


《计算机应用》唯一官方网站 ›› 2022, Vol. 42 ›› Issue (1): 115-122.DOI: 10.11772/j.issn.1001-9081.2021071181
范莉莉, 卢桂馥( ), 唐肝翌, 杨丹
), 唐肝翌, 杨丹
收稿日期:2021-07-08
修回日期:2021-09-03
接受日期:2021-09-06
发布日期:2021-09-16
出版日期:2022-01-10
通讯作者:
卢桂馥
作者简介:范莉莉(1982—),女,山东莱芜人,讲师,硕士,CCF会员,主要研究方向:机器学习、模式识别基金资助:
Lili FAN, Guifu LU(), Ganyi TANG, Dan YANG
Received:2021-07-08
Revised:2021-09-03
Accepted:2021-09-06
Online:2021-09-16
Published:2022-01-10
Contact:
Guifu LU
About author:FAN Lili, born in 1982, M. S., lecturer. Her research interests include machine learning, pattern recognition.Supported by:摘要:
针对低秩表示(LRR)子空间聚类算法没有考虑数据局部结构,在学习中可能会造成局部相似信息丢失的问题,提出了一种基于Hessian正则化和非负约束的低秩表示子空间聚类算法(LRR-HN),用来探索数据的全局结构和局部结构。首先,利用Hessian正则化良好的推测能力来保持数据的局部流形结构,使数据局部拓扑结构的表达能力更强;其次,考虑到获得的系数矩阵往往有正有负,而负值往往没有实际意义的特点,引入非负约束来保证模型解的有效性,使其在数据局部结构描述上更有意义;最后,通过最小化核范数寻求数据全局结构的低秩表示,从而更好地聚类高维数据。此外,利用自适应惩罚的线性交替方向法设计了一种求解LRR-HN的有效算法,并在一些真实数据集上,采用正确率(AC)和归一化互信息(NMI)对所提出的算法进行了评估。在ORL数据集上聚类数目为20时的实验中,LRR-HN与LRR算法相比,AC和NMI分别提高了11%和9.74%;与自适应低秩表示(ALRR)算法相比,AC和NMI分别提高了5%和1.05%。实验结果表明,LRR-HN与现有的一些算法相比,AC和NMI均有较大的提升,有较好的聚类性能。
中图分类号:
范莉莉, 卢桂馥, 唐肝翌, 杨丹. 基于Hessian正则化和非负约束的低秩表示子空间聚类算法[J]. 计算机应用, 2022, 42(1): 115-122.
Lili FAN, Guifu LU, Ganyi TANG, Dan YANG. Low-rank representation subspace clustering method based on Hessian regularization and non-negative constraint[J]. Journal of Computer Applications, 2022, 42(1): 115-122.

图1 Yale数据集中的部分图像
Fig. 1 Some images in Yale dataset

图2 ORL数据集中的部分图像
Fig. 2 Some images in ORL dataset
| 聚类数目 | 算法 | AC | NMI |
|---|---|---|---|
| 5 | K-means | 48.73 | 36.17 |
| NMF | 49.82 | 40.60 | |
| PCA | 29.10 | 11.64 | |
| Ncut | 61.45 | 53.36 | |
LRR ALRR | 67.27 67.45 | 56.00 59.03 | |
| LRR-HN | 80.00 | 62.53 | |
| 8 | K-means | 48.86 | 44.69 |
| NMF | 48.64 | 43.25 | |
| PCA | 20.91 | 13.91 | |
| Ncut | 56.14 | 57.77 | |
LRR ALRR | 65.91 62.50 | 58.16 57.61 | |
| LRR-HN | 69.32 | 60.15 | |
| 12 | K-means | 43.18 | 46.19 |
| NMF | 43.18 | 45.04 | |
| PCA | 20.45 | 19.48 | |
| Ncut | 50.91 | 56.39 | |
LRR ALRR | 56.44 59.85 | 55.36 62.10 | |
| LRR-HN | 60. 61 | 59.60 | |
| 15 | K-means | 40.74 | 46.92 |
| NMF | 38.73 | 45.82 | |
| PCA | 23.39 | 24.32 | |
| Ncut | 45.52 | 54.55 | |
LRR ALRR | 52.67 52.12 | 53.69 57.56 | |
| LRR-HN | 55.58 | 56.35 |
表1 不同算法在Yale数据集上的聚类结果 (%)
Tab.1 Clustering results of different algorithms on Yale dataset
| 聚类数目 | 算法 | AC | NMI |
|---|---|---|---|
| 5 | K-means | 48.73 | 36.17 |
| NMF | 49.82 | 40.60 | |
| PCA | 29.10 | 11.64 | |
| Ncut | 61.45 | 53.36 | |
LRR ALRR | 67.27 67.45 | 56.00 59.03 | |
| LRR-HN | 80.00 | 62.53 | |
| 8 | K-means | 48.86 | 44.69 |
| NMF | 48.64 | 43.25 | |
| PCA | 20.91 | 13.91 | |
| Ncut | 56.14 | 57.77 | |
LRR ALRR | 65.91 62.50 | 58.16 57.61 | |
| LRR-HN | 69.32 | 60.15 | |
| 12 | K-means | 43.18 | 46.19 |
| NMF | 43.18 | 45.04 | |
| PCA | 20.45 | 19.48 | |
| Ncut | 50.91 | 56.39 | |
LRR ALRR | 56.44 59.85 | 55.36 62.10 | |
| LRR-HN | 60. 61 | 59.60 | |
| 15 | K-means | 40.74 | 46.92 |
| NMF | 38.73 | 45.82 | |
| PCA | 23.39 | 24.32 | |
| Ncut | 45.52 | 54.55 | |
LRR ALRR | 52.67 52.12 | 53.69 57.56 | |
| LRR-HN | 55.58 | 56.35 |
| 聚类数目 | 算法 | AC | NMI |
|---|---|---|---|
| 10 | K-means | 56.30 | 63.24 |
| NMF | 56.60 | 63.11 | |
| PCA | 24.60 | 22.55 | |
| Ncut | 58.60 | 63.90 | |
LRR ALRR | 63.60 68.00 | 70.06 77.47 | |
| LRR-HN | 68.73 | 78.31 | |
| 20 | K-means | 52.05 | 67.18 |
| NMF | 52.85 | 68.45 | |
| PCA | 27.70 | 38.54 | |
| Ncut | 56.40 | 70.53 | |
LRR ALRR | 63.50 69.50 | 76.23 84.92 | |
| LRR-HN | 74.50 | 85.97 | |
| 30 | K-means | 52.97 | 71.74 |
| NMF | 53.10 | 71.87 | |
| PCA | 40.77 | 59.18 | |
| Ncut | 53.57 | 72.41 | |
LRR ALRR | 65.90 66.67 | 78.77 81.42 | |
| LRR-HN | 67.80 | 82.76 | |
| 40 | K-means | 51.53 | 72.76 |
| NMF | 50.08 | 72.58 | |
| PCA | 44.85 | 65.30 | |
| Ncut | 53.58 | 75.00 | |
LRR ALRR | 66.30 67.75 | 81.07 82.16 | |
| LRR-HN | 68.30 | 81.66 |
表2 不同算法在ORL数据集上的聚类结果 (%)
Tab.2 Clustering results of different algorithms on ORL dataset
| 聚类数目 | 算法 | AC | NMI |
|---|---|---|---|
| 10 | K-means | 56.30 | 63.24 |
| NMF | 56.60 | 63.11 | |
| PCA | 24.60 | 22.55 | |
| Ncut | 58.60 | 63.90 | |
LRR ALRR | 63.60 68.00 | 70.06 77.47 | |
| LRR-HN | 68.73 | 78.31 | |
| 20 | K-means | 52.05 | 67.18 |
| NMF | 52.85 | 68.45 | |
| PCA | 27.70 | 38.54 | |
| Ncut | 56.40 | 70.53 | |
LRR ALRR | 63.50 69.50 | 76.23 84.92 | |
| LRR-HN | 74.50 | 85.97 | |
| 30 | K-means | 52.97 | 71.74 |
| NMF | 53.10 | 71.87 | |
| PCA | 40.77 | 59.18 | |
| Ncut | 53.57 | 72.41 | |
LRR ALRR | 65.90 66.67 | 78.77 81.42 | |
| LRR-HN | 67.80 | 82.76 | |
| 40 | K-means | 51.53 | 72.76 |
| NMF | 50.08 | 72.58 | |
| PCA | 44.85 | 65.30 | |
| Ncut | 53.58 | 75.00 | |
LRR ALRR | 66.30 67.75 | 81.07 82.16 | |
| LRR-HN | 68.30 | 81.66 |

图3 Yale数据集上不同λ1时的AC和NMI变化曲线
Fig. 3 Change curves of AC and NMI with different λ1 on Yale dataset
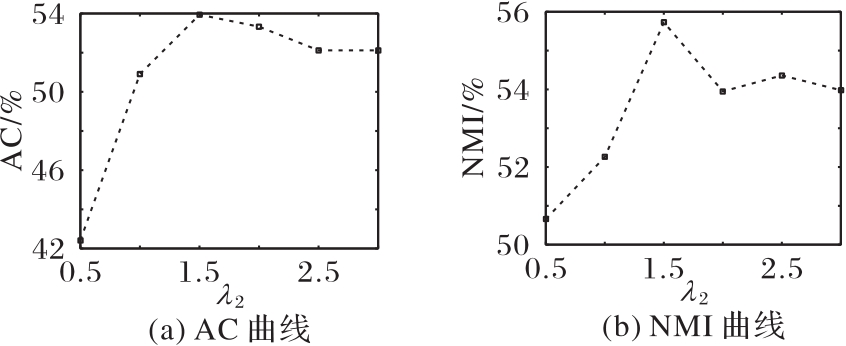
图4 Yale数据集上不同λ2时的AC和NMI变化曲线
Fig. 4 Change curves of AC and NMI with different λ2 on Yale dataset

图5 Yale数据集上不同λ3时的AC和NMI变化曲线
Fig. 5 Change curves of AC and NMI with different λ3 on Yale dataset

图6 ORL数据集上不同λ1时的AC和NMI变化曲线
Fig. 6 Change curves of AC and NMI with different λ1 on ORL dataset
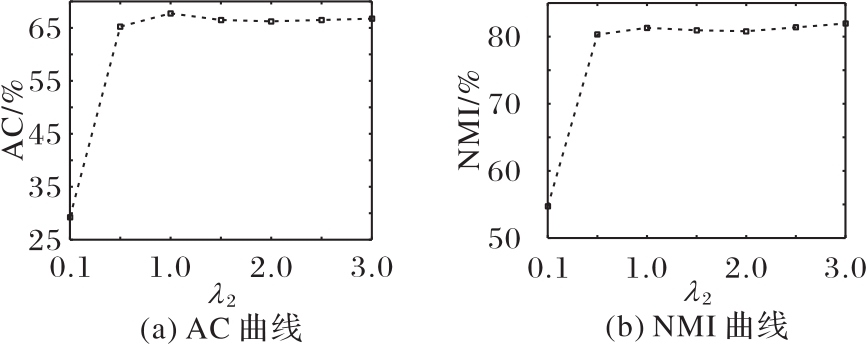
图7 ORL数据集上不同λ2时的AC和NMI变化曲线
Fig. 7 Change curves of AC and NMI with different λ2 on ORL dataset

图8 ORL数据集上不同λ3时的AC和NMI变化曲线
Fig. 8 Change curves of AC and NMI with different λ3 on ORL dataset
| 1 | ZHANG X, SUN F C, LIU G C, et al. Fast low-rank subspace segmentation[J]. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(5): 1293-1297. 10.1109/tkde.2013.114 |
| 2 | PATEL V M, NGUYEN H VAN, VIDAL R. Latent space sparse and low-rank subspace clustering[J]. IEEE Journal of Selected Topics in Signal Processing, 2015, 9(4): 691-701. 10.1109/jstsp.2015.2402643 |
| 3 | BRBIĆ M, KOPRIVA I. Multi-view low-rank sparse subspace clustering[J]. Pattern Recognition, 2018, 73: 247-258. 10.1016/j.patcog.2017.08.024 |
| 4 | CHEN J, MAO H, WANG Z, et al. Low-rank representation with adaptive dictionary learning for subspace clustering[J]. Knowledge-Based Systems, 2021, 223: No.107053. 10.1016/j.knosys.2021.107053 |
| 5 | VIDAL R. Subspace clustering[J]. IEEE Signal Processing, 2011, 28(2): 52-68. 10.1109/msp.2010.939739 |
| 6 | LUXBURG U VON. A tutorial on spectral clustering[J]. Statistics and Computing, 2007, 17(4): 395-416. 10.1007/s11222-007-9033-z |
| 7 | LAUER F, SCHNÖRR C. Spectral clustering of linear subspaces for motion segmentation[C]// Proceedings of the IEEE 12th International Conference on Computer Vision. Piscataway: IEEE, 2009: 678-685. 10.1109/iccv.2009.5459173 |
| 8 | ELHAMIFAR E, VIDAL R. Sparse subspace clustering: algorithm, theory, and applications[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(11): 2765-2781. 10.1109/tpami.2013.57 |
| 9 | LIU G C, LIN Z C, YU Y. Robust subspace segmentation by low-rank representation[C]// Proceedings of the 27th International Conference on Machine Learning. Madison, WI: Omnipress, 2010: 663-670. 10.1109/iccv.2011.6126422 |
| 10 | LIU G C, LIN Z C, YAN S C, et al. Robust recovery of subspace structures by low-rank representation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(1): 171-184. 10.1109/tpami.2012.88 |
| 11 | LU C Y, MIN H, ZHAO Z Q, et al. Robust and efficient subspace segmentation via least squares regression[C]// Proceedings of the 2012 European Conference on Computer Vision, LNCS7578. Berlin: Springer, 2012: 347-360. |
| 12 | JI P, SALZMANN M, LI H D. Efficient dense subspace clustering[C]// Proceedings of the 2014 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2014: 461-468. 10.1109/wacv.2014.6836065 |
| 13 | CHEN J, MAO H, SANG Y S, et al. Subspace clustering using a symmetric low-rank representation[J]. Knowledge-Based Systems, 2017, 127: 46-57. 10.1016/j.knosys.2017.02.031 |
| 14 | ZHU X F, ZHANG S C, LI Y G, et al. Low-rank sparse subspace for spectral clustering[J]. IEEE Transactions on Knowledge and Data Engineering, 2019, 31(8): 1532-1543. 10.1109/tkde.2018.2858782 |
| 15 | LIU J M, CHEN Y J, ZHANG J S, et al. Enhancing low-rank subspace clustering by manifold regularization[J]. IEEE Transactions on Image Processing, 2014, 23(9): 4022-4030. 10.1109/tip.2014.2343458 |
| 16 | YIN M, GAO J B, LIN Z C. Laplacian regularized low-rank representation and its applications[J]. IEEE Transactions Pattern Analysis and Machine Intelligence, 2016, 38(3): 504-517. 10.1109/tpami.2015.2462360 |
| 17 | HE W, CHEN J X, ZHANG W H. Low-rank representation with graph regularization for subspace clustering[J]. Soft Computing, 2017, 21(6): 1569-1581. 10.1007/s00500-015-1869-0 |
| 18 | CHEN Y Y, WANG S Q, ZHENG F Y, et al. Graph-regularized least squares regression for multi-view subspace clustering[J]. Knowledge-Based Systems, 2020, 194: No.105482. 10.1016/j.knosys.2020.105482 |
| 19 | KIM K I, STEINKE F, HEIN M. Semi-supervised regression using Hessian energy with an application to semi-supervised dimensionality reduction[C]// Proceedings of the 22nd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2009: 979-987. |
| 20 | ZHANG J H, WAN Y, CHEN Z P, et al. Non-negative and local sparse coding based on l2-norm and Hessian regularization[J]. Information Sciences, 2019, 486: 88-100. 10.1016/j.ins.2019.02.024 |
| 21 | XIE J Y, GIRSHICK R, FARHADI A. Unsupervised deep embedding for clustering analysis[C]// Proceedings of the 33rd International Conference on Machine Learning. New York: JMLR.org, 2016: 478-487. |
| 22 | JI P, ZHANG T, LI H D, et al. Deep subspace clustering networks[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 23-32. |
| 23 | LAW M T, URTASUN R, ZEMEL R S. Deep spectral clustering learning[C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 1985-1994. 10.1109/cvpr.2017.630 |
| 24 | PENG X, FENG J S, ZHOU J T Y, et al. Deep subspace clustering[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020, 31(12): 5509-5521. 10.1109/tnnls.2020.2968848 |
| 25 | ZHENG M, BU J J, CHEN C. Hessian sparse coding[J]. Neurocomputing, 2014, 123: 247-254. 10.1016/j.neucom.2013.08.001 |
| 26 | 卢桂馥,万鸣华. Hessian正则化的低秩矩阵分解算法[J]. 小型微型计算机系统, 2016, 37(10): 2296-2299. 10.3969/j.issn.1000-1220.2016.10.029 |
| LU G F, WAN M H. Hessian regularized low-rank matrix factorization[J]. Journal of Chinese Computer Systems, 2016, 37(10): 2296-2299. 10.3969/j.issn.1000-1220.2016.10.029 | |
| 27 | LIN Z C, LIU R S, SU Z X. Linearized alternating direction method with adaptive penalty for low-rank representation[C]// Proceedings of the 24th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2011: 612-620. |
| 28 | CAI J F, CANDÈS E J, SHEN Z W. A singular value thresholding algorithm for matrix completion[J]. SIAM Journal on Optimization, 2010, 20(4): 1956-1982. 10.1137/080738970 |
| 29 | LIN Z C, CHEN M M, WU L Q, et al. The augmented Lagrange multiplier method for exact recovery of corrupted low-rank matrices: UILU-ENG-09-2215, DC-247[R]. Urbana, IL: University of Illinois at Urbana-Champaign, Coordinated Science Laboratory, 2009:10. |
| 30 | HARTIGAN J A, WONG M A. A K-means clustering algorithm[J]. Journal of the Royal Statistical Society, Series C (Applied Statistics), 1979, 28(1): 100-108. 10.2307/2346830 |
| 31 | LEE D D, SEUNG H S. Algorithms for non-negative matrix factorization[C]// Proceedings of the 13th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2000: 535-541. |
| 32 | ABDI H, WILLIAMS L J. Principal component analysis[J]. Wiley Interdisciplinary Reviews: Computational Statistics, 2010, 2(4): 433-459. 10.1002/wics.101 |
| 33 | SHI J B, MALIK J. Normalized cuts and image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22(8): 888-905. 10.1109/34.868688 |
| 34 | CAI D, HE X F, WANG X H, et al. Locality preserving nonnegative matrix factorization[C]// Proceedings of the 21st International Joint Conferences on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2009: 1010-1015. |
| [1] | 王清, 赵杰煜, 叶绪伦, 王弄潇. 统一框架的增强深度子空间聚类方法[J]. 《计算机应用》唯一官方网站, 2024, 44(7): 1995-2003. |
| [2] | 张卓, 陈花竹. 基于一致性和多样性的多尺度自表示学习的深度子空间聚类[J]. 《计算机应用》唯一官方网站, 2024, 44(2): 353-359. |
| [3] | 马志峰, 于俊洋, 王龙葛. 多样性表示的深度子空间聚类算法[J]. 《计算机应用》唯一官方网站, 2023, 43(2): 407-412. |
| [4] | 任奇泽, 贾洪杰, 陈东宇. 融合局部结构学习的大规模子空间聚类算法[J]. 《计算机应用》唯一官方网站, 2023, 43(12): 3747-3754. |
| [5] | 吴明月, 周栋, 赵文玉, 屈薇. 基于流形学习的句向量优化[J]. 《计算机应用》唯一官方网站, 2023, 43(10): 3062-3069. |
| [6] | 高冉, 陈花竹. 改进的基于谱聚类的子空间聚类模型[J]. 《计算机应用》唯一官方网站, 2021, 41(12): 3645-3651. |
| [7] | 朱玉娜, 张玉涛, 闫少阁, 范钰丹, 陈韩托. 基于半监督子空间聚类的协议识别方法[J]. 计算机应用, 2021, 41(10): 2900-2904. |
| [8] | 王丽娟, 陈少敏, 尹明, 许跃颖, 郝志峰, 蔡瑞初, 温雯. 基于近邻图改进的块对角子空间聚类算法[J]. 计算机应用, 2021, 41(1): 36-42. |
| [9] | 曾梦, 宁彬, 蔡之华, 谷琼. 使用深度对抗子空间聚类实现高光谱波段选择[J]. 《计算机应用》唯一官方网站, 2020, 40(2): 381-385. |
| [10] | 张乐园, 李佳烨, 李鹏清. 低秩约束的非线性属性选择算法[J]. 计算机应用, 2018, 38(12): 3444-3449. |
| [11] | 程铃钫, 杨天鹏, 陈黎飞. 不平衡数据的软子空间聚类算法[J]. 计算机应用, 2017, 37(10): 2952-2957. |
| [12] | 吴杰祺, 李晓宇, 袁晓彤, 刘青山. 利用坐标下降实现并行稀疏子空间聚类[J]. 计算机应用, 2016, 36(2): 372-376. |
| [13] | 程晓雅, 王春红. 基于特征化字典的低秩表示人脸识别[J]. 计算机应用, 2016, 36(12): 3423-3428. |
| [14] | 支晓斌, 许朝晖. 鲁棒的特征权重自调节软子空间聚类算法[J]. 计算机应用, 2015, 35(3): 770-774. |
| [15] | 张成, 刘亚东, 李元. 基于判别式扩散映射分析的非线性特征提取[J]. 计算机应用, 2015, 35(2): 470-475. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||