


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (1): 39-46.DOI: 10.11772/j.issn.1001-9081.2023010055
收稿日期:2023-01-30
修回日期:2023-05-05
接受日期:2023-05-09
发布日期:2023-06-06
出版日期:2024-01-10
通讯作者:
江爱文
作者简介:陈思航(1997—),男,江西萍乡人,硕士研究生,CCF学生会员,主要研究方向:视觉对话;基金资助:
Sihang CHEN, Aiwen JIANG( ), Zhaoyang CUI, Mingwen WANG
), Zhaoyang CUI, Mingwen WANG
Received:2023-01-30
Revised:2023-05-05
Accepted:2023-05-09
Online:2023-06-06
Published:2024-01-10
Contact:
Aiwen JIANG
About author:CHEN Sihang, born in 1997, M. S. candidate. His research interests include visual dialogue.Supported by:摘要:
当前视觉对话任务在多模态信息融合和推理方面取得了较大进展,但是,在回答一些涉及具有比较明确语义属性和位置空间关系的问题时,主流模型的能力依然有限。比较少的主流模型在正式响应之前能够显式地提供有关图像内容的、语义充分的细粒度表达。视觉特征表示与对话历史、当前问句等文本语义之间缺少必要的、缓解语义鸿沟的桥梁,因此提出一种基于多通道多步融合的视觉对话模型MCMI。该模型显式提供一组关于视觉内容的细粒度语义描述信息,并通过“视觉-语义-对话”历史三者相互作用和多步融合,能够丰富问题的语义表示,实现较为准确的答案解码。在VisDial v0.9/VisDial v1.0数据集中,MCMI模型较基准模型双通道多跳推理模型(DMRM),平均倒数排名(MRR)分别提升了1.95和2.12个百分点,召回率(R@1)分别提升了2.62和3.09个百分点,正确答案平均排名(Mean)分别提升了0.88和0.99;在VisDial v1.0数据集中,较最新模型UTC(Unified Transformer Contrastive learning model), MRR、R@1、Mean分别提升了0.06百分点,0.68百分点和1.47。为了进一步评估生成对话的质量,提出类图灵测试响应通过比例M1和对话质量分数(五分制)M2两个人工评价指标。在VisDial v0.9数据集中,相较于基准模型DMRM,MCMI模型的M1和M2指标分别提高了9.00百分点和0.70。
中图分类号:
陈思航, 江爱文, 崔朝阳, 王明文. 基于多通道多步融合的生成式视觉对话模型[J]. 计算机应用, 2024, 44(1): 39-46.
Sihang CHEN, Aiwen JIANG, Zhaoyang CUI, Mingwen WANG. Multi-channel multi-step integration model for generative visual dialogue[J]. Journal of Computer Applications, 2024, 44(1): 39-46.
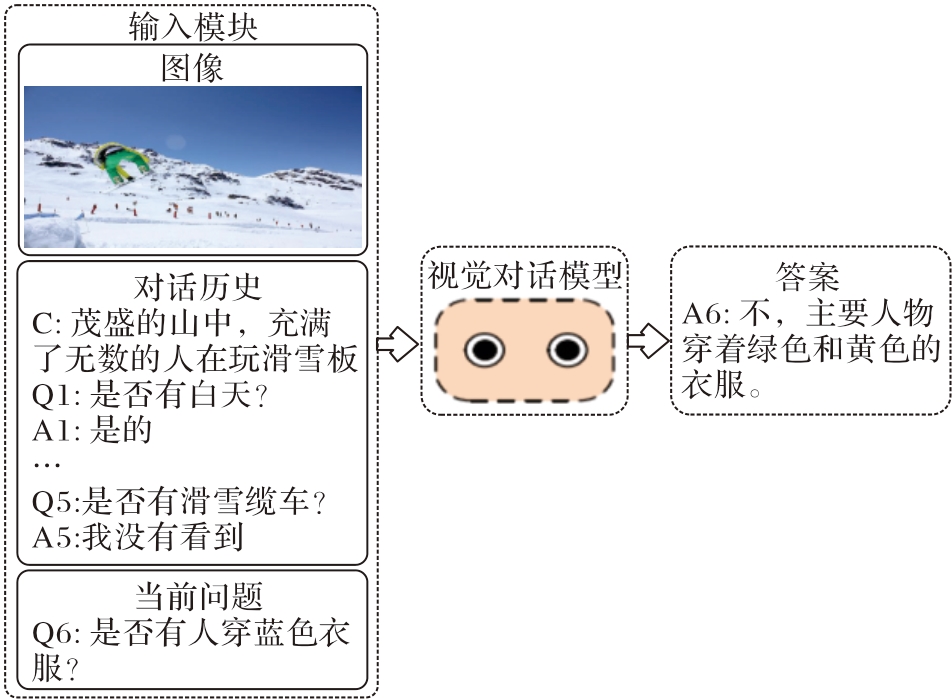
图1 视觉对话的示例
Fig. 1 Example of visual dialogue

图2 视觉对话难点示例
Fig. 2 Example of visual dialogue difficulties

图3 基于多通道多步融合的视觉对话模型总体框架
Fig. 3 Overall framework of visual dialogue model based on multi-channel multi-step integration

图4 细粒度视觉语义特征编码示意图
Fig. 4 Encoding schematic diagram of fine-grained visual semantic features

图5 多通道多步推理过程示意图
Fig. 5 Schematic diagram of multi-channel multi-step inference process
| 模型 | MRR↑/% | R@1↑/% | R@5↑/% | R@10↑/% | Mean↓ |
|---|---|---|---|---|---|
| MN[ | 52.59 | 42.29 | 62.85 | 68.88 | 17.06 |
| HCIAE[ | 53.86 | 44.06 | 63.55 | 69.24 | 16.01 |
| CoAtt[ | 54.11 | 44.32 | 63.82 | 69.75 | 16.47 |
| DMRM[ | 55.96 | 46.20 | 66.02 | 72.43 | 13.35 |
| VD-BERT[ | 55.95 | 46.83 | 65.43 | 72.05 | 13.18 |
| MITVG[ | 56.83 | 47.14 | 67.19 | 73.72 | 14.37 |
| LTMI-GoG[ | 56.32 | 46.65 | 66.41 | 72.69 | 13.78 |
| LTMI-LG[ | 56.56 | 46.71 | 66.69 | 73.37 | 13.62 |
| MCMI | 57.91 | 48.82 | 68.86 | 74.73 | 12.47 |
表1 VisDial v0.9上与主流模型的实验结果比较(生成式任务)
Tab. 1 Experimental result comparison with mainstream models on VisDial v0.9 (generative tasks)
| 模型 | MRR↑/% | R@1↑/% | R@5↑/% | R@10↑/% | Mean↓ |
|---|---|---|---|---|---|
| MN[ | 52.59 | 42.29 | 62.85 | 68.88 | 17.06 |
| HCIAE[ | 53.86 | 44.06 | 63.55 | 69.24 | 16.01 |
| CoAtt[ | 54.11 | 44.32 | 63.82 | 69.75 | 16.47 |
| DMRM[ | 55.96 | 46.20 | 66.02 | 72.43 | 13.35 |
| VD-BERT[ | 55.95 | 46.83 | 65.43 | 72.05 | 13.18 |
| MITVG[ | 56.83 | 47.14 | 67.19 | 73.72 | 14.37 |
| LTMI-GoG[ | 56.32 | 46.65 | 66.41 | 72.69 | 13.78 |
| LTMI-LG[ | 56.56 | 46.71 | 66.69 | 73.37 | 13.62 |
| MCMI | 57.91 | 48.82 | 68.86 | 74.73 | 12.47 |
| 模型 | MRR↑/% | R@1↑/% | R@5↑/% | R@10↑/% | Mean↓ |
|---|---|---|---|---|---|
| MN[ | 47.99 | 38.18 | 57.54 | 64.32 | 18.60 |
| HCIAE[ | 49.10 | 39.35 | 58.49 | 64.70 | 18.46 |
| CoAtt[ | 49.25 | 39.66 | 58.83 | 65.38 | 18.15 |
| ReDAN[ | 49.69 | 40.19 | 59.35 | 66.06 | 17.92 |
| DMRM[ | 50.16 | 40.15 | 60.02 | 67.21 | 15.19 |
| DAM[ | 50.51 | 40.53 | 60.84 | 67.94 | 15.26 |
| KBGN[ | 50.05 | 40.40 | 60.11 | 66.82 | 17.54 |
| MITVG[ | 51.14 | 41.03 | 61.25 | 68.49 | 14.37 |
| LTMI-GoG[ | 51.32 | 41.25 | 61.83 | 69.44 | 15.32 |
| LTMI-LG[ | 51.30 | 41.34 | 61.61 | 69.06 | 15.26 |
| UTC[ | 52.22 | 42.56 | 62.40 | 69.51 | 15.67 |
| MCMI | 52.28 | 43.24 | 62.78 | 69.45 | 14.20 |
表2 VisDial v1.0上与主流模型的实验结果比较(生成式任务)
Tab. 2 Experimental result comparison with mainstream models on VisDial v1.0 (generative tasks)
| 模型 | MRR↑/% | R@1↑/% | R@5↑/% | R@10↑/% | Mean↓ |
|---|---|---|---|---|---|
| MN[ | 47.99 | 38.18 | 57.54 | 64.32 | 18.60 |
| HCIAE[ | 49.10 | 39.35 | 58.49 | 64.70 | 18.46 |
| CoAtt[ | 49.25 | 39.66 | 58.83 | 65.38 | 18.15 |
| ReDAN[ | 49.69 | 40.19 | 59.35 | 66.06 | 17.92 |
| DMRM[ | 50.16 | 40.15 | 60.02 | 67.21 | 15.19 |
| DAM[ | 50.51 | 40.53 | 60.84 | 67.94 | 15.26 |
| KBGN[ | 50.05 | 40.40 | 60.11 | 66.82 | 17.54 |
| MITVG[ | 51.14 | 41.03 | 61.25 | 68.49 | 14.37 |
| LTMI-GoG[ | 51.32 | 41.25 | 61.83 | 69.44 | 15.32 |
| LTMI-LG[ | 51.30 | 41.34 | 61.61 | 69.06 | 15.26 |
| UTC[ | 52.22 | 42.56 | 62.40 | 69.51 | 15.67 |
| MCMI | 52.28 | 43.24 | 62.78 | 69.45 | 14.20 |
| 模型 | M1↑/% | M2↑ |
|---|---|---|
| DMRM | 67.00 | 3.20 |
| MCMI | 76.00 | 3.90 |
表3 DMRM和MCMI的人工评价结果对比
Tab. 3 Manual evaluation result comparison between DMRM and MCMI
| 模型 | M1↑/% | M2↑ |
|---|---|---|
| DMRM | 67.00 | 3.20 |
| MCMI | 76.00 | 3.90 |
| 模型 | MRR↑/% | R@1↑/% | R@5↑/% | R@10↑/% | Mean↓ |
|---|---|---|---|---|---|
| MCMI-1 | 51.48 | 41.93 | 60.46 | 67.90 | 14.76 |
| MCMI-2 | 52.10 | 42.35 | 61.43 | 68.21 | 14.47 |
| MCMI-V | 49.94 | 40.20 | 59.18 | 65.87 | 16.17 |
| MCMI-H | 51.63 | 41.44 | 60.72 | 66.71 | 15.18 |
| MCMI-S | 50.26 | 41.39 | 60.17 | 67.34 | 15.01 |
| MCMI-FA | 52.02 | 42.26 | 61.37 | 67.69 | 14.47 |
| MCMI | 52.28 | 43.24 | 62.78 | 69.45 | 14.20 |
表4 消融实验结果
Tab. 4 Ablation experiment results
| 模型 | MRR↑/% | R@1↑/% | R@5↑/% | R@10↑/% | Mean↓ |
|---|---|---|---|---|---|
| MCMI-1 | 51.48 | 41.93 | 60.46 | 67.90 | 14.76 |
| MCMI-2 | 52.10 | 42.35 | 61.43 | 68.21 | 14.47 |
| MCMI-V | 49.94 | 40.20 | 59.18 | 65.87 | 16.17 |
| MCMI-H | 51.63 | 41.44 | 60.72 | 66.71 | 15.18 |
| MCMI-S | 50.26 | 41.39 | 60.17 | 67.34 | 15.01 |
| MCMI-FA | 52.02 | 42.26 | 61.37 | 67.69 | 14.47 |
| MCMI | 52.28 | 43.24 | 62.78 | 69.45 | 14.20 |

图6 MCMI与部分消融模型的直观示例比较
Fig. 6 Visual example comparison of MCMI and partial ablation models

图7 MCMI与DMRM的直观示例比较
Fig. 7 Visual example comparison of MCMI and DMR
| 1 | 魏忠钰,范智昊,王瑞泽,等.从视觉到文本:图像描述生成的研究进展综述[J].中文信息学报, 2020, 34(7): 19-29. 10.3969/j.issn.1003-0077.2020.07.002 |
| WEI Z Y, FAN Z H, WANG R Z, et al. From vision to text: a brief survey for image captioning [J]. Journal of Chinese Information Processing, 2020, 34(7): 19-29. 10.3969/j.issn.1003-0077.2020.07.002 | |
| 2 | KASAI J, SAKAGUCHI K, DUNAGAN L, et al. Transparent human evaluation for image captioning [C]// Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2022: 3464-3478. 10.18653/v1/2022.naacl-main.254 |
| 3 | YANG X, ZHANG H, CAI J. Auto-encoding and distilling scene graphs for image captioning [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(5): 2313-2327. |
| 4 | YU J, ZHANG W, LU Y, et al. Reasoning on the relation: Enhancing visual representation for visual question answering and cross-modal retrieval [J]. IEEE Transactions on Multimedia, 2020, 22(12): 3196-3209. 10.1109/tmm.2020.2972830 |
| 5 | LIU Y, WEI W, PENG D, et al. Depth-aware and semantic guided relational attention network for visual question answering [J]. IEEE Transactions on Multimedia, 2022(Early Access): 1-14. 10.1109/tmm.2022.3190686 |
| 6 | JIANG J, LIU Z, ZHENG N. LiVLR: a lightweight visual-linguistic reasoning framework for video question answering [J]. IEEE Transactions on Multimedia, 2022(Early Access): 1-12. 10.1109/tmm.2022.3185900 |
| 7 | BITEN A F, LITMAN R, XIE Y, et al. LaTr: layout-aware transformer for scene-text VQA [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 16527-16537. 10.1109/cvpr52688.2022.01605 |
| 8 | DAS A, KOTTUR S, GUPTA K, et al. Visual dialog [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1080-1089. 10.1109/cvpr.2017.121 |
| 9 | LU J, XIONG C, PARIKH D, et al. Knowing when to look: adaptive attention via a visual sentinel for image captioning [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 3242-3250. 10.1109/cvpr.2017.345 |
| 10 | GAN Z, CHENG Y, KHOLY A, et al. Multi-step reasoning via recurrent dual attention for visual dialog [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2019: 6463-6474. 10.18653/v1/p19-1648 |
| 11 | GUO D, XU C, TAO D. Image-question-answer synergistic network for visual dialog [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 10426-10435. 10.1109/cvpr.2019.01068 |
| 12 | PARK S, WHANG T, YOON Y, et al. Multi-view attention network for visual dialog [J]. Applied Sciences, 2021, 11(7): No.3009. 10.3390/app11073009 |
| 13 | NIU Y, ZHANG H, ZHANG M, et al. Recursive visual attention in visual dialog [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 6672-6681. 10.1109/cvpr.2019.00684 |
| 14 | CHEN F, MENG F, XU J, et al. DMRM: a dual-channel multi-hop reasoning model for visual dialog [C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 7504-7511. 10.1609/aaai.v34i05.6248 |
| 15 | YU Z, YU J, CUI Y, et al. Deep modular co-attention networks for visual question answering [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 6274-6283. 10.1109/cvpr.2019.00644 |
| 16 | KIM H, TAN H, BANSAL M. Modality-balanced models for visual dialogue [C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 8091-8098. 10.1609/aaai.v34i05.6320 |
| 17 | WANG Y, JOTY S, LYU M, et al. VD-BERT: a unified vision and dialog transformer with BERT [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2020: 3325-3338. 10.18653/v1/2020.emnlp-main.269 |
| 18 | NGUYEN V Q, SUGANUMA M, OKATANI T. Efficient attention mechanism for visual dialog that can handle all the interactions between multiple inputs [C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12369. Cham: Springer, 2020: 223-240. |
| 19 | WANG Z, WANG J, JIANG C. Unified multimodal model with unlikelihood training for visual dialog [C]// Proceedings of the 30th ACM International Conference on Multimedia. New York: ACM, 2022: 4625-4634. 10.1145/3503161.3547974 |
| 20 | LU J, BATRA D, PARIKH D, et al. ViLBERT: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks [C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2019: 13-23. 10.1109/cvpr.2018.00754 |
| 21 | YU X, ZHANG H, HONG R, et al. VD-PCR: improving visual dialog with pronoun coreference resolution [J]. Pattern Recognition, 2022, 125: No.108540. 10.1016/j.patcog.2022.108540 |
| 22 | JIANG X, DU S, QIN Z, et al. KBGN: knowledge-bridge graph network for adaptive vision-text reasoning in visual dialogue [C]// Proceedings of the 28th ACM International Conference on Multimedia. New York: ACM, 2020: 1265-1273. 10.1145/3394171.3413826 |
| 23 | CHEN F, CHEN X, MENG F, et al. GoG: relation-aware graph-over-graph network for visual dialog [C]// Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Stroudsburg, PA: ACL, 2021: 230-243. 10.18653/v1/2021.findings-acl.20 |
| 24 | JOHNSON J, KARPATHY A, LI F F. DenseCap: fully convolutional localization networks for dense captioning [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 4565-4574. 10.1109/cvpr.2016.494 |
| 25 | ANDERSON P, HE X, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and visual question answering [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6077-6086. 10.1109/cvpr.2018.00636 |
| 26 | LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// Proceedings of the 2014 European Conference, LNCS 8693. Cham: Springer, 2014: 740-755. |
| 27 | LU J, KANNAN A, YANG J, et al. Best of both worlds: transferring knowledge from discriminative learning to a generative visual dialog model [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 313-323. |
| 28 | WU Q, WANG P, SHEN C, et al. Are you talking to me? reasoned visual dialog generation through adversarial learning [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6106-6115. 10.1109/cvpr.2018.00639 |
| 29 | CHEN F, CHEN X, XU C, et al. Learning to ground visual objects for visual dialog [C]// Findings of the Association for Computational Linguistics: EMNLP 2021. Stroudsburg, PA: ACL, 2021: 1081-1091. 10.18653/v1/2021.findings-emnlp.93 |
| 30 | JIANG X, YU J, SUN Y, et al. DAM: deliberation, abandon and memory networks for generating detailed and non-repetitive responses in visual dialogue [C]// Proceedings of the 29th International Conference on International Joint Conferences on Artificial Intelligence. California: ijcai.org, 2021: 687-693. 10.24963/ijcai.2020/96 |
| 31 | CHEN F, MENG F, CHEN X, et al. Multimodal incremental transformer with visual grounding for visual dialogue generation [C]// Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Stroudsburg, PA: ACL, 2021: 436-446. 10.18653/v1/2021.findings-acl.38 |
| 32 | CHEN C, TAN Z, CHENG Q, et al. UTC: a unified transformer with inter-task contrastive learning for visual dialog [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 18082-18091. 10.1109/cvpr52688.2022.01757 |
| [1] | 潘家航, 王嘉航, 施展, 许营坤, 许永安, 黄晓霞. FPD-ViT: 面部疼痛检测视觉转换器[J]. 《计算机应用》唯一官方网站, 2023, 43(S2): 77-82. |
| [2] | 刘磊, 伍鹏, 谢凯, 程贝芝, 盛冠群. 自监督学习HOG预测辅助任务下的车位检测方法[J]. 《计算机应用》唯一官方网站, 2023, 43(12): 3933-3940. |
| [3] | 魏楚元, 王梦珂, 户传豪, 张桄齐. 增强推荐系统可解释性的深度评论注意力神经网络模型[J]. 《计算机应用》唯一官方网站, 2023, 43(11): 3443-3448. |
| [4] | 张郅 李欣 叶乃夫 胡凯茜. 基于暗知识保护的模型窃取防御技术——DKP[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [5] | 何国欢, 朱江平. WT-U-Net++:基于小波变换的表面缺陷检测网络[J]. 《计算机应用》唯一官方网站, 2023, 43(10): 3260-3266. |
| [6] | 周晓敏, 滕飞, 张艺. 基于元网络的自动国际疾病分类编码模型[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2721-2726. |
| [7] | 宋钰丹 王晶 王雪徽 马朝阳 林友芳. 基于自适应多任务学习的睡眠生理时序分类方法[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [8] | 王昊冉 于丹 杨玉丽 马垚 陈永乐. 面向工控未知攻击的域迁移入侵检测方法[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [9] | 杨海宇, 郭文普, 康凯. 基于卷积长短时深度神经网络的信号调制方式识别方法[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 1318-1322. |
| [10] | 郝劭辰, 卫孜钻, 马垚, 于丹, 陈永乐. 基于高效联邦学习算法的网络入侵检测模型[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 1169-1175. |
| [11] | 孟佳娜, 吕品, 于玉海, 孙世昶, 林鸿飞. 基于胶囊网络的方面级跨领域情感分析[J]. 《计算机应用》唯一官方网站, 2022, 42(12): 3700-3707. |
| [12] | 蔡昌骁 王士同. 基于相关性差异化迁移的渐进式神经网络[J]. 《计算机应用》唯一官方网站, 0, (): 0-0. |
| [13] | 侯旭东, 滕飞, 张艺. 基于深度自编码的医疗命名实体识别模型[J]. 《计算机应用》唯一官方网站, 2022, 42(9): 2686-2692. |
| [14] | 蔡淳豪, 李建良. 小样本问题下培训弱教师网络的模型蒸馏模型[J]. 《计算机应用》唯一官方网站, 2022, 42(9): 2652-2658. |
| [15] | 陈荣源, 姚剑敏, 严群, 林志贤. 基于深度神经网络的视频播放速度识别[J]. 《计算机应用》唯一官方网站, 2022, 42(7): 2043-2051. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||