


Journal of Computer Applications ›› 2023, Vol. 43 ›› Issue (12): 3668-3675.DOI: 10.11772/j.issn.1001-9081.2022121869
Special Issue: 人工智能
• Artificial intelligence • Previous Articles Next Articles
Liang XU( ), Chun ZHANG, Ning ZHANG, Xuetao TIAN
), Chun ZHANG, Ning ZHANG, Xuetao TIAN
Received:2022-12-22
Revised:2023-03-27
Accepted:2023-03-28
Online:2023-05-06
Published:2023-12-10
Contact:
Liang XU
About author:ZHANG Chun, born in 1966, M. S., research fellow. Her research interests include railway information, intelligent information processing.Supported by:
许亮(), 张春, 张宁, 田雪涛
通讯作者:
许亮
作者简介:许亮(1997—),男,安徽芜湖人,硕士研究生,主要研究方向:自然语言处理;Email:20120467@bjtu.edu.cn基金资助:CLC Number:
Liang XU, Chun ZHANG, Ning ZHANG, Xuetao TIAN. Zero-shot relation extraction model via multi-template fusion in Prompt[J]. Journal of Computer Applications, 2023, 43(12): 3668-3675.
许亮, 张春, 张宁, 田雪涛. 融合多Prompt模板的零样本关系抽取模型[J]. 《计算机应用》唯一官方网站, 2023, 43(12): 3668-3675.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2022121869

Fig. 1 Different forms for using Prompt

Fig. 2 RE model based on Prompt paradigm
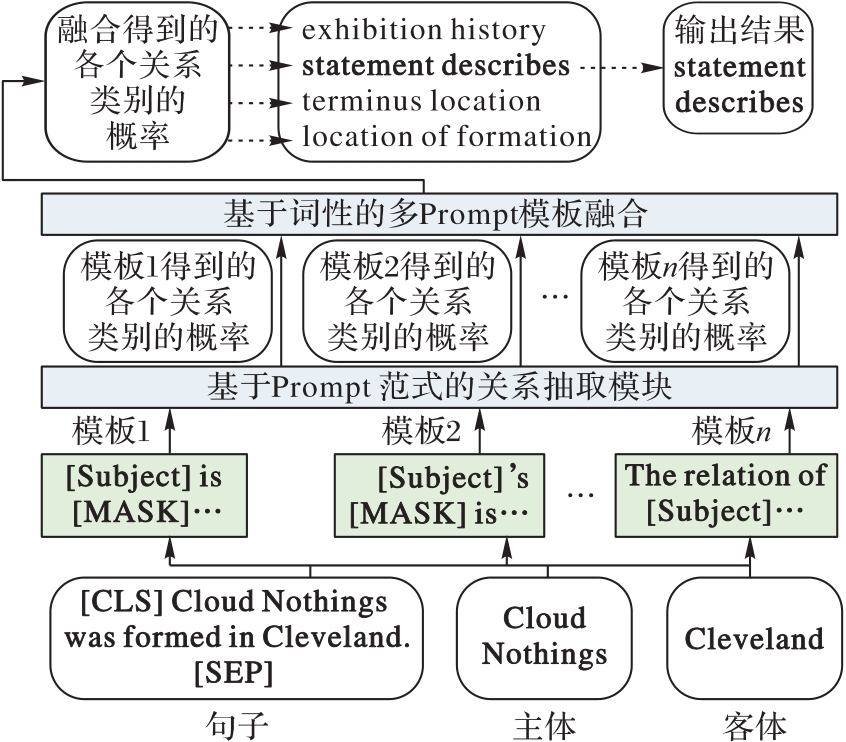
Fig. 3 Multi-Prompt template fusion method based on part of speech
| 词性缩写 | 含义 | 解释 |
|---|---|---|
| NN | noun, singular | 名词单数 |
| IN | preposition/ subordinating conjunction | 介词/从属连词;主从连词; 从属连接词 |
| JJ | adjective | 形容词 |
| VBN | verb, pastparticiple | 动词,过去分词 |
| NNS | nounplural | 名词复数 |
| DT | determiner | 限定词 |
| TO | to | 单词to |
| VBG | verb, gerund/present participle taking | 动词;动名词/现在分词 |
Tab. 1 Meanings of some parts of speech and their abbreviations in NLTK library
| 词性缩写 | 含义 | 解释 |
|---|---|---|
| NN | noun, singular | 名词单数 |
| IN | preposition/ subordinating conjunction | 介词/从属连词;主从连词; 从属连接词 |
| JJ | adjective | 形容词 |
| VBN | verb, pastparticiple | 动词,过去分词 |
| NNS | nounplural | 名词复数 |
| DT | determiner | 限定词 |
| TO | to | 单词to |
| VBG | verb, gerund/present participle taking | 动词;动名词/现在分词 |
数据集(不可见 关系种类数) | 模型 | η=20 | η=100 | η=200 | η=all | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Prec | Rec | F1 | Prec | Rec | F1 | Prec | Rec | F1 | Prec | Rec | F1 | ||
FewRel (m=15) | Att Bi-LSTM | 14.19 | 13.88 | 14.03 | 15.75 | 19.80 | 17.55 | 20.83 | 26.00 | 23.13 | 16.48 | 26.36 | 20.28 |
| R-BERT | 8.40 | 8.38 | 8.39 | 13.61 | 15.90 | 14.67 | 16.05 | 18.58 | 17.22 | 16.95 | 19.37 | 18.08 | |
| ESIM | 0.60 | 5.45 | 1.08 | 0.90 | 6.56 | 1.58 | 7.66 | 7.38 | 7.52 | 29.15 | 31.59 | 30.32 | |
| ZS-BERT | 6.04 | 6.36 | 6.20 | 6.34 | 7.93 | 7.05 | 8.35 | 9.59 | 8.93 | 35.54 | 38.19 | 36.82 | |
| RelationPrompt | 17.62 | 48.33 | 25.84 | 53.90 | 49.19 | 51.44 | 56.59 | 50.06 | 53.12 | 74.33 | 72.51 | 73.40 | |
| MFP | 9.31 | 13.92 | 11.16 | 19.93 | 24.98 | 22.17 | 40.88 | 45.72 | 43.16 | 54.58 | 62.24 | 58.16 | |
| 本文模型(BERT-base) | 14.83 | 25.29 | 18.70 | 34.49 | 42.60 | 38.12 | 47.02 | 56.87 | 51.48 | 59.82 | 66.07 | 62.79 | |
| 本文模型(BERT-large) | 31.81 | 30.25 | 31.01 | 65.76 | 72.72 | 69.07 | 70.88 | 75.17 | 72.96 | 74.35 | 75.42 | 74.88 | |
TACRED (m=11) | Att Bi-LSTM | 14.33 | 11.38 | 12.68 | 13.73 | 10.64 | 11.99 | 15.68 | 21.70 | 18.20 | 25.20 | 20.17 | 22.41 |
| R-BERT | 14.59 | 7.27 | 9.70 | 18.93 | 12.12 | 14.78 | 23.62 | 19.67 | 21.47 | 44.66 | 45.86 | 45.25 | |
| ESIM | 9.09 | 0.15 | 0.29 | 8.54 | 9.41 | 8.96 | 1.52 | 9.15 | 2.61 | 26.99 | 18.38 | 21.87 | |
| ZS-BERT | 10.79 | 9.35 | 10.02 | 12.53 | 9.25 | 10.64 | 14.98 | 15.79 | 15.38 | 38.08 | 42.72 | 40.27 | |
| RelationPrompt | — | — | — | 18.54 | 60.01 | 28.33 | 27.25 | 68.55 | 39.00 | 35.64 | 68.56 | 46.90 | |
| MFP | 6.79 | 10.99 | 8.39 | 9.32 | 15.11 | 11.53 | 35.77 | 39.81 | 37.68 | 53.33 | 58.62 | 55.85 | |
| 本文模型(BERTbase) | 11.69 | 15.91 | 13.48 | 12.21 | 22.98 | 15.95 | 39.12 | 44.33 | 41.56 | 54.86 | 59.21 | 56.95 | |
| 本文模型(BERT-large) | 16.48 | 24.67 | 19.76 | 40.70 | 46.94 | 43.60 | 53.11 | 56.50 | 54.75 | 60.66 | 64.35 | 62.46 | |
Tab. 2 Performance comparison on different datasets with different unseen relation quantity and varied training data volume
数据集(不可见 关系种类数) | 模型 | η=20 | η=100 | η=200 | η=all | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Prec | Rec | F1 | Prec | Rec | F1 | Prec | Rec | F1 | Prec | Rec | F1 | ||
FewRel (m=15) | Att Bi-LSTM | 14.19 | 13.88 | 14.03 | 15.75 | 19.80 | 17.55 | 20.83 | 26.00 | 23.13 | 16.48 | 26.36 | 20.28 |
| R-BERT | 8.40 | 8.38 | 8.39 | 13.61 | 15.90 | 14.67 | 16.05 | 18.58 | 17.22 | 16.95 | 19.37 | 18.08 | |
| ESIM | 0.60 | 5.45 | 1.08 | 0.90 | 6.56 | 1.58 | 7.66 | 7.38 | 7.52 | 29.15 | 31.59 | 30.32 | |
| ZS-BERT | 6.04 | 6.36 | 6.20 | 6.34 | 7.93 | 7.05 | 8.35 | 9.59 | 8.93 | 35.54 | 38.19 | 36.82 | |
| RelationPrompt | 17.62 | 48.33 | 25.84 | 53.90 | 49.19 | 51.44 | 56.59 | 50.06 | 53.12 | 74.33 | 72.51 | 73.40 | |
| MFP | 9.31 | 13.92 | 11.16 | 19.93 | 24.98 | 22.17 | 40.88 | 45.72 | 43.16 | 54.58 | 62.24 | 58.16 | |
| 本文模型(BERT-base) | 14.83 | 25.29 | 18.70 | 34.49 | 42.60 | 38.12 | 47.02 | 56.87 | 51.48 | 59.82 | 66.07 | 62.79 | |
| 本文模型(BERT-large) | 31.81 | 30.25 | 31.01 | 65.76 | 72.72 | 69.07 | 70.88 | 75.17 | 72.96 | 74.35 | 75.42 | 74.88 | |
TACRED (m=11) | Att Bi-LSTM | 14.33 | 11.38 | 12.68 | 13.73 | 10.64 | 11.99 | 15.68 | 21.70 | 18.20 | 25.20 | 20.17 | 22.41 |
| R-BERT | 14.59 | 7.27 | 9.70 | 18.93 | 12.12 | 14.78 | 23.62 | 19.67 | 21.47 | 44.66 | 45.86 | 45.25 | |
| ESIM | 9.09 | 0.15 | 0.29 | 8.54 | 9.41 | 8.96 | 1.52 | 9.15 | 2.61 | 26.99 | 18.38 | 21.87 | |
| ZS-BERT | 10.79 | 9.35 | 10.02 | 12.53 | 9.25 | 10.64 | 14.98 | 15.79 | 15.38 | 38.08 | 42.72 | 40.27 | |
| RelationPrompt | — | — | — | 18.54 | 60.01 | 28.33 | 27.25 | 68.55 | 39.00 | 35.64 | 68.56 | 46.90 | |
| MFP | 6.79 | 10.99 | 8.39 | 9.32 | 15.11 | 11.53 | 35.77 | 39.81 | 37.68 | 53.33 | 58.62 | 55.85 | |
| 本文模型(BERTbase) | 11.69 | 15.91 | 13.48 | 12.21 | 22.98 | 15.95 | 39.12 | 44.33 | 41.56 | 54.86 | 59.21 | 56.95 | |
| 本文模型(BERT-large) | 16.48 | 24.67 | 19.76 | 40.70 | 46.94 | 43.60 | 53.11 | 56.50 | 54.75 | 60.66 | 64.35 | 62.46 | |
模板 类型 | 模板 | FewRel | TACRED | ||||
|---|---|---|---|---|---|---|---|
| Prec | Rec | F1 | Prec | Rec | F1 | ||
| 单模板 | [SEP][subject] is [MASK] to [object].[SEP] | 55.26 | 63.45 | 59.07 | 50.24 | 53.18 | 51.67 |
| [SEP][subject] [MASK] [object].[SEP] | 52.57 | 57.07 | 54.73 | 48.53 | 57.16 | 52.49 | |
| [SEP] The relation of [subject] and [object] is [MASK].[SEP] | 53.64 | 59.81 | 56.56 | 49.29 | 53.24 | 51.19 | |
| [SEP] [subject] 's [MASK] is [object].[SEP] | 55.48 | 62.29 | 58.69 | 51.41 | 56.44 | 53.81 | |
| [SEP] [ MASK] is the relation between [subject] and [object].[SEP] | 48.14 | 55.87 | 51.72 | 49.76 | 57.90 | 53.52 | |
| 多模板 | 基于加权融合的多Prompt模板融合方法 | 54.58 | 62.24 | 58.16 | 52.57 | 54.24 | 53.39 |
| 基于平均融合的多Prompt模板融合方法 | 51.77 | 57.49 | 54.48 | 51.71 | 58.40 | 54.85 | |
| 基于词性的多Prompt模板融合方法(本文模型) | 59.82 | 66.07 | 62.79 | 54.86 | 59.21 | 56.95 | |
Tab.3 Ablation experimental results on TACRED and FewRel datasets
模板 类型 | 模板 | FewRel | TACRED | ||||
|---|---|---|---|---|---|---|---|
| Prec | Rec | F1 | Prec | Rec | F1 | ||
| 单模板 | [SEP][subject] is [MASK] to [object].[SEP] | 55.26 | 63.45 | 59.07 | 50.24 | 53.18 | 51.67 |
| [SEP][subject] [MASK] [object].[SEP] | 52.57 | 57.07 | 54.73 | 48.53 | 57.16 | 52.49 | |
| [SEP] The relation of [subject] and [object] is [MASK].[SEP] | 53.64 | 59.81 | 56.56 | 49.29 | 53.24 | 51.19 | |
| [SEP] [subject] 's [MASK] is [object].[SEP] | 55.48 | 62.29 | 58.69 | 51.41 | 56.44 | 53.81 | |
| [SEP] [ MASK] is the relation between [subject] and [object].[SEP] | 48.14 | 55.87 | 51.72 | 49.76 | 57.90 | 53.52 | |
| 多模板 | 基于加权融合的多Prompt模板融合方法 | 54.58 | 62.24 | 58.16 | 52.57 | 54.24 | 53.39 |
| 基于平均融合的多Prompt模板融合方法 | 51.77 | 57.49 | 54.48 | 51.71 | 58.40 | 54.85 | |
| 基于词性的多Prompt模板融合方法(本文模型) | 59.82 | 66.07 | 62.79 | 54.86 | 59.21 | 56.95 | |

Fig.4 Statistics of parts of speech of words predicted by different templates
| 模型 | FewRel to TACRED | TACRED to FewRel | ||||
|---|---|---|---|---|---|---|
| Prec | Rec | F1 | Prec | Rec | F1 | |
| Att Bi-LSTM | 21.86 | 27.72 | 24.44 | 31.27 | 39.26 | 34.82 |
| R-BERT | 22.67 | 18.91 | 20.62 | 19.38 | 11.93 | 14.77 |
| ESIM | 23.10 | 28.49 | 23.98 | 15.31 | 14.70 | 15.00 |
| ZS-BERT | 35.90 | 29.78 | 32.55 | 17.69 | 11.81 | 14.16 |
| RelationPrompt | 30.21 | 39.95 | 34.40 | 41.33 | 49.48 | 45.04 |
| 本文模型(BERT-base) | 46.12 | 53.11 | 49.37 | 54.86 | 59.21 | 56.95 |
Tab.4 Results of cross domain experiments
| 模型 | FewRel to TACRED | TACRED to FewRel | ||||
|---|---|---|---|---|---|---|
| Prec | Rec | F1 | Prec | Rec | F1 | |
| Att Bi-LSTM | 21.86 | 27.72 | 24.44 | 31.27 | 39.26 | 34.82 |
| R-BERT | 22.67 | 18.91 | 20.62 | 19.38 | 11.93 | 14.77 |
| ESIM | 23.10 | 28.49 | 23.98 | 15.31 | 14.70 | 15.00 |
| ZS-BERT | 35.90 | 29.78 | 32.55 | 17.69 | 11.81 | 14.16 |
| RelationPrompt | 30.21 | 39.95 | 34.40 | 41.33 | 49.48 | 45.04 |
| 本文模型(BERT-base) | 46.12 | 53.11 | 49.37 | 54.86 | 59.21 | 56.95 |

Fig.5 Performance comparison with different number of templates
| 1 | ZHANG F, YUAN N, LIAN D, et al. Collaborative knowledge base embedding for recommender systems [C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York: ACM, 2016: 353-362. 10.1145/2939672.2939673 |
| 2 | HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. 10.1162/neco.1997.9.8.1735 |
| 3 | YAN Z, ZHANG C, FU J, et al. A partition filter network for joint entity and relation extraction [C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Stroudsburg, PA: Association for Computational Linguistics, 2021: 185-197. 10.18653/v1/2021.emnlp-main.17 |
| 4 | WANG Y, YU B, ZHANG Y, et al. TPLinker: single-stage joint extraction of entities and relations through token pair linking [C]//Proceedings of the 28th International Conference on Computational Linguistics. Stroudsburg, PA: International Committee on Computational Linguistics, 2020: 1572-1582. 10.18653/v1/2020.coling-main.138 |
| 5 | 叶育鑫,薛环,王璐,等. 基于带噪观测的远监督神经网络关系抽取[J].软件学报,2020,31(4):1025-1038. 10.13328/j.cnki.jos.005929 |
| YE Y X, XUE H, WANG L, et al. Distant supervision neural network relation extraction base on noisy observation[J]. Journal of Software, 2020, 31(4): 1025-1038. 10.13328/j.cnki.jos.005929 | |
| 6 | 武小平, 张强, 赵芳,等. 基于BERT的心血管医疗指南实体关系抽取方法[J]. 计算机应用, 2021, 41(1): 145-149. 10.11772/j.issn.1001-9081.2020061008 |
| WU X P, ZHANG Q, ZHAO F, et al. Entity relation extraction method for guidelines of cardiovascular disease based on bidirectional encoder representation from transformers [J]. Journal of Computer Applications, 2021, 41(1): 145-149. 10.11772/j.issn.1001-9081.2020061008 | |
| 7 | LAMPERT C H, NICKISCH H, HARMELING S. Learning to detect unseen object classes by between-class attribute transfer [C]// Proceedings of the 2009 Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2009: 951-958. 10.1109/cvpr.2009.5206594 |
| 8 | LEVY O, SEO M, CHOI E, et al. Zero-shot relation extraction via reading comprehension [C]// Proceedings of the 21st Conference on Computational Natural Language Learning, Stroudsburg, PA: Association for Computational Linguistics, 2017: 333-342. 10.18653/v1/k17-1034 |
| 9 | OBAMUYIDE A, VLACHOS A. Zero-shot relation classification as textual entailment [C]// Proceedings of the First Workshop on Fact Extraction and Verification, Stroudsburg, PA: Association for Computational Linguistics, 2018: 72-78. 10.18653/v1/w18-5511 |
| 10 | DEVLIN J, CHANG M, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long and Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2019: 4171-4186. 10.18653/v1/n18-2 |
| 11 | RAZNIEWSKI S, YATES A, KASSNER N, et al. Language models as or for knowledge bases [EB/OL]. (2021-10-10) [2022-07-14]. . |
| 12 | SCAO T L, RUSH A M. How many data points is a prompt worth? [EB/OL]. (2021-03-15) [2022-07-14]. . 10.18653/v1/2021.naacl-main.208 |
| 13 | SAINZ O, DE LACALLE O L, LABAKA G, et al. Label verbalization and entailment for effective zero-and few-shot relation extraction [EB/OL]. (2021-09-08) [2022-07-14]. . 10.18653/v1/2021.emnlp-main.92 |
| 14 | LIU X, ZHENG Y, DU Z, et al. GPT understands, too [EB/OL]. (2021-03-18) [2022-07-14]. . 10.1016/j.aiopen.2023.08.012 |
| 15 | ZHAO J, HU Y, XU N, et al. An exploration of prompt-based zero-shot relation extraction method [C]// Proceedings of the 21st Chinese National Conference on Computational Linguistic. Beijing: Chinese Information Processing Society of China, 2022: 786-797. 10.1007/978-3-031-18315-7_6 |
| 16 | HU S, DING N, WANG H, et al. Knowledgeable prompt-tuning: incorporating knowledge into prompt verbalizer for text classification [EB/OL]. (2021-08-04) [2022-07-14]. . 10.18653/v1/2022.acl-long.158 |
| 17 | ZHANG Y, ZHONG V, CHEN D, et al. Position-aware attention and supervised data improve slot filling [C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2017: 35-45. 10.18653/v1/d17-1004 |
| 18 | HAN X, ZHU H, YU P, et al. FewRel: a large-scale supervised few-shot relation classification dataset with state-of-the-art evaluation [C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2018: 4803-4809. 10.18653/v1/d18-1514 |
| 19 | CHEN C-Y, LI C-T. ZS-BERT: towards zero-shot relation extraction with attribute representation learning [C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2021: 3470-3479. 10.18653/v1/2021.naacl-main.272 |
| 20 | RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training [EB/OL]. [2022-07-14]. . 10.4324/9781003267836-1 |
| 21 | BROWN T, MANN B, RYDER N, et al. Language models are few-shot learners [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook:Curran Associates Inc., 2020: 1877-1901. |
| 22 | SCHICK T, SCHÜTZE H. Exploiting cloze questions for few shot text classification and natural language inference [C]// Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2021: 255-269. 10.18653/v1/2021.eacl-main.20 |
| 23 | SCHICK T, SCHÜTZE H. It’s not just size that matters: small language models are also few-shot learners [C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Stroudsburg, PA: Association for Computational Linguistics, 2021: 2339-2352. 10.18653/v1/2021.naacl-main.185 |
| 24 | GAO T, FISCH A, CHEN D. Making pre-trained language models better few-shot learners [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2021: 3816-3830. 10.18653/v1/2021.acl-long.295 |
| 25 | LIU P, YUAN W, FU J, et al. Pre-train, prompt, and predict: a systematic survey of prompting methods in natural language processing [EB/OL]. (2021-07-28) [2022-07-14]. . 10.1145/3560815 |
| 26 | WAGNER W.Natural language processing with Python: analyzing text with the natural language Toolkit [J]. Language Resources and Evaluation, 2010, 44(4):421-424. 10.1007/s10579-010-9124-x |
| 27 | LOSHCHILOV I, HUTTER F. Decoupled weight decay regularization [EB/OL]. (2019-01-04) [2022-07-14]. . |
| 28 | WOLF T, DEBUT L, SANH V, et al. Transformers: state-of-the-art natural language processing [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Stroudsburg, PA: Association for Computational Linguistics, 2020: 38-45. 10.18653/v1/2020.emnlp-demos.6 |
| 29 | ZHOU P, SHI W, TIAN J, et al. Attention-based bidirectional long short-term memory networks for relation classification [C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2016: 207-212. 10.18653/v1/p16-2034 |
| 30 | WU S, HE Y. Enriching pretrained language model with entity information for relation classification [C]// Proceedings of the 28th ACM International Conference on Information and Knowledge Management. New York: ACM, 2019: 2361-2364. 10.1145/3357384.3358119 |
| 31 | CHEN Q, ZHU X, LING Z, et al. Enhanced LSTM for natural language inference [C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2017: 1657-1668. 10.18653/v1/p17-1152 |
| 32 | CHIA Y K, BING L, PORIA S, et al. RelationPrompt: leveraging prompts to generate synthetic data for zero-shot relation triplet extraction [EB/OL]. (2022-03-17) [2022-07-14]. . 10.18653/v1/2022.findings-acl.5 |
| 33 | LEWIS M, LIU Y, GOYAL N, et al. BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension [EB/OL]. (2019-10-29) [2022-07-14]. . 10.18653/v1/2020.acl-main.703 |
| 34 | 北京交通大学. 一种基于Prompt多模板融合的零样本关系抽取方法: CN202211082703.4[P]. 2023-02-03. |
| Beijing Jiaotong University. A zero-shot relation extraction method fusing multiple templates based on Prompt: CN202211082703.4[P]. 2023-02-03. | |
| 35 | WANG L, HUANG J, HUANG K, et al. Improving neural language generation with spectrum control [EB/OL]. (2022-03-11) [2022-07-14]. . |
| 36 | GAO J, HE D, TAN X, et al. Representation degeneration problem in training natural language generation models [EB/OL]. (2019-07-28) [2022-07-14]. . |
| 37 | LI B, ZHOU H, HE J, et al. On the sentence embeddings from pre-trained language models [EB/OL]. (2020-11-02) [2022-07-14]. . 10.18653/v1/2020.emnlp-main.733 |
| [1] | Xianglan WU, Yang XIAO, Mengying LIU, Mingming LIU. Text-to-SQL model based on semantic enhanced schema linking [J]. Journal of Computer Applications, 2024, 44(9): 2689-2695. |
| [2] | Chao WEI, Yanping CHEN, Kai WANG, Yongbin QIN, Ruizhang HUANG. Relation extraction method based on mask prompt and gated memory network calibration [J]. Journal of Computer Applications, 2024, 44(6): 1713-1719. |
| [3] | Yuelin TIAN, Ruizhang HUANG, Lina REN. Scholar fine-grained information extraction method fused with local semantic features [J]. Journal of Computer Applications, 2023, 43(9): 2707-2714. |
| [4] | Yuxin TUO, Tao XUE. Joint triple extraction model combining pointer network and relational embedding [J]. Journal of Computer Applications, 2023, 43(7): 2116-2124. |
| [5] | Menglin HUANG, Lei DUAN, Yuanhao ZHANG, Peiyan WANG, Renhao LI. Prompt learning based unsupervised relation extraction model [J]. Journal of Computer Applications, 2023, 43(7): 2010-2016. |
| [6] | Jingsheng LEI, Kaijun LA, Shengying YANG, Yi WU. Joint entity and relation extraction based on contextual semantic enhancement [J]. Journal of Computer Applications, 2023, 43(5): 1438-1444. |
| [7] | Yongbing GAO, Juntian GAO, Rong MA, Lidong YANG. User granularity-level personalized social text generation model [J]. Journal of Computer Applications, 2023, 43(4): 1021-1028. |
| [8] | Haifeng ZHANG, Cheng ZENG, Lie PAN, Rusong HAO, Chaodong WEN, Peng HE. News topic text classification method based on BERT and feature projection network [J]. Journal of Computer Applications, 2022, 42(4): 1116-1124. |
| [9] | Ping LUO, Ling DING, Xue YANG, Yang XIANG. Chinese event detection based on data augmentation and weakly supervised adversarial training [J]. Journal of Computer Applications, 2022, 42(10): 2990-2995. |
| [10] | CUI Bowen, JIN Tao, WANG Jianmin. Overview of information extraction of free-text electronic medical records [J]. Journal of Computer Applications, 2021, 41(4): 1055-1063. |
| [11] | Zhichao LI, Tohti TURDI, Hamdulla ASKAR. Answer selection model based on dynamic attention and multi-perspective matching [J]. Journal of Computer Applications, 2021, 41(11): 3156-3163. |
| [12] | TAN Jinyuan, DIAO Yufeng, QI Ruihua, LIN Hongfei. Automatic summary generation of Chinese news text based on BERT-PGN model [J]. Journal of Computer Applications, 2021, 41(1): 127-132. |
| [13] | XU Ge, XIAO Yongqiang, WANG Tao, CHEN Kaizhi, LIAO Xiangwen, WU Yunbing. Zero-shot image classification based on visual error and semantic attributes [J]. Journal of Computer Applications, 2020, 40(4): 1016-1022. |
| [14] | Yang LI, Wei ZHANG, Chen PENG. Target-dependent method for authorship attribution [J]. Journal of Computer Applications, 2020, 40(2): 473-478. |
| [15] | LUO Ming, HUANG Hailiang. Information extraction method of financial events based on lexical-semantic pattern [J]. Journal of Computer Applications, 2018, 38(1): 84-90. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||