


Journal of Computer Applications ›› 2022, Vol. 42 ›› Issue (1): 87-93.DOI: 10.11772/j.issn.1001-9081.2021020272
Special Issue: 人工智能
• Artificial intelligence • Previous Articles Next Articles
Xiaopeng WANG, Yuanyuan SUN( ), Hongfei LIN
), Hongfei LIN
Received:2021-02-21
Revised:2021-06-27
Accepted:2021-07-08
Online:2021-07-29
Published:2022-01-10
Contact:
Yuanyuan SUN
About author:WANG Xiaopeng, born in 1996, M. S. candidate. His research interests include natural language processing.Supported by:
王小鹏, 孙媛媛(), 林鸿飞
通讯作者:
孙媛媛
作者简介:王小鹏(1996—),男,甘肃天水人,硕士研究生,研究方向:自然语言处理基金资助:CLC Number:
Xiaopeng WANG, Yuanyuan SUN, Hongfei LIN. Encoding-decoding relationship extraction model based on criminal Electra[J]. Journal of Computer Applications, 2022, 42(1): 87-93.
王小鹏, 孙媛媛, 林鸿飞. 基于刑事Electra的编-解码关系抽取模型[J]. 《计算机应用》唯一官方网站, 2022, 42(1): 87-93.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2021020272
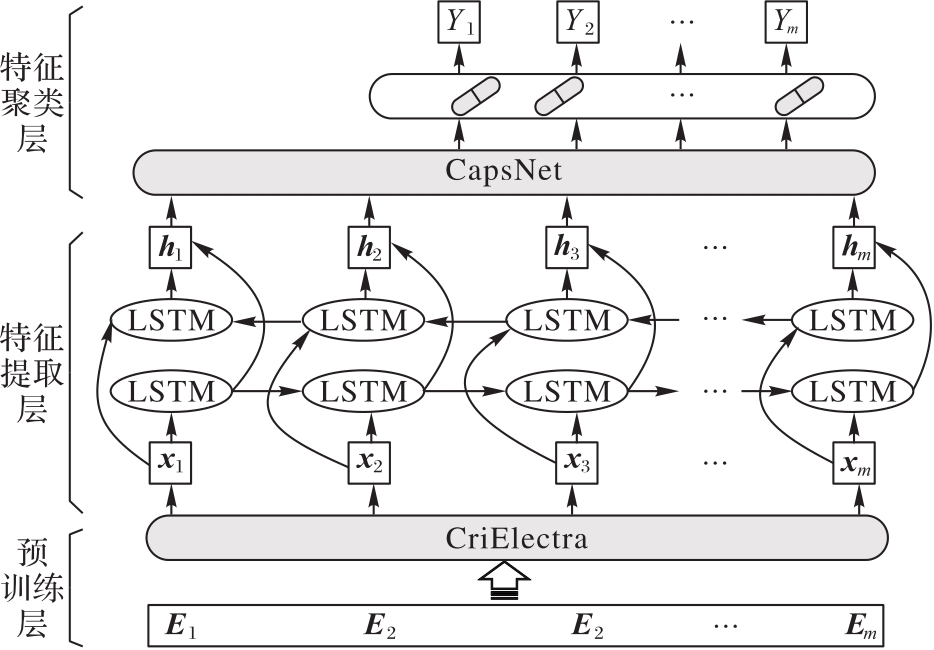
Fig. 1 Structure of CELCN model

Fig. 2 CriElectra training example

Fig. 3 Structure of capsule network model

Fig. 4 Relationship distribution

Fig. 5 F1-score curves of CELCN and ELCN

Fig. 6 F1-score curves of CELCN, MBLCN and XBLCN
| 对比设置 | 模型 | 精确率 | 召回率 | F1值 |
|---|---|---|---|---|
| 预训练模型实验对比 | XBLCN | 77.86 | 83.33 | 80.51 |
| MBLCN | 76.73 | 78.08 | 76.58 | |
| ELCN | 75.72 | 81.51 | 77.95 | |
| 特征提取模型实验对比 | CERCN | 75.13 | 81.57 | 78.21 |
| CECCN | 76.64 | 78.72 | 77.26 | |
| CECN | 76.89 | 80.98 | 79.47 | |
| 特征聚类模型实验对比 | CELAP | 72.52 | 80.82 | 76.15 |
| CELMP | 76.48 | 78.31 | 76.35 | |
| 本文模型 | CELCN | 77.26 | 82.68 | 79.88 |
Tab. 1 Performance comparison of different models
| 对比设置 | 模型 | 精确率 | 召回率 | F1值 |
|---|---|---|---|---|
| 预训练模型实验对比 | XBLCN | 77.86 | 83.33 | 80.51 |
| MBLCN | 76.73 | 78.08 | 76.58 | |
| ELCN | 75.72 | 81.51 | 77.95 | |
| 特征提取模型实验对比 | CERCN | 75.13 | 81.57 | 78.21 |
| CECCN | 76.64 | 78.72 | 77.26 | |
| CECN | 76.89 | 80.98 | 79.47 | |
| 特征聚类模型实验对比 | CELAP | 72.52 | 80.82 | 76.15 |
| CELMP | 76.48 | 78.31 | 76.35 | |
| 本文模型 | CELCN | 77.26 | 82.68 | 79.88 |

Fig. 7 F1-score curves of CELMP and CELAP
| 模型方法 | 精确率 | 召回率 | F1值 |
|---|---|---|---|
| CELAP | 39.78 | 45.16 | 42.30 |
| CELMP | 42.97 | 34.65 | 38.65 |
| CELCN | 43.88 | 41.32 | 42.56 |
Tab. 2 Experimental results of some multi-label overlapping relationship data
| 模型方法 | 精确率 | 召回率 | F1值 |
|---|---|---|---|
| CELAP | 39.78 | 45.16 | 42.30 |
| CELMP | 42.97 | 34.65 | 38.65 |
| CELCN | 43.88 | 41.32 | 42.56 |
| 1 | 率蕴铤,顾克广. 司法文书[M]. 北京:中国政法大学出版社, 1996:1-2. |
| SHUAI Y T, GU K G. Judicial Documents[M]. Beijing: China University of Political Science and Law Press, 1996: 1-2. | |
| 2 | TOLIAS G, SICRE R, JÉGOU H. Particular object retrieval with integral max-pooling of CNN activations[EB/OL]. (2016-02-24) [2021-02-27].. |
| 3 | ZHOU P, SHI W, TIAN J, et al. Attention-based bidirectional long short-term memory networks for relation classification[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2016: 207-212. 10.18653/v1/p16-2034 |
| 4 | CHENG J P, DONG L, LAPATA M. Long short-term memory-networks for machine reading[C]// Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2016: 551-561. 10.18653/v1/d16-1053 |
| 5 | SABOUR S, FROSST N, HINTON G E. Dynamic routing between capsules[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 3859-3869. |
| 6 | CLARK K, LUONG M T, LE Q V, et al. ELECTRA: pre-training text encoders as discriminators rather than generators[EB/OL]. (2020-03-23) [2021-02-27].. 10.18653/v1/2020.emnlp-main.20 |
| 7 | ZHOU G D, SU J, ZHANG J, et al. Exploring various knowledge in relation extraction[C]// Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2005: 427-434. 10.3115/1219840.1219893 |
| 8 | LIU C Y, SUN W B, CHAO W H, et al. Convolution neural network for relation extraction[C]// Proceedings of the 9th International Conference on Advanced Data Mining and Applications, LNCS8347. Berlin: Springer, 2013: 231-242. |
| 9 | ZHANG R Y, MENG F R, ZHOU Y, et al. Relation classification via recurrent neural network with attention and tensor layers[J]. Big Data Mining and Analytics, 2018, 1(3): 234-244. 10.26599/bdma.2018.9020022 |
| 10 | 孙紫阳,顾君忠,杨静. 基于深度学习的中文实体关系抽取方法[J]. 计算机工程, 2018, 44(9):164-170. 10.19678/j.issn.1000-3428.0048518 |
| SUN Z Y, GU J Z, YANG J. Chinese entity relation extraction method based on deep learning[J]. Computer Engineering, 2018, 44(9): 164-170. 10.19678/j.issn.1000-3428.0048518 | |
| 11 | LU T B, GAO P, DU X F, et al. An analysis of active attacks on anonymity systems[J]. International Journal of Security and its Applications, 2016, 10(4):95-104. 10.14257/ijsia.2016.10.4.11 |
| 12 | KIYAVASH N, HOUMANSADR A, BORISOV N. Multi-flow attacks against network flow watermarking schemes[C]// Proceedings of the 17th USENIX Security Symposium. Berkeley: USENIX Association, 2008: 307-320. 10.1109/icassp.2009.4959879 |
| 13 | LUO X P, ZHANG J J, PERDISCI R, et al. On the secrecy of spread-spectrum flow watermarks[C]// Proceedings of the 15th European Conference on Research in Computer Security, LNCS6345. Berlin: Springer, 2010: 232-248. |
| 14 | PETERS M, NEUMANN M, IYYER M, et al. Deep contextualized word representations[C]// Proceedings of the 2018 North American Chapter of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2018: 2227-2237. 10.18653/v1/n18-1202 |
| 15 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[EB/OL]. [2021-02-27]. . 10.18653/v1/n19-1423 |
| 16 | RADFORD A, WU J, CHILD R, et al. Language models are unsupervised multitask learners[EB/OL]. [2021-02-27].. |
| 17 | YANG Z L, DAI Z H, YANG Y M, et al. XLNet: generalized autoregressive pretraining for language understanding[C/OL]// Proceedings of the 33rd Conference on Neural Information Processing Systems. [2021-02-27].. 10.1145/3369985.3370025 |
| 18 | 李妮,关焕梅,杨飘,等. 基于BERT-IDCNN-CRF的中文命名实体识别方法[J]. 山东大学学报(理学版), 2020, 55(1):102-109. 10.6040/j.issn.1671-9352.2.2019.076 |
| LI N, GUAN H M, YANG P, et al. BERT-IDCNN-CRF for named entity recognition in Chinese[J]. Journal of Shandong University (Natural Science), 2020, 55(1):102-109. 10.6040/j.issn.1671-9352.2.2019.076 | |
| 19 | 王子牛,姜猛,高建瓴,等. 基于BERT的中文命名实体识别方法[J]. 计算机科学, 2019, 46(11A):138-142. |
| WANG Z N, JIANG M, GAO J L, et al. Chinese named entity recognition method based on BERT [J]. Computer Science, 2019, 46(11A): 138-142. | |
| 20 | 尹学振,赵慧,赵俊保,等. 多神经网络协作的军事领域命名实体识别[J]. 清华大学学报(自然科学版), 2020, 60(8):648-655. 10.16511/j.cnki.qhdxxb.2020.25.004 |
| YIN X Z, ZHAO H, ZHAO J B, et al. Multi-neural network collaboration for Chinese military named entity recognition[J]. Journal of Tsinghua University (Science and Technology), 2020, 60(8): 648-655. 10.16511/j.cnki.qhdxxb.2020.25.004 | |
| 21 | 王月,王孟轩,张胜,等. 基于BERT的警情文本命名实体识别[J]. 计算机应用, 2020, 40(2):535-540. 10.11772/j.issn.1001-9081.2019101717 |
| WANG Y, WANG M X, ZHANG S, et al. Alarm text named entity recognition based on BERT[J]. Journal of Computer Applications, 2020, 40(2): 535-540. 10.11772/j.issn.1001-9081.2019101717 | |
| 22 | LEE J, YOON W, KIM S, et al. BioBERT: a pre-trained biomedical language representation model for biomedical text mining[J]. Bioinformatics, 2020, 36(4): 1234-1240. 10.1093/bioinformatics/btz682 |
| 23 | HINTON G E , KRIZHEVSKY A , WANG S D. Transforming auto-encoders[C]// Proceedings of the 21st International Conference on Artificial Neural Networks, LNCS6791. Berlin: Springer, 2012: 44-51. |
| 24 | HINTON G E, SABOUR S, FROSST N. Matrix capsules with EM routing[EB/OL]. [2021-02-27].. |
| 25 | ZHANG N Y, DENG S M, SUN Z L, et al. Attention-based capsule networks with dynamic routing for relation extraction[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2018: 986-992. 10.18653/v1/d18-1120 |
| 26 | ZHANG X S, LI P S, JIA W J, et al. Multi-labeled relation extraction with attentive capsule network[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Palo Alto, CA: AAAI Press, 2019: 7484-7491. 10.1609/aaai.v33i01.33017484 |
| 27 | ZHAO W, YE J B, YANG M, et al. Investigating capsule networks with dynamic routing for text classification[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2018: 3110-3119. 10.18653/v1/d18-1350 |
| 28 | 王祺,邱家辉,阮彤,等. 基于循环胶囊网络的临床语义关系识别研究[J]. 广西师范大学学报(自然科学版), 2019, 37(1): 80-88. 10.1007/978-3-030-26072-9_6 |
| WANG Q, QIU J H, RUAN T, et al. Recurrent capsule network for clinical relation extraction[J]. Journal of Guangxi Normal University (Natural Science Edition), 2019, 37(1): 80-88. 10.1007/978-3-030-26072-9_6 |
| [1] | Yuqing WANG, Guangli ZHU, Wenjie DUAN, Shuyu LI, Ruotong ZHOU. Sentiment classification model of psychological counseling text based on attention over attention mechanism [J]. Journal of Computer Applications, 2024, 44(8): 2393-2399. |
| [2] | Yubo ZHAO, Liping ZHANG, Sheng YAN, Min HOU, Mao GAO. Relation extraction between discipline knowledge entities based on improved piecewise convolutional neural network and knowledge distillation [J]. Journal of Computer Applications, 2024, 44(8): 2421-2429. |
| [3] | Dianhui MAO, Xuebo LI, Junling LIU, Denghui ZHANG, Wenjing YAN. Chinese entity and relation extraction model based on parallel heterogeneous graph and sequential attention mechanism [J]. Journal of Computer Applications, 2024, 44(7): 2018-2025. |
| [4] | Yuan TANG, Yanping CHEN, Ying HU, Ruizhang HUANG, Yongbin QIN. Relation extraction model based on multi-scale hybrid attention convolutional neural networks [J]. Journal of Computer Applications, 2024, 44(7): 2011-2017. |
| [5] | Chao WEI, Yanping CHEN, Kai WANG, Yongbin QIN, Ruizhang HUANG. Relation extraction method based on mask prompt and gated memory network calibration [J]. Journal of Computer Applications, 2024, 44(6): 1713-1719. |
| [6] | Quan YUAN, Changping CHEN, Ze CHEN, Linfeng ZHAN. Twice attention mechanism distantly supervised relation extraction based on BERT [J]. Journal of Computer Applications, 2024, 44(4): 1080-1085. |
| [7] | Yongfeng DONG, Jiaming BAI, Liqin WANG, Xu WANG. Chinese named entity recognition combining prior knowledge and glyph features [J]. Journal of Computer Applications, 2024, 44(3): 702-708. |
| [8] | Andi GUO, Zhen JIA, Tianrui LI. High-precision entity and relation extraction in medical domain based on pseudo-entity data augmentation [J]. Journal of Computer Applications, 2024, 44(2): 393-402. |
| [9] | Kezheng CHEN, Xiaoran GUO, Yong ZHONG, Zhenping LI. Relation extraction method based on negative training and transfer learning [J]. Journal of Computer Applications, 2023, 43(8): 2426-2430. |
| [10] | Menglin HUANG, Lei DUAN, Yuanhao ZHANG, Peiyan WANG, Renhao LI. Prompt learning based unsupervised relation extraction model [J]. Journal of Computer Applications, 2023, 43(7): 2010-2016. |
| [11] | Jingsheng LEI, Kaijun LA, Shengying YANG, Yi WU. Joint entity and relation extraction based on contextual semantic enhancement [J]. Journal of Computer Applications, 2023, 43(5): 1438-1444. |
| [12] | Qinghai XU, Shifei DING, Tongfeng SUN, Jian ZHANG, Lili GUO. Improved capsule network based on multipath feature [J]. Journal of Computer Applications, 2023, 43(5): 1330-1335. |
| [13] | Shunhang CHENG, Zhihua LI, Tao WEI. Threat intelligence entity relation extraction method integrating bootstrapping and semantic role labeling [J]. Journal of Computer Applications, 2023, 43(5): 1445-1453. |
| [14] | Quan YUAN, Yunpeng XU, Chengliang TANG. Document-level relation extraction method based on path labels [J]. Journal of Computer Applications, 2023, 43(4): 1029-1035. |
| [15] | Liang XU, Chun ZHANG, Ning ZHANG, Xuetao TIAN. Zero-shot relation extraction model via multi-template fusion in Prompt [J]. Journal of Computer Applications, 2023, 43(12): 3668-3675. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||