


Journal of Computer Applications ›› 2025, Vol. 45 ›› Issue (12): 3839-3846.DOI: 10.11772/j.issn.1001-9081.2024121841
• Artificial intelligence • Previous Articles Next Articles
Dongwei ZHANG1, Zheng YE1,2( ), Jun GE3
), Jun GE3
Received:2024-12-31
Revised:2025-02-24
Accepted:2025-04-07
Online:2025-06-05
Published:2025-12-10
Contact:
Zheng YE
About author:ZHANG Dongwei, born in 1999, M. S. candidate. His research interests include natural language processing.Supported by:
张东伟1, 叶正1,2(), 葛君3
通讯作者:
叶正
作者简介:张东伟(1999—),男(苗族),湖南湘西人,硕士研究生,主要研究方向:自然语言处理基金资助:CLC Number:
Dongwei ZHANG, Zheng YE, Jun GE. CovMW-net: robust text matching method based on meta-weight network[J]. Journal of Computer Applications, 2025, 45(12): 3839-3846.
张东伟, 叶正, 葛君. 基于元权重网络的鲁棒性文本匹配方法CovMW-net[J]. 《计算机应用》唯一官方网站, 2025, 45(12): 3839-3846.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2024121841
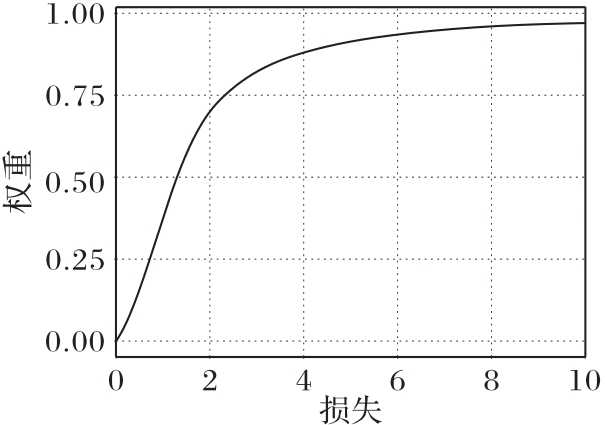
Fig.1 Weight function in Focal Loss
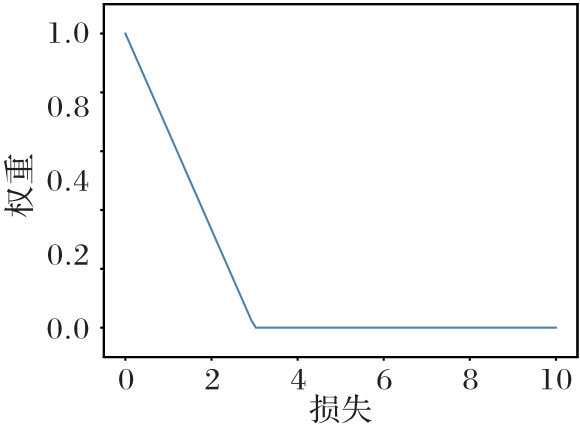
Fig.2 Weight function in SPL
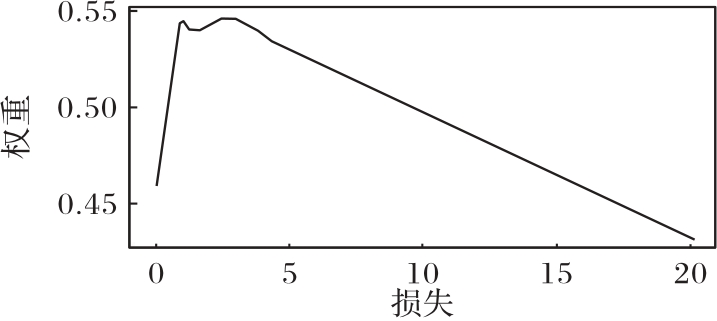
Fig.3 MW-net function learned on Clothing1M dataset
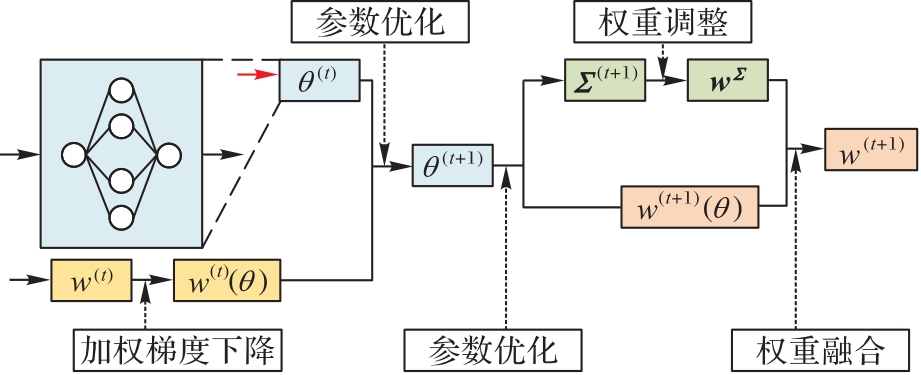
Fig.4 Process of updating significant hyperparameters in CovMW-net
| 序号 | 方法 | 准确率/% | 序号 | 方法 | 准确率/% |
|---|---|---|---|---|---|
| 1 | CrossEntropy | 68.94 | 6 | MW-net | 73.70 |
| 2 | Bootstrapping | 69.12 | 7 | MetaBalance | 74.12 |
| 3 | Forward | 69.84 | 8 | FSR | 74.03 |
| 4 | JointOptimization | 72.23 | 9 | EMN | 74.14 |
| 5 | MLNT | 73.47 | 本文方法 | 74.56 |
Tab. 1 Experimental results of accuracy on Clothing1M dataset
| 序号 | 方法 | 准确率/% | 序号 | 方法 | 准确率/% |
|---|---|---|---|---|---|
| 1 | CrossEntropy | 68.94 | 6 | MW-net | 73.70 |
| 2 | Bootstrapping | 69.12 | 7 | MetaBalance | 74.12 |
| 3 | Forward | 69.84 | 8 | FSR | 74.03 |
| 4 | JointOptimization | 72.23 | 9 | EMN | 74.14 |
| 5 | MLNT | 73.47 | 本文方法 | 74.56 |
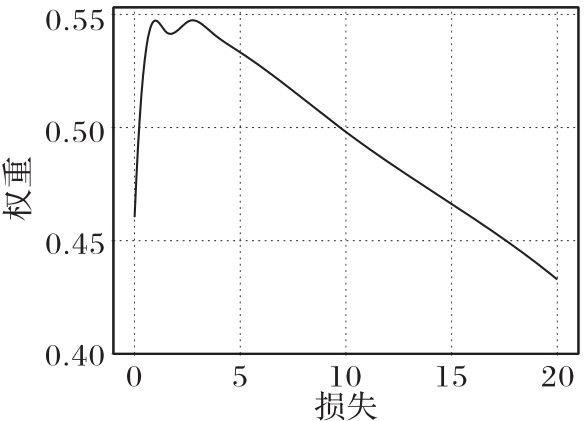
Fig.5 CovMW-net function learned on Clothing1M dataset
| 类型 | LCQMC数据集 | BQ数据集 | ||||
|---|---|---|---|---|---|---|
| 问题一 | 问题二 | 标签 | 问题一 | 问题二 | 标签 | |
| 含义一致文本 | 看图猜一电影名 | 看图猜电影 | 1 | 贷款后多久接听电话 | 借款后什么时候来客服电话 | 1 |
| 含义不同文本 | 无线路由器怎么无线上网 | 无线上网卡和无线路由器怎么用 | 0 | 开通要钱不 | 不会乱收费吧 | 0 |
Tab. 2 Samples of LCQMC dataset and BQ dataset
| 类型 | LCQMC数据集 | BQ数据集 | ||||
|---|---|---|---|---|---|---|
| 问题一 | 问题二 | 标签 | 问题一 | 问题二 | 标签 | |
| 含义一致文本 | 看图猜一电影名 | 看图猜电影 | 1 | 贷款后多久接听电话 | 借款后什么时候来客服电话 | 1 |
| 含义不同文本 | 无线路由器怎么无线上网 | 无线上网卡和无线路由器怎么用 | 0 | 开通要钱不 | 不会乱收费吧 | 0 |
| 数据集 | 训练集 问题对数量 | 开发集 问题对数量 | 测试集 问题对数量 |
|---|---|---|---|
| LCQMC | 238 766 | 8 802 | 12 500 |
| BQ Corpus | 100 000 | 10 000 | 10 000 |
Tab. 3 Data statistics of LCQMC dataset and BQ dataset
| 数据集 | 训练集 问题对数量 | 开发集 问题对数量 | 测试集 问题对数量 |
|---|---|---|---|
| LCQMC | 238 766 | 8 802 | 12 500 |
| BQ Corpus | 100 000 | 10 000 | 10 000 |
| 模型 | LCQMC数据集 | BQ数据集 | ||
|---|---|---|---|---|
| ERNIE | ERNIE-ATT | ERNIE | ERNIE-ATT | |
| baseline | 0.898 | 0.846 | 0.858 | 0.821 |
| MW‑net | 0.926 | 0.881 | 0.861 | 0.857 |
| CovMW‑net | 0.939 | 0.896 | 0.878 | 0.881 |
Tab. 4 Experimental results on LCQMC and BQ datasets
| 模型 | LCQMC数据集 | BQ数据集 | ||
|---|---|---|---|---|
| ERNIE | ERNIE-ATT | ERNIE | ERNIE-ATT | |
| baseline | 0.898 | 0.846 | 0.858 | 0.821 |
| MW‑net | 0.926 | 0.881 | 0.861 | 0.857 |
| CovMW‑net | 0.939 | 0.896 | 0.878 | 0.881 |
| [1] | 王新宇,王宏生. 基于深度学习的文本匹配技术的研究综述[J]. 信息与电脑, 2020, 32(15): 73-74. |
| WANG X Y, WANG H S. Research summary of text matching techniques based on deep learning[J]. China Computer & Communication, 2020, 32(15): 73-74. | |
| [2] | BAU D, ZHU J Y, STROBELT H, et al. Understanding the role of individual units in a deep neural network[J]. Proceedings of the National Academy of Sciences, 2020, 117(48): 30071-30078. |
| [3] | FINN C, ABBEEL P, LENVINE S. Model-agnostic meta-learning for fast adaptation of deep networks[C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 1126-1135. |
| [4] | GHAROUN H, MOMENIFAR F, CHEN F, et al. Meta-learning approaches for few-shot learning: a survey of recent advances[J]. ACM Computing Surveys, 2024, 56(12): No.294. |
| [5] | SHU J, XIE Q, YI L, et al. Meta-weight-net: learning an explicit mapping for sample weighting[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2019: 1919-1930. |
| [6] | RIYANTO S, SITANGGANG I S, DJATNA T, et al. Comparative analysis using various performance metrics in imbalanced data for multi-class text classification[J]. International Journal of Advanced Computer Science and Applications, 2023, 14(6): 1082-1090. |
| [7] | KARIMI D, DOU H, WARFIELD S K, et al. Deep learning with noisy labels: exploring techniques and remedies in medical image analysis[J]. Medical Image Analysis, 2020, 65: No.101759. |
| [8] | WANG J X. Meta-learning in natural and artificial intelligence[J]. Current Opinion in Behavioral Sciences, 2021, 38: 90-95. |
| [9] | TAUD H, MAS J F. MultiLayer Perceptron (MLP)[M]// CAMACHO OLMEDO M, PAEGELOW M, MAS J F, et al Geomatic approaches for modeling land change scenarios. Cham: Springer, 2018: 451-455. |
| [10] | 程宁,戴远泉. 基于核协方差矩阵的无监督数据聚类[J]. 计算机应用与软件, 2023, 40(5): 288-296. |
| CHENG N, DAI Y Q. Unsupervised data clustering based on kernel covariance matrix[J]. Computer Applications and Software, 2023, 40(5): 288-296. | |
| [11] | XIAO T, XIA T, YANG Y, et al. Learning from massive noisy labeled data for image classification[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 2691-2699. |
| [12] | LIU X, CHEN Q, DENG C, et al. LCQMC: a large-scale Chinese question matching corpus[C]// Proceedings of the 27th International Conference on Computational Linguistics. Stroudsburg: ACL, 2018: 1952-1962. |
| [13] | CHEN J, CHEN Q, LU X, et al. The BQ corpus: a large-scale domain-specific Chinese corpus for sentence semantic equivalence identification[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2018: 4946-4951. |
| [14] | FAN Y, XIA Y, WU L, et al. Learning to reweight with deep interactions[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 7385-7393. |
| [15] | SHAHRAKI A, ABBASI M, HAUGEN Ø. Boosting algorithms for network intrusion detection: a comparative evaluation of Real AdaBoost, Gentle AdaBoost and Modest AdaBoost[J]. Engineering Applications of Artificial Intelligence, 2020, 94: No.103770. |
| [16] | 黄月平,李小锋,齐乃新,等. 基于难例挖掘和自适应时间正则化的视觉目标跟踪算法[J]. 机器人, 2021, 43(3): 350-363. |
| HUANG Y P, LI X F, QI N X, et al. Visual object tracking algorithm based on hard negative mining and adaptive temporal regularization[J]. Robot, 2021, 43(3): 350-363. | |
| [17] | QIAN X, GAO S, DENG W, et al. Improving oriented object detection by scene classification and task-aligned focal loss[J]. Mathematics, 2024, 12(9): No.1343. |
| [18] | OBIEDAT Q M, SCHWARTZ J K, MENDONCA R, et al. Studying the educational effect of a self-paced learning protocol for evaluating community environment accessibility: a preliminary analysis[J]. American Journal of Occupational Therapy, 2022, 76(S1): No.7610500021p1. |
| [19] | GE Z, WU Z, ZHANG X, et al. An extrapolated proximal iteratively reweighted method for nonconvex composite optimization problems[J]. Journal of Global Optimization, 2023, 86(4): 821-844. |
| [20] | REN M, ZENG W, YANG B, et al. Learning to reweight examples for robust deep learning[C]// Proceedings of the 35th International Conference on Machine Learning. New York: JMLR.org, 2018: 4334-4343. |
| [21] | ZHANG Z, PFISTER T. Learning fast sample re-weighting without reward data[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 705-714. |
| [22] | HE Y, FENG X, CHENG C, et al. MetaBalance: improving multi-task recommendations via adapting gradient magnitudes of auxiliary tasks[C]// Proceedings of the ACM Web Conference 2022. New York: ACM, 2022: 2205-2215. |
| [23] | 王佳琦,袁野,朱永同,等. 基于自适应重加权和正则化的集成元学习算法[J]. 计算机应用研究, 2024, 41(6): 1749-1755. |
| WANG J Q, YUAN Y, ZHU Y T, et al. Ensemble meta net based on adaptive reweight and regularization[J]. Application Research of Computers, 2024, 41(6): 1749-1755. | |
| [24] | LI S, GONG K, LIU C H, et al. MetaSAug: meta semantic augmentation for long-tailed visual recognition[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 5208-5217. |
| [25] | 余晨. 基于对数先验的协方差矩阵的参数估计[J]. 理论数学, 2024, 14(5): 479-488. |
| YU C. Parameter estimation of covariance matrix based on logarithmic prior[J]. Theoretical Mathematics, 2024, 14(5): 479-488. | |
| [26] | 王兴趣,贾世会,迟晓妮. 广义加权鲁棒主成分分析(GWRPCA) 的模型与算法[J]. 系统科学与数学, 2021, 41(12): 3363-3373. |
| WANG X Q, JIA S H, CHI X N. The model and algorithm of Generalized Weighted Robust Principal Component Analysis (GWRPCA)[J]. Journal of Systems Science and Mathematical Sciences, 2021, 41(12): 3363-3373. | |
| [27] | CHEN Y, SHEN X, HU S X, et al. Boosting co-teaching with compression regularization for label noise[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 2682-2686. |
| [28] | KOONCE B. ResNet 50[M]// Convolutional neural networks with swift for TensorFlow: image recognition and dataset categorization. Berkeley: Apress, 2021: 63-72. |
| [29] | MAO A, MOHRI M, ZHONG Y. Cross-entropy loss functions: theoretical analysis and applications[C]// Proceedings of the 2023 International Conference on Machine Learning. New York: JMLR.org, 2023: 23803-23828. |
| [30] | ZELIKMAN E, WU Y, MU J, et al. STaR: bootstrapping reasoning with reasoning[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2022: 15476-15488. |
| [31] | BRENIG J, TIMOFTE R. A study of forward-forward algorithm for self-supervised learning [EB/OL]. [2025-01-30]. . |
| [32] | LIU J, LI H B, HIMED B. Joint optimization of transmit and receive beamforming in active arrays[J]. IEEE Signal Processing Letters, 2014, 21(1): 39-42. |
| [33] | LI J N. Learning to learn from noisy labeled data[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 5051-5059. |
| [34] | SUN Y, WANG S, FENG S, et al. ERNIE 3.0: large-scale knowledge enhanced pre-training for language understanding and generation[EB/OL]. [2024-11-21].. |
| [35] | 车林威. 基于预训练模型的问题匹配任务鲁棒性研究[D]. 武汉:中南民族大学, 2024: 27-40. |
| CHE L W. Research on the robustness of question matching tasks based on pre-trained models[D]. Wuhan: South-Central Minzu University, 2024: 27-40. | |
| [36] | 宋中山,周珊,艾勇,等. 基于GhostNet的改进模型轻量化方法[J]. 中南民族大学学报(自然科学版), 2024, 43(5): 629-636. |
| SONG Z S, ZHOU S, AI Y, et al. Improved model lightweighting method based on GhostNet[J]. Journal of South-central Minzu University (Natural Science Edition), 2024, 43(5): 629-636. |
| [1] | Zhenzhou WANG, Fangfang GUO, Jingfang SU, He SU, Jianchao WANG. Robustness optimization method of visual model for intelligent inspection [J]. Journal of Computer Applications, 2025, 45(7): 2361-2368. |
| [2] | Qianting ZHANG, Liying HU, Lifei CHEN. Robust shapelet representation method for time series [J]. Journal of Computer Applications, 2025, 45(2): 436-443. |
| [3] | Donghong ZHAO, Chuangxin ZHAO, Hewei NIE, Quhui ZHANG, Jiaqi YANG. Design of a longitudinal trajectory tracking control law for somersault maneuver flight [J]. Journal of Computer Applications, 2025, 45(11): 3739-3746. |
| [4] | Xuebin CHEN, Zhiqiang REN, Hongyang ZHANG. Review on security threats and defense measures in federated learning [J]. Journal of Computer Applications, 2024, 44(6): 1663-1672. |
| [5] | Weina DONG, Jia LIU, Xiaozhong PAN, Lifeng CHEN, Wenquan SUN. High-capacity robust image steganography scheme based on encoding-decoding network [J]. Journal of Computer Applications, 2024, 44(3): 772-779. |
| [6] | Xuan CAO, Tianjian LUO. Dynamic multi-domain adversarial learning method for cross-subject motor imagery EEG signals [J]. Journal of Computer Applications, 2024, 44(2): 645-653. |
| [7] | Jintao RAO, Zhe CUI. Electronic voting scheme based on SM2 threshold blind signature [J]. Journal of Computer Applications, 2024, 44(2): 512-518. |
| [8] | Jie HUANG, Ruizi WU, Junli LI. Efficient adaptive robustness optimization algorithm for complex networks [J]. Journal of Computer Applications, 2024, 44(11): 3530-3539. |
| [9] | Han WANG, Yuan WAN, Dong WANG, Yiming DING. Robust weight matrix combination selection method of broad learning system [J]. Journal of Computer Applications, 2024, 44(10): 3032-3038. |
| [10] | Xuyan ZHAO, Yunhe CUI, Chaohui JIANG, Qing QIAN, Guowei SHEN, Chun GUO, Xianchao LI. CHAIN: edge computing node placement algorithm based on overlapping domination [J]. Journal of Computer Applications, 2023, 43(9): 2812-2818. |
| [11] | Mengting GE, Minghua WAN. Feature extraction model based on neighbor supervised locally invariant robust principal component analysis [J]. Journal of Computer Applications, 2023, 43(4): 1013-1020. |
| [12] | Jian GAO, Zhi LI, Bin FAN, Chuanxian JIANG. Efficient robust zero-watermarking algorithm for 3D medical images based on ray-casting sampling and quaternion orthogonal moment [J]. Journal of Computer Applications, 2023, 43(4): 1191-1197. |
| [13] | Xianbojun FAN, Lijia CHEN, Shen LI, Chenlu WANG, Min WANG, Zan WANG, Mingguo LIU. Robust joint modeling and optimization method for visual manipulators [J]. Journal of Computer Applications, 2023, 43(3): 962-971. |
| [14] | Mengdi SUN, Zhonggui SUN, Xu KONG, Hongyan HAN. Design of guided adaptive mathematical morphology for multimodal images [J]. Journal of Computer Applications, 2023, 43(2): 560-566. |
| [15] | Yuntao ZHAO, Wanqi XIE, Weigang LI, Jiaming HU. Robot hand-eye calibration algorithm based on covariance matrix adaptation evolutionary strategy [J]. Journal of Computer Applications, 2023, 43(10): 3225-3229. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||