


Journal of Computer Applications ›› 2022, Vol. 42 ›› Issue (10): 3217-3223.DOI: 10.11772/j.issn.1001-9081.2021050808
Special Issue: 多媒体计算与计算机仿真
• Multimedia computing and computer simulation • Previous Articles Next Articles
Caitong BAI1,2, Xiaolong CUI2,3, Huiji ZHENG1,2, Ai LI1,2
Received:2021-05-20
Revised:2021-09-13
Accepted:2021-09-22
Online:2022-10-14
Published:2022-10-10
Contact:
Xiaolong CUI
About author:BAI Caitong, born in 1995, M. S. candidate. His research interests include deep edge intelligence, robust speech recognition.Supported by:柏财通1,2, 崔翛龙2,3, 郑会吉1,2, 李爱1,2
通讯作者:
崔翛龙
作者简介:柏财通(1995—),男,山东济南人,硕士研究生,主要研究方向:深度边缘智能、鲁棒性语音识别;基金资助:CLC Number:
Caitong BAI, Xiaolong CUI, Huiji ZHENG, Ai LI. Robust speech recognition technology based on self-supervised knowledge transfer[J]. Journal of Computer Applications, 2022, 42(10): 3217-3223.
柏财通, 崔翛龙, 郑会吉, 李爱. 基于自监督知识迁移的鲁棒性语音识别技术[J]. 《计算机应用》唯一官方网站, 2022, 42(10): 3217-3223.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2021050808

Fig. 1 Overall structure of the proposed model
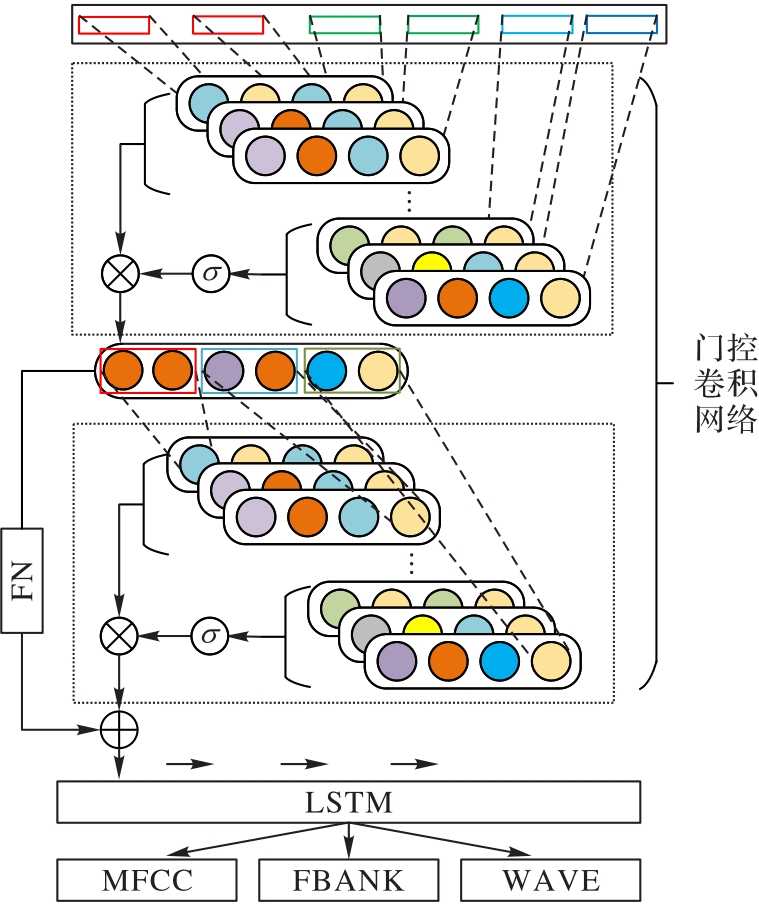
Fig. 2 Structure of feature extraction front-end

Fig. 3 Structure of speech recognition back-end
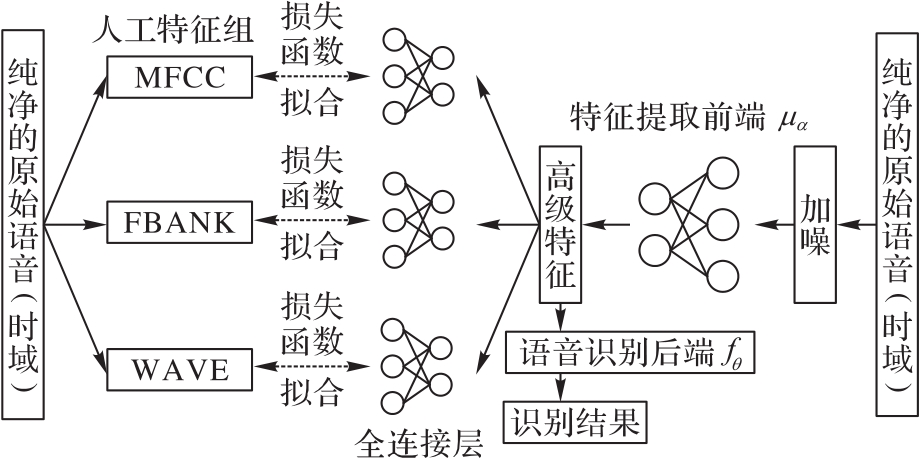
Fig. 4 Training structure of GSDNet model
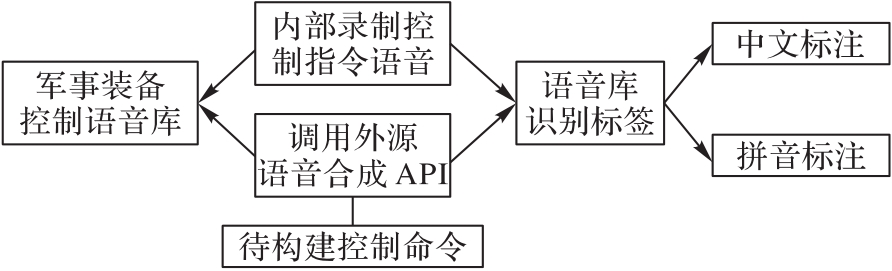
Fig. 5 Logic diagram of dataset construction method
| 模块 | 尺寸参数 | 参数量/106 |
|---|---|---|
| 输入张量 | (30,1,32 000) | — |
| Gated Block 1 | (1,64,1,1) | 64 |
| Gated Block 2 | (64,64,20,10) | 4 096 |
| Gated Block 3 | (64,128,11,2) | 8 192 |
| Gated Block 4 | (128,128,11,1) | 16 384 |
| Gated Block 5 | (128,256,11,2) | 32 768 |
| Gated Block 6 | (256,256,11,1) | 65 536 |
| Gated Block 7 | (256,512,11,2) | 131 072 |
| Gated Block 8 | (512,512,11,2) | 262 144 |
| LSTM | (512) | — |
| MFCC | (1,256) | — |
| FBANK | (1,256) | — |
| WAVE | (1,256) | — |
Tab. 1 Feature extraction front-end network parameters
| 模块 | 尺寸参数 | 参数量/106 |
|---|---|---|
| 输入张量 | (30,1,32 000) | — |
| Gated Block 1 | (1,64,1,1) | 64 |
| Gated Block 2 | (64,64,20,10) | 4 096 |
| Gated Block 3 | (64,128,11,2) | 8 192 |
| Gated Block 4 | (128,128,11,1) | 16 384 |
| Gated Block 5 | (128,256,11,2) | 32 768 |
| Gated Block 6 | (256,256,11,1) | 65 536 |
| Gated Block 7 | (256,512,11,2) | 131 072 |
| Gated Block 8 | (512,512,11,2) | 262 144 |
| LSTM | (512) | — |
| MFCC | (1,256) | — |
| FBANK | (1,256) | — |
| WAVE | (1,256) | — |
| 模块 | 尺寸参数 | 参数量/106 |
|---|---|---|
| 输入张量 | (64,161,601) | 6.0 |
| Gated Block 1 | (161,500,48,2,97) | 3.8 |
| 7*Gated Block 2 | (250,500,7,1) | 6.1 |
| Gated Block 3 | (250,2 000,32,1) | 16.0 |
| Gated Block 4 | (1 000,2 000,1,1) | 2.0 |
| Conv1d | (1 000,Output Units,1,1) | — |
| 中间张量 | (64,1 000, Output Units) | — |
| LSTM | (1 000,Dictionary Dim,2) | — |
| Softmax | (Output Units, Dictionary Dim) | — |
| 集束搜索器 | 3 | — |
Tab. 2 Speech recognition back-end parameters
| 模块 | 尺寸参数 | 参数量/106 |
|---|---|---|
| 输入张量 | (64,161,601) | 6.0 |
| Gated Block 1 | (161,500,48,2,97) | 3.8 |
| 7*Gated Block 2 | (250,500,7,1) | 6.1 |
| Gated Block 3 | (250,2 000,32,1) | 16.0 |
| Gated Block 4 | (1 000,2 000,1,1) | 2.0 |
| Conv1d | (1 000,Output Units,1,1) | — |
| 中间张量 | (64,1 000, Output Units) | — |
| LSTM | (1 000,Dictionary Dim,2) | — |
| Softmax | (Output Units, Dictionary Dim) | — |
| 集束搜索器 | 3 | — |
| 结构变化 | THCHS-30 | AISHELL-1 | ST-CMDS | |||
|---|---|---|---|---|---|---|
| Clean | Noise | Clean | Noise | Clean | Noise | |
| Base structure | 0.320 | 0.370 | 0.320 | 0.400 | 0.450 | 0.580 |
| +gated cnn | 0.200 | 0.230 | 0.240 | 0.260 | 0.443 | 0.460 |
| +50 hours | 0.130 | 0.160 | 0.130 | 0.170 | 0.153 | 0.260 |
| +skip conection | 0.180 | 0.220 | 0.220 | 0.240 | 0.430 | 0.400 |
| +new workers | 0.160 | 0.140 | 0.120 | 0.140 | 0.150 | 0.200 |
Tab. 3 Experimental results of model performance (word error rate) affected by artificial knowledge transfer module
| 结构变化 | THCHS-30 | AISHELL-1 | ST-CMDS | |||
|---|---|---|---|---|---|---|
| Clean | Noise | Clean | Noise | Clean | Noise | |
| Base structure | 0.320 | 0.370 | 0.320 | 0.400 | 0.450 | 0.580 |
| +gated cnn | 0.200 | 0.230 | 0.240 | 0.260 | 0.443 | 0.460 |
| +50 hours | 0.130 | 0.160 | 0.130 | 0.170 | 0.153 | 0.260 |
| +skip conection | 0.180 | 0.220 | 0.220 | 0.240 | 0.430 | 0.400 |
| +new workers | 0.160 | 0.140 | 0.120 | 0.140 | 0.150 | 0.200 |
| 提取特征器 | THCHS-30 | AISHELL-1 | ST-CMDS | |||
|---|---|---|---|---|---|---|
| Clean | Noise | Clean | Noise | Clean | Noise | |
| MFCC | 0.280 | 0.310 | 0.190 | 0.230 | 0.201 | 0.450 |
| FBANK | 0.300 | 0.400 | 0.200 | 0.300 | 0.300 | 0.500 |
| WAVE | 0.320 | 0.430 | 0.210 | 0.360 | 0.370 | 0.580 |
| GSDNet+(Supervised) | 0.120 | 0.150 | 0.130 | 0.156 | 0.152 | 0.260 |
| GSDNet+(Finetuned) | 0.110 | 0.130 | 0.120 | 0.146 | 0.142 | 0.200 |
| GSDNet+(Frozen) | 0.123 | 0.160 | 0.126 | 0.160 | 0.150 | 0.270 |
Tab. 4 Performance (word error rate) comparison of self-supervised feature extraction and manual feature extraction
| 提取特征器 | THCHS-30 | AISHELL-1 | ST-CMDS | |||
|---|---|---|---|---|---|---|
| Clean | Noise | Clean | Noise | Clean | Noise | |
| MFCC | 0.280 | 0.310 | 0.190 | 0.230 | 0.201 | 0.450 |
| FBANK | 0.300 | 0.400 | 0.200 | 0.300 | 0.300 | 0.500 |
| WAVE | 0.320 | 0.430 | 0.210 | 0.360 | 0.370 | 0.580 |
| GSDNet+(Supervised) | 0.120 | 0.150 | 0.130 | 0.156 | 0.152 | 0.260 |
| GSDNet+(Finetuned) | 0.110 | 0.130 | 0.120 | 0.146 | 0.142 | 0.200 |
| GSDNet+(Frozen) | 0.123 | 0.160 | 0.126 | 0.160 | 0.150 | 0.270 |
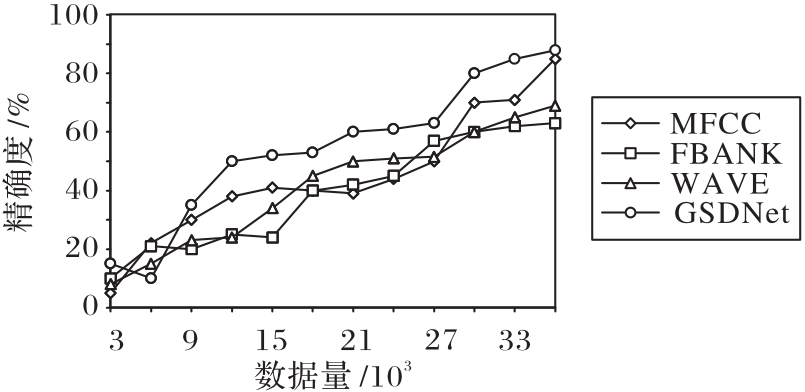
Fig. 6 Data volume vs performance comparison
| 训练方式 | 词错率 |
|---|---|
| 线性 | 0.4 |
| 交叉 | 0.2 |
Tab. 5 Word error rate comparison of linear and cross -training methods
| 训练方式 | 词错率 |
|---|---|
| 线性 | 0.4 |
| 交叉 | 0.2 |

Fig. 7 Training processes of GSDNet with different loss functions
| 算法 | THCHS-30 | AISHELL-1 | ST-CMDS | |||
|---|---|---|---|---|---|---|
| Clean | Noise | Clean | Noise | Clean | Noise | |
| Baseline | 0.170 | 0.180 | 0.200 | 0.270 | 0.250 | 0.450 |
| LAS | 0.150 | 0.160 | 0.160 | 0.190 | 0.201 | 0.443 |
| CTC | 0.130 | 0.156 | 0.140 | 0.160 | 0.160 | 0.420 |
| GSDNet | 0.120 | 0.150 | 0.130 | 0.156 | 0.152 | 0.260 |
Tab. 6 Performance comparison of different algorithms
| 算法 | THCHS-30 | AISHELL-1 | ST-CMDS | |||
|---|---|---|---|---|---|---|
| Clean | Noise | Clean | Noise | Clean | Noise | |
| Baseline | 0.170 | 0.180 | 0.200 | 0.270 | 0.250 | 0.450 |
| LAS | 0.150 | 0.160 | 0.160 | 0.190 | 0.201 | 0.443 |
| CTC | 0.130 | 0.156 | 0.140 | 0.160 | 0.160 | 0.420 |
| GSDNet | 0.120 | 0.150 | 0.130 | 0.156 | 0.152 | 0.260 |
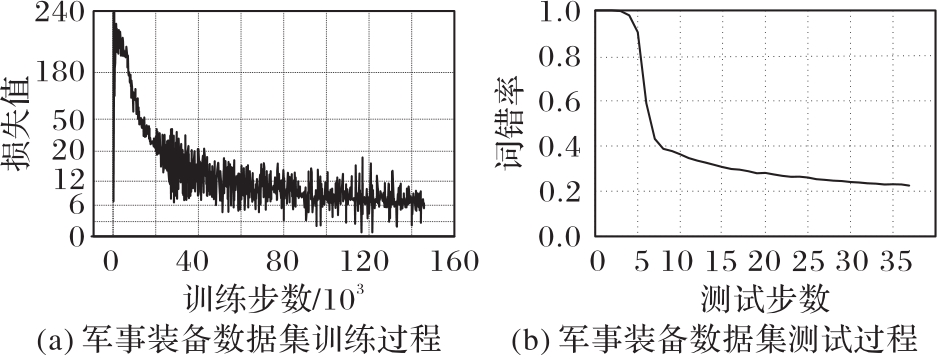
Fig. 8 Training results of the proposed model
| 1 | HE Y Z, SAINATH T N, PRABHAVALKAR R, et al. Streaming end-to-end speech recognition for mobile devices [C]// Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2019: 6381-6385. 10.1109/icassp.2019.8682336 |
| 2 | JUANG B H, RABINER L R. Hidden Markov models for speech recognition[J]. Technometrics, 1991, 33(3): 251-272. 10.1080/00401706.1991.10484833 |
| 3 | GRAVES A, SCHMIDHUBER J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures[J]. Neural Networks, 2005, 18(5/6): 602-610. 10.1016/j.neunet.2005.06.042 |
| 4 | HINTON G, DENG L, YU D, et al. Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups[J]. IEEE Signal Processing Magazine, 2012, 29(6): 82-97. 10.1109/msp.2012.2205597 |
| 5 | CHAN W, JAITLY N, LE Q, et al. Listen, attend and spell: a neural network for large vocabulary conversational speech recognition [C]// Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2016: 4960-4964. 10.1109/icassp.2016.7472621 |
| 6 | GRAVES A, FERNÁNDEZ S, GOMEZ F, et al. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks [C]// Proceedings of the 23rd International Conference on Machine Learning. New York: ACM, 2006: 369-376. 10.1145/1143844.1143891 |
| 7 | GRAVES A. Sequence transduction with recurrent neural networks[EB/OL]. (2012-11-14) [2021-05-01]. . 10.1007/978-3-642-24797-2_3 |
| 8 | JAITLY N, SUSSILLO D, LE Q V, et al. A neural transducer[EB/OL]. (2016-08-04) [2021-05-01]. . |
| 9 | CHIU C C, RAFFEL C. Monotonic chunkwise attention[EB/OL]. (2018-02-23) [2021-05-01]. . |
| 10 | ZHANG Z X, GEIGER J, POHJALAINEN J, et al. Deep learning for environmentally robust speech recognition: an overview of recent developments[J]. ACM Transactions on Intelligent Systems and Technology, 2018, 9(5): No.49. 10.1145/3178115 |
| 11 | 柏财通,高志强,李爱,等.基于门控网络的军事装备控制指令语音识别研究[J].计算机工程, 2021, 47(7): 301-306. 10.19678/j.issn.1000-3428.0058590 |
| BAI C T, GAO Z Q, LI A, et al. Research on voice recognition of military equipment control commands based on gated network[J]. Computer Engineering, 2021, 47(7): 301-306. 10.19678/j.issn.1000-3428.0058590 | |
| 12 | ZHAO X J, SHAO Y, WANG D L. CASA-based robust speaker identification[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20(5): 1608-1616. 10.1109/tasl.2012.2186803 |
| 13 | DAUPHIN Y N, FAN A, AULI M, et al. Language modeling with gated convolutional networks [C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 933-941. |
| 14 | RAVANELLI M, OMOLOGO M. Contaminated speech training methods for robust DNN-HMM distant speech recognition [C]// Proceedings of the Interspeech 2015. [S.l.]: International Speech Communication Association, 2015: 756-760. 10.21437/interspeech.2015-251 |
| 15 | RAVANELLI M, ZHONG J Y, PASCUAL S, et al. Multi-task self-supervised learning for robust speech recognition [C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 6989-6993. 10.1109/icassp40776.2020.9053569 |
| 16 | ALLEN J B, BERKLEY D A. Image method for efficiently simulating small-room acoustics[J]. The Journal of the Acoustical Society of America, 1979, 65(4): 943-950. 10.1121/1.382599 |
| 17 | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 18 | HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. 10.1162/neco.1997.9.8.1735 |
| 19 | POLS L C W. Spectral analysis and identification of Dutch vowels in monosyllabic words[D]. Amsterdam: University of Amsterdam, 1977: 152. |
| 20 | KINGMA D P, BA J L. Adam: a method for stochastic optimization[EB/OL]. (2017-01-30) [2021-05-01]. . |
| 21 | PASZKE A, GROSS S, MASSA F, et al. PyTorch: an imperative style, high-performance deep learning library[C/OL]// Proceedings of the 33rd Conference on Neural Information Processing Systems. [2021-05-01]. . 10.7551/mitpress/11474.003.0014 |
| 22 | WANG D, ZHANG X W. THCHS-30: a free Chinese speech corpus[EB/OL]. (2015-12-10) [2021-05-01]. . |
| 23 | BU H, DU J Y, NA X Y, et al. AISHELL-1: an open-source Mandarin speech corpus and a speech recognition baseline [C]// Proceedings of the 20th Conference of the Oriental Chapter of the International Coordinating Committee on Speech Databases and Speech I/O Systems and Assessment. Piscataway: IEEE, 2017: 1-5. 10.1109/icsda.2017.8384449 |
| 24 | ST-CMDS- 20170001_1, Free ST Chinese Mandarin corpus[DS/OL]. [2021-05-01]. . |
| 25 | KIM S, HORI T, WATANABE S. Joint CTC-attention based end-to-end speech recognition using multi-task learning [C]// Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2017: 4835-4839. 10.1109/icassp.2017.7953075 |
| 26 | KLAKOW D, PETERS J. Testing the correlation of word error rate and perplexity[J]. Speech Communication, 2002, 38(1/2): 19-28. 10.1016/s0167-6393(01)00041-3 |
| 27 | BA J L, KIROS J R, HINTON G E. Layer normalization[EB/OL]. (2016-07-21) [2021-05-01]. . |
| 28 | HINTON G E, SRIVASTAVA N, KRIZHEVSKY A, et al. Improving neural networks by preventing co-adaptation of feature detectors[EB/OL]. (2012-07-03) [2021-05-01]. . |
| [1] | Tingjie TANG, Jiajin HUANG, Jin QIN. Session-based recommendation with graph auxiliary learning [J]. Journal of Computer Applications, 2024, 44(9): 2711-2718. |
| [2] | Jiong WANG, Taotao TANG, Caiyan JIA. PAGCL: positive augmentation graph contrastive learning recommendation method without negative sampling [J]. Journal of Computer Applications, 2024, 44(5): 1485-1492. |
| [3] | Guijin HAN, Xinyuan ZHANG, Wentao ZHANG, Ya HUANG. Self-supervised image registration algorithm based on multi-feature fusion [J]. Journal of Computer Applications, 2024, 44(5): 1597-1604. |
| [4] | Yue WU, Hangqi DING, Hao HE, Shunjie BI, Jun JIANG, Maoguo GONG, Qiguang MIAO, Wenping MA. Research review of multitasking optimization algorithms and applications [J]. Journal of Computer Applications, 2024, 44(5): 1338-1347. |
| [5] | Jiawei ZHAO, Xuefeng CHEN, Liang FENG, Yaqing HOU, Zexuan ZHU, Yew‑Soon Ong. Review of evolutionary multitasking from the perspective of optimization scenarios [J]. Journal of Computer Applications, 2024, 44(5): 1325-1337. |
| [6] | Rong HUANG, Junjie SONG, Shubo ZHOU, Hao LIU. Image aesthetic quality evaluation method based on self-supervised vision Transformer [J]. Journal of Computer Applications, 2024, 44(4): 1269-1276. |
| [7] | Yuning ZHANG, Abudukelimu ABULIZI, Tisheng MEI, Chun XU, Maierdana MAIMAITIREYIMU, Halidanmu ABUDUKELIMU, Yutao HOU. Anomaly detection method for skeletal X-ray images based on self-supervised feature extraction [J]. Journal of Computer Applications, 2024, 44(1): 175-181. |
| [8] | Xiaobing WANG, Xiongwei ZHANG, Tieyong CAO, Yunfei ZHENG, Yong WANG. Self-distillation object segmentation method via scale-attention knowledge transfer [J]. Journal of Computer Applications, 2024, 44(1): 129-137. |
| [9] | Shengwei MA, Ruizhang HUANG, Lina REN, Chuan LIN. Structured deep text clustering model based on multi-layer semantic fusion [J]. Journal of Computer Applications, 2023, 43(8): 2364-2369. |
| [10] | Zhongbo HU, Xupeng WANG. Multifactorial backtracking search optimization algorithm for solving automated test case generation problem [J]. Journal of Computer Applications, 2023, 43(4): 1214-1219. |
| [11] | Lei LIU, Peng WU, Kai XIE, Beizhi CHENG, Guanqun SHENG. Parking space detection method based on self-supervised learning HOG prediction auxiliary task [J]. Journal of Computer Applications, 2023, 43(12): 3933-3940. |
| [12] | DAI Yurou, YANG Qing, ZHANG Fengli, ZHOU Fan. Trajectory prediction model of social network users based on self-supervised learning [J]. Journal of Computer Applications, 2021, 41(9): 2545-2551. |
| [13] | WEI Chunwu, ZHAO Juanjuan, TANG Xiaoxian, QIANG Yan. Knowledge extraction method for follow-up data based on multi-term distillation network [J]. Journal of Computer Applications, 2021, 41(10): 2871-2878. |
| [14] | WU Chongshu, LIN Lin, XUE Yunjing, SHI Peng. Hierarchical segmentation of pathological images based on self-supervised learning [J]. Journal of Computer Applications, 2020, 40(6): 1856-1862. |
| [15] | YU Huangyue, WANG Han, GUO Mengting. Video keyframe extraction based on users' interests [J]. Journal of Computer Applications, 2017, 37(11): 3139-3144. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||