


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (9): 2764-2772.DOI: 10.11772/j.issn.1001-9081.2024091262
• Artificial intelligence • Previous Articles
Bing YIN1, Zhenhua LING2, Yin LIN1,2( ), Changfeng XI1, Ying LIU1
), Changfeng XI1, Ying LIU1
Received:2024-09-06
Revised:2024-11-25
Accepted:2024-11-26
Online:2024-12-20
Published:2025-09-10
Contact:
Yin LIN
About author:YIN Bing, born in 1983, Ph. D., senior engineer. Her research interests include computer vision, multimodal perception.Supported by:
殷兵1, 凌震华2, 林垠1,2(), 奚昌凤1, 刘颖1
通讯作者:
林垠
作者简介:殷兵(1983—),女,山东枣庄人,高级工程师,博士,CCF会员,主要研究方向:计算机视觉、多模态感知基金资助:CLC Number:
Bing YIN, Zhenhua LING, Yin LIN, Changfeng XI, Ying LIU. Emotion recognition method compatible with missing modal reasoning[J]. Journal of Computer Applications, 2025, 45(9): 2764-2772.
殷兵, 凌震华, 林垠, 奚昌凤, 刘颖. 兼容缺失模态推理的情感识别方法[J]. 《计算机应用》唯一官方网站, 2025, 45(9): 2764-2772.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024091262
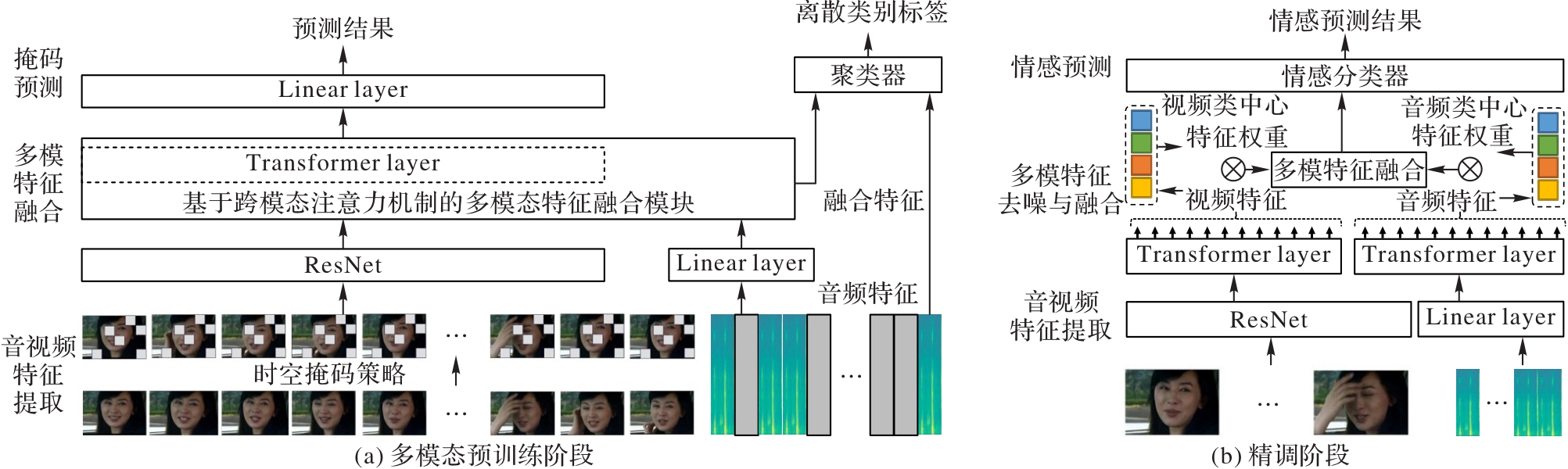
Fig. 1 Overall structure of proposed method

Fig. 2 Flow of spatio-temporal masking strategy
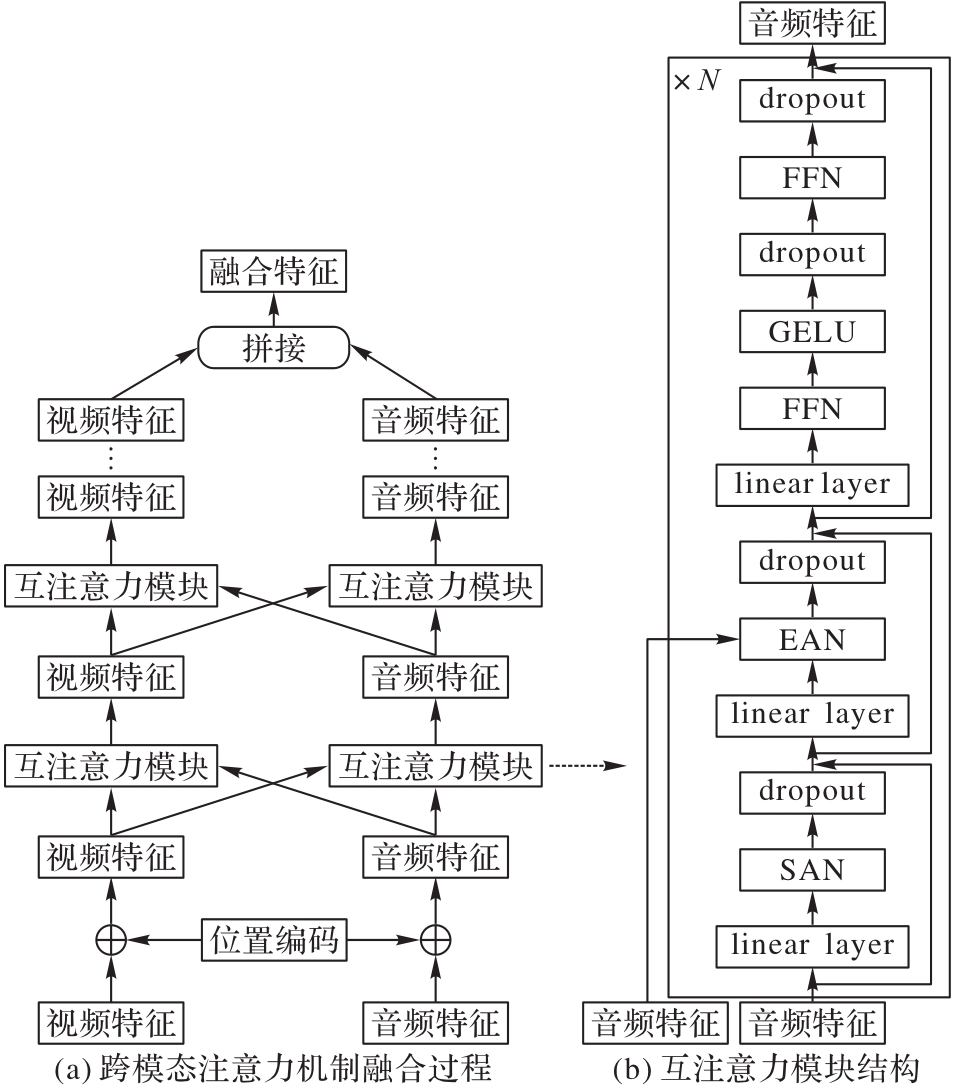
Fig. 3 Structure of multi-modal feature fusion network
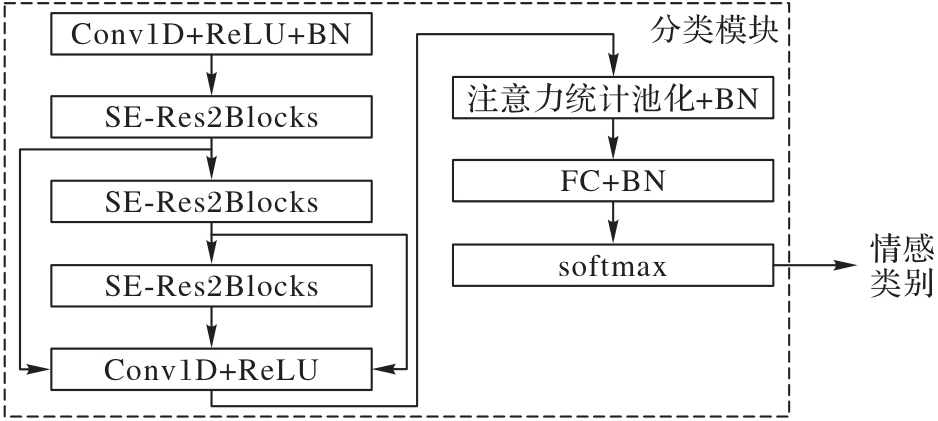
Fig. 4 Flow of emotion classification module
| 模型 | 阶段 | 模态 | WAR | UAR | 召回率 | |||
|---|---|---|---|---|---|---|---|---|
| 悲伤 | 中性 | 生气 | 开心 | |||||
| AV-HuBERT-MA | 精调 | 音频-视频 | 93.11 | 92.52 | 89.24 | 93.83 | 89.13 | 97.90 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频 | 86.04 | 82.42 | 80.23 | 91.32 | 86.19 | 71.96 | |
| 推理 | 音频 | |||||||
| 精调 | 视频 | 90.28 | 87.75 | 79.06 | 93.37 | 82.25 | 96.31 | |
| 推理 | 视频 | |||||||
| 精调 | 音频-视频 | 84.40 | 80.88 | 83.76 | 90.83 | 84.88 | 64.06 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 89.24 | 86.78 | 81.41 | 94.02 | 75.63 | 96.05 | |
| 推理 | 视频 | |||||||
| AV-HuBERT-MAT | 精调 | 音频-视频 | 93.73 | 93.80 | 92.37 | 93.72 | 90.69 | 98.40 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频-视频 | 84.75 | 85.16 | 88.45 | 85.18 | 83.63 | 83.38 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 90.64 | 90.35 | 87.67 | 91.34 | 84.81 | 97.57 | |
| 推理 | 视频 | |||||||
Tab. 1 Comparison of emotion recognition performance with modal alignment or modal absence of different models
| 模型 | 阶段 | 模态 | WAR | UAR | 召回率 | |||
|---|---|---|---|---|---|---|---|---|
| 悲伤 | 中性 | 生气 | 开心 | |||||
| AV-HuBERT-MA | 精调 | 音频-视频 | 93.11 | 92.52 | 89.24 | 93.83 | 89.13 | 97.90 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频 | 86.04 | 82.42 | 80.23 | 91.32 | 86.19 | 71.96 | |
| 推理 | 音频 | |||||||
| 精调 | 视频 | 90.28 | 87.75 | 79.06 | 93.37 | 82.25 | 96.31 | |
| 推理 | 视频 | |||||||
| 精调 | 音频-视频 | 84.40 | 80.88 | 83.76 | 90.83 | 84.88 | 64.06 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 89.24 | 86.78 | 81.41 | 94.02 | 75.63 | 96.05 | |
| 推理 | 视频 | |||||||
| AV-HuBERT-MAT | 精调 | 音频-视频 | 93.73 | 93.80 | 92.37 | 93.72 | 90.69 | 98.40 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频-视频 | 84.75 | 85.16 | 88.45 | 85.18 | 83.63 | 83.38 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 90.64 | 90.35 | 87.67 | 91.34 | 84.81 | 97.57 | |
| 推理 | 视频 | |||||||
| 方法 | WAR | UAR |
|---|---|---|
| ResNet18+GRU[ | 64.02 | 51.68 |
| Former-DFER[ | 65.70 | 53.69 |
| 3DRes+Center Loss[ | 55.48 | 44.91 |
| EC-STFL[ | 56.51 | 45.35 |
| AV-HuBERT-MA | 68.94 | 57.09 |
Tab. 2 Comparison results of different methods on single video modal data of DFEW
| 方法 | WAR | UAR |
|---|---|---|
| ResNet18+GRU[ | 64.02 | 51.68 |
| Former-DFER[ | 65.70 | 53.69 |
| 3DRes+Center Loss[ | 55.48 | 44.91 |
| EC-STFL[ | 56.51 | 45.35 |
| AV-HuBERT-MA | 68.94 | 57.09 |
| 层数 | WAR/% | UAR/% | 召回率/% | |||
|---|---|---|---|---|---|---|
| 悲伤 | 中性 | 生气 | 开心 | |||
| 4 | 95.27 | 85.19 | 97.31 | |||
| 8 | 92.58 | 90.39 | 85.91 | 85.94 | 93.70 | |
| 12 | 84.83 | 80.04 | 73.19 | 91.48 | 80.44 | 75.06 |
| {2,4,6,8} | 93.66 | 91.68 | 86.89 | 96.65 | 87.06 | |
| {6,8,10,12} | 90.91 | 87.33 | 80.63 | 95.78 | 85.75 | 87.15 |
| {1,2,…,12} | 92.31 | 89.85 | 84.15 | 95.65 | 92.61 | |
Tab. 3 Influence of feature selection strategy on emotion recognition performance
| 层数 | WAR/% | UAR/% | 召回率/% | |||
|---|---|---|---|---|---|---|
| 悲伤 | 中性 | 生气 | 开心 | |||
| 4 | 95.27 | 85.19 | 97.31 | |||
| 8 | 92.58 | 90.39 | 85.91 | 85.94 | 93.70 | |
| 12 | 84.83 | 80.04 | 73.19 | 91.48 | 80.44 | 75.06 |
| {2,4,6,8} | 93.66 | 91.68 | 86.89 | 96.65 | 87.06 | |
| {6,8,10,12} | 90.91 | 87.33 | 80.63 | 95.78 | 85.75 | 87.15 |
| {1,2,…,12} | 92.31 | 89.85 | 84.15 | 95.65 | 92.61 | |
| 模型 | 阶段 | 模态 | WAR | UAR | 召回率 | |||
|---|---|---|---|---|---|---|---|---|
| 悲伤 | 中性 | 生气 | 开心 | |||||
| AV-HuBERT | 精调 | 音频-视频 | 86.75 | 85.42 | 84.51 | 89.83 | 79.69 | 87.66 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频-视频 | 80.66 | 81.02 | 81.41 | 80.42 | 79.13 | 83.12 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 57.59 | 63.94 | 80.63 | 54.43 | 41.19 | 79.51 | |
| 推理 | 视频 | |||||||
| AV-HuBERT-M | 精调 | 音频-视频 | 91.30 | 92.20 | 93.14 | 90.48 | 88.88 | 96.31 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频-视频 | 83.57 | 81.02 | 88.85 | 89.83 | 83.69 | 61.71 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 81.83 | 82.98 | 92.56 | 86.40 | 58.31 | 94.63 | |
| 推理 | 视频 | |||||||
| AV-HuBERT-MA | 精调 | 音频-视频 | 93.11 | 92.52 | 89.24 | 93.83 | 89.13 | 97.90 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频-视频 | 84.40 | 80.88 | 83.76 | 90.83 | 84.88 | 64.06 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 89.24 | 86.78 | 81.41 | 94.02 | 75.63 | 96.05 | |
| 推理 | 视频 | |||||||
| AV-HuBERT-MAT | 精调 | 音频-视频 | 93.73 | 93.80 | 92.37 | 93.72 | 90.69 | 98.40 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频-视频 | 84.75 | 85.16 | 88.45 | 85.18 | 83.63 | 83.38 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 90.64 | 90.35 | 87.67 | 91.34 | 84.81 | 97.57 | |
| 推理 | 视频 | |||||||
Tab. 4 Ablation study results on self-built dataset
| 模型 | 阶段 | 模态 | WAR | UAR | 召回率 | |||
|---|---|---|---|---|---|---|---|---|
| 悲伤 | 中性 | 生气 | 开心 | |||||
| AV-HuBERT | 精调 | 音频-视频 | 86.75 | 85.42 | 84.51 | 89.83 | 79.69 | 87.66 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频-视频 | 80.66 | 81.02 | 81.41 | 80.42 | 79.13 | 83.12 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 57.59 | 63.94 | 80.63 | 54.43 | 41.19 | 79.51 | |
| 推理 | 视频 | |||||||
| AV-HuBERT-M | 精调 | 音频-视频 | 91.30 | 92.20 | 93.14 | 90.48 | 88.88 | 96.31 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频-视频 | 83.57 | 81.02 | 88.85 | 89.83 | 83.69 | 61.71 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 81.83 | 82.98 | 92.56 | 86.40 | 58.31 | 94.63 | |
| 推理 | 视频 | |||||||
| AV-HuBERT-MA | 精调 | 音频-视频 | 93.11 | 92.52 | 89.24 | 93.83 | 89.13 | 97.90 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频-视频 | 84.40 | 80.88 | 83.76 | 90.83 | 84.88 | 64.06 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 89.24 | 86.78 | 81.41 | 94.02 | 75.63 | 96.05 | |
| 推理 | 视频 | |||||||
| AV-HuBERT-MAT | 精调 | 音频-视频 | 93.73 | 93.80 | 92.37 | 93.72 | 90.69 | 98.40 |
| 推理 | 音频-视频 | |||||||
| 精调 | 音频-视频 | 84.75 | 85.16 | 88.45 | 85.18 | 83.63 | 83.38 | |
| 推理 | 音频 | |||||||
| 精调 | 音频-视频 | 90.64 | 90.35 | 87.67 | 91.34 | 84.81 | 97.57 | |
| 推理 | 视频 | |||||||
| [1] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. |
| [2] | CHUNG J, GULCEHRE C, CHO K, et al. Empirical evaluation of gated recurrent neural networks on sequence modeling [EB/OL]. [2024-07-11]. . |
| [3] | ZHAO Z, LIU Q. Former-DFER: dynamic facial expression recognition Transformer [C]// Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 1553-1561. |
| [4] | HARA K, KATAOKA H, SATOH Y. Learning spatio-temporal features with 3D residual networks for action recognition [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops. Piscataway: IEEE, 2017:3154-3160. |
| [5] | IQBAL M, SAMEEM M S I, NAQVI N, et al. A deep learning approach for face recognition based on angularly discriminative features [J]. Pattern Recognition Letters, 2019, 128: 414-419. |
| [6] | JIANG X, ZONG Y, ZHENG W, et al. DFEW: a large-scale database for recognizing dynamic facial expressions in the wild [C]// Proceedings of the 28th ACM International Conference on Multimedia. New York: ACM, 2020:2881-2889. |
| [7] | ZHANG S, ZHAO X, CHUANG Y, et al. Feature learning via deep belief network for Chinese speech emotion recognition [C]// Proceedings of the 2016 Chinese Conference on Pattern Recognition, CCIS 663. Singapore: Springer, 2016:645-651. |
| [8] | 陈婧,李海峰,马琳,等. 多粒度特征融合的维度语音情感识别方法[J]. 信号处理, 2017, 33(3):374-382. |
| CHEN J, LI H F, MA L, et al. Multi-granularity feature fusion for dimensional speech emotion recognition [J]. Journal of Signal Processing, 2017, 33(3): 374-382. | |
| [9] | AREZZO A, BERRETTI S. Speaker VGG CCT: cross-corpus speech emotion recognition with speaker embedding and Vision Transformers [C]// Proceedings of the 4th ACM International Conference on Multimedia in Asia. New York: ACM, 2022: No.7. |
| [10] | 龙英潮,丁美荣,林桂锦,等. 基于视听觉感知系统的多模态情感识别[J]. 计算机系统应用, 2021, 30(12):218-225. |
| LONG Y C, DING M R, LIN G J, et al. Emotion recognition based on visual and audiovisual perception system [J]. Computer Systems and Applications, 2021, 30(12):218-225. | |
| [11] | ZADEH A, CHEN M, PORIA S, et al. Tensor fusion network for multimodal sentiment analysis [C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2017: 1103-1114. |
| [12] | ZENG Z, TU J, PIANFETTI B, et al. Audio-visual affect recognition through multi-stream fused HMM for HCI [C]// Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition — Volume 2. Piscataway: IEEE, 2005: 967-972. |
| [13] | 刘菁菁,吴晓峰. 基于长短时记忆网络的多模态情感识别和空间标注[J]. 复旦学报(自然科学版), 2020, 59(5):565-574. |
| LIU J J, WU X F. Real-time multimodal emotion recognition and emotion space labeling using LSTM networks [J]. Journal of Fudan University (Natural Science), 2020, 59(5):565-574. | |
| [14] | 王传昱,李为相,陈震环. 基于语音和视频图像的多模态情感识别研究[J]. 计算机工程与应用, 2021, 57(23):163-170. |
| WANG C Y, LI W X, CHEN Z H. Research of multi-modal emotion recognition based on voice and video images [J]. Computer Engineering and Applications, 2021, 57(23):163-170. | |
| [15] | CHEN S, JIN Q. Multi-modal conditional attention fusion for dimensional emotion prediction [C]// Proceedings of the 24th ACM International Conference on Multimedia. New York: ACM, 2016:571-575. |
| [16] | HUANG J, TAO J, LIU B, et al. Multimodal Transformer fusion for continuous emotion recognition [C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 3507-3511. |
| [17] | ZADEH A B, LIANG P P, PORIA S, et al. Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: ACL, 2018: 2236-2246. |
| [18] | ALWASSEL H, MAHAJAN D, KORBAR B, et al. Self-supervised learning by cross-modal audio-video clustering [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 9758-9770. |
| [19] | ASANO Y M, PATRICK M, RUPPRECHT C, et al. Labelling unlabelled videos from scratch with multi-modal self-supervision[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 4660-4671. |
| [20] | SHI B, HSU W N, LAKHOTIA K, et al. Learning audio-visual speech representation by masked multimodal cluster prediction[EB/OL]. [2022-03-13]. . |
| [21] | AKBARI H, YUAN L, QIAN R, et al. VATT: Transformers for multimodal self-supervised learning from raw video, audio and text[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 24206-24221. |
| [22] | LIU J, ZHU X, LIU F, et al. OPT: omni-perception pre-trainer for cross-modal understanding and generation [EB/OL]. [2024-03-12].. |
| [23] | PARTHASARATHY S, SUNDARAM S. Training strategies to handle missing modalities for audio-visual expression recognition[C]// Companion Publication of the 2020 International Conference on Multimodal Interaction. New York: ACM, 2020: 400-404. |
| [24] | ZHAO J, LI R, JIN Q. Missing modality imagination network for emotion recognition with uncertain missing modalities [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg: ACL, 2021: 2608-2618. |
| [25] | DESPLANQUES B, THIENPONDT J, DEMUYNCK K. ECAPA-TDNN: emphasized channel attention, propagation and aggregation in TDNN based speaker verification [C]// Proceedings of the INTERSPEECH 2020. [S.l.]: International Speech Communication Association, 2020: 3830-3834. |
| [1] | Lina GE, Mingyu WANG, Lei TIAN. Review of research on efficiency of federated learning [J]. Journal of Computer Applications, 2025, 45(8): 2387-2398. |
| [2] | Yanhua LIAO, Yuanxia YAN, Wenlin PAN. Multi-target detection algorithm for traffic intersection images based on YOLOv9 [J]. Journal of Computer Applications, 2025, 45(8): 2555-2565. |
| [3] | Peng PENG, Ziting CAI, Wenling LIU, Caihua CHEN, Wei ZENG, Baolai HUANG. Speech emotion recognition method based on hybrid Siamese network with CNN and bidirectional GRU [J]. Journal of Computer Applications, 2025, 45(8): 2515-2521. |
| [4] | Shuo ZHANG, Guokai SUN, Yuan ZHUANG, Xiaoyu FENG, Jingzhi WANG. Dynamic detection method of eclipse attacks for blockchain node analysis [J]. Journal of Computer Applications, 2025, 45(8): 2428-2436. |
| [5] | Jinxian SUO, Liping ZHANG, Sheng YAN, Dongqi WANG, Yawen ZHANG. Review of interpretable deep knowledge tracing methods [J]. Journal of Computer Applications, 2025, 45(7): 2043-2055. |
| [6] | Zhenzhou WANG, Fangfang GUO, Jingfang SU, He SU, Jianchao WANG. Robustness optimization method of visual model for intelligent inspection [J]. Journal of Computer Applications, 2025, 45(7): 2361-2368. |
| [7] | Qiaoling QI, Xiaoxiao WANG, Qianqian ZHANG, Peng WANG, Yongfeng DONG. Label noise adaptive learning algorithm based on meta-learning [J]. Journal of Computer Applications, 2025, 45(7): 2113-2122. |
| [8] | Xiaoyang ZHAO, Xinzheng XU, Zhongnian LI. Research review on explainable artificial intelligence in internet of things applications [J]. Journal of Computer Applications, 2025, 45(7): 2169-2179. |
| [9] | Lanhao LI, Haojun YAN, Haoyi ZHOU, Qingyun SUN, Jianxin LI. Multi-scale information fusion time series long-term forecasting model based on neural network [J]. Journal of Computer Applications, 2025, 45(6): 1776-1783. |
| [10] | Tianchen HUA, Xiaoning MA, Hui ZHI. Portable executable malware static detection model based on shallow artificial neural network [J]. Journal of Computer Applications, 2025, 45(6): 1911-1921. |
| [11] | Sijie NIU, Yuliang LIU. Auxiliary diagnostic method for retinopathy based on dual-branch structure with knowledge distillation [J]. Journal of Computer Applications, 2025, 45(5): 1410-1414. |
| [12] | Yali YANG, Ying LI, Yutao ZHANG, Peihua SONG. Review of multi-modal research methods for face recognition [J]. Journal of Computer Applications, 2025, 45(5): 1645-1657. |
| [13] | Kai CHEN, Hailiang YE, Feilong CAO. Classification algorithm for point cloud based on local-global interaction and structural Transformer [J]. Journal of Computer Applications, 2025, 45(5): 1671-1676. |
| [14] | Wenpeng WANG, Yinchang QIN, Wenxuan SHI. Review of unsupervised deep learning methods for industrial defect detection [J]. Journal of Computer Applications, 2025, 45(5): 1658-1670. |
| [15] | Xueying LI, Kun YANG, Guoqing TU, Shubo LIU. Adversarial sample generation method for time-series data based on local augmentation [J]. Journal of Computer Applications, 2025, 45(5): 1573-1581. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||