


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (7): 2132-2137.DOI: 10.11772/j.issn.1001-9081.2024070935
• The 39th CCF National Conference of Computer Applications (CCF NCCA 2024) • Previous Articles Next Articles
Bo FENG1, Haizheng YU1( ), Hong BIAN2
), Hong BIAN2
Received:2024-07-05
Revised:2024-10-12
Accepted:2024-10-16
Online:2025-07-10
Published:2025-07-10
Contact:
Haizheng YU
About author:FENG Bo, born in 1999, M. S. candidate. His research interests include big data analytics.Supported by:
冯博1, 于海征1(), 边红2
通讯作者:
于海征
作者简介:冯博(1999—),男,山西运城人,硕士研究生,主要研究方向:大数据分析基金资助:CLC Number:
Bo FENG, Haizheng YU, Hong BIAN. Domain adaptive semantic segmentation based on masking enhanced self-training[J]. Journal of Computer Applications, 2025, 45(7): 2132-2137.
冯博, 于海征, 边红. 基于掩码增强自训练的域适应语义分割[J]. 《计算机应用》唯一官方网站, 2025, 45(7): 2132-2137.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024070935
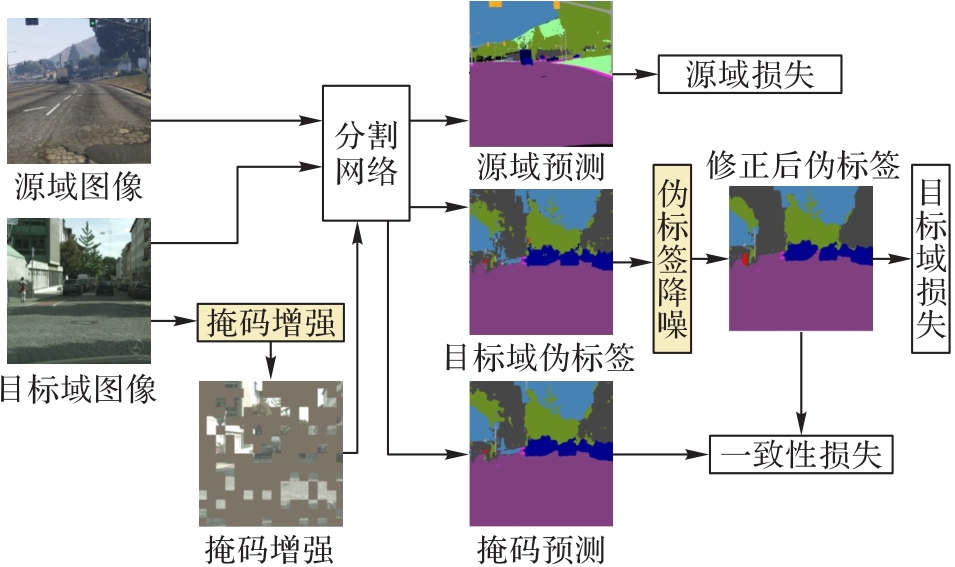
Fig. 1 Masking enhanced self-training network structure
| 类别 | IoU/% | |||
|---|---|---|---|---|
| Source only | ProDA | DACS | 本文方法 | |
| mIoU | 42.3 | 49.5 | 50.5 | 51.8 |
| road | 71.3 | 78.9 | 80.1 | 80.5 |
| sidewalk | 26.1 | 32.7 | 36.7 | 37.4 |
| building | 71.9 | 78.3 | 78.2 | 78.3 |
| wall | 27.7 | 33.4 | 33.1 | 35.4 |
| fence | 35.7 | 40.3 | 38.3 | 41.1 |
| pole | 19.2 | 24.9 | 36.1 | 38.3 |
| light | 54.9 | 60.3 | 61.0 | 63.5 |
| sign | 33.5 | 39.5 | 40.3 | 42.0 |
| veg | 73.4 | 80.1 | 79.5 | 78.1 |
| terrain | 49.7 | 55.5 | 58.3 | 60.1 |
| sky | 63.3 | 70.2 | 72.0 | 73.4 |
| person | 43.6 | 50.7 | 54.4 | 56.5 |
| rider | 45.2 | 57.0 | 55.2 | 54.7 |
| car | 45.1 | 53.3 | 49.9 | 50.5 |
| truck | 27.2 | 40.9 | 39.1 | 45.8 |
| bus | 18.9 | 23.7 | 25.5 | 25.6 |
| train | 32.4 | 41.7 | 43.1 | 40.2 |
| mbike | 37.1 | 44.5 | 43.2 | 45.1 |
| bicycle | 27.5 | 34.9 | 36.3 | 38.0 |
Tab. 1 Semantic segmentation results of different methods in GTA5→Cityscapes domain adaptation task
| 类别 | IoU/% | |||
|---|---|---|---|---|
| Source only | ProDA | DACS | 本文方法 | |
| mIoU | 42.3 | 49.5 | 50.5 | 51.8 |
| road | 71.3 | 78.9 | 80.1 | 80.5 |
| sidewalk | 26.1 | 32.7 | 36.7 | 37.4 |
| building | 71.9 | 78.3 | 78.2 | 78.3 |
| wall | 27.7 | 33.4 | 33.1 | 35.4 |
| fence | 35.7 | 40.3 | 38.3 | 41.1 |
| pole | 19.2 | 24.9 | 36.1 | 38.3 |
| light | 54.9 | 60.3 | 61.0 | 63.5 |
| sign | 33.5 | 39.5 | 40.3 | 42.0 |
| veg | 73.4 | 80.1 | 79.5 | 78.1 |
| terrain | 49.7 | 55.5 | 58.3 | 60.1 |
| sky | 63.3 | 70.2 | 72.0 | 73.4 |
| person | 43.6 | 50.7 | 54.4 | 56.5 |
| rider | 45.2 | 57.0 | 55.2 | 54.7 |
| car | 45.1 | 53.3 | 49.9 | 50.5 |
| truck | 27.2 | 40.9 | 39.1 | 45.8 |
| bus | 18.9 | 23.7 | 25.5 | 25.6 |
| train | 32.4 | 41.7 | 43.1 | 40.2 |
| mbike | 37.1 | 44.5 | 43.2 | 45.1 |
| bicycle | 27.5 | 34.9 | 36.3 | 38.0 |
| 类别 | IoU/% | |||
|---|---|---|---|---|
| Source only | ProDA | DACS | 本文方法 | |
| mIoU | 37.4 | 48.5 | 49.1 | 50.3 |
| road | 46.5 | 78.5 | 73.1 | 75.0 |
| sidewalk | 14.1 | 31.1 | 29.3 | 32.3 |
| building | 65.2 | 69.9 | 72.7 | 72.3 |
| light | 27.4 | 35.9 | 38.4 | 40.1 |
| sign | 32.5 | 36.7 | 36.5 | 41.1 |
| veg | 64.9 | 69.8 | 73.2 | 72.7 |
| sky | 58.7 | 63.2 | 75.1 | 74.2 |
| person | 43.9 | 50.3 | 49.4 | 48.6 |
| rider | 8.4 | 14.7 | 12.3 | 13.6 |
| car | 31.0 | 70.2 | 62.3 | 64.9 |
| bus | 14.4 | 19.7 | 19.2 | 23.3 |
| mbike | 33.7 | 37.8 | 42.5 | 40.2 |
| bicycle | 45.7 | 52.8 | 53.9 | 55.1 |
Tab. 2 Semantic segmentation results of different methods in SYNTHIA→Cityscapes domain adaptation task
| 类别 | IoU/% | |||
|---|---|---|---|---|
| Source only | ProDA | DACS | 本文方法 | |
| mIoU | 37.4 | 48.5 | 49.1 | 50.3 |
| road | 46.5 | 78.5 | 73.1 | 75.0 |
| sidewalk | 14.1 | 31.1 | 29.3 | 32.3 |
| building | 65.2 | 69.9 | 72.7 | 72.3 |
| light | 27.4 | 35.9 | 38.4 | 40.1 |
| sign | 32.5 | 36.7 | 36.5 | 41.1 |
| veg | 64.9 | 69.8 | 73.2 | 72.7 |
| sky | 58.7 | 63.2 | 75.1 | 74.2 |
| person | 43.9 | 50.3 | 49.4 | 48.6 |
| rider | 8.4 | 14.7 | 12.3 | 13.6 |
| car | 31.0 | 70.2 | 62.3 | 64.9 |
| bus | 14.4 | 19.7 | 19.2 | 23.3 |
| mbike | 33.7 | 37.8 | 42.5 | 40.2 |
| bicycle | 45.7 | 52.8 | 53.9 | 55.1 |

Fig. 2 Correction effectiveness predicted of pseudo-labels on Cityscapes validation set
| 方法 | 掩码增强模块 | 伪标签修正模块 | mIoU/% | mIoU增益 |
|---|---|---|---|---|
| 参照组 | 42.3 | — | ||
| 方法1 | √ | 49.7 | +7.4 | |
| 方法2 | √ | 50.6 | +8.3 | |
| 方法3 | √ | √ | 51.8 | +9.5 |
Tab. 3 Ablation experiments results
| 方法 | 掩码增强模块 | 伪标签修正模块 | mIoU/% | mIoU增益 |
|---|---|---|---|---|
| 参照组 | 42.3 | — | ||
| 方法1 | √ | 49.7 | +7.4 | |
| 方法2 | √ | 50.6 | +8.3 | |
| 方法3 | √ | √ | 51.8 | +9.5 |
| [1] | LEE D H. Pseudo-Label: the simple and efficient semi-supervised learning method for deep neural networks [EB/OL]. [2024-06-12]. . |
| [2] | ZHANG P, ZHANG B, ZHANG T, et al. Prototypical pseudo label denoising and target structure learning for domain adaptive semantic segmentation [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 12409-12419. |
| [3] | HOYER L, DAI D, WANG H, et al. MIC: masked image consistency for context-enhanced domain adaptation [C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 11721-11732. |
| [4] | MANCINI M, PORZI L, BULO S R, et al. Boosting domain adaptation by discovering latent domains [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 3771-3780. |
| [5] | CARLUCCI F M, PORZI L, CAPUTO B, et al. AutoDIAL: automatic domain alignment layers [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 5067-5075. |
| [6] | GANIN Y, USTINOVA E, AJAKAN H, et al. Domain-adversarial training of neural networks [J]. Journal of Machine Learning Research, 2016, 17: 1-35. |
| [7] | GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets [C]// Proceedings of the 28th International Conference on Neural Information Processing Systems — Volume 2. Cambridge: MIT Press, 2014: 2672-2680. |
| [8] | WANG H, SHEN T, ZHANG W, et al. Classes matter: a fine-grained adversarial approach to cross-domain semantic segmentation [C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12359. Cham: Springer, 2020: 642-659. |
| [9] | GONG R, LI W, CHEN Y, et al. DLOW: domain flow for adaptation and generalization [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 2472-2481. |
| [10] | TSAI Y H, HUNG W C, SCHULTER S, et al. Learning to adapt structured output space for semantic segmentation [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7472-7481. |
| [11] | CHEN Y, LI W, VAN GOOL L. ROAD: reality oriented adaptation for semantic segmentation of urban scenes [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7892-7901. |
| [12] | LUO Y, ZHENG L, GUAN T, et al. Taking a closer look at domain shift: category-level adversaries for semantics consistent domain adaptation [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 2502-2511. |
| [13] | DU L, TAN J, YANG H, et al. SSF-DAN: separated semantic feature based domain adaptation network for semantic segmentation [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 982-991. |
| [14] | WANG Z, YU M, WEI Y, et al. Differential treatment for stuff and things: a simple unsupervised domain adaptation method for semantic segmentation [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 12632-12641. |
| [15] | HOFFMAN J, WANG D, YU F, et al. FCNs in the wild: pixel-level adversarial and constraint-based adaptation [EB/OL]. [2024-06-12]. . |
| [16] | SANKARANARAYANAN S, BALAJI Y, JAIN A, et al. Learning from synthetic data: addressing domain shift for semantic segmentation [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 3752-3761. |
| [17] | ZOU Y, YU Z, VIJAYA KUMAR B V K, et al. Unsupervised domain adaptation for semantic segmentation via class-balanced self-training [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11207. Cham: Springer, 2018: 297-313. |
| [18] | VU T H, JAIN H, BUCHER M, et al. ADVENT: adversarial entropy minimization for domain adaptation in semantic segmentation [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 2512-2521. |
| [19] | YANG Y, SOATTO S. FDA: Fourier domain adaptation for semantic segmentation [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 4084-4094. |
| [20] | SAKARIDIS C, DAI D, HECKER S, et al. Model adaptation with synthetic and real data for semantic dense foggy scene understanding [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11217. Cham: Springer, 2018: 707-724. |
| [21] | ZOU Y, YU Z, LIU X, et al. Confidence regularized self-training [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 5981-5990. |
| [22] | ARASLANOV N, ROTH S. Self-supervised augmentation consistency for adapting semantic segmentation [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 15379-15389. |
| [23] | MELAS-KYRIAZI L, MANRAI A K. PixMatch: unsupervised domain adaptation via pixelwise consistency training [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 12430-12440. |
| [24] | SOHN K, BERTHELOT D, LI C L, et al. FixMatch: simplifying semi-supervised learning with consistency and confidence [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc, 2020: 596-608. |
| [25] | LI Y, YUAN L, VASCONCELOS N. Bidirectional learning for domain adaptation of semantic segmentation [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 6929-6938. |
| [26] | PIZZATI F, DE CHARETTE R, ZACCARIA M, et al. Domain bridge for unpaired image-to-image translation and unsupervised domain adaptation [C]// Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2020: 2979-2987. |
| [27] | HUO X, XIE L, HU H, et al. Domain-agnostic prior for transfer semantic segmentation [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 7065-7075. |
| [28] | HOYER L, DAI D, VAN GOOL L. DAFormer: improving network architectures and training strategies for domain-adaptive semantic segmentation [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 9914-9925. |
| [1] | Yuyang SUN, Minjie ZHANG, Jie HU. Zero-shot dialogue state tracking domain transfer model based on semantic prefix-tuning [J]. Journal of Computer Applications, 2025, 45(7): 2221-2228. |
| [2] | Yingtao CHEN, Kangkang FANG, Jin’ao ZHANG, Haoran LIANG, Huanbin GUO, Zhaowen QIU. Segmentation network of coronary artery structure from CT angiography images based on multi-scale spatial features [J]. Journal of Computer Applications, 2025, 45(6): 2007-2015. |
| [3] | Meirong DING, Jinxin ZHUO, Yuwu LU, Qinglong LIU, Jicong LANG. Domain adaptation integrating environment label smoothing and nuclear norm discrepancy [J]. Journal of Computer Applications, 2025, 45(4): 1130-1138. |
| [4] | Yang ZHOU, Hui LI. Remote sensing image building extraction network based on dual promotion of semantic and detailed features [J]. Journal of Computer Applications, 2025, 45(4): 1310-1316. |
| [5] | Chunxia LIU, Hanying XU, Gaimei GAO, Weichao DANG, Zilu LI. Smart contract vulnerability detection method based on echo state network [J]. Journal of Computer Applications, 2025, 45(1): 153-161. |
| [6] | Feiyu ZHAI, Handa MA. Hybrid classical-quantum classification model based on DenseNet [J]. Journal of Computer Applications, 2024, 44(6): 1905-1910. |
| [7] | Hongtian LI, Xinhao SHI, Weiguo PAN, Cheng XU, Bingxin XU, Jiazheng YUAN. Few-shot object detection via fusing multi-scale and attention mechanism [J]. Journal of Computer Applications, 2024, 44(5): 1437-1444. |
| [8] | Wangjun SHI, Jing WANG, Xiaojun NING, Youfang LIN. Sleep stage classification model by meta transfer learning in few-shot scenarios [J]. Journal of Computer Applications, 2024, 44(5): 1445-1451. |
| [9] | Pengfei ZHANG, Litao HAN, Hengjian FENG, Hongmei LI. Point cloud semantic segmentation based on attention mechanism and global feature optimization [J]. Journal of Computer Applications, 2024, 44(4): 1086-1092. |
| [10] | Haoran WANG, Dan YU, Yuli YANG, Yao MA, Yongle CHEN. Domain transfer intrusion detection method for unknown attacks on industrial control systems [J]. Journal of Computer Applications, 2024, 44(4): 1158-1165. |
| [11] | Wei LI, Ling CHEN, Xiuyuan XU, Min ZHU, Jixiang GUO, Kai ZHOU, Hao NIU, Yuchen ZHANG, Shanye YI, Yi ZHANG, Fengming LUO. Interstitial lung disease segmentation algorithm based on multi-task learning [J]. Journal of Computer Applications, 2024, 44(4): 1285-1293. |
| [12] | Boyue WANG, Yingxiang LI, Jiandan ZHONG. Segmentation network for day and night ground-based cloud images based on improved Res-UNet [J]. Journal of Computer Applications, 2024, 44(4): 1310-1316. |
| [13] | Ning WU, Yangyang LUO, Huajie XU. Semantic segmentation method for remote sensing images based on multi-scale feature fusion [J]. Journal of Computer Applications, 2024, 44(3): 737-744. |
| [14] | Xuan CAO, Tianjian LUO. Dynamic multi-domain adversarial learning method for cross-subject motor imagery EEG signals [J]. Journal of Computer Applications, 2024, 44(2): 645-653. |
| [15] | Yongjiang LIU, Bin CHEN. Pixel-level unsupervised industrial anomaly detection based on multi-scale memory bank [J]. Journal of Computer Applications, 2024, 44(11): 3587-3594. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||