


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (2): 580-586.DOI: 10.11772/j.issn.1001-9081.2025020241
• Multimedia computing and computer simulation • Previous Articles
Yuebo FAN, Mingxuan CHEN( ), Xian TANG, Yongbin GAO, Wenchao LI
), Xian TANG, Yongbin GAO, Wenchao LI
Received:2025-03-11
Revised:2025-05-10
Accepted:2025-05-15
Online:2025-06-10
Published:2026-02-10
Contact:
Mingxuan CHEN
About author:FAN Yuebo, born in 2000, M. S. candidate. His research interests include computer vision, machine learning.
樊跃波, 陈明轩(), 汤显, 高永彬, 李文超
通讯作者:
陈明轩
作者简介:樊跃波(2000—),男,河南长垣人,硕士研究生,主要研究方向:计算机视觉、机器学习CLC Number:
Yuebo FAN, Mingxuan CHEN, Xian TANG, Yongbin GAO, Wenchao LI. Multi-dimensional frequency domain feature fusion for human-object interaction detection[J]. Journal of Computer Applications, 2026, 46(2): 580-586.
樊跃波, 陈明轩, 汤显, 高永彬, 李文超. 基于多维频域特征融合的人物交互检测[J]. 《计算机应用》唯一官方网站, 2026, 46(2): 580-586.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025020241

Fig. 1 Structure of MFNet model
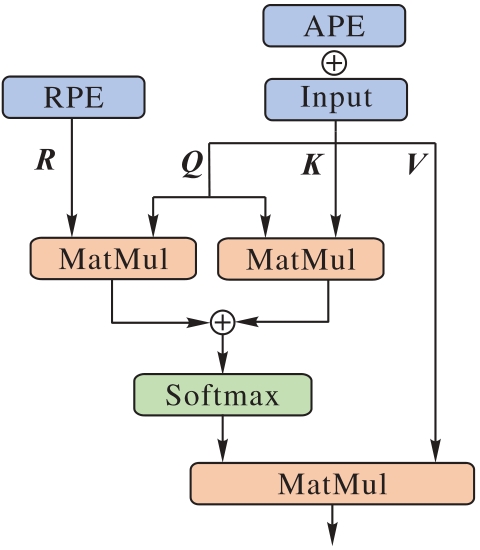
Fig. 2 Structure of HPE Self-Attention
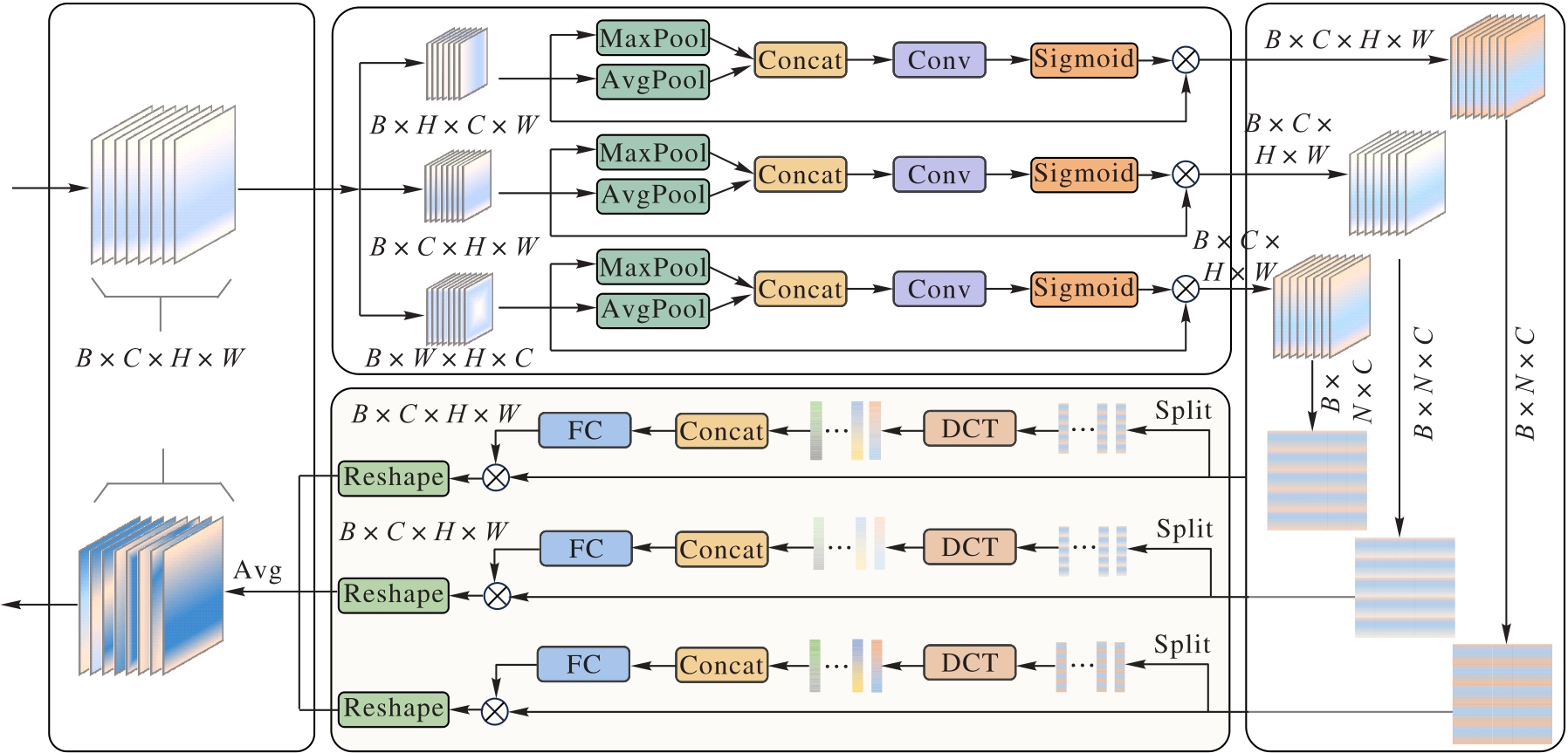
Fig. 3 Structure of MFF module
| 模型 | Backbone | mAP/% | ||
|---|---|---|---|---|
| Full | Rare | Non-rare | ||
| DRG[ | ResNet50-FPN | 19.26 | 17.74 | 19.71 |
| HOTR[ | ResNet50 | 25.10 | 17.34 | 27.42 |
| HOI-Trans[ | ResNet101 | 26.61 | 19.15 | 28.84 |
| SCG[ | ResNet50-FPN | 29.26 | 24.61 | 30.65 |
| QPIC[ | ResNet101 | 29.90 | 23.92 | 31.69 |
| MSTR[ | ResNet50 | 31.17 | 25.31 | 32.92 |
| UPT[ | ResNet50 | 31.66 | 25.94 | 33.36 |
| CDN[ | ResNet50 | 31.78 | 27.55 | 33.05 |
| CycleHOI[ | ResNet50 | 32.23 | 25.27 | 34.01 |
| GEN-VLKT[ | ResNet50 | 32.37 | 26.13 | 34.24 |
| OpenCat[ | ResNet101 | 32.68 | 28.42 | 33.75 |
| PRNet[ | ResNet101 | 32.86 | 28.03 | 34.30 |
| AFFNSNet[ | ResNet50 | 33.08 | 28.66 | 34.41 |
| MFNet | ResNet50 | 33.32 | 28.44 | 34.77 |
Tab. 1 Comparison of detection performance on HICO-DET test set
| 模型 | Backbone | mAP/% | ||
|---|---|---|---|---|
| Full | Rare | Non-rare | ||
| DRG[ | ResNet50-FPN | 19.26 | 17.74 | 19.71 |
| HOTR[ | ResNet50 | 25.10 | 17.34 | 27.42 |
| HOI-Trans[ | ResNet101 | 26.61 | 19.15 | 28.84 |
| SCG[ | ResNet50-FPN | 29.26 | 24.61 | 30.65 |
| QPIC[ | ResNet101 | 29.90 | 23.92 | 31.69 |
| MSTR[ | ResNet50 | 31.17 | 25.31 | 32.92 |
| UPT[ | ResNet50 | 31.66 | 25.94 | 33.36 |
| CDN[ | ResNet50 | 31.78 | 27.55 | 33.05 |
| CycleHOI[ | ResNet50 | 32.23 | 25.27 | 34.01 |
| GEN-VLKT[ | ResNet50 | 32.37 | 26.13 | 34.24 |
| OpenCat[ | ResNet101 | 32.68 | 28.42 | 33.75 |
| PRNet[ | ResNet101 | 32.86 | 28.03 | 34.30 |
| AFFNSNet[ | ResNet50 | 33.08 | 28.66 | 34.41 |
| MFNet | ResNet50 | 33.32 | 28.44 | 34.77 |
| 模型 | Backbone | ||
|---|---|---|---|
| DRG[ | ResNet50-FPN | 51.0 | |
| HOI-Trans[ | ResNet101 | 52.9 | |
| SCG[ | ResNet50-FPN | 54.2 | 60.9 |
| HOTR[ | ResNet50 | 55.2 | 64.4 |
| QPIC[ | ResNet101 | 58.3 | 60.7 |
| UPT[ | ResNet50 | 59.0 | 64.5 |
| CDN[ | ResNet50 | 61.7 | 63.8 |
| OpenCat[ | ResNet101 | 61.9 | 63.2 |
| MSTR[ | ResNet50 | 62.0 | 65.2 |
| GEN-VLKT[ | ResNet50 | 62.4 | 64.5 |
| CycleHOI[ | ResNet50 | 62.4 | 64.7 |
| PRNet[ | ResNet101 | 62.9 | 64.2 |
| AFFNSNet[ | ResNet50 | 62.4 | 64.5 |
| MFNet | ResNet50 | 63.3 | 66.4 |
Tab. 2 Comparison of detection performance on V-COCO test set
| 模型 | Backbone | ||
|---|---|---|---|
| DRG[ | ResNet50-FPN | 51.0 | |
| HOI-Trans[ | ResNet101 | 52.9 | |
| SCG[ | ResNet50-FPN | 54.2 | 60.9 |
| HOTR[ | ResNet50 | 55.2 | 64.4 |
| QPIC[ | ResNet101 | 58.3 | 60.7 |
| UPT[ | ResNet50 | 59.0 | 64.5 |
| CDN[ | ResNet50 | 61.7 | 63.8 |
| OpenCat[ | ResNet101 | 61.9 | 63.2 |
| MSTR[ | ResNet50 | 62.0 | 65.2 |
| GEN-VLKT[ | ResNet50 | 62.4 | 64.5 |
| CycleHOI[ | ResNet50 | 62.4 | 64.7 |
| PRNet[ | ResNet101 | 62.9 | 64.2 |
| AFFNSNet[ | ResNet50 | 62.4 | 64.5 |
| MFNet | ResNet50 | 63.3 | 66.4 |
| 模型 | ||
|---|---|---|
| Base | 61.6 | 64.2 |
| Base+IRPE | 62.1 | 65.1 |
| Base+MFF | 63.0 | 66.0 |
| Base+WIoU | 63.3 | 66.4 |
Tab. 3 Ablation experiment results on V-COCO dataset
| 模型 | ||
|---|---|---|
| Base | 61.6 | 64.2 |
| Base+IRPE | 62.1 | 65.1 |
| Base+MFF | 63.0 | 66.0 |
| Base+WIoU | 63.3 | 66.4 |
| 模型 | mAP | ||
|---|---|---|---|
| Full | Rare | Non-rare | |
| Base | 32.37 | 26.13 | 34.24 |
| Base+IRPE | 32.68 | 26.81 | 34.42 |
| Base+MFF | 33.16 | 27.73 | 34.69 |
| Base+WIoU | 33.32 | 28.44 | 34.77 |
Tab. 4 Ablation experiments results on HICO-DET dataset
| 模型 | mAP | ||
|---|---|---|---|
| Full | Rare | Non-rare | |
| Base | 32.37 | 26.13 | 34.24 |
| Base+IRPE | 32.68 | 26.81 | 34.42 |
| Base+MFF | 33.16 | 27.73 | 34.69 |
| Base+WIoU | 33.32 | 28.44 | 34.77 |
| 方法 | ||
|---|---|---|
| MFF(base) | 62.6 | 65.1 |
| MFF(base+rotate-W) | 62.9 | 65.8 |
| MFF(base+rotate-H) | 62.9 | 65.6 |
| MFF(full) | 63.3 | 66.4 |
Tab. 5 MFF branch structure design on V-COCO dataset
| 方法 | ||
|---|---|---|
| MFF(base) | 62.6 | 65.1 |
| MFF(base+rotate-W) | 62.9 | 65.8 |
| MFF(base+rotate-H) | 62.9 | 65.6 |
| MFF(full) | 63.3 | 66.4 |

Fig. 4 Visualization results of movements
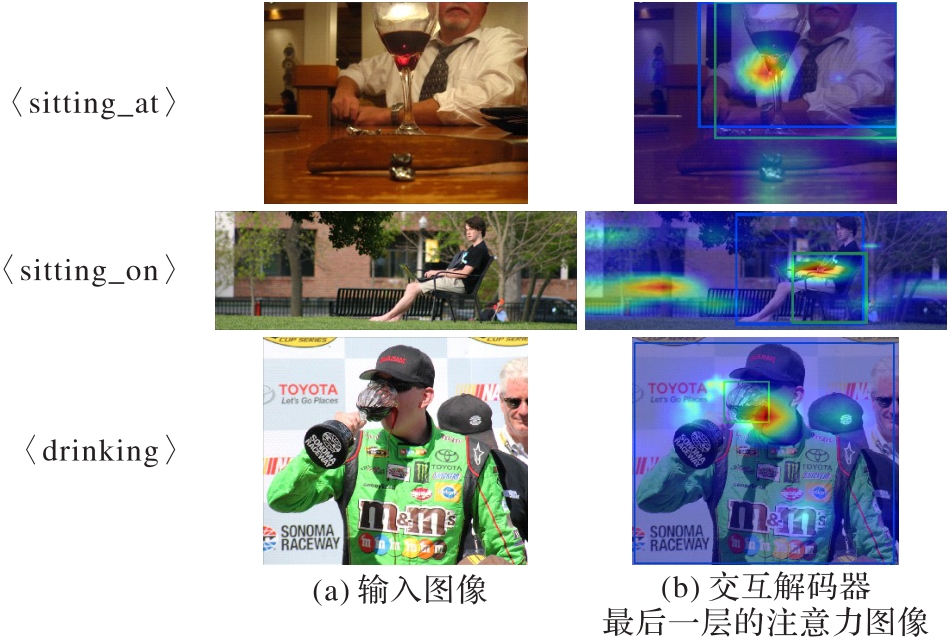
Fig. 5 Visualized attention results
| [1] | 龚勋,张志莹,刘璐,等. 人物交互检测研究进展综述[J]. 西南交通大学学报, 2022, 57(4): 693-704. |
| GONG X, ZHANG Z Y, LIU L, et al. A survey of human-object interaction detection[J]. Journal of Southwest Jiaotong University, 2022, 57(4): 693-704. | |
| [2] | 李佳宁,王东凯,张史梁. 基于深度学习的二维人体姿态估计:现状及展望[J]. 计算机学报, 2024, 47(1): 231-250. |
| LI J N, WANG D K, ZHANG S L. Deep-learning-based 2D human pose estimation: present and future[J]. Chinese Journal of Computers, 2024, 47(1): 231-250. | |
| [3] | 白雪冰,车进,吴金蔓,等. 基于Transformer视觉特征融合的图像描述方法[J]. 计算机工程, 2024, 50(8): 229-238. |
| BAI X B, CHE J, WU J M, et al. Image captioning method based on Transformer visual features fusion[J]. Computer Engineering, 2024, 50(8): 229-238. | |
| [4] | GAO C, ZOU Y, HUANG J B. iCAN: Instance-centric attention network for human-object interaction detection[C]// Proceedings of the 2018 British Machine Vision Conference. Durham: BMVA Press, 2018: No.17. |
| [5] | 宁欣,田伟娟,于丽娜,等. 面向小目标和遮挡目标检测的脑启发CIRA-DETR全推理方法[J]. 计算机学报, 2022, 45(10): 2080-2092. |
| NING X, TIAN W J, YU L N, et al. Brain-inspired CIRA-DETR full inference model for small and occluded object detection[J]. Chinese Journal of Computers, 2022, 45(10): 2080-2092. | |
| [6] | TAMURA M, OHASHI H, YOSHINAGA T. QPIC: query-based pairwise human-object interaction detection with image-wide contextual information[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 10405-10414. |
| [7] | KIM B, LEE J, KANG J, et al. HOTR: end-to-end human-object interaction detection with Transformers[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 74-83. |
| [8] | ZHANG A, LIAO Y, LIU S, et al. Mining the benefits of two-stage and one-stage HOI detection[C]// Proceedings of the 35th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2021: 17209-17220. |
| [9] | LIAO Y, ZHANG A, LU M, et al. GEN-VLKT: simplify association and enhance interaction understanding for HOI detection[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 20091-20100. |
| [10] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010. |
| [11] | CHAO Y W, WANG Z, HE Y, et al. HICO: a benchmark for recognizing human-object interactions in images[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 1017-1025. |
| [12] | GUPTA S, MALIK J. Visual semantic role labeling[EB/OL]. [2024-05-17].. |
| [13] | WU K, PENG H, CHEN M, et al. Rethinking and improving relative position encoding for vision Transformer[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 10013-10021. |
| [14] | 李大海,王忠华,王振东. 结合空间域和频域信息的双分支低光照图像增强网络[J]. 计算机应用, 2024, 44(7): 2175-2182. |
| LI D H, WANG Z H, WANG Z D. Dual-branch low-light image enhancement network combining spatial and frequency domain information[J]. Journal of Computer Applications, 2024, 44(7): 2175-2182. | |
| [15] | MISRA D, NALAMADA T, ARASANIPALAI A U, et al. Rotate to attend: convolutional triplet attention module[C]// Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2021: 3138-3147. |
| [16] | JIANG M, ZENG P, WANG K, et al. FECAM: frequency enhanced channel attention mechanism for time series forecasting[J]. Advanced Engineering Informatics, 2023, 58: No.102158. |
| [17] | GAO C, XU J, ZOU Y, et al. DRG: dual relation graph for human-object interaction detection[C]// Proceedings of the 2020 European Conference on Computer Vision. Cham: Springer, 2020: 696-712. |
| [18] | ZOU C, WANG B, HU Y, et al. End-to-end human object interaction detection with HOI Transformer[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 11820-11829. |
| [19] | ZHANG F Z, CAMPBELL D, GOULD S. Spatially conditioned graphs for detecting human-object interactions[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 13299-13307. |
| [20] | KIM B, MUN J, ON K W, et al. MSTR: multi-scale Transformer for end-to-end human-object interaction detection[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 19556-19565. |
| [21] | ZHANG F Z, CAMPBELL D, GOULD S. Efficient two-stage detection of human-object interactions with a novel unary-pairwise Transformer[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 20072-20080. |
| [22] | WANG Y, TENG Y, WANG L. CycleHOI: improving human-object interaction detection with cycle consistency of detection and generation[EB/OL]. [2024-07-16].. |
| [23] | ZHENG S, XU B, JIN Q. Open-category human-object interaction pre-training via language modeling framework[C]// Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2023: 19392-19402. |
| [24] | PENG H, LIU F, LI Y, et al. Parallel reasoning network for human-object interaction detection[EB/OL]. [2024-01-09].. |
| [25] | CHAN S, ZENG X, WANG X, et al. Auxiliary feature fusion and noise suppression for HOI detection[J]. ACM Transactions on Multimedia Computing, Communications and Applications, 2024, 20(10): No.299. |
| [1] | Mingguang LI, Chongben TAO. Hierarchical cross-modal fusion method for 3D object detection based on Mamba model [J]. Journal of Computer Applications, 2026, 46(2): 572-579. |
| [2] | Binhong XIE, Rui WANG, Rui ZHANG, Yingjun ZHANG. Agent prototype distillation algorithm for few-shot object detection [J]. Journal of Computer Applications, 2026, 46(1): 233-241. |
| [3] | Shiwei LI, Yufeng ZHOU, Pengfei SUN, Weisong LIU, Zhuxuan MENG, Haojie LIAN. Point cloud data augmentation method based on scattering and absorption effects of coal dust on LiDAR electromagnetic waves [J]. Journal of Computer Applications, 2026, 46(1): 331-340. |
| [4] | Shuwen HUANG, Keyu GUO, Xiangyu SONG, Feng HAN, Shijie SUN, Huansheng SONG. Multi-target 3D visual grounding method based on monocular images [J]. Journal of Computer Applications, 2026, 46(1): 207-215. |
| [5] | Yu SANG, Tong GONG, Chen ZHAO, Bowen YU, Siman LI. Domain-adaptive nighttime object detection method with photometric alignment [J]. Journal of Computer Applications, 2026, 46(1): 242-251. |
| [6] | Lili WEI, Lirong YAN, Xiaofen TANG. Contextual semantic representation and pixel relationship correction for few-shot object detection [J]. Journal of Computer Applications, 2025, 45(9): 2993-3002. |
| [7] | Jiaxiang ZHANG, Xiaoming LI, Jiahui ZHANG. Few-shot object detection algorithm based on new category feature enhancement and metric mechanism [J]. Journal of Computer Applications, 2025, 45(9): 2984-2992. |
| [8] | Binhong XIE, Yingkun LA, Yingjun ZHANG, Rui ZHANG. Semi-supervised object detection framework guided by self-paced learning [J]. Journal of Computer Applications, 2025, 45(8): 2546-2554. |
| [9] | Chengzhi YAN, Ying CHEN, Kai ZHONG, Han GAO. 3D object detection algorithm based on multi-scale network and axial attention [J]. Journal of Computer Applications, 2025, 45(8): 2537-2545. |
| [10] | Liang CHEN, Xuan WANG, Kun LEI. Helmet wearing detection algorithm for complex scenarios based on cross-layer multi-scale feature fusion [J]. Journal of Computer Applications, 2025, 45(7): 2333-2341. |
| [11] | Zimo ZHANG, Xuezhuan ZHAO. Multi-scale sparse graph guided vision graph neural networks [J]. Journal of Computer Applications, 2025, 45(7): 2188-2194. |
| [12] | Pingping YU, Yuting YAN, Xinliang TANG, He SU, Jianchao WANG. Multi-object tracking algorithm for construction machinery in transmission line scenarios [J]. Journal of Computer Applications, 2025, 45(7): 2351-2360. |
| [13] | Yingjun ZHANG, Weiwei YAN, Binhong XIE, Rui ZHANG, Wangdong LU. Gradient-discriminative and feature norm-driven open-world object detection [J]. Journal of Computer Applications, 2025, 45(7): 2203-2210. |
| [14] | Peiyu JIANG, Yongguang WANG, Yating REN, Shuochen LI, Huobin TAN. Object detection uncertainty measurement scheme based on guide to the expression of uncertainty in measurement [J]. Journal of Computer Applications, 2025, 45(7): 2162-2168. |
| [15] | Qingqing ZHAO, Bin HU. Moving pedestrian detection neural network with invariant global sparse contour point representation [J]. Journal of Computer Applications, 2025, 45(4): 1271-1284. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||