


《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (2): 365-374.DOI: 10.11772/j.issn.1001-9081.2021020230
• 人工智能 • 上一篇
李亚鸣1,2, 邢凯1,2( ), 邓洪武1,2, 王志勇1,2, 胡璇1,2
), 邓洪武1,2, 王志勇1,2, 胡璇1,2
收稿日期:2021-02-07
修回日期:2021-03-18
接受日期:2021-03-26
发布日期:2021-04-07
出版日期:2022-02-10
通讯作者:
邢凯
作者简介:李亚鸣(1996—),男,江西赣州人,硕士研究生,主要研究方向:深度学习;
Yaming LI1,2, Kai XING1,2(), Hongwu DENG1,2, Zhiyong WANG1,2, Xuan HU1,2
Received:2021-02-07
Revised:2021-03-18
Accepted:2021-03-26
Online:2021-04-07
Published:2022-02-10
Contact:
Kai XING
About author:LI Yaming, born in 1996, M. S. candidate. His research interests include deep learning.摘要:
针对卷积结构的深度学习模型在小样本学习场景中泛化性能较差的问题,以AlexNet和ResNet为例,提出一种基于小样本无梯度学习的卷积结构预训练模型的性能优化方法。首先基于因果干预对样本数据进行调制,由非时序数据生成序列数据,并基于协整检验从数据分布平稳性的角度对预训练模型进行定向修剪;然后基于资本资产定价模型(CAPM)以及最优传输理论,在预训练模型中间输出过程中进行无需梯度传播的正向学习并构建一种全新的结构,从而生成在分布空间中具有明确类间区分性的表征向量;最后基于自注意力机制对生成的有效特征进行自适应加权处理,并在全连接层对特征进行聚合,从而生成具有弱相关性的embedding向量。实验结果表明所提出的方法能够使AlexNet和ResNet卷积结构预训练模型在ImageNet 2012数据集的100类图片上的Top-1准确率分别从58.82%、78.51%提升到68.50%、85.72%,可见所提方法能够基于小样本训练数据有效提高卷积结构预训练模型的性能。
中图分类号:
李亚鸣, 邢凯, 邓洪武, 王志勇, 胡璇. 基于小样本无梯度学习的卷积结构预训练模型性能优化方法[J]. 计算机应用, 2022, 42(2): 365-374.
Yaming LI, Kai XING, Hongwu DENG, Zhiyong WANG, Xuan HU. Derivative-free few-shot learning based performance optimization method of pre-trained models with convolution structure[J]. Journal of Computer Applications, 2022, 42(2): 365-374.
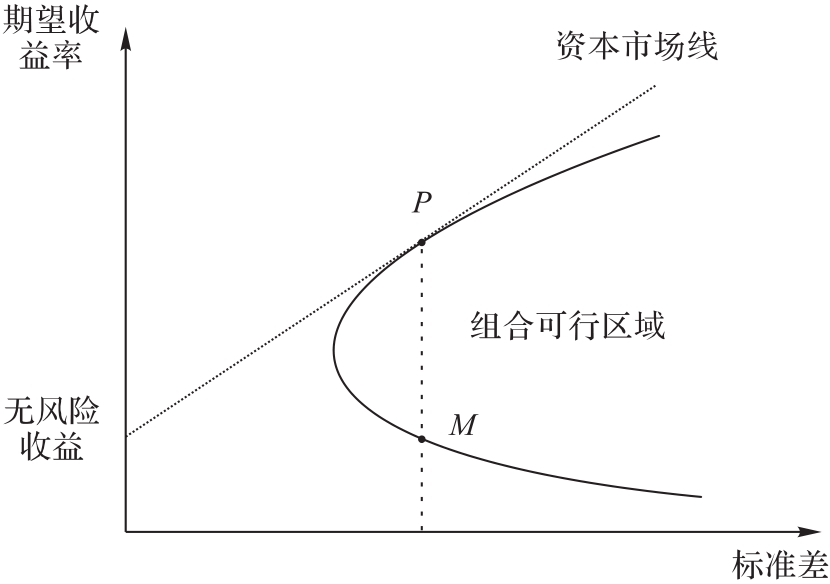
图1 资本资产定价模型
Fig. 1 Capital Asset Pricing Model

图2 样本数据增强
Fig. 2 Sample data augmentation

图3 本文方法的整体框架
Fig. 3 Overall framework of the proposed method

图4 自注意力机制结构
Fig. 4 Structure of self-attention mechanism
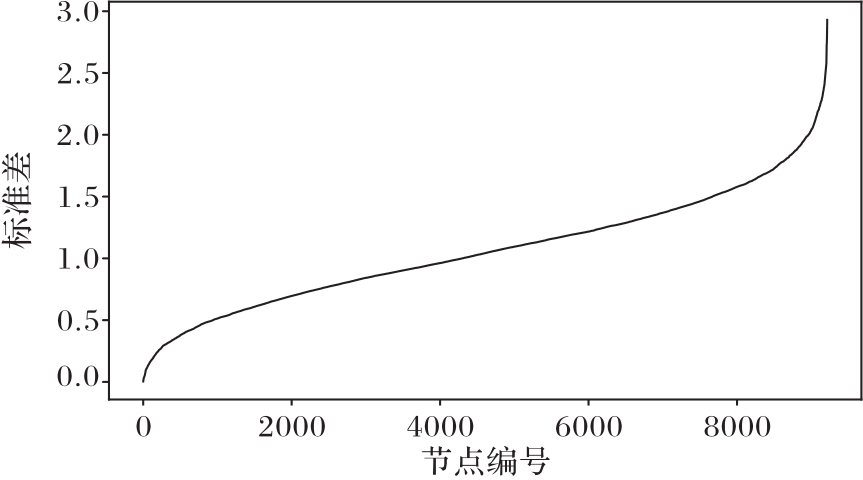
图5 随机类别对应的排序后的标准差分布
Fig. 5 Sorted standard deviation distribution corresponding to random class
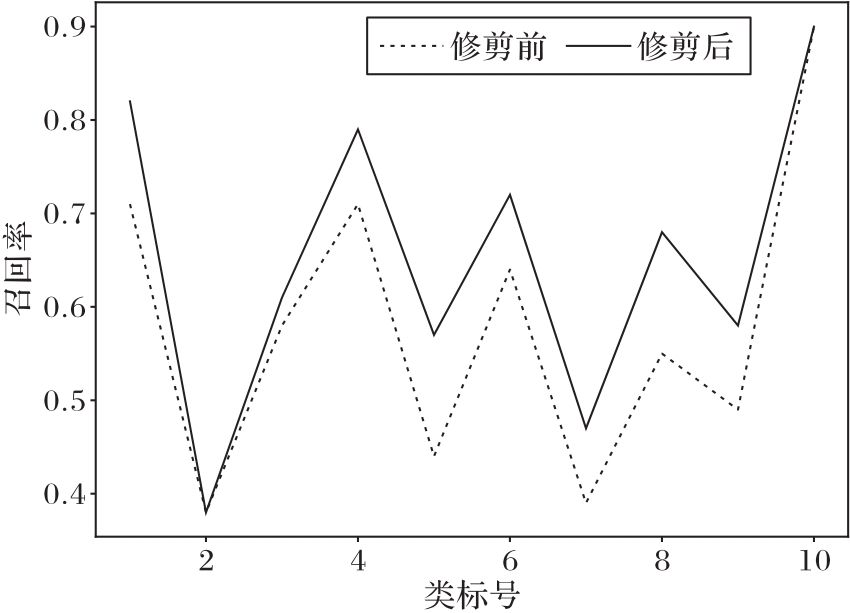
图6 模型经过修剪后,单类别召回率普遍提升
Fig. 6 Most single class recall rates increasing after model pruning
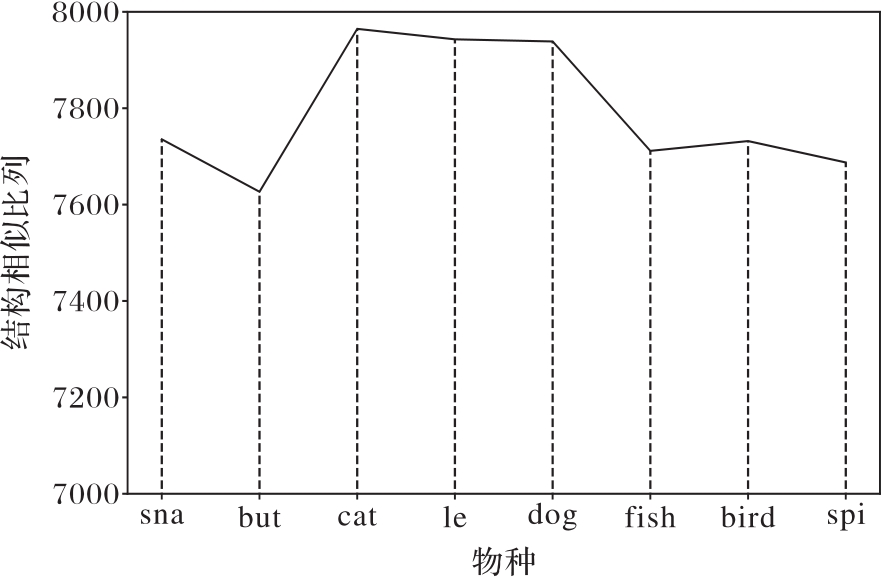
图7 不同物种对应的单分类模型有效结构相似比例
Fig. 7 Similar ratios of effective structures of single classification models for different species
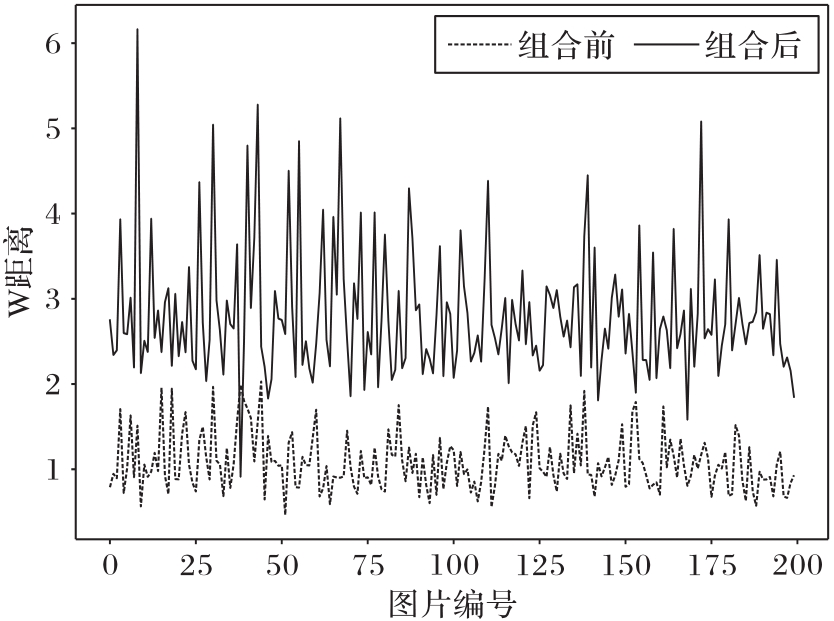
图8 随机选择类别,资本资产定价模型组合优化前后所有采样的收益R分布
Fig. 8 After randomly selecting a class, distribution of income R of all samples before and after combinational optimization of capital asset pricing model

图9 资本资产定价模型组合优化前后单采样点的可区分性
Fig. 9 Distinguishability of single node before and after combinational optimization of capital asset pricing model
| 网络模型 | 数据集 | Top-1 Acc | Top-5 Acc |
|---|---|---|---|
| AlexNet | ImageNet 2012(100类) | 58.82 | 83.51 |
| CIFAR-100 | 61.29 | 81.34 | |
| AlexNet改进模型 | ImageNet 2012(100类) | 68.50 | 92.25 |
| CIFAR-100 | 69.15 | 89.55 | |
| ResNet50 | ImageNet 2012(100类) | 78.51 | 94.20 |
| ResNet50改进模型 | ImageNet 2012(100类) | 85.72 | 96.65 |
表1 图片分类任务性能比较 ( %)
Tab. 1 Performance comparison of image classification tasks
| 网络模型 | 数据集 | Top-1 Acc | Top-5 Acc |
|---|---|---|---|
| AlexNet | ImageNet 2012(100类) | 58.82 | 83.51 |
| CIFAR-100 | 61.29 | 81.34 | |
| AlexNet改进模型 | ImageNet 2012(100类) | 68.50 | 92.25 |
| CIFAR-100 | 69.15 | 89.55 | |
| ResNet50 | ImageNet 2012(100类) | 78.51 | 94.20 |
| ResNet50改进模型 | ImageNet 2012(100类) | 85.72 | 96.65 |
| 1 | XIE S N, GIRSHICK R, DOLLÁR P, et al. Aggregated residual transformations for deep neural networks [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5987-5995. 10.1109/cvpr.2017.634 |
| 2 | HUANG G, LIU Z, MAATEN L VAN DER, et al. Densely connected convolutional networks [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 2261-2269. 10.1109/cvpr.2017.243 |
| 3 | ZHANG M R, LUCAS J, HINTON G, et al. Lookahead optimizer: k steps forward, 1 step back[C/OL]// Proceedings of the 33rd Conference on Neural Information Processing Systems. [2021-01-22]. . |
| 4 | LILLICRAP T P, SANTORO A, MARRIS L, et al. Backpropagation and the brain[J]. Nature Reviews Neuroscience, 2020, 21(6): 335-346. 10.1038/s41583-020-0277-3 |
| 5 | KHAN A, SOHAIL A, ZAHOORA U, et al. A survey of the recent architectures of deep convolutional neural networks[J]. Artificial Intelligence Review, 2020, 53(8): 5455-5516. 10.1007/s10462-020-09825-6 |
| 6 | KINGMA D P, BA J L. Adam: a method for stochastic optimization[J]. [EB/OL]. (2017-01-30) [2021-01-03]. . |
| 7 | DUCHI J, HAZAN E, SINGER Y. Adaptive sub gradient methods for online learning and stochastic optimization[J]. Journal of Machine Learning Research, 2011, 12: 2121-2159. |
| 8 | FERNÁNDEZ-REDONDO M, HERNÁNDEZ-ESPINOSA C. Weight initialization methods for multilayer feedforward [C]// Proceedings of the 2001 European Symposium on Artificial Neural Networks. [2021-01-22]. . 10.1109/ijcnn.2001.939011 |
| 9 | SANTURKAR S, TSIPRAS D, ILYAS A, et al. How does batch normalization help optimization? [C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2018: 2488-2498. |
| 10 | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778. 10.1109/cvpr.2016.90 |
| 11 | BACHLECHNER T, MAJUMDER B P, MAO H H, et al. ReZero is all you need: fast convergence at large depth[EB/OL]. (2020-06-25) [2021-02-05]. . |
| 12 | RAMACHANDRAN P, ZOPH B, LE Q V. Searching for activation functions[EB/OL]. (2017-10-27) [2021-02-05]. . |
| 13 | MISRA D, LANDSKAPE. Mish: a self-regularized non-monotonic neural activation function [C]// Proceedings of the 2020 British Machine Vision Conference. Durham: BMVA Press, 2020: No.928. |
| 14 | GAO Z T, WANG L M, WU G S. LIP: local importance-based pooling [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer. Piscataway: IEEE. 2019: 3354-3363. 10.1109/iccv.2019.00345 |
| 15 | GIRSHICK R. Fast R-CNN [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 1440-1448. 10.1109/iccv.2015.169 |
| 16 | WANG Z N, XIANG C Q, ZOU W B, et al. MMA regularization: decorrelating weights of neural networks by maximizing the minimal angles[C/OL]// Proceedings of the 34th Conference on Neural Information Processing Systems. [2021-01-22]. . 10.1109/lsp.2020.3037512 |
| 17 | JENSEN M C, BLACK F, SCHOLES M S. The capital asset pricing model: some empirical tests[M]// JENSEN M C. Studies in the Theory of Capital Markets. New York: Praeger Publishers Inc., 1972: 25-28. |
| 18 | LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324. 10.1109/5.726791 |
| 19 | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [C]// Proceedings of the 25th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2012: 1097-1105. |
| 20 | SRIVASTAVA N, HINTON G, KRIZHEVSKY A, et al. Dropout: a simple way to prevent neural networks from overfitting[J]. Journal of Machine Learning Research, 2014, 15: 1929-1958. |
| 21 | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. (2015-04-10) [2021-01-20]. . 10.5244/c.28.6 |
| 22 | SANDLER M, HOWARD A, ZHU M L, et al. MobileNetV2: inverted residuals and linear bottlenecks [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 4510-4520. 10.1109/cvpr.2018.00474 |
| 23 | LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 936-944. 10.1109/cvpr.2017.106 |
| 24 | IGNATOV A, GOOL L VAN, TIMOFTE R. Replacing mobile camera ISP with a single deep learning model [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2020: 2275-2285. 10.1109/cvprw50498.2020.00276 |
| 25 | BLUME M E, FRIEND I. A new look at the capital asset pricing model[J]. The Journal of Finance, 1973, 28(1): 19-34. 10.1111/j.1540-6261.1973.tb01342.x |
| 26 | PURKAIT P, ZHAO C, ZACH C. SPP-net: deep absolute pose regression with synthetic views[EB/OL]. (2017-12-09) [2021-02-05]. . |
| 27 | VILLANI C. Optimal Transport: Old and New[M]. Berlin: Springer, 2009: 131-140. 10.1007/978-3-540-71050-9_28 |
| 28 | PEYRÉ G, CUTURI M. Computational optimal transport: with applications to data science[J]. Foundations and Trends in Machine Learning, 2019, 11(5/6): 355-607. 10.1561/2200000073 |
| 29 | DANILA B, YU Y, MARSH J A, et al. Optimal transport on complex networks[J]. Physical Review E, Statistical, Nonlinear, and Soft Matter Physics, 2006, 74(4 Pt 2): No.046106. 10.1103/physreve.74.046106 |
| 30 | ARJOVSKY M, CHINTALA S, BOTTOU L. Wasserstein generative adversarial networks [C]// Proceedings of 34th Machine Learning Research. New York: JMLR.org, 2017: 214-223. |
| 31 | ALBAWI S, MOHAMMED T A, AL-AZAWI S. Understanding of a convolutional neural network [C]// Proceedings of the 2017 International Conference on Engineering and Technology. Piscataway: IEEE, 2017: 1-6. 10.1109/icengtechnol.2017.8308186 |
| 32 | PEARL J, MACKENZIE D. The Book of Why: the New Science of Cause and Effect[M]. New York: Basic Books, 2018: 6-29. |
| 33 | MELLOR J, TURNER J, STORKEY A, et al. Neural architecture search without training[J]. Journal of Machine Learning Research, 2019, 20: 1-21. |
| 34 | WEI W W S. Time Series Analysis: Univariate and Multivariate Methods[M]. 2nd ed. London: Pearson, 2006: 15-80. |
| 35 | KREMERS J J M, ERICSSON N R, DOLADO J J. The power of cointegration tests[J]. Oxford Bulletin of Economics and Statistics, 1992, 54(3): 325-348. 10.1111/j.1468-0084.1992.tb00005.x |
| 36 | HYLLEBERG S, ENGLE R F, GRANGER C W J, et al. Seasonal integration and cointegration[J]. Journal of Econometrics, 1990, 44(1/2): 215-238. 10.1016/0304-4076(90)90080-d |
| 37 | MOLCHANOV P, MALLYA A, TYREE S, et al. Importance estimation for neural network pruning [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 11256-11264. 10.1109/cvpr.2019.01152 |
| 38 | LIU Z, SUN M J, ZHOU T H, et al. Rethinking the value of network pruning[EB/OL]. (2019-03-05) [2021-02-05]. . 10.1002/mrm.27229 |
| 39 | GEIRHOS R, RUBISCH P, MICHAELIS C, et al. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness[EB/OL]. (2019-01-14) [2021-02-05]. . 10.1167/19.10.209c |
| 40 | LI X L, ZHOU Y B, WU T F, et al. Learn to grow: a continual structure learning framework for overcoming catastrophic forgetting [C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 3925-3934. |
| 41 | WORTSMAN M, FARHADI A, RASTEGARI M. Discovering neural wirings[C/OL]// Proceedings of the 33rd Conference on Neural Information Processing Systems. [2021-01-22]. . 10.1109/cvpr42600.2020.01191 |
| 42 | KIM Y, PARK W, ROH M C, et al. GroupFace: learning latent groups and constructing group-based representations for face recognition [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 5620-5629. 10.1109/cvpr42600.2020.00566 |
| 43 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010. 10.1016/s0262-4079(17)32358-8 |
| 44 | RUSSAKOVSKY O, DENG J, SU H, et al. ImageNet large scale visual recognition challenge[J]. International Journal of Computer Vision, 2015, 115(3): 211-252. 10.1007/s11263-015-0816-y |
| 45 | KRIZHEVSKY A. learning multiple layers of features from tiny images[R/OL]. [2021-01-25]. . |
| [1] | 党伟超, 李涛, 白尚旺, 高改梅, 刘春霞. 基于自注意力长短期记忆网络的Web软件系统实时剩余寿命预测方法[J]. 计算机应用, 2021, 41(8): 2346-2351. |
| [2] | 甘岚, 沈鸿飞, 王瑶, 张跃进. 基于改进DCGAN的数据增强方法[J]. 计算机应用, 2021, 41(5): 1305-1313. |
| [3] | 刘睿珩, 叶霞, 岳增营. 面向自然语言处理任务的预训练模型综述[J]. 《计算机应用》唯一官方网站, 2021, 41(5): 1236-1246. |
| [4] | 李慧慧, 闫坤, 张李轩, 刘威, 李执. 基于MobileNetV2的圆形指针式仪表识别系统[J]. 计算机应用, 2021, 41(4): 1214-1220. |
| [5] | 姚博文, 曾碧卿, 蔡剑, 丁美荣. 基于预训练和多层次信息的中文人物关系抽取模型[J]. 《计算机应用》唯一官方网站, 2021, 41(12): 3637-3644. |
| [6] | 罗俊, 陈黎飞. 基于BERT的不完全数据情感分类[J]. 计算机应用, 2021, 41(1): 139-144. |
| [7] | 陈佳伟, 韩芳, 王直杰. 基于自注意力门控图卷积网络的特定目标情感分析[J]. 计算机应用, 2020, 40(8): 2202-2206. |
| [8] | 李生武, 张选德. 基于自注意力机制的多域卷积神经网络的视觉追踪[J]. 计算机应用, 2020, 40(8): 2219-2224. |
| [9] | 许一宁, 何小海, 张津, 卿粼波. 基于多层次分辨率递进生成对抗网络的文本生成图像方法[J]. 计算机应用, 2020, 40(12): 3612-3617. |
| [10] | 张小川, 戴旭尧, 刘璐, 冯天硕. 融合多头自注意力机制的中文短文本分类模型[J]. 计算机应用, 2020, 40(12): 3485-3489. |
| [11] | 王昆, 郑毅, 方书雅, 刘守印. 基于文本筛选和改进BERT的长文本方面级情感分析[J]. 计算机应用, 2020, 40(10): 2838-2844. |
| [12] | 曹小鹿, 辛云宏. 基于Wasserstein距离概率分布模型的非线性降维[J]. 计算机应用, 2017, 37(10): 2819-2822. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||