


Journal of Computer Applications ›› 2023, Vol. 43 ›› Issue (9): 2735-2740.DOI: 10.11772/j.issn.1001-9081.2022081295
• Artificial intelligence • Previous Articles Next Articles
Bihui YU1,2, Xingye CAI1,2( ), Jingxuan WEI1,2
), Jingxuan WEI1,2
Received:2022-09-05
Revised:2022-12-09
Accepted:2023-01-03
Online:2023-02-28
Published:2023-09-10
Contact:
Xingye CAI
About author:YU Bihui, born in 1982, Ph. D., research fellow. His research interests include knowledge engineering, big data, semantic Web.Supported by:
于碧辉1,2, 蔡兴业1,2(), 魏靖烜1,2
通讯作者:
蔡兴业
作者简介:于碧辉(1982—),男,辽宁沈阳人,研究员,博士,主要研究方向:知识工程、大数据、语义网基金资助:CLC Number:
Bihui YU, Xingye CAI, Jingxuan WEI. Few-shot text classification method based on prompt learning[J]. Journal of Computer Applications, 2023, 43(9): 2735-2740.
于碧辉, 蔡兴业, 魏靖烜. 基于提示学习的小样本文本分类方法[J]. 《计算机应用》唯一官方网站, 2023, 43(9): 2735-2740.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2022081295

Fig. 1 Structure of BERT-P-tuning model
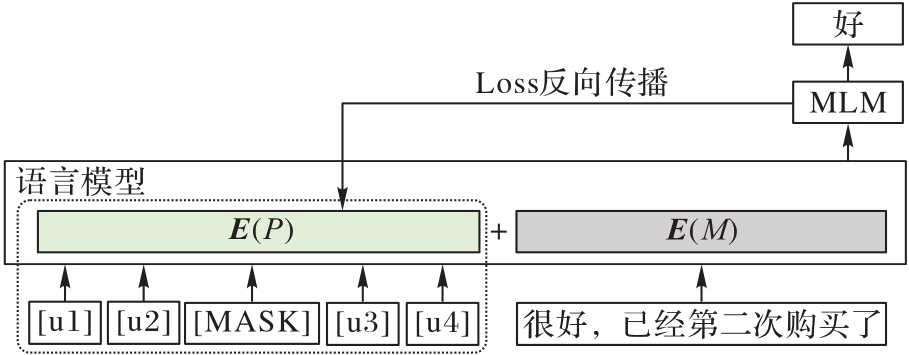
Fig. 2 Template prompt
| 数据集 | 单条训练集样本数 | 全量训练集样本数 | 测试集 样本数 | 标签数 |
|---|---|---|---|---|
| EPRSTMT | 32 | 160 | 610 | 2 |
| Tnews | 240 | 1 185 | 2 010 | 15 |
Tab. 1 Datasets used in experiments
| 数据集 | 单条训练集样本数 | 全量训练集样本数 | 测试集 样本数 | 标签数 |
|---|---|---|---|---|
| EPRSTMT | 32 | 160 | 610 | 2 |
| Tnews | 240 | 1 185 | 2 010 | 15 |
| 环境 | 配置 | 环境 | 配置 |
|---|---|---|---|
| 操作系统 | Linux-ubuntu 20.04 | GPU | Tesla P40 |
| PyTorch | 1.11.0+CUDA 11.3 | 内存 | 32 GB |
Tab. 2 Experimental environment
| 环境 | 配置 | 环境 | 配置 |
|---|---|---|---|
| 操作系统 | Linux-ubuntu 20.04 | GPU | Tesla P40 |
| PyTorch | 1.11.0+CUDA 11.3 | 内存 | 32 GB |
| 参数 | 值 |
|---|---|
| Transformer层数 | 12 |
| 优化器 | Adam |
| 学习率 | 10-5 |
| Batch_size | 8 |
| Max_length | 模板长度+最长样本长度 |
Tab. 3 Experimental parameters
| 参数 | 值 |
|---|---|
| Transformer层数 | 12 |
| 优化器 | Adam |
| 学习率 | 10-5 |
| Batch_size | 8 |
| Max_length | 模板长度+最长样本长度 |
| 模板 | 候选词 | 准确率/% |
|---|---|---|
| 这是一条[MASK]的评价。 | 正面/负面 | 56.5 |
| 我很[MASK]它。 | 喜欢/讨厌 | 73.9 |
| [MASK]满意 | 很/不 | 69.6 |
| 买完回来用了几天,个人认为还不错,[MASK]推荐大家购买。 | 很/不 | 74.4 |
| 但是性价比较[MASK]。 | 高/低 | 64.7 |
Tab. 4 Results of zero-shot experiment
| 模板 | 候选词 | 准确率/% |
|---|---|---|
| 这是一条[MASK]的评价。 | 正面/负面 | 56.5 |
| 我很[MASK]它。 | 喜欢/讨厌 | 73.9 |
| [MASK]满意 | 很/不 | 69.6 |
| 买完回来用了几天,个人认为还不错,[MASK]推荐大家购买。 | 很/不 | 74.4 |
| 但是性价比较[MASK]。 | 高/低 | 64.7 |
| 模型 | EPRTSMT | Tnews | ||
|---|---|---|---|---|
| Acc | F1 | Acc | F1 | |
| Metric BERT | 44.5 | 43.4 | 31.1 | 31.5 |
| LSTM | 52.8 | 63.4 | — | — |
| BERT | 61.7 | 60.6 | 48.0 | 47.1 |
| PET | 84.0 | 82.9 | 51.8 | 50.9 |
| BERT-P-Tuning | 86.9 | 87.3 | 54.6 | 55.1 |
Tab. 5 Comparison of results of different models
| 模型 | EPRTSMT | Tnews | ||
|---|---|---|---|---|
| Acc | F1 | Acc | F1 | |
| Metric BERT | 44.5 | 43.4 | 31.1 | 31.5 |
| LSTM | 52.8 | 63.4 | — | — |
| BERT | 61.7 | 60.6 | 48.0 | 47.1 |
| PET | 84.0 | 82.9 | 51.8 | 50.9 |
| BERT-P-Tuning | 86.9 | 87.3 | 54.6 | 55.1 |
| 模型 | EPRTSMT | Tnews | ||
|---|---|---|---|---|
| Acc | F1 | Acc | F1 | |
| LSTM-P-Tuning[ | 85.2 | 85.6 | 52.3 | 52.7 |
| BERT-P-Tuning-1 | 79.4 | 82.1 | 48.8 | 47.3 |
| BERT-P-Tuning-2 | 82.8 | 85.7 | 52.1 | 53.5 |
| BERT-P-Tuning-Final | 86.9 | 87.3 | 54.6 | 55.1 |
Tab. 6 Results of ablation experiment
| 模型 | EPRTSMT | Tnews | ||
|---|---|---|---|---|
| Acc | F1 | Acc | F1 | |
| LSTM-P-Tuning[ | 85.2 | 85.6 | 52.3 | 52.7 |
| BERT-P-Tuning-1 | 79.4 | 82.1 | 48.8 | 47.3 |
| BERT-P-Tuning-2 | 82.8 | 85.7 | 52.1 | 53.5 |
| BERT-P-Tuning-Final | 86.9 | 87.3 | 54.6 | 55.1 |
| 1 | CAI J J, LI J P, LI W, et al. Deeplearning model used in text classification[C]// Proceedings of the 15th International Computer Conference on Wavelet Active Media Technology and Information Processing. Piscataway: IEEE, 2018: 123-126. 10.1109/iccwamtip.2018.8632592 |
| 2 | 赵凯琳,靳小龙,王元卓. 小样本学习研究综述[J]. 软件学报, 2021, 32(2):349-369. 10.13328/j.cnki.jos.006138 |
| ZHAO K L, JIN X L, WANG Y Z. Survey on few-shot learning[J]. Journal of Software, 2021, 32(2):349-369. 10.13328/j.cnki.jos.006138 | |
| 3 | 李凡长,刘洋,吴鹏翔,等. 元学习研究综述[J]. 计算机学报, 2021, 44(2):422-446. 10.11897/SP.J.1016.2021.00422 |
| LI F Z, LIU Y, WU P X, et al. A survey on recent advances in meta-learning[J]. Chinese Journal of Computers, 2021, 44(2):422-446. 10.11897/SP.J.1016.2021.00422 | |
| 4 | ANDRYCHOWICZ M, DENIL M, COLMENAREJO S G, et al. Learning to learn by gradient descent by gradient descent[C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2016: 3988-3996. |
| 5 | RAVI S, LAROCHELLE H. Optimization as a model for few-shot learning[EB/OL]. (2022-07-22) [2022-08-12].. 10.1007/978-3-030-63416-2_861 |
| 6 | FINN C, ABBEEL P, LEVINE S. Model-agnostic meta-learning for fast adaptation of deep networks[C]// Proceedings of the 34th International Conference on Machine Learning. New York: JMLR.org, 2017: 1126-1135. 10.1109/icra.2016.7487173 |
| 7 | VINYALS O, BLUNDELL C, LILLICRAP T, et al. Matching networks for one shot learning[C]// Proceedings of the 30th International Conference on Neural Information Processing System. Red Hook, NY: Curran Associates Inc., 2016:3637-3645. |
| 8 | CAI Q, PAN Y W, YAO T, et al. Memory matching networks for one-shot image recognition[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 4080-4088. 10.1109/cvpr.2018.00429 |
| 9 | SNELL J, SWERSKY K, ZEMEL R. Prototypical networks for few-shot learning[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 4080-4090. |
| 10 | MEHROTRA A, DUKKIPATI A. Generative adversarial residual pairwise networks for one shot learning[EB/OL]. (2017-03-23) [2022-08-31].. 10.1109/wacv.2019.00099 |
| 11 | HOU R B, CHANG H, MA B P, et al. Cross attention network for few-shot classification[C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2019: 4003-4014. |
| 12 | GENG R Y, LI B H, LI Y B, et al. Induction networks for few-shot text classification[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2019: 3904-3913. 10.18653/v1/d19-1403 |
| 13 | YU M, GUO X X, YI J F, et al. Diverse few-shot text classification with multiple metrics[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). Stroudsburg, PA: ACL, 2018: 1206-1215. 10.18653/v1/n18-1109 |
| 14 | BAILEY K, CHOPRA S. Few-shot text classification with pre-trained word embeddings and a human in the loop[EB/OL]. (2018-04-05) [2022-08-12].. 10.48550/arXiv.1804.02063 |
| 15 | RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training[EB/OL]. [2022-08-12].. |
| 16 | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg, PA: ACL, 2019: 4171-4186. 10.18653/v1/n18-2 |
| 17 | YANG Z L, DAI Z H, YANG Y M, et al. XLNet: generalized autoregressive pretraining for language understanding[C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2019: 5754-5764. |
| 18 | SONG K T, TAN X, QIN T, et al. MPNet: masked and permuted pre-training for language understanding[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2020: 16857-16867. 10.48550/arXiv.2004.09297 |
| 19 | 李舟军,范宇,吴贤杰. 面向自然语言处理的预训练技术研究综述[J]. 计算机科学, 2020, 47(3):162-173. 10.11896/jsjkx.191000167 |
| LI Z J, FAN Y, WU X J. Survey of natural language processing pre-training techniques[J]. Computer Science, 2020, 47(3):162-173. 10.11896/jsjkx.191000167 | |
| 20 | LIU P F, YUAN W Z, FU J L, et al. Pre-train, prompt, and predict: a systematic survey of prompting methods in natural language processing[EB/OL]. (2021-07-28) [2022-08-21].. 10.1145/3560815 |
| 21 | SCHICK T, SCHÜTZE H. Exploiting cloze questions for few shot text classification and natural language inference[C]// Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. Stroudsburg, PA: ACL, 2021: 255-269. 10.18653/v1/2021.eacl-main.20 |
| 22 | LI X L, LIANG P. Prefix-tuning: optimizing continuous prompts for generation[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, PA: ACL, 2021: 4582-4597. 10.18653/v1/2021.acl-long.353 |
| 23 | LIU X, ZHENG Y N, DU Z X, et al. GPT understands, too[EB/OL]. (2021-03-18) [2022-08-29].. 10.1016/j.aiopen.2023.08.012 |
| 24 | HOULSBY N, GIURGIU A, JASTRZĘBSKI S, et al. Parameter-efficient transfer learning for NLP[C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 2790-2799. |
| 25 | XU L, LU X J, YUAN C Y, et al. FewCLUE: a Chinese few-shot learning evaluation benchmark[EB/OL]. (2021-09-29) [2022-08-29].. |
| 26 | CUI Y M, CHE W X, LIU T, et al. Pre-training with whole word masking for Chinese BERT[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 3504-3514. 10.1109/taslp.2021.3124365 |
| 27 | SUN Y, ZHENG Y, HAO C, et al. NSP-BERT: a prompt-based zero-shot learner through an original pre-training task - next sentence prediction[C]// Proceedings of the 29th International Conference on Computational Linguistics. Stroudsburg, PA: ACL, 2022: 3233-3250. |
| [1] | Chenyang LI, Long ZHANG, Qiusheng ZHENG, Shaohua QIAN. Multivariate controllable text generation based on diffusion sequences [J]. Journal of Computer Applications, 2024, 44(8): 2414-2420. |
| [2] | Xindong YOU, Yingzi WEN, Xinpeng SHE, Xueqiang LYU. Triplet extraction method for mine electromechanical equipment field [J]. Journal of Computer Applications, 2024, 44(7): 2026-2033. |
| [3] | Xun YAO, Zhongzheng QIN, Jie YANG. Generative label adversarial text classification model [J]. Journal of Computer Applications, 2024, 44(6): 1781-1785. |
| [4] | Zhengyu ZHAO, Jing LUO, Xinhui TU. Information retrieval method based on multi-granularity semantic fusion [J]. Journal of Computer Applications, 2024, 44(6): 1775-1780. |
| [5] | Junfeng SHEN, Xingchen ZHOU, Can TANG. Dual-channel sentiment analysis model based on improved prompt learning method [J]. Journal of Computer Applications, 2024, 44(6): 1796-1806. |
| [6] | Xinyan YU, Cheng ZENG, Qian WANG, Peng HE, Xiaoyu DING. Few-shot news topic classification method based on knowledge enhancement and prompt learning [J]. Journal of Computer Applications, 2024, 44(6): 1767-1774. |
| [7] | Hang YU, Yanling ZHOU, Mengxin ZHAI, Han LIU. Text classification based on pre-training model and label fusion [J]. Journal of Computer Applications, 2024, 44(3): 709-714. |
| [8] | Jiawei ZHANG, Guandong GAO, Ke XIAO, Shengzun SONG. Violent crime hierarchy algorithm by joint modeling of improved hierarchical attention network and TextCNN [J]. Journal of Computer Applications, 2024, 44(2): 403-410. |
| [9] | Kaitian WANG, Qing YE, Chunlei CHENG. Classification method for traditional Chinese medicine electronic medical records based on heterogeneous graph representation [J]. Journal of Computer Applications, 2024, 44(2): 411-417. |
| [10] | Yingjie GAO, Min LIN, Siriguleng, Bin LI, Shujun ZHANG. Prompt learning method for ancient text sentence segmentation and punctuation based on span-extracted prototypical network [J]. Journal of Computer Applications, 2024, 44(12): 3815-3822. |
| [11] | Xiang LIN, Biao JIN, Weijing YOU, Zhiqiang YAO, Jinbo XIONG. Model integrity verification framework of deep neural network based on fragile fingerprint [J]. Journal of Computer Applications, 2024, 44(11): 3479-3486. |
| [12] | Li XIE, Weiping SHU, Junjie GENG, Qiong WANG, Hailin YANG. Few-shot cervical cell classification combining weighted prototype and adaptive tensor subspace [J]. Journal of Computer Applications, 2024, 44(10): 3200-3208. |
| [13] | Xinyue ZHANG, Rong LIU, Chiyu WEI, Ke FANG. Aspect-based sentiment analysis method with integrating prompt knowledge [J]. Journal of Computer Applications, 2023, 43(9): 2753-2759. |
| [14] | Xiaomin ZHOU, Fei TENG, Yi ZHANG. Automatic international classification of diseases coding model based on meta-network [J]. Journal of Computer Applications, 2023, 43(9): 2721-2726. |
| [15] | Yuelin TIAN, Ruizhang HUANG, Lina REN. Scholar fine-grained information extraction method fused with local semantic features [J]. Journal of Computer Applications, 2023, 43(9): 2707-2714. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||