


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (7): 2208-2215.DOI: 10.11772/j.issn.1001-9081.2023070990
• Multimedia computing and computer simulation • Previous Articles Next Articles
Xun SUN1, Ruifeng FENG2( ), Yanru CHEN2
), Yanru CHEN2
Received:2023-07-21
Revised:2023-09-26
Accepted:2023-09-28
Online:2023-10-26
Published:2024-07-10
Contact:
Ruifeng FENG
About author:SUN Xun, born in 1972, senior engineer.Supported by:
孙逊1, 冯睿锋2(), 陈彦如2
通讯作者:
冯睿锋
作者简介:孙逊(1972—)女,湖北武汉人,高级工程师,主要研究方向:场站智能化、物流规划、场站设计;基金资助:CLC Number:
Xun SUN, Ruifeng FENG, Yanru CHEN. Monocular 3D object detection method integrating depth and instance segmentation[J]. Journal of Computer Applications, 2024, 44(7): 2208-2215.
孙逊, 冯睿锋, 陈彦如. 基于深度与实例分割融合的单目3D目标检测方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 2208-2215.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023070990
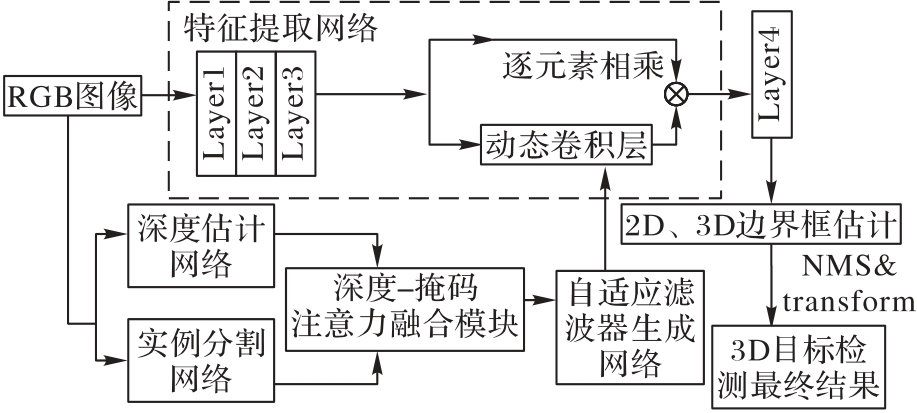
Fig. 1 Monocular 3D object detection method by fusing depth and instance segmentation
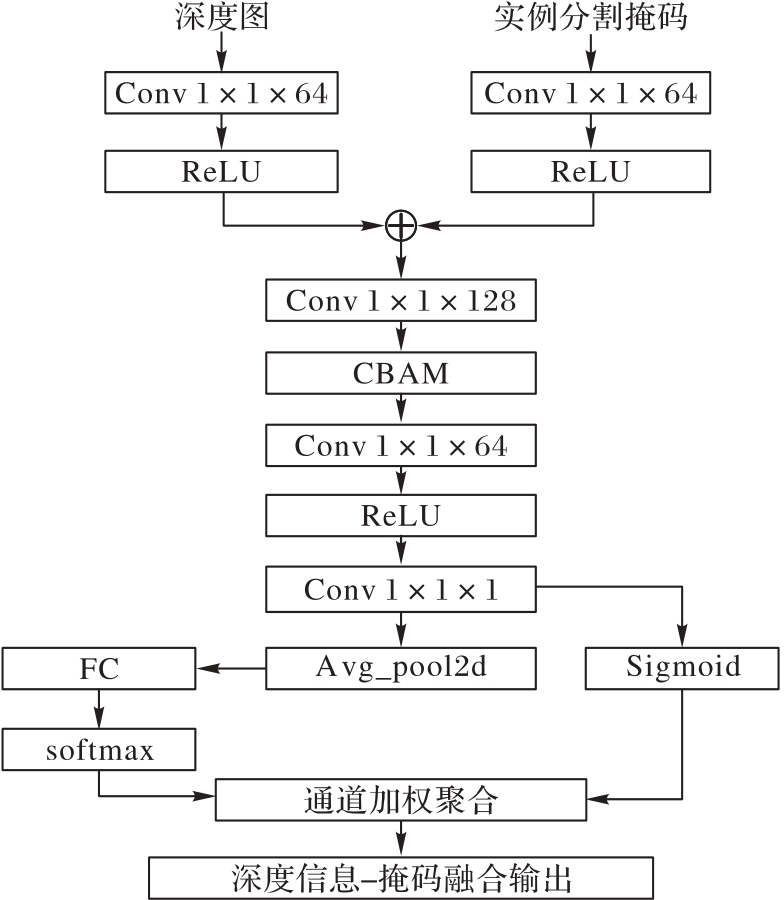
Fig. 2 DMAF module structure

Fig. 3 Traditional 2D convolution kernel (K=n)

Fig. 4 Dynamic convolution kernel
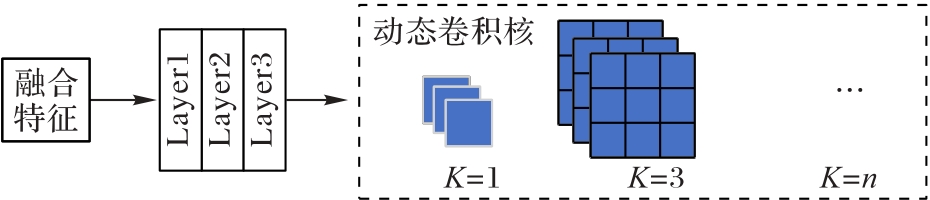
Fig. 5 Filter generation network

Fig. 6 2D bounding box representation of ground truth labels
| 项目 | 配置或版本 |
|---|---|
| CPU | Intel Xeon Gold 5320 |
| 内存 | 120 GB |
| GPU | A30×2 |
| 系统 | Ubuntu 20.04 |
| CUDA | 11.4 |
Tab. 1 Experimental configuration
| 项目 | 配置或版本 |
|---|---|
| CPU | Intel Xeon Gold 5320 |
| 内存 | 120 GB |
| GPU | A30×2 |
| 系统 | Ubuntu 20.04 |
| CUDA | 11.4 |

Fig. 7 Loss function evolution curves
| 方法 | AP3D | APBEV | ||||
|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | |
| Mono3D[ | 2.53 | 2.31 | 2.31 | 5.22 | 5.19 | 4.13 |
| MF3D[ | 10.53 | 5.69 | 5.39 | 22.03 | 13.63 | 11.60 |
| MoNoGRNet[ | 13.88 | 10.19 | 7.62 | 24.97 | 19.44 | 16.30 |
| M3D-RPN[ | 20.27 | 17.06 | 15.21 | 25.94 | 21.18 | 17.90 |
| D4LCN[ | 22.32 | 16.20 | 12.30 | 31.53 | 22.58 | 17.87 |
| SMOKE[ | 14.76 | 12.85 | 11.50 | 19.99 | 15.61 | 15.28 |
| MonoDistill[ | 18.05 | 14.98 | 13.42 | 24.26 | 18.43 | 16.95 |
| 本文方法 | 24.91 | 21.03 | 17.28 | 33.40 | 25.03 | 19.80 |
Tab. 2 Performance comparison of different methods based on aerial view and 3D bounding box (IoU≥0.7)
| 方法 | AP3D | APBEV | ||||
|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | |
| Mono3D[ | 2.53 | 2.31 | 2.31 | 5.22 | 5.19 | 4.13 |
| MF3D[ | 10.53 | 5.69 | 5.39 | 22.03 | 13.63 | 11.60 |
| MoNoGRNet[ | 13.88 | 10.19 | 7.62 | 24.97 | 19.44 | 16.30 |
| M3D-RPN[ | 20.27 | 17.06 | 15.21 | 25.94 | 21.18 | 17.90 |
| D4LCN[ | 22.32 | 16.20 | 12.30 | 31.53 | 22.58 | 17.87 |
| SMOKE[ | 14.76 | 12.85 | 11.50 | 19.99 | 15.61 | 15.28 |
| MonoDistill[ | 18.05 | 14.98 | 13.42 | 24.26 | 18.43 | 16.95 |
| 本文方法 | 24.91 | 21.03 | 17.28 | 33.40 | 25.03 | 19.80 |
| 方法 | AP3D | APBEV | ||||
|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | |
| 基线 | 18.28 | 14.67 | 13.38 | 26.38 | 19.88 | 16.27 |
| +① | 19.41 | 16.49 | 14.41 | 28.12 | 21.30 | 17.54 |
| +①+④ | 22.18 | 16.63 | 15.57 | 28.96 | 23.07 | 17.87 |
| +①+② | 20.89 | 14.92 | 14.12 | 27.42 | 21.81 | 16.82 |
| +①+②+③ | 22.39 | 17.64 | 15.77 | 29.16 | 23.22 | 18.73 |
| +①+②+③+④ | 24.91 | 21.03 | 17.28 | 33.40 | 25.03 | 19.80 |
Tab. 3 Ablation study results (IoU≥0.7)
| 方法 | AP3D | APBEV | ||||
|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | |
| 基线 | 18.28 | 14.67 | 13.38 | 26.38 | 19.88 | 16.27 |
| +① | 19.41 | 16.49 | 14.41 | 28.12 | 21.30 | 17.54 |
| +①+④ | 22.18 | 16.63 | 15.57 | 28.96 | 23.07 | 17.87 |
| +①+② | 20.89 | 14.92 | 14.12 | 27.42 | 21.81 | 16.82 |
| +①+②+③ | 22.39 | 17.64 | 15.77 | 29.16 | 23.22 | 18.73 |
| +①+②+③+④ | 24.91 | 21.03 | 17.28 | 33.40 | 25.03 | 19.80 |

Fig. 8 Visualization results on KITTI dataset
| 1 | MATURANA D, SCHERER S. VoxNet: a 3D convolutional neural network for real-time object recognition [C]// Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2015: 922-928. |
| 2 | QI C R, LIU W, WU C, et al. Frustum PointNets for 3D object detection from RGB-D data [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 918-927. |
| 3 | 周静,胡怡宇,胡成玉,等.基于点云补全和多分辨Transformer的弱感知目标检测方法[J].计算机应用, 2023, 43(7): 2155-2165. |
| ZHOU J, HU Y Y, HU C Y, et al. Weakly perceived object detection method based on point cloud completion and multi-resolution Transformer [J]. Journal of Computer Applications, 2023, 43(7): 2155-2165. | |
| 4 | WANG Y, CHAO W-L, GARG D, et al. Pseudo-LiDAR from visual depth estimation: bridging the gap in 3D object detection for autonomous driving [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 8445-8453. |
| 5 | LI P, CHEN X, SHEN S. Stereo R-CNN based 3D object detection for autonomous driving [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 7636-7644. |
| 6 | WENG X, KITANI K. Monocular 3D object detection with pseudo-lidar point cloud [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop. Piscataway: IEEE, 2019: 857-866. |
| 7 | 王凤随,熊磊,钱亚萍.联合实例深度的多尺度单目3D目标检测算法[J].激光与光电子学进展, 2023, 60(16): 1612002. |
| WANG F S, XIONG L, QIAN Y P. Multiscale monocular three-dimensional object detection algorithm incorporating instance depth [J]. Laser & Optoelectronics Progress, 2023, 60(16): 1612002. | |
| 8 | DING M, HUO Y, YI H, et al. Learning depth-guided convolutions for monocular 3D object detection [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 11669-11678. |
| 9 | MOUSAVIAN A, ANGUELOV D, FLYNN J, et al. 3D bounding box estimation using deep learning and geometry [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5632-5640. |
| 10 | QIN Z, WANG J, LU Y. MonoGRNet: a geometric reasoning network for monocular 3D object localization [J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33(1): 8851-8858. |
| 11 | BRAZIL G, LIU X. M3D-RPN: monocular 3D region proposal network for object detection [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 9286-9295. |
| 12 | GODARD C, AODHA O M, FIRMAN M, et al. Digging into self-supervised monocular depth estimation [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 3827-3837. |
| 13 | FU H, GONG M, WANG C, et al. Deep ordinal regression network for monocular depth estimation [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 2002-2011. |
| 14 | CHEN X, MA H, WAN J, et al. Multi-view 3D object detection network for autonomous driving [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6526-6534. |
| 15 | SHIRMOHAMMADI Z, NIKOOFARD A, ERSHADI G. AM3D: an accurate crosstalk probability modeling to predict channel delay in 3D ICs [J]. Microelectronics Reliability, 2019, 102: 113379. |
| 16 | READING C, HARAKEH A, CHAE J, et al. Categorical depth distribution network for monocular 3D object detection [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 8551-8560. |
| 17 | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| 18 | HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2980-2988. |
| 19 | GIRSHICK R. Fast R-CNN [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 1440-1448. |
| 20 | GEIGER A, LENZ P, URTASUN R. Are we ready for autonomous driving? the KITTI vision benchmark suite [C]// Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2012: 3354-3361. |
| 21 | CORDTS M, OMRAN M, RAMOS S, et al. The Cityscapes dataset for semantic urban scene understanding [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 3213-3223. |
| 22 | WOO S, PARK J, LEE J-Y, et al. CBAM: convolutional block attention module [C]// Proceedings of the 15th European Conference on Computer Vision. Cham: Springer, 2018: 3-19. |
| 23 | DE BRABANDERE B, JIA X, TUYTELAARS T, et al. Dynamic filter networks [C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2016: 667-675. |
| 24 | LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector [C]// Proceedings of the 14th European Conference on Computer Vision. Cham: Springer, 2016: 21-37. |
| 25 | LIN T-Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2999-3007. |
| 26 | CHEN X, KUNDU K, ZHU Y, et al. 3D object proposals for accurate object class detection [C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2015: 424-432. |
| 27 | CHEN X, KUNDU K, ZHANG Z, et al. Monocular 3D object detection for autonomous driving [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 2147-2156. |
| 28 | XU B, CHEN Z. Multi-level fusion based 3D object detection from monocular images [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 2345-2353. |
| 29 | LIU Z, WU Z, TÓTH R. Smoke: single-stage monocular 3D object detection via keypoint estimation [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2020: 4289-4298. |
| 30 | CHONG Z, MA X, ZHANG H, et al. MonoDistill: learning spatial features for monocular 3D object detection [EB/OL]. (2022-01-26) [2023-08-29]. . |
| [1] | Yunchuan HUANG, Yongquan JIANG, Juntao HUANG, Yan YANG. Molecular toxicity prediction based on meta graph isomorphism network [J]. Journal of Computer Applications, 2024, 44(9): 2964-2969. |
| [2] | Yexin PAN, Zhe YANG. Optimization model for small object detection based on multi-level feature bidirectional fusion [J]. Journal of Computer Applications, 2024, 44(9): 2871-2877. |
| [3] | Jing QIN, Zhiguang QIN, Fali LI, Yueheng PENG. Diagnosis of major depressive disorder based on probabilistic sparse self-attention neural network [J]. Journal of Computer Applications, 2024, 44(9): 2970-2974. |
| [4] | Xiyuan WANG, Zhancheng ZHANG, Shaokang XU, Baocheng ZHANG, Xiaoqing LUO, Fuyuan HU. Unsupervised cross-domain transfer network for 3D/2D registration in surgical navigation [J]. Journal of Computer Applications, 2024, 44(9): 2911-2918. |
| [5] | Shunyong LI, Shiyi LI, Rui XU, Xingwang ZHAO. Incomplete multi-view clustering algorithm based on self-attention fusion [J]. Journal of Computer Applications, 2024, 44(9): 2696-2703. |
| [6] | Yuhan LIU, Genlin JI, Hongping ZHANG. Video pedestrian anomaly detection method based on skeleton graph and mixed attention [J]. Journal of Computer Applications, 2024, 44(8): 2551-2557. |
| [7] | Yanjie GU, Yingjun ZHANG, Xiaoqian LIU, Wei ZHOU, Wei SUN. Traffic flow forecasting via spatial-temporal multi-graph fusion [J]. Journal of Computer Applications, 2024, 44(8): 2618-2625. |
| [8] | Qianhong SHI, Yan YANG, Yongquan JIANG, Xiaocao OUYANG, Wubo FAN, Qiang CHEN, Tao JIANG, Yuan LI. Multi-granularity abrupt change fitting network for air quality prediction [J]. Journal of Computer Applications, 2024, 44(8): 2643-2650. |
| [9] | Zheng WU, Zhiyou CHENG, Zhentian WANG, Chuanjian WANG, Sheng WANG, Hui XU. Deep learning-based classification of head movement amplitude during patient anaesthesia resuscitation [J]. Journal of Computer Applications, 2024, 44(7): 2258-2263. |
| [10] | Huanhuan LI, Tianqiang HUANG, Xuemei DING, Haifeng LUO, Liqing HUANG. Public traffic demand prediction based on multi-scale spatial-temporal graph convolutional network [J]. Journal of Computer Applications, 2024, 44(7): 2065-2072. |
| [11] | Zhi ZHANG, Xin LI, Naifu YE, Kaixi HU. DKP: defending against model stealing attacks based on dark knowledge protection [J]. Journal of Computer Applications, 2024, 44(7): 2080-2086. |
| [12] | Yiqun ZHAO, Zhiyu ZHANG, Xue DONG. Anisotropic travel time computation method based on dense residual connection physical information neural networks [J]. Journal of Computer Applications, 2024, 44(7): 2310-2318. |
| [13] | Yangyi GAO, Tao LEI, Xiaogang DU, Suiyong LI, Yingbo WANG, Chongdan MIN. Crowd counting and locating method based on pixel distance map and four-dimensional dynamic convolutional network [J]. Journal of Computer Applications, 2024, 44(7): 2233-2242. |
| [14] | Song XU, Wenbo ZHANG, Yifan WANG. Lightweight video salient object detection network based on spatiotemporal information [J]. Journal of Computer Applications, 2024, 44(7): 2192-2199. |
| [15] | Yajuan ZHAO, Fanjun MENG, Xingjian XU. Review of online education learner knowledge tracing [J]. Journal of Computer Applications, 2024, 44(6): 1683-1698. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||