


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (5): 1562-1569.DOI: 10.11772/j.issn.1001-9081.2023050612
Special Issue: 网络与通信
• Network and communications • Previous Articles Next Articles
Rui TANG1,2( ), Chuanlin PANG2, Ruizhi ZHANG3, Chuan LIU1, Shibo YUE2
), Chuanlin PANG2, Ruizhi ZHANG3, Chuan LIU1, Shibo YUE2
Received:2023-05-22
Revised:2023-08-02
Accepted:2023-08-08
Online:2023-08-10
Published:2024-05-10
Contact:
Rui TANG
About author:PANG Chuanlin, born in 1997, M. S. candidate. His research interests include deep reinforcement learning.Supported by:
唐睿1,2(), 庞川林2, 张睿智3, 刘川1, 岳士博2
通讯作者:
唐睿
作者简介:庞川林(1997—),男,四川南充人,硕士研究生,主要研究方向:深度强化学习基金资助:CLC Number:
Rui TANG, Chuanlin PANG, Ruizhi ZHANG, Chuan LIU, Shibo YUE. DDPG-based resource allocation in D2D communication-empowered cellular network[J]. Journal of Computer Applications, 2024, 44(5): 1562-1569.
唐睿, 庞川林, 张睿智, 刘川, 岳士博. D2D通信增强的蜂窝网络中基于DDPG的资源分配[J]. 《计算机应用》唯一官方网站, 2024, 44(5): 1562-1569.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023050612

Fig. 1 D2D communication-empowered uplink cellular network

Fig. 2 Reinforcement learning model

Fig. 3 Offline training framework based on DDPG algorithm
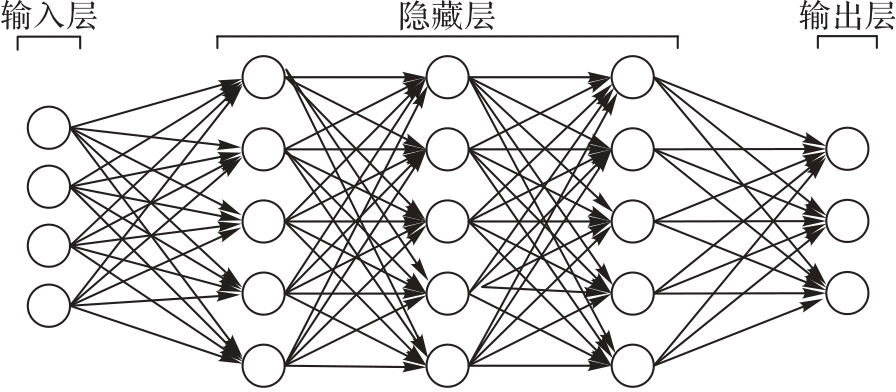
Fig. 4 Structure of fully connected feed-forward DNN
| 超参数 | 数值 |
|---|---|
| 训练轮数R | 2 000 |
| 每轮迭代次数T | 100 |
| 经验回放池大小 | 5 000 |
| mini-batch的大小 | 128 |
| 折扣系数 | 0.9 |
| 目标网络软更新系数 | 0.01 |
| 策略网络/目标策略网络中隐藏层层数 | 2 |
| 策略网络/目标策略网络中隐藏层神经元数 | (128,64) |
| Q值网络/目标Q值网络中隐藏层层数 | 2 |
| Q值网络/目标Q值网络中隐藏层神经元数 | (128,64) |
| 隐藏层激活函数 | ReLU |
| 输出层激活函数 | sigmoid |
| 优化器 | Adam |
Tab. 1 Hyperparameters setting in offline training
| 超参数 | 数值 |
|---|---|
| 训练轮数R | 2 000 |
| 每轮迭代次数T | 100 |
| 经验回放池大小 | 5 000 |
| mini-batch的大小 | 128 |
| 折扣系数 | 0.9 |
| 目标网络软更新系数 | 0.01 |
| 策略网络/目标策略网络中隐藏层层数 | 2 |
| 策略网络/目标策略网络中隐藏层神经元数 | (128,64) |
| Q值网络/目标Q值网络中隐藏层层数 | 2 |
| Q值网络/目标Q值网络中隐藏层神经元数 | (128,64) |
| 隐藏层激活函数 | ReLU |
| 输出层激活函数 | sigmoid |
| 优化器 | Adam |
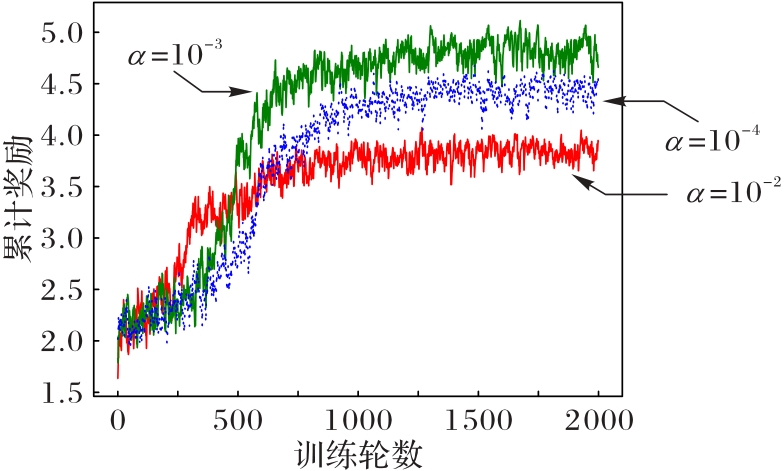
Fig. 5 Convergence of proposed offline training mechanism under different learning rates (M=6)

Fig. 6 Average convergence of best policy network in online deployment (M=6)

Fig.7 Variation of sum transmission rate with number of D2D pairs
| D2D对数 | 对比机制3 | 对比机制4 | 本文机制 |
|---|---|---|---|
| 3 | 0.034 6 | 2.146 | 0.032 9 |
| 4 | 0.035 3 | 3.859 | 0.034 3 |
| 5 | 0.036 9 | 8.257 | 0.035 2 |
| 6 | 0.037 3 | 16.359 | 0.036 7 |
| 7 | 0.037 8 | 30.436 | 0.037 5 |
Tab.2 Variation of operation time with number of D2D pairs
| D2D对数 | 对比机制3 | 对比机制4 | 本文机制 |
|---|---|---|---|
| 3 | 0.034 6 | 2.146 | 0.032 9 |
| 4 | 0.035 3 | 3.859 | 0.034 3 |
| 5 | 0.036 9 | 8.257 | 0.035 2 |
| 6 | 0.037 3 | 16.359 | 0.036 7 |
| 7 | 0.037 8 | 30.436 | 0.037 5 |
| 1 | ASADI A, WANG Q, MANCUSO V. A survey on device-to-device communication in cellular networks[J]. IEEE Communications Surveys & Tutorials, 2014, 16(4): 1801-1819. 10.1109/comst.2014.2319555 |
| 2 | SHEN Q, SHAO W, FU X. D2D relay incenting and charging modes that are commercially compatible with B2D services[J]. IEEE Access, 2019, 7: 36446-36458. 10.1109/access.2019.2904090 |
| 3 | HASHIM M F, ABDUL RAZAK N I. Ultra-dense networks: integration with device to device (D2D) communication[J]. Wireless Personal Communications, 2019, 106(2): 911-925. 10.1007/s11277-019-06195-3 |
| 4 | PAWAR P, TRIVEDI A. Device-to-device communication based IoT system: benefits and challenges[J]. IETE Technical Review, 2019, 36(4): 362-374. 10.1080/02564602.2018.1476191 |
| 5 | 李余,何希平,唐亮贵. 基于终端直通通信的多用户计算卸载资源优化决策[J]. 计算机应用, 2022, 42(5): 1538-1546. 10.11772/j.issn.1001-9081.2021030458 |
| LI Y, HE X P, TANG L G. Multi-user computation offloading and resource optimization policy based on device-to-device communication[J]. Journal of Computer Applications, 2022, 42(5): 1538-1546. 10.11772/j.issn.1001-9081.2021030458 | |
| 6 | TANG R, ZHAO J, QU H, et al. User-centric joint admission control and resource allocation for 5G D2D extreme mobile broadband: a sequential convex programming approach[J]. IEEE Communications Letters, 2017, 21(7): 1641-1644. 10.1109/lcomm.2017.2681664 |
| 7 | 尼俊红,申振涛,杨会峰. 蜂窝网络下基于max-min公平性的D2D功率分配[J]. 计算机应用, 2017, 37(4): 945-947. 10.11772/j.issn.1001-9081.2017.04.0945 |
| NI J H, SHEN Z T, YANG H F. D2D power allocation based on max-min fairness underlying cellular systems[J]. Journal of Computer Applications, 2017, 37(4): 945-947. 10.11772/j.issn.1001-9081.2017.04.0945 | |
| 8 | LYU J, CHEW Y H, W-C WONG. A Stackelberg game model for overlay D2D transmission with heterogeneous rate requirements[J]. IEEE Transactions on Vehicular Technology, 2016, 65(10): 8461-8475. 10.1109/tvt.2015.2511924 |
| 9 | YANG Z-Y, Y-W KUO. Efficient resource allocation algorithm for overlay D2D communication[J]. Computer Networks, 2017, 124: 61-71. 10.1016/j.comnet.2017.06.002 |
| 10 | SWAIN S N, MISHRA S, MURTHY C S R. A novel spectrum reuse scheme for interference mitigation in a dense overlay D2D network [C]// Proceedings of the 2015 IEEE 26th Annual International Symposium on Personal, Indoor, and Mobile Radio Communications. Piscataway: IEEE, 2015: 1201-1205. 10.1109/pimrc.2015.7343481 |
| 11 | 李中捷,谢东朋.异构蜂窝网络中联合功率控制的终端直通通信资源分配[J]. 计算机应用, 2018, 38(9): 2610-2615. |
| LI Z J, XIE D P. Joint power controlled resource allocation scheme for device-to-device communication in heterogeneous cellular networks[J]. Journal of Computer Applications, 2018, 38(9): 2610-2615. | |
| 12 | ZAPPONE A, DI RENZO M, DEBBAH M. Wireless networks design in the era of deep learning: model-based, AI-based, or both?[J]. IEEE Transactions on Communications, 2019, 67(10): 7331-7376. 10.1109/tcomm.2019.2924010 |
| 13 | ZHAO N, LIANG Y-C, NIYATO D, et al. Deep reinforcement learning for user association and resource allocation in heterogeneous cellular networks[J]. IEEE Transactions on Wireless Communications, 2019, 18(11): 5141-5152. 10.1109/twc.2019.2933417 |
| 14 | NASIR Y S, GUO D. Multi-agent deep reinforcement learning for dynamic power allocation in wireless networks[J]. IEEE Journal on Selected Areas in Communications, 2019, 37(10): 2239-2250. 10.1109/jsac.2019.2933973 |
| 15 | TAN J, LIANG Y-C, ZHANG L, et al. Deep reinforcement learning for joint channel selection and power control in D2D networks[J]. IEEE Transactions on Wireless Communications, 2021, 20(2): 1363-1378. 10.1109/twc.2020.3032991 |
| 16 | LEE H-S. Channel metamodeling for explainable data-driven channel model[J]. IEEE Wireless Communications Letters, 2021, 10(12): 2678-2682. 10.1109/lwc.2021.3111874 |
| 17 | SHEN K, YU W. Fractional programming for communication systems — Part I: power control and beamforming[J]. IEEE Transactions on Signal Processing, 2018, 66(10): 2616-2630. 10.1109/tsp.2018.2812733 |
| 18 | LUO Z-Q, ZHANG S. Dynamic spectrum management: complexity and duality[J]. IEEE Journal of Selected Topics in Signal Processing, 2008, 2(1): 57-73. 10.1109/jstsp.2007.914876 |
| 19 | 马礼智,唐睿,张睿智,等.基于无线能量传输的物联网数据采集系统中资源分配机制的设计[J].信息与控制,2023,52(2):220-234. 10.13976/j.cnki.xk.2023.2034 |
| MA L Z, TANG R, ZHANG R Z, et al. Design of resource allocation mechanisms for wireless power transfer-based Internet-of-things data collection system[J]. Information and Control, 2023, 52(2): 220-234. 10.13976/j.cnki.xk.2023.2034 | |
| 20 | SILVER D, HUANG A, MADDISON C J, et al. Mastering the game of go with deep neural networks and tree search[J]. Nature, 2016, 529(7587): 484-489. 10.1038/nature16961 |
| 21 | TANG R, ZHANG R, XU Y, et al. Energy-efficient optimization algorithm in NOMA-based UAV-assisted data collection systems[J]. IEEE Wireless Communications Letters, 2023, 12(1): 158-162. 10.1109/lwc.2022.3219675 |
| 22 | ZHANG R, TANG R, XU Y, et al. Resource allocation for UAV-assisted NOMA systems with dual connectivity[J]. IEEE Wireless Communications Letters, 2023, 12(2): 341-345. 10.1109/lwc.2022.3226265 |
| 23 | KIRAN B R, SOBH I, TALPAERT V, et al. Deep reinforcement learning for autonomous driving: a survey[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(6): 4909-4926. 10.1109/tits.2021.3054625 |
| 24 | MABU S, HATAKEYAMA H, HIRASAWA K, et al. Genetic network programming with reinforcement learning using SARSA algorithm [C]// Proceedings of the 2006 IEEE International Conference on Evolutionary Computation. Piscataway: IEEE, 2006: 463-469. |
| 25 | KIUMARSI B, LEWIS F L, MODARES H, et al. Reinforcement Q-learning for optimal tracking control of linear discrete-time systems with unknown dynamics[J]. Automatica, 2014, 50(4): 1167-1175. 10.1016/j.automatica.2014.02.015 |
| 26 | ALZUBAIDI L, ZHANG J, HUMAIDI A J, et al. Review of deep learning: concepts, CNN architectures, challenges, applications, future directions[J]. Journal of Big Data, 2021, 8: No. 53. 10.1186/s40537-021-00444-8 |
| 27 | LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[EB/OL]. [2023-05-01]. . |
| 28 | LESHNO M, LIN V Y, PINKUS A, et al. Multilayer feedforward networks with a nonpolynomial activation function can approximate any function[J]. Neural Networks, 1993, 6(6): 861-867. 10.1016/s0893-6080(05)80131-5 |
| 29 | KINGMA D P, BA J. Adam: a method for stochastic optimization[EB/OL]. [2023-05-01]. . |
| 30 | FRANÇOIS-LAVET V, HENDERSON P, ISLAM R, et al. An introduction to deep reinforcement learning[J]. Foundations & Trends in Machine Learning, 2018, 11(3/4): 219-354. 10.1561/2200000071 |
| 31 | HERBERT S, WASSELL I, T-H LOH, et al. Characterizing the spectral properties and time variation of the in-vehicle wireless communication channel[J]. IEEE Transactions on Communications, 2014, 62(7): 2390-2399. 10.1109/TCOMM.2014.2328635 |
| [1] | Chuanlin PANG, Rui TANG, Ruizhi ZHANG, Chuan LIU, Jia LIU, Shibo YUE. Distributed power allocation algorithm based on graph convolutional network for D2D communication systems [J]. Journal of Computer Applications, 2024, 44(9): 2855-2862. |
| [2] | Yi ZHOU, Hua GAO, Yongshen TIAN. Proximal policy optimization algorithm based on clipping optimization and policy guidance [J]. Journal of Computer Applications, 2024, 44(8): 2334-2341. |
| [3] | Tian MA, Runtao XI, Jiahao LYU, Yijie ZENG, Jiayi YANG, Jiehui ZHANG. Mobile robot 3D space path planning method based on deep reinforcement learning [J]. Journal of Computer Applications, 2024, 44(7): 2055-2064. |
| [4] | Junna ZHANG, Xinxin WANG, Tianze LI, Xiaoyan ZHAO, Peiyan YUAN. Task offloading method based on dynamic service cache assistance [J]. Journal of Computer Applications, 2024, 44(5): 1493-1500. |
| [5] | Xiaoyan ZHAO, Wei HAN, Junna ZHANG, Peiyan YUAN. Collaborative offloading strategy in internet of vehicles based on asynchronous deep reinforcement learning [J]. Journal of Computer Applications, 2024, 44(5): 1501-1510. |
| [6] | Hualiang LUO, Quanzhong LI, Qi ZHANG. Robust resource allocation optimization in cognitive wireless network integrating information communication and over-the-air computation [J]. Journal of Computer Applications, 2024, 44(4): 1195-1202. |
| [7] | Fatang CHEN, Miao HUANG, Yufeng JIN. Resource allocation algorithm for low earth orbit satellites oriented to user demand [J]. Journal of Computer Applications, 2024, 44(4): 1242-1247. |
| [8] | Rui TANG, Shibo YUE, Ruizhi ZHANG, Chuan LIU, Chuanlin PANG. Energy efficiency optimization mechanism for UAV-assisted and non-orthogonal multiple access-enabled data collection system [J]. Journal of Computer Applications, 2024, 44(4): 1209-1218. |
| [9] | Xintong QIN, Zhengyu SONG, Tianwei HOU, Feiyue WANG, Xin SUN, Wei LI. Channel access and resource allocation algorithm for adaptive p-persistent mobile ad hoc network [J]. Journal of Computer Applications, 2024, 44(3): 863-868. |
| [10] | Yuanchao LI, Chongben TAO, Chen WANG. Gait control method based on maximum entropy deep reinforcement learning for biped robot [J]. Journal of Computer Applications, 2024, 44(2): 445-451. |
| [11] | Fuqin DENG, Huifeng GUAN, Chaoen TAN, Lanhui FU, Hongmin WANG, Tinlun LAM, Jianmin ZHANG. Multi-robot reinforcement learning path planning method based on request-response communication mechanism and local attention mechanism [J]. Journal of Computer Applications, 2024, 44(2): 432-438. |
| [12] | Jiachen YU, Ye YANG. Irregular object grasping by soft robotic arm based on clipped proximal policy optimization algorithm [J]. Journal of Computer Applications, 2024, 44(11): 3629-3638. |
| [13] | Yu WANG, Zhihui GUAN, Yuanpeng LI. Distributed UAV cluster pursuit decision-making based on trajectory prediction and MADDPG [J]. Journal of Computer Applications, 2024, 44(11): 3623-3628. |
| [14] | Jie LONG, Liang XIE, Haijiao XU. Integrated deep reinforcement learning portfolio model [J]. Journal of Computer Applications, 2024, 44(1): 300-310. |
| [15] | Yongjian MA, Xuhua SHI, Peiyao WANG. Constrained multi-objective evolutionary algorithm based on two-stage search and dynamic resource allocation [J]. Journal of Computer Applications, 2024, 44(1): 269-277. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||