


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (6): 1836-1843.DOI: 10.11772/j.issn.1001-9081.2025050647
• Data science and technology • Previous Articles
Jinghong WANG1,2,3,4,5, Xiao CHEN1, Yingmei MA2,5( ), Bi LI6, Jusheng MI7, Wei WANG1
), Bi LI6, Jusheng MI7, Wei WANG1
Received:2025-06-12
Revised:2025-08-16
Accepted:2025-09-01
Online:2025-09-15
Published:2026-06-10
Contact:
Yingmei MA
About author:WANG Jinghong, born in 1967, Ph. D., professor. Her research interests include artificial intelligence, data mining.Supported by:
王静红1,2,3,4,5, 陈潇1, 马迎梅2,5(), 李笔6, 米据生7, 王威1
通讯作者:
马迎梅
作者简介:王静红(1967—),女,河北石家庄人,教授,博士,CCF会员,主要研究方向:人工智能、数据挖掘基金资助:CLC Number:
Jinghong WANG, Xiao CHEN, Yingmei MA, Bi LI, Jusheng MI, Wei WANG. Multi-level neighborhood contrastive attribute graph clustering based on adaptive learning[J]. Journal of Computer Applications, 2026, 46(6): 1836-1843.
王静红, 陈潇, 马迎梅, 李笔, 米据生, 王威. 基于自适应学习的多层次邻域对比属性图聚类[J]. 《计算机应用》唯一官方网站, 2026, 46(6): 1836-1843.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025050647
| 符号 | 含义 | 符号 | 含义 |
|---|---|---|---|
| 属性图 | 编码表示矩阵 | ||
| 节点集 | 投影表示矩阵 | ||
| 边集 | 目标分布更新间隔 | ||
| 节点特征矩阵 | 温度参数 | ||
| 度矩阵 | 编码级损失超参数 | ||
| n | 节点数 | pro | 投影级损失超参数 |
| 集群数 | 生成分布函数 | ||
| 邻接矩阵 | 目标分布函数 | ||
| 增广邻接矩阵 | 聚类中心 | ||
| 嵌入矩阵 | 预测标签 | ||
| 边嵌入向量 | 对比学习优化超参数 | ||
| 边权重矩阵 | 自监督聚类优化超参数 |
Tab. 1 Symbol definition
| 符号 | 含义 | 符号 | 含义 |
|---|---|---|---|
| 属性图 | 编码表示矩阵 | ||
| 节点集 | 投影表示矩阵 | ||
| 边集 | 目标分布更新间隔 | ||
| 节点特征矩阵 | 温度参数 | ||
| 度矩阵 | 编码级损失超参数 | ||
| n | 节点数 | pro | 投影级损失超参数 |
| 集群数 | 生成分布函数 | ||
| 邻接矩阵 | 目标分布函数 | ||
| 增广邻接矩阵 | 聚类中心 | ||
| 嵌入矩阵 | 预测标签 | ||
| 边嵌入向量 | 对比学习优化超参数 | ||
| 边权重矩阵 | 自监督聚类优化超参数 |
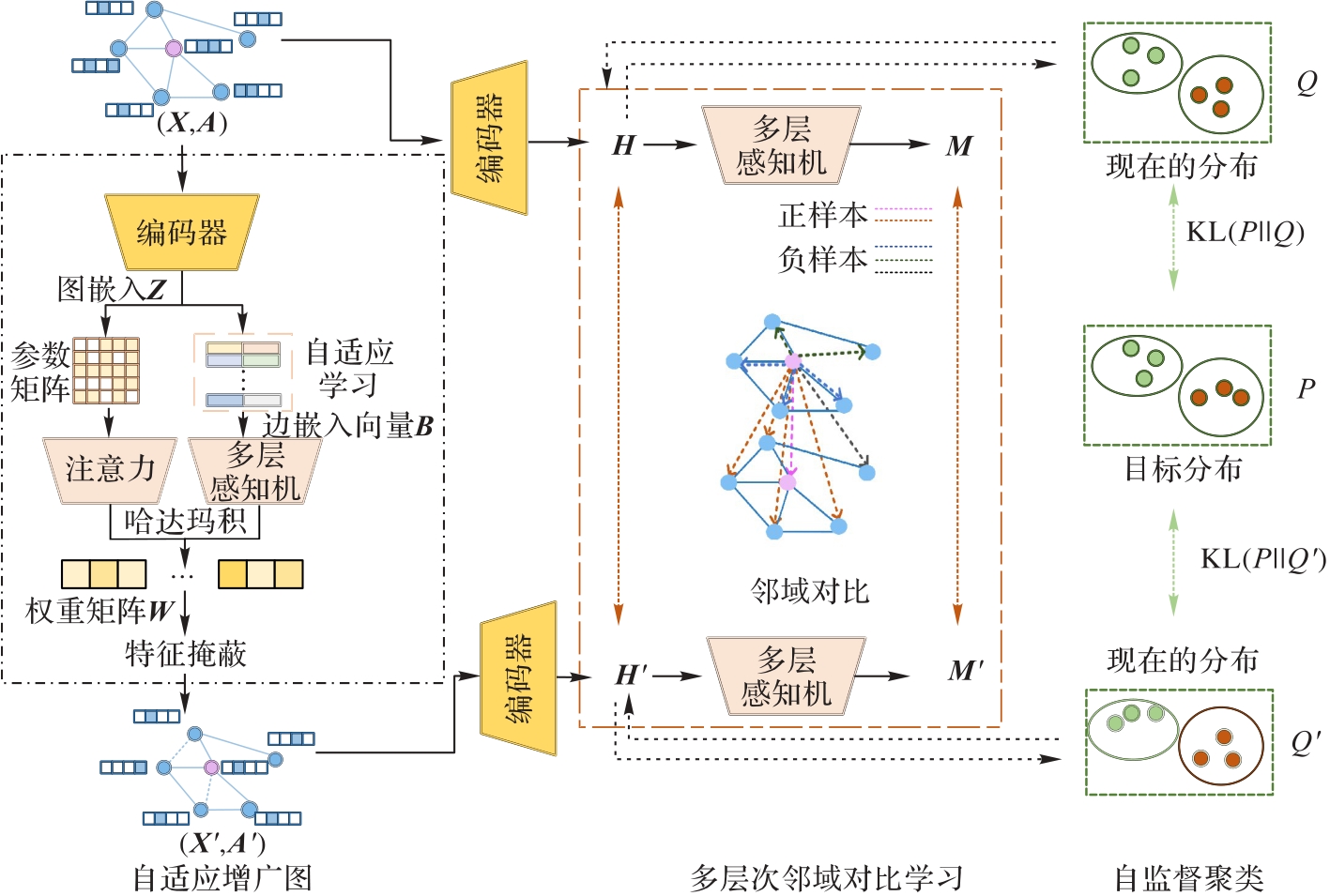
Fig. 1 Framework of MNCGC method
| 数据集 | 节点数 | 边数 | 特征维度 | 标签数 |
|---|---|---|---|---|
| Cora | 2 708 | 5 429 | 1 433 | 7 |
| CiteSeer | 3 327 | 4 732 | 3 703 | 6 |
| PubMed | 19 717 | 44 338 | 500 | 3 |
Tab. 2 Dataset information
| 数据集 | 节点数 | 边数 | 特征维度 | 标签数 |
|---|---|---|---|---|
| Cora | 2 708 | 5 429 | 1 433 | 7 |
| CiteSeer | 3 327 | 4 732 | 3 703 | 6 |
| PubMed | 19 717 | 44 338 | 500 | 3 |
| 超参数 | 含义 | 值 |
|---|---|---|
| 预训练次数 | 120 | |
| 学习率 | 0.000 1 | |
| 正式训练次数 | 50 | |
| 编码级损失超参数 | 1 | |
| 投影级损失超参数 | 0.1 | |
| 对比学习优化超参数 | 1 | |
| 自监督聚类优化超参数 | 1 |
Tab. 3 Hyperparameter setting
| 超参数 | 含义 | 值 |
|---|---|---|
| 预训练次数 | 120 | |
| 学习率 | 0.000 1 | |
| 正式训练次数 | 50 | |
| 编码级损失超参数 | 1 | |
| 投影级损失超参数 | 0.1 | |
| 对比学习优化超参数 | 1 | |
| 自监督聚类优化超参数 | 1 |
| 方法 | Cora | CiteSeer | PubMed | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | F1 | NMI | ARI | ACC | F1 | NMI | ARI | ACC | F1 | NMI | ARI | |
| GRACE | 60.22 | 58.01 | 47.11 | 35.91 | 62.13 | 62.04 | 37.90 | 37.15 | Out of memory | |||
| SDCN | 6.67 | 27.41 | 18.73 | 8.29 | 64.29 | 59.32 | 36.49 | 38.17 | 62.32 | 61.53 | 23.04 | 21.64 |
| AGCN | 38.74 | 28.59 | 18.55 | 9.62 | 67.54 | 62.46 | 39.12 | 41.85 | 62.44 | 60.52 | 23.94 | 21.67 |
| GCA | 56.33 | 51.13 | 46.36 | 30.16 | 64.47 | 60.03 | 39.57 | 39.45 | 66.67 | 66.18 | 33.11 | 28.33 |
| GC-VGE | 70.68 | 69.48 | 53.57 | 48.15 | 66.61 | 63.39 | 40.91 | 41.52 | 66.88 | 29.71 | 29.76 | |
| DNENC-con | 68.30 | 65.90 | 51.20 | 47.70 | 69.20 | 63.90 | 42.60 | 44.90 | 67.70 | 27.50 | 27.80 | |
| DNENC-att | 70.40 | 68.20 | 52.80 | 49.60 | 67.20 | 63.60 | 39.70 | 41.00 | 67.10 | 65.90 | 26.60 | 27.80 |
| AGGDC | 74.60 | — | 52.20 | 69.60 | — | 45.80 | 61.90 | — | 29.50 | |||
| ASP | 65.81 | 60.58 | 55.99 | 46.78 | 68.66 | 64.20 | 43.78 | 44.83 | Out of memory | |||
| CCGC | 74.36 | 56.32 | 52.13 | 69.35 | 62.21 | 43.47 | 44.12 | 62.47 | 61.38 | 27.72 | 25.67 | |
| CGC | 66.22 | 56.90 | 69.31 | 64.74 | 43.61 | 42.14 | 67.43 | 67.14 | 33.07 | |||
| CoCGC | 72.51 | 68.71 | 56.15 | 49.49 | 70.15 | 62.88 | 44.58 | 45.29 | — | — | — | — |
| AMGC | 66.65 | 61.02 | 47.99 | 43.40 | 60.92 | 57.33 | 32.93 | 33.73 | 64.56 | 64.52 | 24.58 | 24.19 |
| MPCCL | 72.03 | 69.73 | 53.86 | 52.29 | 70.56 | 45.10 | 46.90 | — | — | — | — | |
| MNCGC | 75.52 | 73.42 | 59.57 | 58.06 | 66.75 | 45.43 | 71.08 | 70.84 | 35.57 | 34.48 | ||
Tab. 4 Comparison of clustering performance of methods on three experimental datasets
| 方法 | Cora | CiteSeer | PubMed | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | F1 | NMI | ARI | ACC | F1 | NMI | ARI | ACC | F1 | NMI | ARI | |
| GRACE | 60.22 | 58.01 | 47.11 | 35.91 | 62.13 | 62.04 | 37.90 | 37.15 | Out of memory | |||
| SDCN | 6.67 | 27.41 | 18.73 | 8.29 | 64.29 | 59.32 | 36.49 | 38.17 | 62.32 | 61.53 | 23.04 | 21.64 |
| AGCN | 38.74 | 28.59 | 18.55 | 9.62 | 67.54 | 62.46 | 39.12 | 41.85 | 62.44 | 60.52 | 23.94 | 21.67 |
| GCA | 56.33 | 51.13 | 46.36 | 30.16 | 64.47 | 60.03 | 39.57 | 39.45 | 66.67 | 66.18 | 33.11 | 28.33 |
| GC-VGE | 70.68 | 69.48 | 53.57 | 48.15 | 66.61 | 63.39 | 40.91 | 41.52 | 66.88 | 29.71 | 29.76 | |
| DNENC-con | 68.30 | 65.90 | 51.20 | 47.70 | 69.20 | 63.90 | 42.60 | 44.90 | 67.70 | 27.50 | 27.80 | |
| DNENC-att | 70.40 | 68.20 | 52.80 | 49.60 | 67.20 | 63.60 | 39.70 | 41.00 | 67.10 | 65.90 | 26.60 | 27.80 |
| AGGDC | 74.60 | — | 52.20 | 69.60 | — | 45.80 | 61.90 | — | 29.50 | |||
| ASP | 65.81 | 60.58 | 55.99 | 46.78 | 68.66 | 64.20 | 43.78 | 44.83 | Out of memory | |||
| CCGC | 74.36 | 56.32 | 52.13 | 69.35 | 62.21 | 43.47 | 44.12 | 62.47 | 61.38 | 27.72 | 25.67 | |
| CGC | 66.22 | 56.90 | 69.31 | 64.74 | 43.61 | 42.14 | 67.43 | 67.14 | 33.07 | |||
| CoCGC | 72.51 | 68.71 | 56.15 | 49.49 | 70.15 | 62.88 | 44.58 | 45.29 | — | — | — | — |
| AMGC | 66.65 | 61.02 | 47.99 | 43.40 | 60.92 | 57.33 | 32.93 | 33.73 | 64.56 | 64.52 | 24.58 | 24.19 |
| MPCCL | 72.03 | 69.73 | 53.86 | 52.29 | 70.56 | 45.10 | 46.90 | — | — | — | — | |
| MNCGC | 75.52 | 73.42 | 59.57 | 58.06 | 66.75 | 45.43 | 71.08 | 70.84 | 35.57 | 34.48 | ||
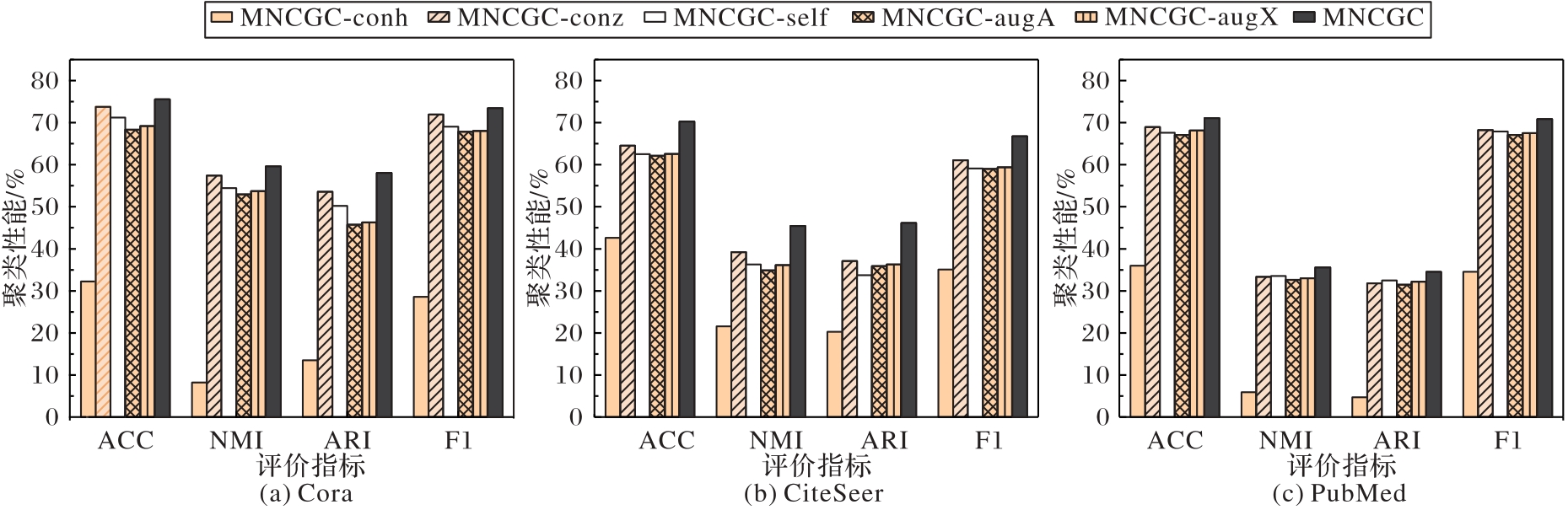
Fig. 2 Experimental results comparison of variant study
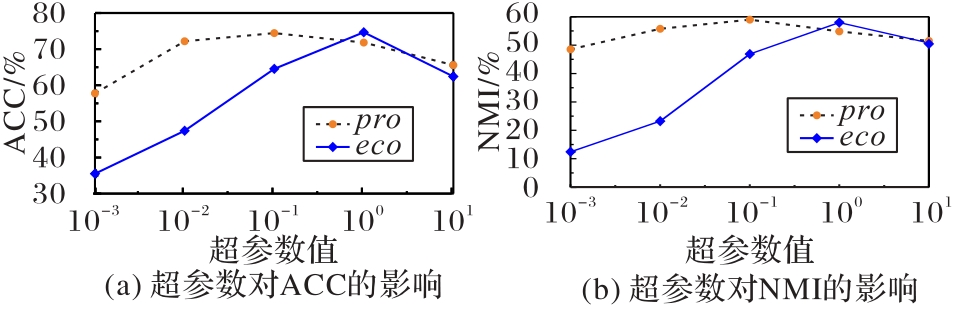
Fig. 3 Impact of hyperparameters of multi-level comparison module
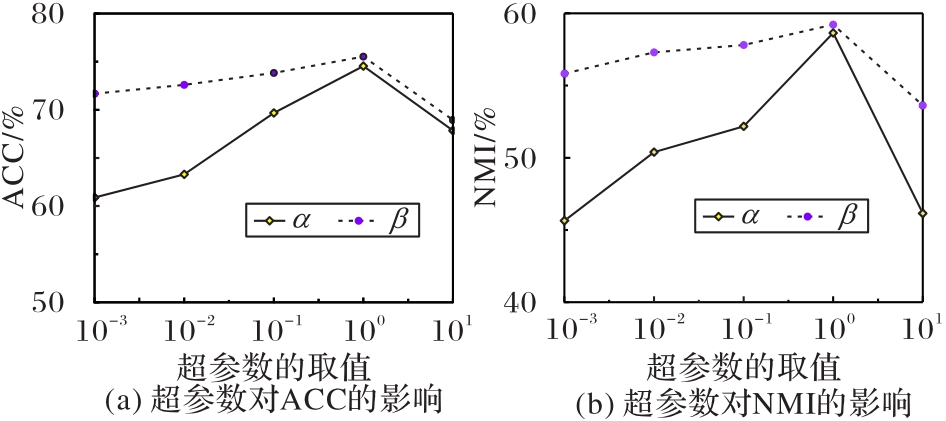
Fig. 4 Impact of hyperparameters of two modules
| lr | Cora | CiteSeer | PubMed | ||||||
|---|---|---|---|---|---|---|---|---|---|
| τ=0.5 | τ=1.0 | τ=1.5 | τ=0.5 | τ=1.0 | τ=1.5 | τ=0.5 | τ=1.0 | τ=1.5 | |
| 0.000 1 | 72.51 | 72.71 | 72.35 | 67.48 | 68.82 | 68.67 | 67.65 | 69.11 | 68.04 |
| 0.000 3 | 74.68 | 75.52 | 73.79 | 68.51 | 70.24 | 67.32 | 68.47 | 70.14 | 68.71 |
| 0.000 5 | 73.06 | 73.39 | 73.01 | 66.53 | 69.33 | 66.58 | 68.29 | 71.08 | 69.24 |
Tab. 5 Experimental results comparison of parameter sensitivity (ACC)
| lr | Cora | CiteSeer | PubMed | ||||||
|---|---|---|---|---|---|---|---|---|---|
| τ=0.5 | τ=1.0 | τ=1.5 | τ=0.5 | τ=1.0 | τ=1.5 | τ=0.5 | τ=1.0 | τ=1.5 | |
| 0.000 1 | 72.51 | 72.71 | 72.35 | 67.48 | 68.82 | 68.67 | 67.65 | 69.11 | 68.04 |
| 0.000 3 | 74.68 | 75.52 | 73.79 | 68.51 | 70.24 | 67.32 | 68.47 | 70.14 | 68.71 |
| 0.000 5 | 73.06 | 73.39 | 73.01 | 66.53 | 69.33 | 66.58 | 68.29 | 71.08 | 69.24 |
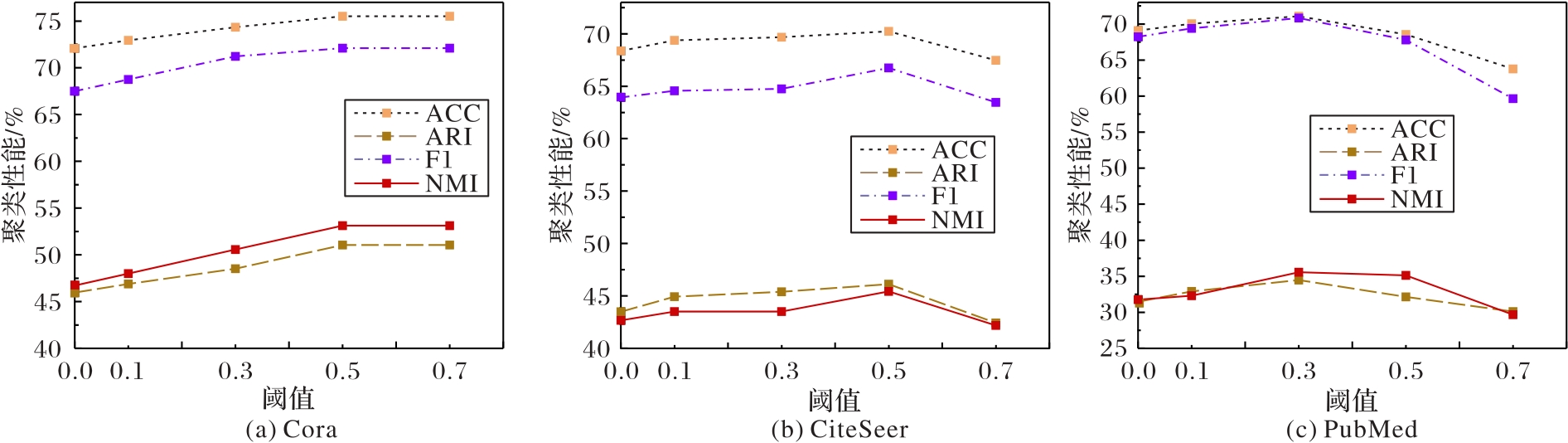
Fig. 5 Impact of edge weight
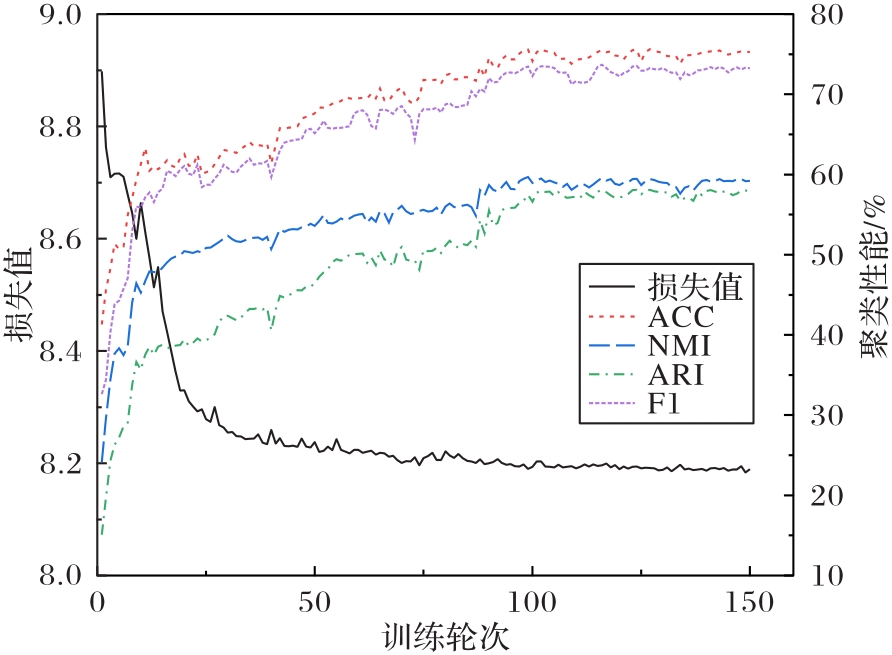
Fig. 6 Convergence analysis on Cora dataset
| [1] | LIU X, ZHANG F, HOU Z, et al. Self-supervised learning: generative or contrastive[J]. IEEE Transactions on Knowledge and Data Engineering, 2023, 35(1): 857-876. |
| [2] | WU L, LIN H, TAN C, et al. Self-supervised learning on graphs: contrastive, generative, or predictive[J]. IEEE Transactions on Knowledge and Data Engineering, 2023, 35(4): 4216-4235. |
| [3] | LIU J, CAO F, JING X, et al. Deep multi-view graph clustering network with weighting mechanism and collaborative training[J]. Expert Systems with Applications, 2024, 236: No.121298. |
| [4] | PAN S, HU R, LONG G, et al. Adversarially regularized graph autoencoder for graph embedding[C]// Proceedings of the 27th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2018: 2609-2615. |
| [5] | PARK J, LEE M, CHANG H J, et al. Symmetric graph convolutional autoencoder for unsupervised graph representation learning[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 6518-6527. |
| [6] | WANG W, SUO X, WEI X, et al. HGATE: heterogeneous graph attention auto-encoders[J]. IEEE Transactions on Knowledge and Data Engineering, 2023, 35(4): 3938-3951. |
| [7] | CHEN M, WANG B, LI X. Deep contrastive graph learning with clustering-oriented guidance[C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 11364-11372. |
| [8] | LIU Y, YANG X, ZHOU S, et al. Simple contrastive graph clustering [J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(10): 13789-13800. |
| [9] | ZHONG H, WU J, CHEN C, et al. Graph contrastive clustering[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 9204-9213. |
| [10] | 安俊秀,柳源,杨林旺. 基于对比学习的深度聚类研究综述[J]. 微电子学与计算机, 2025, 42(7): 1-10. |
| AN J X, LIU Y, YANG L W. A review of deep clustering research based on comparative learning[J]. Microelectronics & Computer, 2025, 42(7): 1-10. | |
| [11] | SHEN X, SUN D, PAN S, et al. Neighbor contrastive learning on learnable graph augmentation[C]// Proceedings of the 37th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023: 9782-9791. |
| [12] | ZHENG Y, JIA C, YU J. Attributed graph clustering under the contrastive mechanism with cluster-preserving augmentation[J]. Information Sciences, 2024, 681: No.121225. |
| [13] | YOU Y, CHEN T, SUI Y, et al. Graph contrastive learning with augmentations[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 5812-5823. |
| [14] | ZHU Y, XU Y, YU F, et al. Deep graph contrastive representation learning [EB/OL]. [2025-08-15].. |
| [15] | ZHU Y, XU Y, YU F, et al. Graph contrastive learning with adaptive augmentation [C]// Proceedings of the Web Conference 2021. New York: ACM, 2021: 2069-2080. |
| [16] | YANG X, LIU Y, ZHOU S, et al. Cluster-guided contrastive graph clustering network[C]// Proceedings of the 37th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023: 10834-10842. |
| [17] | HUANG Y D, ZHANG G Y, HUANG D, et al. Confidence-oriented contrastive graph clustering[C]// Proceedings of the 2024 International Joint Conference on Neural Networks. Piscataway: IEEE, 2024: 1-8. |
| [18] | ZHANG C Y, YAO H Y, CHEN C L P, et al. Graph representation learning via contrasting cluster assignments[J]. IEEE Transactions on Cognitive and Developmental Systems, 2024, 16(3): 912-922. |
| [19] | JIN M, ZHENG Y, LI Y F, et al. Multi-scale contrastive Siamese networks for self-supervised graph representation learning[C]// Proceedings of the 30th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2021: 1477-1483. |
| [20] | WANG T, YANG G, HE Q, et al. NCAGC: a neighborhood contrast framework for attributed graph clustering [EB/OL]. [2025-08-15].. |
| [21] | XIE X, CHEN W, KANG Z, et al. Contrastive graph clustering with adaptive filter[J]. Expert Systems with Applications, 2023, 219: No.119645. |
| [22] | CHEN J, KOU G. Attribute and structure preserving graph contrastive learning[C]// Proceedings of the 37th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023: 7024-7032. |
| [23] | LI B, WANG Y, ZHAO B, et al. Attributed graph clustering with multi-scale weight-based pairwise coarsening and contrastive learning [J]. Neurocomputing, 2025, 648: No.130796. |
| [24] | BO D, WANG X, SHI C, et al. Structural deep clustering network[C]// Proceedings of the Web Conference 2020. New York: ACM, 2020: 1400-1410. |
| [25] | PENG Z, LIU H, JIA Y, et al. Attention-driven graph clustering network[C]// Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 935-943. |
| [26] | WANG C, PAN S, YU C P, et al. Deep neighbor-aware embedding for node clustering in attributed graphs[J]. Pattern Recognition, 2022, 122: No.108230. |
| [27] | GUO L, DAI Q. Graph clustering via variational graph embedding[J]. Pattern Recognition, 2022, 122: No.108334. |
| [28] | GUO Y, KANG L, WU M, et al. Joint node representation learning and clustering for attributed graph via graph diffusion convolution[C]// Proceedings of the 2023 International Joint Conference on Neural Networks. Piscataway: IEEE, 2023: 1-7. |
| [29] | TU W, GUAN R, ZHOU S, et al. Attribute-missing graph clustering network[C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 15392-15401. |
| [30] | VELIČKOVIĆ P, FEDUS W, HAMITON W L, et al. Deep graph infomax[EB/OL]. [2025-08-15].. |
| [1] | Bingqing LI, Binhao HUANG, Yubei TANG, Baili ZHANG. Quality of service prediction model for data sparsity and cold start problems [J]. Journal of Computer Applications, 2026, 46(6): 1829-1835. |
| [2] | Hang QI, Tingting DONG, Yongqiang NAI, Xian MO. Contrastive collaborative filtering method based on graph diffusion generation and adaptive sampling [J]. Journal of Computer Applications, 2026, 46(6): 1818-1828. |
| [3] | Kun FU, Haoyu WEI, Weijing LIU, Xing DANG, Zezheng LIU, Jianwei LI. Graph neural network framework for topology semantic dual-domain collaboration [J]. Journal of Computer Applications, 2026, 46(5): 1378-1387. |
| [4] | Dirui ZHANG, Jiayu LIN, Zuhong LIANG. Supervised contrastive generative sentiment analysis method with uncertainty-aware unlikelihood learning [J]. Journal of Computer Applications, 2026, 46(5): 1416-1423. |
| [5] | Haihua ZHAO, Yijun HU, Rui TANG, Xian MO. Multimodal recommendation method based on semantic fusion and contrast enhancement [J]. Journal of Computer Applications, 2026, 46(4): 1058-1068. |
| [6] | Xiaoxia LIU, Liqun KUANG, Song WANG, Shichao JIAO, Huiyan HAN, Fengguang XIONG. Multi-scale spatio-temporal decoupling for contrastive learning of skeleton action recognition [J]. Journal of Computer Applications, 2026, 46(3): 767-774. |
| [7] | Yuhang XIAO, Guanfeng LI, Yuyin CHEN, Jing QIN. Few-shot relation extraction model with graph-based multi-view contrastive learning [J]. Journal of Computer Applications, 2026, 46(3): 732-740. |
| [8] | Hu LUO, Mingshu ZHANG. Rumor detection method based on cross-modal attention mechanism and contrastive learning [J]. Journal of Computer Applications, 2026, 46(2): 361-367. |
| [9] | Limei DONG, Yanzi LI, Jiayin LI, Li XU. Neighborhood-enhanced unsupervised graph anomaly detection [J]. Journal of Computer Applications, 2026, 46(2): 458-466. |
| [10] | Ziyang CHENG, Ruizhang HUANG, Jingjing XUE. Deep evolutionary topic clustering model [J]. Journal of Computer Applications, 2026, 46(1): 85-94. |
| [11] | Wen LI, Kairong LI, Kai YANG. Subgraph-aware contrastive learning with data augmentation [J]. Journal of Computer Applications, 2026, 46(1): 1-9. |
| [12] | Xingyao YANG, Zheng QI, Jiong YU, Zulian ZHANG, Shuai MA, Hongtao SHEN. Session-based recommendation model based on time-aware and space-enhanced dual channel graph neural network [J]. Journal of Computer Applications, 2026, 46(1): 104-112. |
| [13] | Chao LIU, Yanhua YU. Knowledge-aware recommendation model combining denoising strategy and multi-view contrastive learning [J]. Journal of Computer Applications, 2025, 45(9): 2827-2837. |
| [14] | Zhixiong XU, Bo LI, Xiaoyong BIAN, Qiren HU. Adversarial sample embedded attention U-Net for 3D medical image segmentation [J]. Journal of Computer Applications, 2025, 45(9): 3011-3016. |
| [15] | Zhiyuan WANG, Tao PENG, Jie YANG. Integrating internal and external data for out-of-distribution detection training and testing [J]. Journal of Computer Applications, 2025, 45(8): 2497-2506. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||