


Journal of Computer Applications ›› 2024, Vol. 44 ›› Issue (3): 767-771.DOI: 10.11772/j.issn.1001-9081.2023030365
Special Issue: 数据科学与技术
• Data science and technology • Previous Articles Next Articles
Shengjie MENG( ), Wanjun YU, Ying CHEN
), Wanjun YU, Ying CHEN
Received:2023-04-04
Revised:2023-05-16
Accepted:2023-05-19
Online:2023-06-05
Published:2024-03-10
Contact:
Shengjie MENG
About author:YU Wanjun,born in 1966, Ph. D., professor. His research interests include artificial intelligence, big data.Supported by:
孟圣洁(), 于万钧, 陈颖
通讯作者:
孟圣洁
作者简介:于万钧(1966—),男,吉林德惠人,教授,博士,CCF会员,主要研究方向:人工智能、大数据基金资助:CLC Number:
Shengjie MENG, Wanjun YU, Ying CHEN. Feature selection algorithm for high-dimensional data with maximum correlation and maximum difference[J]. Journal of Computer Applications, 2024, 44(3): 767-771.
孟圣洁, 于万钧, 陈颖. 最大相关和最大差异的高维数据特征选择算法[J]. 《计算机应用》唯一官方网站, 2024, 44(3): 767-771.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.joca.cn/EN/10.11772/j.issn.1001-9081.2023030365
| 数据集 | 特征数 | 样本数 | 类别数 |
|---|---|---|---|
| COIL | 1 024 | 1 440 | 20 |
| Colon | 2 000 | 62 | 2 |
| RELA | 4 322 | 1 427 | 2 |
| Leuk | 7 070 | 72 | 2 |
| ARBT | 8 266 | 1 427 | 8 |
| CLL | 11 340 | 111 | 3 |
Tab. 1 Dataset information
| 数据集 | 特征数 | 样本数 | 类别数 |
|---|---|---|---|
| COIL | 1 024 | 1 440 | 20 |
| Colon | 2 000 | 62 | 2 |
| RELA | 4 322 | 1 427 | 2 |
| Leuk | 7 070 | 72 | 2 |
| ARBT | 8 266 | 1 427 | 8 |
| CLL | 11 340 | 111 | 3 |
| 数据集 | RR | MIC | mRMR | WCFR | PSO | MCD |
|---|---|---|---|---|---|---|
| Avg | 63.87 | 67.44 | 72.48 | 66.98 | 54.35 | 78.15 |
| COIL | 48.14 | 59.28 | 55.21 | 60.95 | 40.52 | 80.47 |
| Colon | 74.18 | 78.12 | 77.12 | 73.65 | 69.79 | 86.27 |
| RELA | 57.09 | 66.51 | 74.70 | 59.96 | 57.34 | 75.27 |
| Leuk | 93.43 | 90.69 | 95.67 | 90.11 | 76.93 | 98.14 |
| ARBT | 47.87 | 57.87 | 62.62 | 58.06 | 33.54 | 65.42 |
| CLL | 62.48 | 52.17 | 69.54 | 59.12 | 47.98 | 63.31 |
Tab. 2 Comparison of average classification accuracy between MCD and other algorithms with SVM classifier
| 数据集 | RR | MIC | mRMR | WCFR | PSO | MCD |
|---|---|---|---|---|---|---|
| Avg | 63.87 | 67.44 | 72.48 | 66.98 | 54.35 | 78.15 |
| COIL | 48.14 | 59.28 | 55.21 | 60.95 | 40.52 | 80.47 |
| Colon | 74.18 | 78.12 | 77.12 | 73.65 | 69.79 | 86.27 |
| RELA | 57.09 | 66.51 | 74.70 | 59.96 | 57.34 | 75.27 |
| Leuk | 93.43 | 90.69 | 95.67 | 90.11 | 76.93 | 98.14 |
| ARBT | 47.87 | 57.87 | 62.62 | 58.06 | 33.54 | 65.42 |
| CLL | 62.48 | 52.17 | 69.54 | 59.12 | 47.98 | 63.31 |
| 数据集 | RR | MIC | mRMR | WCFR | PSO | MCD |
|---|---|---|---|---|---|---|
| Avg | 64.00 | 70.58 | 73.73 | 69.32 | 51.24 | 76.42 |
| COIL | 69.70 | 82.57 | 80.00 | 85.11 | 41.13 | 84.35 |
| Colon | 72.13 | 77.41 | 78.62 | 75.23 | 66.66 | 85.68 |
| RELA | 55.42 | 61.82 | 67.51 | 65.35 | 53.87 | 74.21 |
| Leuk | 93.27 | 92.42 | 94.91 | 90.32 | 72.71 | 97.57 |
| ARBT | 34.03 | 46.87 | 49.85 | 45.44 | 20.77 | 54.41 |
| CLL | 59.43 | 62.36 | 71.46 | 54.44 | 52.28 | 62.27 |
Tab. 3 Comparison of average classification accuracy between MCD and other algorithms with KNN classifier (K=5)
| 数据集 | RR | MIC | mRMR | WCFR | PSO | MCD |
|---|---|---|---|---|---|---|
| Avg | 64.00 | 70.58 | 73.73 | 69.32 | 51.24 | 76.42 |
| COIL | 69.70 | 82.57 | 80.00 | 85.11 | 41.13 | 84.35 |
| Colon | 72.13 | 77.41 | 78.62 | 75.23 | 66.66 | 85.68 |
| RELA | 55.42 | 61.82 | 67.51 | 65.35 | 53.87 | 74.21 |
| Leuk | 93.27 | 92.42 | 94.91 | 90.32 | 72.71 | 97.57 |
| ARBT | 34.03 | 46.87 | 49.85 | 45.44 | 20.77 | 54.41 |
| CLL | 59.43 | 62.36 | 71.46 | 54.44 | 52.28 | 62.27 |
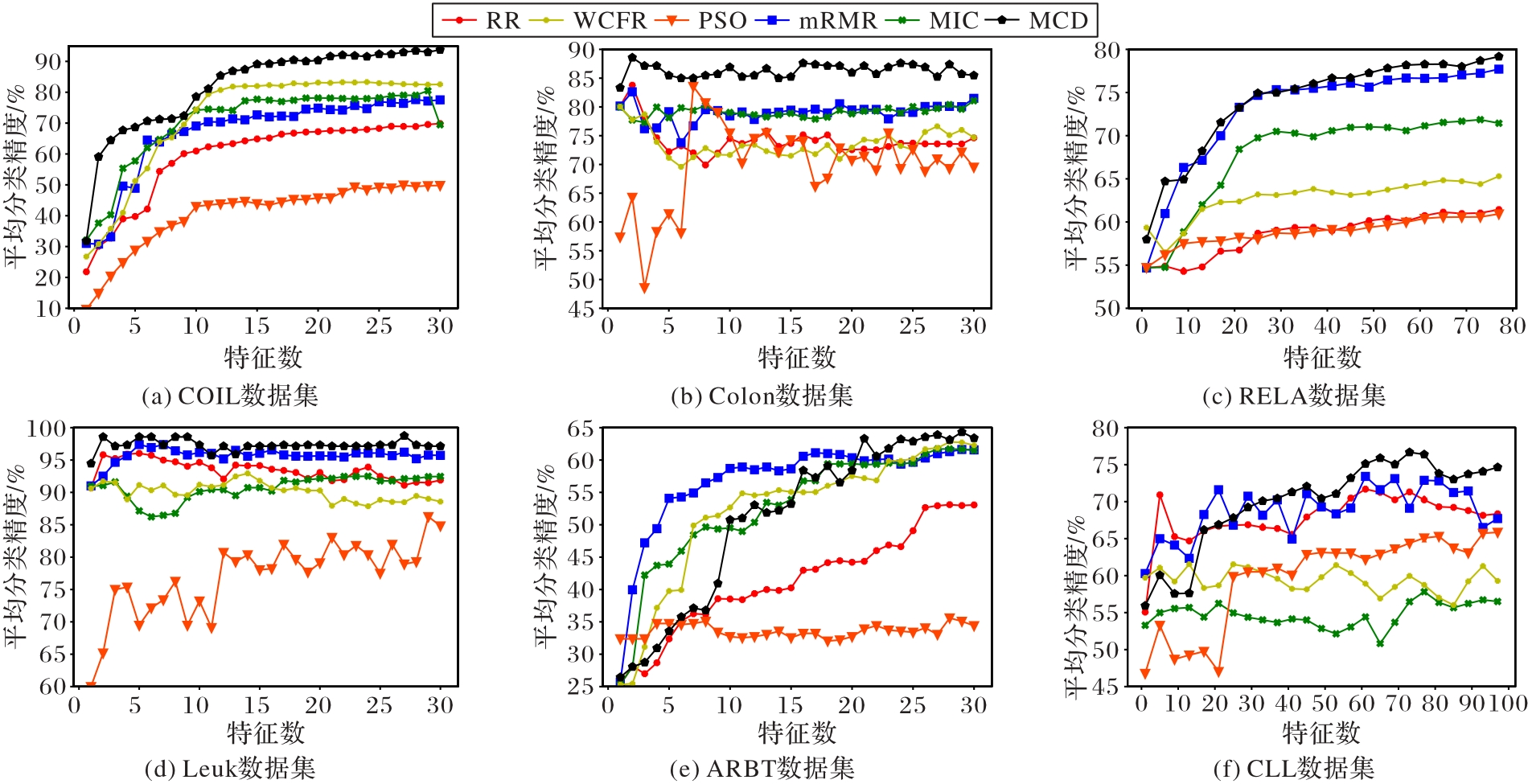
Fig. 1 Average classification accuracies of different algorithms on six datasets
| 1 | 章蓉,陈谊,张梦录,等.高维数据聚类可视分析方法综述[J].图学学报,2020,41(1):44-56. |
| ZHANG R, CHEN Y, ZHANG M L, et al. Overviewing of visual analysis appoaches for clustering high-dimensional data [J]. Journal of Graphics, 2020,41(1):44-56. | |
| 2 | 王艳丽,梁静,薛冰,等.基于进化计算的特征选择方法研究概述[J].郑州大学学报(工学版),2020,41(1):49-57. 10.13705/j.issn.1671-6833.2019.04.026 |
| WANG Y L, LIANG J, XUE B, et al. Research on evolutionary computation for feature selection [J]. Journal of Zhengzhou University (Engineering Science), 2020, 41(1):49-57. 10.13705/j.issn.1671-6833.2019.04.026 | |
| 3 | SHEIKHPOUR R, SARRAM M A, GHARAGHANI S, et al. A survey on semi-supervised feature selection methods [J]. Pattern Recognition, 2017, 64:141-158. 10.1016/j.patcog.2016.11.003 |
| 4 | MAFARJA M, MIRJALILI S. Whale optimization approaches for wrapper feature selection [J]. Applied Soft Computing, 2018,62:441-453. 10.1016/j.asoc.2017.11.006 |
| 5 | VIOLA M, SANGIOVANNI M, TORALDO G, et al. A generalized eigenvalues classifier with embedded feature selection [J]. Optimization Letters, 2017, 11: 299-311. 10.1007/s11590-015-0955-7 |
| 6 | PARLAK B, UYSAL A K. A novel filter feature selection method for text classification: extensive feature selector [J]. Journal of Information Science, 2023, 49(1): 59-78. 10.1177/0165551521991037 |
| 7 | CUI X, LI Y, FAN J, et al. A novel filter feature selection algorithm based on Relief [J]. Applied Intelligence, 2022, 52: 5063-5081. 10.1007/s10489-021-02659-x |
| 8 | LIU Z, YANG J, WANG L, et al. A novel relation aware wrapper method for feature selection [J]. Pattern Recognition, 2023, 140: No.109566. 10.1016/j.patcog.2023.109566 |
| 9 | LIU W, WANG J. Recursive elimination current algorithms and a distributed computing scheme to accelerate wrapper feature selection[J]. Information Sciences, 2022, 589: 636-654. 10.1016/j.ins.2021.12.086 |
| 10 | CHANG H, GUO J, ZHU W. Rethinking embedded unsupervised feature selection: a simple joint approach [J]. IEEE Transactions on Big Data, 2023, 9(1): 380-387. 10.1109/tbdata.2022.3178715 |
| 11 | ZHANG Y, HU Y, GAO X, et al. An embedded vertical-federated feature selection algorithm based on particle swarm optimisation [J]. CAAI Transaction on Intelligence Technology, 2023, 8(3): 734-754. 10.1049/cit2.12122 |
| 12 | 万琳,夏树进,朱毅,等.一种改进的基于信息熵的半监督特征选择算法[J].统计与决策,2021,37(17):66-70. |
| WAN L, XIA S J, ZHU Y, et al. An improved semi-supervised feature selection algorithm based on information entropy [J]. Statistics and Decision, 2021, 37 (17): 66-70. | |
| 13 | 王锋,刘吉超,魏巍.基于信息熵的半监督特征选择算法[J].计算机科学,2018,45(11A):427-430. 10.11896/j.issn.1002-137X.2018.11A.088 |
| WANG F, LIU J C, WEI W.Semi-supervised feature selection algorithm based on information entropy[J].Computer Science, 2018,45(11A): 427-430. 10.11896/j.issn.1002-137X.2018.11A.088 | |
| 14 | 翟俊海,刘博,张素芳.基于粗糙集相对分类信息熵和粒子群优化的特征选择方法[J].智能系统学报,2017,12(3):397-404. 10.11992/tis.201705004 |
| ZHAI J H, LIU B, ZHANG S F. A feature selection approach based on rough set relative classification information entropy and particle swarm optimization [J]. CAAI Transactions on Intelligent Systems, 2017,12 (3): 397-404. 10.11992/tis.201705004 | |
| 15 | HU L, GAO L, LI Y, et al. Feature-specific mutual information variation for multi-label feature selection [J]. Information Sciences, 2022, 593: 449-471. 10.1016/j.ins.2022.02.024 |
| 16 | LI C, HU L, LI Y, et al. Information-theoretic feature selection based on the weight of the new classification information [C]// Proceedings of the 2022 2nd International Conference on Consumer Electronics and Computer Engineering. Piscataway: IEEE, 2022: 617-622. 10.1109/iccece54139.2022.9712810 |
| 17 | 徐洪峰,孙振强.多标签学习中基于互信息的快速特征选择方法[J].计算机应用,2019,39(10):2815-2821. |
| XU H F, SUN Z Q. Fast feature selection method based on mutual information in multi label learning [J]. Journal of Computer Applications, 2019, 39(10): 2815-2821. | |
| 18 | 李洋,冯早,黄国勇,等.基于广义Fisher-互信息的管道堵塞故障特征选择方法[J].电子测量与仪器学报,2018,32(11):1-8. |
| LI Y, FENG Z, HUANG G Y, et al. Feature selection method for pipeline blockage based on generalized Fisher-mutual information [J]. Journal of Electronic Measurement and Instrumentation, 2018, 32 (11): 1-8. | |
| 19 | 张俐,王枞.基于最大相关最小冗余联合互信息的多标签特征选择算法[J].通信学报,2018,39(5):111-122. 10.11959/j.issn.1000-436x.2018082 |
| ZHANG L, WANG C. Multi-label feature selection algorithm based on joint mutual information of max-relation min-redundancy [J]. Journal on Communications, 2018,39(5): 111-122. 10.11959/j.issn.1000-436x.2018082 | |
| 20 | GAO W, HU L, ZHANG P. Class-specific mutual information variation for feature selection [J]. Pattern Recognition, 2018, 79: 328-339. 10.1016/j.patcog.2018.02.020 |
| 21 | RAKES D K, JANA P K. A general framework for class label specific mutual information feature selection method [J]. IEEE Transactions on Information Theory, 2022, 68(12): 7996-8014. 10.1109/tit.2022.3188708 |
| 22 | WANG Y, LI X, RUIZ R. Feature selection with maximal relevance and minimal supervised redundancy [J]. IEEE Transactions on Cybernetics, 2023, 53(2): 707-717. 10.1109/tcyb.2021.3139898 |
| 23 | ROBNIK-ŠIKONJA M, KONONENKO I. An adaptation of Relief for attribute estimation in regression [C]// Proceedings of the 14th International Conference on Machine learning. San Francisco: Morgan Kaufmann, 1997, 5: 296-304. |
| 24 | RESHEF D N, RESHEF Y A, FINUCANE H K, et al. Detecting novel associations in large data sets [J]. Science, 2011, 334(6062): 1518-1524. 10.1126/science.1205438 |
| 25 | PENG H, LONG F, DING C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(8): 1226-1238. 10.1109/tpami.2005.159 |
| 26 | GAO W, HU L, ZHANG P, et al. Feature selection considering the composition of feature relevancy [J]. Pattern Recognition Letters, 2018,112: 70-74. 10.1016/j.patrec.2018.06.005 |
| 27 | ZHOU H, WANG X, ZHANG Y. Feature selection based on weighted conditional mutual information [J/OL]. Applied Computing and Informatics, 2020[2023-03-01]. . |
| 28 | ZHANG P, GAO W. Feature selection considering uncertainty change ratio of the class label [J]. Applied Soft Computing, 2020, 95: 106537. 10.1016/j.asoc.2020.106537 |
| 29 | MEILĂ M.Comparing clusterings — an information based distance[J]. Journal of Multivariate Analysis, 2007,98(5):873-895. 10.1016/j.jmva.2006.11.013 |
| 30 | ZHANG P, GAO W, LIU G. Feature selection considering weighted relevancy [J]. Applied Intelligence,2018,48:4615-4625. 10.1007/s10489-018-1239-6 |
| 31 | KENNEDY J, EBERHART R. Particle swarm optimization [C]// Proceedings of the 1995 International Conference on Neural Networks. Piscataway: IEEE,1995, 4:1942-1948. 10.1109/ICNN.1995.488968 |
| [1] | Liting LI, Bei HUA, Ruozhou HE, Kuang XU. Multivariate time series prediction model based on decoupled attention mechanism [J]. Journal of Computer Applications, 2024, 44(9): 2732-2738. |
| [2] | Yun LI, Fuyou WANG, Peiguang JING, Su WANG, Ao XIAO. Uncertainty-based frame associated short video event detection method [J]. Journal of Computer Applications, 2024, 44(9): 2903-2910. |
| [3] | Wentao JIANG, Wanxuan LI, Shengchong ZHANG. Correlation filtering based target tracking with nonlinear temporal consistency [J]. Journal of Computer Applications, 2024, 44(8): 2558-2570. |
| [4] | Hong CHEN, Bing QI, Haibo JIN, Cong WU, Li’ang ZHANG. Class-imbalanced traffic abnormal detection based on 1D-CNN and BiGRU [J]. Journal of Computer Applications, 2024, 44(8): 2493-2499. |
| [5] | Hongtao SONG, Jiangsheng YU, Qilong HAN. Industrial multivariate time series data quality assessment method [J]. Journal of Computer Applications, 2024, 44(6): 1743-1750. |
| [6] | Lin GAO, Yu ZHOU, Tak Wu KWONG. Evolutionary bi-level adaptive local feature selection [J]. Journal of Computer Applications, 2024, 44(5): 1408-1414. |
| [7] | Mingzhu LEI, Hao WANG, Rong JIA, Lin BAI, Xiaoying PAN. Oversampling algorithm based on synthesizing minority class samples using relationship between features [J]. Journal of Computer Applications, 2024, 44(5): 1428-1436. |
| [8] | Shunwang FU, Qian CHEN, Zhi LI, Guomei WANG, Yu LU. Two-channel progressive feature filtering network for tampered image detection and localization [J]. Journal of Computer Applications, 2024, 44(4): 1303-1309. |
| [9] | Lin SUN, Menghan LIU. K-means clustering based on adaptive cuckoo optimization feature selection [J]. Journal of Computer Applications, 2024, 44(3): 831-841. |
| [10] | Shuai REN, Yuanfa JI, Xiyan SUN, Zhaochuan WEI, Zian LIN. Prediction of landslide displacement based on improved grey wolf optimizer and support vector regression [J]. Journal of Computer Applications, 2024, 44(3): 972-982. |
| [11] | Dapeng XU, Xinmin HOU. Feature selection method for graph neural network based on network architecture design [J]. Journal of Computer Applications, 2024, 44(3): 663-670. |
| [12] | Chenghao YANG, Jie HU, Hongjun WANG, Bo PENG. Incomplete multi-view clustering algorithm based on attention mechanism [J]. Journal of Computer Applications, 2024, 44(12): 3784-3789. |
| [13] | Jingxin LIU, Wenjing HUANG, Liangsheng XU, Chong HUANG, Jiansheng WU. Unsupervised feature selection model with dictionary learning and sample correlation preservation [J]. Journal of Computer Applications, 2024, 44(12): 3766-3775. |
| [14] | Bo LI, Jianqiang HUANG, Dongqiang HUANG, Xiaoying WANG. Adaptive computing optimization of sparse matrix-vector multiplication based on heterogeneous platforms [J]. Journal of Computer Applications, 2024, 44(12): 3867-3875. |
| [15] | Jia CHEN, Hong ZHANG. Image text retrieval method based on feature enhancement and semantic correlation matching [J]. Journal of Computer Applications, 2024, 44(1): 16-23. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||