


Journal of Computer Applications ›› 2026, Vol. 46 ›› Issue (4): 1058-1068.DOI: 10.11772/j.issn.1001-9081.2025050528
• Artificial intelligence • Previous Articles Next Articles
Haihua ZHAO1, Yijun HU1, Rui TANG2, Xian MO1( )
)
Received:2025-05-15
Revised:2025-07-18
Accepted:2025-08-06
Online:2025-08-12
Published:2026-04-10
Contact:
Xian MO
About author:ZHAO Haihua, born in 1999, M. S. candidate. His research interests include graph learning, recommender systems.Supported by:
赵海华1, 胡怡君1, 唐瑞2, 莫先1()
通讯作者:
莫先
作者简介:赵海华(1999—),男,宁夏中卫人,硕士研究生,CCF会员,主要研究方向:图学习、推荐系统基金资助:CLC Number:
Haihua ZHAO, Yijun HU, Rui TANG, Xian MO. Multimodal recommendation method based on semantic fusion and contrast enhancement[J]. Journal of Computer Applications, 2026, 46(4): 1058-1068.
赵海华, 胡怡君, 唐瑞, 莫先. 基于语义融合和对比增强的多模态推荐方法[J]. 《计算机应用》唯一官方网站, 2026, 46(4): 1058-1068.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2025050528
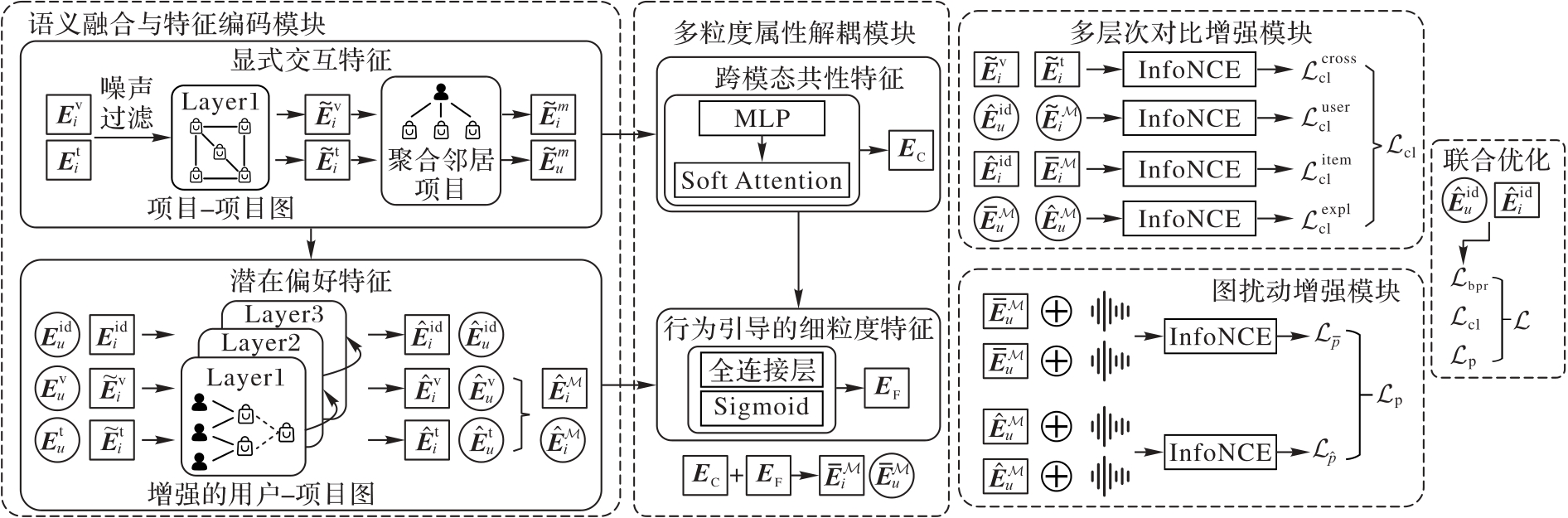
Fig. 1 Framework of SFCERec
| 数据集 | 用户数 | 项目数 | 交互数 | 稀疏度/% | 模态 |
|---|---|---|---|---|---|
| Baby | 19 445 | 7 050 | 160 792 | 99.88 | v、t |
| Sports | 35 598 | 18 357 | 296 337 | 99.95 | v、t |
| Clothing | 39 387 | 23 033 | 278 677 | 99.97 | v、t |
Tab. 1 Statistics of datasets
| 数据集 | 用户数 | 项目数 | 交互数 | 稀疏度/% | 模态 |
|---|---|---|---|---|---|
| Baby | 19 445 | 7 050 | 160 792 | 99.88 | v、t |
| Sports | 35 598 | 18 357 | 296 337 | 99.95 | v、t |
| Clothing | 39 387 | 23 033 | 278 677 | 99.97 | v、t |
| 名称 | 参数 |
|---|---|
| 处理器 | Intel_Core i9-13900HX |
| 操作系统 | Windows11 64位 |
| 内存 | 16 GB |
| 显卡 | 5张NVIDIA GeForce RTX 4090显卡 |
| 深度学习框架 | PyTorch 1.12.0 |
Tab. 2 Configuration of experiments
| 名称 | 参数 |
|---|---|
| 处理器 | Intel_Core i9-13900HX |
| 操作系统 | Windows11 64位 |
| 内存 | 16 GB |
| 显卡 | 5张NVIDIA GeForce RTX 4090显卡 |
| 深度学习框架 | PyTorch 1.12.0 |
| 模型 | Baby | Sports | Clothing | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R@10 | R@20 | N@10 | N@20 | R@10 | R@20 | N@10 | N@20 | R@10 | R@20 | N@10 | N@20 | |
| MF-BPR | 0.035 7 | 0.057 5 | 0.019 2 | 0.024 9 | 0.043 2 | 0.065 3 | 0.024 1 | 0.029 8 | 0.018 7 | 0.027 9 | 0.010 3 | 0.012 6 |
| LightGCN | 0.047 9 | 0.075 4 | 0.025 7 | 0.032 8 | 0.056 9 | 0.086 4 | 0.031 3 | 0.038 7 | 0.034 0 | 0.052 6 | 0.018 8 | 0.023 6 |
| SGL | 0.053 2 | 0.082 0 | 0.028 9 | 0.036 3 | 0.062 0 | 0.094 5 | 0.033 9 | 0.042 3 | 0.039 2 | 0.058 6 | 0.021 6 | 0.026 6 |
| NCL | 0.053 8 | 0.083 6 | 0.029 2 | 0.036 9 | 0.061 6 | 0.094 0 | 0.033 9 | 0.042 1 | 0.041 0 | 0.060 7 | 0.022 8 | 0.027 5 |
| VBPR | 0.042 3 | 0.066 3 | 0.022 3 | 0.028 4 | 0.055 8 | 0.085 6 | 0.030 7 | 0.038 4 | 0.042 3 | 0.066 3 | 0.022 3 | 0.028 4 |
| SLMRec | 0.052 9 | 0.077 5 | 0.029 0 | 0.035 3 | 0.066 3 | 0.099 0 | 0.036 5 | 0.045 0 | 0.045 2 | 0.067 5 | 0.024 7 | 0.030 3 |
| BM3 | 0.056 4 | 0.088 3 | 0.030 1 | 0.038 3 | 0.065 6 | 0.098 0 | 0.035 5 | 0.043 8 | 0.042 2 | 0.062 1 | 0.023 1 | 0.028 1 |
| FREEDOM | 0.062 7 | 0.099 2 | 0.033 0 | 0.042 4 | 0.071 7 | 0.108 9 | 0.038 5 | 0.048 1 | 0.062 9 | 0.094 1 | 0.034 1 | 0.042 0 |
| MGCN | 0.062 0 | 0.096 4 | 0.033 9 | 0.042 7 | 0.072 9 | 0.110 6 | 0.039 7 | 0.049 6 | 0.064 1 | 0.094 5 | 0.034 7 | 0.042 8 |
| LGMRec | 0.064 9 | 0.097 9 | 0.035 1 | 0.043 6 | 0.071 9 | 0.108 5 | 0.039 5 | 0.049 0 | 0.055 3 | 0.082 3 | 0.030 1 | 0.037 1 |
| DGVAE | 0.063 6 | 0.100 9 | 0.034 0 | 0.043 6 | 0.075 3 | 0.112 7 | 0.050 6 | 0.061 9 | 0.091 7 | 0.033 6 | 0.041 2 | |
| MENTOR | 0.064 7 | 0.034 9 | 0.044 7 | 0.075 6 | 0.112 9 | 0.040 6 | 0.050 3 | 0.065 6 | 0.096 9 | 0.036 0 | 0.043 9 | |
| SMORE | 0.102 1 | 0.040 7 | ||||||||||
| SFCERec | 0.067 5 | 0.105 2 | 0.036 5 | 0.046 1 | 0.079 3 | 0.118 1 | 0.042 9 | 0.052 9 | 0.069 1 | 0.102 1 | 0.037 8 | 0.046 2 |
Tab. 3 Performance comparison of different methods on three datasets
| 模型 | Baby | Sports | Clothing | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R@10 | R@20 | N@10 | N@20 | R@10 | R@20 | N@10 | N@20 | R@10 | R@20 | N@10 | N@20 | |
| MF-BPR | 0.035 7 | 0.057 5 | 0.019 2 | 0.024 9 | 0.043 2 | 0.065 3 | 0.024 1 | 0.029 8 | 0.018 7 | 0.027 9 | 0.010 3 | 0.012 6 |
| LightGCN | 0.047 9 | 0.075 4 | 0.025 7 | 0.032 8 | 0.056 9 | 0.086 4 | 0.031 3 | 0.038 7 | 0.034 0 | 0.052 6 | 0.018 8 | 0.023 6 |
| SGL | 0.053 2 | 0.082 0 | 0.028 9 | 0.036 3 | 0.062 0 | 0.094 5 | 0.033 9 | 0.042 3 | 0.039 2 | 0.058 6 | 0.021 6 | 0.026 6 |
| NCL | 0.053 8 | 0.083 6 | 0.029 2 | 0.036 9 | 0.061 6 | 0.094 0 | 0.033 9 | 0.042 1 | 0.041 0 | 0.060 7 | 0.022 8 | 0.027 5 |
| VBPR | 0.042 3 | 0.066 3 | 0.022 3 | 0.028 4 | 0.055 8 | 0.085 6 | 0.030 7 | 0.038 4 | 0.042 3 | 0.066 3 | 0.022 3 | 0.028 4 |
| SLMRec | 0.052 9 | 0.077 5 | 0.029 0 | 0.035 3 | 0.066 3 | 0.099 0 | 0.036 5 | 0.045 0 | 0.045 2 | 0.067 5 | 0.024 7 | 0.030 3 |
| BM3 | 0.056 4 | 0.088 3 | 0.030 1 | 0.038 3 | 0.065 6 | 0.098 0 | 0.035 5 | 0.043 8 | 0.042 2 | 0.062 1 | 0.023 1 | 0.028 1 |
| FREEDOM | 0.062 7 | 0.099 2 | 0.033 0 | 0.042 4 | 0.071 7 | 0.108 9 | 0.038 5 | 0.048 1 | 0.062 9 | 0.094 1 | 0.034 1 | 0.042 0 |
| MGCN | 0.062 0 | 0.096 4 | 0.033 9 | 0.042 7 | 0.072 9 | 0.110 6 | 0.039 7 | 0.049 6 | 0.064 1 | 0.094 5 | 0.034 7 | 0.042 8 |
| LGMRec | 0.064 9 | 0.097 9 | 0.035 1 | 0.043 6 | 0.071 9 | 0.108 5 | 0.039 5 | 0.049 0 | 0.055 3 | 0.082 3 | 0.030 1 | 0.037 1 |
| DGVAE | 0.063 6 | 0.100 9 | 0.034 0 | 0.043 6 | 0.075 3 | 0.112 7 | 0.050 6 | 0.061 9 | 0.091 7 | 0.033 6 | 0.041 2 | |
| MENTOR | 0.064 7 | 0.034 9 | 0.044 7 | 0.075 6 | 0.112 9 | 0.040 6 | 0.050 3 | 0.065 6 | 0.096 9 | 0.036 0 | 0.043 9 | |
| SMORE | 0.102 1 | 0.040 7 | ||||||||||
| SFCERec | 0.067 5 | 0.105 2 | 0.036 5 | 0.046 1 | 0.079 3 | 0.118 1 | 0.042 9 | 0.052 9 | 0.069 1 | 0.102 1 | 0.037 8 | 0.046 2 |
| 算法 | Baby | Sports | Clothing | |||
|---|---|---|---|---|---|---|
| R@20 | N@20 | R@20 | N@20 | R@20 | N@20 | |
| w/o GE | 0.104 4 | 0.045 5 | 0.116 7 | 0.052 6 | 0.099 8 | 0.045 5 |
| w/o PD | 0.094 3 | 0.040 9 | 0.105 8 | 0.046 5 | 0.082 3 | 0.036 9 |
| w/o CL | 0.095 1 | 0.040 7 | 0.108 0 | 0.047 7 | 0.093 1 | 0.041 6 |
| w/o PE | 0.104 5 | 0.045 2 | 0.114 8 | 0.052 3 | 0.098 4 | 0.044 4 |
| SFCERec | 0.105 2 | 0.046 1 | 0.118 1 | 0.052 9 | 0.102 1 | 0.046 2 |
Tab. 4 Results of ablation experiments
| 算法 | Baby | Sports | Clothing | |||
|---|---|---|---|---|---|---|
| R@20 | N@20 | R@20 | N@20 | R@20 | N@20 | |
| w/o GE | 0.104 4 | 0.045 5 | 0.116 7 | 0.052 6 | 0.099 8 | 0.045 5 |
| w/o PD | 0.094 3 | 0.040 9 | 0.105 8 | 0.046 5 | 0.082 3 | 0.036 9 |
| w/o CL | 0.095 1 | 0.040 7 | 0.108 0 | 0.047 7 | 0.093 1 | 0.041 6 |
| w/o PE | 0.104 5 | 0.045 2 | 0.114 8 | 0.052 3 | 0.098 4 | 0.044 4 |
| SFCERec | 0.105 2 | 0.046 1 | 0.118 1 | 0.052 9 | 0.102 1 | 0.046 2 |

Fig. 2 Hyperparameter experimental results in contrast enhancement
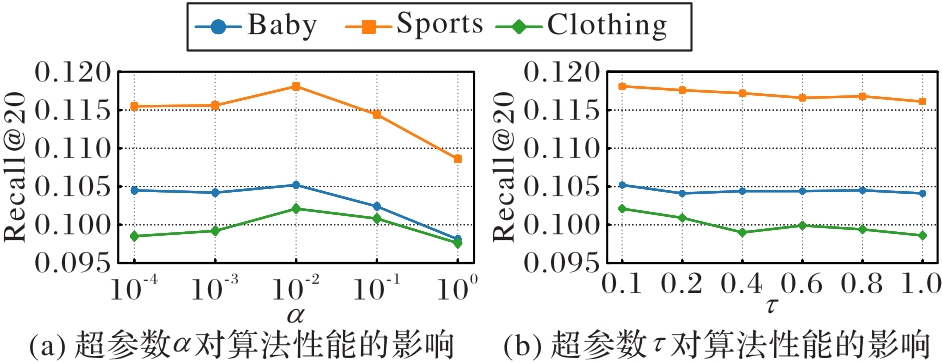
Fig. 3 Hyperparameter experimental results in perturbation enhancement
| 模型 | 平均epoch时间 | |
|---|---|---|
| Baby | Sports | |
| MENTOR | 8.95 | 24.30 |
| SMORE | 6.51 | 15.42 |
| SFCERec | 6.42 | 15.23 |
Tab. 5 Average epoch training time
| 模型 | 平均epoch时间 | |
|---|---|---|
| Baby | Sports | |
| MENTOR | 8.95 | 24.30 |
| SMORE | 6.51 | 15.42 |
| SFCERec | 6.42 | 15.23 |
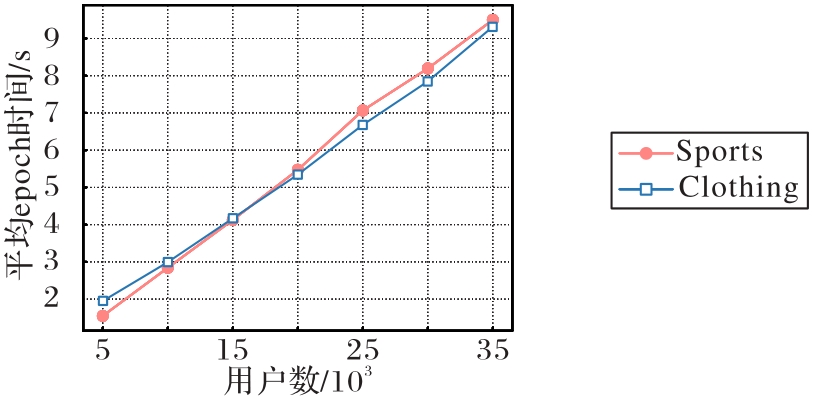
Fig. 4 Experimental results of scalability analysis
| 数据集 | 模型 | 交互数<5 | 交互数<10 | 交互数<20 | |||
|---|---|---|---|---|---|---|---|
| R@20 | N@20 | R@20 | N@20 | R@20 | N@20 | ||
| Sports | LGMRec | 0.077 0 | 0.033 5 | 0.100 0 | 0.043 3 | 0.106 6 | 0.047 1 |
| MENTOR | 0.078 6 | 0.034 8 | 0.108 0 | 0.047 6 | 0.112 4 | 0.050 2 | |
| SFCERec | 0.083 2 | 0.036 8 | 0.112 3 | 0.049 8 | 0.116 8 | 0.052 1 | |
| Clothing | LGMRec | 0.064 9 | 0.029 1 | 0.081 0 | 0.036 1 | 0.082 0 | 0.036 7 |
| MENTOR | 0.075 3 | 0.033 6 | 0.093 7 | 0.042 3 | 0.096 8 | 0.043 6 | |
| SFCERec | 0.076 5 | 0.035 3 | 0.099 2 | 0.044 3 | 0.101 1 | 0.045 5 | |
Tab. 6 Experimental results of sparsity analysis
| 数据集 | 模型 | 交互数<5 | 交互数<10 | 交互数<20 | |||
|---|---|---|---|---|---|---|---|
| R@20 | N@20 | R@20 | N@20 | R@20 | N@20 | ||
| Sports | LGMRec | 0.077 0 | 0.033 5 | 0.100 0 | 0.043 3 | 0.106 6 | 0.047 1 |
| MENTOR | 0.078 6 | 0.034 8 | 0.108 0 | 0.047 6 | 0.112 4 | 0.050 2 | |
| SFCERec | 0.083 2 | 0.036 8 | 0.112 3 | 0.049 8 | 0.116 8 | 0.052 1 | |
| Clothing | LGMRec | 0.064 9 | 0.029 1 | 0.081 0 | 0.036 1 | 0.082 0 | 0.036 7 |
| MENTOR | 0.075 3 | 0.033 6 | 0.093 7 | 0.042 3 | 0.096 8 | 0.043 6 | |
| SFCERec | 0.076 5 | 0.035 3 | 0.099 2 | 0.044 3 | 0.101 1 | 0.045 5 | |
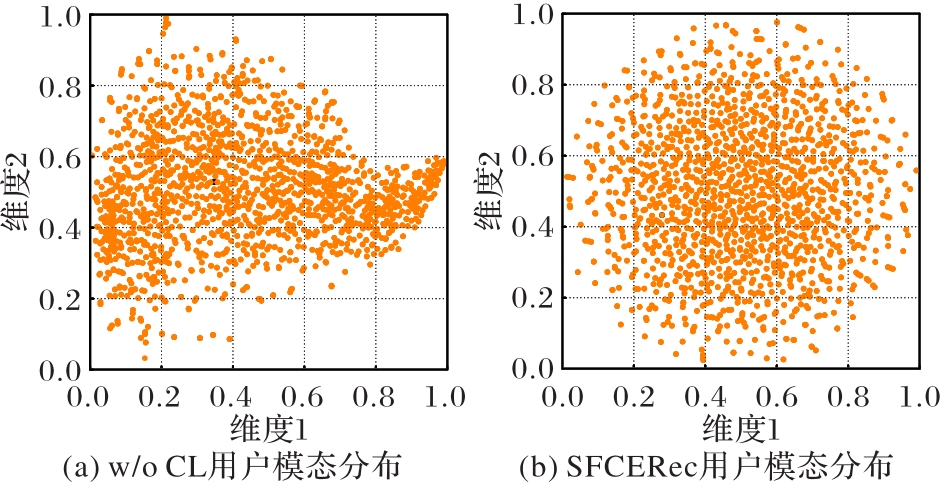
Fig. 5 User modal distribution maps
| [1] | RENDLE S, FREUDENTHALER C, GANTNER Z, et al. BPR: Bayesian personalized ranking from implicit feedback[C]// Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence. Arlington, VA: AUAI Press, 2009: 452-461. |
| [2] | KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks[EB/OL]. [2025-04-20].. |
| [3] | WANG X, HE X, WANG M, et al. Neural graph collaborative filtering[C]// Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2019: 165-174. |
| [4] | LI S. Harnessing multimodal data and Mult-Recall strategies for enhanced product recommendation in e-commerce[C]// Proceedings of the 4th International Conference on Computer Systems. Piscataway: IEEE, 2024: 181-185. |
| [5] | ZHANG J, ZHU Y, LIU Q, et al. Latent structure mining with contrastive modality fusion for multimedia recommendation[J]. IEEE Transactions on Knowledge and Data Engineering, 2023, 35(9): 9154-9167. |
| [6] | MALITESTA D, CORNACCHIA G, POMO C, et al. Formalizing multimedia recommendation through multimodal deep learning[J]. ACM Transactions on Recommender Systems, 2025, 3(3): No.37. |
| [7] | HE R, McAULEY J. VBPR: visual Bayesian personalized ranking from implicit feedback[C]// Proceedings of the 30th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2016: 144-150. |
| [8] | WEI Y, WANG X, NIE L, et al. MMGCN: multi-modal graph convolution network for personalized recommendation of micro-video[C]// Proceedings of the 27th ACM International Conference on Multimedia. New York: ACM, 2019: 1437-1445. |
| [9] | WANG Q, WEI Y, YIN J, et al. DualGNN: dual graph neural network for multimedia recommendation[J]. IEEE Transactions on Multimedia, 2023, 25: 1074-1084. |
| [10] | ZHANG J, ZHU Y, LIU Q, et al. Mining latent structures for multimedia recommendation[C]// Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 3872-3880. |
| [11] | TAO Z, LIU X, XIA Y, et al. Self-supervised learning for multimedia recommendation[J]. IEEE Transactions on Multimedia, 2023, 25: 5107-5116. |
| [12] | YI Z, WANG X, OUNIS I, et al. Multi-modal graph contrastive learning for micro-video recommendation[C]// Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2022: 1807-1811. |
| [13] | WEI W, HUANG C, XIA L, et al. Multi-modal self-supervised learning for recommendation[C]// Proceedings of the ACM Web Conference 2023. New York: ACM, 2023: 790-800. |
| [14] | CHEN J, ZHANG H, HE X, et al. Attentive collaborative filtering: multimedia recommendation with item- and component-level attention[C]// Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2017: 335-344. |
| [15] | KANG W C, FANG C, WANG Z, et al. Visually-aware fashion recommendation and design with generative image models[C]// Proceedings of the 2017 IEEE International Conference on Data Mining. Piscataway: IEEE, 2017: 207-216. |
| [16] | ZHOU X, SHEN Z. A tale of two graphs: freezing and denoising graph structures for multimodal recommendation[C]// Proceedings of the 31st ACM International Conference on Multimedia. New York: ACM, 2023: 935-943. |
| [17] | WU J, WANG X, FENG F, et al. Self-supervised graph learning for recommendation[C]// Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2021: 726-735. |
| [18] | LIN Z, TIAN C, HOU Y, et al. Improving graph collaborative filtering with neighborhood-enriched contrastive learning[C]// Proceedings of the ACM Web Conference 2022. New York: ACM, 2022: 2320-2329. |
| [19] | ZHOU X, ZHOU H, LIU Y, et al. Bootstrap latent representations for multi-modal recommendation[C]// Proceedings of the ACM Web Conference 2023. New York: ACM, 2023: 845-854. |
| [20] | LIU F, CHENG Z, ZHU L, et al. Interest-aware message-passing GCN for recommendation[C]// Proceedings of the Web Conference 2021. New York: ACM, 2021: 1296-1305. |
| [21] | YU P, TAN Z, LU G, et al. Multi-view graph convolutional network for multimedia recommendation[C]// Proceedings of the 31st ACM International Conference on Multimedia. New York: ACM, 2023: 6576-6585. |
| [22] | XIAO M, QIAO Z, FU Y, et al. Hierarchical interdisciplinary topic detection model for research proposal classification[J]. IEEE Transactions on Knowledge and Data Engineering, 2023, 35(9): 9685-9699. |
| [23] | YE X, XIAO M, NING Z, et al. NEEDED: introducing hierarchical transformer to eye diseases diagnosis[C]// Proceedings of the 2023 SIAM International Conference on Data Mining. Philadelphia, PA: SIAM, 2023: 667-675. |
| [24] | YU J, YIN H, XIA X, et al. Are graph augmentations necessary? simple graph contrastive learning for recommendation[C]// Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2022: 1294-1303. |
| [25] | McAULEY J, TARGETT C, SHI Q, et al. Image-based recommendations on styles and substitutes[C]// Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2015: 43-52. |
| [26] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. [2025-03-15].. |
| [27] | REIMERS N, GUREVYCH I. Sentence-BERT: sentence embeddings using Siamese BERT-networks[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg: ACL, 2019: 3982-3992. |
| [28] | GLOROT X, BENGIO Y. Understanding the difficulty of training deep feedforward neural networks[C]// Proceedings of the 13th International Conference on Artificial Intelligence and Statistics. New York: JMLR.org, 2010: 249-256. |
| [29] | KINGMA D P, BA J L. Adam: a method for stochastic optimization[EB/OL]. [2025-04-10].. |
| [30] | HE X, DENG K, WANG X, et al. LightGCN: simplifying and powering graph convolution network for recommendation[C]// Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2020: 639-648. |
| [31] | GUO Z, LI J, LI G, et al. LGMRec: local and global graph learning for multimodal recommendation[C]// Proceedings of the 38th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2024: 8454-8462. |
| [32] | ZHAO X, MIAO C. Disentangled graph variational auto-encoder for multimodal recommendation with interpretability[J]. IEEE Transactions on Multimedia, 2024, 26: 7543-7554. |
| [33] | XU J, CHEN Z, YANG S, et al. MENTOR: multi-level self-supervised learning for multimodal recommendation[C]// Proceedings of the 39th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2025: 12908-12917. |
| [34] | ONG R K, KHONG A W H. Spectrum-based modality representation fusion graph convolutional network for multimodal recommendation[C]// Proceedings of the 18th ACM International Conference on Web Search and Data Mining. New York: ACM, 2025: 773-781. |
| [1] | Huanxian LIU, Hongtao WANG, Xian’ao WANG, Hongmei WANG, Weifeng XU. Multimodal fact verification with cross-modal semantic association [J]. Journal of Computer Applications, 2026, 46(4): 1069-1076. |
| [2] | Xiaoxia LIU, Liqun KUANG, Song WANG, Shichao JIAO, Huiyan HAN, Fengguang XIONG. Multi-scale spatio-temporal decoupling for contrastive learning of skeleton action recognition [J]. Journal of Computer Applications, 2026, 46(3): 767-774. |
| [3] | Yuhang XIAO, Guanfeng LI, Yuyin CHEN, Jing QIN. Few-shot relation extraction model with graph-based multi-view contrastive learning [J]. Journal of Computer Applications, 2026, 46(3): 732-740. |
| [4] | Hanqing LIU, Guoming SANG, Yijia ZHANG. Remote sensing image captioning model combining dense multi-scale feature fusion and feature knowledge-enhanced Transformer [J]. Journal of Computer Applications, 2026, 46(3): 741-749. |
| [5] | Hanyue WEI, Chenjuan GUO, Jieyuan MEI, Jindong TIAN, Peng CHEN, Ronghui XU, Bin YANG. MATCH: multimodal stock prediction framework integrating time-frequency features and hybrid text [J]. Journal of Computer Applications, 2026, 46(2): 427-436. |
| [6] | Hu LUO, Mingshu ZHANG. Rumor detection method based on cross-modal attention mechanism and contrastive learning [J]. Journal of Computer Applications, 2026, 46(2): 361-367. |
| [7] | Limei DONG, Yanzi LI, Jiayin LI, Li XU. Neighborhood-enhanced unsupervised graph anomaly detection [J]. Journal of Computer Applications, 2026, 46(2): 458-466. |
| [8] | Wen LI, Kairong LI, Kai YANG. Subgraph-aware contrastive learning with data augmentation [J]. Journal of Computer Applications, 2026, 46(1): 1-9. |
| [9] | Xingyao YANG, Zheng QI, Jiong YU, Zulian ZHANG, Shuai MA, Hongtao SHEN. Session-based recommendation model based on time-aware and space-enhanced dual channel graph neural network [J]. Journal of Computer Applications, 2026, 46(1): 104-112. |
| [10] | Ziyang CHENG, Ruizhang HUANG, Jingjing XUE. Deep evolutionary topic clustering model [J]. Journal of Computer Applications, 2026, 46(1): 85-94. |
| [11] | Zhixiong XU, Bo LI, Xiaoyong BIAN, Qiren HU. Adversarial sample embedded attention U-Net for 3D medical image segmentation [J]. Journal of Computer Applications, 2025, 45(9): 3011-3016. |
| [12] | Chao LIU, Yanhua YU. Knowledge-aware recommendation model combining denoising strategy and multi-view contrastive learning [J]. Journal of Computer Applications, 2025, 45(9): 2827-2837. |
| [13] | Jinyang HUANG, Fengqi CUI, Changxiu MA, Wendong FAN, Meng LI, Jingyu LI, Xiao SUN, Linsheng HUANG, Zhi LIU. Sleep apnea detection based on universal wristband [J]. Journal of Computer Applications, 2025, 45(9): 3045-3056. |
| [14] | Zhiyuan WANG, Tao PENG, Jie YANG. Integrating internal and external data for out-of-distribution detection training and testing [J]. Journal of Computer Applications, 2025, 45(8): 2497-2506. |
| [15] | Wei ZHANG, Jiaxiang NIU, Jichao MA, Qiongxia SHEN. Chinese spelling correction model ReLM enhanced with deep semantic features [J]. Journal of Computer Applications, 2025, 45(8): 2484-2490. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||