


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (1): 318-324.DOI: 10.11772/j.issn.1001-9081.2023121878
• Multimedia computing and computer simulation • Previous Articles Next Articles
Qiang FU, Zhenping XU( ), Wenxing SHENG, Qing YE
), Wenxing SHENG, Qing YE
Received:2024-01-10
Revised:2024-04-25
Accepted:2024-05-07
Online:2024-05-21
Published:2025-01-10
Contact:
Zhenping XU
About author:FU Qiang, born in 1999, M. S. candidate. His research interests include deep learning, speech recognition.Supported by:
付强, 徐振平(), 盛文星, 叶青
通讯作者:
徐振平
作者简介:付强(1999—),男,湖北广水人,硕士研究生,主要研究方向:深度学习、语音识别;基金资助:CLC Number:
Qiang FU, Zhenping XU, Wenxing SHENG, Qing YE. End-to-end Chinese speech recognition method with byte-level byte pair encoding[J]. Journal of Computer Applications, 2025, 45(1): 318-324.
付强, 徐振平, 盛文星, 叶青. 结合字节级别字节对编码的端到端中文语音识别方法[J]. 《计算机应用》唯一官方网站, 2025, 45(1): 318-324.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023121878

Fig. 1 Zipformer overall architecture
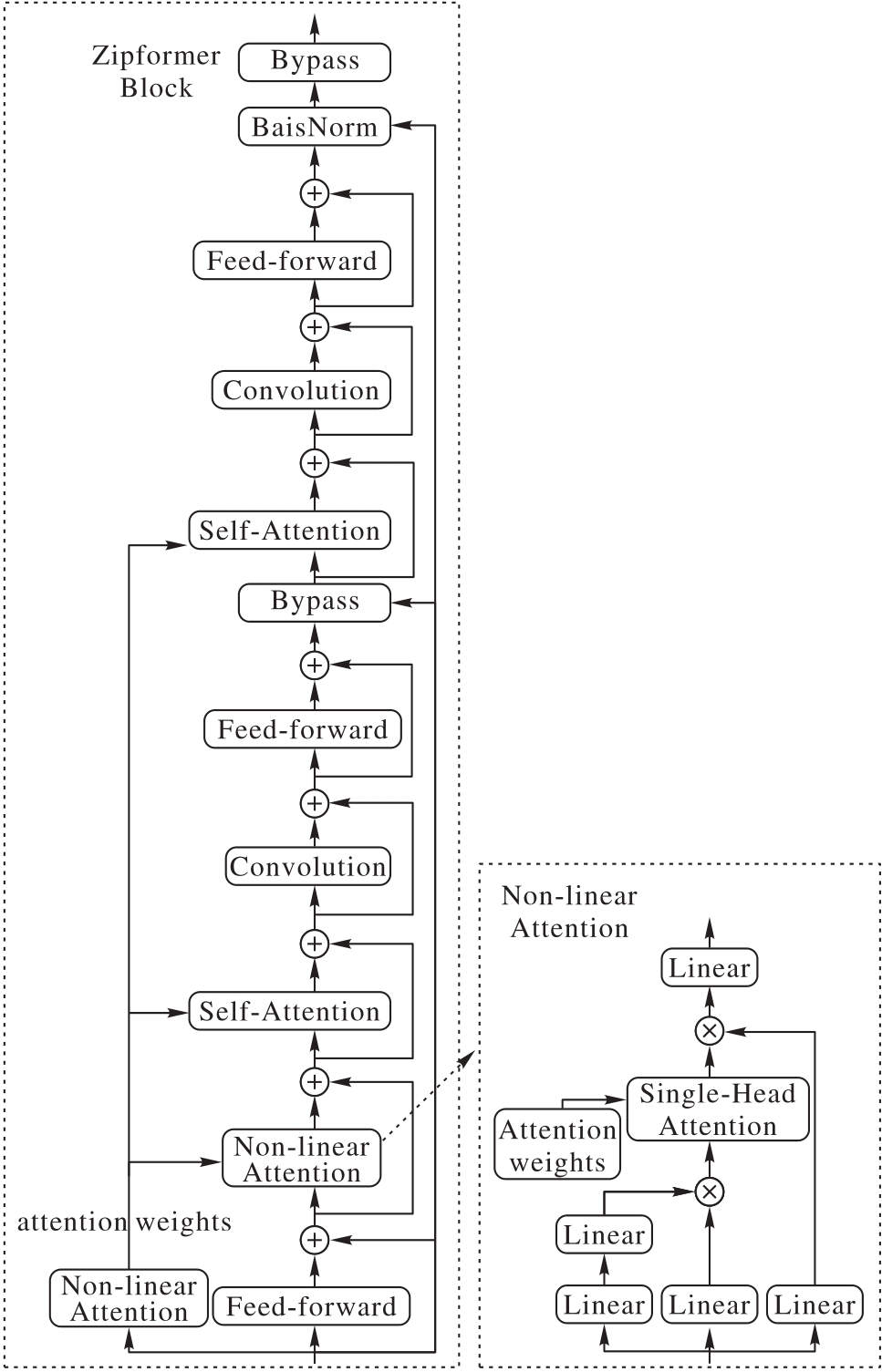
Fig. 2 Internal structure of Zipformer block
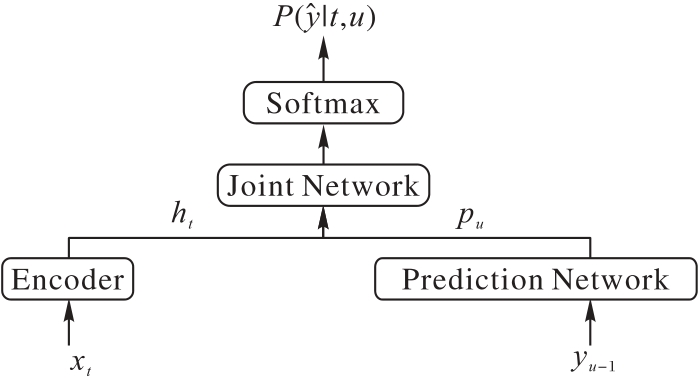
Fig. 3 Transducer model structure
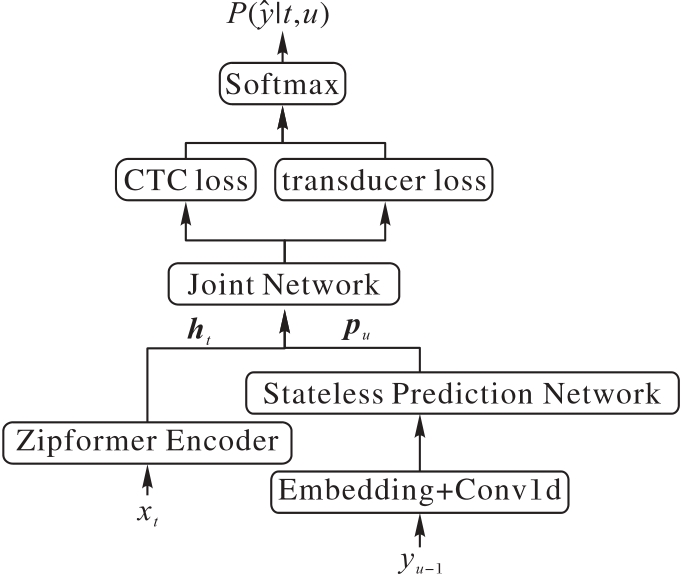
Fig. 4 Zipformer-T model structure

Fig. 5 Structure of end-to-end speech recognition system
| 参数 | 值 | 备注 |
|---|---|---|
| num_encoder_layers | 2,2,3,4,3,2 | Zipformer块数 |
| downsampling_factor | 1,2,4,8,4,2 | 下采样因子 |
| feedforward_dim | 512,768,1 024,1 536,1 024,768 | 前馈层维度 |
| num_heads | 4,4,4,8,4,4 | 注意力头数 |
| encoder_dim | 192,256,384,512,384,256 | 嵌入层维度 |
| cnn_module_kernel | 31,31,15,15,15,31 | 卷积块大小 |
Tab. 1 Description of Zipformer-T model parameters
| 参数 | 值 | 备注 |
|---|---|---|
| num_encoder_layers | 2,2,3,4,3,2 | Zipformer块数 |
| downsampling_factor | 1,2,4,8,4,2 | 下采样因子 |
| feedforward_dim | 512,768,1 024,1 536,1 024,768 | 前馈层维度 |
| num_heads | 4,4,4,8,4,4 | 注意力头数 |
| encoder_dim | 192,256,384,512,384,256 | 嵌入层维度 |
| cnn_module_kernel | 31,31,15,15,15,31 | 卷积块大小 |
| 模型 | CER | |
|---|---|---|
| 测试集 | 验证集 | |
| TDNN-LSTM-CTC | 12.90 | 11.82 |
| Conformer-T | 5.14 | 4.71 |
| Zipformer-T | 4.49 | 4.24 |
Tab. 2 CERs of different models on AISHELL-1 dataset
| 模型 | CER | |
|---|---|---|
| 测试集 | 验证集 | |
| TDNN-LSTM-CTC | 12.90 | 11.82 |
| Conformer-T | 5.14 | 4.71 |
| Zipformer-T | 4.49 | 4.24 |
| 模型 | CER | |
|---|---|---|
| 测试集 | 验证集 | |
| Conformer-T + char | 5.14 | 4.71 |
| Conformer-T + BBPE | 5.06 | 4.68 |
| Zipformer-T + char | 4.49 | 4.24 |
| Zipformer-T + BBPE | 4.37 | 4.16 |
| Zipformer-T + BBPE + CTC loss | 4.27 | 3.99 |
Tab. 3 CERs of models with different modeling units on AISHELL-1 dataset
| 模型 | CER | |
|---|---|---|
| 测试集 | 验证集 | |
| Conformer-T + char | 5.14 | 4.71 |
| Conformer-T + BBPE | 5.06 | 4.68 |
| Zipformer-T + char | 4.49 | 4.24 |
| Zipformer-T + BBPE | 4.37 | 4.16 |
| Zipformer-T + BBPE + CTC loss | 4.27 | 3.99 |
| 模型 | CER | |
|---|---|---|
| 测试集 | 验证集 | |
| Zipformer-T + BBPE + CTC loss | 4.27 | 3.99 |
Zipformer-T + BBPE + CTC loss (采用RNNLM) | 4.30 | 4.02 |
Zipformer-T + BBPE + CTC loss (采用TransformerLM) | 4.26 | 3.98 |
Tab. 4 CERs of combining language models on AISHELL-1 dataset
| 模型 | CER | |
|---|---|---|
| 测试集 | 验证集 | |
| Zipformer-T + BBPE + CTC loss | 4.27 | 3.99 |
Zipformer-T + BBPE + CTC loss (采用RNNLM) | 4.30 | 4.02 |
Zipformer-T + BBPE + CTC loss (采用TransformerLM) | 4.26 | 3.98 |
| 1 | JELINEK F. Continuous speech recognition by statistical methods [J]. Proceedings of the IEEE, 1976, 64(4): 532-556. |
| 2 | HANNUN A, CASE C, CASPER J, et al. Deep Speech: scaling up end-to-end speech recognition [EB/OL]. [2023-03-04]. . |
| 3 | GRAVES A, FERNÁNDEZ S, GOMEZ F, et al. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks [C]// Proceedings of the 23rd International Conference on Machine Learning. New York: ACM, 2006: 369-376. |
| 4 | SHAN C, ZHANG J, WANG Y, et al. Attention-based end-to-end speech recognition on voice search [C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2018: 4764-4768. |
| 5 | GRAVES A. Sequence transduction with recurrent neural networks [EB/OL]. [2021-11-08]. . |
| 6 | GONG C, TAN X, HE D, et al. Sentence-wise smooth regularization for sequence to sequence learning [C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2019: 6449-6456. |
| 7 | SENNRICH R, HADDOW B, BIRCH A. Neural machine translation of rare words with subword units [C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2016: 1715-1725. |
| 8 | BAZZI I. Modeling out-of-vocabulary words for robust speech recognition [D]. Cambridge: Massachusetts Institute of Technology, 2002: 47-79. |
| 9 | WANG C, CHO K, GU J. Neural machine translation with byte-level subwords [C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 9154-9160. |
| 10 | DENG L, HSIAO R, GHOSHAL A. Bilingual end-to-end ASR with byte-level subwords [C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 6417-6421. |
| 11 | YAO Z, GUO L, YANG X, et al. Zipformer: a faster and better encoder for automatic speech recognition [EB/OL]. [2024-06-20]. . |
| 12 | SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems — Volume 2. Cambridge: MIT Press, 2014: 3104-3112. |
| 13 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| 14 | BU H, DU J, NA X, et al. AISHELL-1: an open-source Mandarin speech corpus and a speech recognition baseline [C]// Proceedings of the 20th Conference of the Oriental Chapter of the International Coordinating Committee on Speech Databases and Speech I/O Systems and Assessment. Piscataway: IEEE, 2017: 1-5. |
| 15 | GULATI A, QIN J, CHIU C C, et al. Conformer: convolution-augmented transformer for speech recognition [C]// Proceedings of the INTERSPEECH 2022. [S.l.]: International Speech Communication Association, 2022: 5036-5040. |
| 16 | 许鸿奎,卢江坤,张子枫,等.结合Conformer与N-gram的中文语音识别[J].计算机系统应用, 2022, 31(7): 194-202. |
| XU H K, LU J K, ZHANG Z F, et al. Chinese speech recognition combining Conformer and N-gram [J]. Computer Systems and Applications, 2022, 31(7): 194-202. | |
| 17 | BA J L, KIROS J R, HINTON G E. Layer normalization [EB/OL]. [2023-05-03]. . |
| 18 | KINGMA D P, BA J L. Adam: a method for stochastic optimization [EB/OL]. [2023-04-18]. . |
| 19 | GHODSI M, LIU X, APFEL J, et al. RNN-Transducer with stateless prediction network [C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 7049-7053. |
| 20 | 陈戈,谢旭康,孙俊,等.使用Conformer增强的混合CTC/Attention端到端中文语音识别[J].计算机工程与应用, 2023, 59(4): 97-103. |
| CHEN G, XIE X K, SUN J, et al. Hybrid CTC/Attention end-to-end Chinese speech recognition enhanced by Conformer [J]. Computer Engineering and Applications, 2023, 59(4): 97-103. | |
| 21 | POVEY D, GHOSHAL A, BOULIANNE G, et al. The Kaldi speech recognition toolkit [EB/OL]. [2023-04-18]. . |
| 22 | 杭州电子科技大学.基于Fbank特征和MFCC特征融合的声纹识别方法: 202110586134.6 [P]. 2021-09-14. |
| Hangzhou Dianzi University. Method for voiceprint recognition based on fusion of Fbank features and MFCC features: 202110586134.6 [P]. 2021-09-14. | |
| 23 | KO T, PEDDINTI V, POVEY D, et al. Audio augmentation for speech recognition [C]// Proceedings of the INTERSPEECH 2015. [S.l.]: International Speech Communication Association, 2015: 3586-3589. |
| 24 | PARK D S, CHAN W, ZHANG Y, et al. SpecAugment: a simple data augmentation method for automatic speech recognition [C]// Proceedings of the INTERSPEECH 2019. [S.l.]: International Speech Communication Association, 2019: 2613-2617. |
| 25 | MICIKEVICIUS P, NARANG S, ALBEN J, et al. Mixed precision training [EB/OL]. [2023-06-18]. . |
| 26 | JAIN M, SCHUBERT K, MAHADEOKAR J, et al. RNN-T for latency controlled ASR with improved beam search [EB/OL]. [2023-10-21]. . |
| 27 | WAIBEL A, HANAZAWA T, HINTON G, et al. Phoneme recognition using time-delay neural networks [M]// CHAUVIN Y, RUMELHART D E. Backpropagation: theory, architectures, and applications. New York: Psychology Press, 1995: 35-61. |
| [1] | Hua LAI, Tong SUN, Wenjun WANG, Zhengtao YU, Shengxiang GAO, Ling DONG. Text punctuation restoration for Vietnamese speech recognition with multimodal features [J]. Journal of Computer Applications, 2024, 44(2): 418-423. |
| [2] | Jianqing GAO, Yanhui TU, Feng MA, Zhonghua FU. Progressive ratio mask-based adaptive noise estimation method [J]. Journal of Computer Applications, 2023, 43(4): 1303-1308. |
| [3] | Cong LIU, Genshun WAN, Jianqing GAO, Zhonghua FU. End-to-end speech recognition method based on prosodic features [J]. Journal of Computer Applications, 2023, 43(2): 380-384. |
| [4] | Yutang JIN, Yisong WANG, Lihui WANG, Pengli ZHAO. Speech enhancement algorithm based on multi-scale ladder-type time-frequency Conformer GAN [J]. Journal of Computer Applications, 2023, 43(11): 3607-3615. |
| [5] | Lei YANG, Hongdong ZHAO, Kuaikuai YU. End-to-end speech emotion recognition based on multi-head attention [J]. Journal of Computer Applications, 2022, 42(6): 1869-1875. |
| [6] | Caitong BAI, Xiaolong CUI, Huiji ZHENG, Ai LI. Robust speech recognition technology based on self-supervised knowledge transfer [J]. Journal of Computer Applications, 2022, 42(10): 3217-3223. |
| [7] | GUO Shuai, SU Yang. Encrypted traffic classification method based on data stream [J]. Journal of Computer Applications, 2021, 41(5): 1386-1391. |
| [8] | WU Saisai, LIANG Xiaohe, XIE Nengfu, ZHOU Ailian, HAO Xinning. Annotation method for joint extraction of domain-oriented entities and relations [J]. Journal of Computer Applications, 2021, 41(10): 2858-2863. |
| [9] | CHEN Xiukai, LU Zhihua, ZHOU Yu. Speech separation algorithm based on convolutional encoder decoder and gated recurrent unit [J]. Journal of Computer Applications, 2020, 40(7): 2137-2141. |
| [10] | HU Xuemin, TONG Xiuchi, GUO Lin, ZHANG Ruohan, KONG Li. End-to-end autonomous driving model based on deep visual attention neural network [J]. Journal of Computer Applications, 2020, 40(7): 1926-1931. |
| [11] | CHEN Yuna, SHI Xiaodong. Improving machine simultaneous interpretation by punctuation recovery [J]. Journal of Computer Applications, 2020, 40(4): 972-977. |
| [12] | JIA Yongchao, HE Xiaowei, ZHENG Zhonglong. Object tracking algorithm combining re-detection mechanism and convolutional regression network [J]. Journal of Computer Applications, 2019, 39(8): 2247-2251. |
| [13] | QIU Zeyu, QU Dan, ZHANG Lianhai. End-to-end speech synthesis based on WaveNet [J]. Journal of Computer Applications, 2019, 39(5): 1325-1329. |
| [14] | PAN Peike, WANG Yan, LUO Yong, ZHOU Jiliu. Automatic segmentation of nasopharyngeal neoplasm in MR image based on U-net model [J]. Journal of Computer Applications, 2019, 39(4): 1183-1188. |
| [15] | LIU Weibo, ZENG Qingning, BU Yuting, ZHENG Zhanheng. Speech recognition method based on dual micro-array and convolutional neural network [J]. Journal of Computer Applications, 2019, 39(11): 3268-3273. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||