


《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (2): 654-660.DOI: 10.11772/j.issn.1001-9081.2021122053
• 前沿与综合应用 • 上一篇
收稿日期:2021-12-09
修回日期:2022-02-28
接受日期:2022-03-07
发布日期:2023-02-08
出版日期:2023-02-10
通讯作者:
李彩虹
作者简介:李永迪(1996—),男,山东淄博人,硕士研究生,主要研究方向:检测与控制基金资助:
Yongdi LI, Caihong LI( ), Yaoyu ZHANG, Guosheng ZHANG
), Yaoyu ZHANG, Guosheng ZHANG
Received:2021-12-09
Revised:2022-02-28
Accepted:2022-03-07
Online:2023-02-08
Published:2023-02-10
Contact:
Caihong LI
About author:LI Yongdi, born in 1996, M. S. candidate. His research interests include detection and control.Supported by:摘要:
为解决SAC算法在移动机器人局部路径规划中训练时间长、收敛速度慢等问题,通过引入优先级经验回放(PER)技术,提出了PER-SAC算法。首先从等概率从经验池中随机抽取样本变为按优先级抽取,使网络优先训练误差较大的样本,从而提高了机器人训练过程的收敛速度和稳定性;其次优化时序差分(TD)误差的计算,以降低训练偏差;然后利用迁移学习,使机器人从简单环境到复杂环境逐步训练,从而提高训练速度;另外,设计了改进的奖励函数,增加机器人的内在奖励,从而解决了环境奖励稀疏的问题;最后在ROS平台上进行仿真测试。仿真结果表明,在不同的障碍物环境中,PER-SAC算法均比原始算法收敛速度更快、规划的路径长度更短,并且PER-SAC算法能够减少训练时间,在路径规划性能上明显优于原始算法。
中图分类号:
李永迪, 李彩虹, 张耀玉, 张国胜. 基于改进SAC算法的移动机器人路径规划[J]. 计算机应用, 2023, 43(2): 654-660.
Yongdi LI, Caihong LI, Yaoyu ZHANG, Guosheng ZHANG. Mobile robot path planning based on improved SAC algorithm[J]. Journal of Computer Applications, 2023, 43(2): 654-660.
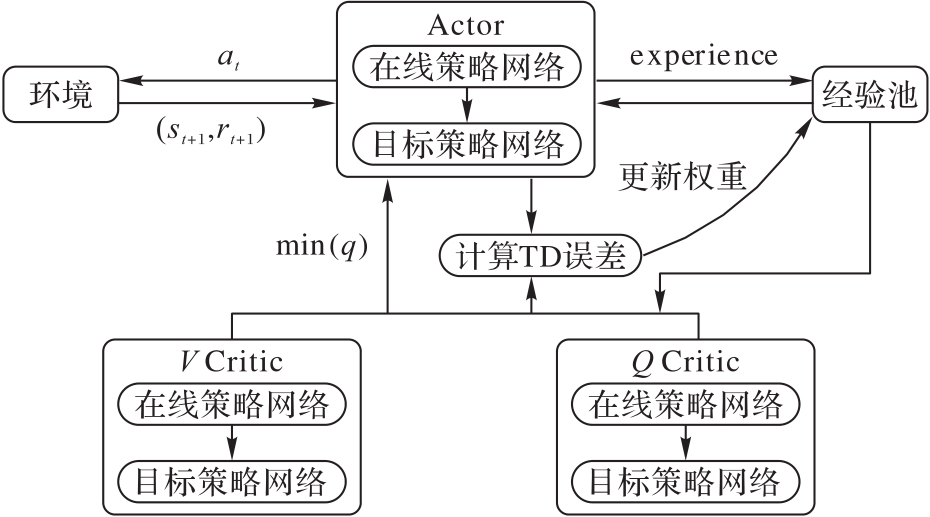
图1 SAC算法网络构架
Fig. 1 Network framework of SAC algorithm
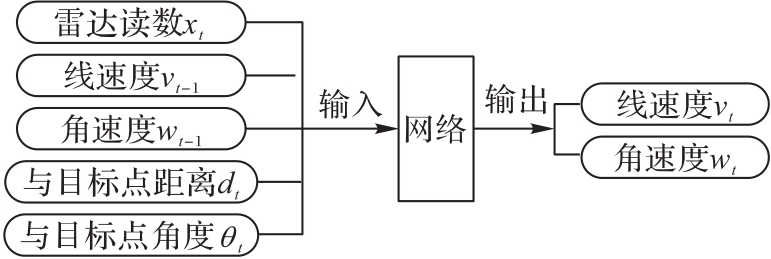
图2 网络的输入和输出
Fig. 2 Network input and output

图3 SAC网络结构
Fig. 3 SAC network structure
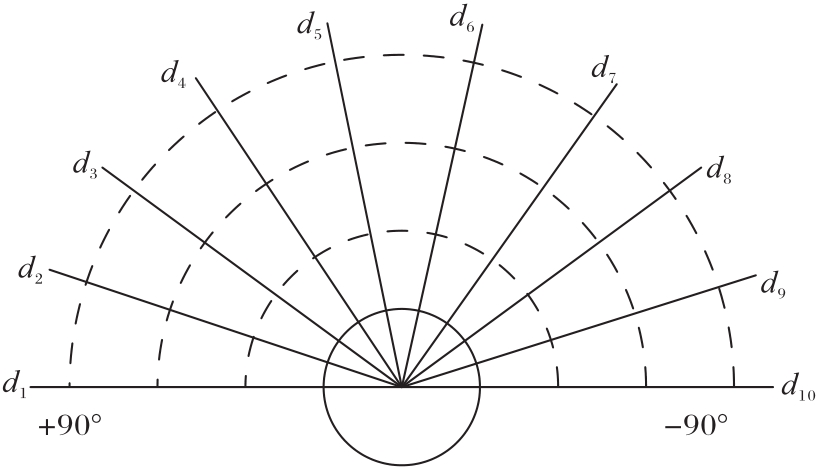
图4 激光雷达数据采集结构
Fig. 4 Lidar data acquisition structure
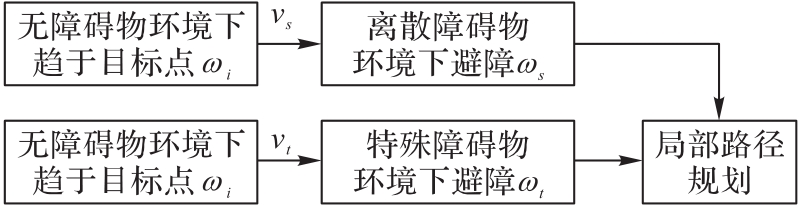
图5 迁移学习结构
Fig. 5 Transfer learning structure
| 参数 | 数值 | 参数 | 数值 |
|---|---|---|---|
| 学习率 | 0.000 3 | 每轮学习经验数量 | 256 |
| 折扣系数 | 0.99 | 训练轮数 | 200 |
| 隐藏层神经元个数 | 512 | 每轮训练步数最大值 | 500 |
| 经验池容量 | 50 000 |
表1 仿真参数设置
Tab. 1 Simulation parameter setting
| 参数 | 数值 | 参数 | 数值 |
|---|---|---|---|
| 学习率 | 0.000 3 | 每轮学习经验数量 | 256 |
| 折扣系数 | 0.99 | 训练轮数 | 200 |
| 隐藏层神经元个数 | 512 | 每轮训练步数最大值 | 500 |
| 经验池容量 | 50 000 |

图6 无障碍仿真环境
Fig. 6 Obstacle-free simulation environment

图7 无障碍环境下每轮的平均奖励对比
Fig. 7 Comparison of average reward per round of obstacle-free environment
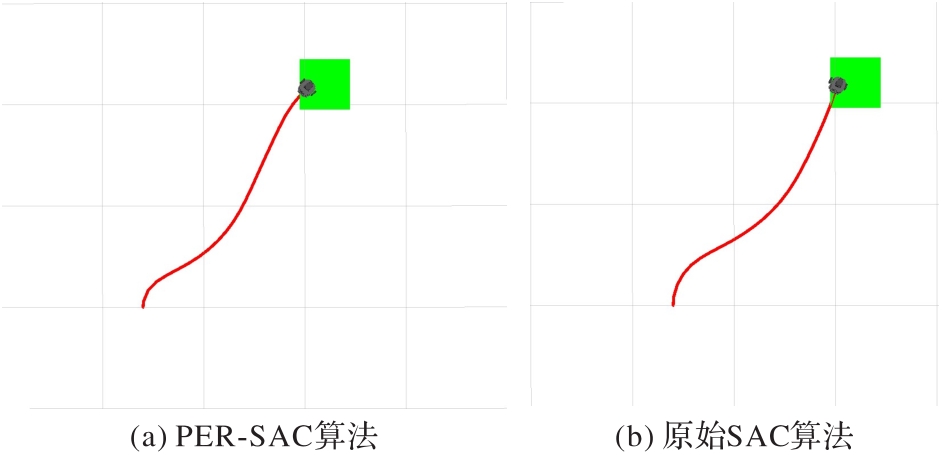
图8 无障碍环境下的路径规划
Fig. 8 Path planning in obstacle-free environment
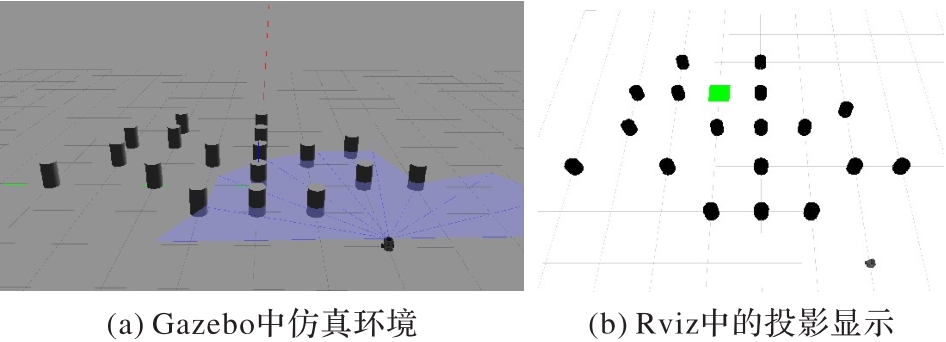
图9 离散障碍物仿真环境
Fig. 9 Discrete obstacle simulation environment
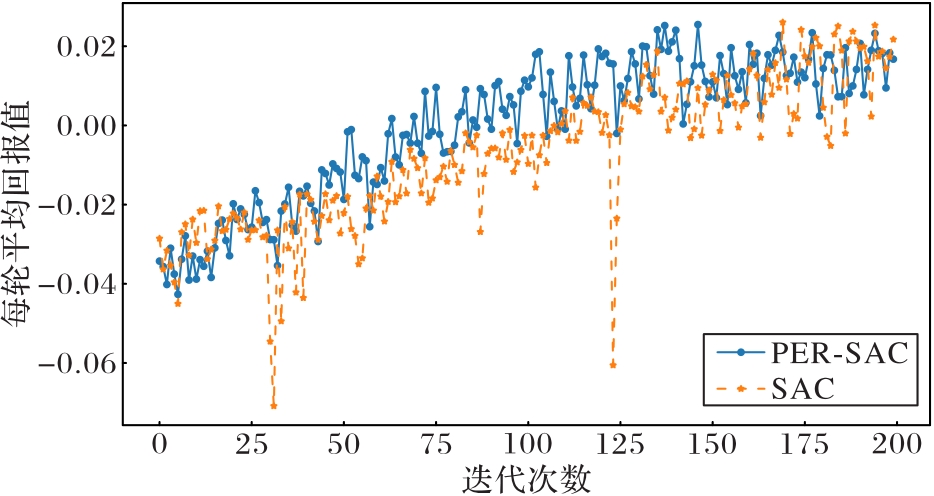
图10 离散障碍环境下每轮的平均奖励对比
Fig. 10 Comparison of average reward per round in discrete obstacle environment

图11 离散障碍环境下的路径规划
Fig. 11 Path planning in discrete obstacle environment
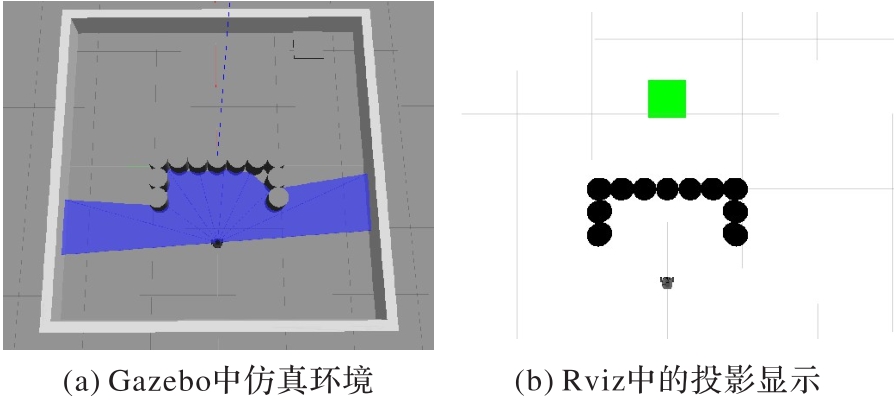
图12 U型障碍物仿真环境
Fig. 12 U-shaped obstacle simulation environment

图13 U型障碍环境下每轮的平均奖励对比
Fig. 13 Comparison of average reward per round in U-shaped obstacle environment
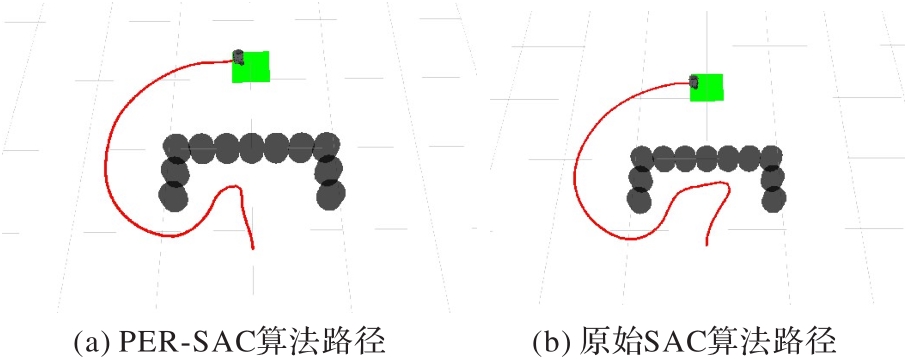
图14 U型障碍环境下的路径规划
Fig. 14 Path planning in U-shaped obstacle environment
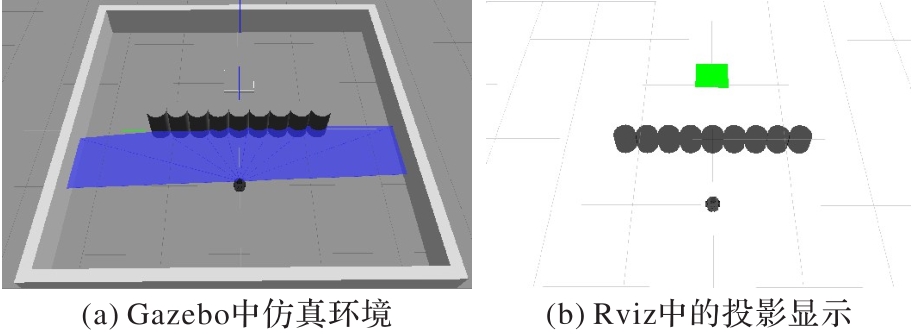
图15 一型障碍物仿真环境
Fig. 15 1-shaped obstacle simulation environment
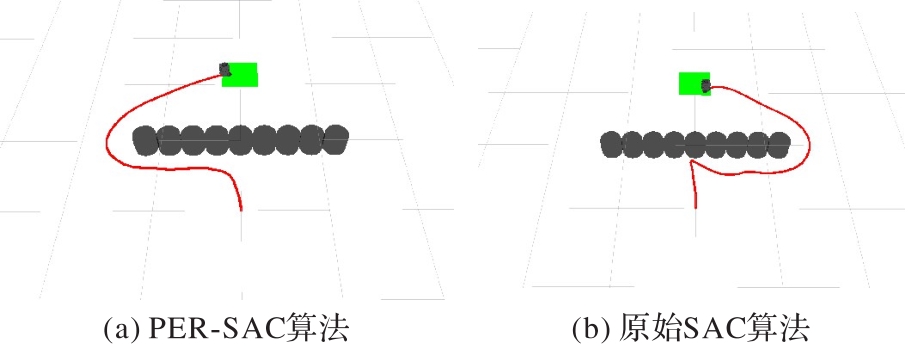
图16 一型障碍环境下的路径规划
Fig. 16 Path planning in one-shaped obstacle environment
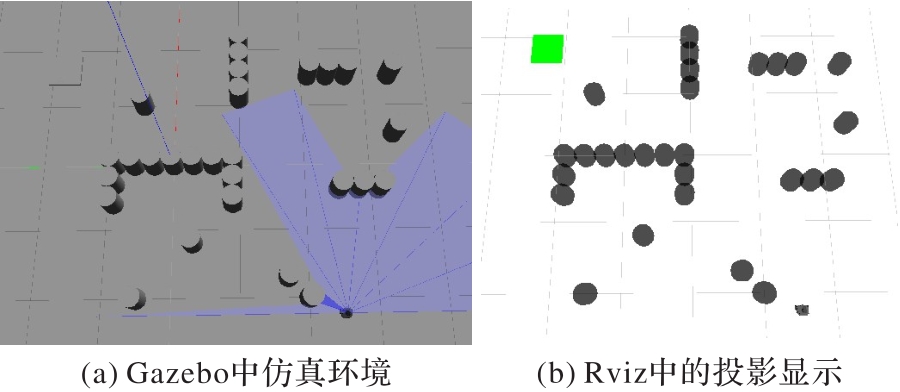
图17 混合障碍环境一
Fig. 17 The first mixed obstacle environment
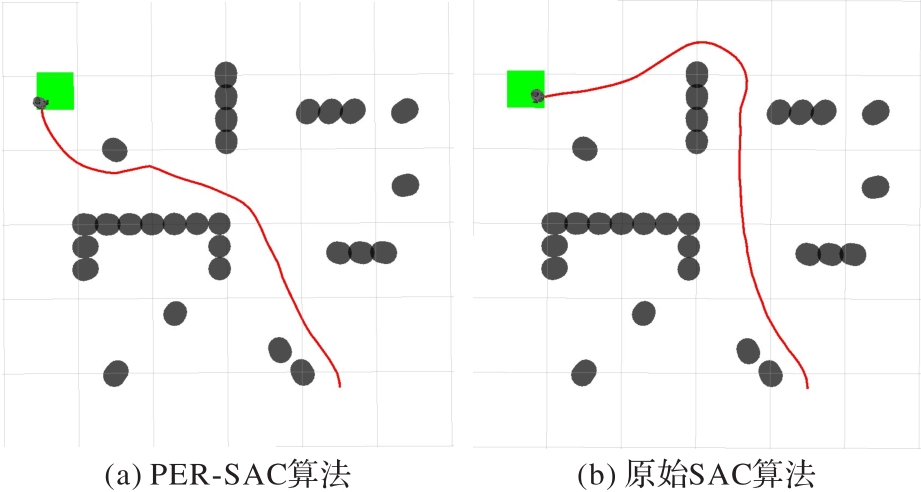
图18 混合障碍环境一下的路径规划
Fig. 18 Path planning in the first mixed obstacle environment
图19 混合障碍物环境二
Fig. 19 The second mixed obstacle environment
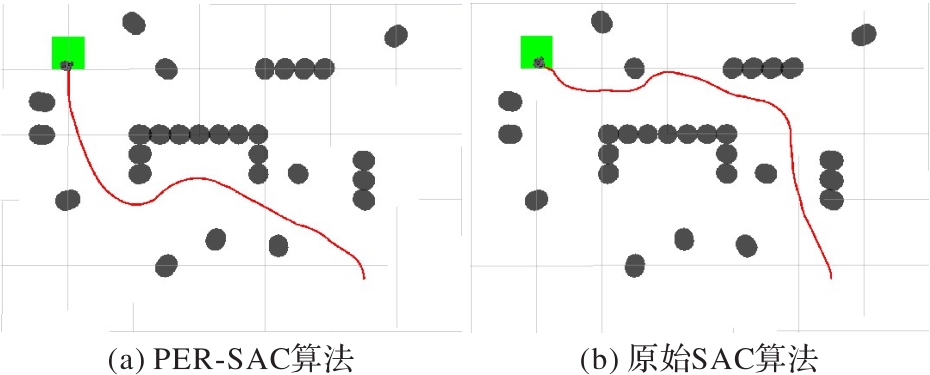
图20 混合障碍环境二下的路径规划
Fig. 20 Path planning in the second mixed obstacle environment
障碍物 类型 | 开始收敛轮数 | 稳定收敛轮数 | ||
|---|---|---|---|---|
| PER-SAC算法 | SAC算法 | PER-SAC算法 | SAC算法 | |
| 无障碍物 | 30 | 60 | 65 | 85 |
| 离散障碍物 | 35 | 60 | 110 | 130 |
| U型障碍物 | 50 | 90 | 135 | 180 |
表2 算法收敛时间
Tab. 2 Algorithm convergence time
障碍物 类型 | 开始收敛轮数 | 稳定收敛轮数 | ||
|---|---|---|---|---|
| PER-SAC算法 | SAC算法 | PER-SAC算法 | SAC算法 | |
| 无障碍物 | 30 | 60 | 65 | 85 |
| 离散障碍物 | 35 | 60 | 110 | 130 |
| U型障碍物 | 50 | 90 | 135 | 180 |
| 障碍物类型 | PER-SAC算法 | SAC算法 |
|---|---|---|
| 无障碍物 | 115 | 118 |
| 离散障碍物 | 248 | 257 |
| U型障碍物 | 274 | 298 |
| 一型障碍物 | 183 | 226 |
| 混合障碍物一 | 271 | 304 |
| 混合障碍物二 | 279 | 310 |
表3 到达目标所用步数
Tab. 3 Number of steps reaching target
| 障碍物类型 | PER-SAC算法 | SAC算法 |
|---|---|---|
| 无障碍物 | 115 | 118 |
| 离散障碍物 | 248 | 257 |
| U型障碍物 | 274 | 298 |
| 一型障碍物 | 183 | 226 |
| 混合障碍物一 | 271 | 304 |
| 混合障碍物二 | 279 | 310 |
| 1 | 郭凯红,李博昊,宗晓瑞,等. 基于改进人工势场的避障路径规划策略研究[J]. 舰船科学技术, 2021, 43(7): 54-57. |
| GUO K H, LI B H, ZONG X R, et al. Research on path planning based on improved artificial potential field[J]. Ship Science and Technology, 2021, 43(7): 54-57. | |
| 2 | 汪四新,谭功全,蒋沁,等. 基于改进A*算法的移动机器人路径规划[J]. 计算机仿真, 2021, 38(9): 386-389, 404. 10.3969/j.issn.1006-9348.2021.09.077 |
| WANG S X, TAN G Q, JIANG Q, et al. Path planning for mobile robot based on improved A* algorithm[J]. Computer Simulation, 2021, 38 (9): 386-389, 404. 10.3969/j.issn.1006-9348.2021.09.077 | |
| 3 | GURUJI A K, AGARWAL H, PARSEDIYA D K. Time efficient A* algorithm for robot path planning[J]. Procedia Technology, 2016, 23: 144-149. 10.1016/j.protcy.2016.03.010 |
| 4 | 张松灿,普杰信,司彦娜,等. 蚁群算法在移动机器人路径规划中的应用综述[J]. 计算机工程与应用, 2020, 56(8):10-19. |
| ZHANG S C, PU J X, SI Y N, et al. Survey on application of ant colony algorithm in path planning of mobile robot[J]. Computer Engineering and Applications, 2020, 56(8): 10-19. | |
| 5 | MIRJALILI S, DONG J S, LEWIS A. Ant colony optimizer: theory, literature review, and application in AUV path planning: methods and applications[M]// MIRJALILI S, DONG J S, LEWIS A.Nature-Inspired Optimizers: Theories, Literature Reviews and Applications, SCI 811. Cham: Springer, 2020: 7-21. 10.1007/978-3-030-12127-3_2 |
| 6 | 李少波,宋启松,李志昂,等. 遗传算法在机器人路径规划中的研究综述[J]. 科学技术与工程, 2020, 20(2):423-431. 10.3969/j.issn.1671-1815.2020.02.001 |
| LI S B, SONG Q S, LI Z A, et al. Review of genetic algorithm in robot path planning[J]. Science Technology and Engineering, 2020, 20(2): 423-431. 10.3969/j.issn.1671-1815.2020.02.001 | |
| 7 | 吕柏行,郭志光,赵韦皓,等. 标准粒子群算法的优化方式综述[J]. 科学技术创新, 2021(28):33-37. 10.3969/j.issn.1673-1328.2021.28.013 |
| LYU B X, GUO Z G, ZHAO W H, et al. A review on optimization methods of standard particle swarm optimization[J]. Scientific and Technological Innovation, 2021(28): 33-37. 10.3969/j.issn.1673-1328.2021.28.013 | |
| 8 | 王彩霞,林寿英. 基于深度学习的多目标跟踪算法综述[J]. 中阿科技论坛(中英文), 2021(10):118-120. 10.1109/cac53003.2021.9727659 |
| WANG C X, LIN S Y. A survey on multi-target tracking algorithm based on deep learning[J]. China-Arab States Science and Technology Forum, 2021(10): 118-120. 10.1109/cac53003.2021.9727659 | |
| 9 | 李茹杨,彭慧民,李仁刚,等. 强化学习算法与应用综述[J]. 计算机系统应用, 2020, 29(12):13-25. |
| LI R Y, PENG H M, LI R G, et al. Overview on algorithms and applications for reinforcement learning[J]. Computer Systems and Applications, 2020, 29(12): 13-25. | |
| 10 | 张荣霞,武长旭,孙同超,等. 深度强化学习及在路径规划中的研究进展[J]. 计算机工程与应用, 2021, 57(19):44-56. |
| ZHANG R X, WU C X, SUN T C, et al. Progress on deep reinforcement learning in path planning[J]. Computer Engineering and Applications, 2021, 57(19): 44-56. | |
| 11 | HAARNOJA T, ZHOU A, ABBEEL P, et al. Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor[C]// Proceedings of the 35th International Conference on Machine Learning. New York: JMLR.org, 2018: 1861-1870. 10.1109/icra.2018.8460756 |
| 12 | HAARNOJA T, ZHOU A, HARTIKAINEN K, et al. Soft actor-critic algorithms and applications[EB/OL]. (2019-01-29) [2020-06-28].. |
| 13 | DE JESUS J C, KICH V A, KOLLING A H, et al. Soft actor-critic for navigation of mobile robots[J]. Journal of Intelligent and Robotic Systems, 2021, 102(2): No.31. 10.1007/s10846-021-01367-5 |
| 14 | 肖硕,黄珍珍,张国鹏,等. 基于SAC的多智能体深度强化学习算法[J]. 电子学报, 2021, 49(9):1675-1681. 10.12263/DZXB.20200243 |
| XIAO S, HUANG Z Z, ZHANG G P, et al. Deep reinforcement learning algorithm of multi-agent based on SAC[J]. Acta Electronica Sinica, 2021, 49(9): 1675-1681. 10.12263/DZXB.20200243 | |
| 15 | 单麒源,张智豪,张耀心,等. 基于SAC算法的矿山应急救援智能车快速避障控制[J]. 黑龙江科技大学学报, 2021, 31(1):14-20. 10.3969/j.issn.2095-7262.2021.01.003 |
| SHAN Q Y, ZHANG Z H, ZHANG Y X, et al. High speed obstacle avoidance control of mine emergency rescue intelligent vehicle based on SAC algorithm[J]. Journal of Heilongjiang University of Science and Technology, 2021, 31(1): 14-20. 10.3969/j.issn.2095-7262.2021.01.003 | |
| 16 | 胡仕柯,赵海军. 基于改进柔性演员评论家算法的研究[J]. 太原师范学院学报(自然科学版), 2021, 20(3):48-52. |
| HU S K, ZHAO H J. Research on algorithm based on improved soft actor-critic[J]. Journal of Taiyuan Normal University (Natural Science Edition), 2021, 20(3): 48-52. | |
| 17 | 姜玉斌,刘全,胡智慧. 带最大熵修正的行动者评论家算法[J]. 计算机学报, 2020, 43(10):1897-1908. 10.11897/SP.J.1016.2020.01897 |
| JIANG Y B, LIU Q, HU Z H. Actor-critic algorithm with maximum-entropy correction[J]. Chinese Journal of Computers, 2020, 43(10): 1897-1908. 10.11897/SP.J.1016.2020.01897 |
| [1] | 申炳琦, 张志明, 舒少龙. 移动机器人超宽带与视觉惯性里程计组合的室内定位算法[J]. 《计算机应用》唯一官方网站, 2022, 42(12): 3924-3930. |
| [2] | 李开荣, 刘爽, 胡倩倩, 唐亦媛. 基于转角约束的改进蚁群优化算法路径规划[J]. 计算机应用, 2021, 41(9): 2560-2568. |
| [3] | 陆国庆, 孙昊. 基于随机行走的群机器人二维地图构建[J]. 计算机应用, 2021, 41(7): 2121-2127. |
| [4] | 栾佳宁, 张伟, 孙伟, 张奥, 韩冬. 基于二维码视觉与激光雷达融合的高精度定位算法[J]. 计算机应用, 2021, 41(5): 1484-1491. |
| [5] | 李二超, 齐款款. B样条曲线融合蚁群算法的机器人路径规划[J]. 《计算机应用》唯一官方网站, 2021, 41(12): 3558-3564. |
| [6] | 刘昂, 蒋近, 徐克锋. 改进蚁群和鸽群算法的机器人路径规划[J]. 计算机应用, 2020, 40(11): 3366-3372. |
| [7] | 王坤, 曾国辉, 鲁敦科, 黄勃, 李晓斌. 基于改进渐进最优的双向快速扩展随机树的移动机器人路径规划算法[J]. 计算机应用, 2019, 39(5): 1312-1317. |
| [8] | 陈若男, 文聪聪, 彭玲, 尤承增. 改进A*算法在机器人室内路径规划中的应用[J]. 计算机应用, 2019, 39(4): 1006-1011. |
| [9] | 黄超, 梁圣涛, 张毅, 张杰. 基于多目标蝗虫优化算法的移动机器人路径规划[J]. 计算机应用, 2019, 39(10): 2859-2864. |
| [10] | 杜柳青, 许贺作, 余永维, 张建恒. 基于改进SURF算法的柔性装夹机器人快速工件匹配方法[J]. 计算机应用, 2018, 38(7): 2050-2055. |
| [11] | 罗蕊, 师五喜, 李宝全. 受侧滑和滑移影响的移动机器人自抗扰控制[J]. 计算机应用, 2018, 38(5): 1517-1522. |
| [12] | 王维, 裴东, 冯璋. 改进A*算法的移动机器人最短路径规划[J]. 计算机应用, 2018, 38(5): 1523-1526. |
| [13] | 张涛, 马磊, 梅玲玉. 基于单目视觉的仓储物流机器人定位方法[J]. 计算机应用, 2017, 37(9): 2491-2495. |
| [14] | 罗天洪, 梁爽, 何泽银, 张霞. 基于情景萤火虫算法的机器人路径规划[J]. 计算机应用, 2017, 37(12): 3608-3613. |
| [15] | 林辉灿, 吕强, 王国胜, 张洋, 梁冰. 基于VSLAM的自主移动机器人三维同时定位与地图构建[J]. 计算机应用, 2017, 37(10): 2884-2887. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||