3 | |||
| √ | 56.3 | 64.1 | 64.9 | 68.3 | 68.5 | |||
| √ | √ | 55.7 | 64.2 | 65.0 | 68.5 | 68.6 | ||
| √ | √ | 56.7 | 64.5 | 65.8 | 68.3 | 68.6 | ||
| √ | √ | √ | 57.1 | 64.8 | 66.3 | 68.0 | 68.8 |
| 分支 | 范围选择 | 1-shot | 2-shot | 3-shot | 5-shot | 10-shot |
|---|---|---|---|---|---|---|
| 查询分支 | Q:9 | 53.4 | 63.2 | 64.8 | 67.8 | 68.7 |
| Q:11 | 54.5 | 63.0 | 64.7 | 67.9 | 68.2 | |
| Q:13 | 54.1 | 63.6 | 64.9 | 68.4 | 68.1 | |
| Q:15 | 55.1 | 63.4 | 64.9 | 68.8 | 69.0 | |
| 支持分支 | S:5 | 54.1 | 62.9 | 65.0 | 67.9 | 68.1 |
| S:7 | 52.1 | 62.3 | 64.5 | 67.7 | 67.9 | |
| S:9 | 53.5 | 63.3 | 64.5 | 68.2 | 68.2 | |
| 双分支 | Q:11,S:5 | 55.7 | 63.7 | 64.6 | 68.3 | 68.1 |
| Q:11,S:7 | 54.1 | 63.5 | 64.8 | 67.8 | 68.7 | |
| Q:11,S:9 | 57.1 | 64.9 | 66.2 | 68.1 | 68.5 | |
| Q:11,S:11 | 56.4 | 64.5 | 65.1 | 67.8 | 68.4 | |
| Q:13,S:5 | 55.3 | 64.0 | 64.8 | 67.7 | 68.4 | |
| Q:13,S:7 | 55.3 | 63.4 | 64.2 | 67.5 | 68.3 | |
| Q:13,S:9 | 55.0 | 63.5 | 64.9 | 69.0 | 68.2 |
Tab. 5 Comparison results of selecting different spatial ranges in SCL module (AP50)
| 分支 | 范围选择 | 1-shot | 2-shot | 3-shot | 5-shot | 10-shot |
|---|---|---|---|---|---|---|
| 查询分支 | Q:9 | 53.4 | 63.2 | 64.8 | 67.8 | 68.7 |
| Q:11 | 54.5 | 63.0 | 64.7 | 67.9 | 68.2 | |
| Q:13 | 54.1 | 63.6 | 64.9 | 68.4 | 68.1 | |
| Q:15 | 55.1 | 63.4 | 64.9 | 68.8 | 69.0 | |
| 支持分支 | S:5 | 54.1 | 62.9 | 65.0 | 67.9 | 68.1 |
| S:7 | 52.1 | 62.3 | 64.5 | 67.7 | 67.9 | |
| S:9 | 53.5 | 63.3 | 64.5 | 68.2 | 68.2 | |
| 双分支 | Q:11,S:5 | 55.7 | 63.7 | 64.6 | 68.3 | 68.1 |
| Q:11,S:7 | 54.1 | 63.5 | 64.8 | 67.8 | 68.7 | |
| Q:11,S:9 | 57.1 | 64.9 | 66.2 | 68.1 | 68.5 | |
| Q:11,S:11 | 56.4 | 64.5 | 65.1 | 67.8 | 68.4 | |
| Q:13,S:5 | 55.3 | 64.0 | 64.8 | 67.7 | 68.4 | |
| Q:13,S:7 | 55.3 | 63.4 | 64.2 | 67.5 | 68.3 | |
| Q:13,S:9 | 55.0 | 63.5 | 64.9 | 69.0 | 68.2 |
| 类别 | VFA | SCM | 类别 | VFA | SCM |
|---|---|---|---|---|---|
| bicycle | 78.4 | 81.4 | diningtable | 40.4 | 48.2 |
| car | 76.7 | 79.4 | horse | 83.9 | 84.2 |
| boat | 66.3 | 67.1 | sheep | 75.2 | 76.1 |
| cat | 86.1 | 87.2 | tvmonitor | 52.2 | 56.0 |
| chair | 10.8 | 18.6 |
Tab. 6 Comparison of base class precision under 1-shot setting
| 类别 | VFA | SCM | 类别 | VFA | SCM |
|---|---|---|---|---|---|
| bicycle | 78.4 | 81.4 | diningtable | 40.4 | 48.2 |
| car | 76.7 | 79.4 | horse | 83.9 | 84.2 |
| boat | 66.3 | 67.1 | sheep | 75.2 | 76.1 |
| cat | 86.1 | 87.2 | tvmonitor | 52.2 | 56.0 |
| chair | 10.8 | 18.6 |
| 类别 | VFA | SCM | 类别 | VFA | SCM |
|---|---|---|---|---|---|
| bird | 47.2 | 49.2 | motorbike | 69.2 | 70.6 |
| bus | 62.2 | 63.1 | sofa | 37.5 | 40.0 |
| cow | 59.0 | 62.5 |
Tab. 7 Comparison of novel class precision under 1-shot setting
| 类别 | VFA | SCM | 类别 | VFA | SCM |
|---|---|---|---|---|---|
| bird | 47.2 | 49.2 | motorbike | 69.2 | 70.6 |
| bus | 62.2 | 63.1 | sofa | 37.5 | 40.0 |
| cow | 59.0 | 62.5 |
| 特征 | 1-shot | 2-shot | 3-shot | 4-shot | 5-shot |
|---|---|---|---|---|---|
| Context Feature | 56.4 | 64.3 | 66.3 | 68.3 | 68.6 |
| Initial Feature | 57.1 | 64.8 | 66.3 | 68.0 | 68.8 |
Tab. 8 Comparison of AP50 for pixel context relationships with different features
| 特征 | 1-shot | 2-shot | 3-shot | 4-shot | 5-shot |
|---|---|---|---|---|---|
| Context Feature | 56.4 | 64.3 | 66.3 | 68.3 | 68.6 |
| Initial Feature | 57.1 | 64.8 | 66.3 | 68.0 | 68.8 |
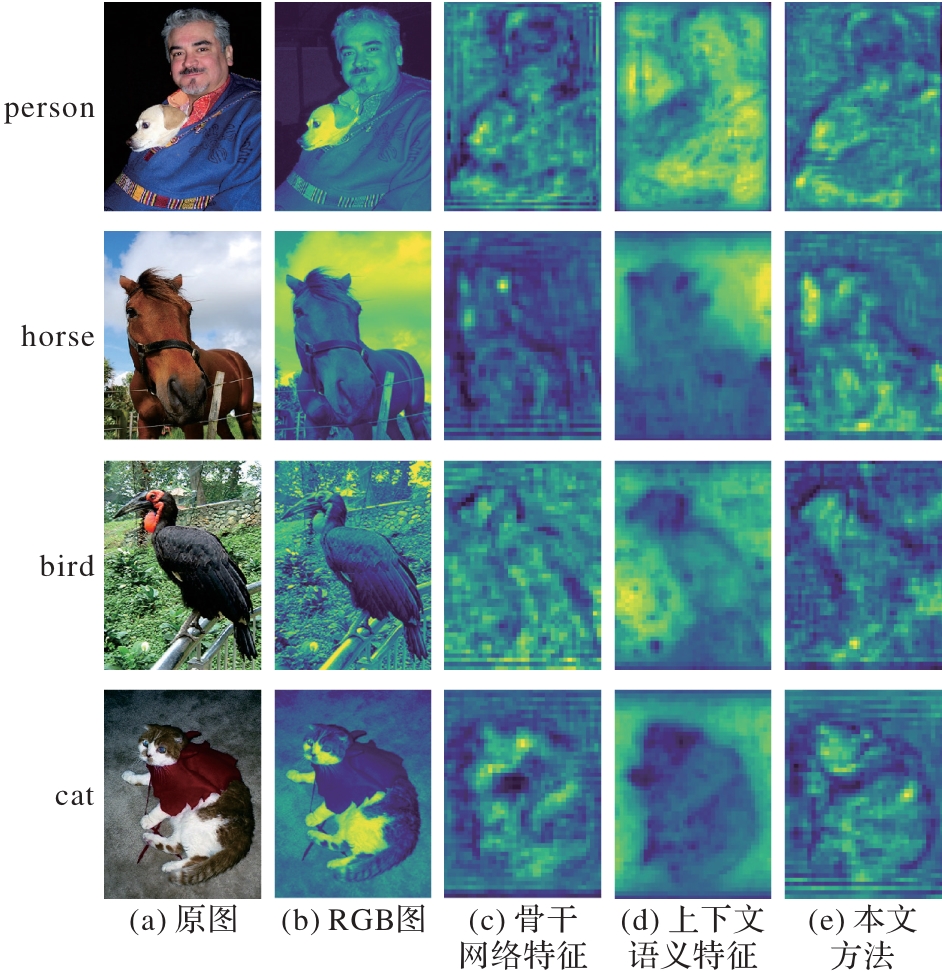
Fig. 6 Visualization of feature maps

Fig. 7 Visualization of few-shot object detection results
| [1] | ZHANG Y, WEI X S, ZHOU B, et al. Bag of tricks for long-tailed visual recognition with deep convolutional neural networks [C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 3447-3455. |
| [2] | WANG C, LI Z, MO X, et al. Exploiting unfairness with meta-Set learning for chronological age estimation [J]. IEEE Transactions on Information Forensics and Security, 2023, 18: 5678-5690. |
| [3] | 史燕燕,史殿习,乔子腾,等. 小样本目标检测研究综述[J]. 计算机学报, 2023, 46(8): 1753-1780. |
| SHI Y Y, SHI D X, QIAO Z T, et al. A survey on recent advances in few-shot object detection[J]. Chinese Journal of Computers, 2023, 46(8): 1753-1780. | |
| [4] | SUN B, LI B, CAI S, et al. FSCE: few-shot object detection via contrastive proposal encoding [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 7348-7358. |
| [5] | WU A, HAN Y, ZHU L, et al. Universal-prototype enhancing for few-shot object detection [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 9547-9556. |
| [6] | CHEN H, WANG Y, WANG G, et al. LSTD: a low-shot transfer detector for object detection [C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2018: 2836-2843. |
| [7] | SHANGGUAN Z, SEITA D, ROSTAMI M. Cross-domain multi-modal few-shot object detection via rich text [C]// Proceedings of the 2025 IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2025: 6570-6580. |
| [8] | FU Y, WANG Y, PAN Y, et al. Cross-domain few-shot object detection via enhanced open-set object detector [C]// Proceedings of the 2024 European Conference on Computer Vision, LNCS 15116. Cham: Springer, 2025: 247-264. |
| [9] | CAO Y, WANG J, JIN Y, et al. Few-shot object detection via association and discrimination [C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 16570-16581. |
| [10] | ZHANG S, WANG L, MURRAY N, et al. Kernelized few-shot object detection with efficient integral aggregation [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 19185-19194. |
| [11] | KANG B, LIU Z, WANG X, et al. Few-shot object detection via feature reweighting [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 8419-8428. |
| [12] | 李鸿天,史鑫昊,潘卫国,等. 融合多尺度和注意力机制的小样本目标检测[J].计算机应用, 2024, 44(5):1437-1444. |
| LI H T, SHI X H, PAN W G, et al. Few-shot object detection via fusing multi-scale and attention mechanism [J]. Journal of Computer Applications, 2024, 44(5):1437-1444. | |
| [13] | CHEN T I, LIU Y C, SU H T, et al. Dual-awareness attention for few-shot object detection [J]. IEEE Transactions on Multimedia, 2023, 25: 291-301. |
| [14] | LI B, WANG C, REDDY P, et al. AirDet: few-shot detection without fine-tuning for autonomous exploration [C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13699. Cham: Springer, 2022: 427-444. |
| [15] | ZHANG X, CHEN Z, ZHANG J, et al. Learning general and specific embedding with Transformer for few-shot object detection[J]. International Journal of Computer Vision, 2025, 133(2): 968-984. |
| [16] | LI W, ZHOU J, LI X, et al. InfRS: incremental few-shot object detection in remote sensing images [J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: No.5644314. |
| [17] | MA J, NIU Y, XU J, et al. DiGeo: discriminative geometry-aware learning for generalized few-shot object detection [C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 3208-3218. |
| [18] | CHEN H, WANG Q, XIE K, et al. MPF-Net: multi-projection filtering network for few-shot object detection [J]. Applied Intelligence, 2024, 54(17/18): 7777-7792. |
| [19] | LI B, YANG B, LIU C, et al. Beyond max-margin: class margin equilibrium for few-shot object detection [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 7359-7368. |
| [20] | 李新叶,侯晔凝,孔英会,等. 结合特征融合与增强注意力的少样本目标检测[J]. 计算机应用, 2024, 44(3):745-751. |
| LI X Y, HOU Y N, KONG Y H, et al. Few-shot object detection combining feature fusion and enhanced attention [J]. Journal of Computer Applications, 2024, 44(3):745-751. | |
| [21] | HAN G, MA J, HUANG S, et al. Few-shot object detection with fully cross-Transformer [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 5321-5330. |
| [22] | CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with Transformers [C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12346. Cham: Springer, 2020: 213-229. |
| [23] | FAN Q, ZHUO W, TANG C K, et al. Few-shot object detection with attention-RPN and multi-relation detector [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 4012-4021. |
| [24] | SHANGGUAN Z, ROSTAMI M. Improved region proposal network for enhanced few-shot object detection [J]. Neural Networks, 2024, 180: No.106699. |
| [25] | CHOI T M, KIM J H. Incremental few-shot object detection via simple fine-tuning approach [C]// Proceedings of the 2023 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2023: 9289-9295. |
| [26] | WANG X, HUANG T E, DARRELL T, et al. Frustratingly simple few-shot object detection [C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 9919-9928. |
| [27] | HU H, BAI S, LI A, et al. Dense relation distillation with context-aware aggregation for few-shot object detection [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 10180-10189. |
| [28] | QIAO L, ZHAO Y, LI Z, et al. DeFRCN: decoupled Faster R-CNN for few-shot object detection [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 8661-8670. |
| [29] | WANG Y X, RAMANAN D, HEBERT M. Meta-learning to detect rare objects [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 9924-9933. |
| [30] | ZHANG G, LUO Z, CUI K, et al. Meta-DETR: image-level few-shot object detection with inter-class correlation exploitation [J]. Neural Networks, 2023, 45(11): 12832-12843. |
| [31] | ZHU X, SU W, LU L, et al. Deformable DETR: deformable Transformers for end-to-end object detection [EB/OL]. [2024-05-18]. . |
| [32] | WU J, LIU S, HUANG D, et al. Multi-scale positive sample refinement for few-shot object detection [C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12361. Cham: Springer, 2020: 456-472. |
| [33] | HAN J, REN Y, DING J, et al. Few-shot object detection via variational feature aggregation [C]// Proceedings of the 37th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023: 755-763. |
| [34] | KINGMA D P, WELLING M. Auto-encoding variational Bayes[EB/OL]. [2024-05-24]. . |
| [35] | REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks [C]// Proceedings of the 28th International Conference on Neural Information Processing Systems — Volume 1. Cambridge: MIT Press, 2015: 91-99. |
| [36] | WANG Z, YANG B, YUE H, et al. Fine-grained prototypes distillation for few-shot object detection [C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 5859-5866. |
| [37] | EVERINGHAM M, VAN GOOL L, WILLIAMS C K I, et al. The PASCAL Visual Object Classes (VOC) challenge [J]. International Journal of Computer Vision, 2010, 88(2): 303-338. |
| [38] | CHEN X, FANG H, LIN T Y, et al. Microsoft COCO captions: data collection and evaluation server [EB/OL]. [2024-05-21].. |
| [39] | OpenMMLab. OpenMMLab few shot learning toolbox and benchmark [EB/OL]. [2024-06-18].. |
| [40] | DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database [C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2009: 248-255. |
| [41] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| [42] | ZHANG W, WANG Y X. Hallucination improves few-shot object detection [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 13003-13012. |
| [43] | HAN G, HUANG S, MA J, et al. Meta Faster R-CNN: towards accurate few-shot object detection with attentive feature alignment[C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2022: 780-789. |
| [44] | YAN X, CHEN Z, XU A, et al. Meta R-CNN: towards general solver for instance-level low-shot learning [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 9576-9585. |
| [45] | XIAO Y, LEPETIT V, MARLET R. Few-shot object detection and Viewpoint estimation for objects in the wild [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(3): 3090-3106. |
| [1] | Jiaxiang ZHANG, Xiaoming LI, Jiahui ZHANG. Few-shot object detection algorithm based on new category feature enhancement and metric mechanism [J]. Journal of Computer Applications, 2025, 45(9): 2984-2992. |
| [2] | Hongtian LI, Xinhao SHI, Weiguo PAN, Cheng XU, Bingxin XU, Jiazheng YUAN. Few-shot object detection via fusing multi-scale and attention mechanism [J]. Journal of Computer Applications, 2024, 44(5): 1437-1444. |
| [3] | Keyi FU, Gaocai WANG, Man WU. Few-shot object detection method based on improved region proposal network and feature aggregation [J]. Journal of Computer Applications, 2024, 44(12): 3790-3797. |
| [4] | Runchao LIN, Rong HUANG, Aihua DONG. Few-shot object detection based on attention mechanism and secondary reweighting of meta-features [J]. Journal of Computer Applications, 2022, 42(10): 3025-3032. |
| [5] | Yang LIU Feng-bin ZHENG Bao-qing JIANG Kun CAI. Research of cross-media information retrieval model based on multimodal fusion and temporal-spatial context semantic [J]. Journal of Computer Applications, 2009, 29(4): 1182-1187. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||