


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (11): 3642-3648.DOI: 10.11772/j.issn.1001-9081.2024111589
• Advanced computing • Previous Articles
Yanpeng ZHANG1,2, Yuqian ZHAO1,2( ), Fan ZHANG1,2, Tenghai QIU1,3, Gui GUI1,2, Lingli YU1,2
), Fan ZHANG1,2, Tenghai QIU1,3, Gui GUI1,2, Lingli YU1,2
Received:2024-11-11
Revised:2025-02-14
Accepted:2025-02-20
Online:2025-02-26
Published:2025-11-10
Contact:
Yuqian ZHAO
About author:ZHANG Yanpeng, born in 1999, M. S. candidate. His research interests include deep reinforcement learning, combinatorial optimization.Supported by:
张焱鹏1,2, 赵于前1,2(), 张帆1,2, 丘腾海1,3, 桂瑰1,2, 余伶俐1,2
通讯作者:
赵于前
作者简介:张焱鹏(1999—),男,黑龙江齐齐哈尔人,硕士研究生,主要研究方向:深度强化学习、组合优化基金资助:CLC Number:
Yanpeng ZHANG, Yuqian ZHAO, Fan ZHANG, Tenghai QIU, Gui GUI, Lingli YU. Capacitated vehicle routing problem solving method based on improved MAML and GVAE[J]. Journal of Computer Applications, 2025, 45(11): 3642-3648.
张焱鹏, 赵于前, 张帆, 丘腾海, 桂瑰, 余伶俐. 基于改进MAML与GVAE的容量约束车辆路径问题求解方法[J]. 《计算机应用》唯一官方网站, 2025, 45(11): 3642-3648.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024111589
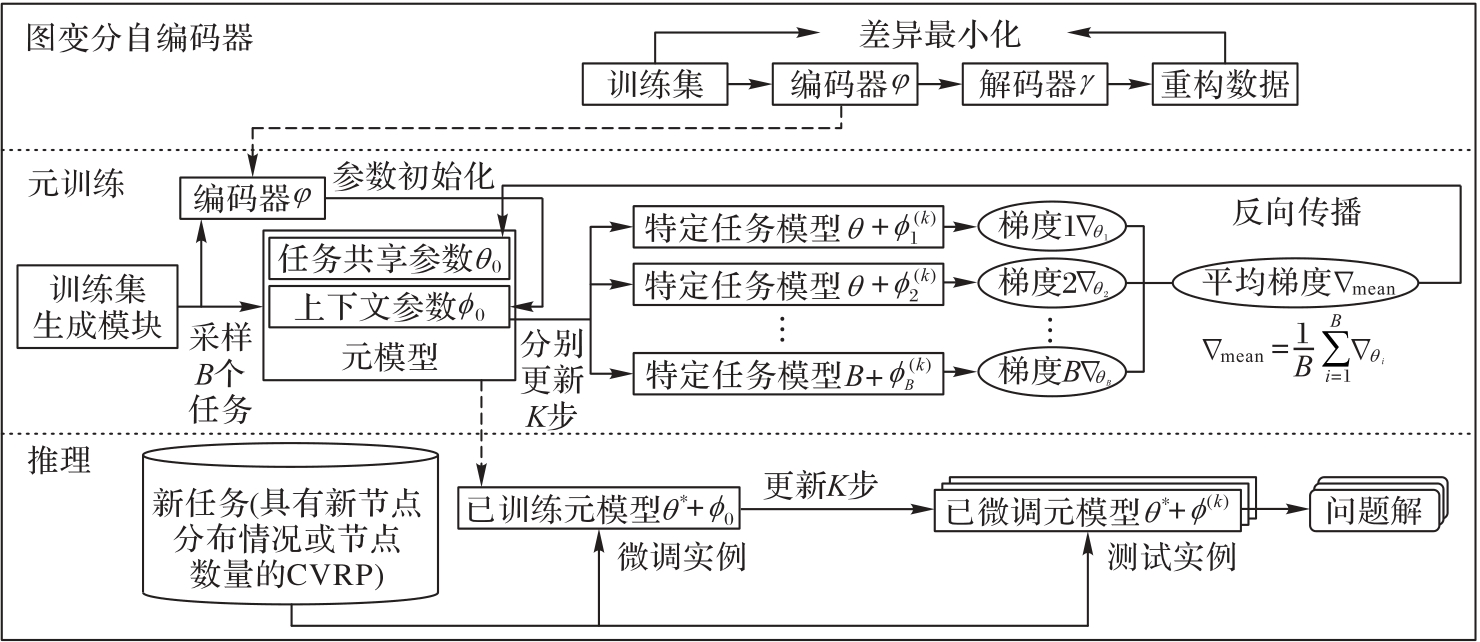
Fig. 1 Meta-learning framework based on improved MAML and GVAE

Fig. 2 Context parameter setting in POMO model

Fig. 3 Principle of GVAE
| 方法 | 100G | 150U | 150G | 200U | 200G | 均值 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 成本 | Gap/% | 成本 | Gap/% | 成本 | Gap/% | 成本 | Gap/% | 成本 | Gap/% | 成本 | Gap/% | ||
专业 求解器 | HGS[ | 12.653 | 0.00 | 19.146 | 0.00 | 15.398 | 0.00 | 21.914 | 0.00 | 18.845 | 0.00 | 17.591 | 0.00 |
| LKH3[ | 12.769 | 0.92 | 19.330 | 0.96 | 15.544 | 0.95 | 22.148 | 1.07 | 19.028 | 0.97 | 17.764 | 0.98 | |
深度 强化 学习 | AM[ | 13.734 | 8.54 | 21.434 | 11.95 | 17.130 | 11.25 | 24.673 | 12.59 | 21.103 | 11.98 | 19.615 | 11.50 |
| POMO[ | 13.010 | 2.82 | 19.810 | 3.47 | 15.914 | 3.35 | 22.720 | 3.68 | 19.531 | 3.64 | 18.197 | 3.44 | |
| POMO-reptile[ | 13.014 | 2.85 | 19.797 | 3.40 | 15.911 | 3.33 | 22.734 | 3.74 | 19.533 | 3.65 | 18.198 | 3.45 | |
本文 方法 | without GVAE | 12.969 | 2.50 | 19.768 | 3.25 | 15.902 | 3.27 | 22.642 | 3.32 | 19.510 | 3.53 | 18.158 | 3.22 |
| with GVAE | 12.960 | 2.43 | 19.736 | 3.08 | 15.897 | 3.24 | 22.602 | 3.14 | 19.448 | 3.20 | 18.129 | 3.05 | |
| with GVAE+使用微调 | 12.952 | 2.36 | 19.725 | 3.02 | 15.880 | 3.13 | 22.591 | 3.09 | 19.436 | 3.14 | 18.117 | 2.99 | |
Tab. 1 Costs and deviation rates comparison of different methods on five tasks
| 方法 | 100G | 150U | 150G | 200U | 200G | 均值 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 成本 | Gap/% | 成本 | Gap/% | 成本 | Gap/% | 成本 | Gap/% | 成本 | Gap/% | 成本 | Gap/% | ||
专业 求解器 | HGS[ | 12.653 | 0.00 | 19.146 | 0.00 | 15.398 | 0.00 | 21.914 | 0.00 | 18.845 | 0.00 | 17.591 | 0.00 |
| LKH3[ | 12.769 | 0.92 | 19.330 | 0.96 | 15.544 | 0.95 | 22.148 | 1.07 | 19.028 | 0.97 | 17.764 | 0.98 | |
深度 强化 学习 | AM[ | 13.734 | 8.54 | 21.434 | 11.95 | 17.130 | 11.25 | 24.673 | 12.59 | 21.103 | 11.98 | 19.615 | 11.50 |
| POMO[ | 13.010 | 2.82 | 19.810 | 3.47 | 15.914 | 3.35 | 22.720 | 3.68 | 19.531 | 3.64 | 18.197 | 3.44 | |
| POMO-reptile[ | 13.014 | 2.85 | 19.797 | 3.40 | 15.911 | 3.33 | 22.734 | 3.74 | 19.533 | 3.65 | 18.198 | 3.45 | |
本文 方法 | without GVAE | 12.969 | 2.50 | 19.768 | 3.25 | 15.902 | 3.27 | 22.642 | 3.32 | 19.510 | 3.53 | 18.158 | 3.22 |
| with GVAE | 12.960 | 2.43 | 19.736 | 3.08 | 15.897 | 3.24 | 22.602 | 3.14 | 19.448 | 3.20 | 18.129 | 3.05 | |
| with GVAE+使用微调 | 12.952 | 2.36 | 19.725 | 3.02 | 15.880 | 3.13 | 22.591 | 3.09 | 19.436 | 3.14 | 18.117 | 2.99 | |
| 方法 | 求解时间/min | 平均求解时间/min | |||||
|---|---|---|---|---|---|---|---|
| 100G | 150U | 150G | 200U | 200G | |||
| 专业求解器 | HGS[ | 13.00 | 36.00 | 36.00 | 48.00 | 48.00 | 36.00 |
| LKH3[ | 10.00 | 30.00 | 30.00 | 42.00 | 42.00 | 30.00 | |
| 深度强化学习 | AM[ | 3.00 | 7.00 | 7.00 | 15.00 | 14.00 | 9.20 |
| POMO[ | 0.15 | 0.43 | 0.43 | 0.87 | 0.80 | 0.54 | |
| POMO-reptile[ | 0.15 | 0.43 | 0.43 | 0.87 | 0.80 | 0.54 | |
| 本文方法 | without GVAE | 0.15 | 0.43 | 0.43 | 0.87 | 0.80 | 0.54 |
| with GVAE | 0.15 | 0.43 | 0.43 | 0.87 | 0.80 | 0.54 | |
| with GVAE+使用微调 | 0.67 | 2.10 | 2.10 | 3.90 | 3.80 | 2.50 | |
Tab. 2 Solution time comparison of different methods on five tasks
| 方法 | 求解时间/min | 平均求解时间/min | |||||
|---|---|---|---|---|---|---|---|
| 100G | 150U | 150G | 200U | 200G | |||
| 专业求解器 | HGS[ | 13.00 | 36.00 | 36.00 | 48.00 | 48.00 | 36.00 |
| LKH3[ | 10.00 | 30.00 | 30.00 | 42.00 | 42.00 | 30.00 | |
| 深度强化学习 | AM[ | 3.00 | 7.00 | 7.00 | 15.00 | 14.00 | 9.20 |
| POMO[ | 0.15 | 0.43 | 0.43 | 0.87 | 0.80 | 0.54 | |
| POMO-reptile[ | 0.15 | 0.43 | 0.43 | 0.87 | 0.80 | 0.54 | |
| 本文方法 | without GVAE | 0.15 | 0.43 | 0.43 | 0.87 | 0.80 | 0.54 |
| with GVAE | 0.15 | 0.43 | 0.43 | 0.87 | 0.80 | 0.54 | |
| with GVAE+使用微调 | 0.67 | 2.10 | 2.10 | 3.90 | 3.80 | 2.50 | |
| [1] | 季彬,周赛琦,张政.分支定价方法求解带二维装箱约束的车辆路径问题[J].控制理论与应用,2023,40(3):409-418. |
| JI B, ZHOU S Q, ZHANG Z. Branch-and-price approach for solving the vehicle routing problem with two-dimensional loading constraints[J]. Control Theory and Applications, 2023, 40(3): 409-418. | |
| [2] | BOGYRBAYEVA A, MERALIYEV M, MUSTAKHOV T, et al. Machine learning to solve vehicle routing problems: a survey[J]. IEEE Transactions on Intelligent Transportation Systems, 2024, 25(6): 4754-4772. |
| [3] | 李熠胥,胡蓉,吴绍云,等.三阶段拉格朗日启发式算法求解带同时取送货的绿色车辆路径问题[J].控制与决策,2023,38(12): 3525-3533. |
| LI Y X, HU R, WU S Y, et al. Three-stage Lagrangian heuristic algorithm for solving green vehicle routing problem with simultaneous pickup and delivery[J]. Control and Decision, 2023, 38(12): 3525-3533. | |
| [4] | 罗佳,李朝锋.基于残差图卷积网络与深度强化学习的需求可拆分车辆路径优化算法[J].控制理论与应用,2024,41(6):1123-1136. |
| LUO J, LI C F. The split delivery vehicle routing optimization with the residual graph convolutional network and deep reinforcement learning[J]. Control Theory and Applications, 2024, 41(6): 1123-1136. | |
| [5] | BELLO I, PHAM H, LE V Q, et al. Neural combinatorial optimization with reinforcement learning[EB/OL]. [2024-06-12].. |
| [6] | NAZARI M, OROOJLOOY A, TAKÁČ M, et al. Reinforcement learning for solving the vehicle routing problem[C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2018: 9861-9871. |
| [7] | KOOL W, VAN HOOF H, WELLING M. Attention, learn to solve routing problems![EB/OL]. [2024-09-25].. |
| [8] | XIN L, SONG W, CAO Z, et al. Multi-decoder attention model with embedding glimpse for solving vehicle routing problems[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 12042-12049. |
| [9] | PENG B, WANG J, ZHANG Z. A deep reinforcement learning algorithm using dynamic attention model for vehicle routing problems[C]// Proceedings of the 2019 International Symposium on Intelligence Computation and Applications, CCIS 1205. Singapore: Springer, 2020: 636-650. |
| [10] | KWON Y D, CHOO J, KIM B, et al. POMO: policy optimization with multiple optima for reinforcement learning[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 21188-21198. |
| [11] | JIANG Y, CAO Z, WU Y, et al. Multi-view graph contrastive learning for solving vehicle routing problems[C]// Proceedings of the 39th Conference on Uncertainty in Artificial Intelligence. New York: JMLR.org, 2023: 984-994. |
| [12] | CHEN X, TIAN Y. Learning to perform local rewriting for combinatorial optimization[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 6281-6292. |
| [13] | WU Y, SONG W, CAO Z, et al. Learning improvement heuristics for solving routing problems[J]. IEEE Transactions on Neural Networks and Learning Systems, 2022, 33(9): 5057-5069. |
| [14] | MA Y, LI J, CAO Z, et al. Learning to iteratively solve routing problems with dual-aspect collaborative transformer[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 11096-11107. |
| [15] | ZHAO J, MAO M, ZHAO X, et al. A hybrid of deep reinforcement learning and local search for the vehicle routing problems[J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 22(11): 7208-7218. |
| [16] | KIPF T N, WELLING M. Variational graph auto-encoders[EB/OL]. [2024-12-01].. |
| [17] | PAN S, HU R, LONG G, et al. Adversarially regularized graph autoencoder for graph embedding[C]// Proceedings of the 27th International Joint Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2019: 2609-2615. |
| [18] | GROVER A, ZWEIG A, ERMON S. Graphite: iterative generative modeling of graphs[C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 2434-2444. |
| [19] | HOTTUNG A, KWON Y D, TIERNEY K. Efficient active search for combinatorial optimization problems[EB/OL]. [2024-07-09].. |
| [20] | BI J, MA Y, WANG J, et al. Learning generalizable models for vehicle routing problems via knowledge distillation[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 31226-31238. |
| [21] | 刘颖,雷研博,范九伦,等.基于小样本学习的图像分类技术综述[J].自动化学报,2021,47(2):297-315. |
| LIU Y, LEI Y B, FAN J L, et al. Survey on image classification technology based on small sample learning[J]. Acta Automatica Sinica, 2021, 47(2): 297-315. | |
| [22] | FINN C, ABBEEL P, LEVINE S. Model-agnostic meta-learning for fast adaptation of deep networks[C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 1126-1135. |
| [23] | NICHOL A, ACHIAM J, SCHULMAN J. On first-order meta-learning algorithms[EB/OL]. [2024-04-12].. |
| [24] | ZINTGRAF L, SHIARLI K, KURIN V, et al. Fast context adaptation via meta-learning[C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 7693-7702. |
| [25] | PATACCHIOLA M, BRONSKILL J, SHYSHEYA A, et al. Contextual squeeze-and-excitation for efficient few-shot image classification[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 36680-36692. |
| [26] | VIDAL T. Hybrid genetic search for the CVRP: open-source implementation and SWAP* neighborhood[J]. Computers and Operations Research, 2022, 140: No.105643. |
| [27] | HELSGAUN K. An extension of the Lin-Kernighan-Helsgaun TSP solver for constrained traveling salesman and vehicle routing problems[R/OL]. [2024-06-01].. |
| [28] | MANCHANDA S, MICHEL S, DRAKULIC D, et al. On the generalization of neural combinatorial optimization heuristics[C]// Proceedings of the 2022 Joint European Conference on Machine Learning and Knowledge Discovery in Databases, LNCS 1371. Cham: Springer, 2023: 426-442. |
| [1] | Qiaoling QI, Xiaoxiao WANG, Qianqian ZHANG, Peng WANG, Yongfeng DONG. Label noise adaptive learning algorithm based on meta-learning [J]. Journal of Computer Applications, 2025, 45(7): 2113-2122. |
| [2] | Tianyu XUE, Aiping LI, Liguo DUAN. Vehicular edge computing scheme with task offloading and resource optimization [J]. Journal of Computer Applications, 2025, 45(6): 1766-1775. |
| [3] | Meng LUO, Chao GAO, Zhen WANG. Improvement method of heuristic vehicle routing algorithm based on constrained spectral clustering [J]. Journal of Computer Applications, 2025, 45(5): 1387-1394. |
| [4] | Kun FU, Shicong YING, Tingting ZHENG, Jiajie QU, Jingyuan CUI, Jianwei LI. Graph data augmentation method for few-shot node classification [J]. Journal of Computer Applications, 2025, 45(2): 392-402. |
| [5] | Huahua WANG, Liang HUANG, Jiajie CHEN, Jiening FANG. Dynamic allocation algorithm for multi-beam subcarriers of low orbit satellites based on deep reinforcement learning [J]. Journal of Computer Applications, 2025, 45(2): 571-577. |
| [6] | Lin WEI, Jinyang LI, Yajie WANG, Mengyang HE. Highly reliable matching method based on multi-dimensional resource measurement and rescheduling in computing power network [J]. Journal of Computer Applications, 2025, 45(11): 3632-3641. |
| [7] | Zhihao WU, Ziqiu CHI, Ting XIAO, Zhe WANG. Meta-learning adaption for few-shot text-to-speech [J]. Journal of Computer Applications, 2024, 44(5): 1629-1635. |
| [8] | Xuanfeng LI, Shengcai LIU, Ke TANG. Novel genetic algorithm for solving chance-constrained multiple-choice Knapsack problems [J]. Journal of Computer Applications, 2024, 44(5): 1378-1385. |
| [9] | Xiaoyan ZHAO, Wei HAN, Junna ZHANG, Peiyan YUAN. Collaborative offloading strategy in internet of vehicles based on asynchronous deep reinforcement learning [J]. Journal of Computer Applications, 2024, 44(5): 1501-1510. |
| [10] | Jianqiang LI, Zhou HE. Hybrid NSGA-Ⅱ for vehicle routing problem with multi-trip pickup and delivery [J]. Journal of Computer Applications, 2024, 44(4): 1187-1194. |
| [11] | Jiachen YU, Ye YANG. Irregular object grasping by soft robotic arm based on clipped proximal policy optimization algorithm [J]. Journal of Computer Applications, 2024, 44(11): 3629-3638. |
| [12] | Xiaomin ZHOU, Fei TENG, Yi ZHANG. Automatic international classification of diseases coding model based on meta-network [J]. Journal of Computer Applications, 2023, 43(9): 2721-2726. |
| [13] | Jian LIN, Jingxuan YE, Wenwen LIU, Xiaowen SHAO. Multimodal differential evolution algorithm for solving capacitated vehicle routing problem [J]. Journal of Computer Applications, 2023, 43(7): 2248-2254. |
| [14] | Hui WANG, Jianhong LI. Few-shot recognition method of 3D models based on Transformer [J]. Journal of Computer Applications, 2023, 43(6): 1750-1758. |
| [15] | Tengfei CAO, Yanliang LIU, Xiaoying WANG. Edge computing and service offloading algorithm based on improved deep reinforcement learning [J]. Journal of Computer Applications, 2023, 43(5): 1543-1550. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||