


《计算机应用》唯一官方网站 ›› 2023, Vol. 43 ›› Issue (8): 2636-2643.DOI: 10.11772/j.issn.1001-9081.2022071069
• 前沿与综合应用 • 上一篇
收稿日期:2022-07-23
修回日期:2022-11-03
接受日期:2022-11-07
发布日期:2023-01-15
出版日期:2023-08-10
通讯作者:
王昱
作者简介:任田君(1995—),男,山西运城人,硕士研究生,主要研究方向:智能决策基金资助:
Yu WANG( ), Tianjun REN, Zilin FAN
), Tianjun REN, Zilin FAN
Received:2022-07-23
Revised:2022-11-03
Accepted:2022-11-07
Online:2023-01-15
Published:2023-08-10
Contact:
Yu WANG
About author:REN Tianjun, born in 1995, M. S. candidate. His research interests include intelligent decision-making.Supported by:摘要:
针对无人机(UAV)空战环境信息复杂、对抗性强所导致的敌机机动策略难以预测,以及作战胜率不高的问题,设计了一种引导Minimax-DDQN(Minimax-Double Deep Q-Network)算法。首先,在Minimax决策方法的基础上提出了一种引导式策略探索机制;然后,结合引导Minimax策略,以提升Q网络更新效率为出发点设计了一种DDQN(Double Deep Q-Network)算法;最后,提出进阶式三阶段的网络训练方法,通过不同决策模型间的对抗训练,获取更为优化的决策模型。实验结果表明,相较于Minimax-DQN(Minimax-DQN)、Minimax-DDQN等算法,所提算法追击直线目标的成功率提升了14%~60%,并且与DDQN算法的对抗胜率不低于60%。可见,与DDQN、Minimax-DDQN等算法相比,所提算法在高对抗的作战环境中具有更强的决策能力,适应性更好。
中图分类号:
王昱, 任田君, 范子琳. 基于引导Minimax-DDQN的无人机空战机动决策[J]. 计算机应用, 2023, 43(8): 2636-2643.
Yu WANG, Tianjun REN, Zilin FAN. Air combat maneuver decision-making of unmanned aerial vehicle based on guided Minimax-DDQN[J]. Journal of Computer Applications, 2023, 43(8): 2636-2643.
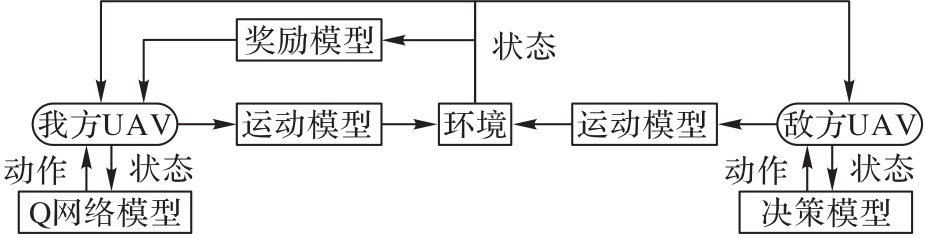
图1 无人机对战决策系统
Fig.1 UAV combat decision-making system

图2 无人机运动参数
Fig.2 UAV motion parameters
| 动作序号 | 动作名称 | 动作序号 | 动作名称 |
|---|---|---|---|
| 1 | 匀速直线运动 | 5 | 最大过载右转 |
| 2 | 最大加速运动 | 6 | 最大过载爬升 |
| 3 | 最大减速运动 | 7 | 最大过载俯冲 |
| 4 | 最大过载左转 |
表1 机动动作分类
Tab. 1 Maneuver motion classification
| 动作序号 | 动作名称 | 动作序号 | 动作名称 |
|---|---|---|---|
| 1 | 匀速直线运动 | 5 | 最大过载右转 |
| 2 | 最大加速运动 | 6 | 最大过载爬升 |
| 3 | 最大减速运动 | 7 | 最大过载俯冲 |
| 4 | 最大过载左转 |
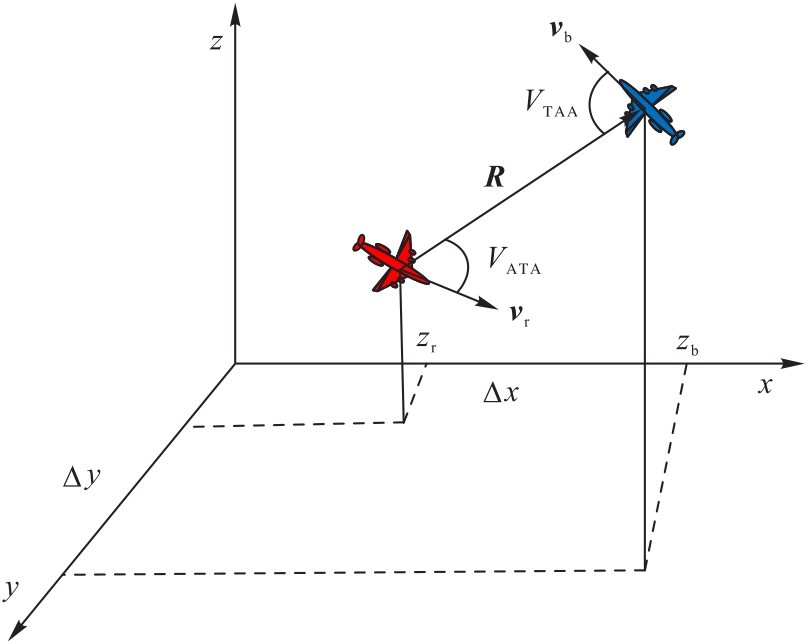
图3 双方战机相对态势关系
Fig.3 Relative state relationship of fighters of both sides
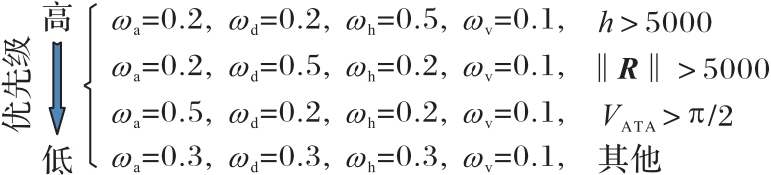
图4 权值分配
Fig.4 Weight assignment
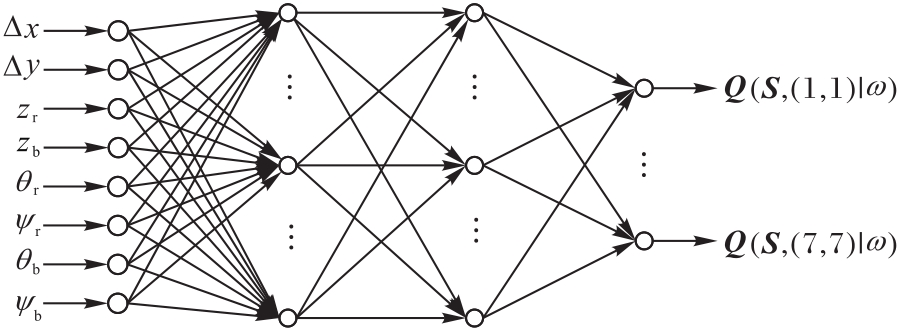
图5 Q网络模型
Fig.5 Q-network model

图6 引导策略示意图
Fig. 6 Schematic diagram of guidance strategy
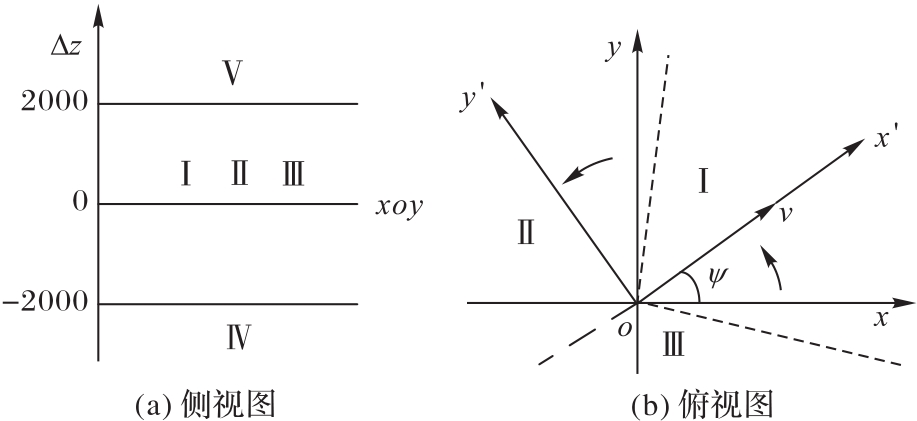
图7 引导策略的区域划分
Fig. 7 Regional division of guidance strategy
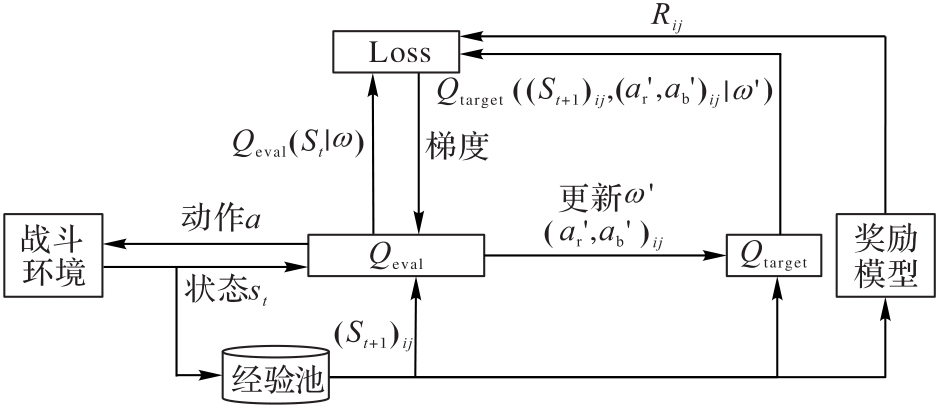
图8 DDQN决策算法
Fig. 8 DDQN decision-making algorithm
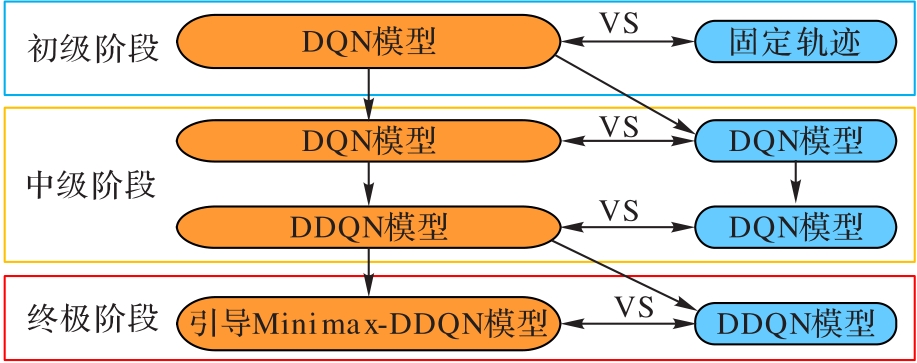
图9 三阶段进阶式模型训练方法
Fig. 9 Advanced three-stage network training method
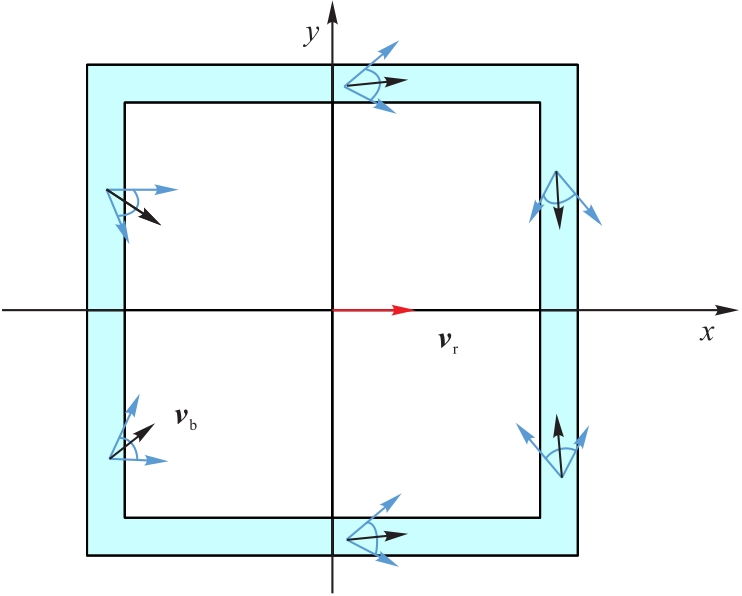
图10 双方初始态势示意图(俯视图)
Fig.10 Schematic diagram of initial states of both sides (vertical view)
| 参数 | 值 | 参数 | 值 |
|---|---|---|---|
| Rmin/m | 5 000 | Rmax/m | 10 000 |
| hmin /m | -4 000 | hmax /m | 4 000 |
| hop /m | 1 000 | vmin /(m·s-1) | 150 |
| g /(m·s-2) | 9.8 | vmax /(m·s-1) | 450 |
| ηxmax | 1.5 | ηx-max | -1 |
| ηzmax | 9 |
表2 实验参数
Tab. 2 Experimental parameters
| 参数 | 值 | 参数 | 值 |
|---|---|---|---|
| Rmin/m | 5 000 | Rmax/m | 10 000 |
| hmin /m | -4 000 | hmax /m | 4 000 |
| hop /m | 1 000 | vmin /(m·s-1) | 150 |
| g /(m·s-2) | 9.8 | vmax /(m·s-1) | 450 |
| ηxmax | 1.5 | ηx-max | -1 |
| ηzmax | 9 |
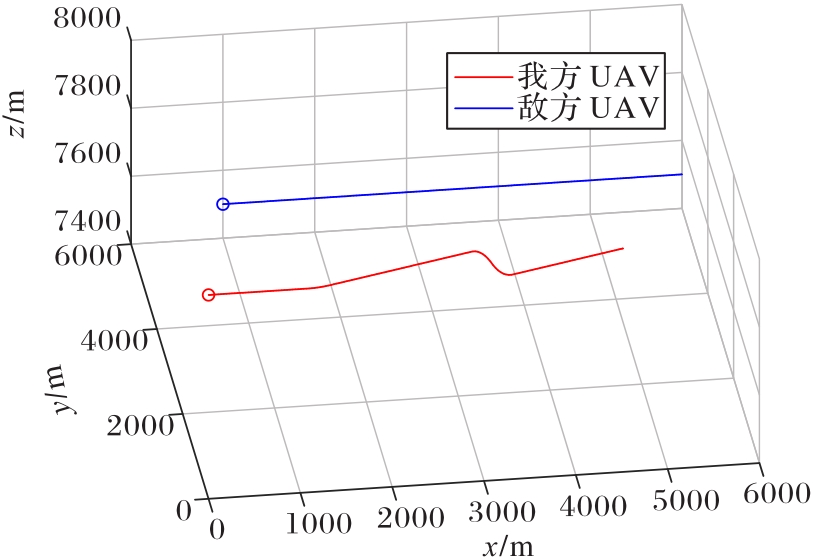
图11 固定双方初始状态的对抗轨迹
Fig.11 Confrontation trajectories of both sides with fixed initial states
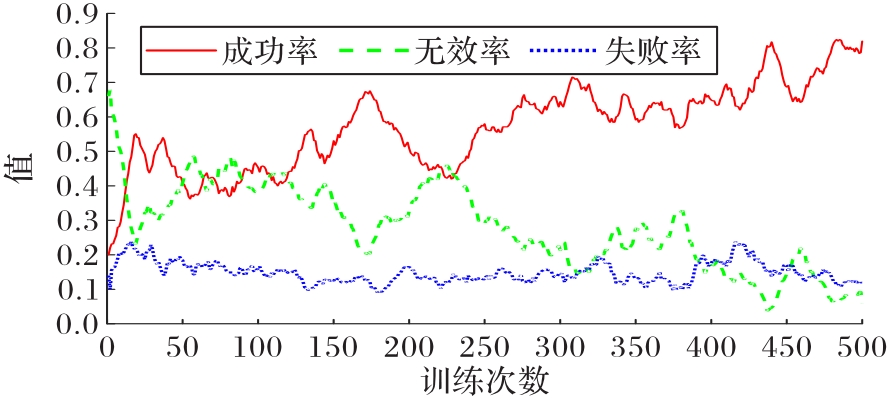
图12 第一阶段训练胜率变化曲线
Fig.12 Winning rate changing curve of training in the first stage

图13 第二阶段DQN自我博弈胜率变化曲线
Fig.13 Winning rate changing curve of DQN self-play in the second stage
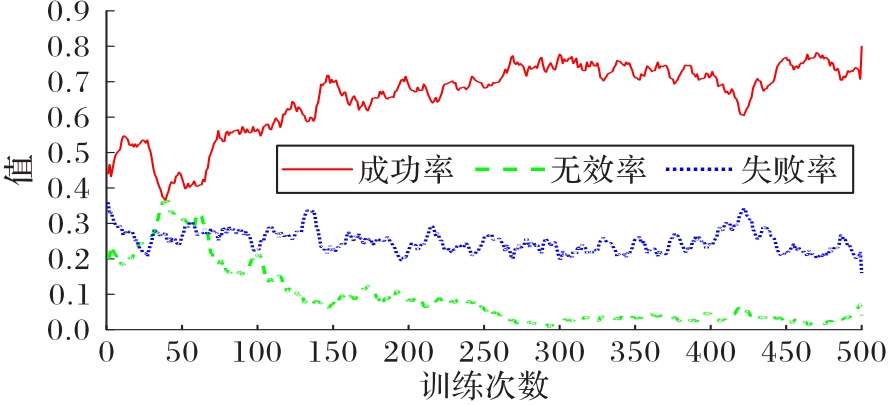
图14 第二阶段DDQN vs DQN胜率变化曲线
Fig.14 Winning rate changing curve of DDQN vs DQN in the second stage
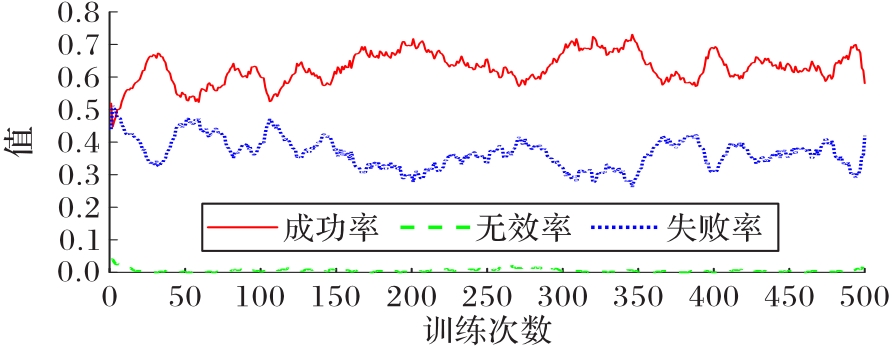
图15 第三阶段训练胜率变化曲线
Fig.15 Winning rate changing curve in the third stage
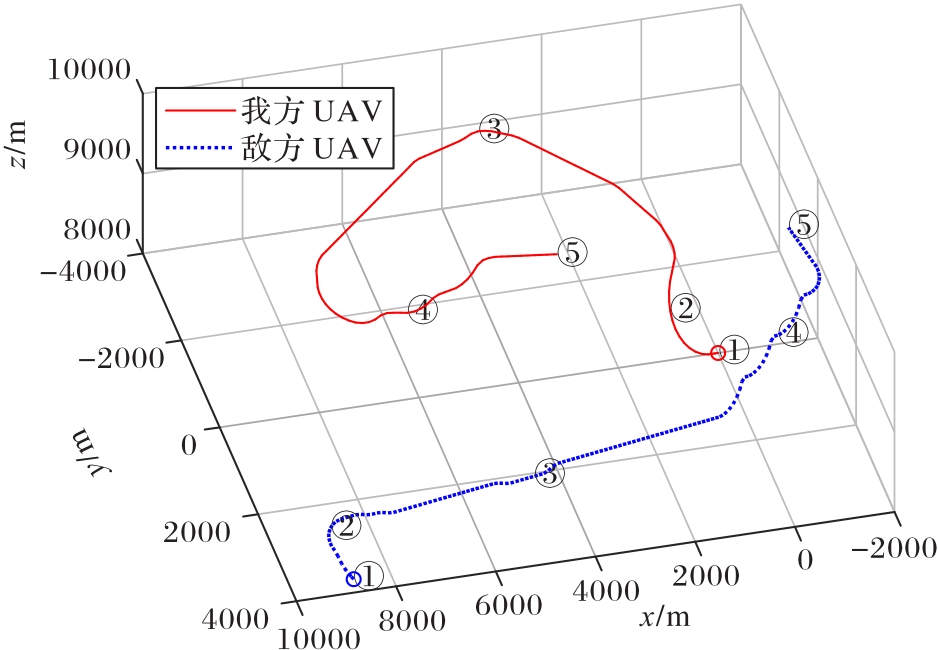
图16 优势态势下双方对抗轨迹
Fig.16 Confrontation trajectories of both sides in superior situation
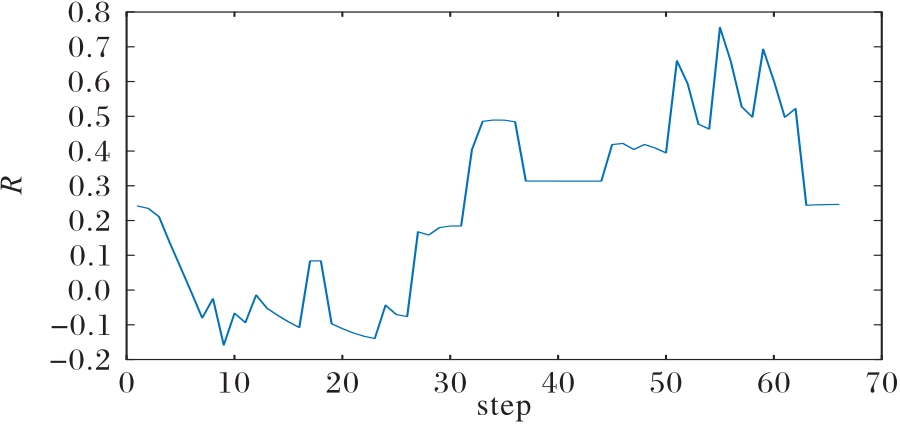
图17 优势态势下我方优势变化曲线
Fig.17 Advantage change curve in superior situation

图18 均势态势下双方对抗轨迹图
Fig.18 Confrontation trajectories of both sides in equilibrium situation
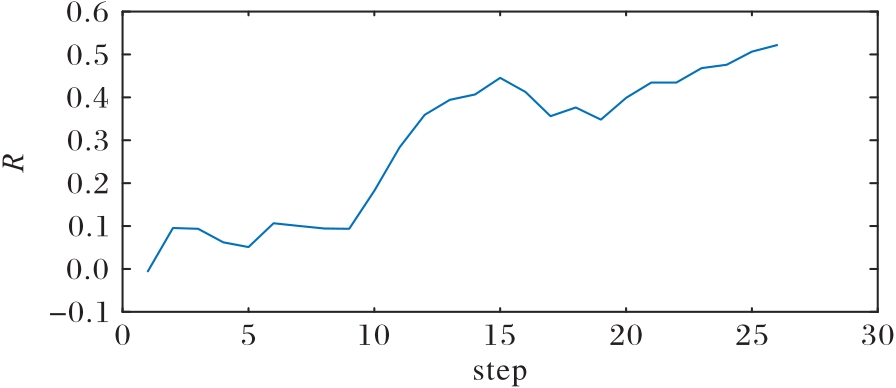
图19 均势态势下我方优势变化曲线
Fig.19 Advantage change curve in equilibrium situation

图20 劣势态势下双方对抗轨迹图
Fig.20 Confrontation trajectories of both sides in inferior situation
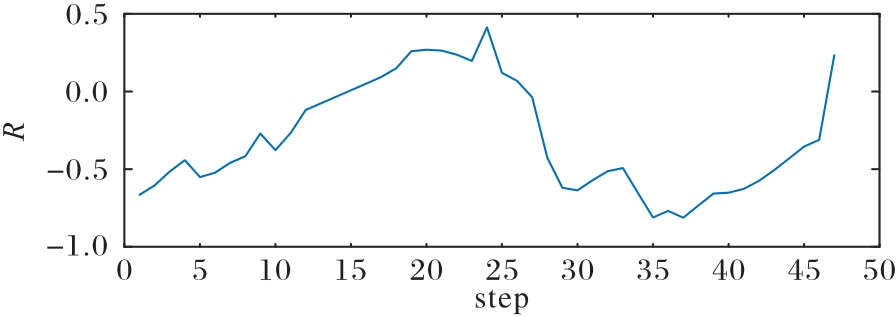
图21 劣势态势下我方优势变化曲线
Fig.21 Advantage change curve in inferior situation

图22 不同算法的胜率曲线对比
Fig.22 Comparison of winning curves of different algorithms
| 1 | 周新民,吴佳晖,贾圣德,等. 无人机空战决策技术研究进展[J]. 国防科技, 2021, 42(3):33-41. |
| ZHOU X M, WU J H, JIA S D, et al. Progress in research on combat decision-making technology in UAVs[J]. National Defense Technology, 2021, 42(3): 33-41. | |
| 2 | 张宏鹏,黄长强,轩永波,等. 基于深度神经网络的无人作战飞机自主空战机动决策[J]. 兵工学报, 2020, 41(8):1613-1622. 10.3969/j.issn.1000-1093.2020.08.016 |
| ZHANG H P, HUANG C Q, XUAN Y B, et al. Maneuver decision of autonomous air combat of unmanned combat aerial vehicle based on deep neural network[J]. Acta Armamentarii, 2020, 41(8): 1613-1622. 10.3969/j.issn.1000-1093.2020.08.016 | |
| 3 | ZHANG S, ZHOU Y Q, LI Z M, et al. Grey wolf optimizer for unmanned combat aerial vehicle path planning[J]. Advances in Engineering Software, 2016, 99: 121-136. 10.1016/j.advengsoft.2016.05.015 |
| 4 | ERNEST N, CARROLL D, SCHUMACHER C, et al. Genetic fuzzy based artificial intelligence for unmanned combat aerial vehicle control in simulated air combat missions[J]. Journal of Defense Management, 2016, 6(1): No.1000144. |
| 5 | HUANG C Q, DONG K S, HUANG H Q, et al. Autonomous air combat maneuver decision using Bayesian inference and moving horizon optimization[J]. Journal of Systems Engineering and Electronics, 2018, 29(1): 86-97. 10.21629/jsee.2018.01.09 |
| 6 | 杨萍,毕义明,刘卫东. 基于模糊马尔科夫理论的机动智能体决策模型[J]. 系统工程与电子技术, 2008, 30(3):511-514. 10.3321/j.issn:1001-506X.2008.03.030 |
| YANG P, BI Y M, LIU W D. Decision-making model of tactics maneuver agent based on fuzzy Markov decision theory[J]. Systems Engineering and Electronic, 2008, 30(3): 511-514. 10.3321/j.issn:1001-506X.2008.03.030 | |
| 7 | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing Atari with deep reinforcement learning[EB/OL]. (2013-12-19) [2022-04-15].. 10.1038/nature14236 |
| 8 | SILVER D, HUANG A, MADDISON C J, et al. Mastering the game of go with deep neural networks and tree search[J]. Nature, 2016, 2016, 529(7587): 484-489. 10.1038/nature16961 |
| 9 | 唐振韬,邵坤,赵冬斌,等. 深度强化学习进展:从AlphaGo到AlphaGo Zero[J]. 控制理论与应用, 2017, 34(12):1529-1546. |
| TANG Z T, SHAO K, ZHAO D B, et al. Recent progress of deep reinforcement learning: from AlphaGo to AlphaGo Zero[J]. Control Theory and Applications, 2017, 34(12): 1529-1546. | |
| 10 | 余伶俐,邵玄雅,龙子威,等. 智能车辆深度强化学习的模型迁移轨迹规划方法[J]. 控制理论与应用, 2019, 36(9):1409-1422. 10.7641/CTA.2018.80341 |
| YU L L, SHAO X Y, LONG Z W, et al. Intelligent land vehicle model transfer trajectory planning method of deep reinforcement learning[J]. Control Theory and Applications, 2019, 36(9): 1409-1422. 10.7641/CTA.2018.80341 | |
| 11 | DUAN J L, LI S E, GUAN Y, et al. Hierarchical reinforcement learning for self-driving decision-making without reliance on labelled driving data[J]. IET Intelligent Transport Systems, 2020, 14(5): 297-305. 10.1049/iet-its.2019.0317 |
| 12 | 张强,杨任农,俞利新,等. 基于Q-network强化学习的超视距空战机动决策[J]. 空军工程大学学报(自然科学版), 2018, 19(6):8-14. |
| ZHANG Q, YANG R N, YU L X, et al. BVR air combat maneuver decision by using Q-network reinforcement learning[J]. Journal of Air Force Engineering University (Natural Science Edition), 2018, 19(6): 8-14. | |
| 13 | 丁林静,杨啟明. 基于强化学习的无人机空战机动决策[J]. 航空电子技术, 2018, 49(2):29-35. 10.3969/j.issn.1006-141X.2018.02.06 |
| DING L J, YANG Q M. Research on air combat maneuver decision of UAVs based on reinforcement learning[J]. Avionics Technology, 2018, 49(2): 29-35. 10.3969/j.issn.1006-141X.2018.02.06 | |
| 14 | POPE A P, IDE J S, MIĆOVIĆ D, et al. Hierarchical reinforcement learning for air-to-air combat[C]// Proceedings of the 2021 International Conference on Unmanned Aircraft System. Piscataway: IEEE, 2021: 275-284. 10.1109/icuas51884.2021.9476700 |
| 15 | 马文,李辉,王壮,等. 基于深度随机博弈的近距空战机动决策[J]. 系统工程与电子技术, 2021, 43(2):443-451. 10.12305/j.issn.1001-506X.2021.02.19 |
| MA W, LI H, WANG Z, et al. Close air combat maneuver decision based on deep stochastic game[J]. Systems Engineering and Electronic, 2021, 43(2): 443-451. 10.12305/j.issn.1001-506X.2021.02.19 | |
| 16 | YANG Q M, ZHANG J D, SHI G Q, et al. Maneuver decision of UAV in short-range air combat based on deep reinforcement learning[J]. IEEE Access, 2020, 8: 363-378. 10.1109/access.2019.2961426 |
| 17 | van HASSELT H, GUEZ A, SILVER D. Deep reinforcement learning with double Q-learning[C]// Proceedings of the 30th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2016: 2094-2100. 10.1609/aaai.v30i1.10295 |
| 18 | 刘建伟,高峰,罗雄麟. 基于值函数和策略梯度的深度强化学习综述[J]. 计算机学报, 2019, 42(6):1406-1438. 10.11897/SP.J.1016.2019.01406 |
| LIU J W, GAO F, LUO X L. Survey of deep reinforcement learning based on value function and policy gradient[J]. Chinese Journal of Computers, 2019, 42(6): 1406-1438. 10.11897/SP.J.1016.2019.01406 | |
| 19 | GUO T, JIANG N, LI B Y, et al. UAV navigation in high dynamic environments: a deep reinforcement learning approach[J]. Chinese Journal of Aeronautics, 2021, 34(2): 479-489. 10.1016/j.cja.2020.05.011 |
| 20 | LI Y F, SHI J P, JIANG W, et al. Autonomous maneuver decision-making for a UCAV in short range aerial combat based on an MS-DDQN algorithm[J]. Defence Technology, 2022, 18(9): 1697-1714. 10.1016/j.dt.2021.09.014 |
| 21 | 李永丰,史静平,章卫国,等. 深度强化学习的无人作战飞机空战机动决策[J]. 哈尔滨工业大学学报, 2021, 53(12):33-41. 10.11918/202005108 |
| LI Y F, SHI J P, ZHANG W G, et al. Maneuver decision of UCAV in air combat based on deep reinforcement learning[J]. Journal of Harbin Institute of Technology, 2021, 53(12): 33-41. 10.11918/202005108 |
| [1] | 王子腾, 于亚新, 夏子芳, 乔佳琪. 融合好奇心和策略蒸馏的稀疏奖励探索机制[J]. 《计算机应用》唯一官方网站, 2023, 43(7): 2082-2090. |
| [2] | 方和平, 刘曙光, 冉泳屹, 钟坤华. 基于深度强化学习的多数据中心一体化调度优化[J]. 《计算机应用》唯一官方网站, 2023, 43(6): 1884-1892. |
| [3] | 李校林, 江雨桑. 无人机辅助移动边缘计算中的任务卸载算法[J]. 《计算机应用》唯一官方网站, 2023, 43(6): 1893-1899. |
| [4] | 黄晓辉, 杨凯铭, 凌嘉壕. 基于共享注意力的多智能体强化学习订单派送[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1620-1624. |
| [5] | 曹腾飞, 刘延亮, 王晓英. 基于改进深度强化学习的边缘计算服务卸载算法[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1543-1550. |
| [6] | 丁正凯, 傅启明, 陈建平, 陆悠, 吴宏杰, 方能炜, 邢镔. 结合注意力机制与深度强化学习的超短期光伏功率预测[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1647-1654. |
| [7] | 邓晖奕, 李勇振, 尹奇跃. 引入通信与探索的多智能体强化学习QMIX算法[J]. 《计算机应用》唯一官方网站, 2023, 43(1): 202-208. |
| [8] | 邓绍斌, 朱军, 周晓锋, 李帅, 刘舒锐. 基于局部策略交互探索的深度确定性策略梯度的工业过程控制方法[J]. 《计算机应用》唯一官方网站, 2022, 42(5): 1642-1648. |
| [9] | 石兵, 黄茜子, 宋兆翔, 徐建桥. 基于用户激励的共享单车调度策略[J]. 《计算机应用》唯一官方网站, 2022, 42(11): 3395-3403. |
| [10] | 臧嵘, 王莉, 史腾飞. 基于注意力消息共享的多智能体强化学习[J]. 《计算机应用》唯一官方网站, 2022, 42(11): 3346-3353. |
| [11] | 徐郁, 朱韵攸, 刘筱, 邓雨婷, 廖勇. 基于深度强化学习的电力物资配送多目标路径优化[J]. 《计算机应用》唯一官方网站, 2022, 42(10): 3252-3258. |
| [12] | 王建平, 王刚, 毛晓彬, 马恩琪. 基于深度强化学习的二连杆机械臂运动控制方法[J]. 计算机应用, 2021, 41(6): 1799-1804. |
| [13] | 姚兴虎, 谭晓阳. 基于奖励高速路网络的多智能体强化学习中的全局信用分配算法[J]. 计算机应用, 2021, 41(1): 1-7. |
| [14] | 傅魁, 梁少晴, 李冰. 基于改进的深度Q网络结构的商品推荐模型[J]. 计算机应用, 2020, 40(9): 2613-2621. |
| [15] | 王甜甜, 于双元, 徐保民. 基于策略梯度算法的工作量证明中挖矿困境研究[J]. 计算机应用, 2019, 39(5): 1336-1342. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||