


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (3): 815-822.DOI: 10.11772/j.issn.1001-9081.2024010013
• Frontier research and typical applications of large models • Previous Articles Next Articles
Chaofeng LU1, Ye TAO1( ), Lianqing WEN1, Fei MENG2, Xiugong QIN3, Yongjie DU4, Yunlong TIAN4
), Lianqing WEN1, Fei MENG2, Xiugong QIN3, Yongjie DU4, Yunlong TIAN4
Received:2024-01-11
Revised:2024-03-22
Accepted:2024-03-22
Online:2024-05-09
Published:2025-03-10
Contact:
Ye TAO
About author:LU Chaofeng, born in 1999, M. S. His research interests include speech synthesis, neural language processing.Supported by:
鲁超峰1, 陶冶1(), 文连庆1, 孟菲2, 秦修功3, 杜永杰4, 田云龙4
通讯作者:
陶冶
作者简介:鲁超峰(1999—),男,山东菏泽人,硕士,主要研究方向:语音合成、自然语言处理基金资助:CLC Number:
Chaofeng LU, Ye TAO, Lianqing WEN, Fei MENG, Xiugong QIN, Yongjie DU, Yunlong TIAN. Speaker-emotion voice conversion method with limited corpus based on large language model and pre-trained model[J]. Journal of Computer Applications, 2025, 45(3): 815-822.
鲁超峰, 陶冶, 文连庆, 孟菲, 秦修功, 杜永杰, 田云龙. 融合大语言模型和预训练模型的少量语料说话人-情感语音转换方法[J]. 《计算机应用》唯一官方网站, 2025, 45(3): 815-822.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024010013

Fig. 1 Flow of proposed method

Fig. 2 Examples of data augmentation

Fig. 3 Structure of speaker-emotion voice conversion model
| 语料库 | 语言 | 情感类别数 | 情感名称 | 训练集样本数 | 验证集样本数 | 测试集样本数 | 说话人数 |
|---|---|---|---|---|---|---|---|
| AISHELL-3 | 中文 | 1 | 中性 | 79 235 | 4 400 | 4 400 | 218 |
| LibriTTS | 英文 | 1 | 中性 | 26 590 | 3 323 | 3 323 | 251 |
| ESD | 中英混合 | 5 | 中性、快乐、愤怒、悲伤、惊喜 | 30 000 | 3 000 | 2 000 | 20 |
| EMONANA | 中文 | 5 | 中性、快乐、愤怒、悲伤、惊喜 | 150 | 15 | 15 | 1 |
Tab. 1 Corpora used in experiments
| 语料库 | 语言 | 情感类别数 | 情感名称 | 训练集样本数 | 验证集样本数 | 测试集样本数 | 说话人数 |
|---|---|---|---|---|---|---|---|
| AISHELL-3 | 中文 | 1 | 中性 | 79 235 | 4 400 | 4 400 | 218 |
| LibriTTS | 英文 | 1 | 中性 | 26 590 | 3 323 | 3 323 | 251 |
| ESD | 中英混合 | 5 | 中性、快乐、愤怒、悲伤、惊喜 | 30 000 | 3 000 | 2 000 | 20 |
| EMONANA | 中文 | 5 | 中性、快乐、愤怒、悲伤、惊喜 | 150 | 15 | 15 | 1 |
| 分数 | SMOS标准 | EMOS标准 |
|---|---|---|
| [0,1) | 未知的说话人相似度 | 未知的情感相似度 |
| [1,2) | 模糊的说话人相似度 | 模糊的情感相似度 |
| [2,3) | 可接受的说话人相似度 | 可接受的情感相似度 |
| [3,4) | 乐意接受的说话人相似度 | 乐意接受的情感相似度 |
| [ | 理想的说话人相似度 | 理想的情感相似度 |
Tab. 2 Scoring criteria of SMOS and EMOS
| 分数 | SMOS标准 | EMOS标准 |
|---|---|---|
| [0,1) | 未知的说话人相似度 | 未知的情感相似度 |
| [1,2) | 模糊的说话人相似度 | 模糊的情感相似度 |
| [2,3) | 可接受的说话人相似度 | 可接受的情感相似度 |
| [3,4) | 乐意接受的说话人相似度 | 乐意接受的情感相似度 |
| [ | 理想的说话人相似度 | 理想的情感相似度 |
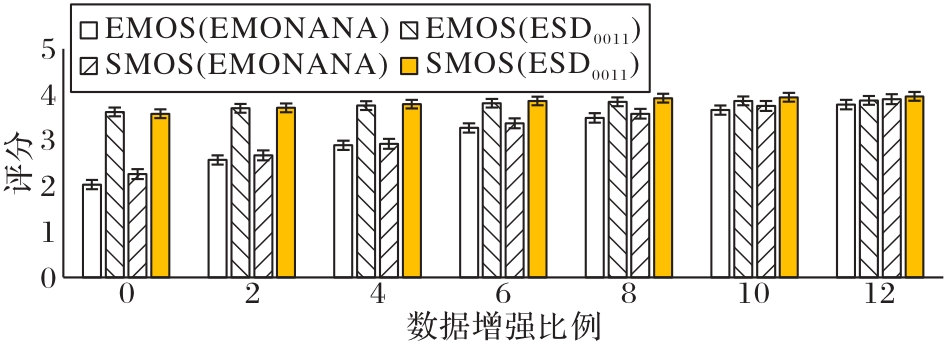
Fig. 4 Influence of data augmentation ratio on converted speech
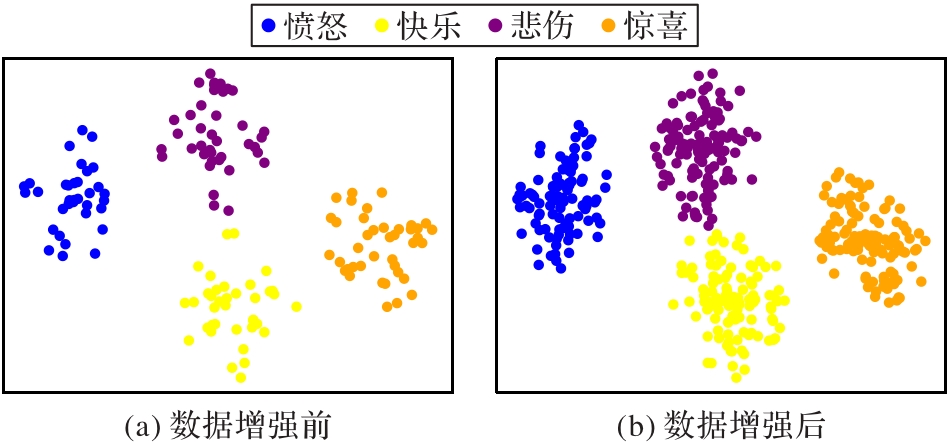
Fig. 5 Vector visualization before and after data augmentation
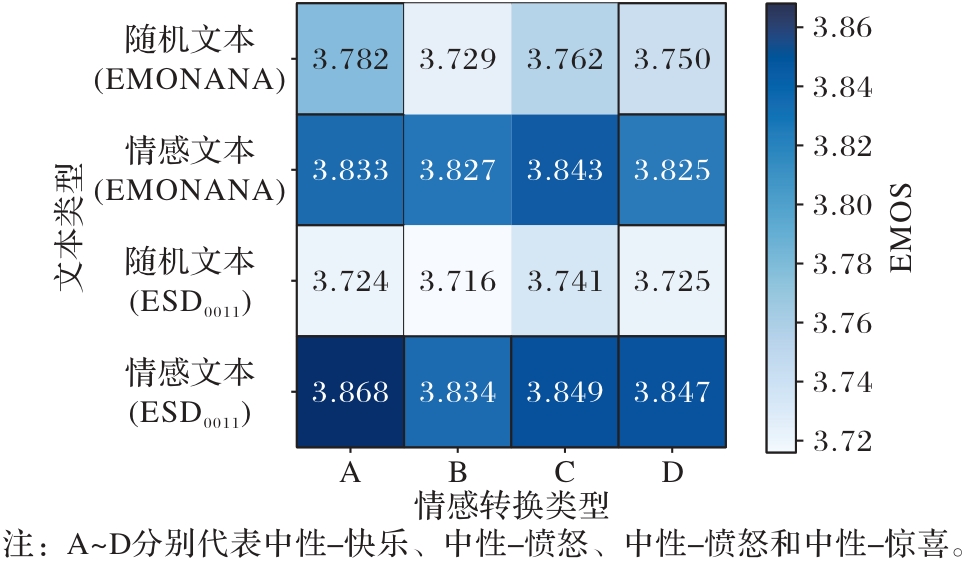
Fig. 6 Influence of augmented data’s text sentiment on EMOS of converted speech
| 方法 | SMOS | EMOS | MCD | WER/% | ||||
|---|---|---|---|---|---|---|---|---|
| EMONANA | ESD0011 | EMONANA | ESD0011 | EMONANA | ESD0011 | EMONANA | ESD0011 | |
| B | 2.64±0.12 | 2.96±0.14 | 3.61±0.10 | 3.64±0.11 | 4.03 | 4.06 | 6 | 5 |
| B+MP | 2.63±0.11 | 2.96±0.13 | 3.77±0.10 | 3.76±0.12 | 4.02 | 4.06 | ||
| B+DA | 3.95±0.13 | 3.97±0.11 | 3.84±0.12 | 3.85±0.11 | 3.98 | 3.96 | 1 | 1 |
| B+DA+FN | 4.03±0.11 | 3.85 | 1 | 1 | ||||
| B+MP+DA | 3.97±0.14 | 3.96±0.12 | 4.01±0.12 | 3.77 | 1 | 1 | ||
| B+MP+DA+FN | 4.19±0.11 | 4.16±0.13 | 4.17±0.12 | 4.20±0.11 | 3.77 | 3.78 | 1 | 1 |
Tab. 3 SMOS, EMOS, MCD, WER scores of different module combinations
| 方法 | SMOS | EMOS | MCD | WER/% | ||||
|---|---|---|---|---|---|---|---|---|
| EMONANA | ESD0011 | EMONANA | ESD0011 | EMONANA | ESD0011 | EMONANA | ESD0011 | |
| B | 2.64±0.12 | 2.96±0.14 | 3.61±0.10 | 3.64±0.11 | 4.03 | 4.06 | 6 | 5 |
| B+MP | 2.63±0.11 | 2.96±0.13 | 3.77±0.10 | 3.76±0.12 | 4.02 | 4.06 | ||
| B+DA | 3.95±0.13 | 3.97±0.11 | 3.84±0.12 | 3.85±0.11 | 3.98 | 3.96 | 1 | 1 |
| B+DA+FN | 4.03±0.11 | 3.85 | 1 | 1 | ||||
| B+MP+DA | 3.97±0.14 | 3.96±0.12 | 4.01±0.12 | 3.77 | 1 | 1 | ||
| B+MP+DA+FN | 4.19±0.11 | 4.16±0.13 | 4.17±0.12 | 4.20±0.11 | 3.77 | 3.78 | 1 | 1 |
| 方法 | SMOS | EMOS | MCD | WER/% | ||||
|---|---|---|---|---|---|---|---|---|
| EMONANA | ESD0011 | EMONANA | ESD0011 | EMONANA | ESD0011 | EMONANA | ESD0011 | |
| CycleGAN-EVC | 2.86±0.13 | 3.58±0.12 | 3.51±0.12 | 3.53±0.14 | 4.56 | 4.51 | 5 | 5 |
| StarGAN-EVC | 2.88±0.11 | 3.59±0.13 | 3.56±0.11 | 3.59±0.13 | 4.39 | 4.36 | 6 | 5 |
| Seq2Seq-EVC | 2.93±0.11 | 3.83±0.13 | 3.85±0.11 | 3.83±0.13 | 3.94 | 3.92 | 4 | 4 |
| Seq2Seq-EVC-WA2 | 3.89±0.14 | 3.96±0.12 | 3.75 | 3.74 | 3 | |||
| SMAL-ET2 | 4.06±0.13 | 4.08±0.12 | 3.80 | 3.81 | 1 | |||
| LSEVC | 4.19±0.11 | 4.16±0.13 | 4.17±0.12 | 4.20±0.11 | 1 | 0 | ||
Tab. 4 Performance comparison of different methods in experiments
| 方法 | SMOS | EMOS | MCD | WER/% | ||||
|---|---|---|---|---|---|---|---|---|
| EMONANA | ESD0011 | EMONANA | ESD0011 | EMONANA | ESD0011 | EMONANA | ESD0011 | |
| CycleGAN-EVC | 2.86±0.13 | 3.58±0.12 | 3.51±0.12 | 3.53±0.14 | 4.56 | 4.51 | 5 | 5 |
| StarGAN-EVC | 2.88±0.11 | 3.59±0.13 | 3.56±0.11 | 3.59±0.13 | 4.39 | 4.36 | 6 | 5 |
| Seq2Seq-EVC | 2.93±0.11 | 3.83±0.13 | 3.85±0.11 | 3.83±0.13 | 3.94 | 3.92 | 4 | 4 |
| Seq2Seq-EVC-WA2 | 3.89±0.14 | 3.96±0.12 | 3.75 | 3.74 | 3 | |||
| SMAL-ET2 | 4.06±0.13 | 4.08±0.12 | 3.80 | 3.81 | 1 | |||
| LSEVC | 4.19±0.11 | 4.16±0.13 | 4.17±0.12 | 4.20±0.11 | 1 | 0 | ||
| 1 | 张小峰,谢钧,罗健欣,等. 深度学习语音合成技术综述[J]. 计算机工程与应用, 2021, 57(9): 50-59. |
| ZHANG X F, XIE J, LUO J X, et al. Overview of deep learning speech synthesis technology [J]. Computer Engineering and Applications, 2021, 57(9): 50-59. | |
| 2 | TAN X, CHEN J, LIU H, et al. NaturalSpeech: end-to-end text to speech synthesis with human-level quality [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(6): 4234-4245. |
| 3 | HUANG R, ZHAO Z, LIU H, et al. ProDiff: progressive fast diffusion model for high-quality text-to-speech [C]// Proceedings of the 30th ACM International Conference on Multimedia. New York: ACM, 2022: 2595-2605. |
| 4 | SHEN J, PANG R, WEISS R J. Natural TTS synthesis by conditioning WaveNet on Mel spectrogram predictions [C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2018: 4779-4783. |
| 5 | REN Y, HU C, TAN X, et al. FastSpeech 2: fast and high-quality end-to-end text to speech [EB/OL]. [2023-02-21]. . |
| 6 | 姚文翰,柯登峰,黄良杰,等. 基于多领域条件生成的语音情感转换[J]. 郑州大学学报(理学版), 2023, 55(5): 67-72. |
| YAO W H, KE D F, HUANG L J, et al. Emotional voice conversion based on multiple domain conditional generation [J]. Journal of Zhengzhou University (Natural Science Edition), 2023, 55(5): 67-72. | |
| 7 | YANG Z, JING X, TRIANTAFYLLOPOULOS A, et al. An overview & analysis of sequence-to-sequence emotional voice conversion [C]// Proceedings of the INTERSPEECH 2022. [S.l.]: International Speech Communication Association, 2022: 4915-4919. |
| 8 | SHAH N, SINGH M, TAKAHASHI N, et al. Nonparallel emotional voice conversion for unseen speaker-emotion pairs using dual domain adversarial network & virtual domain pairing [C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| 9 | 陈乐乐,张雄伟,孙蒙,等. 融合梅尔谱增强与特征解耦的噪声鲁棒语音转换[J]. 声学学报, 2023, 48(5): 1070-1080. |
| CHEN L L, ZHANG X W, SUN M, et al. Noise robust voice conversion with the fusion of Mel-spectrum enhancement and feature disentanglement [J]. Acta Acustica, 2023, 48(5):1070-1080. | |
| 10 | 王翠英. 基于深度学习的合成语音转换问题研究[J]. 自动化与仪器仪表, 2023(7): 196-200. |
| WANG C J. Research on synthetic speech conversion based on deep learning [J]. Automation and Instrumentation, 2023(7):196-200. | |
| 11 | WALCZYNA T, PIOTROWSKI Z. Overview of voice conversion methods based on deep learning [J]. Applied Sciences, 2023, 13(5): No.3100. |
| 12 | ZHU X, LEI Y, SONG K, et al. Multi-speaker expressive speech synthesis via multiple factors decoupling [C]// Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2023: 1-5. |
| 13 | 李晨光,张波,赵骞,等. 基于迁移学习的文本共情预测[J]. 计算机应用, 2022, 42(11):3603-3609. |
| LI C G, ZHANG B, ZHAO Q, et al. Empathy prediction from texts based on transfer learning [J]. Journal of Computer Applications, 2022, 42(11): 3603-3609. | |
| 14 | LEI Y, YANG S, WANG X, et al. MsEmoTTS: multi-scale emotion transfer, prediction, and control for emotional speech synthesis [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2022, 30: 853-864. |
| 15 | ZHOU K, SISMAN B, LI H. Limited data emotional voice conversion leveraging text-to-speech: two-stage sequence-to-sequence training [C]// Proceedings of the INTERSPEECH 2021. [S.l.]: International Speech Communication Association, 2021: 811-815. |
| 16 | ZHOU K, SISMAN B, LIU R, et al. Seen and unseen emotional style transfer for voice conversion with a new emotional speech dataset [C]// Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2021: 920-924. |
| 17 | DU Z, QIAN Y, LIU X, et al. GLM: general language model pretraining with autoregressive blank infilling [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2022: 320-335. |
| 18 | STYLIANOU Y, CAPPÉ O, MOULINES É. Continuous probabilistic transform for voice conversion [J]. IEEE Transactions on Speech and Audio Processing, 1998, 6(2): 131-142. |
| 19 | YE H, YOUNG S. Voice conversion for unknown speakers[C]// Proceedings of the INTERSPEECH 2004. [S.l.]: International Speech Communication Association, 2004:1161-1164. |
| 20 | ZHOU K, SISMAN B, LI H. Transforming spectrum and prosody for emotional voice conversion with non-parallel training data [C]// Proceedings of the 2020 Speaker and Language Recognition Workshop. [S.l.]: International Speech Communication Association, 2020: 230-237. |
| 21 | KIM T H, CHO S, CHOI S, et al. Emotional voice conversion using multitask learning with Text-To-Speech [C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 7774-7778. |
| 22 | ZHAO Z, LIANG J, ZHENG Z, et al. Improving model stability and training efficiency in fast, high quality expressive voice conversion system [C]// Companion Publication of the 2021 International Conference on Multimodal Interaction. New York: ACM, 2021: 75-79. |
| 23 | ABBAS A, ABDELSAMEA M M, GABER M M. 4S-DT: self-supervised super sample decomposition for transfer learning with application to COVID-19 detection [J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(7): 2798-2808. |
| 24 | PAN J, LIN Z, ZHU X, et al. St-Adapter: parameter-efficient image-to-video transfer learning [C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 26462-26477. |
| 25 | QASIM R, BANGYAL W H, ALQARNI M A, et al. A fine-tuned BERT-based transfer learning approach for text classification [J]. Journal of Healthcare Engineering, 2022, 2022: No.3498123. |
| 26 | LIU Y, SUN H, CHEN G, et al. Multi-level knowledge distillation for speech emotion recognition in noisy conditions [C]// Proceedings of the INTERSPEECH 2023. [S.l.]: International Speech Communication Association, 2023: 1893-1897. |
| 27 | SUN H, ZHAO S, WANG X, et al. Fine-grained disentangled representation learning for multimodal emotion recognition [C]// Proceedings of the 2024 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2024: 11051-11055. |
| 28 | LI Y A, HAN C, MESGARANI N. StyleTTS-VC: one-shot voice conversion by knowledge transfer from style-based tts models [C]// Proceedings of the 2022 IEEE Spoken Language Technology Workshop. Piscataway: IEEE, 2023: 920-927. |
| 29 | HUANG W C, HAYASHI T, WU Y C, et al. Pretraining techniques for sequence-to-sequence voice conversion [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 745-755. |
| 30 | DU Z, SISMAN B, ZHOU K, et al. Disentanglement of emotional style and speaker identity for expressive voice conversion [C]// Proceedings of the INTERSPEECH 2022. [S.l.]: International Speech Communication Association, 2022: 2603-2607. |
| 31 | WANG D, DENG L, YEUNG Y T, et al. VQMIVC: vector quantization and mutual information-based unsupervised speech representation disentanglement for one-shot voice conversion [C]// Proceedings of the INTERSPEECH 2021. [S.l.]: International Speech Communication Association, 2021: 1344-1348. |
| 32 | KLAPSAS K, ELLINAS N, SUNG J S, et al. Word-level style control for expressive, non-attentive speech synthesis [C]// Proceedings of the 2021 International Conference on Speech and Computer, LNCS 12997. Cham: Springer, 2021: 336-347. |
| 33 | LUO Z, CHEN J, TAKIGUCHI T, et al. Emotional voice conversion using dual supervised adversarial networks with continuous wavelet transform F0 features [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, 27(10): 1535-1548. |
| 34 | XUE L, SOONG F K, ZHANG S, et al. ParaTTS: learning linguistic and prosodic cross-sentence information in paragraph-based TTS [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2022, 30: 2854-2864. |
| 35 | WU N Q, LIU Z C, LING Z H, et al. Discourse-level prosody modeling with a variational autoencoder for non-autoregressive expressive speech synthesis [C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 7592-7596. |
| 36 | SUN G, ZHANG Y, WEISS R J, et al. Generating diverse and natural Text-To-Speech samples using a quantized fine-grained VAE and autoregressive prosody prior [C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 6699-6703. |
| 37 | CHIEN C M, LEE H Y. Hierarchical prosody modeling for non-autoregressive speech synthesis [C]// Proceedings of the 2021 IEEE Spoken Language Technology Workshop. Piscataway: IEEE, 2021: 446-453. |
| 38 | CHAN W, JAITLY N, LE Q, et al. Listen, attend and spell: a neural network for large vocabulary conversational speech recognition [C]// Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2016: 4960-4964. |
| 39 | SHI Y, BU H, XU X, et al. AISHELL-3: a multi-speaker mandarin TTS corpus[C]// Proceedings of the INTERSPEECH 2021. [S.l.]: International Speech Communication Association, 2021: 2756-2760. |
| 40 | ZEN H, DANG V, CLARK R, et al. LibriTTS: a corpus derived from LibriSpeech for Text-To-Speech [C]// Proceedings of the INTERSPEECH 2019. [S.l.]: International Speech Communication Association, 2019: 1526-1530. |
| 41 | ZHOU K, SISMAN B, LIU R, et al. Emotional voice conversion: theory, databases and ESD [J]. Speech Communication, 2022, 137: 1-18. |
| 42 | VAN DER MAATEN L, HINTON G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research, 2008, 9: 2579-2605. |
| 43 | ZHANG J X, LING Z H, DAI L R. Non-parallel sequence-to-sequence voice conversion with disentangled linguistic and speaker representations [J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020, 28: 540-552. |
| 44 | ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2242-2251. |
| 45 | MORISE M, YOKOMORI F, OZAWA K. WORLD: a vocoder-based high-quality speech synthesis system for real-time applications [J]. IEICE Transactions on Information and Systems, 2016, E99-D(7): 1877-1884. |
| 46 | MORITANI A, SAKAMOTO S, OZAKI R, et al. StarGAN-based emotional voice conversion for Japanese phrases [C]// Proceedings of the 2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference. Piscataway: IEEE, 2021: 836-840. |
| 47 | CHOI Y, CHOI M, KIM M, et al. StarGAN: unified generative adversarial networks for multi-domain image-to-image translation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 8789-8797. |
| 48 | ZHANG J, WUSHOUER M, TUERHONG G, et al. Semi-supervised learning for robust emotional speech synthesis with limited data [J]. Applied Sciences, 2023, 13(9): No.5724. |
| 49 | KONG J, KIM J, BAE J. Hifi-GAN: generative adversarial networks for efficient and high fidelity speech synthesis [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 17022-17033. |
| [1] | Xiaolin QIN, Xu GU, Dicheng LI, Haiwen XU. Survey and prospect of large language models [J]. Journal of Computer Applications, 2025, 45(3): 685-696. |
| [2] | Chengzhe YUAN, Guohua CHEN, Dingding LI, Yuan ZHU, Ronghua LIN, Hao ZHONG, Yong TANG. ScholatGPT: a large language model for academic social networks and its intelligent applications [J]. Journal of Computer Applications, 2025, 45(3): 755-764. |
| [3] | Hui ZENG, Shiyu XIONG, Yongzheng DI, Hongzhou SHI. Federated parameter-efficient fine-tuning technology for large model based on pruning [J]. Journal of Computer Applications, 2025, 45(3): 715-724. |
| [4] | Jing HE, Yang SHEN, Runfeng XIE. Recognition and optimization of hallucination phenomena in large language models [J]. Journal of Computer Applications, 2025, 45(3): 709-714. |
| [5] | Kun SHENG, Zhongqing WANG. Synaesthesia metaphor analysis based on large language model and data augmentation [J]. Journal of Computer Applications, 2025, 45(3): 794-800. |
| [6] | Xuefei ZHANG, Liping ZHANG, Sheng YAN, Min HOU, Yubo ZHAO. Personalized learning recommendation in collaboration of knowledge graph and large language model [J]. Journal of Computer Applications, 2025, 45(3): 773-784. |
| [7] | Peng CAO, Guangqi WEN, Jinzhu YANG, Gang CHEN, Xinyi LIU, Xuechun JI. Efficient fine-tuning method of large language models for test case generation [J]. Journal of Computer Applications, 2025, 45(3): 725-731. |
| [8] | Chenwei SUN, Junli HOU, Xianggen LIU, Jiancheng LYU. Large language model prompt generation method for engineering drawing understanding [J]. Journal of Computer Applications, 2025, 45(3): 801-807. |
| [9] | Yanmin DONG, Jiajia LIN, Zheng ZHANG, Cheng CHENG, Jinze WU, Shijin WANG, Zhenya HUANG, Qi LIU, Enhong CHEN. Design and practice of intelligent tutoring algorithm based on personalized student capability perception [J]. Journal of Computer Applications, 2025, 45(3): 765-772. |
| [10] | Yuemei XU, Yuqi YE, Xueyi HE. Bias challenges of large language models: identification, evaluation, and mitigation [J]. Journal of Computer Applications, 2025, 45(3): 697-708. |
| [11] | Yan YANG, Feng YE, Dong XU, Xuejie ZHANG, Jin XU. Construction of digital twin water conservancy knowledge graph integrating large language model and prompt learning [J]. Journal of Computer Applications, 2025, 45(3): 785-793. |
| [12] | Hongye LIU, Xiai CHEN, Tao ZENG. Tri-modal adapter based on selective state space [J]. Journal of Computer Applications, 2025, 45(2): 411-420. |
| [13] | Huanliang SUN, Siyi WANG, Junling LIU, Jingke XU. Help-seeking information extraction model for flood event in social media data [J]. Journal of Computer Applications, 2024, 44(8): 2437-2445. |
| [14] | Yuemei XU, Ling HU, Jiayi ZHAO, Wanze DU, Wenqing WANG. Technology application prospects and risk challenges of large language models [J]. Journal of Computer Applications, 2024, 44(6): 1655-1662. |
| [15] | Xue LI, Guangle YAO, Honghui WANG, Jun LI, Haoran ZHOU, Shaoze YE. Remote sensing image classification based on sample incremental learning [J]. Journal of Computer Applications, 2024, 44(3): 732-736. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||