


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (7): 2277-2287.DOI: 10.11772/j.issn.1001-9081.2025060786
• Multimedia computing and computer simulation • Previous Articles
Yue MA1,2,3, Huicheng LAI1,2,3( ), Di JIANG1,2,3, Liejun WANG1,2,3
), Di JIANG1,2,3, Liejun WANG1,2,3
Received:2025-07-16
Revised:2025-09-16
Accepted:2025-09-25
Online:2025-10-13
Published:2026-07-10
Contact:
Huicheng LAI
About author:MA Yue, born in 1998, M. S. candidate. His research interests include computer vision, deep learning.Supported by:
马岳1,2,3, 赖惠成1,2,3(), 姜迪1,2,3, 汪烈军1,2,3
通讯作者:
赖惠成
作者简介:马岳(1998—),男,新疆乌鲁木齐人,硕士研究生,主要研究方向:计算机视觉、深度学习基金资助:CLC Number:
Yue MA, Huicheng LAI, Di JIANG, Liejun WANG. Zero-shot human-object interaction detection method via multimodal collaborative prompt optimization[J]. Journal of Computer Applications, 2026, 46(7): 2277-2287.
马岳, 赖惠成, 姜迪, 汪烈军. 多模态协同提示优化下的零样本人物交互检测方法[J]. 《计算机应用》唯一官方网站, 2026, 46(7): 2277-2287.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025060786
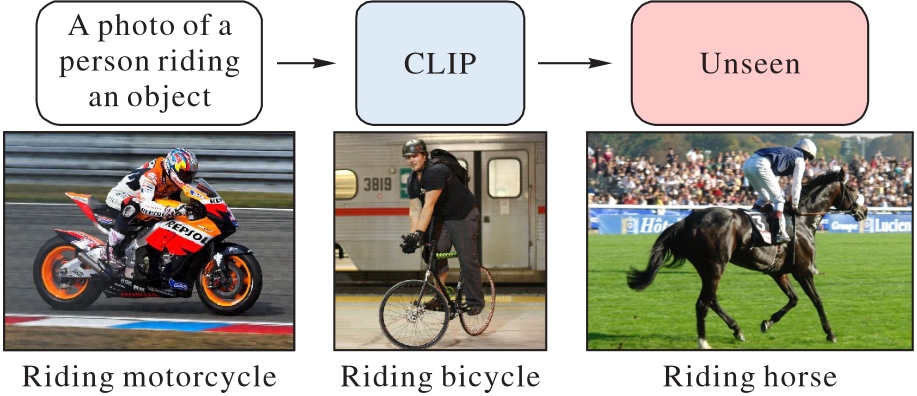
Fig. 1 Schematic diagram of zero-shot human-object interaction detection
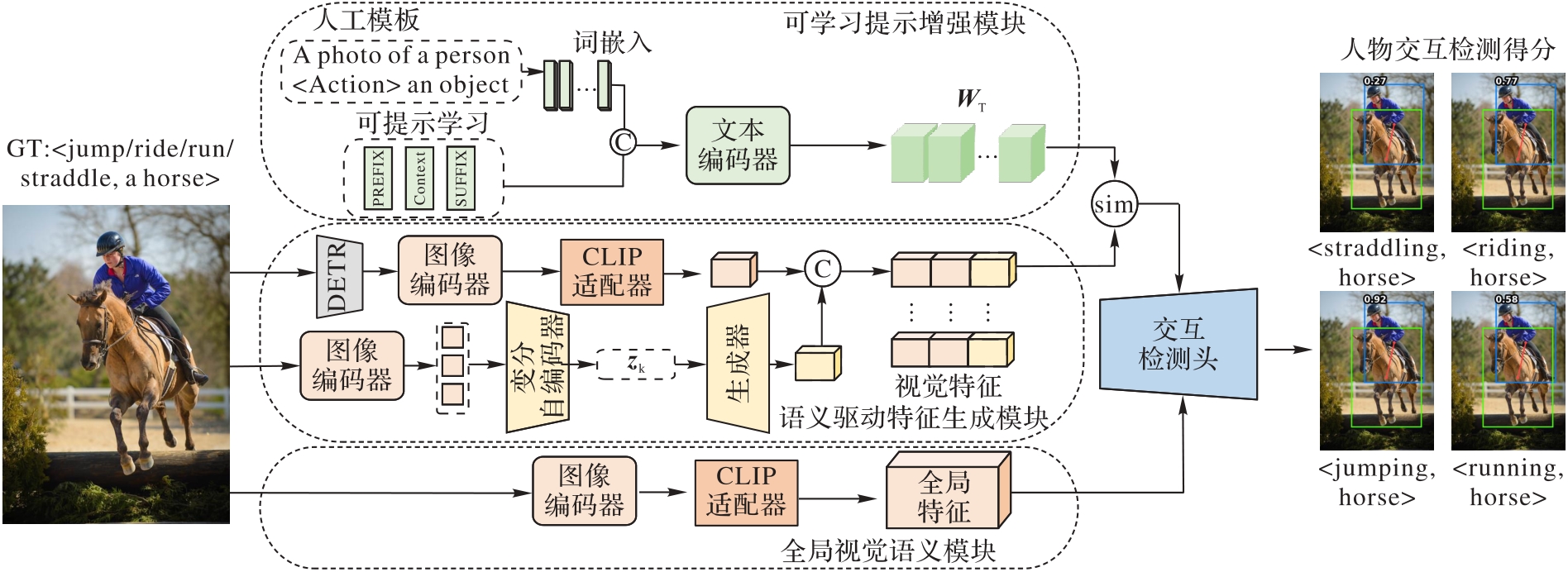
Fig. 2 Overall architecture of MCPNet
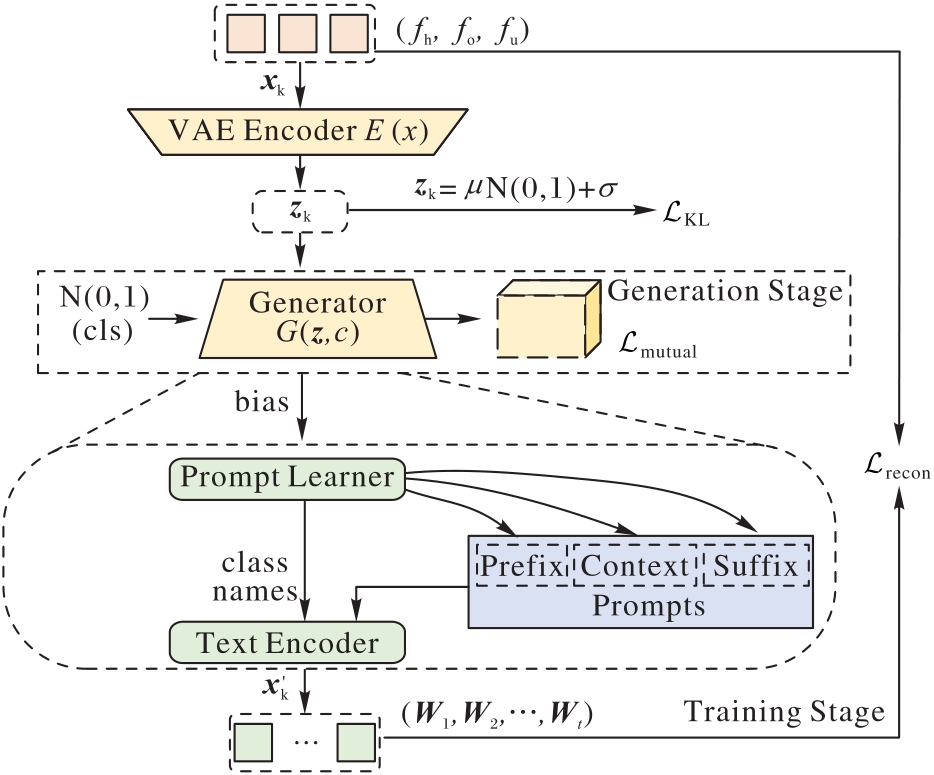
Fig. 3 Semantic-guided feature generation module
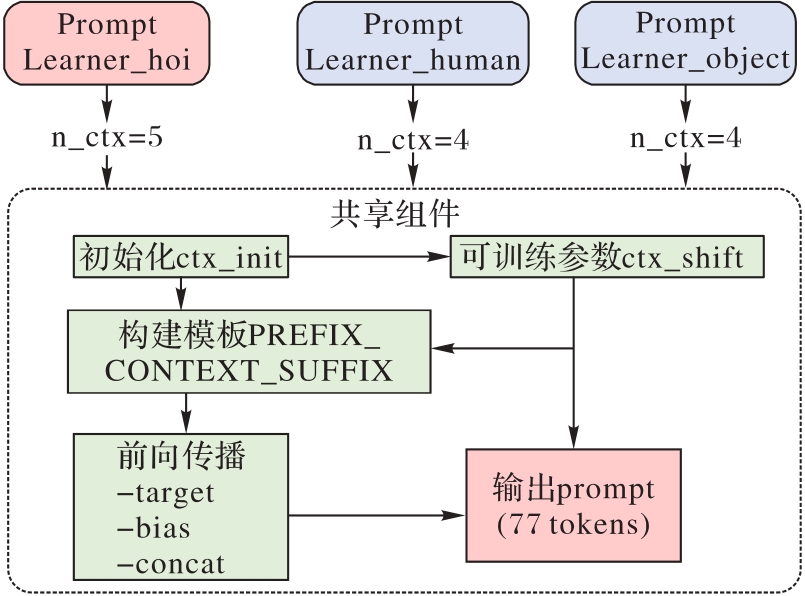
Fig. 4 Learnable prompt
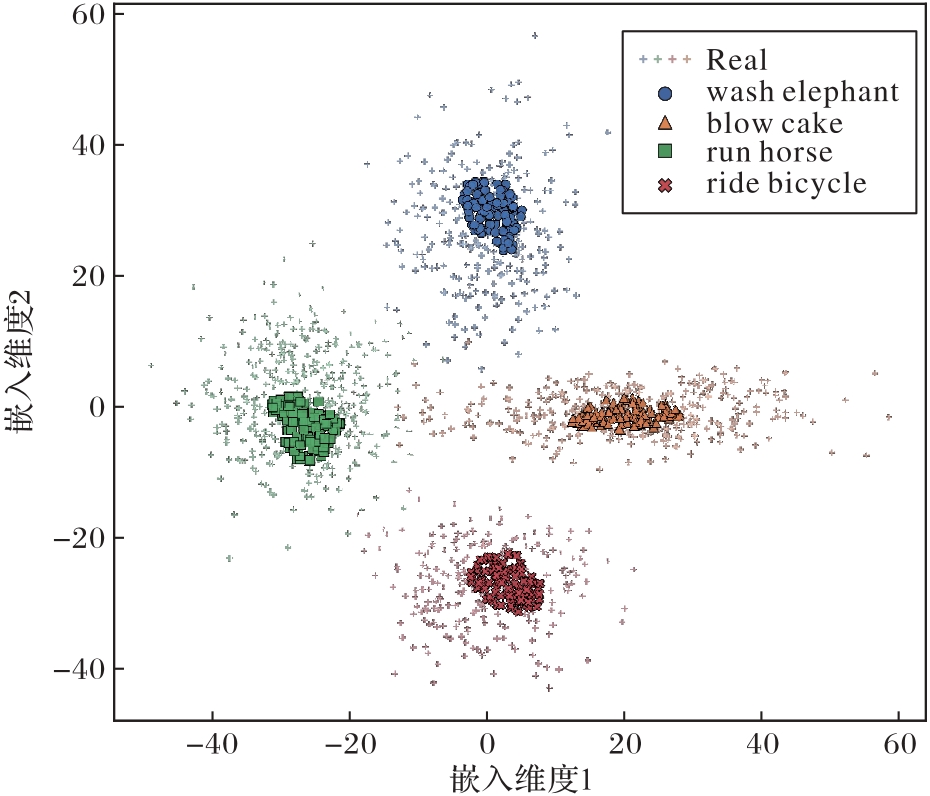
Fig. 5 Feature distribution alignment of unseen HOI categories (t-SNE)
| 方法 | 零样本设置 | TP/106 | AP/106 | 不同类别的mAP/% | ||
|---|---|---|---|---|---|---|
| Full | Seen | Unseen | ||||
| ConsNet[ | UC | — | — | 19.81 | 20.51 | 16.99 |
| GEN-VLKT[ | UC | — | — | 25.23 | 27.16 | 20.64 |
| EoID[ | UC | — | — | 28.91 | 30.39 | 23.01 |
| HOICLIP[ | UC | — | — | 29.93 | 31.65 | 23.15 |
| Linear Probe CLIP[ | UC | — | — | 23.36 | 23.12 | 24.28 |
| CLIP4HOI[ | UC | 71.2 | 262.4 | 33.25 | 27.71 | |
| CMMP[ | UC | 2.3 | 193.4 | 31.84 | 32.39 | |
| 本文方法 | UC | 2.1 | 168.1 | 32.40 | 30.09 | |
| GEN-VLKT[ | RF-UC | — | — | 30.56 | 32.91 | 21.36 |
| EoID[ | RF-UC | — | — | 29.52 | 31.39 | 22.04 |
| HOICLIP[ | RF-UC | — | — | 32.99 | 34.85 | 25.53 |
| LOGICHOI[ | RF-UC | — | — | 33.17 | 25.97 | |
| ADA-CM[ | RF-UC | — | — | 33.01 | 34.35 | 27.63 |
| CLIP4HOI[ | RF-UC | 71.2 | 262.4 | 34.08 | 35.48 | 28.47 |
| UniHOI[ | RF-UC | — | — | 32.27 | 33.16 | 28.68 |
| Linear Probe CLIP[ | RF-UC | — | — | 23.36 | 22.00 | 28.79 |
| EZ-HOI[ | RF-UC | — | — | 33.13 | 34.15 | 29.02 |
| CMMP[ | RF-UC | 2.3 | 193.4 | 32.18 | 32.87 | |
| 本文方法 | RF-UC | 2.1 | 168.1 | 33.73 | 31.30 | |
| GEN-VLKT[ | NF-UC | — | — | 23.71 | 23.38 | 25.05 |
| HOICLIP[ | NF-UC | — | — | 27.75 | 28.10 | 26.39 |
| EoID[ | NF-UC | — | — | 26.69 | 26.66 | 26.77 |
| LOGICHOI[ | NF-UC | — | — | 27.95 | 27.86 | 26.84 |
| UniHOI[ | NF-UC | — | — | 32.63 | 28.45 | |
| Linear Probe CLIP[ | NF-UC | — | — | 22.06 | 28.52 | |
| CLIP4HOI[ | NF-UC | 71.2 | 262.4 | 28.90 | 28.26 | 31.44 |
| CMMP[ | NF-UC | 2.3 | 193.4 | 30.18 | 29.71 | 32.09 |
| ADA-CM[ | NF-UC | — | — | 31.39 | 31.13 | 32.41 |
| EZ-HOI[ | NF-UC | — | — | 31.17 | 30.55 | |
| 本文方法 | NF-UC | 2.2 | 168.1 | 31.95 | 34.03 | |
| GEN-VLKT[ | UO | 42.1 | — | 25.63 | 28.92 | 10.51 |
| LOGICHOI[ | UO | — | — | 28.23 | 30.42 | 15.67 |
| HOICLIP[ | UO | — | — | 28.53 | 30.99 | 16.20 |
| UniHOI[ | UO | — | — | 31.56 | 34.76 | 19.72 |
| Linear Probe CLIP[ | UO | — | — | 23.36 | 22.29 | 28.66 |
| EZ-HOI[ | UO | 6.9 | — | 27.90 | 27.16 | 31.63 |
| CLIP4HOI[ | UO | 71.2 | 262.4 | 31.79 | ||
| CMMP[ | UO | 2.3 | 193.4 | 31.59 | 31.15 | |
| 本文方法 | UO | 2.4 | 168.3 | 32.88 | 32.50 | 34.77 |
| GEN-VLKT[ | UV | 42.1 | — | 28.74 | 30.23 | 20.96 |
| EoID[ | UV | 41.5 | — | 22.71 | ||
| 本文方法 | UV | 1.9 | 167.8 | 31.79 | 33.46 | |
Tab. 1 Detection results of different methods under various zero-shot settings on HICO-DET dataset
| 方法 | 零样本设置 | TP/106 | AP/106 | 不同类别的mAP/% | ||
|---|---|---|---|---|---|---|
| Full | Seen | Unseen | ||||
| ConsNet[ | UC | — | — | 19.81 | 20.51 | 16.99 |
| GEN-VLKT[ | UC | — | — | 25.23 | 27.16 | 20.64 |
| EoID[ | UC | — | — | 28.91 | 30.39 | 23.01 |
| HOICLIP[ | UC | — | — | 29.93 | 31.65 | 23.15 |
| Linear Probe CLIP[ | UC | — | — | 23.36 | 23.12 | 24.28 |
| CLIP4HOI[ | UC | 71.2 | 262.4 | 33.25 | 27.71 | |
| CMMP[ | UC | 2.3 | 193.4 | 31.84 | 32.39 | |
| 本文方法 | UC | 2.1 | 168.1 | 32.40 | 30.09 | |
| GEN-VLKT[ | RF-UC | — | — | 30.56 | 32.91 | 21.36 |
| EoID[ | RF-UC | — | — | 29.52 | 31.39 | 22.04 |
| HOICLIP[ | RF-UC | — | — | 32.99 | 34.85 | 25.53 |
| LOGICHOI[ | RF-UC | — | — | 33.17 | 25.97 | |
| ADA-CM[ | RF-UC | — | — | 33.01 | 34.35 | 27.63 |
| CLIP4HOI[ | RF-UC | 71.2 | 262.4 | 34.08 | 35.48 | 28.47 |
| UniHOI[ | RF-UC | — | — | 32.27 | 33.16 | 28.68 |
| Linear Probe CLIP[ | RF-UC | — | — | 23.36 | 22.00 | 28.79 |
| EZ-HOI[ | RF-UC | — | — | 33.13 | 34.15 | 29.02 |
| CMMP[ | RF-UC | 2.3 | 193.4 | 32.18 | 32.87 | |
| 本文方法 | RF-UC | 2.1 | 168.1 | 33.73 | 31.30 | |
| GEN-VLKT[ | NF-UC | — | — | 23.71 | 23.38 | 25.05 |
| HOICLIP[ | NF-UC | — | — | 27.75 | 28.10 | 26.39 |
| EoID[ | NF-UC | — | — | 26.69 | 26.66 | 26.77 |
| LOGICHOI[ | NF-UC | — | — | 27.95 | 27.86 | 26.84 |
| UniHOI[ | NF-UC | — | — | 32.63 | 28.45 | |
| Linear Probe CLIP[ | NF-UC | — | — | 22.06 | 28.52 | |
| CLIP4HOI[ | NF-UC | 71.2 | 262.4 | 28.90 | 28.26 | 31.44 |
| CMMP[ | NF-UC | 2.3 | 193.4 | 30.18 | 29.71 | 32.09 |
| ADA-CM[ | NF-UC | — | — | 31.39 | 31.13 | 32.41 |
| EZ-HOI[ | NF-UC | — | — | 31.17 | 30.55 | |
| 本文方法 | NF-UC | 2.2 | 168.1 | 31.95 | 34.03 | |
| GEN-VLKT[ | UO | 42.1 | — | 25.63 | 28.92 | 10.51 |
| LOGICHOI[ | UO | — | — | 28.23 | 30.42 | 15.67 |
| HOICLIP[ | UO | — | — | 28.53 | 30.99 | 16.20 |
| UniHOI[ | UO | — | — | 31.56 | 34.76 | 19.72 |
| Linear Probe CLIP[ | UO | — | — | 23.36 | 22.29 | 28.66 |
| EZ-HOI[ | UO | 6.9 | — | 27.90 | 27.16 | 31.63 |
| CLIP4HOI[ | UO | 71.2 | 262.4 | 31.79 | ||
| CMMP[ | UO | 2.3 | 193.4 | 31.59 | 31.15 | |
| 本文方法 | UO | 2.4 | 168.3 | 32.88 | 32.50 | 34.77 |
| GEN-VLKT[ | UV | 42.1 | — | 28.74 | 30.23 | 20.96 |
| EoID[ | UV | 41.5 | — | 22.71 | ||
| 本文方法 | UV | 1.9 | 167.8 | 31.79 | 33.46 | |
| 方法 | 主干网络 | 不同类别的mAP/% | ||
|---|---|---|---|---|
| Full | Rare | Non-rare | ||
| IDN[ | ResNet-50 | 23.36 | 22.47 | 23.63 |
| HOTR[ | ResNet-50 | 25.10 | 17.34 | 27.42 |
| ATL[ | ResNet-50 | 28.53 | 21.64 | 30.59 |
| AS-Net[ | ResNet-50 | 28.87 | 24.25 | 30.25 |
| QPIC[ | ResNet-50 | 29.07 | 21.85 | 31.23 |
| STIP[ | ResNet-50 | 30.56 | 28.15 | 31.28 |
| SCG[ | ResNet-50 | 31.33 | 24.72 | 33.31 |
| UPT[ | ResNet-50 | 31.66 | 25.94 | 33.36 |
| CDN[ | ResNet-50 | 31.78 | 27.55 | 33.05 |
| GEN-VLKT[ | ResNet-50 | 33.75 | 29.25 | 35.10 |
| PViC[ | ResNet-50 | 32.14 | ||
| HOICLIP[ | ResNet-50 | 31.12 | 35.74 | |
| CLIP4HOI[ | ResNet-50 | 35.33 | 35.74 | |
| 本文方法 | ResNet-50 | 34.50 | 34.12 | 34.61 |
Tab. 2 Fully-supervised HOI detection results on HICO-DET dataset
| 方法 | 主干网络 | 不同类别的mAP/% | ||
|---|---|---|---|---|
| Full | Rare | Non-rare | ||
| IDN[ | ResNet-50 | 23.36 | 22.47 | 23.63 |
| HOTR[ | ResNet-50 | 25.10 | 17.34 | 27.42 |
| ATL[ | ResNet-50 | 28.53 | 21.64 | 30.59 |
| AS-Net[ | ResNet-50 | 28.87 | 24.25 | 30.25 |
| QPIC[ | ResNet-50 | 29.07 | 21.85 | 31.23 |
| STIP[ | ResNet-50 | 30.56 | 28.15 | 31.28 |
| SCG[ | ResNet-50 | 31.33 | 24.72 | 33.31 |
| UPT[ | ResNet-50 | 31.66 | 25.94 | 33.36 |
| CDN[ | ResNet-50 | 31.78 | 27.55 | 33.05 |
| GEN-VLKT[ | ResNet-50 | 33.75 | 29.25 | 35.10 |
| PViC[ | ResNet-50 | 32.14 | ||
| HOICLIP[ | ResNet-50 | 31.12 | 35.74 | |
| CLIP4HOI[ | ResNet-50 | 35.33 | 35.74 | |
| 本文方法 | ResNet-50 | 34.50 | 34.12 | 34.61 |
| Global | SFG | LPE | Loss | 不同类别的mAP/% | ||
|---|---|---|---|---|---|---|
| Full | Seen | Unseen | ||||
| × | × | × | × | 31.75 | 31.59 | 32.39 |
| √ | × | × | × | 29.35 | 28.61 | 32.31 |
| × | × | × | √ | 31.82 | 31.63 | 32.61 |
| × | × | √ | × | 31.92 | 31.70 | 32.79 |
| × | √ | × | × | 31.97 | 31.71 | 33.02 |
| √ | √ | × | × | 32.08 | 31.69 | 33.65 |
| √ | √ | √ | × | 31.82 | 31.29 | 33.90 |
| × | √ | √ | √ | 31.87 | 31.63 | 32.85 |
| √ | × | √ | √ | 32.19 | 32.05 | 32.77 |
| √ | √ | × | √ | 31.78 | 31.29 | 33.77 |
| √ | √ | √ | √ | 31.95 | 31.44 | 34.03 |
Tab. 3 Ablation analysis of network modules
| Global | SFG | LPE | Loss | 不同类别的mAP/% | ||
|---|---|---|---|---|---|---|
| Full | Seen | Unseen | ||||
| × | × | × | × | 31.75 | 31.59 | 32.39 |
| √ | × | × | × | 29.35 | 28.61 | 32.31 |
| × | × | × | √ | 31.82 | 31.63 | 32.61 |
| × | × | √ | × | 31.92 | 31.70 | 32.79 |
| × | √ | × | × | 31.97 | 31.71 | 33.02 |
| √ | √ | × | × | 32.08 | 31.69 | 33.65 |
| √ | √ | √ | × | 31.82 | 31.29 | 33.90 |
| × | √ | √ | √ | 31.87 | 31.63 | 32.85 |
| √ | × | √ | √ | 32.19 | 32.05 | 32.77 |
| √ | √ | × | √ | 31.78 | 31.29 | 33.77 |
| √ | √ | √ | √ | 31.95 | 31.44 | 34.03 |
| ( | 不同类别的mAP/% | ||
|---|---|---|---|
| Full | Seen | Unseen | |
| (0.000 1, 1) | 29.68 | 28.79 | 33.25 |
| (0.000 1, 2) | 31.91 | 31.45 | 33.78 |
| (0.000 01, 2) | 32.08 | 31.64 | 33.85 |
| (0.000 01, 3) | 31.51 | 31.12 | 33.03 |
| (0.000 01, 5) | 32.01 | 31.68 | 33.36 |
| (0.000 01, 1) | 31.95 | 31.44 | 34.03 |
Tab. 4 Effectiveness of loss function weights
| ( | 不同类别的mAP/% | ||
|---|---|---|---|
| Full | Seen | Unseen | |
| (0.000 1, 1) | 29.68 | 28.79 | 33.25 |
| (0.000 1, 2) | 31.91 | 31.45 | 33.78 |
| (0.000 01, 2) | 32.08 | 31.64 | 33.85 |
| (0.000 01, 3) | 31.51 | 31.12 | 33.03 |
| (0.000 01, 5) | 32.01 | 31.68 | 33.36 |
| (0.000 01, 1) | 31.95 | 31.44 | 34.03 |
| K-shots | 不同类别的mAP/% | ||
|---|---|---|---|
| Full | Seen | Unseen | |
| 1 | 31.85 | 31.48 | 33.33 |
| 2 | 31.95 | 31.44 | 34.03 |
| 3 | 31.83 | 31.54 | 32.98 |
| 4 | 31.55 | 31.12 | 33.28 |
Tab. 5 Effectiveness of K-shot sampling
| K-shots | 不同类别的mAP/% | ||
|---|---|---|---|
| Full | Seen | Unseen | |
| 1 | 31.85 | 31.48 | 33.33 |
| 2 | 31.95 | 31.44 | 34.03 |
| 3 | 31.83 | 31.54 | 32.98 |
| 4 | 31.55 | 31.12 | 33.28 |

Fig. 6 Visualization of zero-shot HOI detection results
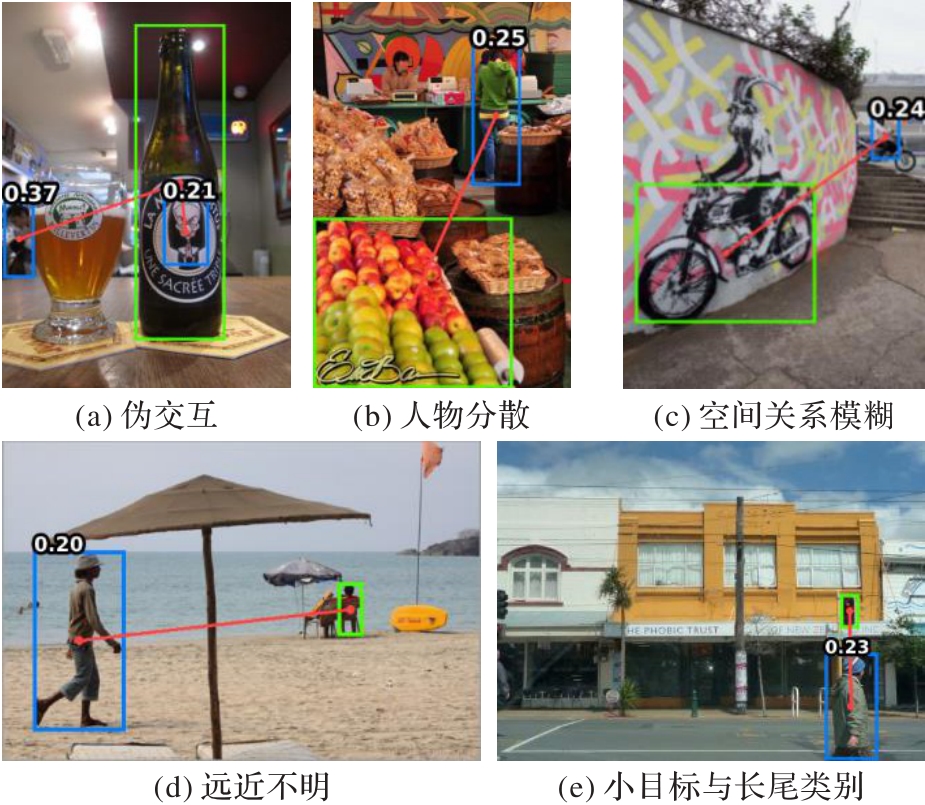
Fig. 7 Cases of failed detection
| [1] | Gupta S, Malik J. Visual semantic role labeling [PP/OL]. arXiv (2024-10-23) [2025-03-20]. . |
| [2] | Feng J, Liu R. LRB-Net: improving VQA via division of labor strategy and multimodal classifiers [J]. Displays, 2022, 75: No.102329. |
| [3] | Bai C, Zheng A, Huang Y, et al. Boosting convolutional image captioning with semantic content and visual relationship [J]. Displays, 2021, 70: No.102069. |
| [4] | Chao Y W, Liu Y, Liu X, et al. Learning to detect human-object interactions [C]// WACV 2018. Piscataway: IEEE, 2018: 381-389. |
| [5] | Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision [C]// ICML 2021. New York: JMLR.org, 2021: 8748-8763. |
| [6] | Liao Y, Zhang A, Lu M, et al. GEN-VLKT: simplify association and enhance interaction understanding for hoi detection [C]// CVPR 2022. Piscataway: IEEE, 2022: 20091-20100. |
| [7] | Wu M, Gu J, Shen Y, et al. End-to-end zero-shot HOI detection via vision and language knowledge distillation [C]// AAAI 2023. Palo Alto: AAAI Press, 2023: 2839-2846. |
| [8] | Ning S, Qiu L, Liu Y, et al. HOICLIP: efficient knowledge transfer for hoi detection with vision-language models [C]// CVPR 2023. Piscataway: IEEE, 2023: 23507-23517. |
| [9] | Mao Y, Deng J, Zhou W, et al. CLIP4HOI: towards adapting CLIP for practical zero-shot HOI detection [C]// NeurIPS 2023. Red Hook: Curran Associates Inc., 2023: 45895-45906. |
| [10] | Zhou K, Yang J, Loy C C, et al. Conditional prompt learning for vision-language models [C]// CVPR 2022. Piscataway: IEEE, 2022: 16795-16804. |
| [11] | Zhou K, Yang J, Loy C C, et al. Learning to prompt for vision-language models [J]. International Journal of Computer Vision, 2022, 130(9): 2337-2348. |
| [12] | Kingma D P, Welling M. Auto-encoding variational Bayes [PP/OL]. V11. arXiv (2022-12-10) [2025-03-20]. . |
| [13] | 阮晨钊,张祥森,刘科,等.深度学习的人-物体交互检测研究进展[J].计算机科学与探索, 2022, 16(2): 323-336. |
| Ruan Chenzhao, Zhang Xiangsen, Liu Ke, et al. Progress on human-object interaction detection of deep learning [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(2): 323-336. | |
| [14] | Carion N, Massa F, Synnaeve G, et al. End-to-end object detection with Transformers [C]// ECCV 2020. Cham: Springer, 2020: 213-229. |
| [15] | Chen M, Liao Y, Liu S, et al. Reformulating HOI detection as adaptive set prediction [C]// CVPR 2021. Piscataway: IEEE, 2021: 9000-9009. |
| [16] | Kim B, Lee J, Kang J, et al. HOTR: end-to-end human-object interaction detection with Transformers [C]// CVPR 2021. Piscataway: IEEE, 2021: 74-83. |
| [17] | Tamura M, Ohashi H, Yoshinaga T. QPIC: query-based pairwise human-object interaction detection with image-wide contextual information [C]// CVPR 2021. Piscataway: IEEE, 2021: 10405-10414. |
| [18] | Chen J, Yanai K. QAHOI: query-based anchors for human-object interaction detection [C]// MVA 2023. Piscataway: IEEE, 2023: 1-5. |
| [19] | Li Y L, Zhou S, Huang X, et al. Transferable interactiveness knowledge for human-object interaction detection [C]// CVPR 2019. Piscataway: IEEE, 2019: 3580-3589. |
| [20] | Gao C, Zou Y, Huang J B. iCAN: instance-centric attention network for human-object interaction detection [C]// BMVC 2018. Durham: BMVA Press, 2018: No.17. |
| [21] | Zhang F Z, Campbell D, Gould S. Efficient two-stage detection of human-object interactions with a novel unary-pairwise transformer [C]// CVPR 2022. Piscataway: IEEE, 2022: 20072-20080. |
| [22] | Lei T, Caba F, Chen Q, et al. Efficient adaptive human-object interaction detection with concept-guided memory [C]// ICCV 2023. Piscataway: IEEE, 2023: 6457-6467. |
| [23] | Zhang F Z, Campbell D, Gould S. Spatially conditioned graphs for detecting human-object interactions [C]// ICCV 2021. Piscataway: IEEE, 2021: 13299-13307. |
| [24] | Hou Z, Yu B, Qiao Y, et al. Affordance transfer learning for human-object interaction detection [C]// CVPR 2021. Piscataway: IEEE, 2021: 495-504. |
| [25] | Hou Z, Yu B, Qiao Y, et al. Detecting human-object interaction via fabricated compositional learning [C]// CVPR 2021. Piscataway: IEEE, 2021: 14641-14650. |
| [26] | Liu Y, Yuan J, Chen C W. ConsNet: learning consistency graph for zero-shot human-object interaction detection [C]// ACM Multimedia 2020. New York: ACM, 2020: 4235-4243. |
| [27] | Liao Y, Liu S, Wang F, et al. PPDM: parallel point detection and matching for real-time human-object interaction detection [C]// CVPR 2020. Piscataway: IEEE, 2020: 479-487. |
| [28] | Sanghi A, Chu H, Lambourne J G, et al. CLIP-Forge: towards zero-shot text-to-shape generation [C]// CVPR 2022. Piscataway: IEEE, 2022: 18582-18592. |
| [29] | Wang Z, Liu W, He Q, et al. CLIP-GEN: language-free training of a text-to-image generator with CLIP [PP/OL]. arXiv (2022-03-01) [2025-03-20]. . |
| [30] | Khattak M U, Rasheed H, Maaz M, et al. MaPLe: multi-modal prompt learning [C]// CVPR 2023. Piscataway: IEEE, 2023: 19113-19122. |
| [31] | Gao P, Geng S, Zhang R, et al. CLIP-Adapter: better vision-language models with feature adapters [J]. International Journal of Computer Vision, 2024, 132(2): 581-595. |
| [32] | Zhang R, Zhang W, Fang R, et al. Tip-Adapter: training-free adaption of CLIP for few-shot classification [C]// ECCV 2022. Cham: Springer, 2022: 493-510. |
| [33] | Lei T, Yin S, Peng Y, et al. Exploring conditional multi-modal prompts for zero-shot hoi detection [C]// ECCV 2024. Cham: Springer, 2025: 1-19. |
| [34] | Bansal A, Rambhatla S S, Shrivastava A, et al. Detecting human-object interactions via functional generalization [C]// AAAI 2020. Palo Alto: AAAI Press, 2020: 10460-10469. |
| [35] | Yuan H, Zhang S, Wang X, et al. RLIPv2: fast scaling of relational language-image pre-training [C]// ICCV 2023. Piscataway: IEEE, 2023: 21592-21604. |
| [36] | Lei Q, Wang B, Tan R T. EZ-HOI: VLM adaptation via guided prompt learning for zero-shot hoi detection [C]// NeurIPS 2024. Red Hook: Curran Associates Inc., 2024: 55831-55857. |
| [37] | Goodfellow I J, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets [C]// NeurIPS 2014. Cambridge: MIT Press, 2014: 2672-2680. |
| [38] | van den OORD A, Vinyals O. Neural discrete representation learning [C]// NeurIPS 2017. Red Hook: Curran Associates Inc., 2017: 6309-6318. |
| [39] | Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need [C]// NeurIPS 2017. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [40] | Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale [PP/OL]. V2. arXiv (2021-06-03) [2025-03-20]. . |
| [41] | Lin T Y, Goyal P, Girshick R, et al. Focal loss for dense object detection [C]// ICCV 2017. Piscataway: IEEE, 2017: 2999-3007. |
| [42] | Zhang A, Liao Y, Liu S, et al. Mining the benefits of two-stage and one-stage hoi detection [C]// NeurIPS 2021. Red Hook: Curran Associates Inc., 2021: 17209-17220. |
| [43] | Li L, Wei J, Wang W, et al. Neural-logic human-object interaction detection [C]// NeurIPS 2023. Red Hook: Curran Associates Inc., 2023: 21158-21171. |
| [44] | Cao Y, Tang Q, Su X, et al. Detecting any human-object interaction relationship: universal HOI detector with spatial prompt learning on foundation models [C]// NeurIPS 2023. Red Hook: Curran Associates Inc., 2023: 739-751. |
| [45] | Li Y L, Liu X, Wu X, et al. HOI Analysis: integrating and decomposing human-object interaction [C]// NeurIPS 2020. Red Hook: Curran Associates Inc., 2020: 5011-5022. |
| [46] | Zhang Y, Pan Y, Yao T, et al. Exploring structure-aware Transformer over interaction proposals for human-object interaction detection [C]// CVPR 2022. Piscataway: IEEE, 2022: 19526-19535. |
| [47] | Zhang F Z, Yuan Y, Campbell D, et al. Exploring predicate visual context in detecting of human-object interactions [C]// ICCV 2023. Piscataway: IEEE, 2023: 10377-10387. |
| [1] | Yuebo FAN, Mingxuan CHEN, Xian TANG, Yongbin GAO, Wenchao LI. Multi-dimensional frequency domain feature fusion for human-object interaction detection [J]. Journal of Computer Applications, 2026, 46(2): 580-586. |
| [2] | Xinran XIE, Zhe CUI, Rui CHEN, Tailai PENG, Dekun LIN. Zero-shot re-ranking method by large language model with hierarchical filtering and label semantic extension [J]. Journal of Computer Applications, 2026, 46(1): 60-68. |
| [3] | Yuyang SUN, Minjie ZHANG, Jie HU. Zero-shot dialogue state tracking domain transfer model based on semantic prefix-tuning [J]. Journal of Computer Applications, 2025, 45(7): 2221-2228. |
| [4] | Yuanlong WANG, Tinghua LIU, Hu ZHANG. Commonsense question answering model based on cross-modal contrastive learning [J]. Journal of Computer Applications, 2025, 45(3): 732-738. |
| [5] | Bingjie QIU, Chaoqun ZHANG, Weidong TANG, Bicheng LIANG, Danyang CUI, Haisheng LUO, Qiming CHEN. Zero-shot relation extraction model based on dual contrastive learning [J]. Journal of Computer Applications, 2025, 45(11): 3555-3563. |
| [6] | Junyi LIN, Mingxuan CHEN, Yongbin GAO. Human-object interaction detection algorithm by fusing local feature enhanced perception [J]. Journal of Computer Applications, 2025, 45(11): 3713-3720. |
| [7] | Liang XU, Chun ZHANG, Ning ZHANG, Xuetao TIAN. Zero-shot relation extraction model via multi-template fusion in Prompt [J]. Journal of Computer Applications, 2023, 43(12): 3668-3675. |
| [8] | XU Ge, XIAO Yongqiang, WANG Tao, CHEN Kaizhi, LIAO Xiangwen, WU Yunbing. Zero-shot image classification based on visual error and semantic attributes [J]. Journal of Computer Applications, 2020, 40(4): 1016-1022. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||