


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (12): 3804-3812.DOI: 10.11772/j.issn.1001-9081.2024111704
• Artificial intelligence • Previous Articles Next Articles
Yonghong FAN1,2,3, Heming HUANG1,2,3( )
)
Received:2024-12-06
Revised:2025-03-08
Accepted:2025-03-18
Online:2025-03-21
Published:2025-12-10
Contact:
Heming HUANG
About author:FAN Yonghong, born in 1997, Ph. D. candidate. Her research interests include pattern recognition, intelligent systems, speech emotion recognition.
Supported by:
樊永红1,2,3, 黄鹤鸣1,2,3()
通讯作者:
黄鹤鸣
作者简介:樊永红(1997—),女,宁夏吴忠人,博士研究生,CCF会员,主要研究方向:模式识别、智能系统、语音情感识别基金资助:CLC Number:
Yonghong FAN, Heming HUANG. CnnPRL: progressive representation learning method for speech emotion recognition[J]. Journal of Computer Applications, 2025, 45(12): 3804-3812.
樊永红, 黄鹤鸣. 渐进式表征学习语音情感识别方法CnnPRL[J]. 《计算机应用》唯一官方网站, 2025, 45(12): 3804-3812.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024111704
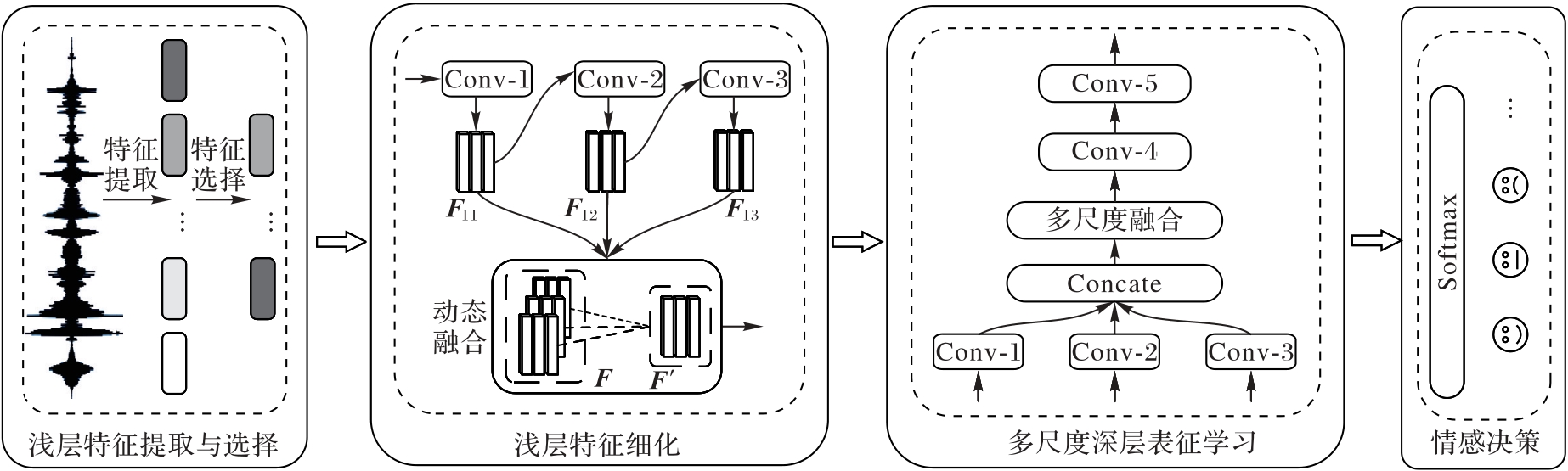
Fig. 1 Overall architecture of CnnPRL
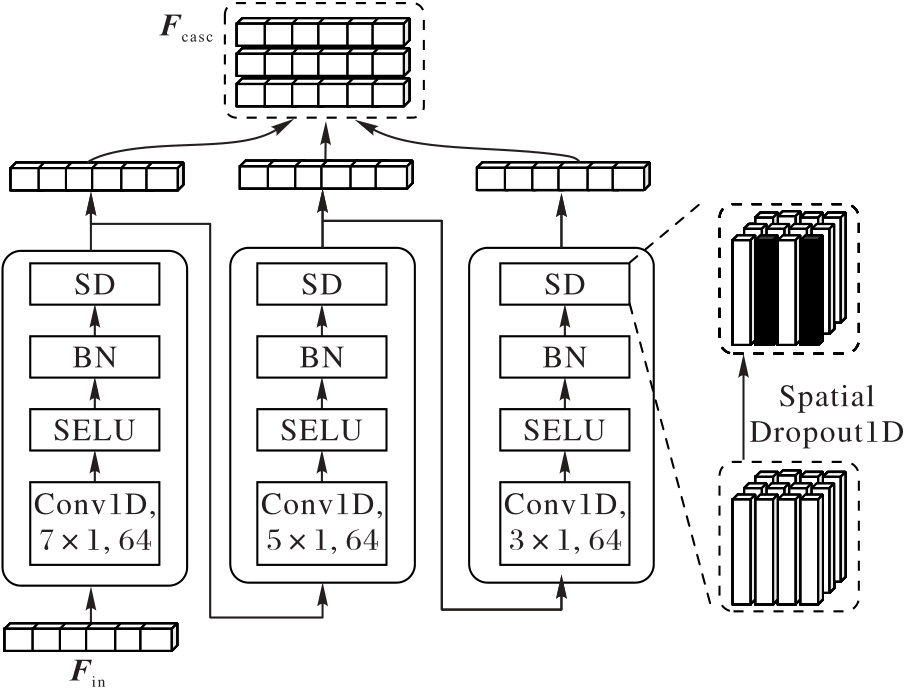
Fig.2 Structure of CasCNN module
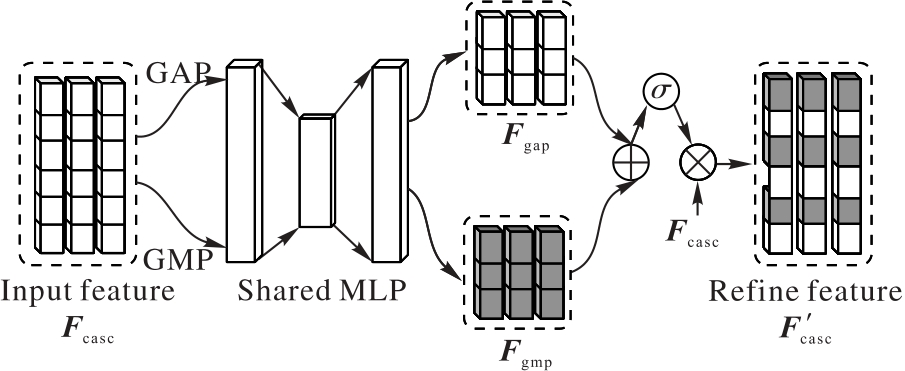
Fig. 3 Structure of dynamic fusion module
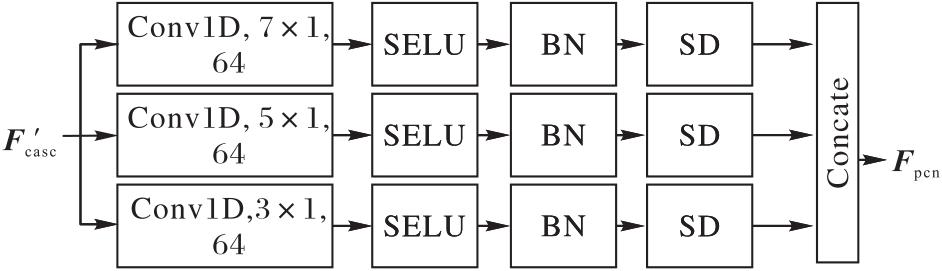
Fig. 4 Structure of PCN module
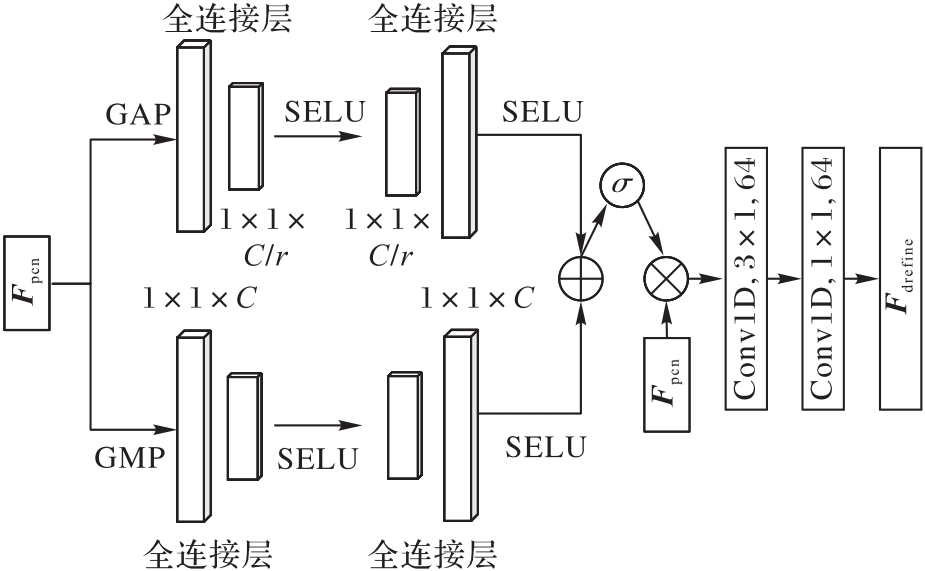
Fig. 5 Structure of multi-scale fusion module
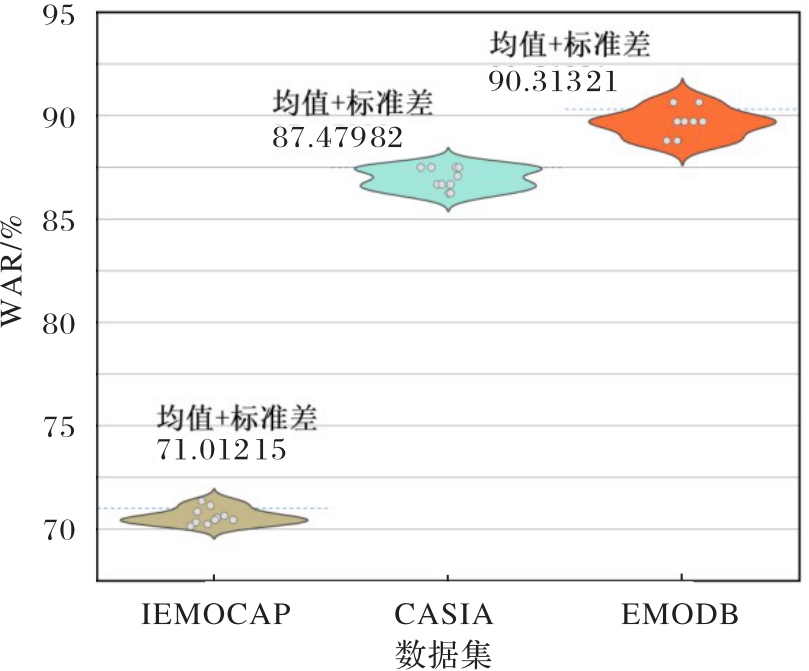
Fig. 6 Distribution of 10 experimental results of CnnPRL on different datasets
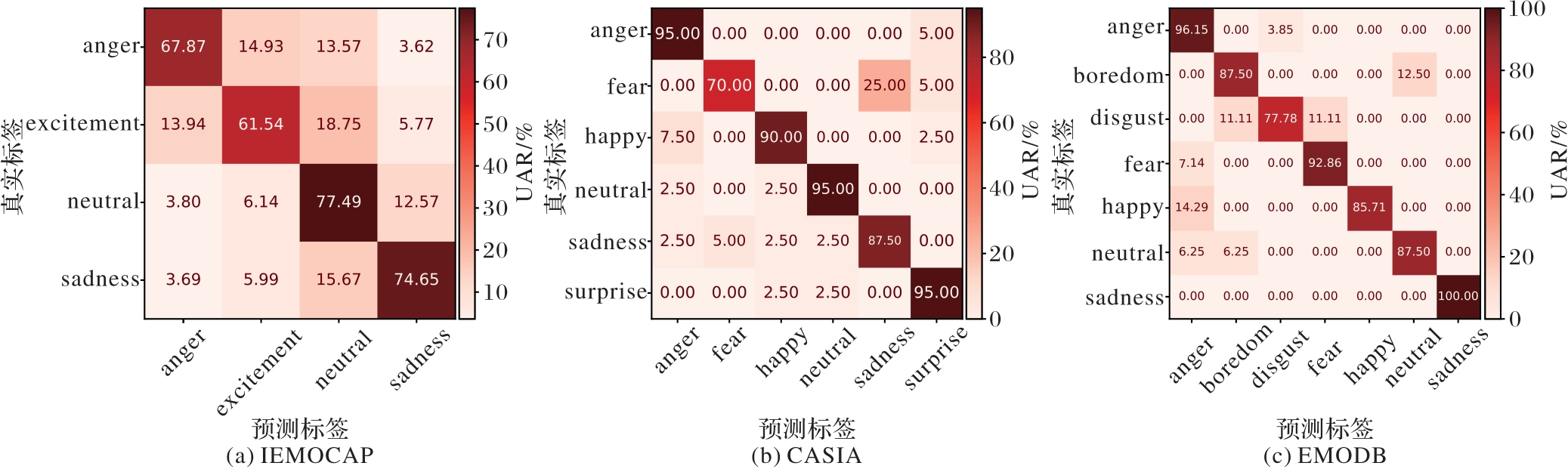
Fig. 7 Confusion matrices of optimal results of CnnPRL on different datasets

Fig. 8 T-SNE visualization of original distribution and classification effects by CnnPRL of data on three datasets
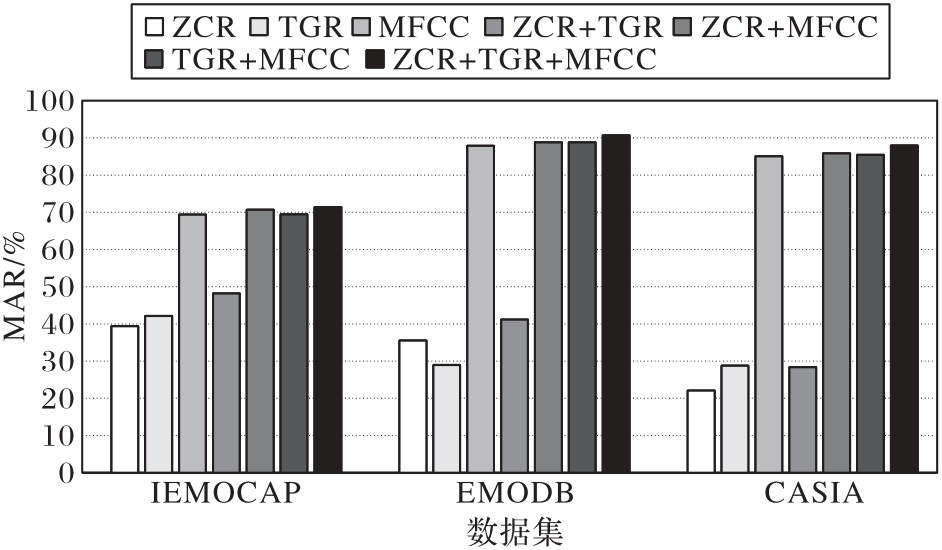
Fig. 9 WAR for different feature sets on multiple datasets
| SFR | MsDRL | SD | IEMOCAP | CASIA | EMODB | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| CasCNN | DF | PCN | MsF | WAR | UAR | WAR | UAR | WAR | UAR | |
| √ | √ | √ | 69.03 | 67.70 | 84.17 | 84.17 | 85.98 | 84.17 | ||
| √ | √ | √ | 68.83 | 67.95 | 85.00 | 85.00 | 86.92 | 85.94 | ||
| √ | √ | √ | 69.13 | 67.83 | 84.58 | 84.58 | 87.85 | 87.88 | ||
| √ | √ | √ | √ | 70.04 | 69.06 | 85.83 | 85.83 | 89.72 | 88.33 | |
| √ | √ | √ | √ | 70.14 | 69.62 | 86.67 | 86.67 | 88.79 | 87.73 | |
| √ | √ | √ | √ | 70.65 | 70.39 | 87.50 | 87.50 | 87.85 | 86.37 | |
| √ | √ | √ | √ | √ | 71.36 | 70.59 | 88.75 | 88.75 | 90.65 | 89.64 |
Tab. 1 Ablation experimental results of each submodule in CnnPRL
| SFR | MsDRL | SD | IEMOCAP | CASIA | EMODB | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| CasCNN | DF | PCN | MsF | WAR | UAR | WAR | UAR | WAR | UAR | |
| √ | √ | √ | 69.03 | 67.70 | 84.17 | 84.17 | 85.98 | 84.17 | ||
| √ | √ | √ | 68.83 | 67.95 | 85.00 | 85.00 | 86.92 | 85.94 | ||
| √ | √ | √ | 69.13 | 67.83 | 84.58 | 84.58 | 87.85 | 87.88 | ||
| √ | √ | √ | √ | 70.04 | 69.06 | 85.83 | 85.83 | 89.72 | 88.33 | |
| √ | √ | √ | √ | 70.14 | 69.62 | 86.67 | 86.67 | 88.79 | 87.73 | |
| √ | √ | √ | √ | 70.65 | 70.39 | 87.50 | 87.50 | 87.85 | 86.37 | |
| √ | √ | √ | √ | √ | 71.36 | 70.59 | 88.75 | 88.75 | 90.65 | 89.64 |
| 数据集 | 方法 | 模型结构 | WAR | UAR |
|---|---|---|---|---|
| IEMOCAP | MCMA[ | CNN | 57.58 | 58.07 |
| Dual-TBNet[ | Transformer+BiLSTM | 64.80 | 64.00 | |
| SFF-NEC[ | SVM | 65.78 | 64.27 | |
| SERC-GCN[ | Graph Convolution | 66.85 | — | |
| Foundation model[ | Transformer-based | 67.45 | — | |
| PTM-based SER[ | Speech Pre-trained Model | 68.85 | — | |
| TIM-Net[ | TCN | 69.00 | 68.29 | |
| BiGRU-Focal[ | CNN+BiGRU | 69.73 | 68.75 | |
| SpeechFormer++[ | Transformer-based | 70.50 | — | |
| DST[ | Transformer-based | 71.80 | — | |
| CnnPRL | CNN | 71.36 | 70.59 | |
| CASIA | MSCRNN-A[ | CNN+BiLSTM | 60.75 | 60.75 |
| AS-CANet[ | CNN | 67.08 | 67.08 | |
| CNN-LSTM[ | CNN+LSTM | 74.17 | 74.17 | |
| MA-CapsNet-DA[ | Capsule Network | 76.28 | — | |
| DT-SVM[ | SVM | 85.08 | 85.08 | |
| TLFMRF[ | Random Forest | 85.83 | 85.83 | |
| CnnPRL | CNN | 88.75 | 88.75 | |
| EMODB | MA-CapsNet-DA[ | Capsule Network | 77.89 | — |
| SFF-NEC[ | SVM | 82.84 | 81.45 | |
| ST-FCANet[ | CNN | 83.30 | 82.10 | |
| Dual-TBNet[ | Transformer+BiLSTM | 84.10 | — | |
| DT-SVM[ | SVM | 87.55 | — | |
| AMSNet[ | CNN+BiLSTM | 88.34 | 88.56 | |
| MSCRNN-A[ | CNN+BiLSTM | 88.41 | 87.95 | |
| TIM-Net[ | TCN | 89.19 | — | |
| CnnPRL | CNN | 90.65 | 89.64 | |
| MCDNet[ | CNN | 96.25 | — | |
| CnnPRL* | CNN | 99.07 | 99.27 |
Tab. 2 Comparison results of CnnPRL and other methods
| 数据集 | 方法 | 模型结构 | WAR | UAR |
|---|---|---|---|---|
| IEMOCAP | MCMA[ | CNN | 57.58 | 58.07 |
| Dual-TBNet[ | Transformer+BiLSTM | 64.80 | 64.00 | |
| SFF-NEC[ | SVM | 65.78 | 64.27 | |
| SERC-GCN[ | Graph Convolution | 66.85 | — | |
| Foundation model[ | Transformer-based | 67.45 | — | |
| PTM-based SER[ | Speech Pre-trained Model | 68.85 | — | |
| TIM-Net[ | TCN | 69.00 | 68.29 | |
| BiGRU-Focal[ | CNN+BiGRU | 69.73 | 68.75 | |
| SpeechFormer++[ | Transformer-based | 70.50 | — | |
| DST[ | Transformer-based | 71.80 | — | |
| CnnPRL | CNN | 71.36 | 70.59 | |
| CASIA | MSCRNN-A[ | CNN+BiLSTM | 60.75 | 60.75 |
| AS-CANet[ | CNN | 67.08 | 67.08 | |
| CNN-LSTM[ | CNN+LSTM | 74.17 | 74.17 | |
| MA-CapsNet-DA[ | Capsule Network | 76.28 | — | |
| DT-SVM[ | SVM | 85.08 | 85.08 | |
| TLFMRF[ | Random Forest | 85.83 | 85.83 | |
| CnnPRL | CNN | 88.75 | 88.75 | |
| EMODB | MA-CapsNet-DA[ | Capsule Network | 77.89 | — |
| SFF-NEC[ | SVM | 82.84 | 81.45 | |
| ST-FCANet[ | CNN | 83.30 | 82.10 | |
| Dual-TBNet[ | Transformer+BiLSTM | 84.10 | — | |
| DT-SVM[ | SVM | 87.55 | — | |
| AMSNet[ | CNN+BiLSTM | 88.34 | 88.56 | |
| MSCRNN-A[ | CNN+BiLSTM | 88.41 | 87.95 | |
| TIM-Net[ | TCN | 89.19 | — | |
| CnnPRL | CNN | 90.65 | 89.64 | |
| MCDNet[ | CNN | 96.25 | — | |
| CnnPRL* | CNN | 99.07 | 99.27 |
| 子模块 | CasCNN | DF | PCN | MsF | FLOPs/106 |
|---|---|---|---|---|---|
| 模块消融 | √ | 0.29 | |||
| √ | √ | 0.34 | |||
| √ | √ | √ | 1.08 | ||
| CnnPRL | √ | √ | √ | √ | 1.31 |
Tab. 3 Computational complexity analysis of CnnPRL
| 子模块 | CasCNN | DF | PCN | MsF | FLOPs/106 |
|---|---|---|---|---|---|
| 模块消融 | √ | 0.29 | |||
| √ | √ | 0.34 | |||
| √ | √ | √ | 1.08 | ||
| CnnPRL | √ | √ | √ | √ | 1.31 |
| 数据集 | 方法 | 愤怒 | 快乐 | 兴奋 | 中性 | 悲伤 | 无聊 | 厌恶 | 恐惧 | 惊讶 |
|---|---|---|---|---|---|---|---|---|---|---|
| IEMOCAP | MCMA[ | 65.10 | — | 53.18 | 57.85 | 56.18 | — | — | — | — |
| Dual-TBNet[ | 62.00 | — | 59.00 | 71.00 | 64.00 | — | — | — | — | |
| BiGRU-Focal[ | 66.54 | — | 55.31 | 71.85 | 60.23 | — | — | — | — | |
| CnnPRL | 67.87 | — | 61.54 | 77.49 | 74.65 | — | — | — | — | |
| CASIA | MSCRNN-A[ | 74.00 | 59.00 | — | 71.00 | 76.50 | — | — | 38.50 | 45.50 |
| DT-SVM[ | 90.00 | 88.50 | — | 92.50 | 78.00 | — | — | 74.50 | 87.00 | |
| TLFMRF[ | 93.00 | 77.00 | — | 94.00 | 88.00 | — | — | 67.00 | 98.00 | |
| CnnPRL | 95.00 | 90.00 | — | 95.00 | 87.50 | — | — | 70.00 | 95.00 | |
| EMODB | Dual-TBNet[ | 75.00 | 82.00 | — | 75.00 | 100.00 | 88.00 | 100.00 | 90.00 | — |
| DT-SVM[ | 91.80 | 85.00 | — | 94.50 | 83.00 | 89.85 | 80.45 | 88.30 | — | |
| AMSNet[ | 92.00 | 91.00 | — | 85.00 | 92.00 | 85.00 | — | 90.00 | — | |
| MSCRNN-A[ | 97.00 | 72.87 | — | 87.55 | 91.35 | 92.57 | 86.87 | 81.29 | — | |
| CnnPRL | 96.15 | 85.71 | — | 87.50 | 100.00 | 87.50 | 77.78 | 92.86 | — | |
| MCDNet[ | 97.37 | 94.74 | — | 100.00 | 100.00 | 100.00 | 92.86 | 95.24 | — | |
| CnnPRL* | 98.04 | 100.00 | — | 96.88 | 100.00 | 100.00 | 100.00 | 100.00 | — |
Tab. 4 UAR results comparison of proposed CnnPRL and other methods on each emotion category
| 数据集 | 方法 | 愤怒 | 快乐 | 兴奋 | 中性 | 悲伤 | 无聊 | 厌恶 | 恐惧 | 惊讶 |
|---|---|---|---|---|---|---|---|---|---|---|
| IEMOCAP | MCMA[ | 65.10 | — | 53.18 | 57.85 | 56.18 | — | — | — | — |
| Dual-TBNet[ | 62.00 | — | 59.00 | 71.00 | 64.00 | — | — | — | — | |
| BiGRU-Focal[ | 66.54 | — | 55.31 | 71.85 | 60.23 | — | — | — | — | |
| CnnPRL | 67.87 | — | 61.54 | 77.49 | 74.65 | — | — | — | — | |
| CASIA | MSCRNN-A[ | 74.00 | 59.00 | — | 71.00 | 76.50 | — | — | 38.50 | 45.50 |
| DT-SVM[ | 90.00 | 88.50 | — | 92.50 | 78.00 | — | — | 74.50 | 87.00 | |
| TLFMRF[ | 93.00 | 77.00 | — | 94.00 | 88.00 | — | — | 67.00 | 98.00 | |
| CnnPRL | 95.00 | 90.00 | — | 95.00 | 87.50 | — | — | 70.00 | 95.00 | |
| EMODB | Dual-TBNet[ | 75.00 | 82.00 | — | 75.00 | 100.00 | 88.00 | 100.00 | 90.00 | — |
| DT-SVM[ | 91.80 | 85.00 | — | 94.50 | 83.00 | 89.85 | 80.45 | 88.30 | — | |
| AMSNet[ | 92.00 | 91.00 | — | 85.00 | 92.00 | 85.00 | — | 90.00 | — | |
| MSCRNN-A[ | 97.00 | 72.87 | — | 87.55 | 91.35 | 92.57 | 86.87 | 81.29 | — | |
| CnnPRL | 96.15 | 85.71 | — | 87.50 | 100.00 | 87.50 | 77.78 | 92.86 | — | |
| MCDNet[ | 97.37 | 94.74 | — | 100.00 | 100.00 | 100.00 | 92.86 | 95.24 | — | |
| CnnPRL* | 98.04 | 100.00 | — | 96.88 | 100.00 | 100.00 | 100.00 | 100.00 | — |
| [1] | 陶建华,陈俊杰,李永伟. 语音情感识别综述[J]. 信号处理, 2023, 39(4): 571-587. |
| TAO J H, CHEN J J, LI Y W. Review on speech emotion recognition[J]. Journal of Signal Processing, 2023, 39(4): 571-587. | |
| [2] | BLASZKE M, KOSZEWSKI D. Determination of low-level audio descriptors of a musical instrument sound using neural network[C]// Proceedings of the 2020 Conference on Signal Processing: Algorithms, Architectures, Arrangements and Applications. Piscataway: IEEE, 2020: 138-141. |
| [3] | WANG X, DU P, CHEN D, et al. Change detection based on low-level to high-level features integration with limited samples[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2020, 13: 6260-6276. |
| [4] | HAN K, YU D, TASHEV I. Speech emotion recognition using deep neural network and extreme learning machine[C]// Proceedings of the INTERSPEECH 2014. [S.l.]: International Speech Communication Association, 2014: 223-227. |
| [5] | ZHOU B, RICHARDSON K, NING Q, et al. Temporal reasoning on implicit events from distant supervision[C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2021: 1361-1371. |
| [6] | ZHU Z, DAI W, HU Y, et al. Speech emotion recognition model based on Bi-GRU and focal loss [J]. Pattern Recognition Letters, 2020, 140: 358-365. |
| [7] | RAJAMANI S T, RAJAMANI K T, MALLOL-RAGOLTA A, et al. A novel attention-based gated recurrent unit and its efficacy in speech emotion recognition[C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 6294-6298. |
| [8] | LIU M, JOSEPH RAJ A N, RAJANGAM V, et al. Multiscale-multichannel feature extraction and classification through one-dimensional convolutional neural network for speech emotion recognition [J]. Speech Communication, 2024, 156: No.103010. |
| [9] | MIAO X, LI Y, WEN M, et al. Fusing features of speech for depression classification based on higher-order spectral analysis[J]. Speech Communication, 2022, 143: 46-56. |
| [10] | GUO L, WANG L, DANG J, et al. Learning affective representations based on magnitude and dynamic relative phase information for speech emotion recognition[J]. Speech Communication, 2022, 136: 118-127. |
| [11] | ZHAO Z P, LI Q F, ZHANG Z X, et al. Combining a parallel 2D CNN with a self-attention dilated residual network for CTC-based discrete speech emotion recognition [J]. Neural Networks, 2021, 141: 52-60. |
| [12] | LIU A T, LI S W, LEE H Y. TERA: self-supervised learning of Transformer encoder representation for speech[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 2351-2366. |
| [13] | LIU Z, KANG X, REN F. Dual-TBNet: improving the robustness of speech features via dual-Transformer-BiLSTM for speech emotion recognition [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023, 31: 2193-2203. |
| [14] | 张钹,朱军,苏航.迈向第三代人工智能[J].中国科学:信息科学,2020, 50(9): 1281-1302. |
| ZHANG B, ZHU J, SU H. Toward the third generation of artificial intelligence[J]. SCIENTIA SINICA Informationis, 2020, 50(9): 1281-1302. | |
| [15] | YE J X, WEN X C, WANG X Z, et al. GM-TCNet: gated multi-scale temporal convolutional network using emotion causality for speech emotion recognition[J]. Speech Communication, 2022, 145: 21-35. |
| [16] | ABADI M, BARHAM P, CHEN J, et al. TensorFlow: a system for large-scale machine learning[C]// Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation. Berkeley: USENIX Association, 2016: 265-283. |
| [17] | KINGMA D P, BA J L. Adam: a method for stochastic optimization[EB/OL]. [2024-11-03].. |
| [18] | CHEN W, XING X, XU X, et al. SpeechFormer++: a hierarchical efficient framework for paralinguistic speech processing[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023, 31: 775-788. |
| [19] | LIU Y, SUN H, GUAN W, et al. A discriminative feature representation method based on cascaded attention network with adversarial strategy for speech emotion recognition[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023, 31: 1063-1074. |
| [20] | THIRUMURU R, GURUGUBELLI K, VUPPALA A K. Novel feature representation using single frequency filtering and nonlinear energy operator for speech emotion recognition[J]. Digital Signal Processing, 2023, 120: No.103293. |
| [21] | CHANDOLA D, ALTARAWNEH E, JENKIN M, et al. SERC-GCN: speech emotion recognition in conversation using graph convolutional networks[C]// Proceedings of the 2024 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2024: 76-80. |
| [22] | YE J, WEN X C, WEI Y, et al. Temporal modeling matters: a novel temporal emotional modeling approach for speech emotion recognition[C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| [23] | TAO H, GENG L, SHAN S, et al. Multi-stream convolution recurrent neural networks based on attention mechanism fusion for speech emotion recognition[J]. Entropy, 2022, 24(8): No.1025. |
| [24] | HE J, REN L. Speech emotion recognition using XGBoost and CNN BLSTM with attention[C]// Proceedings of the 2021 IEEE SmartWorld, Ubiquitous Intelligence and Computing, Advanced and Trusted Computing, Scalable Computing and Communications, Internet of People and Smart City Innovation. Piscataway: IEEE, 2021: 154-159. |
| [25] | SUN L, FU S, WANG F. Decision tree SVM model with Fisher feature selection for speech emotion recognition[J]. EURASIP Journal on Audio, Speech, and Music Processing, 2019, 2019: No.2. |
| [26] | CHEN L, SU W, FENG Y, et al. Two-layer fuzzy multiple random forest for speech emotion recognition in human-robot interaction [J]. Information Sciences, 2020, 509: 150-163. |
| [27] | LI S, XING X, FAN W, et al. Spatiotemporal and frequential cascaded attention networks for speech emotion recognition[J]. Neurocomputing, 2021, 448: 238-248. |
| [28] | CHEN Z, LI J, LIU H, et al. Learning multi-scale features for speech emotion recognition with connection attention mechanism[J]. Expert Systems with Applications, 2023, 214: No.118943. |
| [29] | FENG T, NARAYANAN S. Foundation model assisted automatic speech emotion recognition: transcribing, annotating, and augmenting[C]// Proceedings of the 2024 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2024: 12116-12120. |
| [30] | MA Z, WU W, ZHENG Z, et al. Leveraging speech PTM, text LLM, and emotional TTS for speech emotion recognition[C]// Proceedings of the 2024 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2024: 11146-11150. |
| [31] | ZHANG H, HUANG H, HAN H. MA-CapsNet-DA: speech emotion recognition based on MA-CapsNet using data augmentation[J]. Expert Systems with Applications, 2024, 244: No.122939. |
| [32] | CHEN W, XING X, XU X, et al. DST: deformable speech Transformer for emotion recognition[C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2024: 1-5. |
| [1] | Yanan LI, Mengyang GUO, Guojun DENG, Yunfeng CHEN, Jianji REN, Yongliang YUAN. Method for life prediction of parallel branching engine based on multi-modal fusion features [J]. Journal of Computer Applications, 2026, 46(1): 305-313. |
| [2] | Hongjun ZHANG, Gaojun PAN, Hao YE, Yubin LU, Yiheng MIAO. Multi-source heterogeneous data analysis method combining deep learning and tensor decomposition [J]. Journal of Computer Applications, 2025, 45(9): 2838-2847. |
| [3] | Chao SHI, Yuxin ZHOU, Qian FU, Wanyu TANG, Ling HE, Yuanyuan LI. Action recognition algorithm for ADHD patients using skeleton and 3D heatmap [J]. Journal of Computer Applications, 2025, 45(9): 3036-3044. |
| [4] | Peng PENG, Ziting CAI, Wenling LIU, Caihua CHEN, Wei ZENG, Baolai HUANG. Speech emotion recognition method based on hybrid Siamese network with CNN and bidirectional GRU [J]. Journal of Computer Applications, 2025, 45(8): 2515-2521. |
| [5] | Jinhao LIN, Chuan LUO, Tianrui LI, Hongmei CHEN. Thoracic disease classification method based on cross-scale attention network [J]. Journal of Computer Applications, 2025, 45(8): 2712-2719. |
| [6] | Yongpeng TAO, Shiqi BAI, Zhengwen ZHOU. Neural architecture search for multi-tissue segmentation using convolutional and transformer-based networks in glioma segmentation [J]. Journal of Computer Applications, 2025, 45(7): 2378-2386. |
| [7] | Yingjun ZHANG, Weiwei YAN, Binhong XIE, Rui ZHANG, Wangdong LU. Gradient-discriminative and feature norm-driven open-world object detection [J]. Journal of Computer Applications, 2025, 45(7): 2203-2210. |
| [8] | Yingtao CHEN, Kangkang FANG, Jin’ao ZHANG, Haoran LIANG, Huanbin GUO, Zhaowen QIU. Segmentation network of coronary artery structure from CT angiography images based on multi-scale spatial features [J]. Journal of Computer Applications, 2025, 45(6): 2007-2015. |
| [9] | Dan WANG, Wenhao ZHANG, Lijuan PENG. Channel estimation of reconfigurable intelligent surface assisted communication system based on deep learning [J]. Journal of Computer Applications, 2025, 45(5): 1613-1618. |
| [10] | Junyan ZHANG, Yiming ZHAO, Bing LIN, Yunping WU. Chinese image captioning method based on multi-level visual and dynamic text-image interaction [J]. Journal of Computer Applications, 2025, 45(5): 1520-1527. |
| [11] | Baohua YUAN, Jialu CHEN, Huan WANG. Medical image segmentation network integrating multi-scale semantics and parallel double-branch [J]. Journal of Computer Applications, 2025, 45(3): 988-995. |
| [12] | Dixin WANG, Jiahao WANG, Min LI, Hao CHEN, Guangyao HU, Yu GONG. Abnormal attack detection for underwater acoustic communication network [J]. Journal of Computer Applications, 2025, 45(2): 526-533. |
| [13] | Jianhua REN, Jiahui CAO, Di JIA. Hand pose estimation based on mask prompts and attention [J]. Journal of Computer Applications, 2025, 45(12): 4012-4020. |
| [14] | Xinran XU, Shaobing ZHANG, Miao CHENG, Yang ZHANG, Shang ZENG. Bearings fault diagnosis method based on multi-pathed hierarchical mixture-of-experts model [J]. Journal of Computer Applications, 2025, 45(1): 59-68. |
| [15] | Yun LI, Fuyou WANG, Peiguang JING, Su WANG, Ao XIAO. Uncertainty-based frame associated short video event detection method [J]. Journal of Computer Applications, 2024, 44(9): 2903-2910. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||