


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (12): 3970-3977.DOI: 10.11772/j.issn.1001-9081.2024111619
• Multimedia computing and computer simulation • Previous Articles Next Articles
Chao WEI, Wei YE( ), Guangjian SHENG, Lei ZHANG
), Guangjian SHENG, Lei ZHANG
Received:2024-11-14
Revised:2025-03-01
Accepted:2025-03-12
Online:2025-03-21
Published:2025-12-10
Contact:
Wei YE
About author:WEI Chao, born in 1996, M. S. candidate. His research interests include machine vision, image fusion.
魏超, 叶威(), 盛光健, 张蕾
通讯作者:
叶威
作者简介:魏超(1996—),男,湖北武汉人,硕士研究生,主要研究方向:机器视觉、图像融合CLC Number:
Chao WEI, Wei YE, Guangjian SHENG, Lei ZHANG. Light-adaptive image fusion algorithm based on gradient enhancement and text guidance[J]. Journal of Computer Applications, 2025, 45(12): 3970-3977.
魏超, 叶威, 盛光健, 张蕾. 基于梯度增强和文本引导的光照自适应图像融合算法[J]. 《计算机应用》唯一官方网站, 2025, 45(12): 3970-3977.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024111619
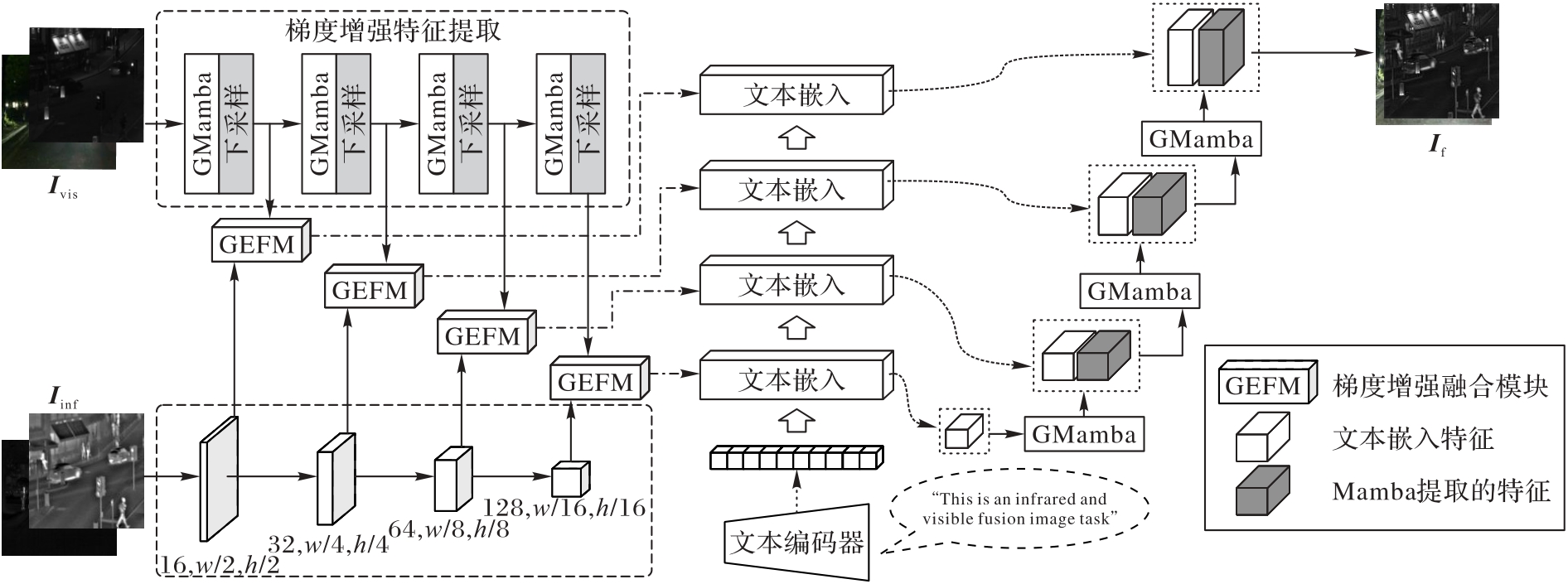
Fig. 1 Network structure of proposed algorithm
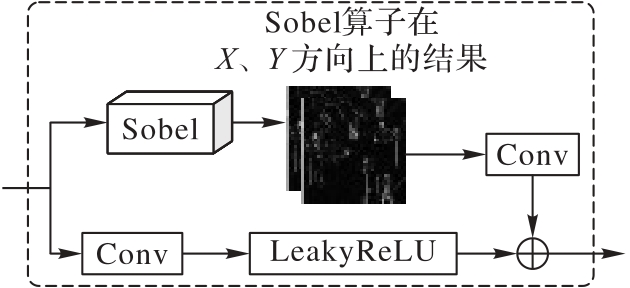
Fig. 2 Overall structure of GEM

Fig. 3 Structure of GMamba

Fig. 4 Structure of GEFM
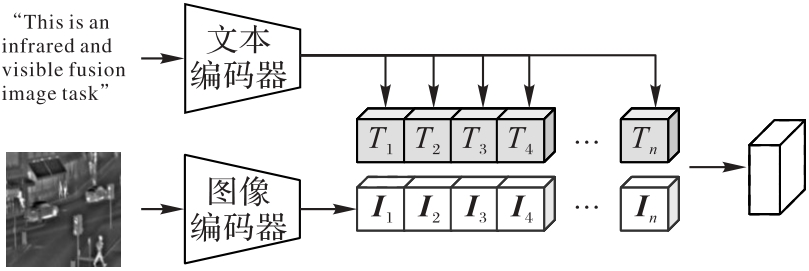
Fig. 5 Structure of text information embedding module
| 数据集 | 算法 | EN | SF | AG | SD | VIF | Qabf |
|---|---|---|---|---|---|---|---|
| TNO | UMF-CMGR | 6.533 | 8.177 | 2.973 | 29.969 | 0.595 | 0.410 |
| GANMcC | 6.736 | 6.111 | 2.544 | 32.035 | 0.530 | 0.281 | |
| LRRNet | 6.991 | 9.510 | 3.762 | 0.564 | 0.353 | ||
| DATFuse | 6.551 | 10.046 | 3.697 | 28.351 | |||
| CAMF | 7.110 | 48.298 | 0.464 | 0.289 | |||
| 本文算法 | 11.352 | 4.317 | 39.285 | 0.833 | 0.621 | ||
| MSRS | UMF-CMGR | 5.058 | 6.033 | 1.738 | 16.889 | 0.308 | 0.232 |
| GANMcC | 5.226 | 1.835 | 24.349 | 0.682 | |||
| LRRNet | 5.183 | 6.088 | 1.692 | 20.323 | 0.436 | 0.308 | |
| DATFuse | 5.809 | 0.542 | |||||
| CAMF | 5.400 | 5.312 | 1.535 | 21.089 | 0.573 | 0.266 | |
| 本文算法 | 7.270 | 15.692 | 6.062 | 47.884 | 1.208 | 0.304 | |
| LLVIP | UMF-CMGR | 6.462 | 9.915 | 2.504 | 29.379 | 0.521 | 0.347 |
| GANMcC | 6.690 | 6.814 | 2.123 | 32.113 | 0.613 | 0.297 | |
| LRRNet | 6.145 | 9.108 | 2.467 | 24.867 | 0.564 | ||
| DATFuse | 0.514 | ||||||
| CAMF | 6.811 | 7.248 | 2.234 | 33.867 | 0.692 | 0.341 | |
| 本文算法 | 7.597 | 23.723 | 7.789 | 52.361 | 1.032 | 0.339 |
Tab. 1 Comparison of objective metrics on different datasets
| 数据集 | 算法 | EN | SF | AG | SD | VIF | Qabf |
|---|---|---|---|---|---|---|---|
| TNO | UMF-CMGR | 6.533 | 8.177 | 2.973 | 29.969 | 0.595 | 0.410 |
| GANMcC | 6.736 | 6.111 | 2.544 | 32.035 | 0.530 | 0.281 | |
| LRRNet | 6.991 | 9.510 | 3.762 | 0.564 | 0.353 | ||
| DATFuse | 6.551 | 10.046 | 3.697 | 28.351 | |||
| CAMF | 7.110 | 48.298 | 0.464 | 0.289 | |||
| 本文算法 | 11.352 | 4.317 | 39.285 | 0.833 | 0.621 | ||
| MSRS | UMF-CMGR | 5.058 | 6.033 | 1.738 | 16.889 | 0.308 | 0.232 |
| GANMcC | 5.226 | 1.835 | 24.349 | 0.682 | |||
| LRRNet | 5.183 | 6.088 | 1.692 | 20.323 | 0.436 | 0.308 | |
| DATFuse | 5.809 | 0.542 | |||||
| CAMF | 5.400 | 5.312 | 1.535 | 21.089 | 0.573 | 0.266 | |
| 本文算法 | 7.270 | 15.692 | 6.062 | 47.884 | 1.208 | 0.304 | |
| LLVIP | UMF-CMGR | 6.462 | 9.915 | 2.504 | 29.379 | 0.521 | 0.347 |
| GANMcC | 6.690 | 6.814 | 2.123 | 32.113 | 0.613 | 0.297 | |
| LRRNet | 6.145 | 9.108 | 2.467 | 24.867 | 0.564 | ||
| DATFuse | 0.514 | ||||||
| CAMF | 6.811 | 7.248 | 2.234 | 33.867 | 0.692 | 0.341 | |
| 本文算法 | 7.597 | 23.723 | 7.789 | 52.361 | 1.032 | 0.339 |
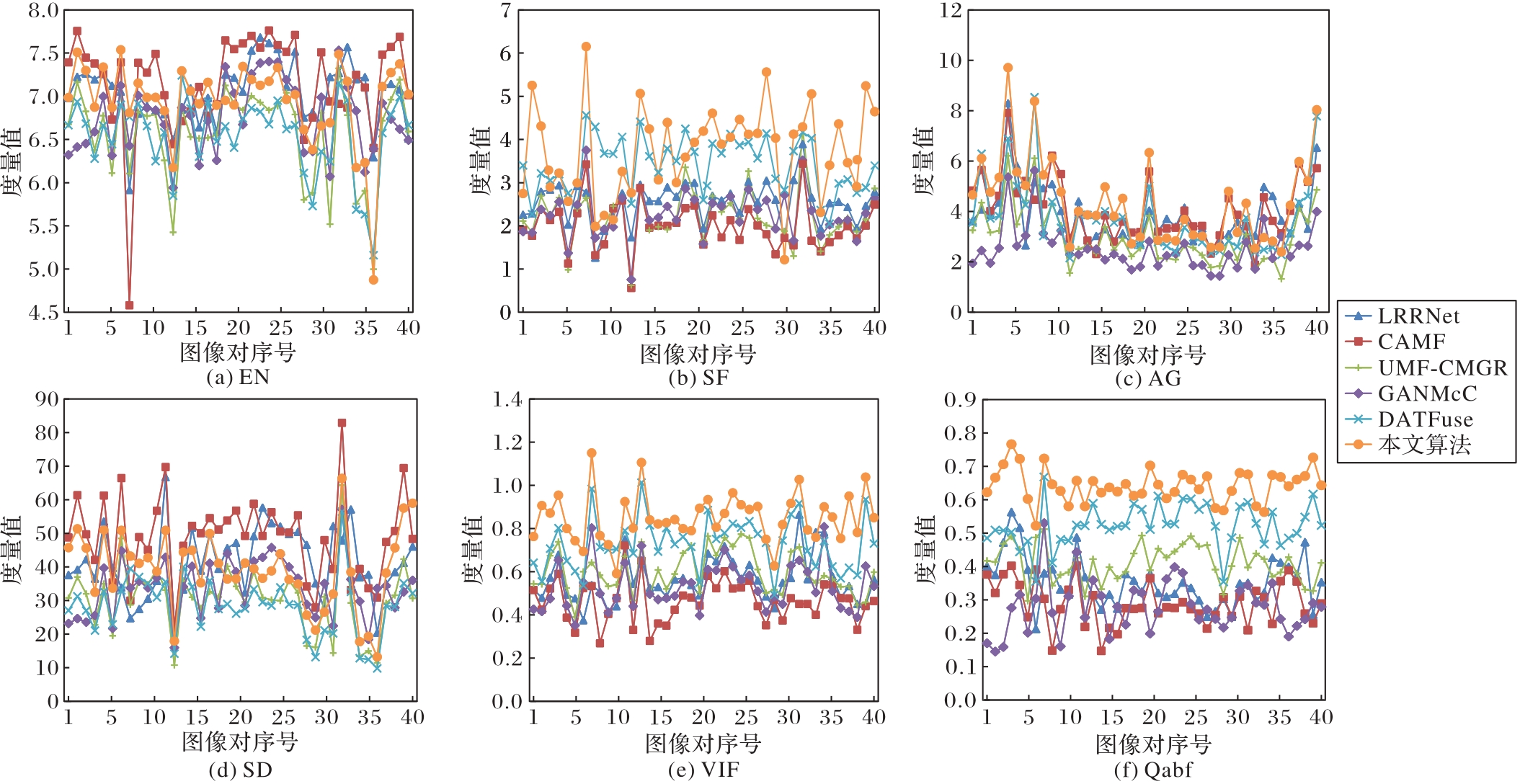
Fig. 6 Comparison of fusion results achieved by six algorithms on forty pairs of images from TNO dataset

Fig. 7 Visual comparison of different algorithms on three datasets
| 模块 | EN | SF | AG | SD | VIF | Qabf |
|---|---|---|---|---|---|---|
| w/o GMamba | 6.813 | 9.706 | 3.554 | 38.853 | 0.857 | 0.560 |
| w/o attention | 6.917 | 10.387 | 3.961 | 38.908 | 0.849 | 0.548 |
| w/o fusion | 6.910 | 10.484 | 3.980 | 38.420 | 0.826 | 0.541 |
| w/o CLIP | 6.731 | 12.250 | 4.734 | 32.060 | 0.619 | 0.456 |
| 本文算法 | 6.926 | 11.352 | 4.318 | 39.285 | 0.834 | 0.621 |
Tab.2 Objective evaluation metrics in ablation experiments
| 模块 | EN | SF | AG | SD | VIF | Qabf |
|---|---|---|---|---|---|---|
| w/o GMamba | 6.813 | 9.706 | 3.554 | 38.853 | 0.857 | 0.560 |
| w/o attention | 6.917 | 10.387 | 3.961 | 38.908 | 0.849 | 0.548 |
| w/o fusion | 6.910 | 10.484 | 3.980 | 38.420 | 0.826 | 0.541 |
| w/o CLIP | 6.731 | 12.250 | 4.734 | 32.060 | 0.619 | 0.456 |
| 本文算法 | 6.926 | 11.352 | 4.318 | 39.285 | 0.834 | 0.621 |
| 实验 | EN | SF | AG | SD | VIF | Qabf |
|---|---|---|---|---|---|---|
| 实验1 | 6.818 | 9.561 | 3.564 | 34.407 | 0.858 | 0.589 |
| 实验2 | 6.709 | 11.070 | 3.961 | 39.502 | 0.652 | 0.610 |
| 实验3 | 6.917 | 11.480 | 3.980 | 38.420 | 0.826 | 0.619 |
| 实验4 | 6.925 | 11.352 | 4.317 | 39.285 | 0.833 | 0.621 |
Tab.3 Comparison of experimental metrics for loss function ablation
| 实验 | EN | SF | AG | SD | VIF | Qabf |
|---|---|---|---|---|---|---|
| 实验1 | 6.818 | 9.561 | 3.564 | 34.407 | 0.858 | 0.589 |
| 实验2 | 6.709 | 11.070 | 3.961 | 39.502 | 0.652 | 0.610 |
| 实验3 | 6.917 | 11.480 | 3.980 | 38.420 | 0.826 | 0.619 |
| 实验4 | 6.925 | 11.352 | 4.317 | 39.285 | 0.833 | 0.621 |
| 算法 | 模型大小/MB | 运行时间/s |
|---|---|---|
| UMF-CMGR | 10.90 | 0.05 |
| GANMcC | 0.21 | 0.07 |
| LRRNet | 0.07 | 0.02 |
| DATFuse | 7.22 | 0.01 |
| CAMF | 10.90 | 0.09 |
| 本文算法 | 479.30 | 0.28 |
Tab.4 Algorithm efficiency analysis
| 算法 | 模型大小/MB | 运行时间/s |
|---|---|---|
| UMF-CMGR | 10.90 | 0.05 |
| GANMcC | 0.21 | 0.07 |
| LRRNet | 0.07 | 0.02 |
| DATFuse | 7.22 | 0.01 |
| CAMF | 10.90 | 0.09 |
| 本文算法 | 479.30 | 0.28 |

Fig. 8 Comparison of fusion effects under different noise intensities
| 噪声类型 | MI | Qabf |
|---|---|---|
| 不添加噪声 | 3.630 7 | 0.621 3 |
| Gaussian(var=10) | 3.047 4 | 0.711 9 |
| Gaussian(var=20) | 3.049 8 | 0.711 9 |
| Gaussian(var=30) | 3.049 0 | 0.711 9 |
| Salt(d=0.01) | 3.480 4 | 0.700 4 |
| Salt(d=0.02) | 3.715 0 | 0.737 2 |
| Salt(d=0.03) | 3.880 2 | 0.770 6 |
Tab.5 Quantitative metric analysis under different noise intensities
| 噪声类型 | MI | Qabf |
|---|---|---|
| 不添加噪声 | 3.630 7 | 0.621 3 |
| Gaussian(var=10) | 3.047 4 | 0.711 9 |
| Gaussian(var=20) | 3.049 8 | 0.711 9 |
| Gaussian(var=30) | 3.049 0 | 0.711 9 |
| Salt(d=0.01) | 3.480 4 | 0.700 4 |
| Salt(d=0.02) | 3.715 0 | 0.737 2 |
| Salt(d=0.03) | 3.880 2 | 0.770 6 |
| [1] | MA J, MA Y, LI C. Infrared and visible image fusion methods and applications: a survey[J]. Information Fusion, 2019, 45: 153-178. |
| [2] | ZHANG H, XU H, TIAN X, et al. Image fusion meets deep learning: a survey and perspective[J]. Information Fusion, 2021, 76: 323-336. |
| [3] | 朱浩然,刘云清,张文颖. 基于对比度增强与多尺度边缘保持分解的红外与可见光图像融合[J]. 电子与信息学报, 2018, 40(6): 1294-1300. |
| ZHU H R, LIU Y Q, ZHANG W Y. Infrared and visible image fusion based on contrast enhancement and multi-scale edge-preserving decomposition[J]. Journal of Electronics and Information Technology, 2018, 40(6): 1294-1300. | |
| [4] | WU M, MA Y, FAN F, et al. Infrared and visible image fusion via joint convolutional sparse representation[J]. Journal of the Optical Society of America A, 2020, 37(7): 1105-1115. |
| [5] | LIU Z, FENG Y, CHEN H, et al. A fusion algorithm for infrared and visible based on guided filtering and phase congruency in NSST domain [J]. Optics and Lasers in Engineering, 2017, 97: 71-77. |
| [6] | LI H, WU X J, KITTLER J. MDLatLRR: a novel decomposition method for infrared and visible image fusion [J]. IEEE Transactions on Image Processing, 2020, 29: 4733-4746. |
| [7] | MA J, ZHOU Z, WANG B, et al. Infrared and visible image fusion based on visual saliency map and weighted least square optimization[J]. Infrared Physics and Technology, 2017, 82: 8-17. |
| [8] | LI H, WU X J. DenseFuse: a fusion approach to infrared and visible images [J]. IEEE Transactions on Image Processing, 2019, 28(5): 2614-2623. |
| [9] | LI H, WU X J, DURRANI T. NestFuse: an infrared and visible image fusion architecture based on nest connection and spatial/Channel attention models[J]. IEEE Transactions on Instrumentation and Measurement, 2020, 69(12): 9645-9656. |
| [10] | TANG L, YUAN J, ZHANG H, et al. PIAFusion: a progressive infrared and visible image fusion network based on illumination aware [J]. Information Fusion, 2022, 83/84: 79-92. |
| [11] | HU K, ZHANG Q, YUAN M, et al. SFDFusion: an efficient spatial-frequency domain fusion network for infrared and visible image fusion [C]// Proceedings of the 1st European Conference on Artificial Intelligence. Amsterdam: IOS Press, 2024: 482-489. |
| [12] | 李嘉元,程江华,刘通,等. 基于密集连接的红外可见光图像融合方法[J]. 计算机应用, 2023, 43(S2): 163-167. |
| LI J Y, CHENG J H, LIU T, et al. Infrared and visible light image fusion method based on dense connection[J]. Journal of Computer Applications, 2023, 43(S2): 163-167. | |
| [13] | MA J, YU W, LIANG P, et al. FusionGAN: a generative adversarial network for infrared and visible image fusion[J]. Information Fusion, 2019, 48: 11-26. |
| [14] | TANG H, LIU H, XU D, et al. AttentionGAN: unpaired image-to-image translation using attention-guided generative adversarial networks [J]. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(4): 1972-1987. |
| [15] | RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation [C]// Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 9351. Cham: Springer, 2015: 234-241. |
| [16] | GU A, DAO T. Mamba: linear-time sequence modeling with selective state spaces [EB/OL]. [2024-06-26]. . |
| [17] | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 8748-8763. |
| [18] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [19] | TOET A. The TNO multiband image data collection [J]. Data in Brief, 2017, 15: 249-251. |
| [20] | JIA X, ZHU C, LI M, et al. LLVIP: a visible-infrared paired dataset for low-light vision [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops. Piscataway: IEEE, 2021: 3489-3497. |
| [21] | LI H, XU T, WU X J, et al. LRRNet: a novel representation learning guided fusion network for infrared and visible images [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(9): 11040-11052. |
| [22] | TANG L, CHEN Z, HUANG J, et al. CAMF: an interpretable infrared and visible image fusion network based on class activation mapping [J]. IEEE Transactions on Multimedia, 2024, 26: 4776-4791. |
| [23] | TANG W, HE F, LIU Y, et al. DATFuse: infrared and visible image fusion via dual attention transformer [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(7): 3159-3172. |
| [24] | WANG D, LIU J, FAN X, et al. Unsupervised misaligned infrared and visible image fusion via cross-modality image generation and registration[C]// Proceedings of the 31st International Joint Conference on Artificial Intelligence. California: ijcai.org, 2022: 3508-3515. |
| [25] | MA J, ZHANG H, SHAO Z, et al. GANMcC: a generative adversarial network with multiclassification constraints for infrared and visible image fusion[J]. IEEE Transactions on Instrumentation and Measurement, 2021, 70: No.5005014. |
| [26] | ZHANG X. Benchmarking and comparing multi-exposure image fusion algorithms [J]. Information Fusion, 2021, 74: 111-131. |
| [1] | Yingjie MA, Jingying QIN, Geng ZHAO, Jing XIAO. Deep compressive sensing network for IoT images and its chaotic encryption protection method [J]. Journal of Computer Applications, 2026, 46(1): 144-151. |
| [2] | Lifang WANG, Wenjing REN, Xiaodong GUO, Rongguo ZHANG, Lihua HU. Trident generative adversarial network for low-dose CT image denoising [J]. Journal of Computer Applications, 2026, 46(1): 270-279. |
| [3] | Yanan LI, Mengyang GUO, Guojun DENG, Yunfeng CHEN, Jianji REN, Yongliang YUAN. Method for life prediction of parallel branching engine based on multi-modal fusion features [J]. Journal of Computer Applications, 2026, 46(1): 305-313. |
| [4] | Jin LI, Liqun LIU. SAR and visible image fusion based on residual Swin Transformer [J]. Journal of Computer Applications, 2025, 45(9): 2949-2956. |
| [5] | Jinggang LYU, Shaorui PENG, Shuo GAO, Jin ZHOU. Speech enhancement network driven by complex frequency attention and multi-scale frequency enhancement [J]. Journal of Computer Applications, 2025, 45(9): 2957-2965. |
| [6] | Weigang LI, Jiale SHAO, Zhiqiang TIAN. Point cloud classification and segmentation network based on dual attention mechanism and multi-scale fusion [J]. Journal of Computer Applications, 2025, 45(9): 3003-3010. |
| [7] | Xiang WANG, Zhixiang CHEN, Guojun MAO. Multivariate time series prediction method combining local and global correlation [J]. Journal of Computer Applications, 2025, 45(9): 2806-2816. |
| [8] | Jin ZHOU, Yuzhi LI, Xu ZHANG, Shuo GAO, Li ZHANG, Jiachuan SHENG. Modulation recognition network for complex electromagnetic environments [J]. Journal of Computer Applications, 2025, 45(8): 2672-2682. |
| [9] | Chao JING, Yutao QUAN, Yan CHEN. Improved multi-layer perceptron and attention model-based power consumption prediction algorithm [J]. Journal of Computer Applications, 2025, 45(8): 2646-2655. |
| [10] | Jinhao LIN, Chuan LUO, Tianrui LI, Hongmei CHEN. Thoracic disease classification method based on cross-scale attention network [J]. Journal of Computer Applications, 2025, 45(8): 2712-2719. |
| [11] | Haifeng WU, Liqing TAO, Yusheng CHENG. Partial label regression algorithm integrating feature attention and residual connection [J]. Journal of Computer Applications, 2025, 45(8): 2530-2536. |
| [12] | Chen LIANG, Yisen WANG, Qiang WEI, Jiang DU. Source code vulnerability detection method based on Transformer-GCN [J]. Journal of Computer Applications, 2025, 45(7): 2296-2303. |
| [13] | Haoyu LIU, Pengwei KONG, Yaoli WANG, Qing CHANG. Pedestrian detection algorithm based on multi-view information [J]. Journal of Computer Applications, 2025, 45(7): 2325-2332. |
| [14] | Xiaoqiang ZHAO, Yongyong LIU, Yongyong HUI, Kai LIU. Batch process quality prediction model using improved time-domain convolutional network with multi-head self-attention mechanism [J]. Journal of Computer Applications, 2025, 45(7): 2245-2252. |
| [15] | Huibin WANG, Zhan’ao HU, Jie HU, Yuanwei XU, Bo WEN. Time series forecasting model based on segmented attention mechanism [J]. Journal of Computer Applications, 2025, 45(7): 2262-2268. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||